递归神经网络
递归神经网络可以解决这个问题。它们是带有循环的神经网络,允许信息保留一段时间。
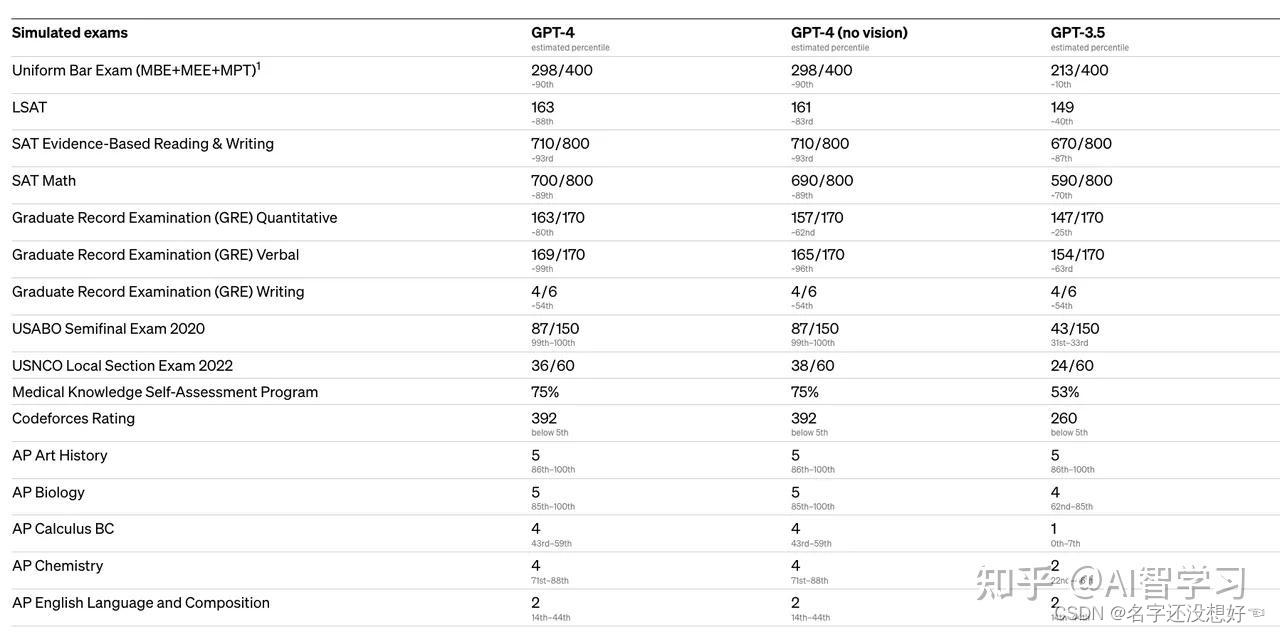
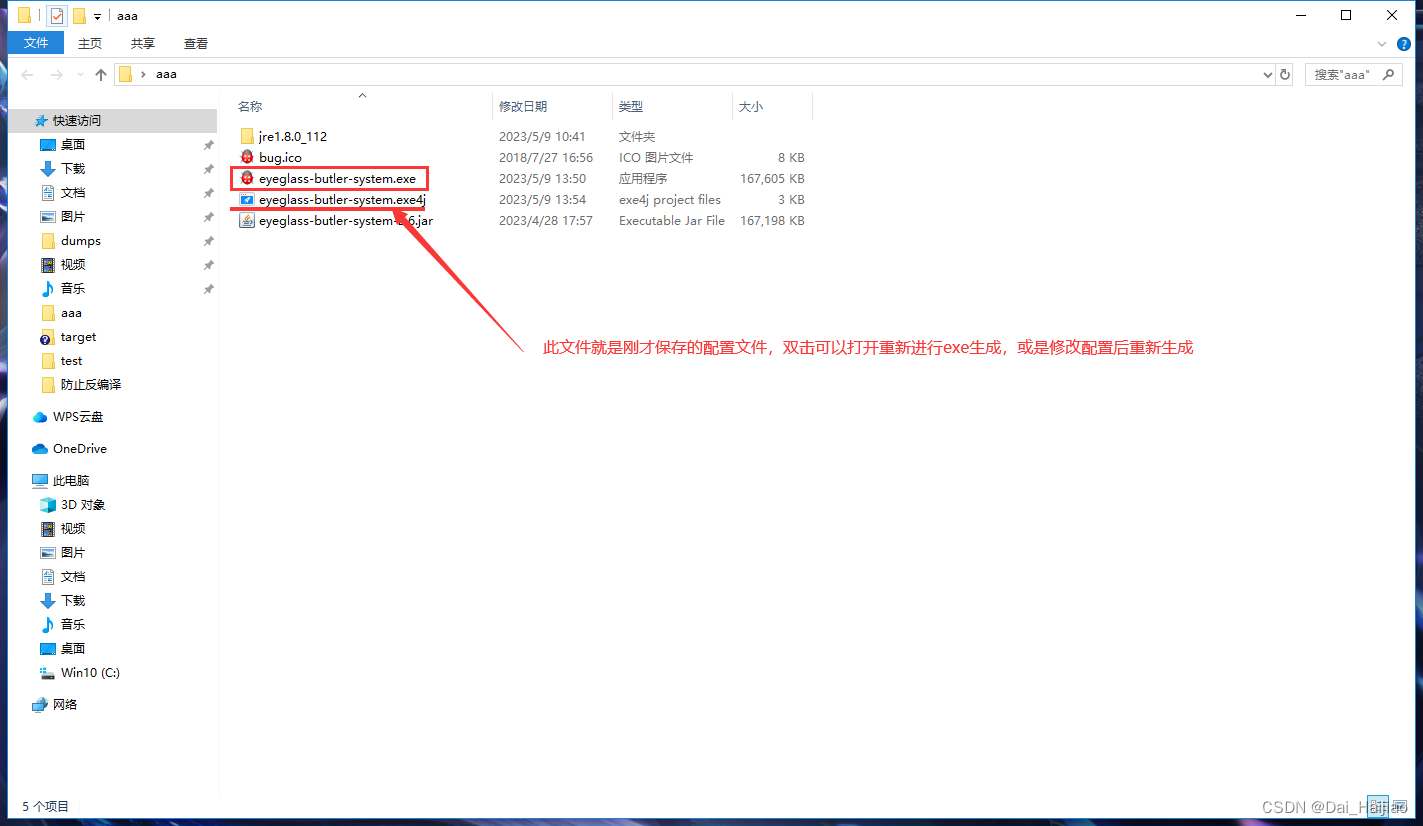
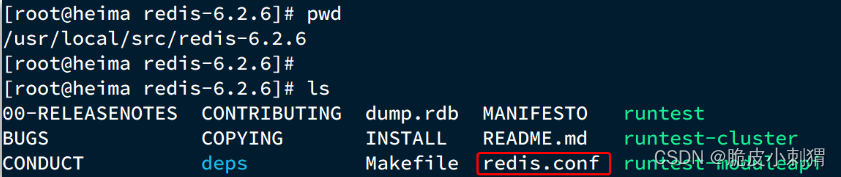
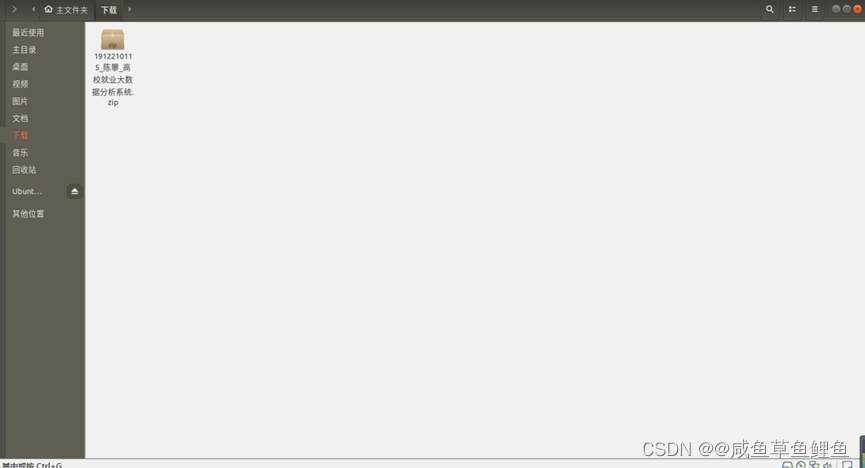
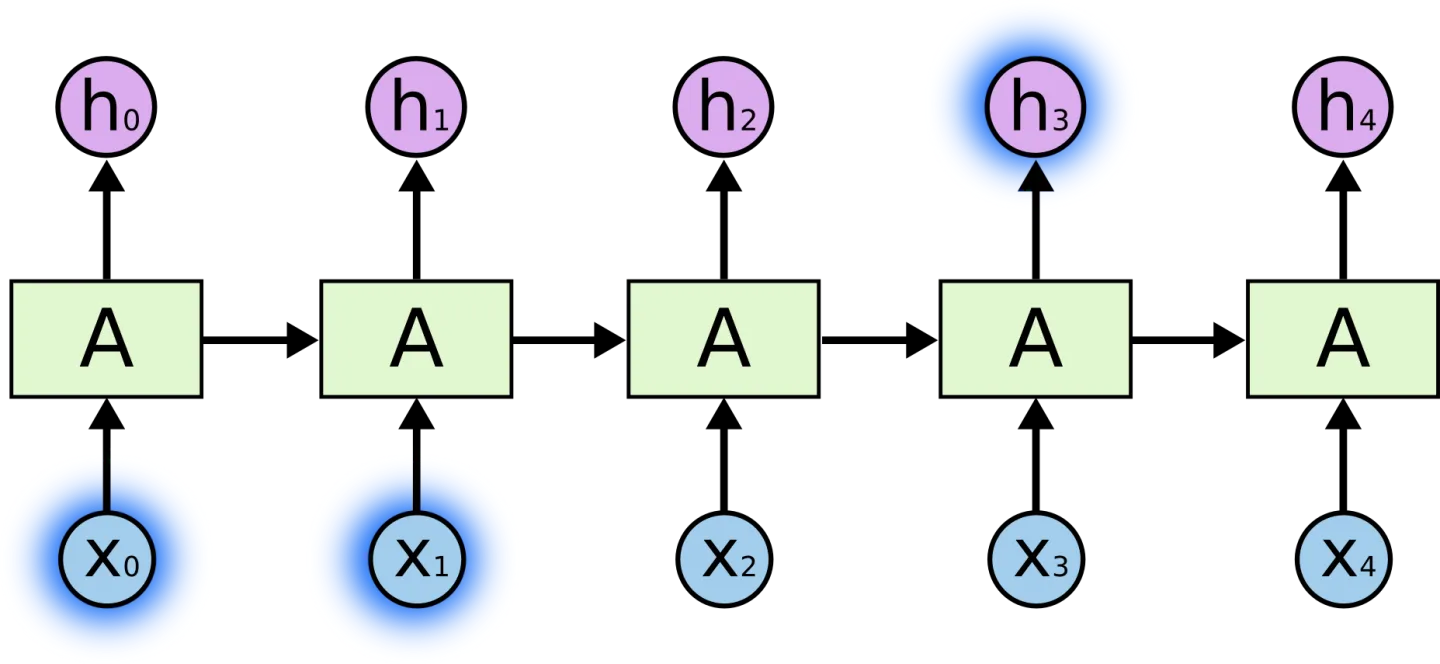
在上图中,A 代表神经网络主体, xt 是网络输入,ht是网络输出,循环结构允许信息从当前输出传递到下一次的网络输入。
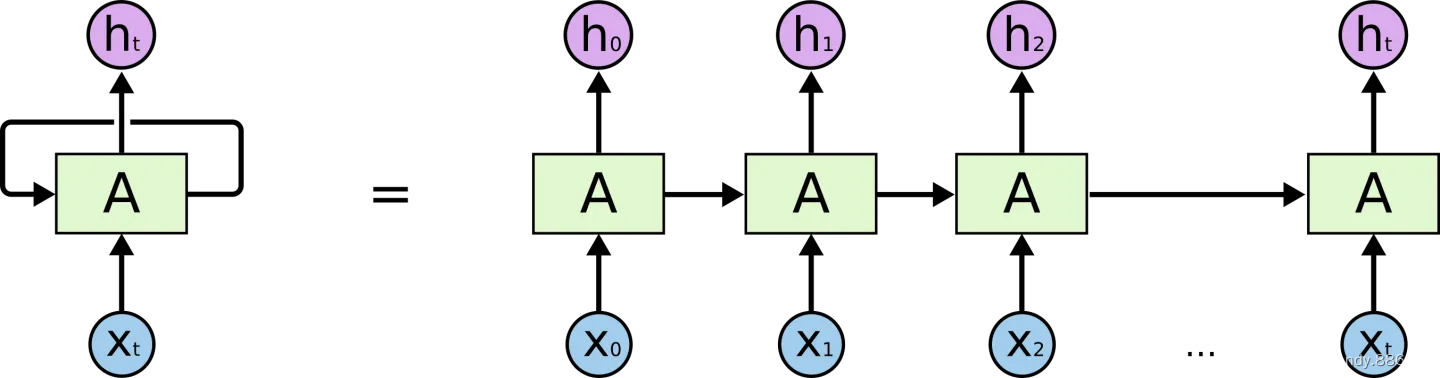 一个递归神经网络可以看多是一个网络的多次拷贝,每次把信息传递给他的继任者。让我们把网络展开,你会看到发生了什么。
