声明:
文章中代码及相关语句为自己根据相应理解编写,文章中出现的相关图片为自己实践中的截图和相关技术对应的图片,若有相关异议,请联系删除。感谢。转载请注明出处,感谢。
By luoyepiaoxue2014
B站:https://space.bilibili.com/1523287361 点击打开链接
微博地址: https://weibo.com/luoyepiaoxue2014 点击打开链接
title: Spark系列
一、Spark SQL前世今生
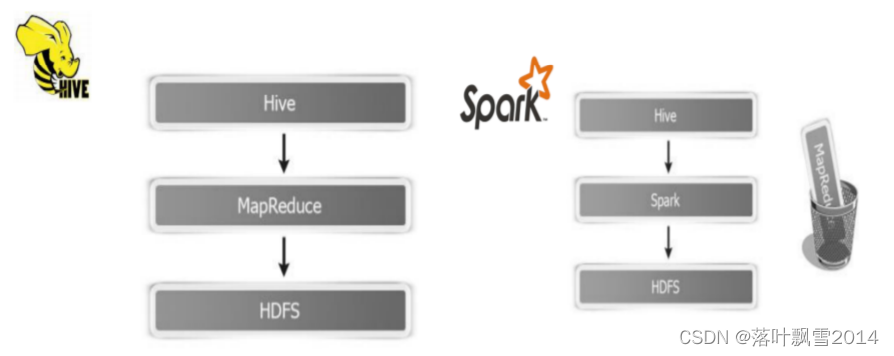
1.1 介绍
1、Hive
Hive 底层基于MapReduce,而MapReduce的shuffle又是基于磁盘的
=> 性能低下。出现复杂的 SQL ETL,要运行数个小时,甚至数十个小时的情况
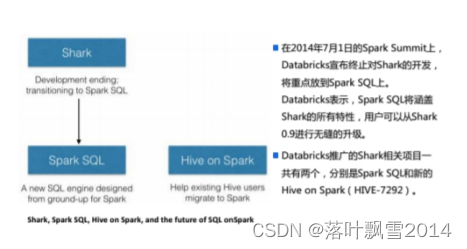
2、Shark
依赖了Hive的语法解析器、查询优化器等组件
修改了内存管理、物理计划、执行三个模块,底层使用Spark的基于内存的计算模型
3、Spark SQL
1、支持多种数据源:Hive、RDD、Parquet、JSON、JDBC等。
2、多种性能优化技术:in-memory columnar storage、byte-code generation、cost model动态评估等。
3、组件扩展性:对于SQL的语法解析器、分析器以及优化器,用户都可以自己重新开发,并且动态扩展
1.2 小总结
Spark 0.x Shark
Spark 1.0.X SparkSQL Spark开始成为顶级项目
Spark 1.3.X 提出来DataFrame的核心抽象
Spark 1.6.X 提出来DataSet的核心抽象,属于测试阶段
Spark 2.X DataSet属于正式阶段
二、Spark SQL程序入口
2.1 SparkSQL程序入口之Spark1.X
以spark1.3.1进行演示
2.1.1 SQLContext
可以去官网可以先 https://spark.apache.org/docs/1.3.1/sql-programming-guide.html
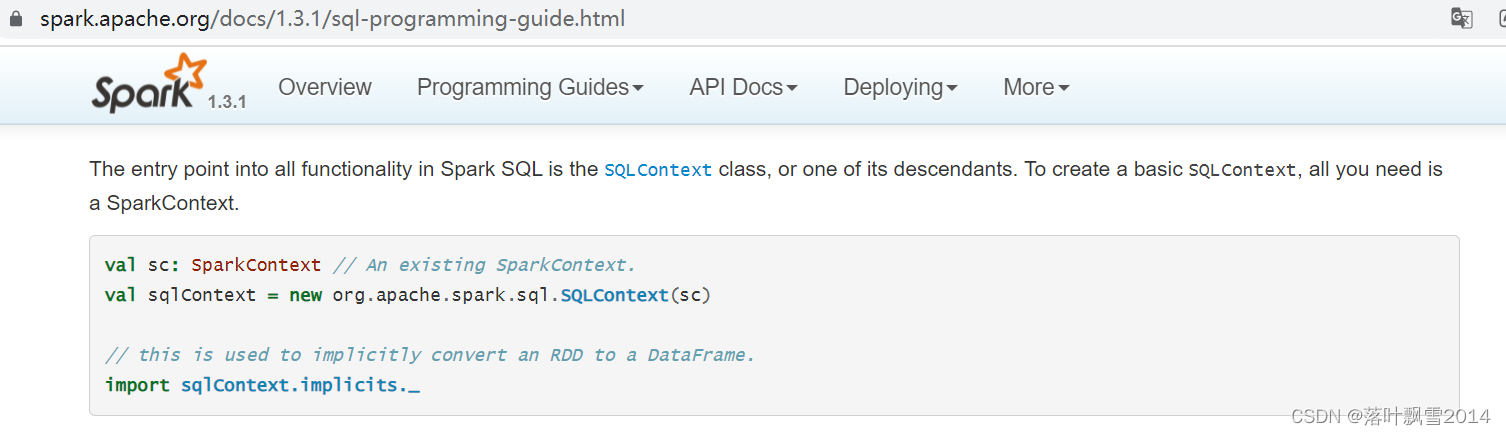
The entry point into all functionality in Spark SQL is the SQLContext class, or one of its descendants. To create a basic SQLContext, all you need is a SparkContext.
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
2.1.2 HiveContext
可以去官网可以先 https://spark.apache.org/docs/1.3.1/sql-programming-guide.html
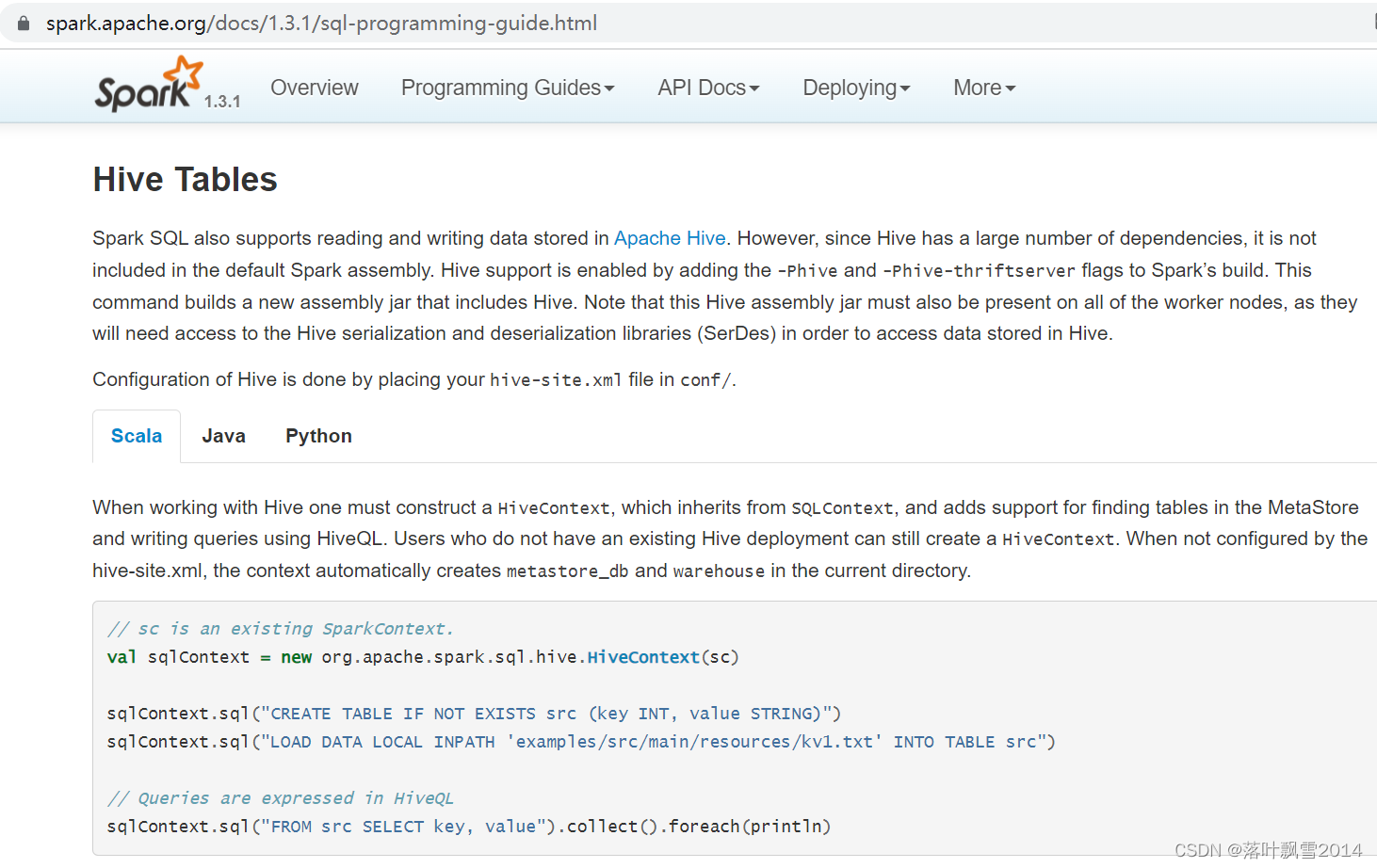
When working with Hive one must construct a HiveContext, which inherits from SQLContext, and adds support for finding tables in the MetaStore and writing queries using HiveQL. Users who do not have an existing Hive deployment can still create a HiveContext. When not configured by the hive-site.xml, the context automatically creates metastore_db and warehouse in the current directory.
