一、数据备份的重要性
-
备份的主要目的是灾难恢复。
-
在生产环境中,数据的安全性至关重要。
-
任何数据的丢失都可能产生严重的后果。
-
造成数据丢失的原因:
- 程序错误
- 人为操作错误
- 运算错误
- 磁盘故障
- 灾难(如火灾、地震)和盗窃
二、数据库备份的分类和备份策略
2.1 数据库备份的分类
1)物理备份
物理备份:对数据库操作系统的物理文件(如数据文件、日志文件等)的备份。
物理备份方法:
- 冷备份(脱机备份) :是在关闭数据库的时候进行的
- 热备份(联机备份) :数据库处于运行状态,依赖于数据库的日志文件
- 温备份:数据库锁定表格(不可写入但可读)的状态下进行备份操作
2)逻辑备份
逻辑备份:对数据库逻辑组件(如:表等数据库对象)的备份。
- 即以sql语句的形式,把库、表结构、表数据保存下来
2.2 数据库的备份策略
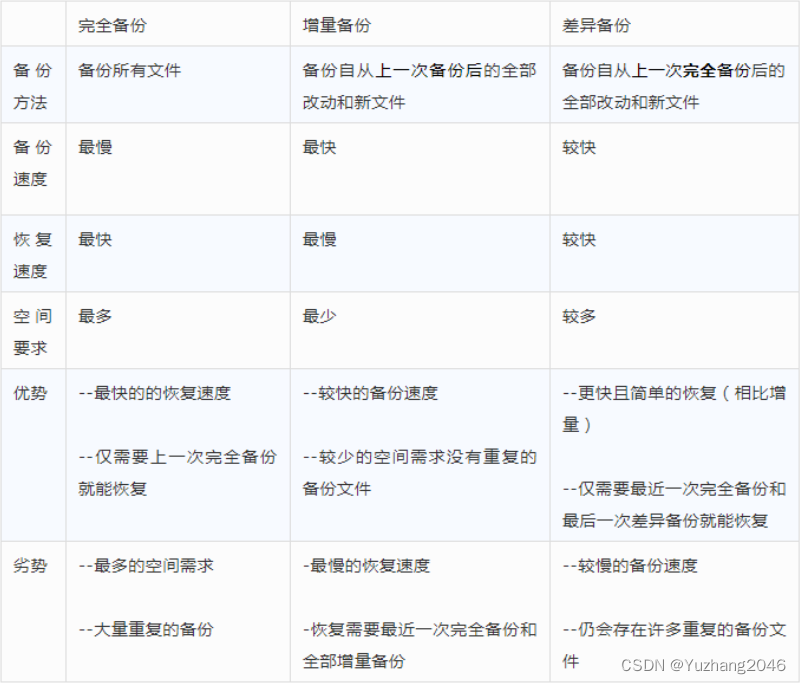
- 完全备份(全量备份):每次对数据库进行完整的备份。
- 差异备份:备份自从上次完全备份之后被修改过的文件。
- 增量备份:只有在上次完全备份或者增量备份后被修改的文件才会被备份。

三、常见的备份方法
物理冷备: (完全备份)
- 备份时数据库处于关闭状态,直接打包数据库文件
- 备份速度快,恢复时也是最简单的
专用备份工具mydump或mysqlhotcopy (完全备份,逻辑备份)
- mysqldump常用的逻辑备份工具 (导出为sql脚本)
- mysqlhotcopy仅拥有备份MyISAM和ARCHIVE表
启用二进制日志进行增量备份 (增量备份)
- 进行增量备份,需要刷新二进制日志
第三方工具备份
- 免费的MySQL热备份软件Percona XtraBackup
(阿里云的工具:dts,支持热迁移)
四、MySQL完全备份介绍
4.1 什么是完全备份
- 完全备份是对整个数据库、数据库结构和文件结构的备份
- 保存的是备份完成时刻的数据库
- 是差异备份与增量备份的基础
4.2 完全备份的优缺点
优点:
- 备份与恢复操作简单方便
缺点:
- 数据存在大量的重复
- 占用大量的备份空间
- 备份与恢复时间长
4.3 完全备份的方法
1)物理冷备份与恢复
- 关闭MySQL数据库
- 使用tar命令直接打包数据库文件夹
- 直接替换现有MySQL目录即可
2)mysqldump备份与恢复
- MySQL自带的备份工具,可方便实现对MySQL的备份
- 可以将指定的库、表导出为SQL脚本
- 使用命令mysq|导入备份的数据
五、完全备份与恢复 操作演示
5.1 物理冷备份
5.1.1 完全备份
