rest_framework视图使用
- CreateAPIView---单独执行post上传逻辑
- views.py
- user_serializers.py
CreateAPIView—单独执行post上传逻辑
基本逻辑:
① 准备视图函数类
② 准备序列化器类 (其中可以自定义如何序列化数据、序列化哪些数据,以及如何自定义验证数据方式 和 创建方式)
③ 在视图函数中指定序列化器类
views.py
from rest_framework.generics import CreateAPIView
from user.user_serializers import CreateUserSerializer
# Create your views here.
class UserRegisterView(CreateAPIView):
"""用户注册"""
# 使用 CreateAPIView 在序列化器设置后 直接自动调用序列后的数据进行保存
serializer_class = CreateUserSerializer
user_serializers.py
① 如果是对原来model模型中的字段进行验证的话,序列化器可以继承
serializers.ModelSerializer,会自动对原字段进行格式检验,这就够了,但也仅仅限于每个字段的单独的格式。
一般的数据验证完格式就可以了,但是有的敏感数据还是需要进一步验证则可以看后续序号234…
from rest_framework import serializers
from .models import User
class CreateUserSerializer(serializers.ModelSerializer):
"""用户注册提交信息的验证序列化器"""
class Meta:
model = User # 代表使用哪个模型类做校验
# 代表对那些字段做校验 默认是全部 或者传入 ’__all__‘ 也是指全部
fields = ('id', 'username', 'password', 'verifi_code', 'phone_number')
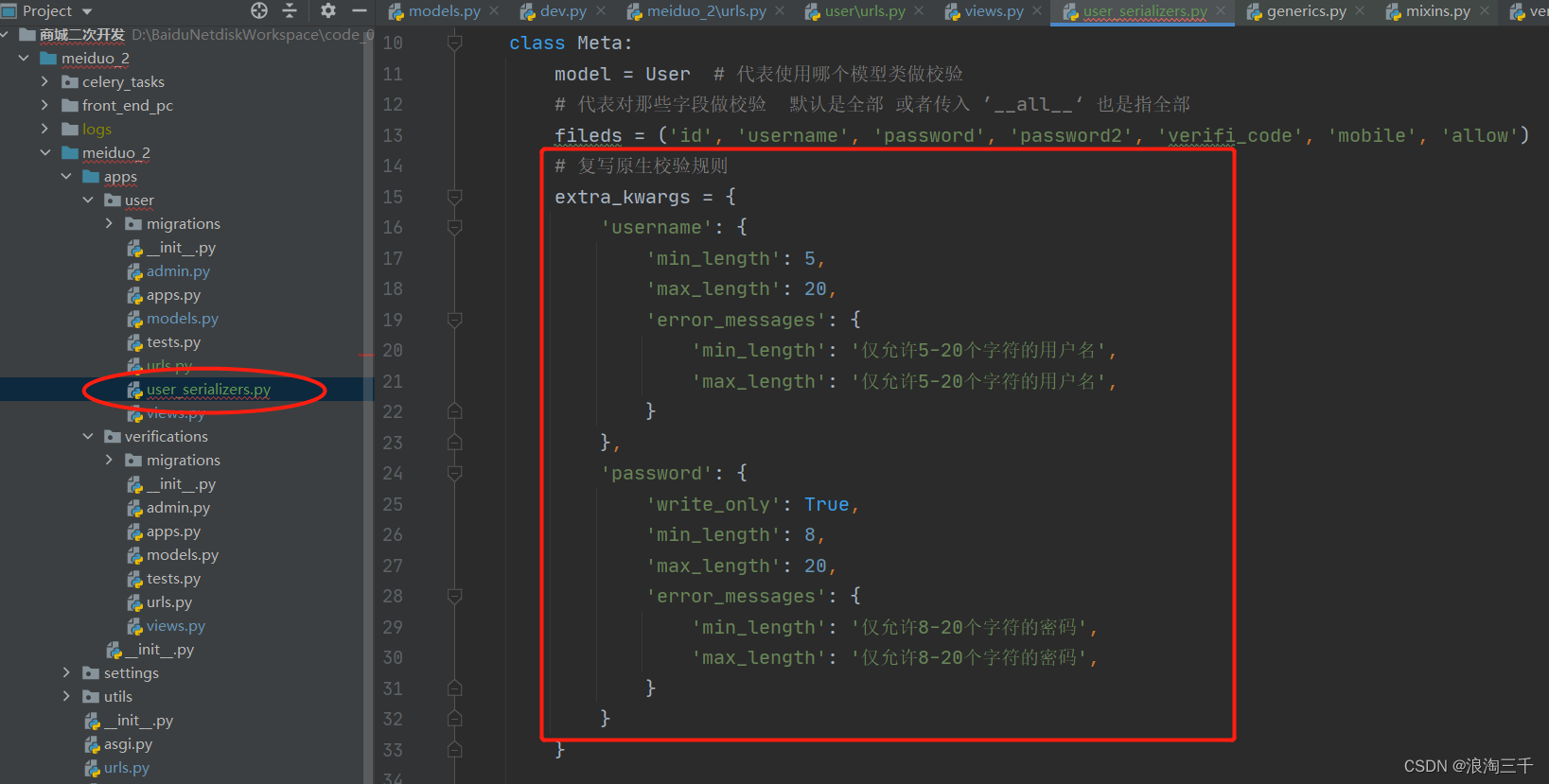
②如果不想使用原生定义的model校验规则(比如默认的username 校验规则里可以用100多个字符,这是不理想的,我们可以使用 extra_kwargs 自定义校验规则,如下)
from rest_framework import serializers
from .models import User
class CreateUserSerializer(serializers.ModelSerializer):
"""用户注册提交信息的验证序列化器"""
class Meta:
model = User # 代表使用哪个模型类做校验
# 代表对那些字段做校验 默认是全部 或者传入 ’__all__‘ 也是指全部
fields = ('id', 'username', 'password', 'verifi_code', 'phone_number')
# 复写原生校验规则
extra_kwargs = {
'username': {
'min_length': 5,
'max_length': 20,
'error_messages': {
'min_length': '仅允许5-20个字符的用户名',
'max_length': '仅允许5-20个字符的用户名',
}
},
'password': {
'write_only': True,
'min_length': 8,
'max_length': 20,
'error_messages': {
'min_length': '仅允许8-20个字符的密码',
'max_length': '仅允许8-20个字符的密码',
}
}
}
③ 下面代码还额外验证了 三个新的前端提交过来的字段 但是这些并不在model 模型里,只是我们在序列化器里临时创建的,所以校验完后 在操作数据库前,要记得把他们仨从校验规则里删除(本段后文有讲)
from rest_framework import serializers
from .models import User