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sqlContext.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
// Queries are expressed in HiveQL
sqlContext.sql("FROM src SELECT key, value").collect().foreach(println)
2.2 SparkSQL程序入口之2.X
2.2.1 SparkSession
以2.1.0为示例
https://spark.apache.org/docs/2.1.0/sql-programming-guide.html
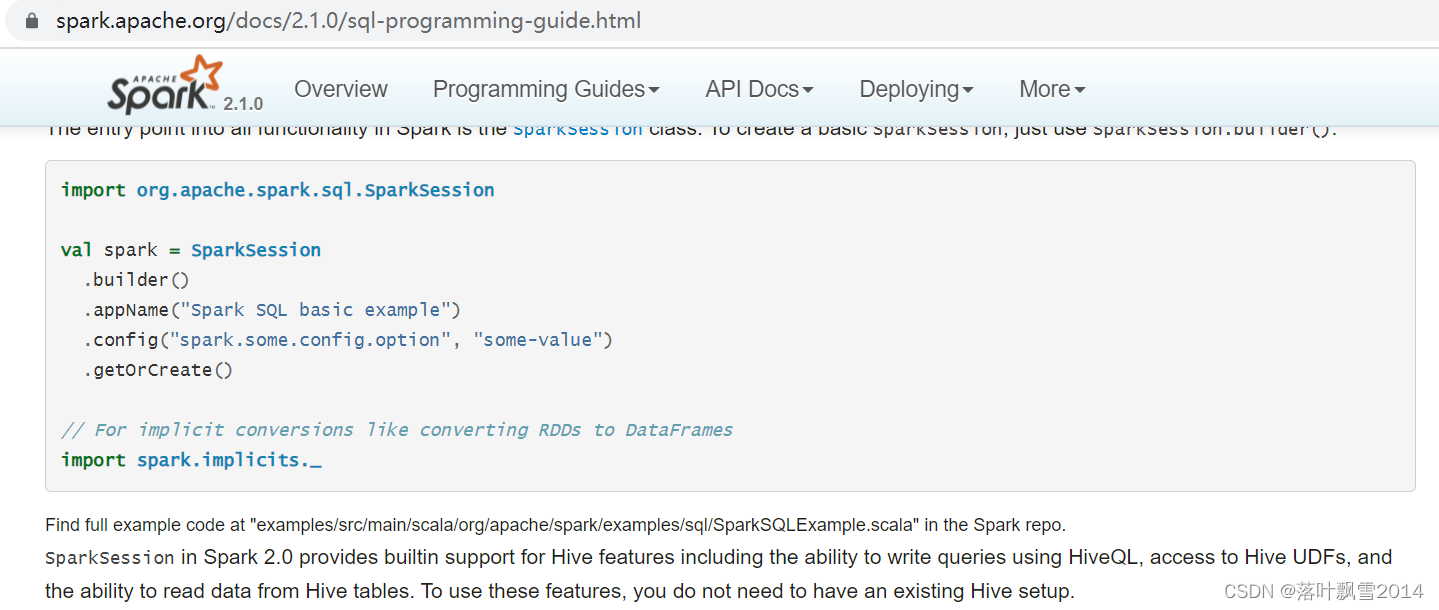
The entry point into all functionality in Spark is the SparkSession class. To create a basic SparkSession, just use SparkSession.builder():
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
SparkSession是Spark-2.0引如的新概念。SparkSession为用户提供了统一的切入点,来让用户学习Spark的各项功能。在Spark的早期版本中,SparkContext是Spark的主要切入点,由于RDD是主要的API,我们通过sparkContext来创建和操作RDD。对于每个其他的API,我们需要使用不同的context。
SparkSession实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了SparkContext,所以计算实际上是由SparkContext完成的。
2.2.2 小总结
1、为用户提供一个统一的切入点使用Spark各项功能
2、允许用户通过它调用DataFrame和Dataset相关API来编写程序
3、减少了用户需要了解的一些概念,可以很容易的与Spark进行交互
4、与Spark交互之时不需要显示的创建SparkConf、SparkContext以及SQlContext,这些对象已经封闭在SparkSession中
5、SparkSession提供对Hive特征的内部支持:用HiveQL写SQL语句,访问Hive UDFs,从Hive表中读取数据。
2.3 SparkSQL程序入口之3.X
2.3.1 SparkSession
以我们课上使用的3.1.2为例
https://spark.apache.org/docs/3.1.2/sql-getting-started.html
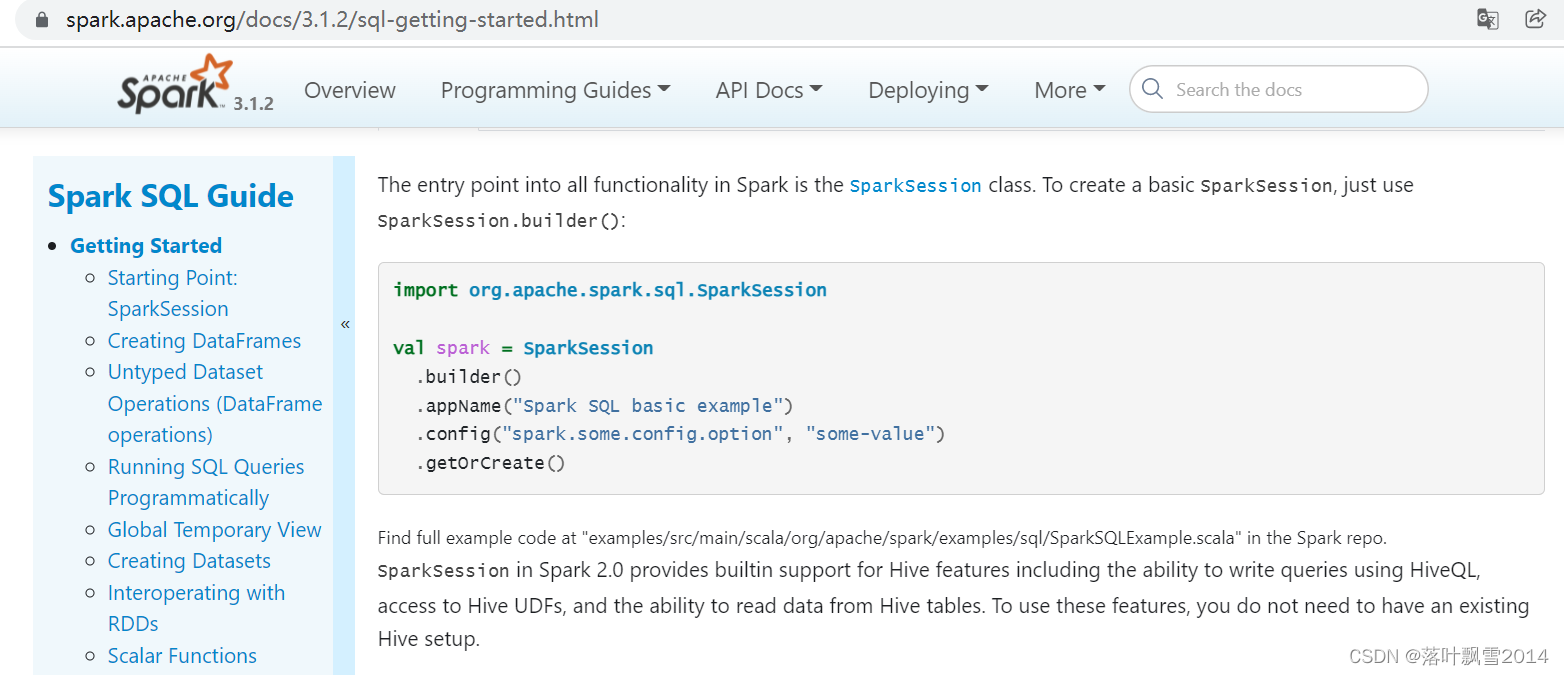
The entry point into all functionality in Spark is the SparkSession class. To create a basic SparkSession, just use SparkSession.builder():
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder()
.appName("Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()