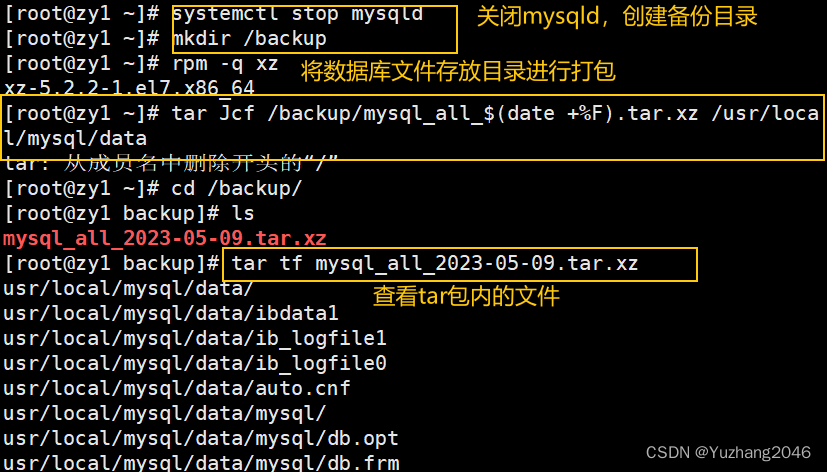
先关闭数据库,之后打包备份
systemctl stop mysqld #先关闭服务
mkdir /backup/ #创建备份目录
rpm -q xz #使用xz工具进行压缩,检查xz工具是否已安装
yum install xz -y #如果没安装,可以先yum安装
tar Jcf /backup/mysql_all_$(date +%F).tar.xz /usr/local/mysql/data #打包数据库文件。/usr/local/mysql/data 为数据库文件存放目录
cd /backup/ #切换到备份目录
ls #查看目录内容
tar tf mysql_all_2022-06-05.tar.xz #查看tar包内的文件
5.1.2 完全恢复
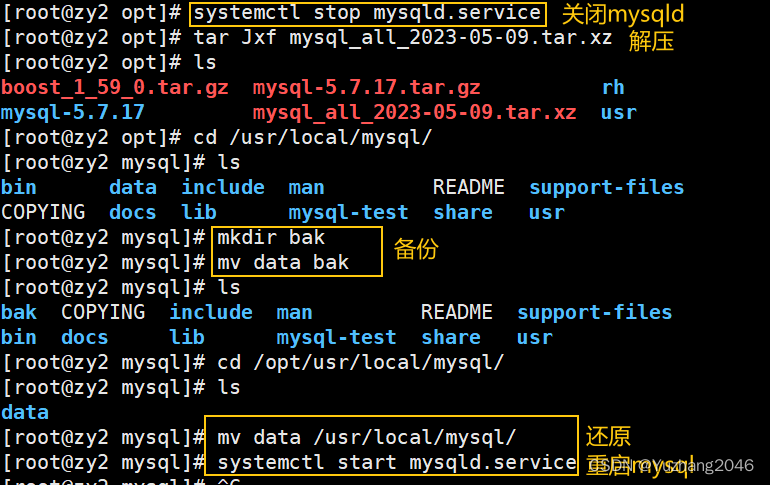
将数据库迁移到另一台主机zy2,测试完全恢复。
#主机A,使用scp命令将tar包传给另一台主机B
scp /backup/mysql_all_2023-05-09.tar.xz 192.168.126.22:/opt
##主机B的操作##
systemctl stop mysqld #关闭mysql
cd /opt/
tar Jxf mysql_all_2023-05-09.tar.xz
cd /usr/local/mysql/
mkdir bak
mv data bak
cd /opt/usr/local/mysql/
mv data /usr/local/mysql/
systemctl start mysqld #启动mysql
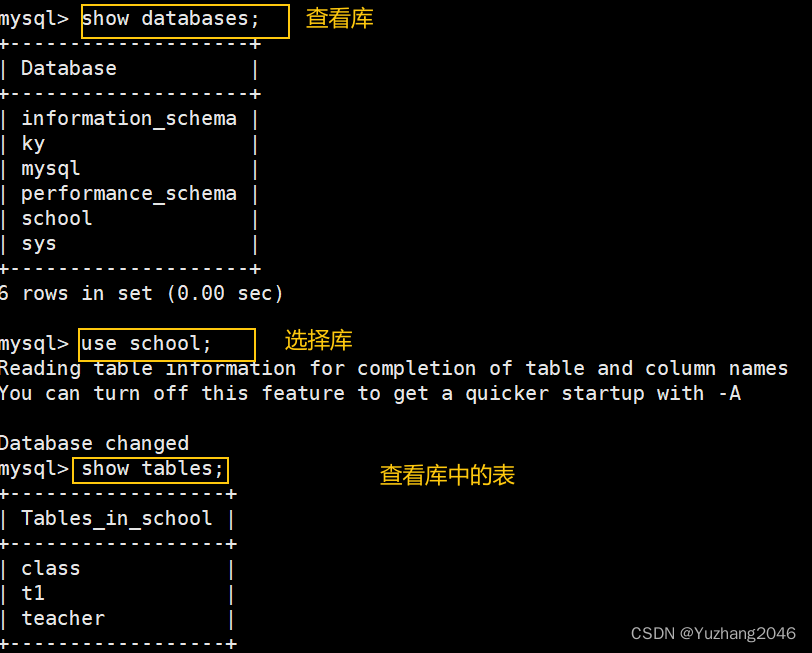
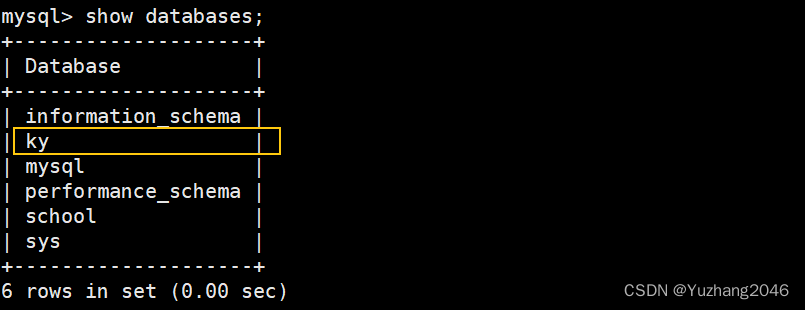
mysql -u root -p #登录数据库查看
show databases;
use ky;
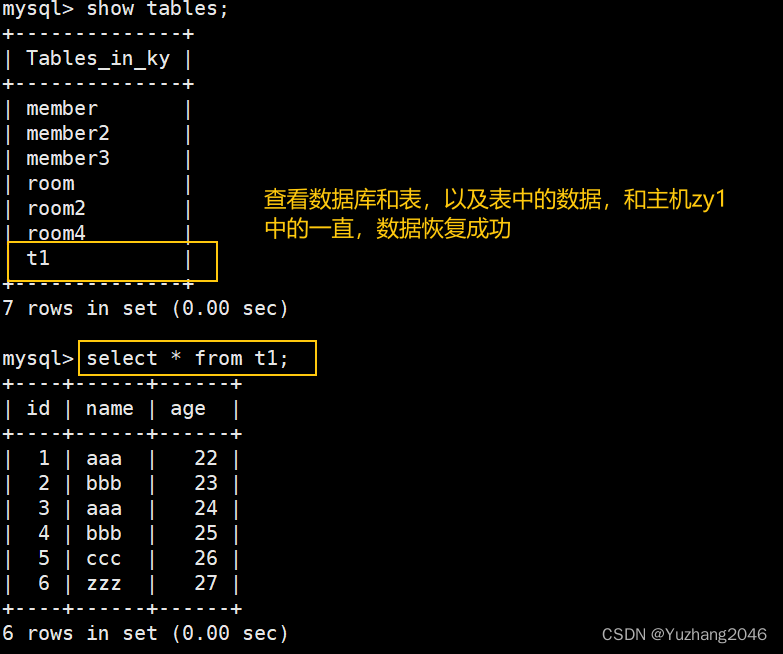
show tables;
select * from t1;
5.2 逻辑备份(使用mysqldump工具)
mysqldump是常用的逻辑备份工具。
mysqldump可以将指定的库、表导出为SQL脚本。
5.2.1 mysqldump完全备份
1)完全备份一个或多个完整的库(包括库中所有的表)
mysqldump -uroot -p[密码] --databases 库名1 [库名2].. >/备份路径/备份文件名.sql#导出的就是数据库脚本文件
示例:
