kotlin入门学习文档
前言:本文会着重对比java和kotlin,方便Java选手理解
提前总结:kotlin在服务端应用本质上是基于Java进行的改进,底层都是由JVM翻译成底层语言,我们只需要关注kotlin本身的代码,无需担心平台的问题。并且kotlin和Java语言本身可以互相反编译,非常方便。kotlin最大的优化应该是两个,一个是繁多的语法糖和新的语法思想,简化编码过程,改进了Java臃肿的结构。另一个是引入了协程,Java产生的年代可能由于协程技术并不流行或者当时的技术无法很好的实现并利用,所以只关注于线程。而kotlin也好go语言也好,都引入了协程这个概念,从而打开了异步编程的大门。其他的优点,比如从强语言类型变为弱语言类型,使用val和var区分只读变量和可变变量解决Java头疼的空指针问题等就不再赘述了。
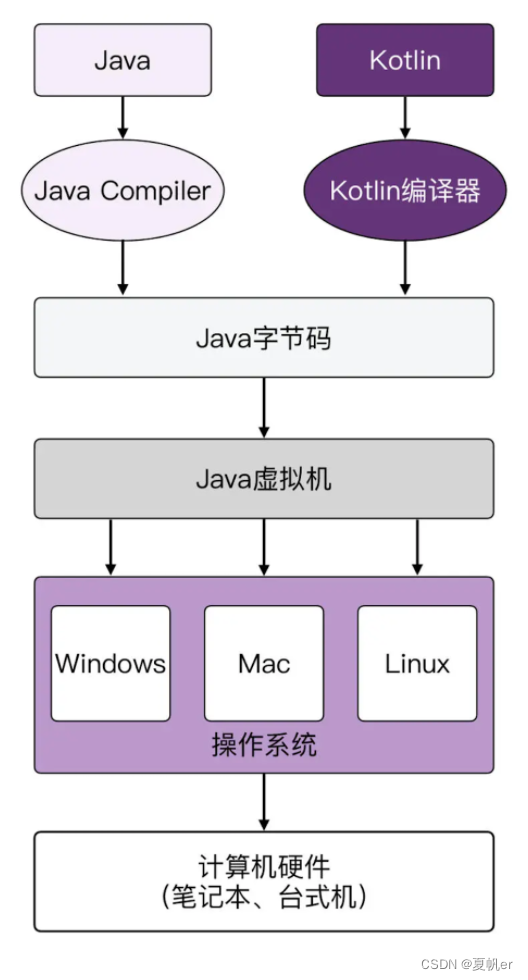
补充一张Java和kotlin的关系图:
一、基础语法
1、变量声明
先看实例代码:
Java:Integer price = 100;
kotlin:var price = 100
从例子可以看出,Java是强类型语言,而kotlin是弱类型语言(同python和js),编译器会自动推断类型。
kotlin自己的语法的话,在声明变量的时候需要携带var或者val。区别在于var声明的是可变变量,而val声明的是不可变变量。
如:
var price = 100
price = 101
val i = 0
i = 1 //编译器会报错
2、基础类型
一切皆对象
Java语言最重要的思想就是一切皆对象,但是Java对于基础类型的处理是分为两种情况,一种是非对象的原始类型,另一种是作为对象的包装类型,原因是原始类型的开销小、性能高,但它不是对象,无法很好地融入到面向对象的系统中。而包装类型的开销大、性能相对较差,但它是对象,可以很好地发挥面向对象的特性。
而到kotlin中,舍弃了原始类型这个概念,也就是实现了真正意义上的一切皆对象。
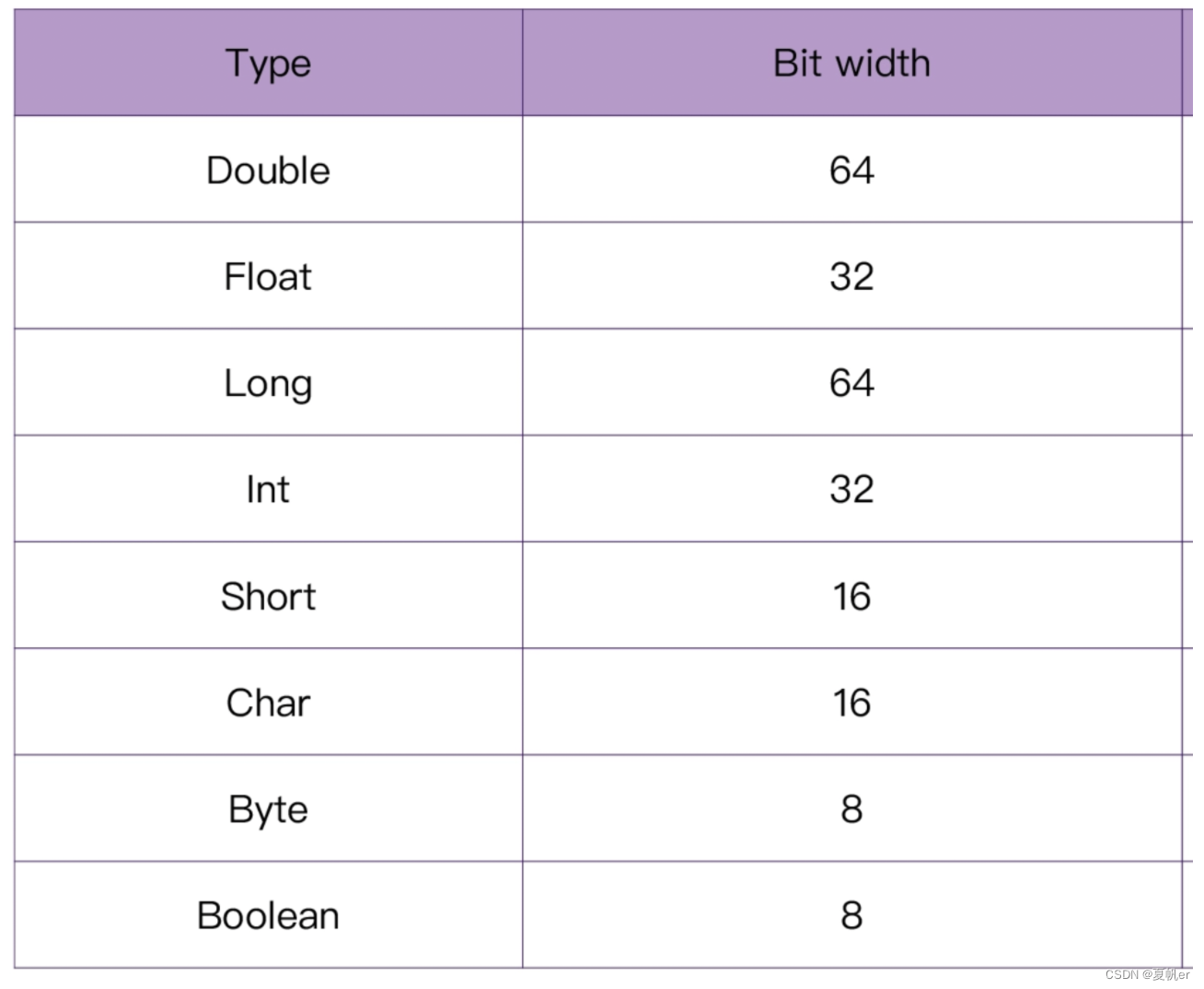
kotlin的基础类型和Java基本一致,如图:
在kotlin中真正实现了一切皆对象,然后呢?有什么作用?