from django_redis import get_redis_connection
class CreateUserSerializer(serializers.ModelSerializer):
"""用户注册提交信息的验证序列化器"""
# 新增原模型类中没有的字段(因为这些也要被校验)
password_2 = serializers.CharField(label="确认密码",write_only=True)
verifi_code = serializers.CharField(label='验证码',write_only=True)
allow = serializers.CharField(label='同意协议',write_only=True)
class Meta:
model = User # 代表使用哪个模型类做校验
# 代表对那些字段做校验 默认是全部 或者传入 ’__all__‘ 也是指全部
fields = ('id', 'username', 'password', 'password_2', 'verifi_code', 'phone_number', 'allow')
# 复写原生校验规则
extra_kwargs = {
'username': {
'min_length': 5,
'max_length': 20,
'error_messages': {
'min_length': '仅允许5-20个字符的用户名',
'max_length': '仅允许5-20个字符的用户名',
}
},
'password': {
'write_only': True,
'min_length': 8,
'max_length': 20,
'error_messages': {
'min_length': '仅允许8-20个字符的密码',
'max_length': '仅允许8-20个字符的密码',
}
}
}
④ 对于不同字段的逻辑合法性,如果想做进一步单独校验,可以在序列化器里使用半自定义的函数(注:是在序列化器里 不是Meta类里)
验证通过则返回该值 ,不通过则抛出异常
validate_字段名(self,value)
def validate_phone_number(self,value):
"""验证手机号"""
if not re.match(r'^1[3-9]\d{9}$',value):
raise serializers.ValidationError(f'手机号{value}格式错误')
return value
⑤ 如果同时相对多个字段做联合验证 则使用如下方式:
下面同时判断了三个字段 并且连接数据库做了校验
def validate(self,data):
"""判断两次密码的一致性 以及 验证码是否正确 这里写了 就不用再单独往视图函数写了"""
if data['password'] != data['password_2']:
raise serializers.ValidationError(f'两次密码不一致 错误')
# 判断验证码正误
redis_conn = get_redis_connection()
# 获取用户在注册界面时候获取的验证码
real_verifi_code = redis_conn.get(f'sms_{data["email"]}')
if not real_verifi_code:
raise serializers.ValidationError(f'验证码已经过期')
elif real_verifi_code != data["verifi_code"]:
raise serializers.ValidationError(f'验证码错误')
return data
⑥ 默认情况下 serializers.ModelSerializer 序列化器内置了 创建和 更新方法,在校验完毕后 会调用序列化器的 save 方法操作数据库,
如果序列化器是反序列化数据的,则会调用 create 方法;
如果序列化器是序列化数据的,则会调用 update 方法;
如果有需要特殊更改的数据,则可以在save 方法调用前,在序列化器里 覆写 该方法
- Default
.create()and.update()implementations are provided.