mysqldump -uroot -pabc123 --databases ky > /opt/ky_bak/ky.sql #完全备份一个库yuji
mysqldump -uroot -pabc123 --databases ky market > /opt/ky_bak/ky-market.sql #完全备份多个库,ky库和market库

2) 完全备份MySQL服务器中所有的库(包括库中所有的表)
mysqldump -u root -p[密码] --all-databases > / 备份路径/备份文件名.sql
示例:
mysqldump -u root -p --all-databases > /opt/ky_bak/all.sql #完全备份所有的库

3)完全备份指定库中的部分表
注意:只备份表,sql语句中只有对表的操作,没有对库的操作。恢复时需要人为确认库存在。
mysqldump -u root -p[密码] [-d] 库名 表名1 [表名2] ... > /备份路径/备份文件名.sql
#使用“-d"选项,说明只保存数据库的表结构
#不使用“-d”选项,说明表数据也进行备份
mysqldump -uroot -pabc123 ky t1 member > /opt/ky_bak/t1_member.sql
#完全备份ky库中的t1表和member表
4)查看备份文件
备份文件中保存的是sql语句。即以sql语句的形式,把库、表结构、表数据保存下来。
cd /opt/ky_bak
cat ky.sql | grep -v "^--" |grep -v "^/" |grep -v "^$"
5.2.2 mysqldump完全恢复
先启动mysql:systemctl start mysqld
1)恢复数据库
先删除数据库,之后进行恢复。
##删除数据库yuji##
mysql -u root -p -e 'drop database ky;'
#"-e"选项,用于指定连接MySQL后执行的命令,命令执行完后自动退出
mysql -u root -p -e 'SHOW DATABASES;' #查看当前有哪些数据库
##恢复数据库yuji##
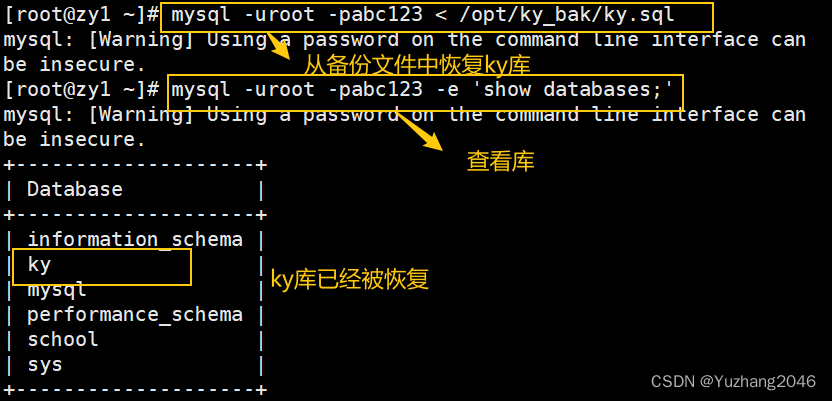
mysql -u root -p < /opt/ky_bak/ky.sql #重定向输入库文件
mysql -u root -p -e 'SHOW DATABASES;' #查看当前有哪些数据库

2)恢复数据表
当备份文件中只包含表的备份,而不包含创建的库的语句时,执行导入操作时必须指定库名,且目标库必须存在。
