1、导入需要的库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
from sklearn.model_selection import GridSearchCV
2、导入数据
在此下载泰坦尼克号训练数据
data = pd.read_csv(r"F:\data\train1.csv")
data
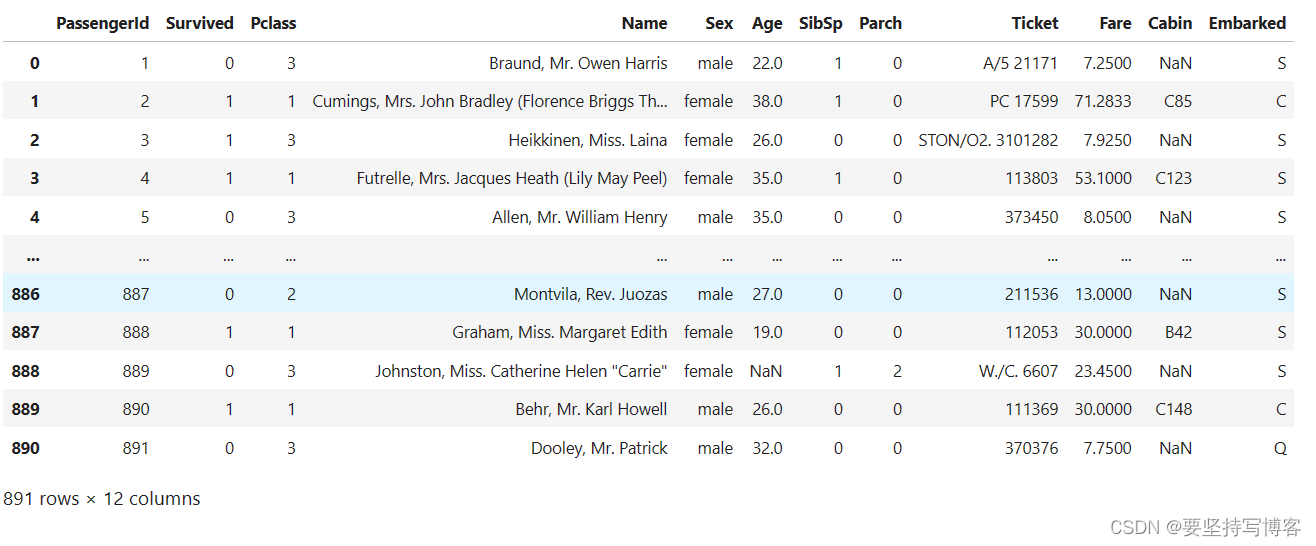
把不需要的特征删除。
#筛选特征
data.drop(['Cabin',"Name","Ticket"],inplace=True,axis=1) #删除列,inplace默认为false也就是是否覆盖原表
并且用data.info()去查看数据是否有缺失
data.info()
#下图age就很多缺失值
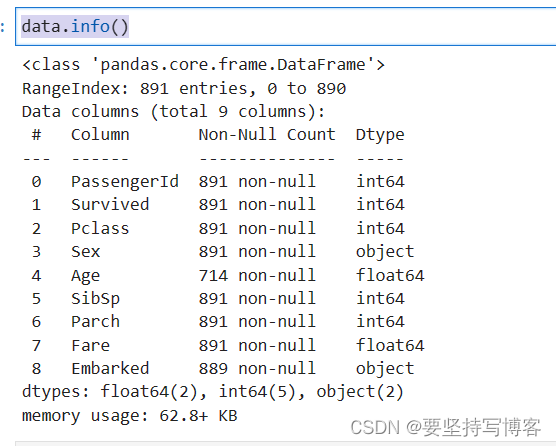
所以我们得填补缺失值。
#处理缺失值
data["Age"] = data["Age"].fillna(data["Age"].mean()) #用fillna均值填充na
data = data.dropna(axis=0) #删掉有缺失值的行(只有两行,对数据影响不大)
把object处理为数字,因为只能处理数字。
labels = data["Embarked"].unique().tolist() #查看有几个值
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x)) #x的Embarked中每一条记录
data.loc[:,"Sex"] = (data["Sex"] == "male").astype("int") #astype转换类型
因为特征和标签都在一个表上,所以得把特征和标签分开。
x = data.loc[:,data.columns != "Survived"] #特征
y = data.loc[:,data.columns == "Survived"] #标签
把数据分为测试集和训练集
from sklearn.model_selection import train_test_split
Xtrain,Xtest,Ytrain,Ytest = train_test_split(x,y,test_size = 0.3)
因为分是随机分的,所以序号可能并没有顺序,为防止后续操作会用的序号必须有序,所以把这里处理一下:
for i in [Xtrain,Xtest,Ytrain,Ytest]:
i.index = range(i.shape[0])
训练数据,(这样划分偶然性很强)
