再有人问你为什么MySQL用B+树做索引,就把这篇文章发给她
本文是参考上述文章进行总结和补充,大家感兴趣也可以阅读原文.
目录
1. 索引
2. 二叉搜索树
3. 平衡二叉树
4. B树
5. B+树
6.扩展 -- 聚集索引 VS 非聚集索引
1. 索引
概念:索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
索引最形象的比喻就是图书的目录了。注意这里的大量,数据量大了索引才显得有意义,如果我想要在[1,2,3,4]中找到4这个数据,直接对全数据检索也很快,没有必要费力气建索引再去查找。
索引在mysql数据库中分三类: B+树索引, Hash索引, 全文索引
本文介绍的是工作开发中最常接触到innodb存储引擎中的的B+树索引。
👉👉👉innodb存储引擎![]() https://baike.baidu.com/item/innodb/8970025?fr=aladdin
https://baike.baidu.com/item/innodb/8970025?fr=aladdin
2. 二叉搜索树
首先回顾一下,在数据结构系列学习的二叉搜索树,我们可以将数据建立索引,每个节点存储了key以及value.
二叉查找树的特点就是:任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。 顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
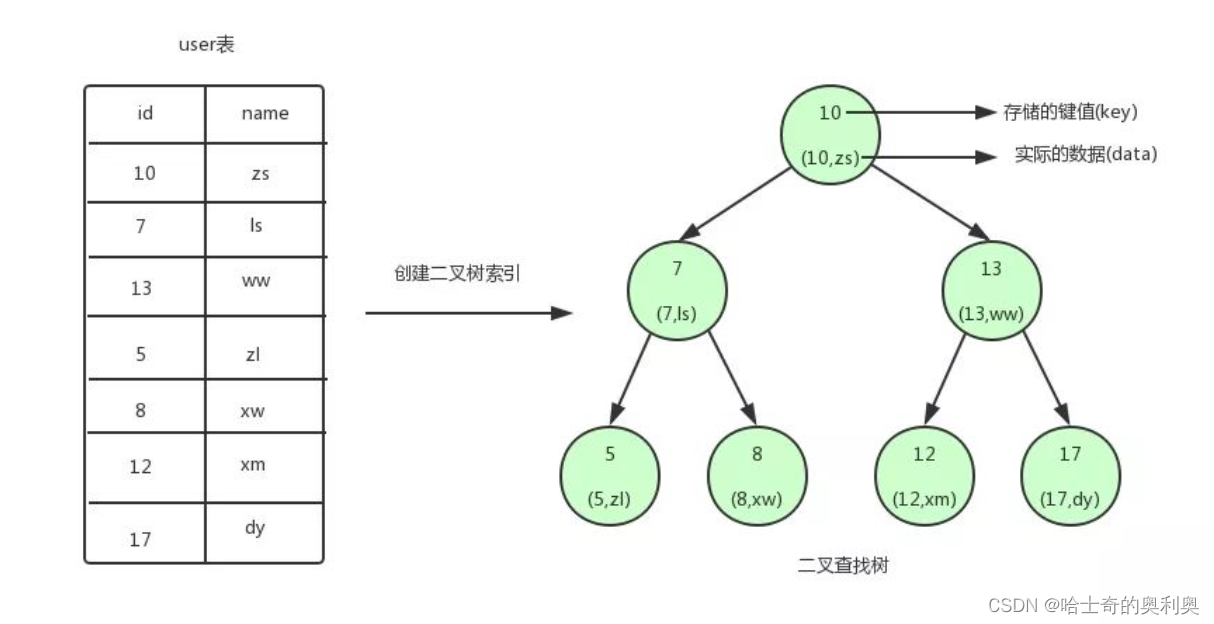
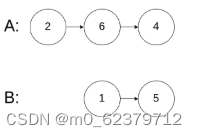
如果我们需要查找id=12的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
-
1. 将根节点作为当前节点,把12与当前节点的键值10比较,12大于10,接下来我们把当前节点>的右子节点作为当前节点。
-
2. 继续把12和当前节点的键值13比较,发现12小于13,把当前节点的左子节点作为当前节点。
-
3. 把12和当前节点的键值12对比,12等于12,满足条件,我们从当前节点中取出data,即id=12,name=xm。
以上的方式进行查找的时间复杂度是树的高度.