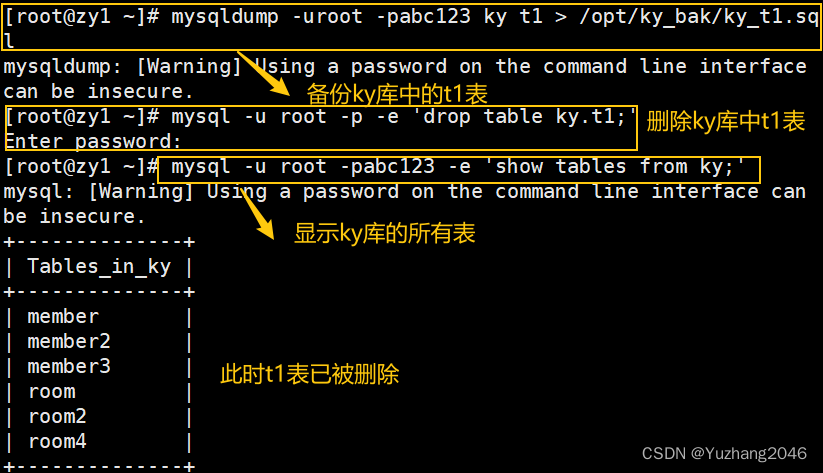
##备份ky库中的class表##
mysqldump -uroot -p ky t1 > /opt/ky_bak/ky_t1.sql
##删除ky库中的t1表##
mysql -u root -p -e 'drop table ky.t1;'
mysql -u root -p -e 'show tables from ky;' #查看ky库中的表,已无t1表
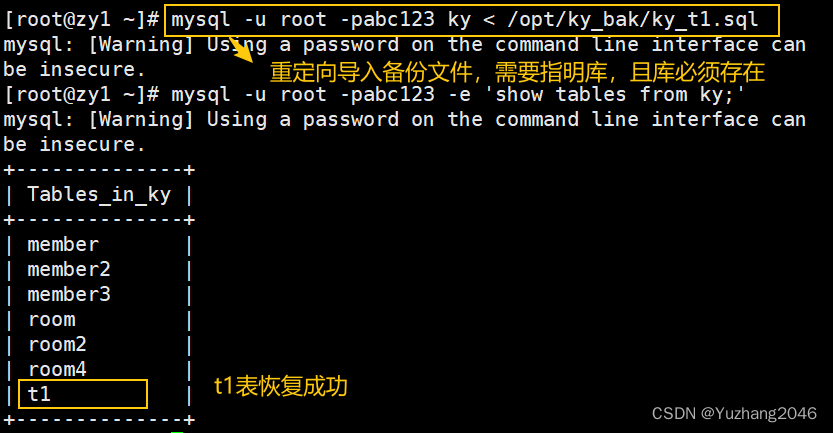
##恢复ky库中的t1表##
mysql -u root -p ky < /opt/ky_bak/ky_t1.sql #重定向导入备份文件,必须指定库名,且目标库必须存在
mysql -u root -p -e 'show tables from ky;'
六、MySQL增量备份与恢复
6.1 MySQL增量备份介绍
使用mysqldump进行完全备份存在的问题
- 备份数据中有重复数据
- 备份时间与恢复时间过长
增量备份是什么:
- 是自上一次备份后增加/变化的文件或者内容
增量备份的特点
- 没有重复数据,备份量不大,时间短
- 恢复需要上次完全备份及完全备份之后所有的增量备份才 能恢复,而且要对所有增量备份进行逐个反推恢复
6.2 MySQL增量备份的方法
-
MySQL没有提供直接的增量备份方法
-
可通过MySQL提供的二进制日志间接实现增量备份
-
MySQL二进制日志对备份的意义
- 二进制日志保存了所有更新或者可能更新数据库的操作
- 二进制日志在启动MySQL服务器后开始记录,并在文件达到 max_binlog_size所设置的大小或者接收到flush logs命令后重新 创建新的日志文件
- 只需定时执行flush logs方法重新创建新的日志,生成二进制文 件序列,并及时把这些日志保存到安全的地方就完成了一个时间 段的增量备份
6.3 MySQL数据库增量恢复
-
一般恢复
- 将所有备份的二进制日志内容全部恢复
-
基于位置恢复
- 数据库在某一时间点可能既有错误的操作也有正确的操作
- 可以基于精准的位置跳过错误的操作
-
基于时间点恢复
- 跳过某个发生错误的时间点实现数据恢复
七、增量备份与恢复 操作演示
7.1 增量备份
1、开启二进制日志功能
vim /etc/my.cnf
[mysqld]
log-bin=mysql-bin #开启二进制日志。如果使用相对路径,则保存在/usr/local/mysql/data/目录下
binlog_format = MIXED #可选,指定二进制日志(binlog)的记录格式为MIXED混合模式