一个递归神经网络可以看多是一个网络的多次拷贝,每次把信息传递给他的继任者。让我们把网络展开,你会看到发生了什么。
长期依赖的问题
人们希望RNNs能够连接之前的信息到当前的任务中,例如,使用之前的图像帧信息去辅助理解当前的帧。
有时,我们仅仅需要使用当前的信息去执行当前的任务。例如, 一个语言模型试图根据之前的单词去预测下一个单词。如果我们试图去预测“the clouds are in the sky”,我们不需要更多的上下文信息–很明显下一个单词会是sky。
当我们去尝试预测“I grew up in France…I speak fluent French”的最后一个单词,最近的信息表明下一个单词应该是语言的名字,但是如果我们想缩小语言的范围,看到底是哪种语言,我们需要France这个在句子中比较靠前的上下文信息。相关信息和需要预测的点的间隔很大的情况是经常发生的。
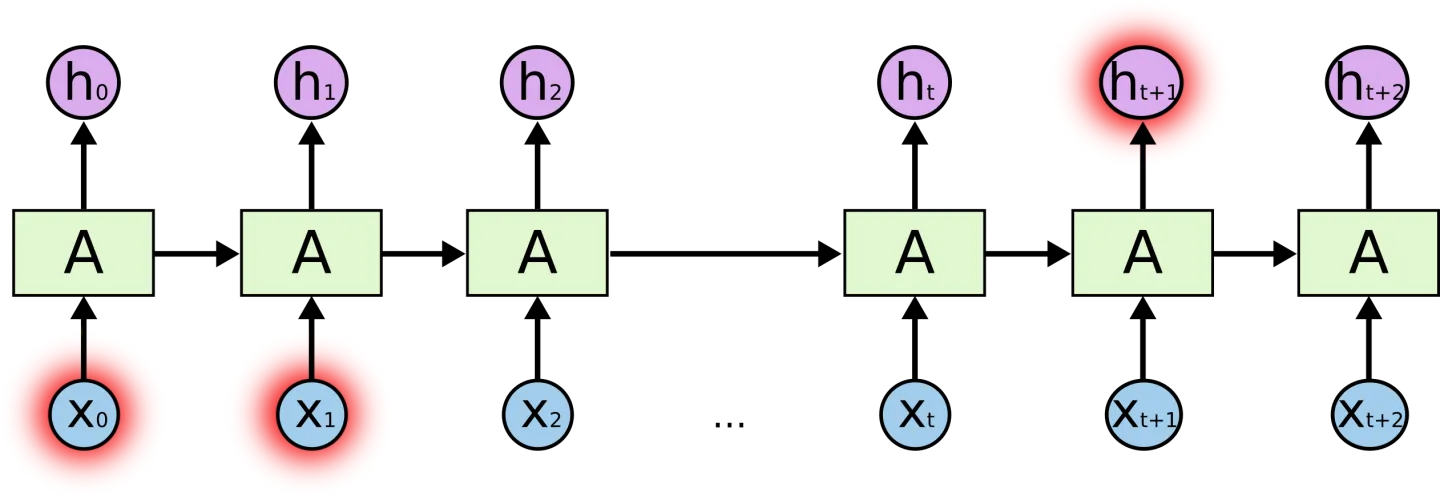 实践表明RNNs不能完美的学习“长期依赖(Long-term dependencies)”,LSTMs没有这些问题。
实践表明RNNs不能完美的学习“长期依赖(Long-term dependencies)”,LSTMs没有这些问题。
LSTM 网络
长短期记忆网络–通畅叫做”LSTMs”–是一种特殊的RNNs, 它能够学习长期依赖。
LSTMs被明确的设计用来解决长期依赖问题,记住长时间段的信息是他们的必备技能。
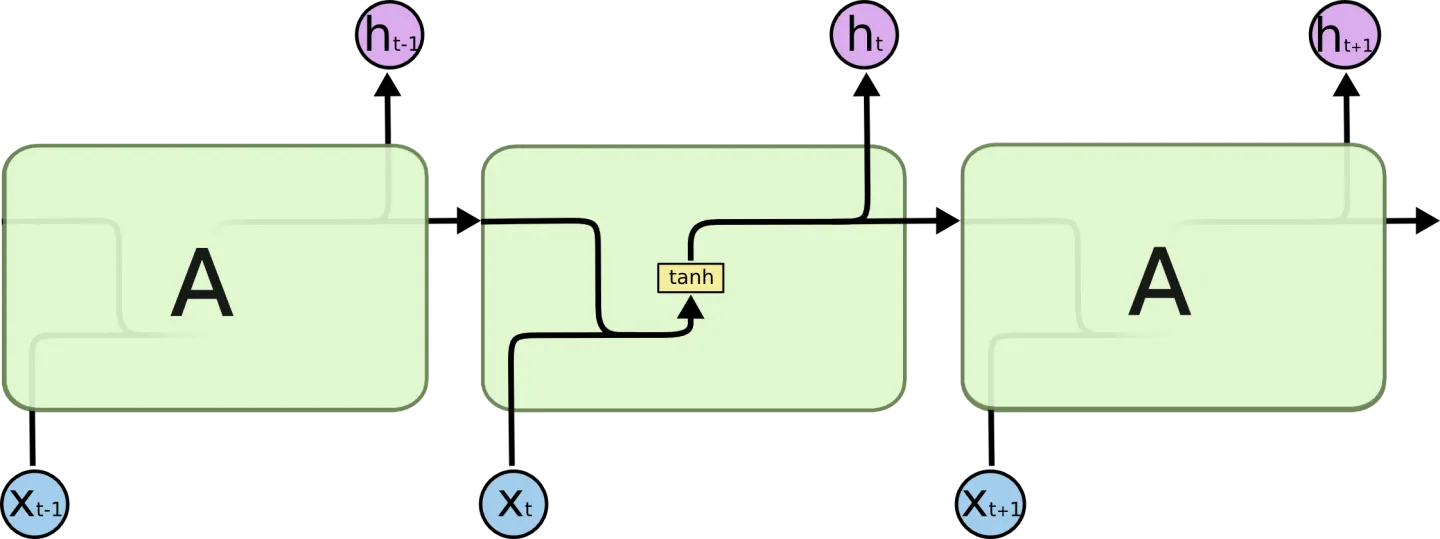
所有的递归神经网络都有重复神经网络本身模型的链式形式。在标准的RNNs, 这个复制模块只有一个非常简单的结构,例如一个双极性(tanh)层。
LSTMs 也有这种链式结构,但是这个重复模块与上面提到的RNNs结构不同:LSTMs并不是只增加一个简单的神经网络层,而是四个,它们以一种特殊的形式交互。