比如在创建用户时 他是拿所有验证数据去存的,但是有些验证的数据是我们临时加的,并不需要往数据库存,此时我们可以删掉后再自己存 之后将实例对象返回即可
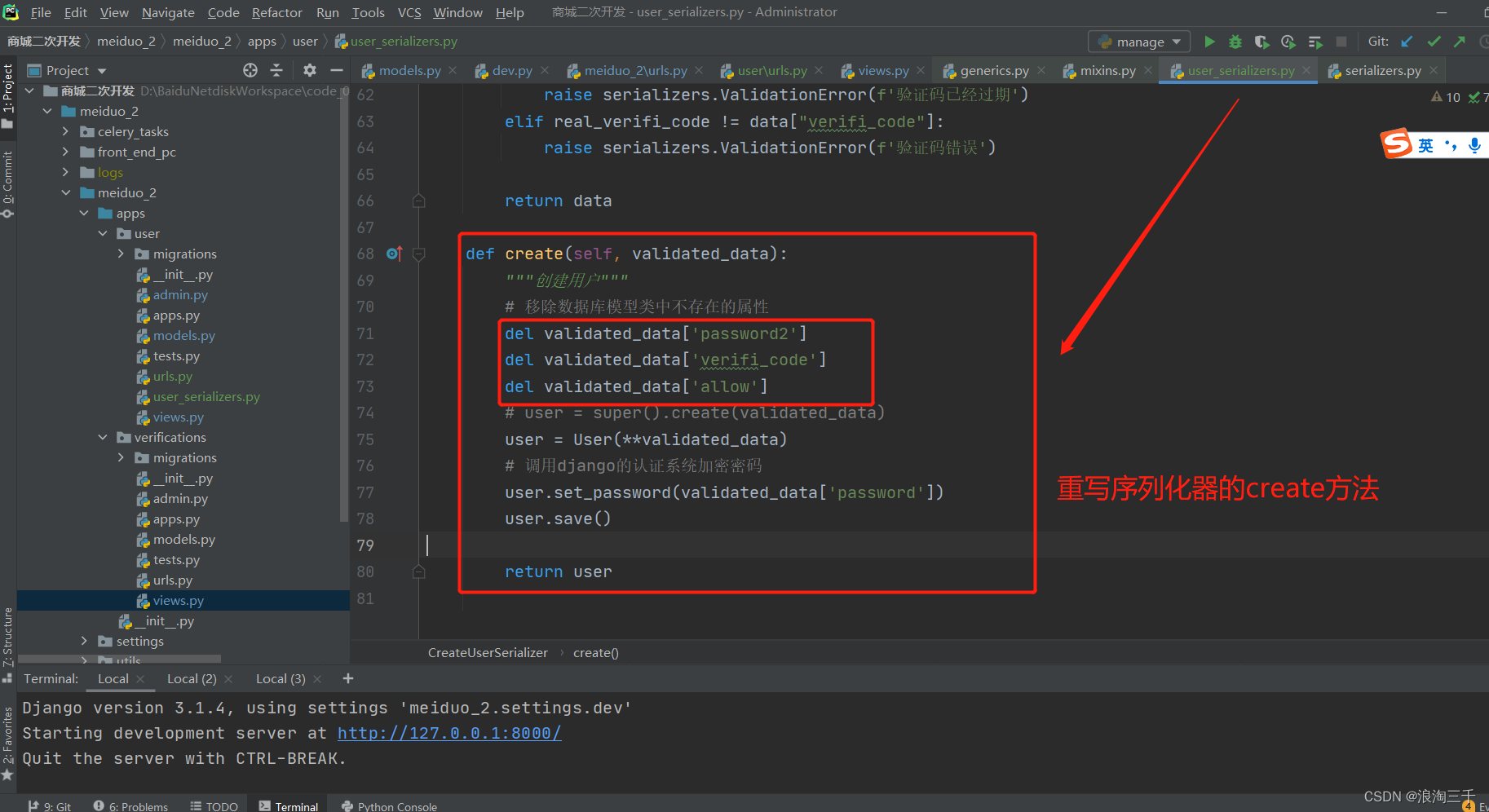
def create(self, validated_data):
"""创建用户"""
# 移除数据库模型类中不存在的属性
del validated_data['password_2']
del validated_data['verifi_code']
del validated_data['allow']
# user = super().create(validated_data)
user = User(**validated_data)
# 调用django的认证系统加密密码
user.set_password(validated_data['password'])
user.save()
return user