我认为,是数字或字符串本身都被当作对象了,所以操作更加灵活了,如:
val i: Double = 1.toDouble()
1直接被当成了对象,可以调用toDouble方法转换为Double类型,这在Java中是做不到。
空安全问题
kotlin中一切皆对象,那么就很可能会发生我们很头疼的空对象错误,但是kotlin本身从编码上改善了这个问题。
kotlin强制要求开发者在定义变量的时候,就必须指定这个变量是否可能为空。对于可能为null的变量,我们必须在声明的时候在变量类型后携带一个“?”。如:
val i: Double = null // 编译器报错
val j: Double? = null // 编译通过
如果是可变变量,可空变量也是不可以赋值给非空变量的。如:
var i: Double = 1.0
var j: Double? = null
i = j // 编译器报错
j = i // 编译通过
如果我们非要这样赋值的话,必须做非空判断。如:
var i: Double = 1.0
val j: Double? = null
if (j != null) {
i = j // 编译通过
}
kotlin这样设计的好处我认为是缩小了空值可能存在的范围,让变量这个大概念更加细分,数据可管理性更强。
数字类型的自动推断和互相转换
在数字类型的定义上,Java和kotlin基本一致,自动推断也是基于这种机制的,如:
val int = 1
val long = 1234567L
val double = 13.14
val float = 13.14F
val hexadecimal = 0xAF
val binary = 0b01010101
解释如下:
-
整数默认会被推导为“Int”类型;
-
Long 类型,我们则需要使用“L”后缀;
-
小数默认会被推导为“Double”,我们不需要使用“D”后缀;
-
Float 类型,我们需要使用“F”后缀;
-
使用“0x”,来代表十六进制字面量;
-
使用“0b”,来代表二进制字面量。
而对象数字类型的转换,在Java中是有隐式类型转换和显式类型转换两种的,各有其规则;而在kotlin中则更崇尚完全的显式类型转换。
如果以Java的隐式转换思想,会导致代码报错,如:
val i = 100
val j: Long = i // 编译器报错
正确做法应该是:
val i = 100
val j: Long = i.toLong() // 编译通过
这样可以一定程度上提高代码的可读性,无论是新手还是老手,都可以一眼看出是类型转换.
布尔类型和字符类型
布尔类型和字符类型基本上和Java一致,这里不再赘述,只做演示。
如:
val i = 1
val j = 2
val k = 3
val isTrue: Boolean = i < j && j < k
val c: Char = 'A'
布尔类型的运算符也是和Java完全一样的,有位运算,也有短路逻辑运算:
-
“&”代表“与运算”;
-
“|”代表“或运算”;
-
“!”代表“非运算”;
-
“&&”和“||”分别代表它们对应的“短路逻辑运算”。
字符串类型
kotlin拼接字符串的时候可以直接访问变量,如果这是访问简单的变量只需要$变量就行了,而如果要访问比较复杂的变量,那么就需要增加花括号语法,具体实例如下:
val name = "Kotlin"
print("Hello $name!")
/* ↑
直接在字符串中访问变量
*/
// 输出结果:
Hello Kotlin!
val array = arrayOf("Java", "Kotlin")
print("Hello ${array.get(1)}!")
/* ↑
复杂的变量,使用${}
*/
// 输出结果:
Hello Kotlin!
kotlin还定义了一个新东西,官方叫原始字符串,由三对引号包裹。它的作用是可以用于存放复杂的多行文本,并且定义的时候是什么样的,最终打印出来也会是什么样的,所以当我们需要使用复杂文本的时候,就不需要像Java一样去加一堆加号拼接和一堆换行符换行了。
如:
val s = """
我会自动
换行的
神奇吗
"""
print(s)
kotlin还额外定制了一个函数trimMargin,用来去除前导空格,如下:
val text = """
|Tell me and I forget.
|Teach me and I remember.
|Involve me and I learn.
|(Benjamin Franklin)
""".trimMargin()
输出结果则每一行不会带有前导空格(|符号是默认的标记去除前导空格的符号,可以自己改)
数组类型
kotlin中的数组也是自动推断元素类型的,和基础类型一样。如:
val arrayInt = arrayOf(1, 2, 3)
val arrayString = arrayOf("apple", "pear")
这里kotlin有一个神奇的处理,就是数组已经没有数组类型这个概念了,数组中的每个元素的类型是可以不同的!如:
val arr1 = arrayOf("test",1,3.0)
println("${arr1.get(0)},${arr1.get(1)},${arr1.get(2)}")
//输出结果为:test,1,3.0
区别在于:在Java中,数组和其他集合类型的操作是不一样的,比如数组的长度是arr.length,而列表的长度是list.size。而到kotlin中,数组虽然依然不属于集合,但是统一了操作,也就是数组也是arr.size就可以获取长度了。如:
val array = arrayOf("apple", "pear")
println("Size is ${array.size}")
println("First element is ${array[0]}")
// 输出结果:
Size is 2
First element is apple
3、函数
函数的声明格式如下:
/*
关键字 函数名 参数类型 返回值类型
↓ ↓ ↓ ↓ */
fun helloFunction(name: String): String {
return "Hello $name !"
}/* ↑
花括号内为:函数体
*/
观察到,像这样的函数,其函数体其实只有一句话,在kotlin中针对这种情况作出了语法优化。这种语法被称为单一表达式函数。
优化后效果如下:
fun helloFunction(name: String): String = "Hello $name !"
再观察到,返回类型是String,而我们的返回值本身就已经是String了,或者说,返回值的类型我们是可以确定的,所以进一步的,返回类型也不需要声明了,kotlin会自动判断返回类型。再次简化后如下:
fun helloFunction(name: String) = "Hello $name !"
可以看到,到函数部分,kotlin的简洁和众多语法糖交杂的特性开始慢慢显示出来了。
函数调用本身其实和Java差不多,如下:
helloFunction("Kotlin")
在Java编程里,很多时候,函数的参数是有很多个的,一旦参数变多并且参数类型相同,参数对应这种简单的事情就变得困难了起来,而kotlin在这里也做了改进,那就是参数命名。
helloFunction(name = "Kotlin")
并且kotlin建议参数类型从上往下写,而不是从左往右写,这样更方便阅读,如:
函数声明:
fun createUser(
name: String,
age: Int,
gender: Int,
friendCount: Int,
feedCount: Int,
likeCount: Long,
commentCount: Int
) {
//函数主体
}
函数调用:
createUser(
name = "Tom",
age = 30,
gender = 1,
friendCount = 78,
feedCount = 2093,
likeCount = 10937,
commentCount = 3285
)
除此之外,kotlin还支持函数设置默认参数,这个特性同样十分方便:
fun createUser(
name: String,
age: Int,
gender: Int = 1,
friendCount: Int = 0,
feedCount: Int = 0,
likeCount: Long = 0L,
commentCount: Int = 0
) {
//..
}
这样做的好处就在于,我们在调用的时候可以省很多事情。比如说,下面这段代码就只需要传 3 个参数,剩余的 4 个参数没有传,但是 Kotlin 编译器会自动帮我们填上默认值。
createUser(
name = "Tom",
age = 30,
commentCount = 3285
)
对于无默认值的参数,我们必须要传参;而对于有默认值的参数,则可传可不传。
如果要在Java中实现这样的操作,我想,则需要使用多态的特性了吧。
4、流程控制
if
if用于逻辑判断的话,和Java基本上是没有区别的,如:
val i = 1
if (i > 0) {
print("Big")
} else {
print("Small")
}
输出结果:
Big
但是在kotlin中还有第二种用法,就是作为表达式,实际作用很像我们的三元运算符,如:
val i = 1
val message = if (i > 0) "Big" else "Small"
print(message)
输出结果:
Big
这段代码相当于Java中的:
int i = 1
String message = ""
if (i > 0) {
message = "Big"
} else {
message = "Small"
}
print(message)
if表达式显得代码更简洁了。
而在kotlin中,对于参数为可空的情况,我们很容易遇到返回值需要判断的情况,这时候函数一般形如:
fun getLength(text: String?): Int {
return if (text != null) text.length else 0
}
而kotlin的开发者觉得,这样依然比较麻烦,则设置了一种叫elvis表达式的东西,用来简化这种情况的if表达式,如:
fun getLength(text: String?): Int {
return text?.length ?: 0
}
when
when语句听起来陌生,其实很像Java的switch case语句,只是在此基础上做了一些改进而已。
像switch的用法如:
val i: Int = 1
when(i) {
1 -> print("一")
2 -> print("二")
else -> print("i 不是一也不是二")
}
输出结果:
一
when除了作为逻辑判断之外,还可以为变量赋值,如:
val i: Int = 1
val message = when(i) {
1 -> "一"
2 -> "二"
else -> "i 不是一也不是二" // 如果去掉这行,会报错
}
print(message)
when和switch不同的一个点是,when的逻辑分支必须是完整的,换句话说,when的逻辑分支必须包含所有的可能性。我认为这是为了方便错误排查,如果是when代码段的错误,那么可能的值一定在when所给的范围项中。
for
kotlin的for关键字语法,如果学过python可能比较熟悉,基本上是跟python差不多。for在这几个语言里面一般可以和while互换使用,但是使用for的出发点一般都旨在迭代。(个人觉得kotlin的这个语法糖没有必要,Java的for语句反而简单易懂,没有那么多规矩,这里的for混合了python的语法还有Java针对集合的foreach语法,反而晦涩难读)
for可以迭代数组或者集合,如下:
val array = arrayOf(1, 2, 3)
for (i in array) {
println(i)
}
kotlin还可以构造一个区间,语法为:左区间…右区间,如:
val range = 1..3 //代表区间【1,3】 左右都是闭区间
我们可以使用这个定义的区间来做迭代,比如:
for(i in range){
print(i)
}
那么有一个问题,从1到3是1…3,那么倒序想从3到1,是不是3…1?