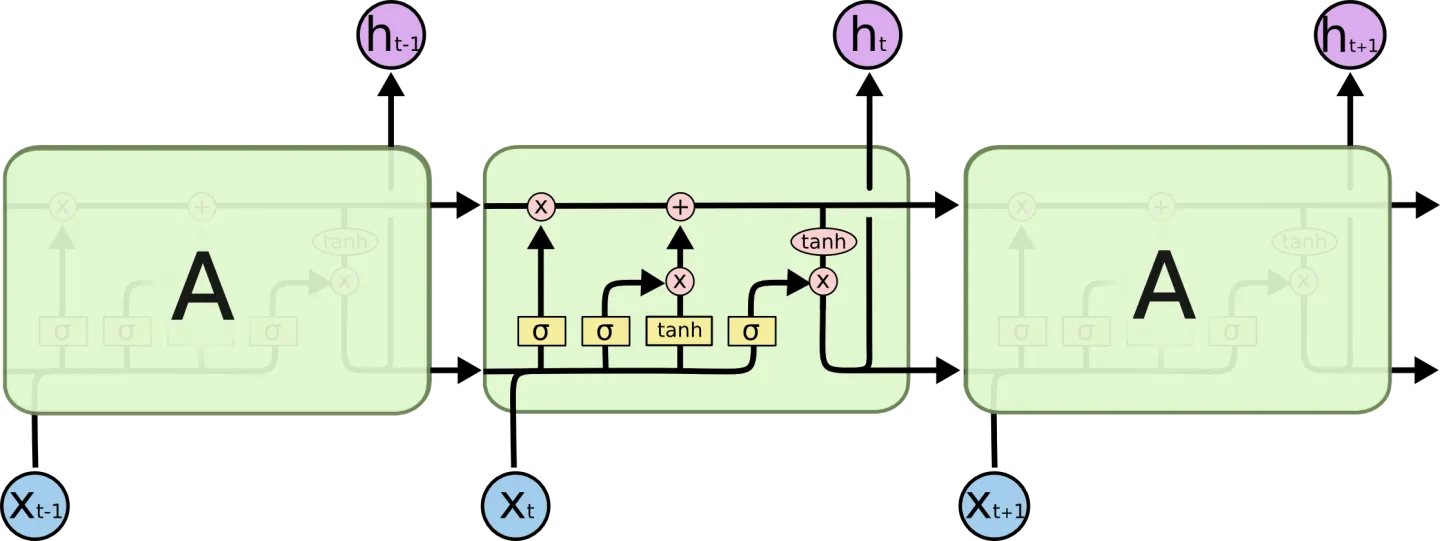
LSTMs背后的核心思想
LSTMs的核心之处就是它的神经元状态,如下图中所示,上面那条贯穿整个结构的水平线。
神经元状态就像是一个传送带。它的线性作用很小,贯穿整个链式结构。信息很容易在传送带上传播,状态却并不会改变。
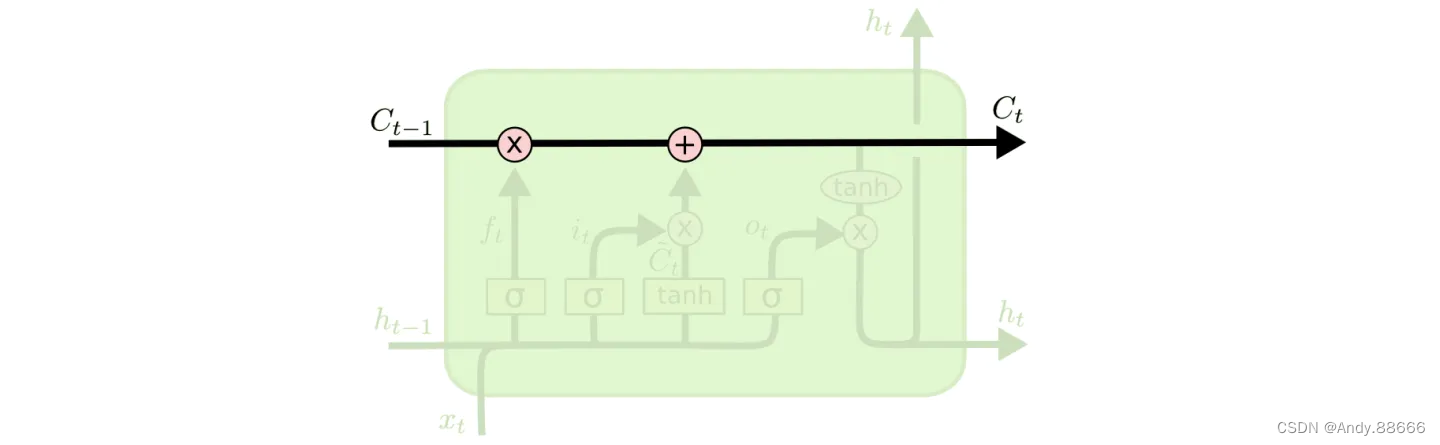 LSTM有能力删除或者增加神经元状态中的信息,这一机制是由被称为门限的结构精心管理的。
LSTM有能力删除或者增加神经元状态中的信息,这一机制是由被称为门限的结构精心管理的。
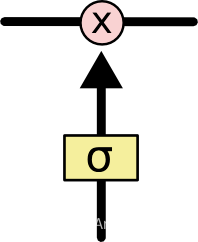
门限是一种让信息选择性通过的方式,它们是由Sigmoid神经网络层和逐点相乘器做成的。
Sigmod层输出0~1之间的数字,描述了一个神经元有多少信息应该被通过。输出“0”意味着“全都不能通过”,输出“1”意味着“让所有都通过”。
