实验介绍
在上一篇文章中,作者通过给Alder Lake(12th gen i5 1240p)安装Ubuntu22.04,终于把PMU用起来了
$ dmesg | grep PMU
[ 0.127326] Performance Events: XSAVE Architectural LBR, PEBS fmt4+-baseline, AnyThread deprecated, Alderlake Hybrid events, 32-deep LBR, full-width counters, Intel PMU driver.
[ 0.127326] core: cpu_core PMU driver:
[ 0.127326] NMI watchdog: Enabled. Permanently consumes one hw-PMU counter.
[ 0.019855] core: cpu_atom PMU driver: PEBS-via-PT
[ 4.096409] RAPL PMU: API unit is 2^-32 Joules, 4 fixed counters, 655360 ms ovfl timer
[ 4.096413] RAPL PMU: hw unit of domain pp0-core 2^-14 Joules
[ 4.096414] RAPL PMU: hw unit of domain package 2^-14 Joules
[ 4.096415] RAPL PMU: hw unit of domain pp1-gpu 2^-14 Joules
[ 4.096416] RAPL PMU: hw unit of domain psys 2^-14 Joules
先来简单实验一下,检验一下CPU的分支预测功能。
在实验前,先要有一个给定预期的程序,于是,我就写了一个死循环,如下所示
int main()
{
while (1);
return 0;
}
命名为dead_loop.c
$ gcc -g -O0 dead_loop.c -o dead_loop
$ ./dead_loop
$ ps -ef | grep dead_loop #查看进程ID
$ perf stat -p [dead_loop的进程ID]
Performance counter stats for process id '9177':
12,727.43 msec task-clock # 1.000 CPUs utilized
168 context-switches # 13.200 /sec
24 cpu-migrations # 1.886 /sec
0 page-faults # 0.000 /sec
55,753,235,526 cpu_core/cycles/ # 4.381 G/sec
<not counted> cpu_atom/cycles/ (0.00%)
130,101,578,945 cpu_core/instructions/ # 10.222 G/sec
<not counted> cpu_atom/instructions/ (0.00%)
130,082,139,921 cpu_core/branches/ # 10.221 G/sec
<not counted> cpu_atom/branches/ (0.00%)
17,389 cpu_core/branch-misses/ # 1.366 K/sec
<not counted> cpu_atom/branch-misses/ (0.00%)
12.730348071 seconds time elapsed
这里有两个数据值得关注一下:
(1)cpu_core/instructions为什么是10G/sec
(2)cpu_core/branch-misses为什么不是0
两个疑问
每秒指令数为什么有10G,而运行时频率只有4302.811 MHz
这里就涉及到IPC(Instructions Per Cycle)了,再看一下我们的程序执行的指令
$ objdump -S dead_loop

CPU(准确讲应该是CPU的某一个核)其实一直在疯狂的执行这条jmp指令。也就是说执行jmp的时候,IPC大约是2
IPC为什么会大于1
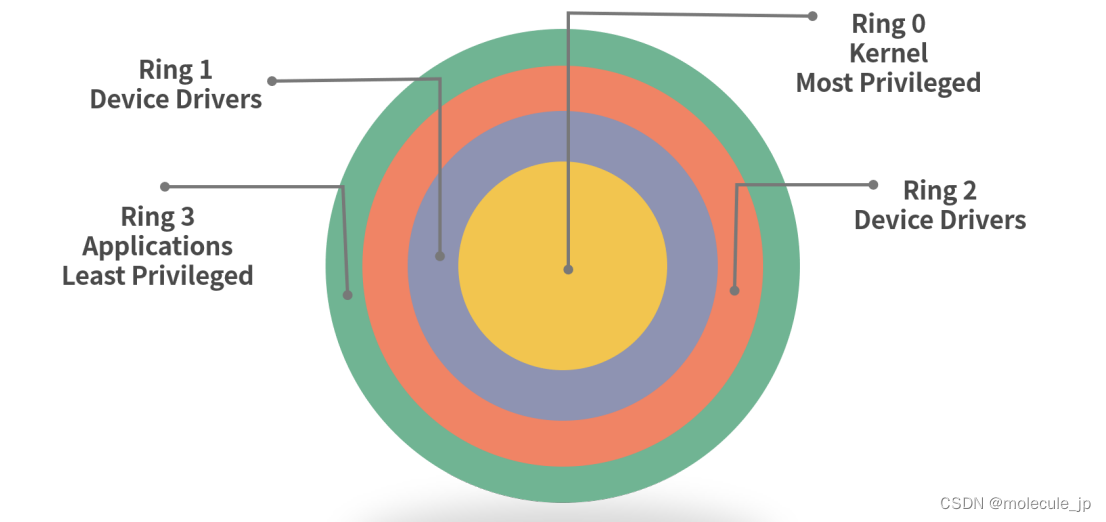
为此,笔者找到了一篇参考文献[1],其中讲到超标量处理,如下图所示
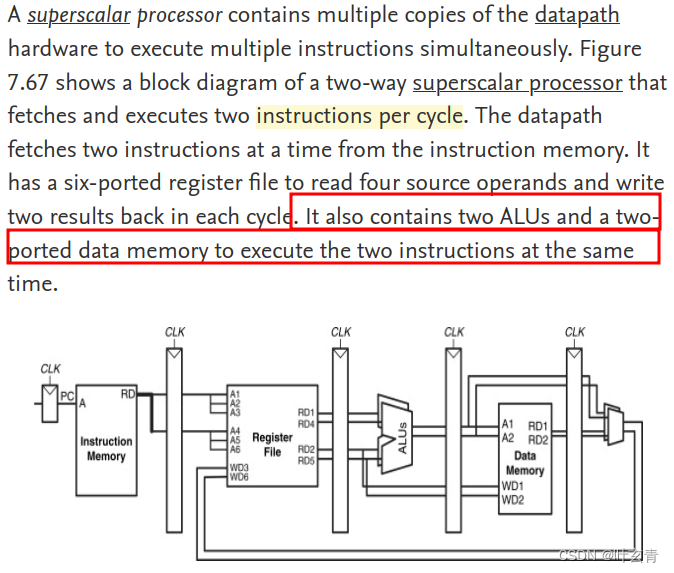
有两个ALU,配合对应的register file结构,在1个时钟周期中能执行2条指令。这也是为什么笔者这款处理器出现每秒10G指令数的原因。
为什么会有分支预测失败
按理说,这个程序都没有分支跳转,哪里来的分支预测失败呢?突然想到,上面报的分支预测可能是内核态导致的,于是试验了一下
$ perf stat -e branch-misses:u -p [dead_loop的PID] #这次PID是20910
Performance counter stats for process id '20910':
0 cpu_core/branch-misses:u/ (100.00%)
0 cpu_atom/branch-misses:u/ (0.00%)
26.299047205 seconds time elapsed
和预期的一样,branch-misses成为0了。再看看内核态的分支预测miss数
$ perf stat -e branch-misses:u -p 20910
Performance counter stats for process id '20910':
5,670 cpu_core/branch-misses:k/
<not counted> cpu_atom/branch-misses:k/ (0.00%)
6.563240004 seconds time elapsed
和预期一样,果然是内核态导致了分支预测失败
参考文献
[1] https://www.sciencedirect.com/topics/computer-science/instructions-per-cycle