Java爬取壁纸图片
- 前言
- 依赖
- 爬取图片
- 工具类 -- WallHavenDownloadToDir.java
- 测试
前言
自己写了一个项目 想加一个功能:自动爬取壁纸发送给用户。说干就干,Python能干的,Java也能干!
参考文章:
jsoup的使用
Java爬虫爬取wallhaven的图片
依赖
这里使用Java爬取的话就要先引入一个依赖:jsoup,其中具体的方法可以看看上面我参考的文章,可以简单理解为一个用来处理HTML页面,并找出其中的元素的工具。
引入依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.15.1</version>
</dependency>
爬取图片
在这里我就爬取WallHaven上的图片了,当然要爬取其他的具体网站的图片就需要对需要爬取的界面做具体分析了。 遇到问题的话,就是访问太频繁的话,会被拒绝连接,建议爬取的时候每次爬取一张以后暂停几秒钟再去爬取。
工具类 – WallHavenDownloadToDir.java
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.URL;
import java.net.URLEncoder;
import java.util.Random;
import java.util.regex.Pattern;
/**
* @Description 爬取图片的工具类
* @Author 三文鱼先生
* @Data 2023/5/6 11:42
*/
public class WallHavenDownloadToDir {
/**
* @Description 下载对应的图片地址到指定的目录下
* @Param filePath 存储的文价目录
* @Param imgUrl 下载的图片url
* @Return {@link boolean} 是否下载成功
* @Author 三文鱼先生
* @Date 2023/5/9 14:58
**/
private static boolean downImages(String filePath, String imgUrl) {
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36";
// 若指定文件夹没有,则先创建
File dir = new File(filePath);
if (!dir.exists()) {
dir.mkdirs();
}
// 截取图片文件名
String fileName = imgUrl.substring(imgUrl.lastIndexOf('/') + 1, imgUrl.length());
try {
// 文件名里面可能有中文或者空格,所以这里要进行处理。但空格又会被URLEncoder转义为加号
String urlTail = URLEncoder.encode(fileName, "UTF-8");
// 因此要将加号转化为UTF-8格式的%20
imgUrl = imgUrl.substring(0, imgUrl.lastIndexOf('/') + 1) + urlTail.replaceAll("\\+", "\\%20");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
// 写出的路径 如果已存在就不再下载
File file = new File(filePath + File.separator + fileName);
if(file.exists()) {
System.out.println("该图片已下载。");
return true;
}
try {
//随机暂停几秒 太过频繁会被识别成爬虫 导致抓取不成功
Thread.sleep(new Random().nextInt(3)*1000);
//连接对应的url