确实很容易联想到这么使用,但是kotlin的语法在这里却不那么简洁了,需要使用另外的关键字来倒序执行,如:
for (i in 6 downTo 0 step 2) {
println(i)
}
输出结果:
6
4
2
0
while
while的用法和Java的while基本一致,这里不再赘述,放一段实例代码应该就理解了:
fun whiletest():Int{
var n= 3;
var res = 0;
while(n>=0){
res++;
n--;
}
return res;
}
二、面向对象
先说大前提,kotlin和Java一样,对于类是单继承的,对于接口才是多继承的
1、类
kotlin的类默认是public的,如果需要使用别的访问器修饰符才需要修改。
先看Java类的定义,再对比kotlin的类定义,比较一下才能凸显出kotlin的简洁:
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 属性 name 没有 setter
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
可以看到,这是一个简单人的类,包含的属性有名字和年龄。其中年龄属性在构造的时候即赋值,且只有getter,因为默认姓名是不可变的。
可以看到Java的类声明非常的繁琐,除了定义属性外,还要自己写构造函数,还要自己写setter和getter(即使有idea的快捷创建方式和lombok插件依然麻烦)
而kotlin的声明值需要一行:
class Person(val name: String, var age: Int)
解释一下,val修饰的变量是只读变量,所以构造的时候指定后就无法再修改了,对应了Java中只有getter没有setter,而var修饰的变量是可变变量,所以会自动拥有setter和getter方法。
这里只是展示kotlin的简洁,详细的如下:
- 构造函数
constructor关键字是用来标识构造函数的,在kotlin中有主构造函数和次构造函数的概念。
我们上面的代码就是主构造函数,并且省略了constructor关键字。若不省略则如下:
class Person constructor(val name: String, var age: Int)
当主构造函数没有注解和可见性修饰符的时候就可以省略掉constructor关键字
显而易见,主构造函数不能携带别的代码,所以如果我们想要初始化一些东西,可以在类主体中加入初始化块,如下:
class Person constructor(val name: String, var age: Int){
init{
print("i am init")
}
}
初始代码块实际上会成为主构造函数的一部分,所以当次构造函数委托主构造函数的时候也会执行
如果我们不指定主构造函数,kotlin也会默认生成一个无参的主构造函数,和Java自带无参构造函数很像。
而次级构造函数,我认为是为了一定程度上贴合Java的编码习惯,常见的用法如下:
class Person {
va name: String? = null
var age: Int? = null
constructor()
constructor(name:String,age:Int) {
this.name = name
this.age = age
}
}
次构造函数必须委托给主构造函数,当主构造函数为无参构造函数的时候才可以省略。比如:
class Person(val name: String) {
var children: MutableList<Person> = mutableListOf()
constructor(name: String, parent: Person) : this(name) {
parent.children.add(this)
}
}
更具体的概念整合由一个实例来展示,使用次构造函数来构造对象,会发现它会先调用初始化块,应证了初始化块是主函数块的一部分,并且初始化块是在构造完成后才运行的。如何new一个对象也在这里有所体现。
(顺便再补充一个点,当涉及继承的时候,如果派生类有一个主构造函数,其基类可以(并且必须) 用派生类主构造函数的参数就地初始化。如果派生类没有主构造函数,那么每个次构造函数必须使用 super 关键字初始化其基类型,或委托给另一个构造函数做到这一点。 注意,在这种情况下,不同的次构造函数可以调用基类型的不同的构造函数:)
class ClassDemo(name: String) {
var name:String? = null
var age:Int = 0
init {
println("this is a test")
println(name)
println(age)
}
constructor(name:String,age:Int):this(name){
this.name = name
this.age = age
}
}
fun main() {
var obj = ClassDemo("test",18)
println(obj.name)
println(obj.age)
}
//输出结果
this is a test
test
0
test
18
- 继承
在Java中Object是所有类的超类,而在kotlin中也有相同的概念,只不过这里换了个名字,叫Any。
Any 有三个方法:equals()、 hashCode() 与 toString()。因此,为所有 Kotlin 类都定义了这些方法。
先说一下和Java对应的抽象类,抽象类的使用和Java基本一样,但是kotlin抽象类可以直接继承,默认是可继承的,如下:
abstract class Person(val name: String) {
abstract fun walk()
// 省略
}
// Java 的继承
// ↓
public class Man extends Person {
@Override
void walk(){ ... }
}
// Kotlin 的继承
// ↓
class Man : Person() {
//覆盖加上override关键字就行
override fun walk() { ... }
}
而普通的类默认是无法继承的,相当于Java中的final类,不可变类。如果需要开启继承机制的话,就要加open关键字,如:
```kotlin
open class Person() {
}
class Boy: Person() {
// 省略重写逻辑
}
并且,不仅仅是类不可变,类中的属性和方法也必须由open修饰才支持覆盖,并且覆盖的时候必须加override关键字,如:
open class Person() {
open val canWalk: Boolean = false
fun walk()
}
class Boy: Person() {
// 不会报错
override val canWalk: Boolean = true
// 报错
override fun walk() {
}
}
总结:Java的继承机制是开放的,而kotlin的继承机制是封闭的。kotlin这种改进使得继承不会被滥用
这里再补充一点知识点:
- 关于覆盖方法:标记为 override 的成员本身是开放的,也就是说,它可以在子类中覆盖。如果你想禁止再次覆盖,使用 final 关键字:
final override fun draw()
-
关于覆盖变量:可以用一个
var属性覆盖一个val属性,但反之则不行。 这是允许的,因为一个val属性本质上声明了一个get方法, 而将其覆盖为var只是在子类中额外声明一个set方法。 -
属性声明
属性声明主要是初始化、get、set,一般的语法如下:
var stringRepresentation: String
get() = this.toString()
set(value) {
setDataFromString(value) // 解析字符串并赋值给其他属性
}
按照惯例,setter 参数的名称是 value,但是如果你喜欢你可以选择一个不同的名称。
如果需要加访问器或者注解同样只需要在前面加上就行了,在kotlin中几乎都是这样。
var setterVisibility: String = "abc"
private set // 此 setter 是私有的并且有默认实现
var setterWithAnnotation: Any? = null
@Inject set // 用 Inject 注解此 setter
这里补充一个,幕后字段和幕后属性。
先看一个例子:
如果将这样一段Java代码翻译成kotlin是什么样的?