3. 平衡二叉树
如果我们建立的树是下方这个样子,那么我们查找数据的时间将会与在顺序表中查找的时间是一样的.
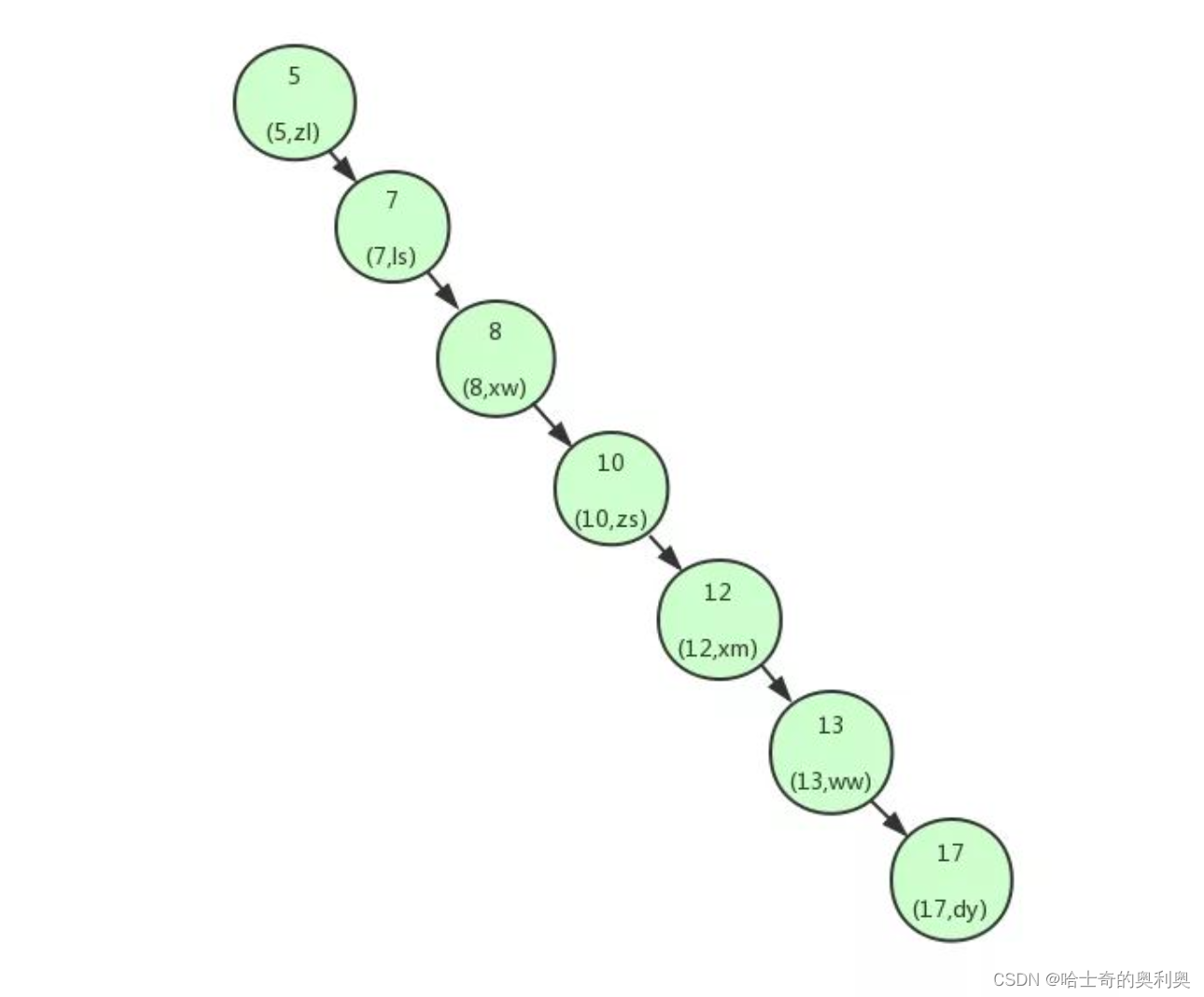
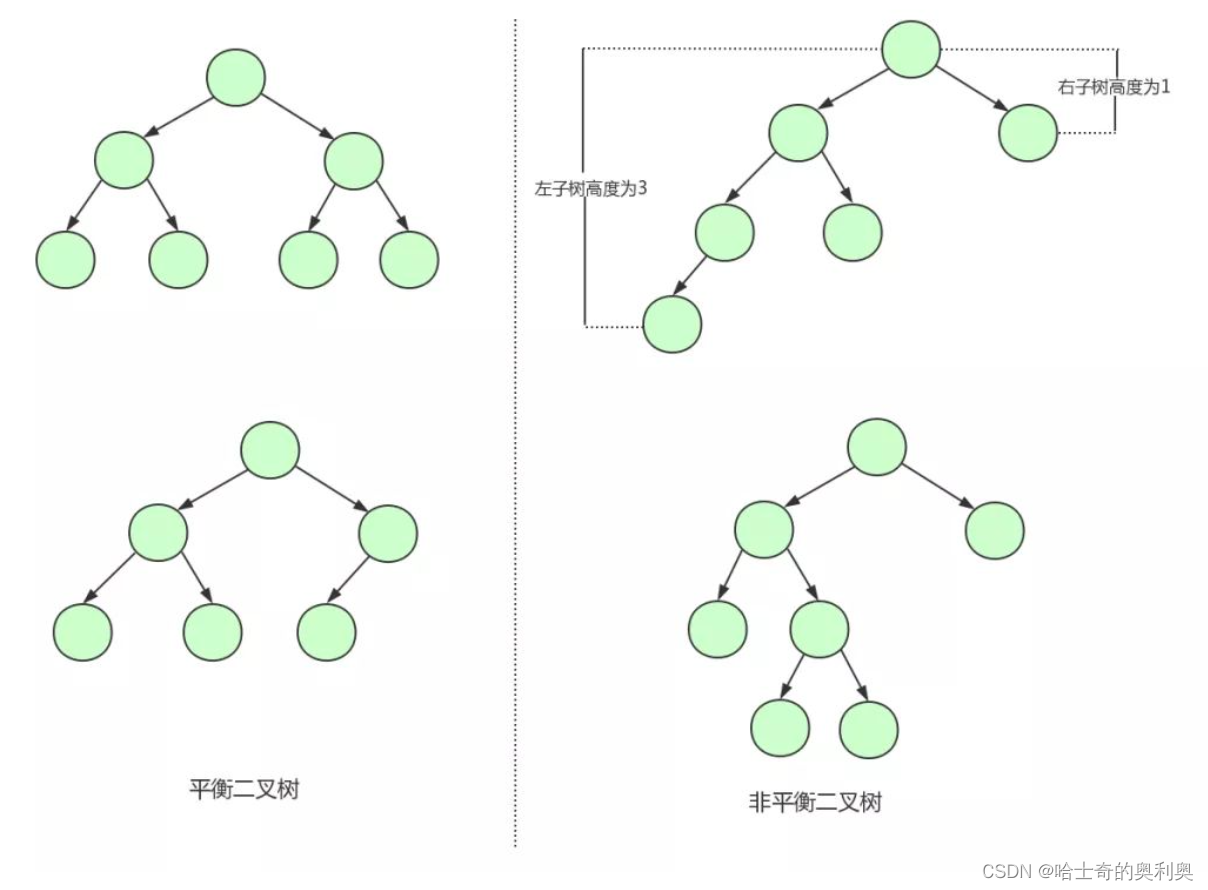
导致这个现象的原因其实是二叉查找树变得不平衡了,也就是高度太高了,从而导致查找效率的不稳定。为了解决这个问题,我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树了。 平衡二叉树又称AVL树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过1。
4. B树
将节B树之前我们要先了解一下B树的查找元素原理以及如构造一颗B树
B树又称B-树,是一颗N叉搜索树.为什么出现了这个B树的概念呢,要解决的问题是什么,我们都要了解清楚.