server-id = 1
systemctl restart mysqld
ls /usr/local/mysql//data #查看是否生成二进制日志文件
-------------- 以下是注释 -----------------
#二进制日志(binlog)有3种不同的记录格式:
STATEMENT (基于SQL语句)、ROW(基于行)、MIXED(混合模式),默认格式是STATEMENT
STATEMENT (基于SQL语句):记录修改的sql语句。高并发的情况下,记录操作的sql语句时可能顺序会有错误,导致恢复数据时,数据丢失或有误差。效率高,但数据可能有误差。
ROW(基于行):记录每一行数据,准确,但恢复时效率低。
MIXED(混合模式):正常情况下使用STATEMENT,高并发的情况下会智能地切换到ROW。

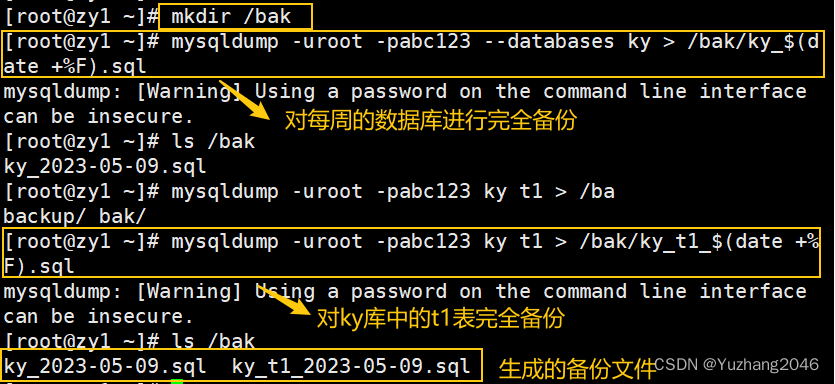
2、可每周对数据库或表进行完全备份
mkdir bak
mysqldump -u root -p ky t1 > /bak/ky_t1_$(date +%F).sql
mysqldump -u root -p --databases ky > /bak/ky_$(date +%F).sql
3、可每天进行增量备份操作,生成新的二进制日志文件(例如mysql-bin.000002)
mysqladmin -u root -p flush-logs
4、插入新数据,以模拟数据的增加或变更
use ky;
insert into t1 values(7,'fff',20);
insert into t1 values(8,'ggg',20);
5、再次生成新的二进制日志文件(例如mysql -bin.000003)
mysqladmin -u root -p flush-logs
#之前的步骤4的数据库操作会保存到mysql-bin.000002文件中,之后数据库数据再发生变化则保存在mysql-bin.00003文件中
6、查看二进制日志文件的内容
cp /usr/local/mysql/data/mysql-bin.000002 /bak/
mysqlbinlog --no-defaults --base64-output=decode-rows -v /bak/mysql-bin.000002
#--base64-output=decode-rows:使用64位编码机制去解码并按行读取
#-v:显示详细内容
7.2 增量恢复
-
一般恢复
- 将所有备份的二进制日志内容全部恢复
-
基于位置恢复