三、Spark SQL核心抽象
3.1 DataFrame核心抽象
官网链接:https://spark.apache.org/docs/3.1.2/sql-programming-guide.html
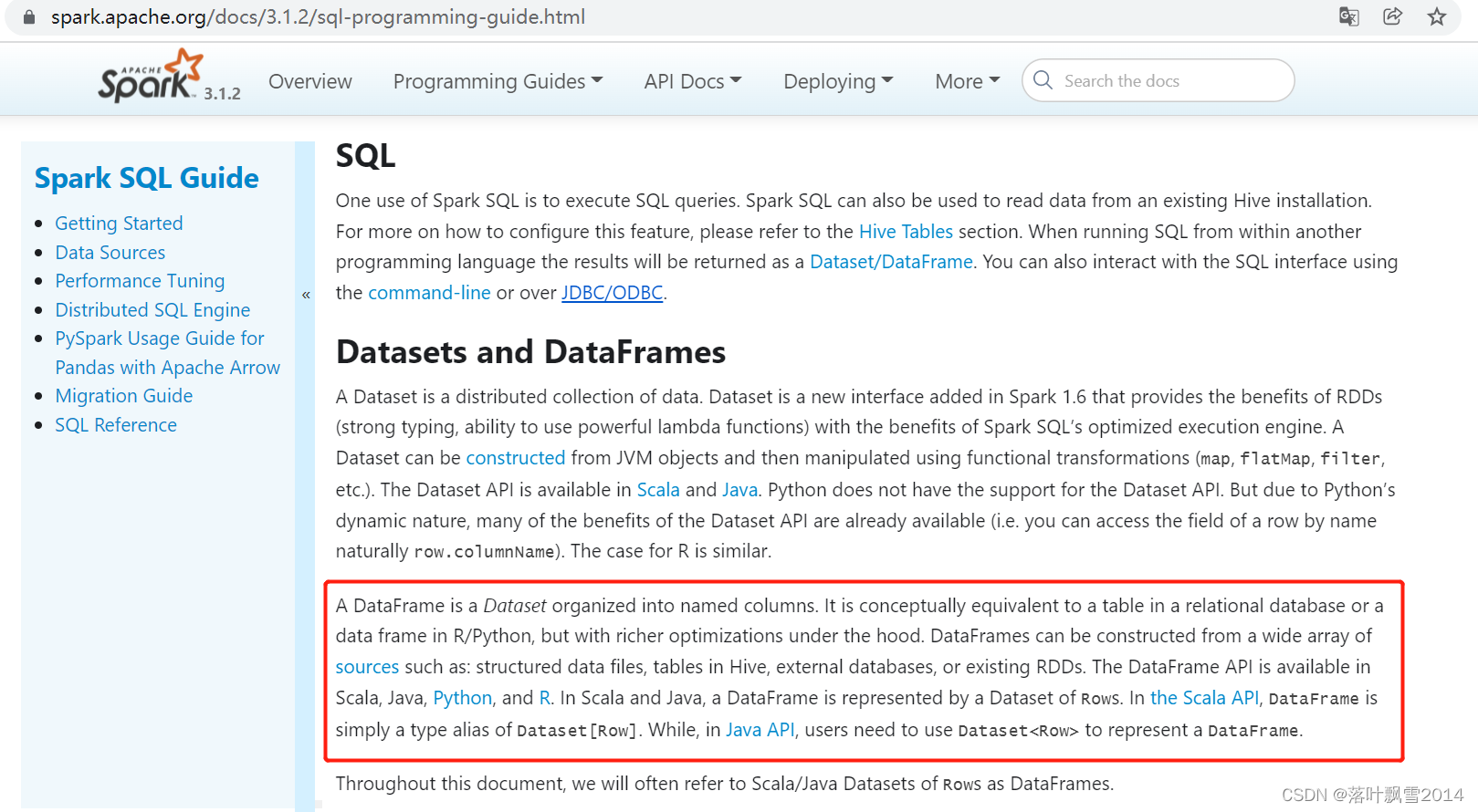
A DataFrame is a Dataset organized into named columns. It is conceptually equivalent to a table in a relational database or a data frame in R/Python, but with richer optimizations under the hood. DataFrames can be constructed from a wide array of sources such as: structured data files, tables in Hive, external databases, or existing RDDs. The DataFrame API is available in Scala, Java, Python, and R. In Scala and Java, a DataFrame is represented by a Dataset of Rows. In the Scala API, DataFrame is simply a type alias of Dataset[Row]. While, in Java API, users need to use Dataset<Row> to represent a DataFrame.
DataFrame 是组织成命名列的数据集。它在概念上等同于关系数据库中的表或 R/Python 中的数据框,但在幕后进行了更丰富的优化。DataFrame 可以从多种来源构建,例如:结构化数据文件、Hive 中的表、外部数据库或现有 RDD。DataFrame API 在 Scala、Java、Python和R 中可用。在 Scala 和 Java 中,一个 DataFrame 由一个Rows的 Dataset 表示。在Scala API 中,DataFrame只是 的类型别名Dataset[Row]。虽然在Java的API,用户需要使用Dataset<Row>来表示DataFrame。
3.2 RDD VS DataFrame
3.2.1 理论
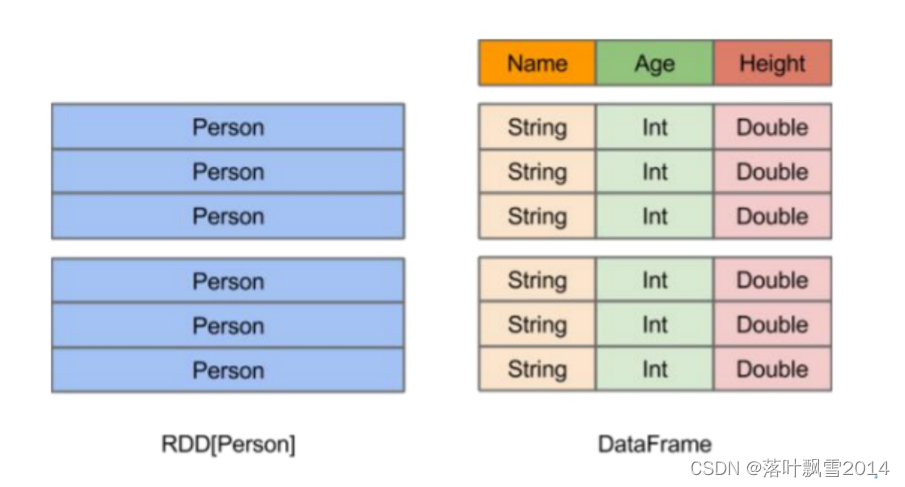
1、在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
2、DataFrame与RDD的主要区别在于,前者带有schema元数据,即DataFrame所表示的二维表数据集的每一列都带有名称和类型
3、使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时候效率的目标。
4、反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水化优化。
3.2.2 实践
初始化之后你会看到两行提示:
Spark context available as 'sc' (master = local[*], app id = local-1638778822523).
Spark session available as 'spark'.