class Computer{
//这里name就是字段,用于装载数据使用的,一般我们定义为私有的
private int age;
//这里的getter和setter或者其他访问器供与外部使用的就是所谓的属性
public void setter(int age){this.age = age}
public int getter(return this.age){}
}
如果想当然的话,我们可能会这么写:
var age:Int
get() = age
set(value){
age = value
}
但是这样会造成死循环,我们可以反编译成Java代码看一下:
public final int getAge() {
return this.getAge();
}
public final void setAge(int value) {
this.setAge(value);
}
这是为什么?因为kotlin在我们直接获取age的时候,调用的就是get方法,当我们写age属性的时候,调用的就是set方法,所以编程了无限循环。
这个时候就需要我们的幕后字段field了,它的作用就是告诉编译器,我不是要调用set或者get方法,而是要获取这个值而已。如下:
var age:Int = 0
get() = field
set(value){
field = value
}
再看看反编译的结果:
public final int getAge() {
return this.age;
}
public final void setAge(int value) {
this.age = value;
}
这下就没有问题了,这就是幕后字段的作用。
也可以用幕后属性来实现一样的效果:
private var _table: Map<String, Int>? = null
public val table: Map<String, Int>
get() {
if (_table == null) {
_table = HashMap() // 类型参数已推断出
}
return _table ?: throw AssertionError("Set to null by another thread")
}
- 编译器常量
如果val只读属性的值在编译期是已知的,那么可以使用 const 修饰符将其标记为编译期常量。 这种属性需要满足以下要求:
- 位于顶层或者是 object 声明 或 companion object 的一个成员
- 以
String或原生类型值初始化 - 没有自定义 getter
- 延迟初始化属性和变量
看项目代码的话,用的最多的地方就是自动装配依赖注入的时候。
一般地,属性声明为非空类型必须在构造函数中初始化。 然而,这经常不方便。例如:属性可以通过依赖注入来初始化, 或者在单元测试的 setup 方法中初始化。 这种情况下,你不能在构造函数内提供一个非空初始器。 但你仍然想在类体中引用该属性时避免空检测。如:
@RestController
@RequestMapping("/v1")
class TestController {
//依赖注入
@Autowired
private lateinit var encloudIntf: EncloudIntf
@GetMapping("/v2")
fun getCoursewareInfo(@PathVariable("id") id: String){
encloudIntf.getm1()
}
}
kotlin还提供了一个方法,可以查看一个延迟初始化的属性是否已经初始化过,如:
if(!::test1.isInitialized){
test1 = HelloWorld()
}
代码的意思是,如果还没初始化,就初始化一个HellWorld类给它
2、接口
接口的定义和Java中就基本一致了,都是由interface关键字修饰的。如:
interface Behavior {
fun walk()
}
class Person(val name: String): Behavior {
override fun walk() {
// walk
}
// ...
}
和Java不同的是,kotlin的接口拥有了部分抽象类的特性,比如接口的方法可以有默认实现,也可以有属性,如:
interface Behavior {
// 接口内的可以有属性
val canWalk: Boolean
// 接口方法的默认实现
fun walk() {
if (canWalk) {
// do something
}
}
}
class Person(val name: String): Behavior {
// 重写接口的属性
override val canWalk: Boolean
get() = true
}
可能有人会觉得,jdk1.8之后也引入了类似的特性,但是kotlin可是兼容了jdk1.6的。为了实现这个特性,kotlin编译器肯定做出了什么独特的转换,这也意味着,这种特性必然有一定的局限性。我个人猜测kotlin的接口在jdk1.8以下的版本会和抽象类本身有一定的交互(甚至是直接转换为抽象类),这里不过多深究。
补充一个特殊的接口,函数式接口,和jdk8引入的函数式接口基本上是一样的:
fun interface IntPredicate {
fun accept(i: Int): Boolean
}
函数式接口的优点也和Java差不多,就是实现匿名内部类的时候很方便,如果不用sam转换的话:
var test = object:InterfaceTest{
override fun accept(i:Int):Boolean{
return i%2==0
}
}
使用sam转化的话就很简单了:
var test = InterfaceTest{it%2==0}
3、类的嵌套
Java中的内部类分为两种,静态内部类和普通内部类,其中静态内部类无法访问非静态外部类的属性。kotlin中也有这样的概念。
看一段代码:
class A {
val name: String = ""
fun foo() = 1
class B {
val a = name // 报错
val b = foo() // 报错
}
}
如果只是简单的class定义内部类的话,是无法访问外部类的属性的。这就相当于Java的静态内部类了:
// 等价的Java代码如下:
public class A() {
public String name = "";
public int foo() { return 1; }
public static class B {
String a = name) // 报错
int b = foo() // 报错
}
}
如果想要在kotlin中定义普通内部类,则需要给class加上inner关键字作为标识,如:
class A {
val name: String = ""
fun foo() = 1
// 增加了一个关键字
// ↓
inner class B {
val a = name // 通过
val b = foo() // 通过
}
}
Kotlin 的这种设计非常巧妙。
如果你熟悉 Java 开发,你会知道,Java 当中的嵌套类,如果没有 static 关键字的话,它就是一个内部类,这样的内部类是会持有外部类的引用的。可是,这样的设计在 Java 当中会非常容易出现内存泄漏!而大部分 Java 开发者之所以会犯这样的错误,往往只是因为忘记加“static”关键字了。这是一个 Java 开发者默认情况下就容易犯的错。
Kotlin 则反其道而行之,在默认情况下,嵌套类变成了静态内部类,而这种情况下的嵌套类是不会持有外部类引用的。只有当我们真正需要访问外部类成员的时候,我们才会加上 inner 关键字。这样一来,默认情况下,开发者是不会犯错的,只有手动加上 inner 关键字之后,才可能会出现内存泄漏,而当我们加上 inner 之后,其实往往也就能够意识到内存泄漏的风险了。也就是说,Kotlin 这样的设计,就将默认犯错的风险完全抹掉了!
4、数据类
数据类实际上就是只存放数据的类,我的理解是多用于我们Java中经常需要的:常量类等特殊的类。
它的使用方法也很简单,就是创建类的时候加上data关键字就可以了。如:
// 数据类当中,最少要有一个属性
↓
data class Person(val name: String, val age: Int)
在 Kotlin 当中,编译器会为数据类自动生成一些有用的方法。
它们分别是:equals();hashCode();toString();componentN() ;copy()
函数演示:
val tom = Person("Tom", 18)
val jack = Person("Jack", 19)
println(tom.equals(jack)) // 输出:false
println(tom.hashCode()) // 输出:对应的hash code
println(tom.toString()) // 输出:Person(name=Tom, age=18)
val (name, age) = tom // name=Tom, age=18
println("name is $name, age is $age .")
val mike = tom.copy(name = "Mike")
println(mike) // 输出:Person(name=Mike, age=18)
“val (name, age) = tom”这行代码,其实是使用了数据类的解构声明。这种方式,可以让我们快速通过数据类来创建一连串的变量。另外,就是 copy 方法。数据类为我们默认实现了 copy 方法,可以让我们非常方便地在创建一份拷贝的同时,修改某个属性。
5、枚举类和密封类
先看枚举类,kotlin的枚举类和Java的枚举基本上也是一样的。如:
enum class Human {
MAN, WOMAN
}
fun isMan(data: Human) = when(data) {
Human.MAN -> true
Human.WOMAN -> false
// 这里不需要else分支,编译器自动推导出逻辑已完备
}
我们在 when 表达式当中使用枚举时,编译器甚至可以自动帮我们推导出逻辑是否完备。这是枚举的优势。
但是枚举有一定的局限性,那就是枚举的值在内存中始终都是同一个对象引用,如下:
println(Human.MAN == Human.MAN)
println(Human.MAN === Human.MAN)
输出
true
true
比较结构相等和引用相等的时候,返回的都是true。
如果我们希望枚举的值拥有不同的对象引用,那么就需要用到密封类了。
密封类的使用也很简单,值需要加上sealed关键字就可以了,这个单词的意思也是密封的意思。
这里来看一个例子就可以了,这个密封类封装的是网络请求的response。
sealed class Result<out R> {
data class Success<out T>(val data: T, val message: String = "") : Result<T>()
data class Error(val exception: Exception) : Result<Nothing>()
data class Loading(val time: Long = System.currentTimeMillis()) : Result<Nothing>()
}
首先,我们使用 sealed 关键字定义了一个 Result 类,并且它需要一个泛型参数 R,R 前面的 out 我们可以暂时先忽略。
这个密封类,我们是专门用于封装网络请求结果的。可以看到,在 Result 类当中,分别有三个数据类,分别是 Success、Error、Loading。我们将一个网络请求结果也分为了三大类,分别代表请求成功、请求失败、请求中。
这样,当网络请求有结果以后,我们的 UI 展示逻辑就会变得非常简单,也就是非常直白的三个逻辑分支:成功、失败、进行中。我们将其与 Kotlin 协程当中的 when 表达式相结合,就能很好地处理 UI 展示逻辑:如果是 Loading,我们就展示进度条;如果是 Success,我们就展示成功的数据;如果是 Error,我们就展示错误提示框。
fun display(data: Result) = when(data) {
is Result.Success -> displaySuccessUI(data)
is Result.Error -> showErrorMsg(data)
is Result.Loading -> showLoading()
}
由于我们的密封类只有这三种情况,所以我们的 when 表达式不需要 else 分支。可以看到,这样的代码风格,既实现了类似枚举类的逻辑完备性,还完美实现了数据结构的封装。
三、一些小探究
1、数据类和密封类的等价Java代码到底是怎么样的?