URL url = new URL(imgUrl);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestProperty("User-agent", userAgent);//伪装报头
connection.setConnectTimeout(20 * 1000);
InputStream in = connection.getInputStream();
System.out.println("图片大小为:" + in.available());
BufferedOutputStream out = new BufferedOutputStream(
new FileOutputStream(file)
);
byte[] buf = new byte[1024];
int size;
while (-1 != (size = in.read(buf))) {
out.write(buf, 0, size);
}
out.close();
in.close();
return true;
} catch (IOException e) {
System.out.println("下载图片时遇到未知错误。");
return false;
} catch (InterruptedException e) {
e.printStackTrace();
return false;
}
}
/**
* @Description 根据对应的url 下载其中的所有图片
* @Param filePath 保存的文件路劲
* @Param url WallHaven对应的地址
* @Return {@link boolean} 是否下载成功
* @Author 三文鱼先生
* @Date 2023/5/9 15:02
**/
private static boolean getImage(String filePath, String url) {
//伪装的报头
String userAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36";
try {
// 利用Jsoup获得连接
Connection connect = Jsoup.connect(url)
.userAgent(userAgent);//伪装报头
// 得到Document对象
Document document = connect.get();
// 查找所有img标签
Elements imgs = document.getElementsByTag("a");
String pattern = "https://wallhaven.cc/w/.*";
//每次仅仅获取一个
boolean result = false;
// 遍历img标签并获得src的属性
for (Element element : imgs) {
//获取每个img标签URL "abs:"表示绝对路径
String imgSrc = element.attr("abs:href");
// 打印URL
boolean isMatch = Pattern.matches(pattern, imgSrc);
if (isMatch){
System.out.println("下载链接:"+imgSrc);
Connection con = Jsoup.connect(imgSrc)
.userAgent(userAgent)
.timeout(10*1000);//伪装报头;
Document doc = con.get();
Elements pic = doc.getElementsByTag("img");
System.out.println(pic);
System.out.println("开始下载");
for(Element p : pic)
{
Element picSrc = p.getElementById("wallpaper");
if(picSrc!=null)
{
String picsrc = picSrc.attr("abs:src");