通过Spark Content方式
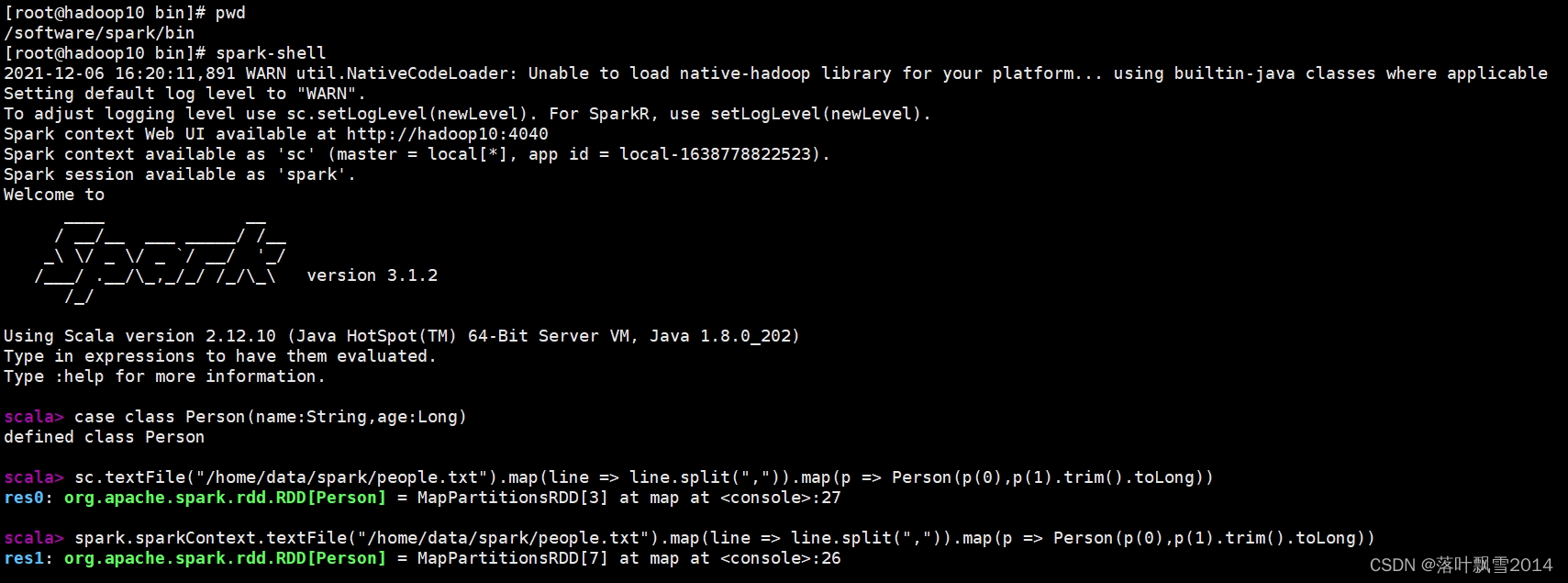
scala> case class Person(name:String,age:Long)
defined class Person
scala> sc.textFile("/home/data/spark/people.txt").map(line => line.split(",")).map(p => Person(p(0),p(1).trim().toLong))
res0: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[3] at map at <console>:27
scala> spark.sparkContext.textFile("/home/data/spark/people.txt").map(line => line.split(",")).map(p => Person(p(0),p(1).trim().toLong))
res1: org.apache.spark.rdd.RDD[Person] = MapPartitionsRDD[7] at map at <console>:26
通过Spark Session 方式
遇到了错误1:8020连接不上
scala> spark.read.json("/home/data/spark/people.txt")
java.net.ConnectException: Call From hadoop10/192.168.22.136 to hadoop10:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.hadoop.net.NetUtils.wrapWithMessage(NetUtils.java:831)
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:755)
at org.apache.hadoop.ipc.Client.getRpcResponse(Client.java:1515)
at org.apache.hadoop.ipc.Client.call(Client.java:1457)
at org.apache.hadoop.ipc.Client.call(Client.java:1367)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:228)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:116)
at com.sun.proxy.$Proxy24.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:903)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:422)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeMethod(RetryInvocationHandler.java:165)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invoke(RetryInvocationHandler.java:157)
at org.apache.hadoop.io.retry.RetryInvocationHandler$Call.invokeOnce(RetryInvocationHandler.java:95)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:359)
at com.sun.proxy.$Proxy25.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.getFileInfo(DFSClient.java:1665)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1582)
at org.apache.hadoop.hdfs.DistributedFileSystem$29.doCall(DistributedFileSystem.java:1579)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
at org.apache.hadoop.hdfs.DistributedFileSystem.getFileStatus(DistributedFileSystem.java:1594)
at org.apache.hadoop.fs.FileSystem.isDirectory(FileSystem.java:1700)
at org.apache.spark.sql.execution.streaming.FileStreamSink$.hasMetadata(FileStreamSink.scala:47)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:377)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:325)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:307)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:307)
at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:519)
at org.apache.spark.sql.DataFrameReader.json(DataFrameReader.scala:428)
... 47 elided
Caused by: java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.apache.hadoop.net.SocketIOWithTimeout.connect(SocketIOWithTimeout.java:206)
at org.apache.hadoop.net.NetUtils.connect(NetUtils.java:531)
at org.apache.hadoop.ipc.Client$Connection.setupConnection(Client.java:690)
at org.apache.hadoop.ipc.Client$Connection.setupIOstreams(Client.java:794)
at org.apache.hadoop.ipc.Client$Connection.access$3700(Client.java:411)
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1572)
at org.apache.hadoop.ipc.Client.call(Client.java:1403)
... 76 more
scala>
从上面报错来看,应该是即使是spark的local模式也是需要hadoop相关的后台服务,所以找不到8020端口,给hadoop启动起来即可。使用start-all.sh给hadoop启动起来之后即可。
遇到了错误2:文件找不到路径
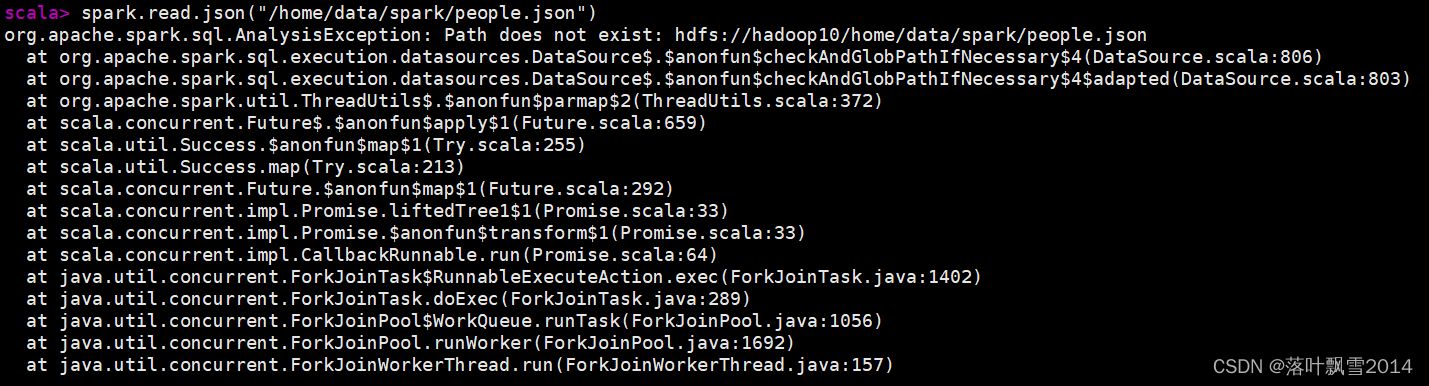
scala> spark.read.json("/home/data/spark/people.json")
org.apache.spark.sql.AnalysisException: Path does not exist: hdfs://hadoop10/home/data/spark/people.json
at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$4(DataSource.scala:806)
at org.apache.spark.sql.execution.datasources.DataSource$.$anonfun$checkAndGlobPathIfNecessary$4$adapted(DataSource.scala:803)