clf = DecisionTreeClassifier(random_state=25) #实例化
clf = clf.fit(Xtrain,Ytrain)
score = clf.score(Xtest,Ytest)
score
#0.7378
这就有下面使用交叉验证再取平均:
from sklearn.model_selection import cross_val_score
#使用交叉验证
clf = DecisionTreeClassifier(random_state=25) #实例化
score = cross_val_score(clf,x,y,cv=10).mean()
score
#0.7469
下面就是调参:
#调参
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
)
clf = clf.fit(Xtrain,Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,x,y,cv=10).mean()
#这里测试和训练的数据有所变化
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color='red',label='train')
plt.plot(range(1,11),te,color='black',label='test')
plt.xticks(range(1,11))
plt.legend()
plt.show()
#由此可调出max_depth的参数。
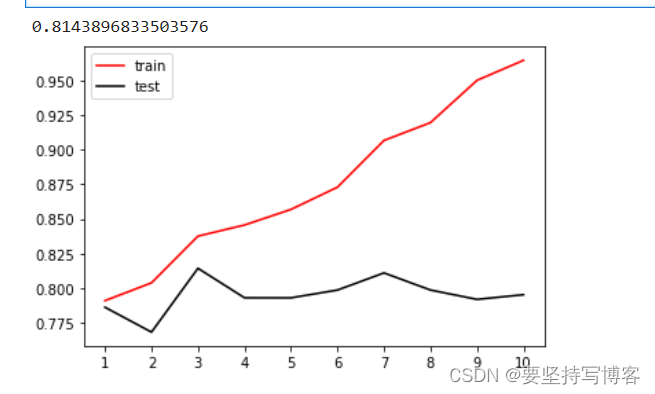
这样只能一次调一个参数,所以有了下面的网格搜索。
import numpy as np
parameters = {"criterion":("gini","entropy")
,"splitter":("best","random")
,"max_depth":[*range(1,10)]
,"min_samples_leaf":[*range(1,50,5)]
,"min_impurity_decrease":[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf,parameters,cv=10)
GS = GS.fit(Xtrain,Ytrain)
#得跑好几分钟
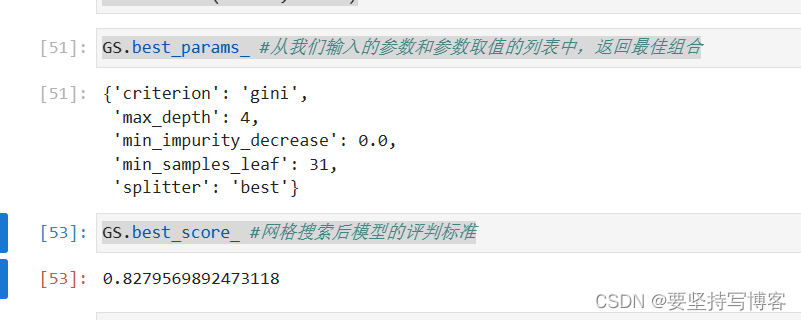
GS.best_params_ #从我们输入的参数和参数取值的列表中,返回最佳组合
GS.best_score_ #网格搜索后模型的评判标准
#0.8279