一个LSTM有三个这样的门限,去保护和控制神经元状态。
一步一步的推导LSTM
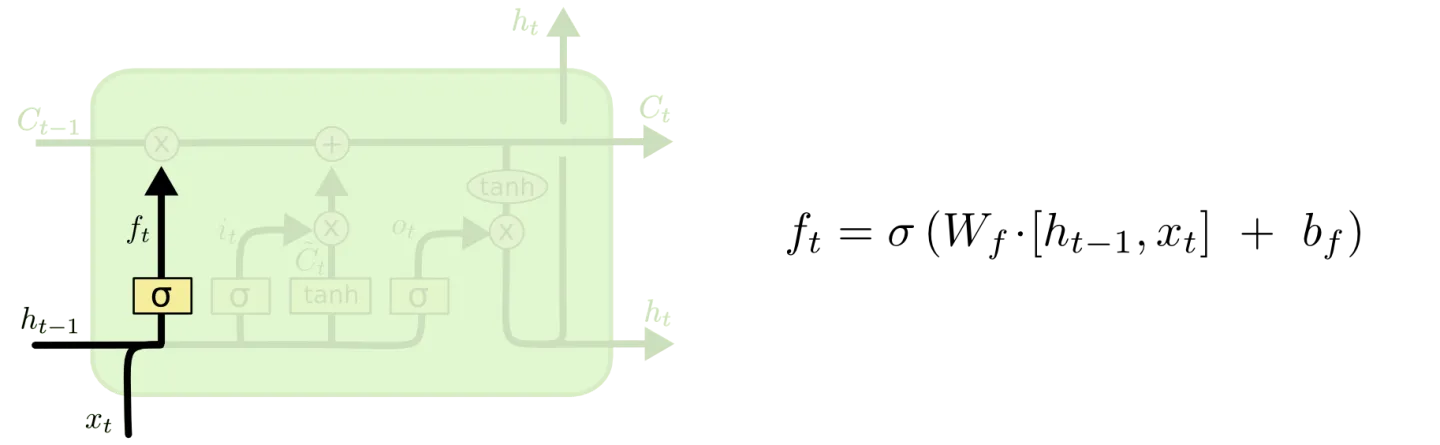
LSTM的第一步就是决定什么信息应该被神经元遗忘。这是一个被称为“遗忘门层”的Sigmod层组成的。它输入 ht−1和xt,然后在Ct−1 的每个神经元状态输出0~1之间的数字。“1”表示“完全保留这个”,“0”表示“完全遗忘这个”。
让我们再次回到那个尝试去根据之前的词语去预测下一个单词的语言模型。在这个问题中,神经元状态或许包括当前主语中的性别信息,所以可以使用正确的代词。当我们看到一个新的主语,我们会去遗忘之前的性别信息。
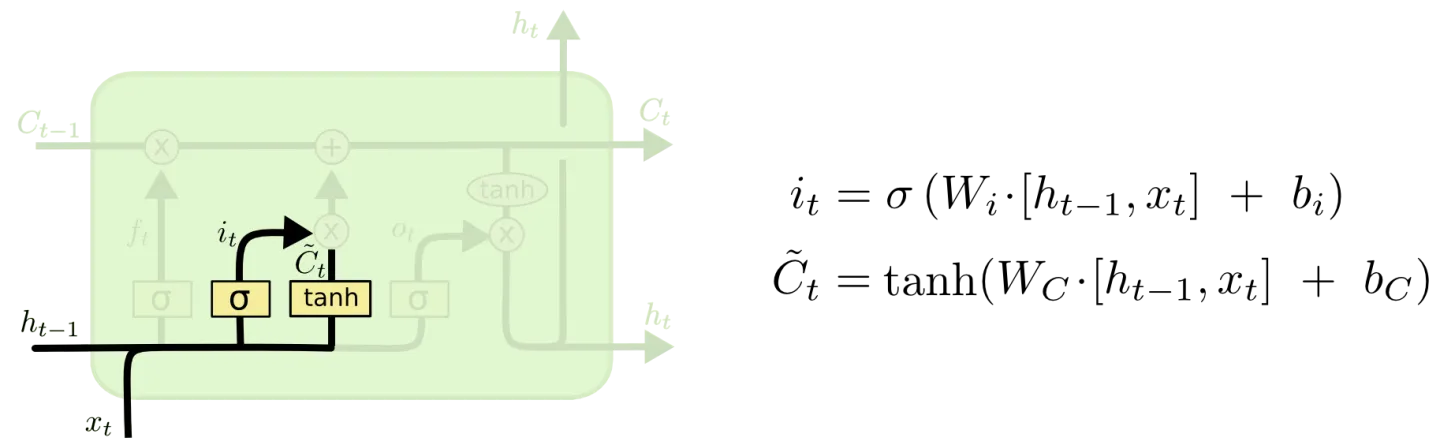
