EXPLAIN 语句 概貌



-
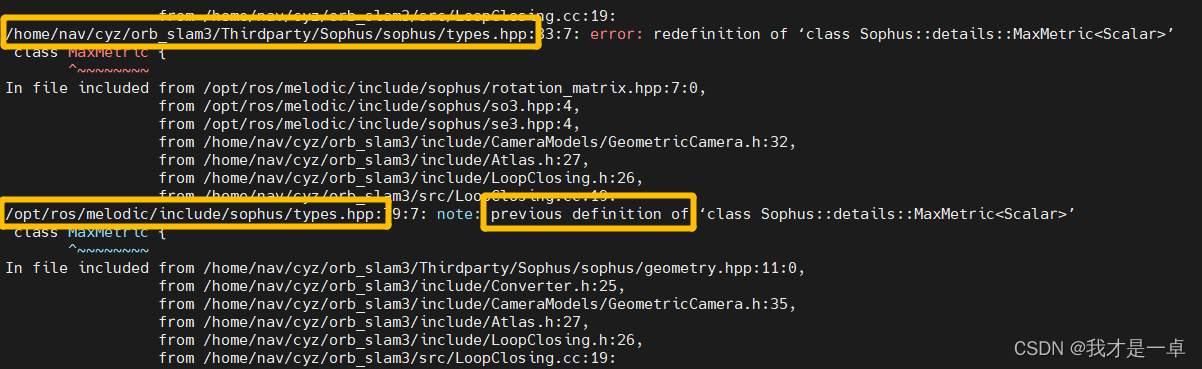
在连接查询的执行计划中: 每个表都会对应一条记录,这些记录的 id 列的值是相同的;
-
在包含子查询的执行计划中 :每个 select关键字都会对应一个唯一的 id 值。
-
驱动表:出现在前面的表;
-
被驱动表:出现在后面的表。
EXPLAIN 各字段详解
1. select_type值为:
-
PRIMARY
-
UNION
-
UNION RESULT:MySQL选择使用临时表来完成
UNION查询的去重工作。 -
SUBQUERY: 如果包含子查询的查询语句,不能转为对应的半连接形式,并且该子查询是不相关子查询,而且查询优化器决定采用将该子查询物化的方案来执行该子查询时,则,
selct_type的值为SUBQUERY。 -
DEPENDENT SUBQUERY : 如果包含子查询的查询语句,不能转为对应的半连接形式,并且该子查询是相关子查询,则,
selct_type的值为DEPENDENT SUBQUERY。 -
DEPENDENT UNION
-
DERIVED: 在包含派生表的查询中,以物化派生表的方式执行查询。
-
MATERIALIZED: 当查询优化器在执行包含子查询的语句时,选择将子查询物化之后与外层查询进行连接,则,该子查询对应的
selct_type的值为MATERIALIZED -
UNCACHEABLE SUBQUERY:不常用
-
UNCACHEABLE UNION: 不常用
2. type值(表明访问方法)
完整的访问方法有:system, const, eq_ref, ref, fulltext, ref_or_null, index_merge, unique_subquery, index_subquery, range, index, ALL等。
-
system:当表中只有一条记录,且,该表使用的存储引擎(比如,MyISAM、MEMORY)的统计数据是精确的,那么对该表的访问方法就是system。
-
const : 当我们根据主键或者唯一二级索引列与常数进行等值匹配时,对单表的访问方法就是const。如:
EXPLAIN SELECT * FROM s1 WHERE id = 5; -
eq_ref : 如果被驱动表是通过主键or 不允许存储 NULL 值的唯一二级索引列等值匹配的方式进行访问的(如果该主键or不允许存储NULL值的唯一二级索引列是联合索引,则,所有的索引列都必须进行等值比较),则,对该被驱动表的访问方法就是eq_ref。例如,
EXPLAIN SELECT * FROM s1 INNER JOIN s2 ON s1.id = s2.id;,此时, s1 的type 为 ALL, s2 的 type 为 eq_ref。 -
ref : 当通过普通的 二级索引列 与 常量 进行等值匹配的方式来查询某个表时,对该表的访问方法就可能时 ref。
-
fulltext:全文索引
-
ref_or_null :当对普通二级索引列进行等值匹配,且,该索引列的值也可以是NULL值时,对该表的访问方法就可能是 ref_or_null。
-
index_merge : 一般情况下,只会为单个索引生成扫描区间。索引合并。
-
unique_subquery : 类似于两表连接中被驱动表的 eq_ref访问方法,unique_subquery针对的是一些包含 IN 子查询的查询语句。如果查询优化器决定将IN子查询转换为 EXISTS子查询,且,子查询在转换之后可以使用主键或者不允许存储NULL值的唯一二级索引进行等值匹配,则,该子查询的type列的值为 unique_subquery。
-
index_subquery : 与 unique_subquery 类似,只不过在访问子查询中的表时,使用的时普通的索引。
-
range :
-
使用索引获取某些单点扫描区间的记录(如,
explain select * from s1 where key1 in ('a', 'b', 'c');, 此时,表s1的type列的值为 range)。 -