首先,数据库会将数据存储在磁盘这种外围设备中,因为内存有易失性.但是有一点,内存有着很大优势,那就是访问与读取数据的速度有着天壤之别,所以为了提高查找元素的效率,我们要减少从磁盘读取数据的次数,此外从磁盘读取数据的时候,都是按照磁盘块进行读取的,并不是一条一条的度读取,如果我们能够尽可能的将数据放在一个磁盘块中,那么一次读取的数据就会越多,那么查找的效率就会提高.为了解决上述问题我们应该建立一种单个节点可以存储多个键值和数据的平衡树。也就是我们接下来要说的B树。
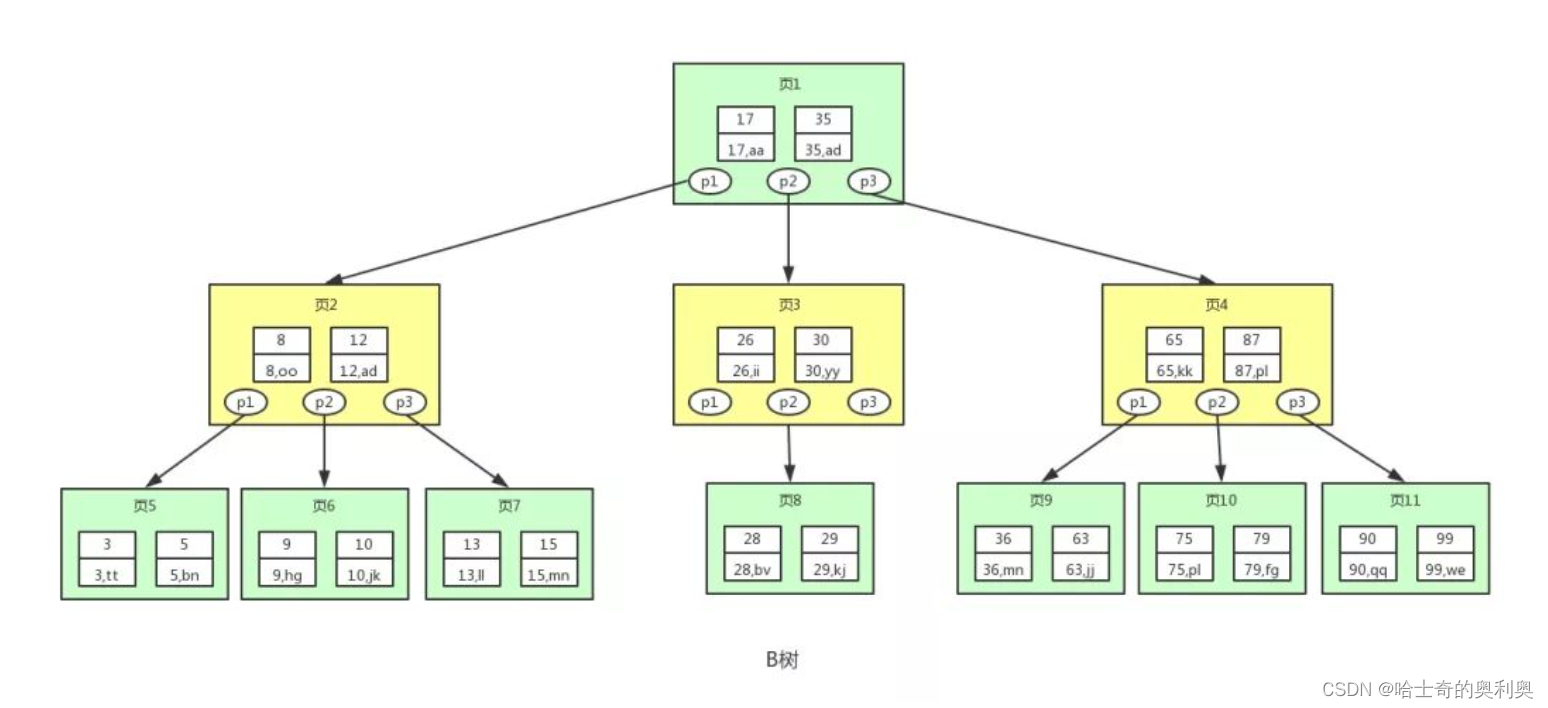
从上图可以看出,B树相对于平衡二叉树,每个节点存储了更多的键值(key)和数据(data),并且每个节点拥有更多的子节点,子节点的个数一般称为阶,上述图中的B树为3阶B树,高度也会很低。基于这个特性,B树查找数据读取磁盘的次数将会很少,数据的查找效率也会比平衡二叉树高很多。
假如我们要查找id=28的用户信息,那么我们在上图B树中查找的流程如下:
-
1. 先找到根节点也就是页1,判断28在键值17和35之间,我们那么我们根据页1中的指针p2找到页3。
-
2. 将28和页3中的键值相比较,28在26和30之间,我们根据页3中的指针p2找到页8。