 下一步就是决定我们要在神经元细胞中保存什么信息,这包括两个部分。首先,一个被称为“输入门层”的Sigmod层决定我们要更新的数值。然后,一个tanh层生成一个新的候选数值,Ct˜,它会被增加到神经元状态中。在下一步中中,我们会组合这两步去生成一个更新状态值。
下一步就是决定我们要在神经元细胞中保存什么信息,这包括两个部分。首先,一个被称为“输入门层”的Sigmod层决定我们要更新的数值。然后,一个tanh层生成一个新的候选数值,Ct˜,它会被增加到神经元状态中。在下一步中中,我们会组合这两步去生成一个更新状态值。
在那个语言模型例子中,我们想给神经元状态增加新的主语的性别,替换我们将要遗忘的旧的主语。
我们给旧的状态乘以一个ft,遗忘掉我们之前决定要遗忘的信息,然后我们增加it∗Ct˜。这是新的候选值,是由我们想多大程度上更新每个状态的值来度量的。
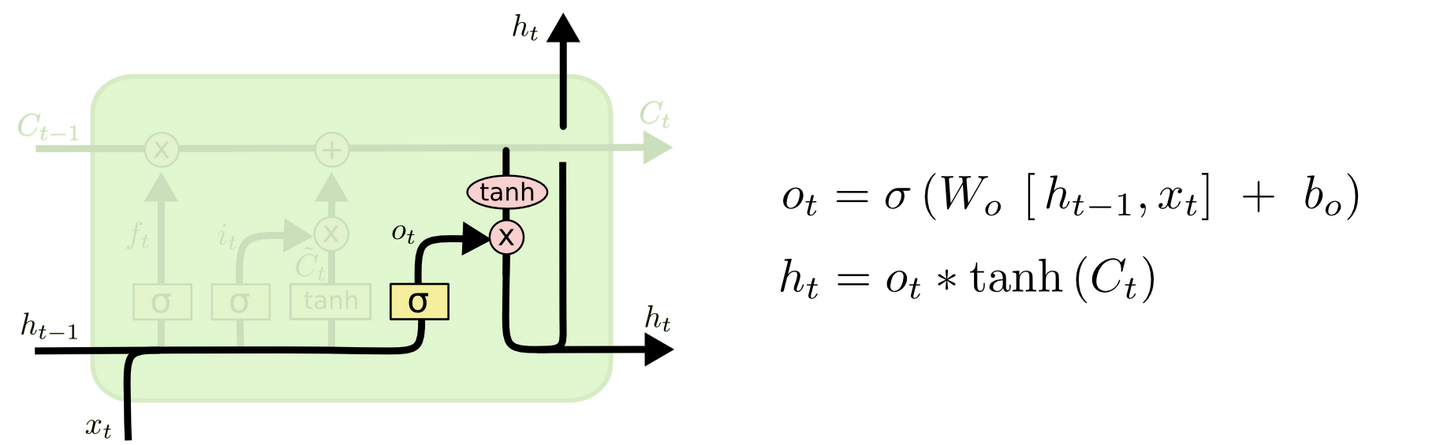