System.out.println("图片链接:"+picsrc);
result = downImages(filePath, picsrc);
if(
result
) {
System.out.println("下载一张");
} else {
//只要有一张下载不成功则重新来 但是已经下载的不会再进行下载
return false;
}
}
}
}
}
return result;
} catch (IOException e) {
System.out.println("获取图片链接时遇到未知错误");
return false;
}
}
/**
* @Description 循环一百次 直到爬取成功
* @Param filePath 图片存储地址
* @Param url WallHaven里面的对应搜索网址
* @Return {@link boolean} 是否成功
* @Author 三文鱼先生
* @Date 2023/5/9 15:04
**/
public static boolean downloadImageWithUrl(String filePath,String url) {
try {
for (int i = 0; i < 100; i++) {
//每个界面随机暂停五秒 防止太过频繁被识别成爬虫
Thread.sleep(new Random().nextInt(5)*1000);
//获取对应url的图片
if(getImage(filePath ,url)) {
//下载成功则不再执行循环
break;
}
}
return true;
} catch (InterruptedException e) {
e.printStackTrace();
}
return false;
}
}
测试
根据自己的喜好去WallHaven里面筛选自己喜欢的类型图片,然后将对应的网址复制下来,作为上述工具类中的downloadImageWithUrl方法中的URL参数
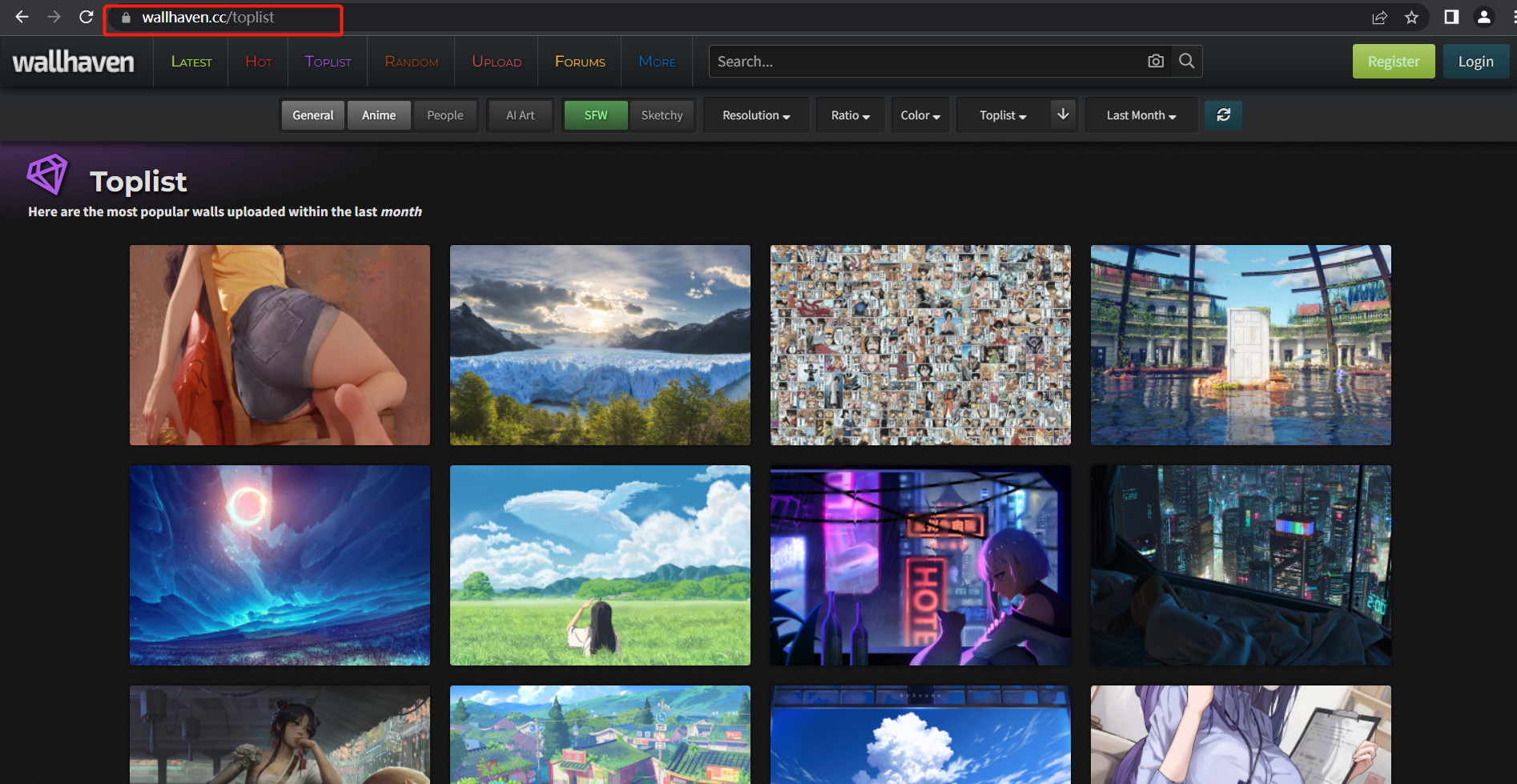
如以下这样
WallHavenDownloadToDir.downloadImageWithUrl(storePath ,
"https://wallhaven.cc/toplist");
等待爬取结束即可。控制台会输出以下爬取信息
下载链接:https://wallhaven.cc/w/ex99o8
<img src="https://wallhaven.cc/images/layout/logo_sm.png" alt="wallhaven">
<img src="//wallhaven.cc/images/user/avatar/32/519198_046b6874f485.png" alt="jrmnt">
<img id="wallpaper" src="https://w.wallhaven.cc/full/ex/wallhaven-ex99o8.png" alt="General 1920x1080 digital art artwork illustration clouds city building skyscraper palm trees sunset sky trees sunset glow" data-wallpaper-id="ex99o8" data-wallpaper-width="1920" data-wallpaper-height="1080" crossorigin="anonymous">
共检测到下列图片URL:
开始下载
图片链接:https://w.wallhaven.cc/full/ex/wallhaven-ex99o8.png
图片大小为:15636
下载一张
再进自己设置的存储目录看下,没什么问题了
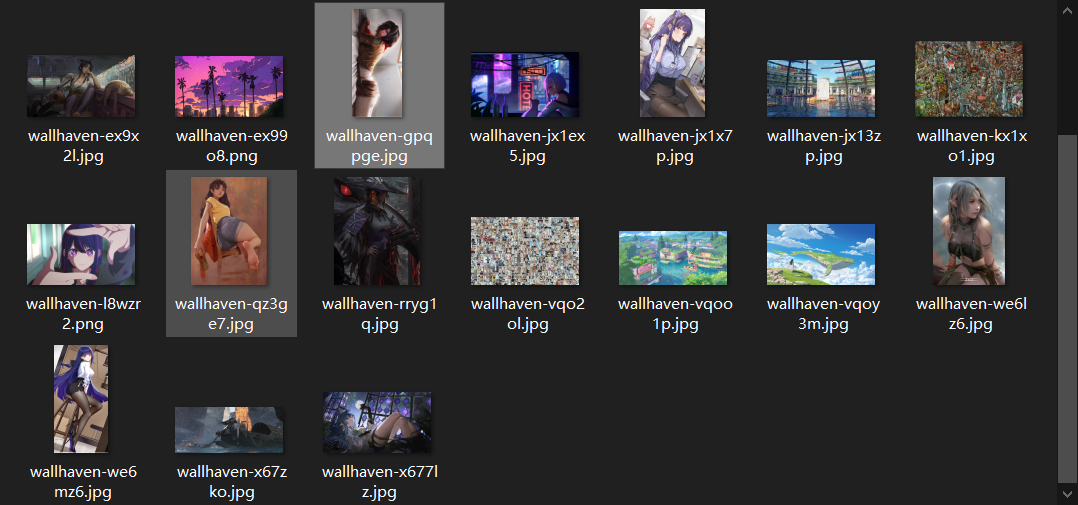
当然有时候会拒绝连接好几次,显示获取图片时出错,等一会就好了,一般是会被拒绝二十来次。但是不要担心,循环里设置的是100次基本都会成功。