我们知道,kotlin和java底层都是基于jvm的,换句话说,无论是kotlin代码还是Java代码都会被翻译成字节码。那么,kotlin独特的数据类和密封类到底会被等价翻译成什么样的Java语言?
这里我给出一个例子来对照看就可以了(说实话,从这里就能看到kotlin的极简性了,kotlin一行代码翻译到Java中到了接近90行代码的程度)
在等价Java代码中,我会给出注释。
kotlin:
data class DataTest(val id:Int,var name:String)
java;
public final class DataTest {
//set和get方法包括类都是final的,也就是不可继承,和我们前面学的一样
private final int id;
//加上非空校验,对应kotlin中的var修饰符
@NotNull
private String name;
public final int getId() {
return this.id;
}
//加上非空校验,对应kotlin中的var修饰符
@NotNull
public final String getName() {
return this.name;
}
public final void setName(@NotNull String var1) {
//这里也加了一层非空校验
Intrinsics.checkParameterIsNotNull(var1, "<set-?>");
this.name = var1;
}
//加上非空校验,对应kotlin中的var修饰符
public DataTest(int id, @NotNull String name) {
//这里也加了一层非空校验
Intrinsics.checkParameterIsNotNull(name, "name");
super();
this.id = id;
this.name = name;
}
public final int component1() {
return this.id;
}
@NotNull
public final String component2() {
return this.name;
}
//复制函数,可以说直接解决了Java的深拷贝问题
@NotNull
public final DataTest copy(int id, @NotNull String name) {
Intrinsics.checkParameterIsNotNull(name, "name");
return new DataTest(id, name);
}
// $FF: synthetic method
public static DataTest copy$default(DataTest var0, int var1, String var2, int var3, Object var4) {
if ((var3 & 1) != 0) {
var1 = var0.id;
}
if ((var3 & 2) != 0) {
var2 = var0.name;
}
return var0.copy(var1, var2);
}
@NotNull
public String toString() {
return "DataTest(id=" + this.id + ", name=" + this.name + ")";
}
public int hashCode() {
int var10000 = Integer.hashCode(this.id) * 31;
String var10001 = this.name;
return var10000 + (var10001 != null ? var10001.hashCode() : 0);
}
public boolean equals(@Nullable Object var1) {
if (this != var1) {
if (var1 instanceof DataTest) {
DataTest var2 = (DataTest)var1;
if (this.id == var2.id && Intrinsics.areEqual(this.name, var2.name)) {
return true;
}
}
return false;
} else {
return true;
}
}
}
再用同样的方法去查看密封类,这里就不贴代码了。查看的方法为:使用idea上面的工具,鼠标放在kotlin上,再点击翻译为kotlin字节码,字节码左上角有个反编译按钮,会翻译成Java代码。
会发现密封类翻译成Java代码居然是一个抽象类,而其中的数据类反编译结果和我们之前看的一样。
2、kotlin真的没有Java中的数据类型吗?
我们以Long类型为例,来翻译一段kotlin代码,看等价的Java代码是怎么样的:
kotlin:
// kotlin 代码
// 用 val 定义可为空、不可为空的Long,并且赋值
val a: Long = 1L
val b: Long? = 2L
// 用 var 定义可为空、不可为空的Long,并且赋值
var c: Long = 3L
var d: Long? = 4L
// 用 var 定义可为空的Long,先赋值,然后改为null
var e: Long? = 5L
e = null
// 用 val 定义可为空的Long,直接赋值null
val f: Long? = null
// 用 var 定义可为空的Long,先赋值null,然后赋值数字
var g: Long? = null
g = 6L
翻译成Java代码为:
long a = 1L;
long b = 2L;
long c = 3L;
long d = 4L;
Long e = 5L;
e = (Long)null;
Long f = (Long)null;
Long g = (Long)null;
g = 6L;
从这个例子可以总结出两个规律:
-
如果变量可能为空,那么就会被翻译成Java的包装类型
-
如果变量不可能为空,那么就会被翻译成Java的基础类型
3、kotlin的接口对应到Java中是什么样的?
我们之前说,kotlin的接口具备Java普通接口不存在的特定,我的猜测是跟抽象类有关,但很可惜我猜错了,事实上也肯定不对,因为类是单继承的,不可能是和抽象类有关。
我们看一段kotlin接口和对应的Java翻译代码:
kotlin:
// Kotlin 代码
interface Behavior {
// 接口内可以有成员属性
val canWalk: Boolean
// 接口方法的默认实现
fun walk() {
if (canWalk) {
println(canWalk)
}
}
}
可以看到有canwalk属性并且walk方法是有默认实现的,翻译成Java代码为:
// 等价的 Java 代码
public interface Behavior {
// 接口属性变成了方法
boolean getCanWalk();
// 方法默认实现消失了
void walk();
// 多了一个静态内部类
public static final class DefaultImpls {
public static void walk(Behavior $this) {
if ($this.getCanWalk()) {
boolean var1 = $this.getCanWalk();
System.out.println(var1);
}
}
}
}
我们能看出来,Kotlin 接口的“默认属性”canWalk,本质上并不是一个真正的属性,当它转换成 Java 以后,就变成了一个普通的接口方法 getCanWalk()。另外,Kotlin 接口的“方法默认实现”,它本质上也没有直接提供实现的代码。对应的,它只是在接口当中定义了一个静态内部类“DefaultImpls”,然后将默认实现的代码放到了静态内部类当中去了。
再看看接口实现的代码有什么不一样的:
kotlin:
// Kotlin 代码
class Man: Behavior {
override val canWalk: Boolean = true
}
java:
// 等价的 Java 代码
public final class Man implements Behavior {
private final boolean canWalk = true;
public boolean getCanWalk() {
// 关键点 ①
return this.canWalk;
}
public void walk() {
// 关键点 ②
Behavior.DefaultImpls.walk(this);
}
}
可以看到,Man 类里的 getCanWalk() 实现了接口当中的方法,从注释①那里我们注意到,getCanWalk() 返回的还是它内部私有的 canWalk 属性,这就跟 Kotlin 当中的逻辑“override val canWalk: Boolean = true”对应上了。
另外,对于 Man 类当中的 walk() 方法,它将执行流程交给了“Behavior.DefaultImpls.walk()”,并将 this 作为参数传了进去。这里的逻辑,就可以跟 Kotlin 接口当中的默认方法逻辑对应上来了。
具体的代码对应分析如下:

箭头①,代表 Kotlin 接口属性,实际上会被当中接口方法来看待。
箭头②,代表 Kotlin 接口默认实现,实际上还是一个普通的方法。
箭头③,代表 Kotlin 接口默认实现的逻辑是被放在 DefaultImpls 当中的,它成了静态内部类当中的一个静态方法 DefaultImpls.walk()。
箭头④,代表 Kotlin 接口的实现类必须要重写接口当中的属性,同时,它仍然还是一个方法。
箭头⑤,即使 Kotlin 里的 Man 类没有实现 walk() 方法,但是从 Java 的角度看,它仍然存在 walk() 方法,并且,walk() 方法将它的执行流程转交给了 DefaultImpls.walk(),并将 this 传入了进去。这样,接口默认方法的逻辑就可以成功执行了。
总结:Kotlin 接口当中的属性,在它被真正实现之前,本质上并不是一个真正的属性。因此,Kotlin 接口当中的属性,它既不能真正存储任何状态,也不能被赋予初始值,因为它本质上还是一个接口方法。
四、object关键字
object关键字一共有三个作用:1、作为匿名内部类 2、简化单例模式的实现 3、作为伴生对象
1、匿名内部类
先看看Java的匿名内部类的实现:
public interface OnClickListener {
void onClick(View v);
}
image.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
gotoPreview();
}
});
因为接口没有实现,所以创建的时候需要实现方法。在看看kotlin,kotlin是使用了object关键字来实现匿名内部类的:
image.setOnClickListener(object: View.OnClickListener {
override fun onClick(v: View?) {
gotoPreview()
}
})
kotlin的匿名内部类还有一个扩展的点,就是可以在可以在继承一个抽象类之外还实现多了接口,如下:
interface A {
fun funA()
}
interface B {
fun funB()
}
abstract class Man {
abstract fun findMan()
}
fun main() {
// 这个匿名内部类,在继承了Man类的同时,还实现了A、B两个接口
val item = object : Man(), A, B{
override fun funA() {
// do something
}
override fun funB() {
// do something
}
override fun findMan() {
// do something
}
}
}
2、单例模式
kotlin中要实现单例模式非常简单,只需要把class换成object就可以了,如:
object UserManager {
fun login() {}
}
这其实是优点方便过头了,Java中要实现单例模式可是非常麻烦的事情。但是kotlin这种方便的单例模式的实现有两个问题:
-
不支持懒加载
-
不支持传参构造单例
3、伴生对象
如果我们在类中使用object定义一个单例对象,那么调用它的方法的时候,就会很像我们Java中的静态方法,如下:
定义:
class Person{
object InnerSingleton(){
fun foo(){
...
