💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
1.1 DBSCAN密度聚类
1.2 数据预处理
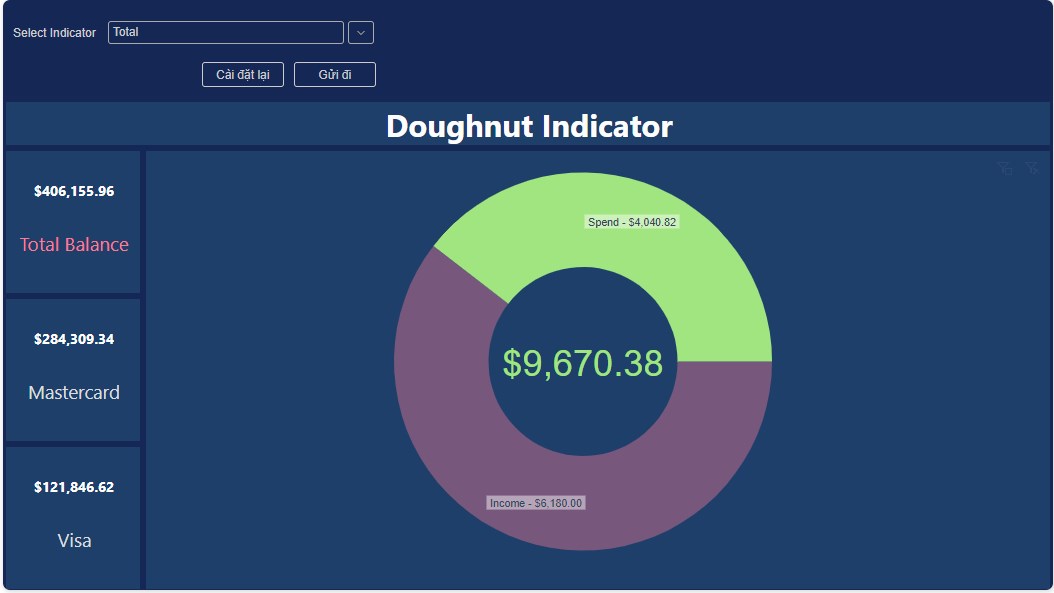
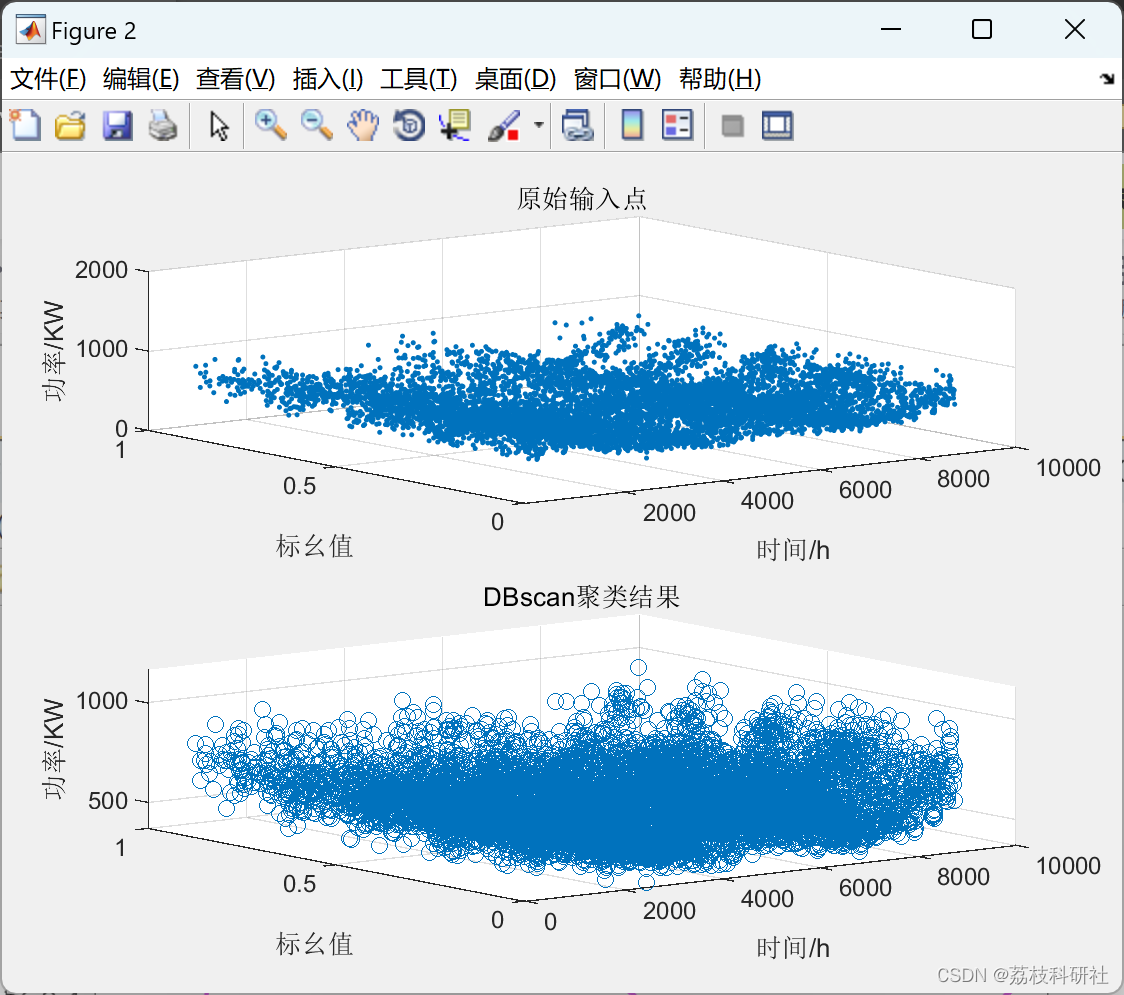
📚2 运行结果
🎉3 参考文献
🌈4 Matlab代码、数据、文章讲解