- 数据库在某一时间点可能既有错误的操作也有正确的操作
- 可以基于精准的位置跳过错误的操作
-
基于时间点恢复
- 跳过某个发生错误的时间点实现数据恢复
7.2.1 一般恢复
将所有备份的二进制日志内容全部恢复。
1、模拟丢失更改的数据的恢复步骤。
use ky;
delete from t1 where id=3; #删除今天新增加的两条数据
delete from t1 where id=4;
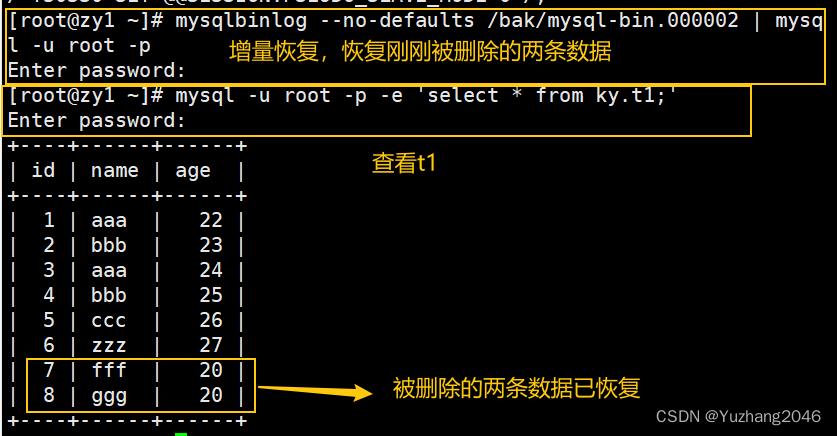
#增量恢复(今天新增加的两条数据记录保存在mysql-bin.000002日志中)
mysqlbinlog --no-defaults /bak/mysql-bin.000002 | mysql -u root -p
mysql -u root -p -e 'select * from ky.t1;' #查看表中数据

2、模拟丢失表中所有数据的恢复步骤。
mysql -u root -p -e 'drop table ky.t1;' #删除整个t1表
mysql -u root -p -e 'show tables from ky;' #查看ky库中的表
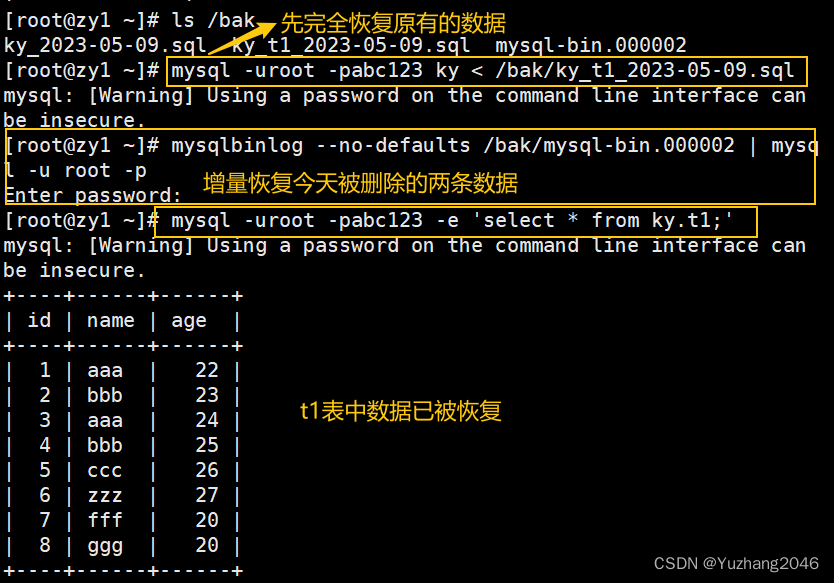
#先完全恢复历史数据
mysql -uroot -pabc123 ky < /bak/ky_t1_2023-05-09.sql
#再进行增量恢复今天新增的2条数据(mysql-bin.000002日志中保存了今天新增加的两条数据记录)
mysqlbinlog --no-defaults /bak/mysql-bin.000002 | mysql -u root -p
mysql -uroot -pabc123 -e 'select * from ky.t1;' #查看表中数据

7.2.2 断点恢复
向class表中插入4条数据,之后刷新二进制日志,移动前一个日志:
use ky;
insert into t1 values(9,'qqq',21);
insert into t1 values(10,'www',22);
mysqladmin -uroot -pabc123 flush-logs; #刷新日志,生成新的二进制日志
cp /usr/local/mysql/data/mysql-bin.000003 /bak/ #将前一个日志复制到/bak/目录下
mysqlbinlog --no-defaults --base64-output=decode-rows -v /bak/mysql-bin.000003 > /bak/binlog.txt #将二进制文件内容重定向到binlog.txt文件中