用于获取某个or某些范围扫描区间的记录(如,
explain select * from s1 where key1 > 'a' and key1 < 'b';, 此时,表s1的type列的值为 range)。
- index:
-
使用索引覆盖,且需要扫描全部的索引记录。如,
explain select key_part2 from s1 where key_part3 = 'a';, 此时,表s1的type列的值为 index。- 解析:key_part2列,key_part3列都包含在联合索引 idx_key_part中,但搜索条件 key_part3=‘a’ 不能形成合适的扫描区间从而减少需要扫描的记录数量,而只能扫描整个 idx_key_part 索引的记录,所以,执行计划的type列的值就是 index。
-
特殊:对于InnoDB存储引擎来说,当需要全表扫描且要对主键进行排序时,如,
explain select * from s1 order by id;,此时的 type 列的值也是 index。
- ALL : 全表扫描。
3. possible_keys 和 key
在EXPLAIN语句输出的执行计划中,
-
possible_keys列: 表示在某个查询语句中,对某个表执行单表查询时,可能用的到的索引有哪些;
-
key 列: 表示实际用到的索引有哪些。(经过查询优化器计算不同索引的使用成本后,决定使用某索引执行查询)
4. key_len
key_len 值由下面3部分组成。
-
该列的实际数据最多占用的存储空间长度。
-
如果该列可以存储NULL值,则key_len值在该列的实际数据最多占用的存储空间长度的基础上再加1字节。
-
对于使用变长类型的列来说,都会有2字节的空间来存储该变列的实际数据占用的存储空间长度,key_len值还要在原先的基础上加2字节。
5. ref
当访问方法是 const, eq_ref, ref, ref_or_null, unique_subquery, index_subquery中的其中一个时,ref 列展示的就是与索引列进行等值匹配的东西是啥,比如,只是一个常数或者是某个列。
6. rows
rows列:
-
代表该表的估计行数(全表扫描);
-
代表预计扫描的索引记录行数(用索引执行查询)。
7. filtered
分析连接查询成本时,提出过一个condition filtering(条件过滤)的概念,此概念是MySQL在计算驱动表扇出时采用的一个策略。
-
如果使用全表扫描的方式来执行单表查询,那么计算驱动表扇出时,需要估计出满足全部搜索条件的记录到底有多少条。
-
如果使用索引来执行单表扫描,那么计算驱动表扇出时,需要估计出在满足形成索引扫描区间的搜索条件外,还满足其他搜索条件的记录有多少条。
举个小例子, 在连接查询中, 驱动表的rows列 x 驱动表的 filtered 列 = 驱动表的扇出值(还要对被驱动表执行多少次查询)
8. Extra
Extra列是用来说明一些额外信息的。有很多个,常见的如下:
-
No tables used: 查询语句中没有FROM子句。
-
Impossible WHERE : WHERE子句永远为FALSE。
-
No matching min/max row: 查询列表处有MIN或者MAX聚集函数,但并没有符合WHERE子句中的搜索条件时,会提示该额外信息。
-
Using Index :使用覆盖索引执行查询。
-
Using index condition : 有些搜索条件中虽然出现了索引列,但却不能充当边界条件来形成扫描区间,也就是不能用来减少需要扫描的记录数量。
-
Using where: 某个搜索条件需要在server层进行判断。
-
Using filesort: 使用文件排序的方式执行查询。(文件排序:在内存中或者磁盘中进行排序的方式)
-
Using temporary: 建立内部的临时表来执行查询。
彩蛋——Extented EXPLAIN
在使用EXPLAIN语句查看了某个查询的执行计划后,紧接着还可以使用 SHOW WARNINGS语句查看与这个查询的执行计划有关的扩展信息。