-
3. 将28和页8中的键值相比较,发现有匹配的键值28,键值28对应的用户信息为(28,bv)
5. B+树
B+树是对B树的进一步优化。让我们先来看下B+树的结构图:
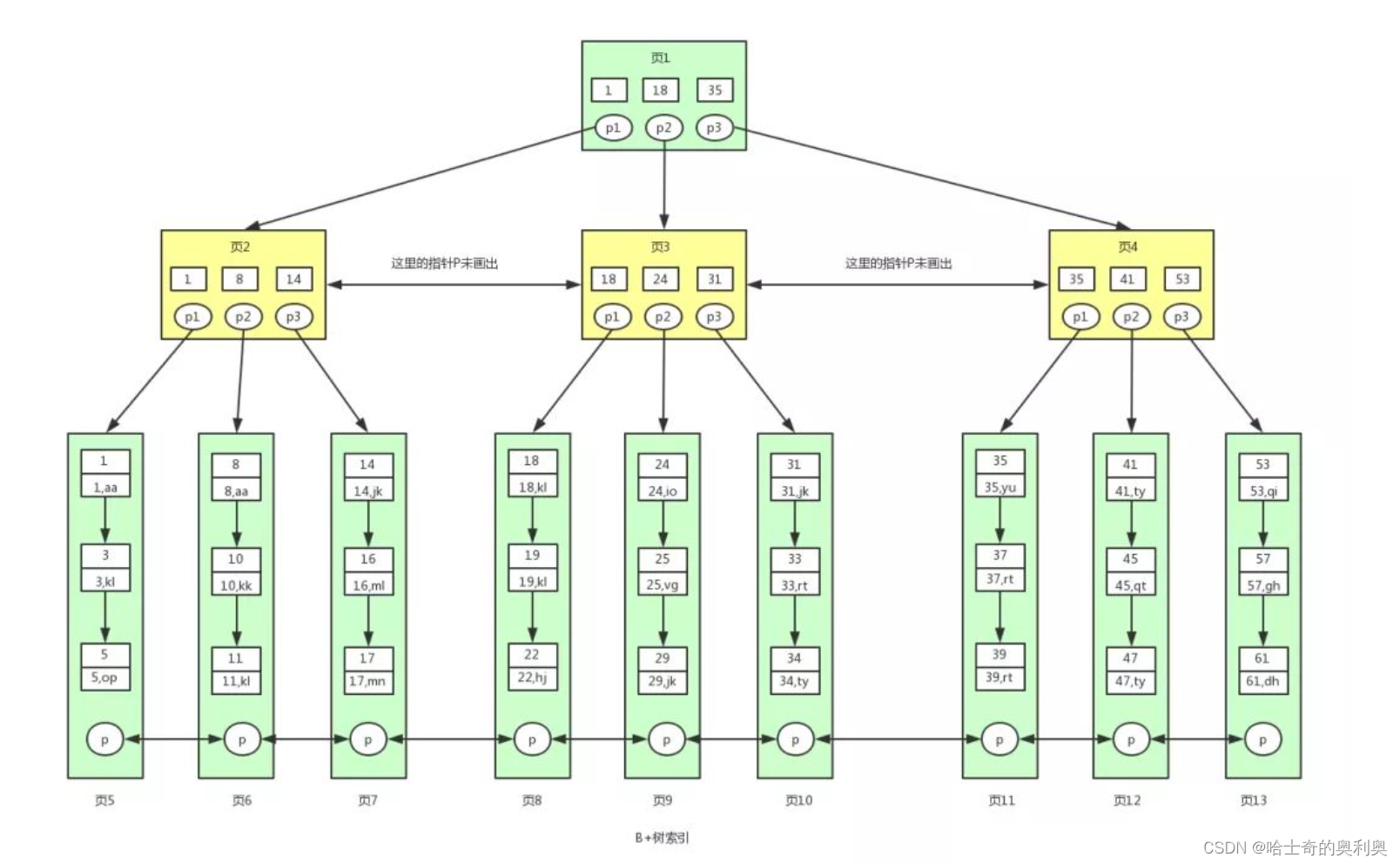
B+树的特点:
1.一个节点,可以存储N个key,N个key划分出了N个区间
2.每个节点的key都会在子节点同时存在 , 同时也是子节点的最大key值
3.B+树的叶子结点是首尾相连,是一个双向的链表,而叶子节点中的数据是通过单向链表进行连接的.
4.由于叶子结点是完整的数据结合,只在叶子结点存储数表中的每一行完整的数据,而非叶子节点,只存在key值本身即可.
B+树的优势
1.当前一个节点保存更多的key,最终数的高度是相对更矮一些的,查询的时候减少了IO (硬盘的访问)的次数.(这里的优势是和B树是一样的)
2.所有的查询最终都会落到叶子结点上.(查询每一个数据,经过的IO次数是一样的)(这里就很稳定,可以对执行的效率进行一个评估).
3.B+树的所有叶子节点否成一个链表,此时比较方便进行查询.
4.由于数据都在叶子节点上,非叶子节点,只需要存储key值,导致了非叶子节点占用的空间是比较小的.可以讲这些非叶子节点在内存中进行缓存(或者缓存一部分),这样可以进一步减少IO的次数.
6.扩展 -- 聚集索引 VS 非聚集索引
1. 聚集索引(聚簇索引):以innodb作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。这是因为innodb是把数据存放在B+树中的,而B+树的键值就是主键,在B+树的叶子节点中,存储了表中所有的数据。这种以主键作为B+树索引的键值而构建的B+树索引,我们称之为聚集索引。
2. 非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的B+树索引,我们称之为非聚集索引。非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
明白了聚集索引和非聚集索引的定义,我们应该明白这样一句话:数据即索引,索引即数据。
聚焦索引就是上述我们讲的B+树查找的过程,叶子结点直接存储的查询表的数据.
非聚焦索引:叶子节点并没有存储数据,而是存储的该列对应的主键,通过这个主键我们再去通过聚焦索引进行查找,也就是在第一个B+树的叶子节点上又构建了一个新的B+树,这个过程叫做回表.