1)基于位置的断点恢复
mysqlbinlog --no-defaults --start-position='位置点' 文件名 | mysql -uroot -pabc123
#从某一个位置点开始恢复,一直到日志结尾
mysqlbinlog --no-defaults --stop-position='位置点' 文件名 | mysql -uroot -pabc123
#从日志开头,一直恢复到某一个位置点前结束
mysqlbinlog --no-defaults --start-position='xxx'--stop-position='位置点' 文件名 | mysql -u root -pabc123
#从某一个位置点开始恢复,一直到某一个位置点前结束
use ky;
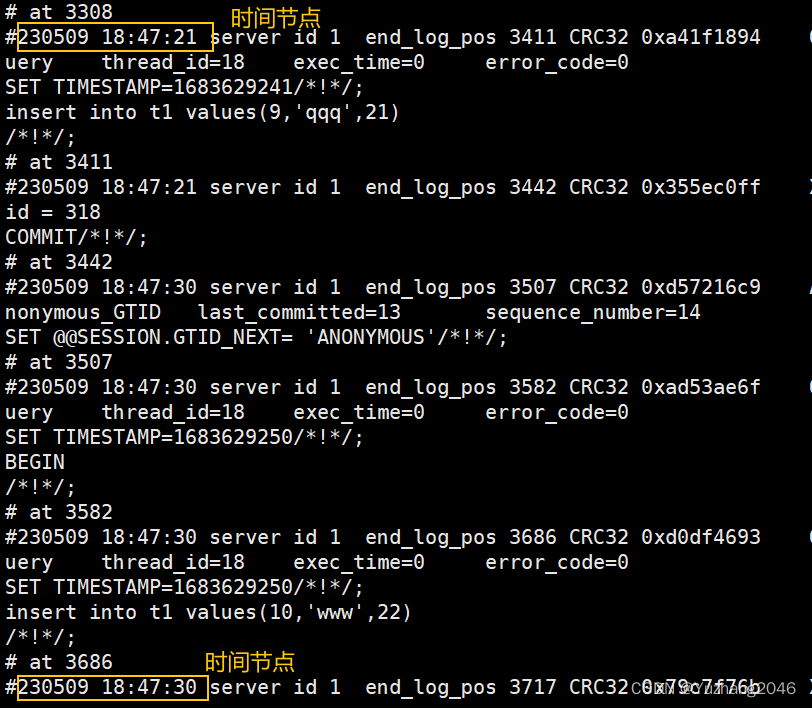
delete from t1 where id between 9 and 10; #删除id为9到10的数据记录
cat /bak/binlog.txt #查看二进制文件内容,找到id=9的位置点
#从id=9的位置点3308一直恢复到结尾
mysqlbinlog --no-defaults --start-position='3308' /bak/mysql-bin.000003 | mysql -uroot -pabc123
mysql -uroot -pabc123 -e 'select * from ky.t1;' #查看表数据



#从头开始恢复,在"id=9"的SQL语句后面截止
mysqlbinlog --no-defaults --stop-position='3308' /bak/mysql-bin.000003 | mysql -uroot -pabc123
#恢复某一段数据
mysqlbinlog --no-defaults --start-position='位置节点号' --stop-position='位置节点号' /bak/mysql-bin.000003 | mysql -uroot -pabc123同样基于时间点的断点恢复,注意:日期必须是"yyyy-mm-dd hh:mm:ss"的格式
mysqlbinlog --no-defaults --start-datetime='yyyy-mm-dd hh:mm:ss' 文件名 | mysql -uroot -pabc123
#从某一个时间点开始恢复,一直到日志结尾
mysqlbinlog --no-defaults --stop-datetime='yyyy-mm-dd hh:mm:ss' 文件名 | mysql -uroot -pabc123