}
}
}
调用:
Person.InnerSingleton.foo()
但是实际上,如果我们反编译成Java代码,会发现不是这样的:
public final class Person {
public static final class InnerSingleton {
public static final Person.InnerSingleton INSTANCE;
public final void foo() {}
private InnerSingleton() {}
static {
Person.InnerSingleton var0 = new Person.InnerSingleton();
INSTANCE = var0;
}
}
}
实际上,foo方法并不是静态方法,而是调用一个单例模式的对象的普通方法而已。那么kotlin有没有办法可以构造我们熟悉的静态方法?
在kotlin中,如果我们希望方法是静态的,可以加上一个注解@JvmStatic,如:
class Person {
object InnerSingleton {
@JvmStatic
fun foo() {}
}
}
此时再反编译会发现foo方法就是由static修饰的方法了。
但是访问的时候依然隔了一个单例对象,让人觉得代码不太清爽,有没有可能跟Java一样直接定义静态方法?
这时候就需要伴生对象了,伴生对象的关键字是companion object,如:
class Person {
companion object InnerSingleton {
@JvmStatic
fun foo() {}
}
}
其实伴生对象是嵌套单例对象的一种特殊情况。
在伴生对象的内部,如果存在“@JvmStatic”修饰的方法或属性,它会被挪到伴生对象外部的类当中,变成静态成员。不止如此,val变量也会被挪到伴生对象的外部类当中,作为静态变量
上面的代码反编译成Java代码如下:
public final class Person {
public static final Person.InnerSingleton InnerSingleton = new Person.InnerSingleton((DefaultConstructorMarker)null);
// 注意这里
public static final void foo() {
InnerSingleton.foo();
}
public static final class InnerSingleton {
public final void foo() {}
private InnerSingleton() {}
public InnerSingleton(DefaultConstructorMarker $constructor_marker) {
this();
}
}
}
可以说:嵌套单例,是 object 单例的一种特殊情况;伴生对象,是嵌套单例的一种特殊情况。
4、kotlin的另外几种单例模式实现方式
- 借助kotlin自带的懒加载委托
这是一种折中的方法,就是把内部属性用by lazy块给包起来,这样就能得到一部分懒加载的效果。
使用也很简单,如下:
object UserManager {
// 对外暴露的 user
val user by lazy { loadUser() }
private fun loadUser(): User {
// 从网络或者数据库加载数据
return User.create("tom")
}
fun login() {}
}
- 双重检查
这个其实是模仿Java的写法的。
class UserManager private constructor(name: String) {
companion object {
@Volatile private var INSTANCE: UserManager? = null
fun getInstance(name: String): UserManager =
// 第一次判空
INSTANCE?: synchronized(this) {
// 第二次判空
INSTANCE?:UserManager(name).also { INSTANCE = it }
}
}
}
// 使用
UserManager.getInstance("Tom")
这种写法,真正实现了UserManager的懒加载,Volatile注解实现了可见性,而synchronized关键字实现了原子性。所以这种写法是线程安全的。
- 对双重检查的封装
这里先不写,后面补上
五、扩展
1、扩展是什么
扩展本质上就是官方帮我们规定好工具类或者工具方法的定义。
比如我们想为String这个基类多创建一个方法,这在Java中我们是难以直接往第三方类中插入方法的,所以我们一般采取的策略是创建一个xxxutils工具类,来间接实现一些功能。而kotlin的设计者看到了这种使用习惯,做出了新特性的改进。
下面由一个例子来举例。
比如我想实现一个功能,获取String的最后一个元素的方法,那么在kotlin中是这么做的:
// Ext.kt
package com.boycoder.chapter06
/*
① ② ③ ④
↓ ↓ ↓ ↓ */
fun String.lastElement(): Char? {
// ⑤
// ↓
if (this.isEmpty()) {
return null
}
return this[length - 1]
}
// 使用扩展函数
fun main() {
val msg = "Hello Wolrd"
// lastElement就像String的成员方法一样可以直接调用
val last = msg.lastElement() // last = d
}
我们先是定义了一个 String 的扩展函数“lastElement()”,然后在 main 函数当中调用了这个函数。并且,这个扩展函数是直接定义在 Kotlin 文件里的,而不是定义在某个类当中的。这种扩展函数,我们称之为“顶层扩展”,这么叫它是因为它并没有嵌套在任何的类当中,它自身就在最外层。
-
注释①,fun关键字,代表我们要定义一个函数。也就是说,不管是定义普通 Kotlin 函数,还是定义扩展函数,我们都需要 fun 关键字。
-
注释②,“String.”,代表我们的扩展函数是为 String 这个类定义的。在 Kotlin 当中,它有一个名字,叫做接收者(Receiver),也就是扩展函数的接收方。
-
注释③,lastElement(),是我们定义的扩展函数的名称。
-
注释④,“Char?”,代表扩展函数的返回值是可能为空的 Char 类型。
-
注释⑤,“this.”,代表“具体的 String 对象”,当我们调用 msg.lastElement() 的时候,this 就代表了 msg。
可以把kotlin代码反编译成Java代码,看看jvm是这么理解的:
public final class ExtKt {
public static final Character lastElement(String $this) {
CharSequence var1 = (CharSequence)$this;
if (var1.length() == 0) {
return null
}
return var1.charAt(var1.length() - 1);
}
}
public static final void main() {
String msg = "Hello Wolrd";
Character last = ExtKt.lastElement(msg);
}
可以看到,其实就是封装成一个静态工具函数而已,调用也是我们以前Java工具类的调用,只是从kotlin语法层面来说,看起来很像是直接给String加了一个方法。
扩展属性和扩展函数其实差不多,如下:
// 接收者类型
// ↓
val String.lastElement: Char?