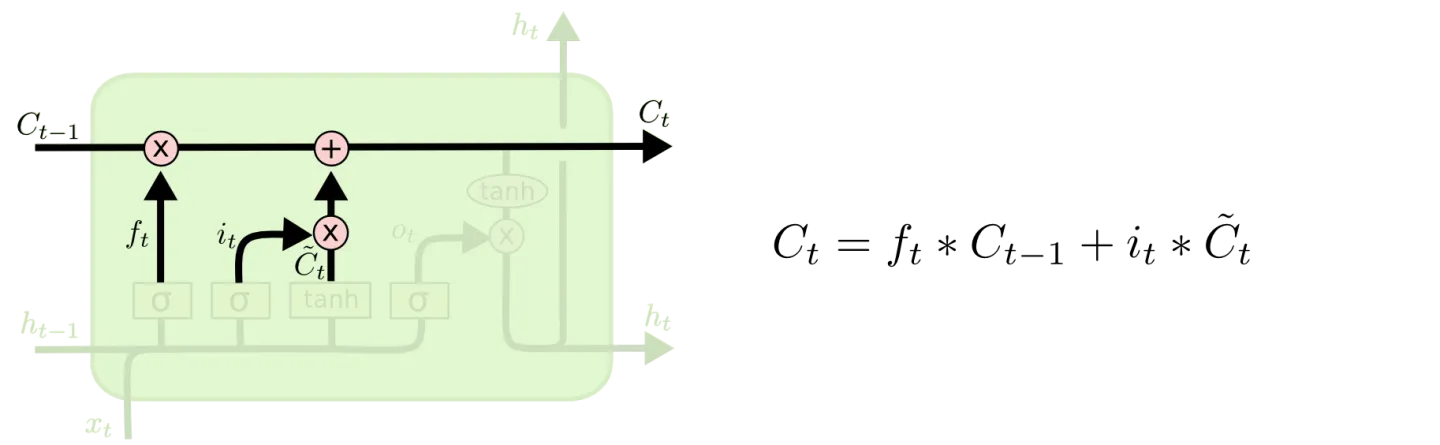 最后,我们要决定要输出什么。这个输出是建立在我们的神经元状态的基础上的,但是有一个滤波器。首先,我们使用Sigmod层决定哪一部分的神经元状态需要被输出;然后我们让神经元状态经过tanh(让输出值变为-1~1之间)层并且乘上Sigmod门限的输出,我们只输出我们想要输出的。
最后,我们要决定要输出什么。这个输出是建立在我们的神经元状态的基础上的,但是有一个滤波器。首先,我们使用Sigmod层决定哪一部分的神经元状态需要被输出;然后我们让神经元状态经过tanh(让输出值变为-1~1之间)层并且乘上Sigmod门限的输出,我们只输出我们想要输出的。
长短期记忆神经网络的变体
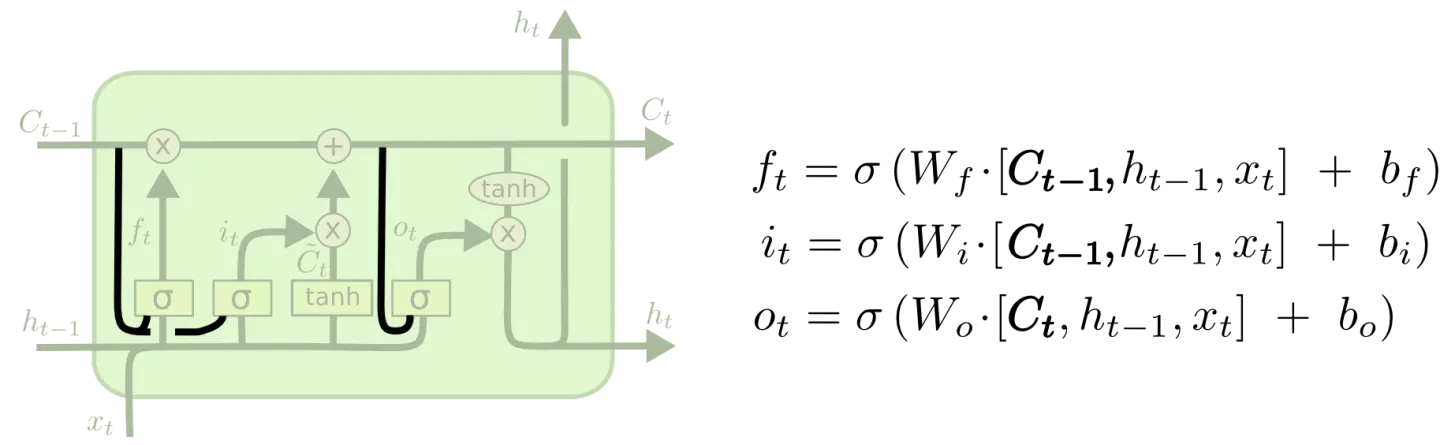 上图中给每个门限增加了窥视孔,但是有些论文,只给一部分门限增加窥视孔,并不是全部都加上。
上图中给每个门限增加了窥视孔,但是有些论文,只给一部分门限增加窥视孔,并不是全部都加上。