#从日志开头,一直恢复到某一个时间点前结束
mysqlbinlog --no-defaults --start-datetime='yyyy-mm-dd hh:mm:ss' --stop-datetime'yyyy-mm-dd hh:mm:ss' 文件名 | mysql -uroot -pabc123
#从某一个时间点开始恢复,一直到某一个位置点前结束
八、使用脚本备份
-
使用脚本每周三进行一次完全备份,之后每天进行增量备份。
- 如果数据量很大,可以一周做2次完全备份,比如星期一和星期四各一次。
-
增量备份减少磁盘空间的占用,但恢复起来比较麻烦。需要一个一个恢复。
-
一般使用crontab在凌晨进行备份。
获取最新的二进制文件名称
查看索引文件,可获取最新的二进制文件
tail -1 /usr/local/mysql/data/mysql-bin.index
或者
sed -n '$p' /usr/local/mysql/data/mysql-bin.index完全备份脚本(每周三完全备份一次)
vim /opt/mysqlquan.sh #编写脚本
#!/bin/bash
mysqldump -uroot -pabc123 --all-databases > /bak/all_$(date +%F).sql
chmod 700 /opt/mysqlquan.sh
crontab -e #定时任务执行脚本
00 1 * * 3 /opt/mysqlquan.sh #每周三凌晨1点备份一次
增量备份脚本(每天凌晨3点备份一次)
vim /opt/binlog.sh
#!/bin/bash
#使用sed命令打印二进制日志文件最后一行内容作为filename变量的值
filename=$(sed -n '$p' /usr/local/mysql/data/mysql-bin.index | awk -F '/' '{print $2}')
#将二进制日志移动到备份目录下,并将移动后的文件名称加上日期
mv /usr/local/mysql/data/$filename /bak/binlog_$(date +%F)
#生成新的二进制日志文件
mysqladmin -uroot -pabc123 flush-logs
chmod 700 /opt/binlog.sh
crontab -e
00 1 * * 3 /opt/mysqlquan.sh #完全备份,每周三凌晨1点备份一次
00 3 * * * /opt/binlog.sh #增量备份,每天凌晨3点备份一次