get() = if (isEmpty()) {
null
} else {
get(length - 1)
}
fun main() {
val msg = "Hello Wolrd"
// lastElement就像String的成员属性一样可以直接调用
val last = msg.lastElement // last = d
}
翻译成Java代码也是一模一样的。
扩展的最大作用就是代替我们之前Java代码的工具类用法。
2、扩展的局限
-
kotlin的扩展不是真正的成员变量,无法被子类重写,因为本质上它是另一个类的成员变量。
-
扩展属性无法存储状态,因为它是取决于对象来取值的。
-
扩展可以访问的范围:
-
如果扩展是顶层的扩展,那么扩展的访问域仅限于该 Kotlin 文件当中的所有成员,以及被扩展类型的公开成员,这种方式定义的扩展是可以被全局使用的。
-
如果扩展是被定义在某个类当中的,那么该扩展的访问域仅限于该类当中的所有成员,以及被扩展类型的公开成员,这种方式定义的扩展仅能在该类当中使用。
3、扩展的使用
-
主动使用扩展,通过它来优化软件架构。
- 对复杂的类进行职责划分,关注点分离。让类的核心尽量简单易懂,而让类的功能性属性与方法以扩展的形式存在于类的外部。比如官方的String.kt与Strings.kt,String.kt这个类,只关注 String 的核心逻辑;而Strings.kt则只关注 String 的操作符逻辑。
-
被动使用扩展,提升可读性与开发效率。
- 当我们无法修改外部的 SDK 时,对于重复的代码模式,我们将其以扩展的方式封装起来,提供给对应的接收者类型,比如 view.updateMargin()。
六、高阶函数
1、函数类型
在kotlin的概念里面,函数是由类型的,比如:
fun add(a: Int, b: Int): Float { return (a+b).toFloat() }
其中的(Int, Int) ->Float就是这个函数的函数类型。
不止如此,函数也是可以作为被引用了,如:
// 函数赋值给变量 函数引用
// ↑ ↑
val function: (Int, Int) -> Float = ::add
这个引用就等于是这个函数,可以直接调用:
fun main() {
println(func(1,2))
}
val func:(Int,Int)->Int = ::add
fun add(i: Int, j: Int): Int {
return i+j
}
//输出3
2、高阶函数
所谓高阶函数就是把函数作为参数或者返回值的函数,如:
// 函数作为参数的高阶函数
// ↓
fun setOnClickListener(l: (Int) -> Unit) { ... }
具体用法,就结合项目看吧,用到的地方不是很多。
3、带接收者的高阶函数
形如:
// 带接收者的函数类型
// ↓
fun User.apply(block: User.() -> Unit): User{
// 不用再传this
// ↓
block()
return this
}
user?.apply { this: User ->
// this 可以省略
// ↓
username.text = this.name
website.text = this.blog
image.setOnClickListener { gotoImagePreviewActivity(this) }
}
因为实战里用的不多,笔者在这里没有深究。先跳过。
4、inline关键字
inline关键字一般用于高阶函数的定义。
它能提高高阶函数的效率,底层原理是把函数相关的代码拷贝到执行处,而不是通过匿名内部类。
通过一段简单的代码来理解:
没有inline的情况:
// HigherOrderExample.kt
fun foo(block: () -> Unit) {
block()
}
fun main() {
var i = 0
foo{
i++
}
}
翻译成Java代码:
public final class HigherOrderExampleKt {
public static final void foo(Function0 block) {
block.invoke();
}
public static final void main() {
int i = 0
foo((Function0)(new Function0() {
public final void invoke() {
i++;
}
}));
}
}
可以看到,这里是引入了一个叫Function0的接口,然后执行的时候是实现一个匿名内部类。Function0接口是kotlin的标准接口,意思是一个没有参数的函数类型,空调林中有Function0-Function22,总共23个接口,也就是最多22个参数。
加了inline后:
// HigherOrderInlineExample.kt
/*
多了一个关键字
↓ */
inline fun fooInline(block: () -> Unit) {
block()
}
fun main() {
var i = 0
fooInline{
i++
}
}
翻译成Java语言:
public final class HigherOrderInlineExampleKt {
// 没有变化
public static final void fooInline(Function0 block) {
block.invoke();
}
public static final void main() {
// 差别在这里
int i = 0;
int i = i + 1;
}
}
可以看到,inline的作用就是把匿名实现类重写的方法中真正实行的代码给拷贝到执行的地方直接执行。
官方建议inline只能在高阶函数使用,而且由于高阶函数的原理本身是拷贝的原理,所以如果函数体有无法外部访问的属性或者方法的话,就无法使用inline了。(而且因为kotlin自身是不携带反射功能的,所以也没办法通过反射拿到数据)
七、委托
1、委托类
直接看例子:
interface DB {
fun save()
}
class SqlDB() : DB {
override fun save() { println("save to sql") }
}
class GreenDaoDB() : DB {
override fun save() { println("save to GreenDao") }
}
// 参数 通过 by 将接口实现委托给 db
// ↓ ↓
class UniversalDB(db: DB) : DB by db
fun main() {
UniversalDB(SqlDB()).save()
UniversalDB(GreenDaoDB()).save()
}
/*
输出:
save to sql
save to GreenDao
*/
可以看到,UniversalDB类实现了DB接口,但是它却并不去实现这个接口,而是把接口的实现委托给参数db,具体接口是如何实现的只与传入的参数db所属的类是怎么实现的有关。
翻译成Java代码也很好理解,就是实现的方法里面,调用了传入参数的相应方法而已:
class UniversalDB implements DB {
DB db;
public UniversalDB(DB db) { this.db = db; }
// 手动重写接口,将 save 委托给 db.save()
@Override// ↓
public void save() { db.save(); }
}
2、委托属性
委托属性分五种:两个属性之间的直接委托、by lazy 懒加载委托、Delegates.observable 观察者委托、by map 映射委托、自定义委托。一般常用的是前两种,这里也只介绍前两种以及自定义委托。
2.1、两属性直接委托
直接看例子:
class Item {
var count: Int = 0
// ① ②
// ↓ ↓
var total: Int by ::count
}
注释①,代表 total 属性的 getter、setter 会被委托出去;注释②,::count,代表 total 被委托给了 count。这里的“::count”是属性的引用
这个时候,total的get方法就已经被委托给了count来实现了,看底层逻辑大概是这样的:
// 近似逻辑,实际上,底层会生成一个Item$total$2类型的delegate来实现
class Item {
var count: Int = 0
var total: Int
get() = count
set(value: Int) {
count = value
}
}
这种委托属性其实让人有点摸不着头脑,为什么非要有两个不一样名字但是相同意义的变量呢。
其实它的主要作用是用于软件版本之间的兼容。
比如1.0版本的时候,只有count这个变量,但是在2.0的时候,我们需要把count变量换成total变量。虽然可以直接换,但是老版本的用户可能就没办法共用这一套代码了,但是这样通过委托机制之后,就可以多版本兼容了。
2.2、懒加载委托
懒加载,顾名思义,就是对于一些需要消耗计算机资源的操作,我们希望它在被访问的时候才去触发,从而避免不必要的资源开销。
看一个懒加载的例子:
// 定义懒加载委托
// ↓ ↓
val data: String by lazy {
request()
}
fun request(): String {
println("执行网络请求")
return "网络数据"
}
fun main() {
println("开始")
println(data)
println(data)
}
结果:
开始
执行网络请求
网络数据
网络数据
分析:通过“by lazy{}”,我们就可以实现属性的懒加载了。这样,通过上面的执行结果我们会发现:main() 函数的第一行代码,由于没有用到 data,所以 request() 函数也不会被调用。到了第二行代码,我们要用到 data 的时候,request() 才会被触发执行。到了第三行代码,由于前面我们已经知道了 data 的值,因此也不必重复计算,直接返回结果即可。
并且,去看懒加载的源码,会发现kotlin的懒加载默认是线程安全的:
public actual fun lazy(initializer: () -> T): Lazy = SynchronizedLazyImpl(initializer)
并且可以选择其他懒加载方式:
public actual fun <T> lazy(mode: LazyThreadSafetyMode, initializer: () -> T): Lazy<T> =
when (mode) {
LazyThreadSafetyMode.SYNCHRONIZED -> SynchronizedLazyImpl(initializer)
LazyThreadSafetyMode.PUBLICATION -> SafePublicationLazyImpl(initializer)
LazyThreadSafetyMode.NONE -> UnsafeLazyImpl(initializer)
}
注:实践发现,只有val类型可以懒加载。
2.3、自定义委托
自定义委托只要符合kotlin的规定就可以了,如:
class StringDelegate(private var s: String = "Hello") {
// ① ② ③
// ↓ ↓ ↓
operator fun getValue(thisRef: Owner, property: KProperty<*>): String {
return s
}
// ① ② ③
// ↓ ↓ ↓
operator fun setValue(thisRef: Owner, property: KProperty<*>, value: String) {
s = value
}
}
// ②
// ↓
class Owner {
// ③
// ↓
var text: String by StringDelegate()
}
-