at org.apache.spark.util.ThreadUtils$.$anonfun$parmap$2(ThreadUtils.scala:372)
at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)
at scala.util.Success.$anonfun$map$1(Try.scala:255)
at scala.util.Success.map(Try.scala:213)
at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)
at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)
at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at java.util.concurrent.ForkJoinTask$RunnableExecuteAction.exec(ForkJoinTask.java:1402)
at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289)
at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056)
at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692)
at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157)
解决方案:
访问本地的前面使用file修饰
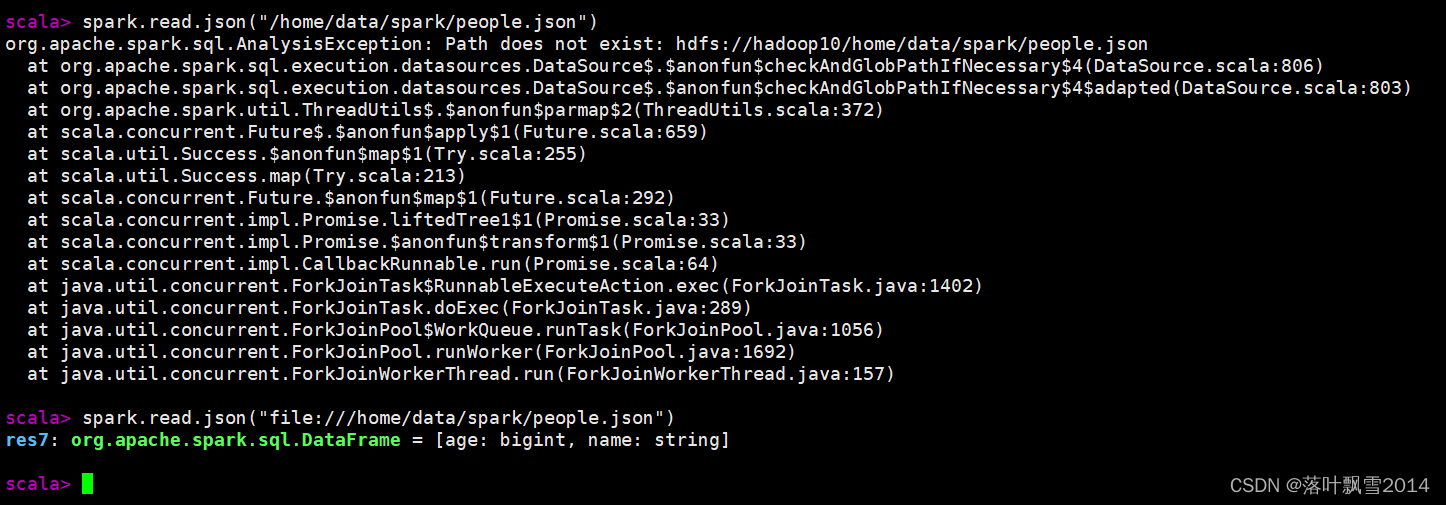
scala> spark.read.json("file:///home/data/spark/people.json")
res7: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
3.2.4 小总结
DataFrame带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
这使得SparkSQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。
反观RDD,由于无从得知所存数据元素的具体内部结构,Spark Core只能在stage层面进行简单、通用的流水线优化。
3.3 DataFrame快速API代码使用
参考官网案例 :
https://spark.apache.org/docs/3.1.2/sql-getting-started.html
3.3.1 添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
</dependency>
3.3.2 代码编写
package com.aa.sparkscala.sql
import org.apache.spark.sql.SparkSession
/**
* @Author AA
* @Date 2021/12/6 15:44
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
*/
object DataFrameExample {
def main(args: Array[String]): Unit = {
// $example on:init_session$
val spark = SparkSession
.builder()
.master("local")
.appName("DataFrame example")
//.config("spark.some.config.option", "some-value")
.getOrCreate()
// $example on:create_df$
//val df = spark.read.json("examples/src/main/resources/people.json")
val df = spark.read.json("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\people.json")
// Displays the content of the DataFrame to stdout
df.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:create_df$
// $example on:untyped_ops$
// This import is needed to use the $-notation
import spark.implicits._
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+
// Select everybody, but increment the age by 1
df.select($"name", $"age" + 1).show()
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+
// Select people older than 21
df.filter($"age" > 21).show()
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+
// Count people by age
df.groupBy("age").count().show()
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
// $example off:untyped_ops$
// $example on:run_sql$
// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people")
val sqlDF = spark.sql("SELECT * FROM people")
sqlDF.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:run_sql$
// $example on:global_temp_view$
// Register the DataFrame as a global temporary view
df.createGlobalTempView("people")
// Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:global_temp_view$
}
}
3.4 DataSet核心抽象
3.4.1 理论
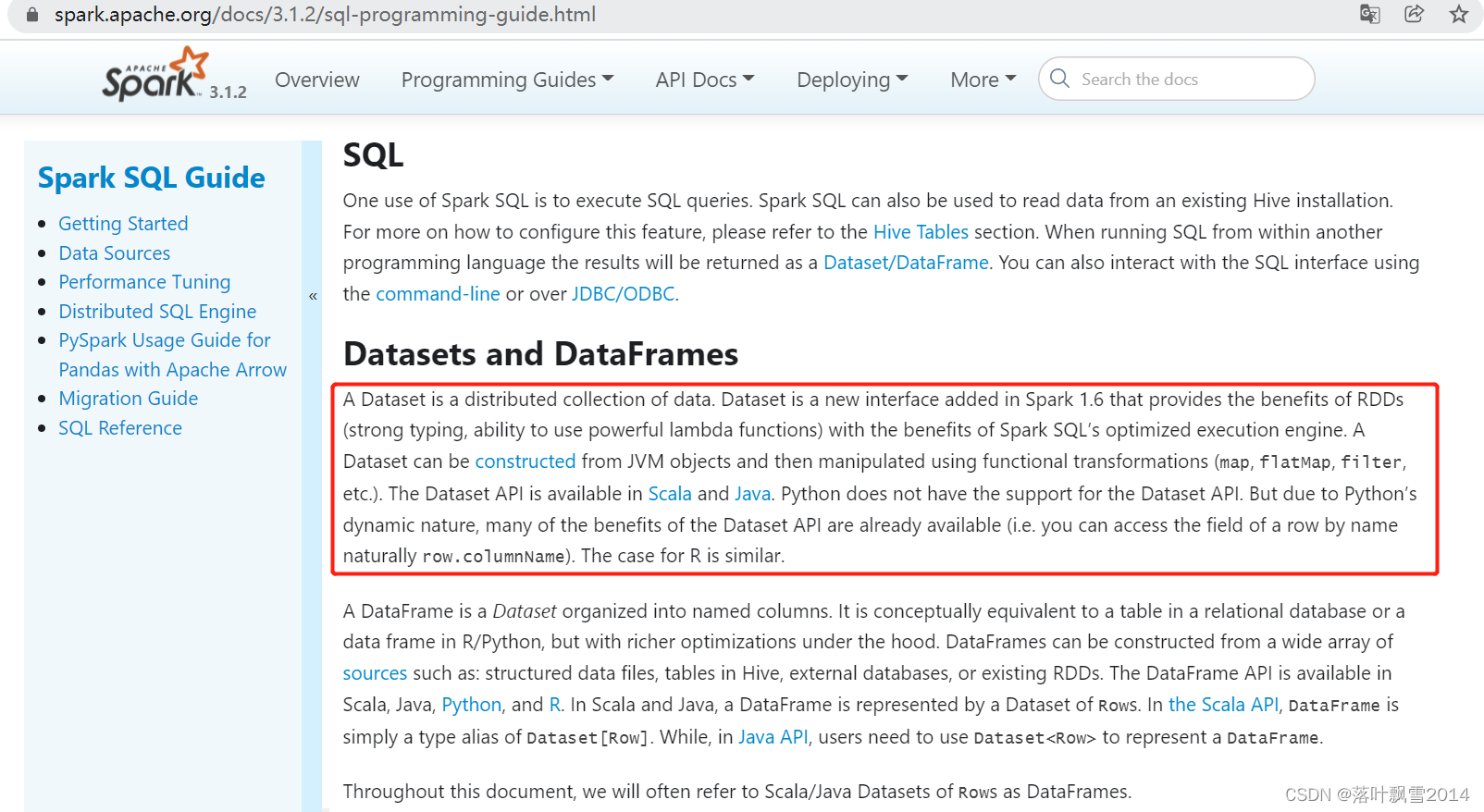
A Dataset is a distributed collection of data. Dataset is a new interface added in Spark 1.6 that provides the benefits of RDDs (strong typing, ability to use powerful lambda functions) with the benefits of Spark SQL’s optimized execution engine. A Dataset can be constructed from JVM objects and then manipulated using functional transformations (map, flatMap, filter, etc.). The Dataset API is available in Scala and Java. Python does not have the support for the Dataset API. But due to Python’s dynamic nature, many of the benefits of the Dataset API are already available (i.e. you can access the field of a row by name naturally row.columnName). The case for R is similar.