💥1 概述
文献来源:

本章提出一种基于聚类融合算法的风电-负荷确定性场景缩减方法。首先,采集风电、电负荷历史数据。然后,通过采用DBSCAN密度聚类的数据预处理消除异常或小概率电负荷、风电数据。之后,针对风电波动性与电负荷时序性、周期性特点,将场景提取分为电负荷场景提取和风电场景提取。电电负荷功率具有明显的季节性、周期性采用有序聚类方法可兼顾上述特点,为保证风电、电负荷时序性,本文根据电负荷分段时间节点将风电出力标幺值分段,结合K-means聚类提取各时段风电场景。
密度聚类算法是以样本间的紧密程度进行分类的。相似的样本在一定数据范围内个数较多,相应的密度较大。通过半径与半径内样本个数两个密度参数将符合参数要求的的样本划为一类,这样就可以得到有效参数,而不在密度范围的可视为噪声。密度聚类的优势就是本身并不需要使用者确定聚类个数,这样就减少了聚类数确定过程所带来的不确定性,简化聚类过程。
1.1 DBSCAN密度聚类
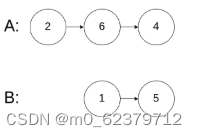
DBSCAN是基于一组邻域来描述样本集的紧密程度的算法。DBSCAN需要二个数值,扫描半径(E)和最小包含点数(MinPts),用来描述邻域的样本分布紧密程,其中,E描述了某一样本的邻域距离阈值,给定对象以E为半径的区域被称为该对象的E邻域。MinPts描述了某一样本的距离为E的邻域中样本个数的阈值。如果给定对象E邻域内的样本点数大于等于MinPts,则称该对象为核心对象。不属于核心对象及核心人象E邻域内的点为噪声点。DBSCAN聚类过程如图所示,具体步骤如下。
首先,确定DBSCAN所需的二个参数值E和MinPts。然后,任选一个未被访问的点开始,找出与其距离在E之内(包括E)的所有附近点。如果附近点的数量>= MinPts,则当前点与其附近点形成一个簇,并且出发点被标记为已访问。然后递归,以相同的方法处理该簇内所有未被标记为已访问的点,从而对簇进行扩展。如果附近点的数量<minPts,则该点暂时被标记作为噪声点。如果簇充分地被扩展,即簇内的所有点被标记为已访问,然后用同样的算法去处理未被访问的点。
1.2 数据预处理
📚2 运行结果







🎉3 参考文献
部分理论来源于网络,如有侵权请联系删除。
[1]曹继雷. 氢能支撑的风—燃气耦合低碳微网容量优化配置研究[D].大连理工大学,2021.DOI:10.26991/d.cnki.gdllu.2021.001667.