首先,看到两处注释①对应的代码,对于 var 修饰的属性,我们必须要有 getValue、setValue 这两个方法,同时,这两个方法必须有 operator 关键字修饰。
-
其次,看到三处注释②对应的代码,我们的 text 属性是处于 Owner 这个类当中的,因此 getValue、setValue 这两个方法中的 thisRef 的类型,必须要是 Owner,或者是 Owner 的父类。也就是说,我们将 thisRef 的类型改为 Any 也是可以的。一般来说,这三处的类型是一致的,当我们不确定委托属性会处于哪个类的时候,就可以将 thisRef 的类型定义为“Any?”。
-
最后,看到三处注释③对应的代码,由于我们的 text 属性是 String 类型的,为了实现对它的委托,getValue 的返回值类型,以及 setValue 的参数类型,都必须是 String 类型或者是它的父类。大部分情况下,这三处的类型都应该是一致的。
kotlin也有实现好的两个接口供使用:ReadOnlyProperty和ReadWriteProperty,第一个接口用于val属性的委托,第二个接口用于var属性的委托。
八、泛型
1、基本的泛型
基本泛型其实很简单,和Java常用的泛型是一模一样的,如下:
// T代表泛型的形参
// ↓
class Controller<T> {
fun turnOn(tv: T) {}
fun turnOff(tv: T) {}
}
fun main() {
// 泛型的实参
// ↓
val mi1Controller = Controller<XiaoMiTV1>()
mi1Controller.turnOn()
// 泛型的实参
// ↓
val mi2Controller = Controller<XiaoMiTV2>()
mi2Controller.turnOn()
}
kotlin的泛型也可以设置上届,也就是传入的参数是该类的子类中的一员就可以了。
// 差别在这里
// ↓
class Controller<T: TV> {
fun turnOn(tv: T) {}
fun turnOff(tv: T) {}
}
泛型的局限:泛型解决的是不变性问题。因为编译器认为泛型父子类是没有关系的(这里指普通泛型)。
2、逆变
逆变其实相当于Java泛型中的super关键字的作用,逆变的关键字是in,也就是这个类的所有父类都可以当成它来使用
有两种用法:
第一种做法,是修改泛型参数的使用处代码,它叫做使用处型变。具体做法就是修改 buy 函数的声明,在定义的方法的泛型前面增加一个 in 关键字:
// 变化在这里
// ↓
fun buy(controller: Controller<in XiaoMiTV1>) {
val xiaoMiTV1 = XiaoMiTV1()
// 打开小米电视1
controller.turnOn(xiaoMiTV1)
}
第二种做法,是修改 类 的源代码,这叫声明处型变。具体做法就是,在泛型形参 T 的前面增加一个关键字 in:
// 变化在这里
// ↓
class Controller<in T> {
fun turnOn(tv: T)
}
3、协变
协变其实相当于Java泛型中的extends关键字的作用,逆变的关键字是out,也就是这个类的所有子类都可以当成它来使用
也有两种用法,和逆变对应:
第一种做法,还是修改泛型参数的使用处,也就是使用处型变。具体的做法就是修改 orderFood() 函数的声明,在 Food 的前面增加一个 out 关键字:
// 变化在这里
// ↓
fun orderFood(restaurant: Restaurant<out Food>) {
// 从这家饭店,点一份外卖
val food = restaurant.orderFood()
}
第二种做法,是修改 Restaurant 的源代码,也就是声明处型变。具体做法就是,在它泛型形参 T 的前面增加一个关键字 out:
// 变化在这里
// ↓
class Restaurant<out T> {
fun orderFood(): T { /*..*/ }
}
和Java的对比:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g6a2ybmp-1669857643515)(file:///Users/geekxf/Library/Application%20Support/marktext/images/2022-10-18-09-34-31-image.png?msec=1669857608258)]
简单来说:
Java中的协变:<? extends T> Java中的逆变:<? super Object> Java中的“星投影”:<?>
4、星投影
其实就是一个*符号而已。
它的作用是,让泛型扩大到一定范围,比如:
class Restaurant<out T> {
fun orderFood(): T {}
}
// 把星号作为泛型实参
// ↓
fun findRestaurant(): Restaurant<*> {}
fun main() {
val restaurant = findRestaurant()
// 注意这里
val food: Any? = restaurant.orderFood() // 返回值可能是:任意类型
}
此时任何参数都可以作为泛型实参。
如果想要增加限制的话,可以这么做:
// 区别在这里
// ↓
class Restaurant<out T: Food> {
fun orderFood(): T {}
}
fun findRestaurant(): Restaurant<*> {}
fun main() {
val restaurant = findRestaurant()
// 注意这里
// ↓
val food: Food = restaurant.orderFood() // 返回值是:Food或其子类
}
这样就多了一个上界限制了。
5、逆变和协变的使用
in和out其实就对应了他们的使用。
逆变in,一般是作为参数的意思;同样的,协变的out,通常则作为返回值。
九、注解和反射
注解和Java基本一致,只看如何定义即可,主要是反射,定义:
@Target(CLASS, FUNCTION, PROPERTY, ANNOTATION_CLASS, CONSTRUCTOR, PROPERTY_SETTER, PROPERTY_GETTER, TYPEALIAS)
@MustBeDocumented
public annotation class Deprecated(
val message: String,
val replaceWith: ReplaceWith = ReplaceWith(""),
val level: DeprecationLevel = DeprecationLevel.WARNING
)
1、反射的引入
kotlin的反射和Java不一样,kotlin需要引入反射包。目的可能是为了在不使用反射的时候为项目减重。
依赖:
<dependency>
<groupId>org.jetbrains.kotlin</groupId>
<artifactId>kotlin-reflect</artifactId>
<version>${kotlin.version}</version>
</dependency>
2、反射的作用
反射其实和人类的反省机制是差不多的
- 人类可以反省自己当前的状态,比如说,我们随时可以知道自己是不是困了。而在 Kotlin 当中,程序可以通过反射来检查代码自身的状态,比如说,判断某个变量,它是不是可变的。
总结:感知程序的状态,包含程序的运行状态,还有源代码结构
- 人类反省自己的状态以后,还可以主动改变自己的状态。比如说,困了就休息一会儿、饿了就吃饭、渴了就喝点水。而在 Kotlin 当中,我们可以在运行时,用反射来查看变量的值是否符合预期,如果不符合预期,我们就可以动态修改这个变量的值,即使这个变量是 private 的甚至是 final 的。
总结:修改程序的状态;
- 人类可以根据状态作出不同的决策。比如说,上班的路上,如果快迟到了,我们就会走快点,如果时间很充足,就可以走慢一点。而在程序世界里,JSON 解析经常会用到 @SerializedName 这个注解,如果属性有 @SerializedName 修饰的话,它就以指定的名称为准,如果没有,那就直接使用属性的名称来解析。
总结:根据程序的状态,调整自身的决策行为。
3、反射相关用法和常见反射类和api
举例:
fun readMembers(obj: Any) {
obj::class.memberProperties.forEach {
println("${obj::class.simpleName}.${it.name}=${it.getter.call(obj)}")
}
}
obj::class,这是 Kotlin 反射的语法,我们叫做类引用,通过这样的语法,我们就可以读取一个变量的“类型信息”,并且就能拿到这个变量的类型,它的类型是 KClass。
KClass 其实就代表了一个 Kotlin 类,通过 obj::class,我们就可以拿到这个类型的所有信息,比如说,类的名称“obj::class.simpleName”。而如果要获取类的所有成员属性,我们访问它的扩展属性 memberProperties 就可以了。
常用的反射类和api:KClass、KCallable、KParameter、KType
KClass 代表了一个 Kotlin 的类,下面是它的重要成员:

KCallable 代表了 Kotlin 当中的所有可调用的元素,比如函数、属性、甚至是构造函数。下面是 KCallable 的重要成员:

KParameter,代表了KCallable当中的参数,它的重要成员如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b161Josr-1669857643516)(file:///Users/geekxf/Library/Application%20Support/marktext/images/2022-10-18-10-46-43-image.png?msec=1669857607998)]](https://img-blog.csdnimg.cn/23c4cee556f144379fddd2549c9a04cb.png)
KType,代表了 Kotlin 当中的类型,它重要的成员如下:

协程部分尽请期待。
![[附源码]Python计算机毕业设计Django的手机电商网站](https://img-blog.csdnimg.cn/c4f36cc670764085ba60959b46f65752.png)
![[附源码]计算机毕业设计springboot农村人居环境治理监管系统](https://img-blog.csdnimg.cn/11a4eefc2f9342abba3ed22ef0cecbc4.png)



![[附源码]计算机毕业设计springboot教学辅助系统](https://img-blog.csdnimg.cn/a860bd685bed4b688da5b6e750cd936a.png)
![[附源码]Python计算机毕业设计Django的云网盘设计](https://img-blog.csdnimg.cn/3b68ae5815ce4bd98aa7696876217abf.png)




![[附源码]SSM计算机毕业设计疫情背景下社区公共卫生服务系统JAVA](https://img-blog.csdnimg.cn/559bbcf560594e9b8dfce4fe984b928f.png)
![[附源码]Python计算机毕业设计SSM辽宁省高考志愿智能辅助填报系统(程序+LW)](https://img-blog.csdnimg.cn/9e23f1d4d61542df9199272612322f01.png)



![[附源码]Python计算机毕业设计SSM课堂考勤(程序+LW)](https://img-blog.csdnimg.cn/dd4523b3cec64af69f9502f5c559abab.png)