Dataset是数据的分布式集合。Dataset 是 Spark 1.6 中添加的一个新接口,它提供了 RDD 的优点(强类型、使用强大 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。数据集可以被构造从JVM对象,然后使用功能性的转换(map,flatMap,filter等等)。Dataset API 在Scala和 Java 中可用。Python 不支持 Dataset API。但是由于 Python 的动态特性,Dataset API 的许多好处已经可用(即您可以自然地按名称访问行的字段 row.columnName)。R 的情况类似。
3.4.2 实践
package com.aa.sparkscala.sql
import org.apache.spark.sql.SparkSession
/**
* @Author AA
* @Date 2021/12/6 17:18
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
*/
object DataSetExample {
case class Person(name: String, age: Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("DataSet example")
.getOrCreate()
import spark.implicits._
// $example on:create_ds$
// Encoders are created for case classes
/**
Seq 和 Set是scala中针对现实使用场景的不同数据结构抽象。
Seq是列表,适合存有序重复数据,进行快速插入/删除元素等场景
Set是集合,适合存无序非重复数据,进行快速查找海量元素的等场景
*/
val caseClassDS = Seq(Person("Andy", 32)).toDS()
caseClassDS.show()
// +----+---+
// |name|age|
// +----+---+
// |Andy| 32|
// +----+---+
// Encoders for most common types are automatically provided by importing spark.implicits._
val primitiveDS = Seq(1, 2, 3).toDS()
primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4)
// DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name
val path = "D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\people.json"
val peopleDS = spark.read.json(path).as[Person]
peopleDS.show()
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
// $example off:create_ds$
}
}
四、RDD转DataFrame
4.1 Inferring the Schema Using Reflection
使用反射推断模式
package com.aa.sparkscala.sql
import org.apache.spark.sql.SparkSession
/**
* @Author AA
* @Date 2021/12/6 17:32
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
*/
object InferSchemaExample {
case class Person(name: String, age: Long)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("DataSet example")
.getOrCreate()
// $example on:schema_inferring$
// For implicit conversions from RDDs to DataFrames
import spark.implicits._
// Create an RDD of Person objects from a text file, convert it to a Dataframe
val peopleDF = spark.sparkContext
.textFile("examples/src/main/resources/people.txt")
.map(_.split(","))
.map(attributes => Person(attributes(0), attributes(1).trim.toInt))
.toDF()
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people")
// SQL statements can be run by using the sql methods provided by Spark
val teenagersDF = spark.sql("SELECT name, age FROM people WHERE age BETWEEN 13 AND 19")
// The columns of a row in the result can be accessed by field index
teenagersDF.map(teenager => "Name: " + teenager(0)).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// or by field name
teenagersDF.map(teenager => "Name: " + teenager.getAs[String]("name")).show()
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
// No pre-defined encoders for Dataset[Map[K,V]], define explicitly
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
// Primitive types and case classes can be also defined as
// implicit val stringIntMapEncoder: Encoder[Map[String, Any]] = ExpressionEncoder()
// row.getValuesMap[T] retrieves multiple columns at once into a Map[String, T]
teenagersDF.map(teenager => teenager.getValuesMap[Any](List("name", "age"))).collect()
// Array(Map("name" -> "Justin", "age" -> 19))
// $example off:schema_inferring$
}
}
4.2 Programmatically Specifying the Schema
以编程方式指定模式
package com.aa.sparkscala.sql
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
/**
* @Author AA
* @Date 2021/12/6 17:35
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
*/
object ProgrammaticSchemaExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("ProgrammaticSchemaExample example")
.getOrCreate()
import spark.implicits._
// $example on:programmatic_schema$
// Create an RDD
val peopleRDD = spark.sparkContext.textFile("examples/src/main/resources/people.txt")
// The schema is encoded in a string
val schemaString = "name age"
// Generate the schema based on the string of schema
val fields = schemaString.split(" ")
.map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
// Convert records of the RDD (people) to Rows
val rowRDD = peopleRDD
.map(_.split(","))
.map(attributes => Row(attributes(0), attributes(1).trim))
// Apply the schema to the RDD
val peopleDF = spark.createDataFrame(rowRDD, schema)
// Creates a temporary view using the DataFrame
peopleDF.createOrReplaceTempView("people")
// SQL can be run over a temporary view created using DataFrames
val results = spark.sql("SELECT name FROM people")
// The results of SQL queries are DataFrames and support all the normal RDD operations
// The columns of a row in the result can be accessed by field index or by field name
results.map(attributes => "Name: " + attributes(0)).show()
// +-------------+
// | value|
// +-------------+
// |Name: Michael|
// | Name: Andy|
// | Name: Justin|
// +-------------+
// $example off:programmatic_schema$
}
}
五、多种数据源的使用
5.1 通用Load / Save
5.1.1 Load 案例
package com.aa.sparkscala.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @Author AA
* @Date 2021/12/6 18:25
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
* Load数据案例
*/
object LoadExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("LoadExample")
.getOrCreate()
// For implicit conversions like converting RDDs to DataFrames
import spark.implicits._
//格式一:parquet格式
val df: DataFrame = spark.read.load("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\users.parquet")
df.createOrReplaceTempView("users")
spark.sql("select name from users").show()
//格式二: JSON格式
val df1 = spark.read.format("json").load("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\people.json")
df1.createOrReplaceTempView("people")
spark.sql("select * from people").show()
//格式三: CSV格式
val df2 = spark.read.format("csv")
.option("header","true")
.option("delimiter",";")
.load("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\people.csv")
df2.createOrReplaceTempView("people2")
spark.sql("select * from people2").show()
}
}
5.1.2 Save 案例
package com.aa.sparkscala.sql
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* @Author AA
* @Date 2021/12/6 18:35
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
* Save 案例
*/
object SaveExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("SaveExample")
.getOrCreate()
//格式一:parquet
val df: DataFrame = spark.read.load("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\users.parquet")
df.createOrReplaceTempView("users")
spark.sql("select name from users").show()
df.write.save("D:\\SaveExample_ParquetResult") //parquet格式输出*/
//格式二: JSON格式的方式输出
val df1 = spark.read.format("json").load("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\people.json")
df1.createOrReplaceTempView("people1")
spark.sql("select name from people1")
//.write.format("json").save("D:\\SaveExample_JsonResult") //JSON格式输出
.write.format("json").mode(SaveMode.Overwrite).save("D:\\SaveExample_JsonResult") //覆盖写出结果
}
}
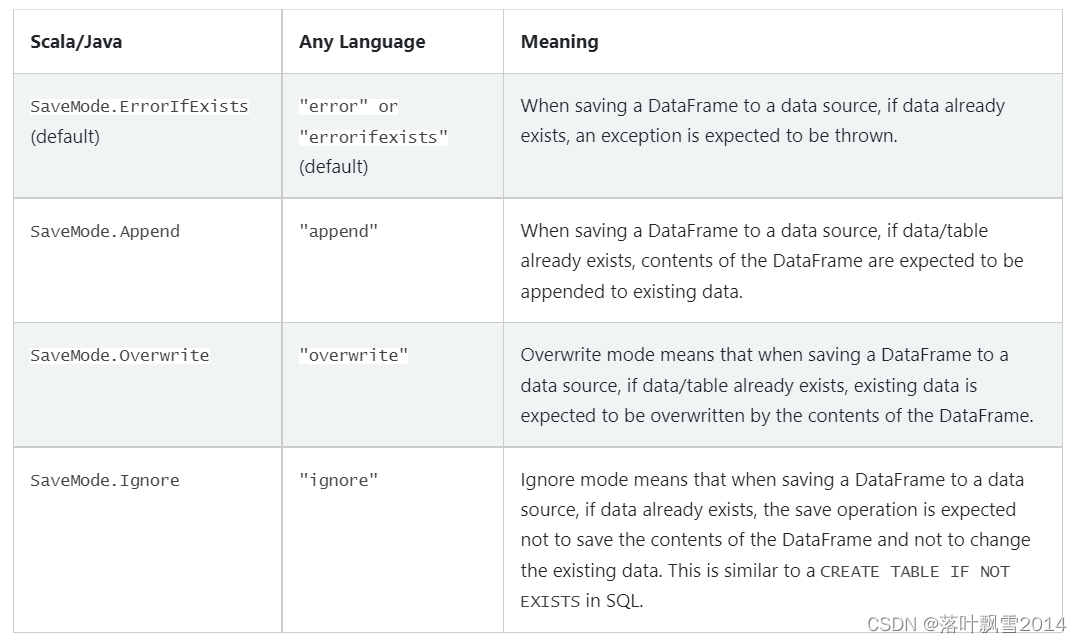
5.1.3 Save Modes
Save operations can optionally take a SaveMode, that specifies how to handle existing data if present. It is important to realize that these save modes do not utilize any locking and are not atomic. Additionally, when performing an Overwrite, the data will be deleted before writing out the new data.