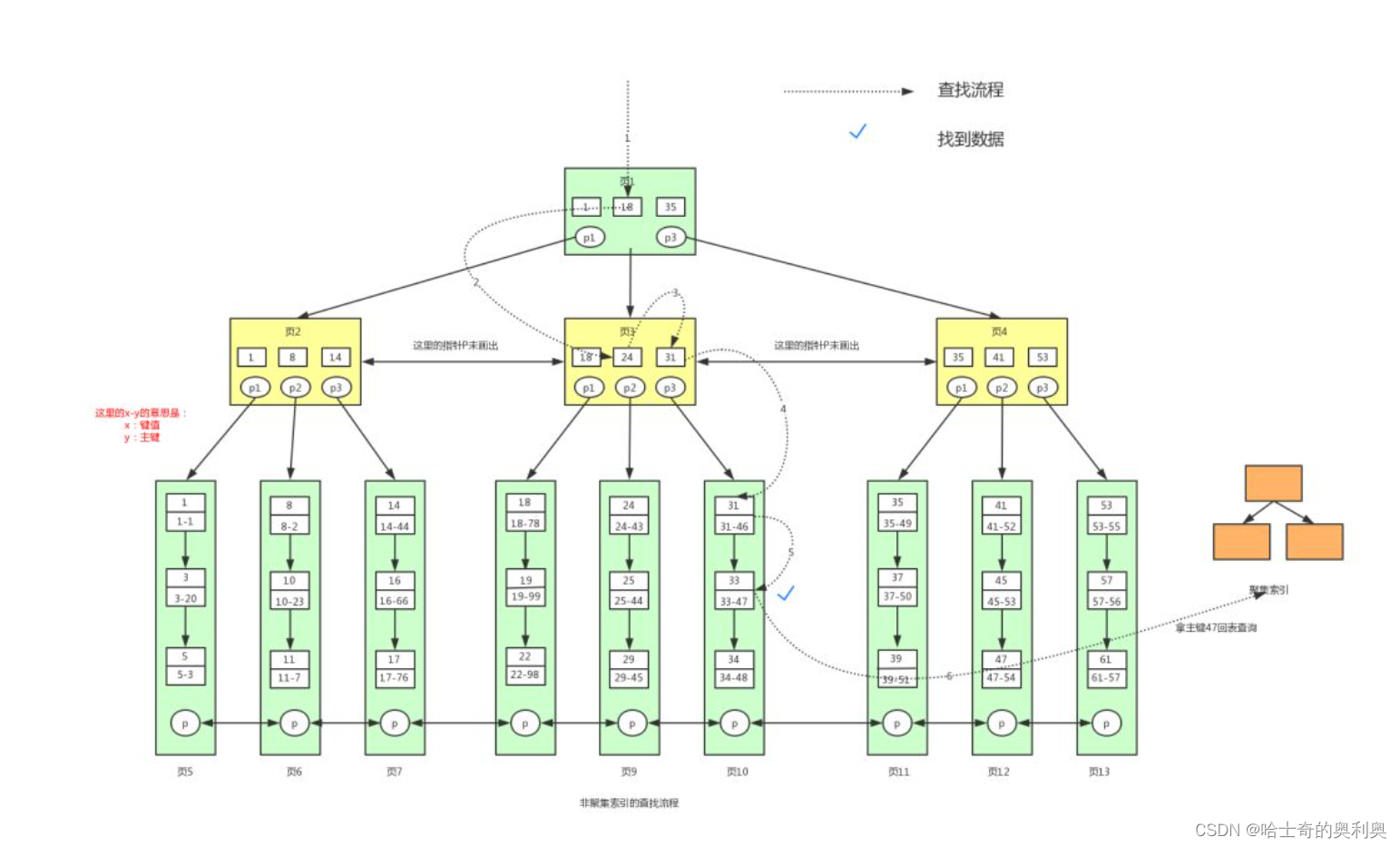
上述情况可以理解为:
如果一个表有多个索引,例如:针对id有索引,针对name也有一个索引,表的数据还是按照id为主键进行构建B+树,通过叶子结点进行组织树据的所有行,针对这个name这个列会构建一个新的B+树,但是这个B+树就不会存储这一行完整的数据,而是存储相应的主键id,此时通过name进行查询,来到叶子结点不会得到整个完整的数据信息,而是得到相应的主键id,然后通过主键id再去另一个B+树查询一次得到完整的数据,这就是回表的过程,这个过程是MySQL自动完成的,用户感知不到.
上述就是对MySQL为什么使用B+树作为索引的总结,希望能够对各位读者有所帮助.