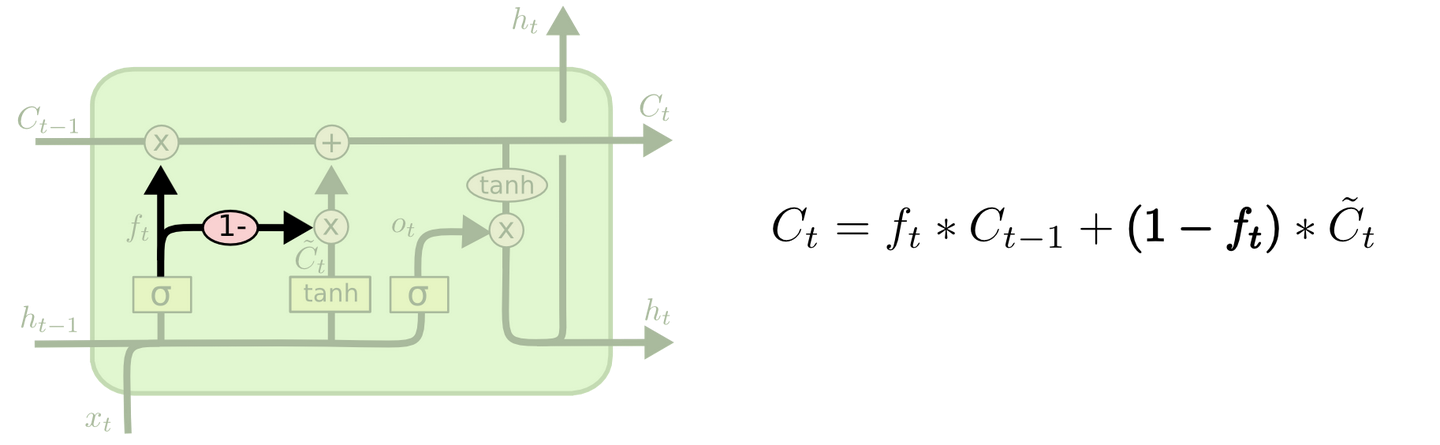 另外一个变体是使用组合遗忘和输入门。而不是分开决定哪些神经元需要遗忘信息,哪些需要增加新的信息,我们组合起来决定。我们只遗忘那些需要被放入新信息的状态,同样,我们只在旧的信息被遗忘之后才输入新的信息。
另外一个变体是使用组合遗忘和输入门。而不是分开决定哪些神经元需要遗忘信息,哪些需要增加新的信息,我们组合起来决定。我们只遗忘那些需要被放入新信息的状态,同样,我们只在旧的信息被遗忘之后才输入新的信息。
 门递归单元。它组合遗忘们和输入门为一个“更新门”,它合并了神经元状态和隐层状态,并且还做了一些其他改变。最终这个模型比标准的LSTM模型简单一些,并且变得越来越流行。
门递归单元。它组合遗忘们和输入门为一个“更新门”,它合并了神经元状态和隐层状态,并且还做了一些其他改变。最终这个模型比标准的LSTM模型简单一些,并且变得越来越流行。