保存操作可以选择采用SaveMode,指定如何处理现有数据(如果存在)。重要的是要意识到这些保存模式不使用任何锁定并且不是原子的。此外,在执行 时Overwrite,将在写出新数据之前删除数据。
5.2 MySQL 源
5.2.1 案例代码
package com.aa.sparkscala.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
import java.util.Properties
/**
* @Author AA
* @Date 2021/12/6 18:55
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
* 通过Spark SQL 连接MySQL 数据库
*/
object MySQLExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("MySQLExample")
.getOrCreate()
val url="jdbc:mysql://localhost:3306/hive?serverTimezone=GMT";
val properties = new Properties()
properties.put("url",url)
properties.put("user","root")
properties.put("password","111111")
val df: DataFrame = spark.read.jdbc(url,"people",properties)
df.show()
}
}
5.2.2 本地运行可能遇到的错误
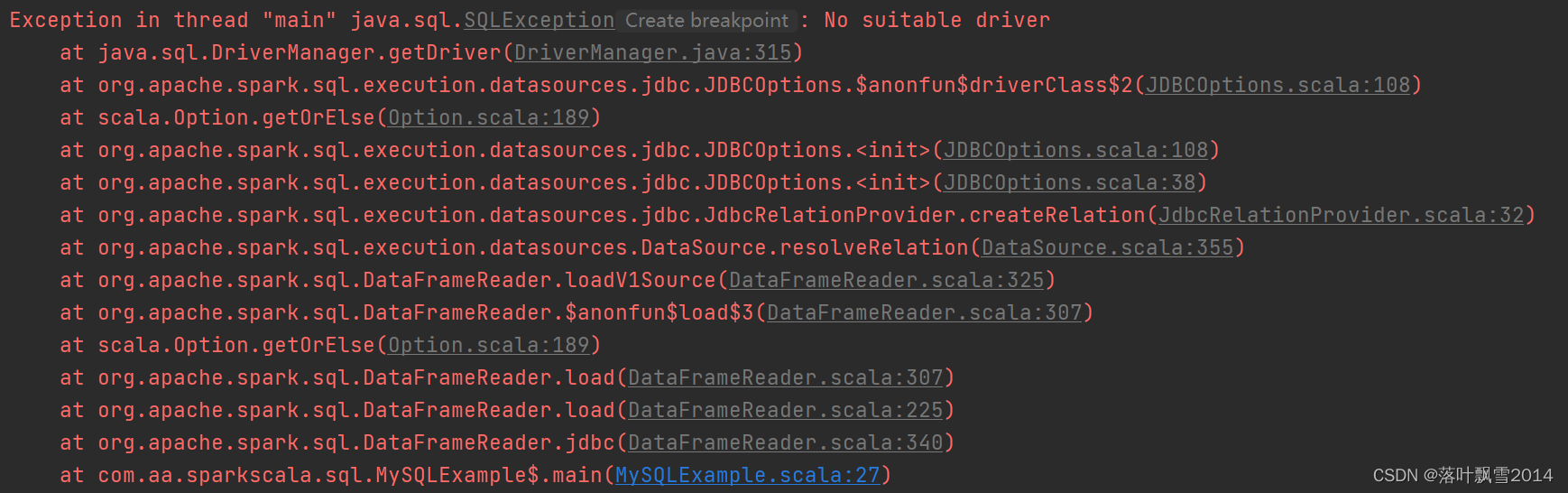
21/12/07 14:38:31 INFO SharedState: Warehouse path is 'file:/D:/work/sourcecode/bigdatapre/spark-warehouse/'.
Exception in thread "main" java.sql.SQLException: No suitable driver
at java.sql.DriverManager.getDriver(DriverManager.java:315)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.$anonfun$driverClass$2(JDBCOptions.scala:108)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:108)
at org.apache.spark.sql.execution.datasources.jdbc.JDBCOptions.<init>(JDBCOptions.scala:38)
at org.apache.spark.sql.execution.datasources.jdbc.JdbcRelationProvider.createRelation(JdbcRelationProvider.scala:32)
at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:355)
at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:325)
at org.apache.spark.sql.DataFrameReader.$anonfun$load$3(DataFrameReader.scala:307)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:307)
at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:225)
at org.apache.spark.sql.DataFrameReader.jdbc(DataFrameReader.scala:340)
at com.aa.sparkscala.sql.MySQLExample$.main(MySQLExample.scala:27)
at com.aa.sparkscala.sql.MySQLExample.main(MySQLExample.scala)
21/12/07 14:38:32 INFO SparkContext: Invoking stop() from shutdown hook
解决方案:在pom.xml文件中添加依赖的jar
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
再次运行正确结果如下:
5.3 Hive 源
5.3.1 在IDEA中操作
5.3.1.1 在model的pom文件中添加依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
</dependency>
5.3.1.2 完整代码
package com.aa.sparkscala.sql
import java.io.File
import org.apache.spark.sql.{Row, SaveMode, SparkSession}
/**
* @Author AA
* @Date 2021/12/7 15:12
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
*/
object HiveExample {
case class Record(key: Int, value: String)
def main(args: Array[String]): Unit = {
// warehouseLocation points to the default location for managed databases and tables
//val warehouseLocation = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.master("local") //这个必须要设置
.appName("Spark Hive Example")
//.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport() //这个hive支持必须添加
.getOrCreate()
import spark.implicits._
import spark.sql
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive")
sql("LOAD DATA LOCAL INPATH 'spark/src/main/resources/kv1.txt' INTO TABLE src")
//sql("truncate table default.src") //清空表里面的数据。
// Queries are expressed in HiveQL
sql("SELECT * FROM src").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// Aggregation queries are also supported.
sql("SELECT COUNT(*) FROM src").show()
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// The results of SQL queries are themselves DataFrames and support all normal functions.
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key")
// The items in DataFrames are of type Row, which allows you to access each column by ordinal.
val stringsDS = sqlDF.map {
case Row(key: Int, value: String) => s"Key: $key, Value: $value"
}
stringsDS.show()
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ...
// You can also use DataFrames to create temporary views within a SparkSession.
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
// Queries can then join DataFrame data with data stored in Hive.
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// | 5| val_5| 5| val_5|
// ...
// Create a Hive managed Parquet table, with HQL syntax instead of the Spark SQL native syntax
// `USING hive`
sql("CREATE TABLE hive_records(key int, value string) STORED AS PARQUET")
// Save DataFrame to the Hive managed table
val df = spark.table("src")
df.write.mode(SaveMode.Overwrite).saveAsTable("hive_records")
// After insertion, the Hive managed table has data now
sql("SELECT * FROM hive_records").show()
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// Prepare a Parquet data directory
val dataDir = "/tmp/parquet_data"
spark.range(10).write.parquet(dataDir)
// Create a Hive external Parquet table
sql(s"CREATE EXTERNAL TABLE hive_bigints(id bigint) STORED AS PARQUET LOCATION '$dataDir'")
// The Hive external table should already have data
sql("SELECT * FROM hive_bigints").show()
// +---+
// | id|
// +---+
// | 0|
// | 1|
// | 2|
// ... Order may vary, as spark processes the partitions in parallel.
// Turn on flag for Hive Dynamic Partitioning
spark.sqlContext.setConf("hive.exec.dynamic.partition", "true")
spark.sqlContext.setConf("hive.exec.dynamic.partition.mode", "nonstrict")
// Create a Hive partitioned table using DataFrame API
df.write.partitionBy("key").format("hive").saveAsTable("hive_part_tbl")
// Partitioned column `key` will be moved to the end of the schema.
sql("SELECT * FROM hive_part_tbl").show()
// +-------+---+
// | value|key|
// +-------+---+
// |val_238|238|
// | val_86| 86|
// |val_311|311|
// ...
spark.stop()
}
}
5.3.2 在Shell窗口中操作
[root@hadoop10 bin]# spark-shell --driver-class-path /software/hive/lib/mysql-connector-java-5.1.40-bin.jar
2021-12-06 19:05:05,212 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = local[*], app id = local-1638788713035).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.{DataFrame, SparkSession}
scala> val spark = SparkSession.builder().appName("Spark Hive Example").enableHiveSupport().getOrCreate()
2021-12-06 19:05:20,846 WARN sql.SparkSession$Builder: Using an existing SparkSession; the static sql configurations will not take effect.
2021-12-06 19:05:20,846 WARN sql.SparkSession$Builder: Using an existing SparkSession; some spark core configurations may not take effect.
spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@29f94912
scala> spark.sql("show databases").show
2021-12-06 19:05:28,559 WARN conf.HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
2021-12-06 19:05:28,559 WARN conf.HiveConf: HiveConf of name hive.stats.retries.wait does not exist
2021-12-06 19:05:32,756 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 2.3.0
2021-12-06 19:05:32,756 WARN metastore.ObjectStore: setMetaStoreSchemaVersion called but recording version is disabled: version = 2.3.0, comment = Set by MetaStore root@192.168.22.136
+---------+
|namespace|
+---------+
| db1|
| default|
+---------+
scala>
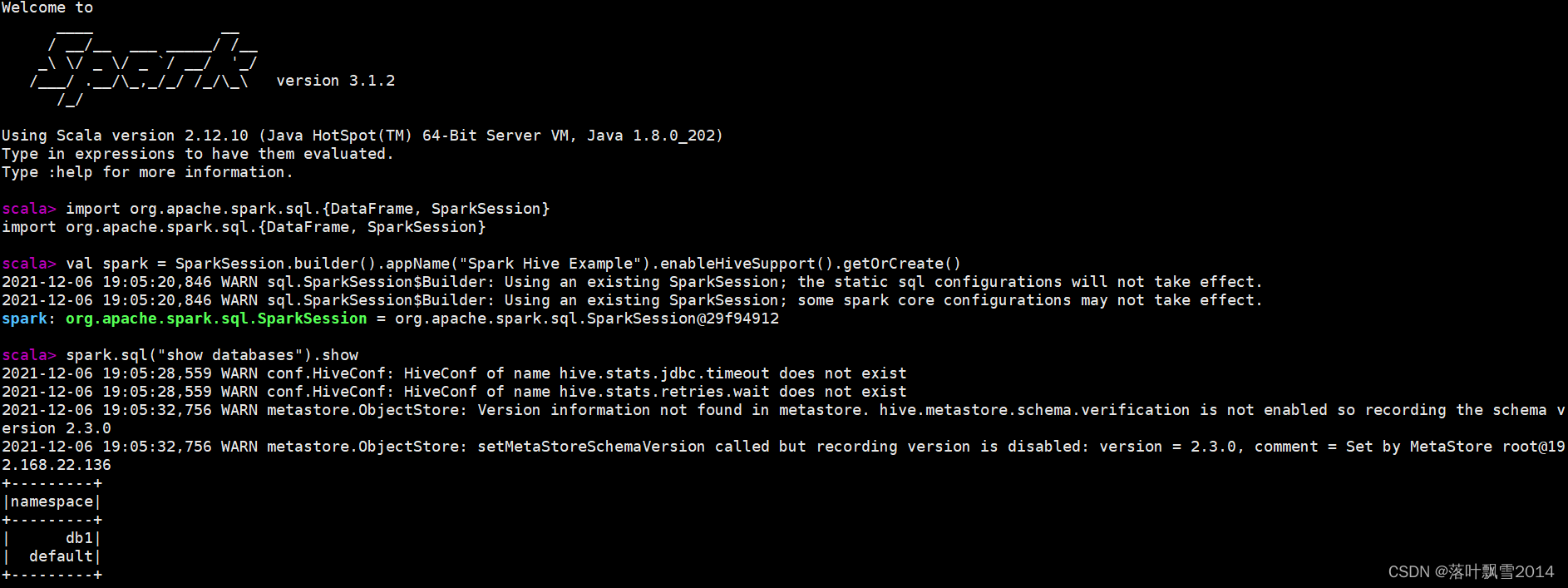
当出现上面的内容的时候,虽然没有任何错误,但是本质上是不对的,因为显示的这两个数据库是spark sql中的数据库。不是我们期望的Hive中的数据库。
下面修改成操作Hive的。
解决方案:
1、给hive下面的 hive-site.xml拷贝到spark的lib下面即可
操作如下:
[root@hadoop10 conf]# cp hive-site.xml /software/spark/conf/
[root@hadoop10 conf]# pwd
/software/hive/conf
[root@hadoop10 conf]#
正确结果如下:
[root@hadoop10 bin]# spark-shell --driver-class-path /software/hive/lib/mysql-connector-java-5.1.40-bin.jar
2021-12-07 16:01:46,338 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://hadoop10:4040
Spark context available as 'sc' (master = local[*], app id = local-1638864112167).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_202)
Type in expressions to have them evaluated.
Type :help for more information.
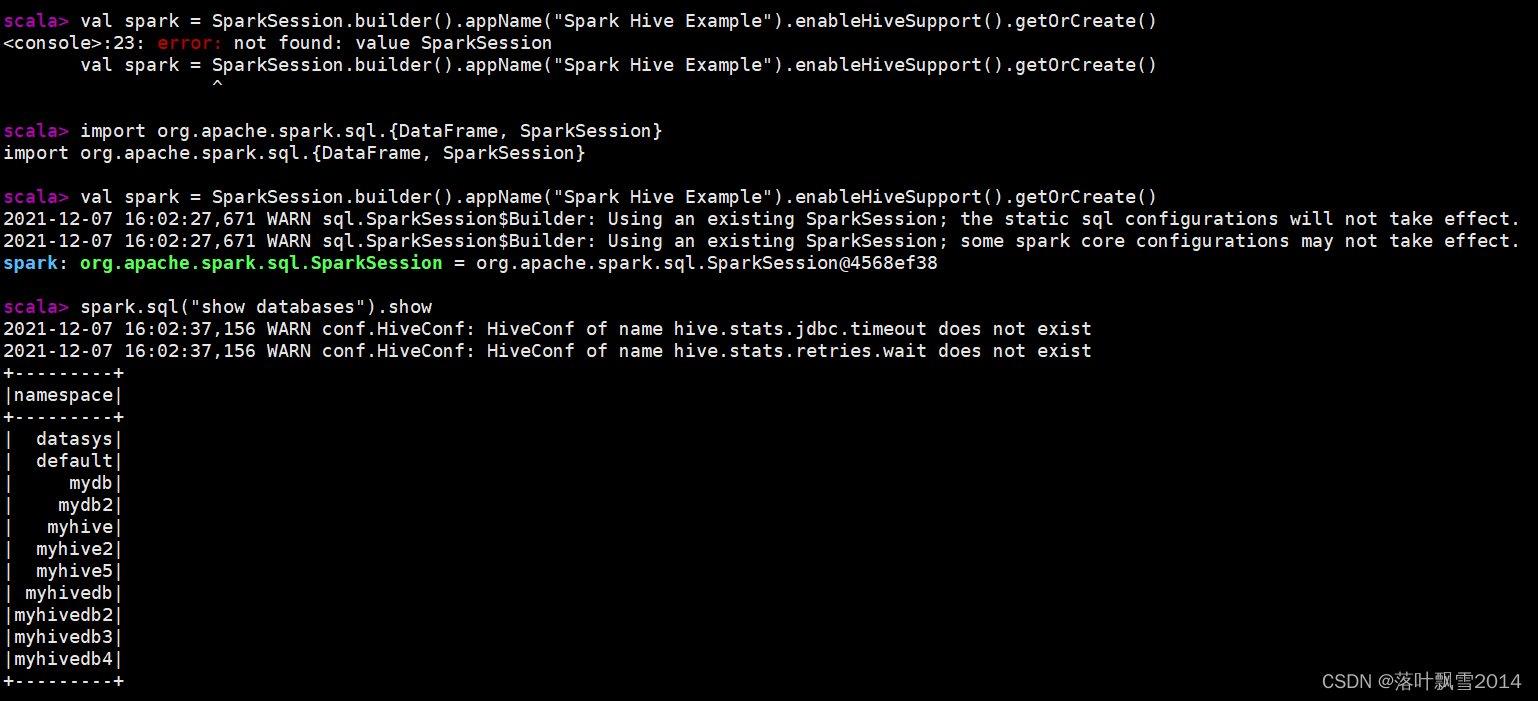
scala> val spark = SparkSession.builder().appName("Spark Hive Example").enableHiveSupport().getOrCreate()
<console>:23: error: not found: value SparkSession
val spark = SparkSession.builder().appName("Spark Hive Example").enableHiveSupport().getOrCreate()
^
scala> import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.{DataFrame, SparkSession}
scala> val spark = SparkSession.builder().appName("Spark Hive Example").enableHiveSupport().getOrCreate()
2021-12-07 16:02:27,671 WARN sql.SparkSession$Builder: Using an existing SparkSession; the static sql configurations will not take effect.
2021-12-07 16:02:27,671 WARN sql.SparkSession$Builder: Using an existing SparkSession; some spark core configurations may not take effect.
spark: org.apache.spark.sql.SparkSession = org.apache.spark.sql.SparkSession@4568ef38
scala> spark.sql("show databases").show
2021-12-07 16:02:37,156 WARN conf.HiveConf: HiveConf of name hive.stats.jdbc.timeout does not exist
2021-12-07 16:02:37,156 WARN conf.HiveConf: HiveConf of name hive.stats.retries.wait does not exist
+---------+
|namespace|
+---------+
| datasys|
| default|
| mydb|
| mydb2|
| myhive|
| myhive2|
| myhive5|
| myhivedb|
|myhivedb2|
|myhivedb3|
|myhivedb4|
+---------+
scala>
截个图
六、函数那些事
6.1 自定义函数
package com.aa.sparkscala.sql
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* @Author AA
* @Date 2021/12/6 19:18
* @Project bigdatapre
* @Package com.aa.sparkscala.sql
* 用户自定义函数案例
*/
object UDFExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("LoadExample")
.getOrCreate()
//求字符串长度
spark.udf.register("StringLength",(str:String) =>{
if(str != null){
str.length
}else{
0
}
})
val df: DataFrame = spark.read.load("D:\\work\\sourcecode\\bigdatapre\\spark\\src\\main\\resources\\users.parquet")
df.createOrReplaceTempView("users")
spark.sql("select StringLength(name) from users").show()
}
}







![[附源码]计算机毕业设计springboot居家养老服务系统小程序](https://img-blog.csdnimg.cn/1ce7757e53a74ef9b340ba60d161f87b.png)
![[附源码]计算机毕业设计JAVA闲置物品交易管理系统](https://img-blog.csdnimg.cn/f62305b75e074038876a03d28f81e82f.png)



![[附源码]Python计算机毕业设计Django的项目管理系统](https://img-blog.csdnimg.cn/f96e8cc560e74bdb8b23e12f6e43a758.png)