简介
夜莺( Nightingale )是一款国产、开源云原生监控分析系统(从 v6 版本开始,尝试转型成为统一观测平台),集数据采集、可视化、监控告警、数据分析于一体。于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 100 多个版本。
夜莺最初由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。夜莺的核心研发团队,也是 Open-Falcon 项目原核心研发人员。
夜莺监控既可以监控传统的物理机架构、可以监控微服务架构和 K8s,也可以监控公有云的资源和服务。不仅支持 Metrics,也支持 Log、Trce。提供统一的监控数据视图,提供集中化的可视化和管理界面。换句话说,你可以使用夜莺监控,来完成Zabbix + Prometheus + Grafana + ELK + Jaeger + 云监控的工作。
项目代码
后端:💡 https://github.com/ccfos/nightingale
前端:💡 https://github.com/n9e/fe
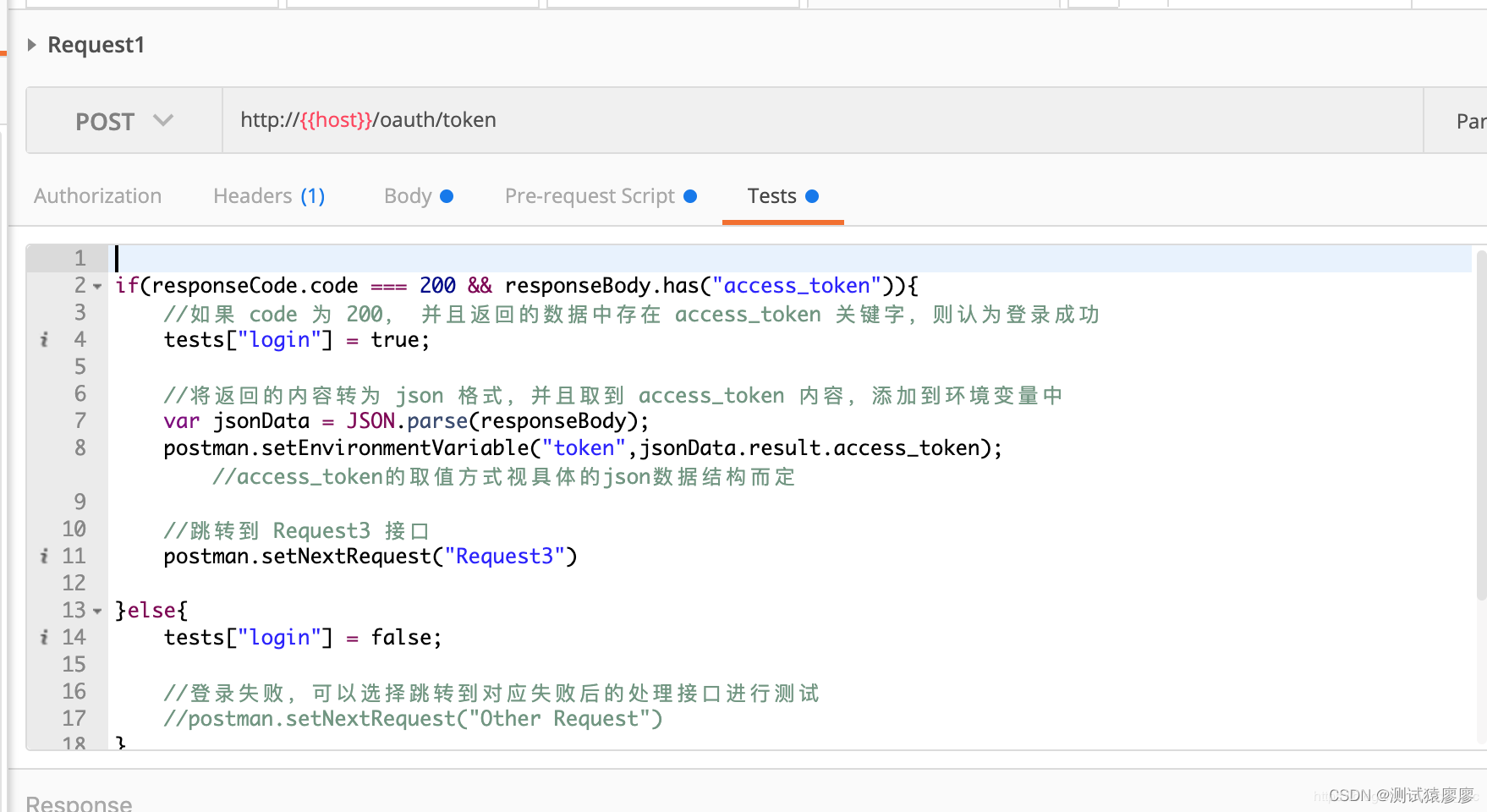
架构图
中心汇聚式部署方案
网络好,数据不多,均可采用此方案;老大说有服务器牛B的,单服务器也可支撑N多服务器;上图:
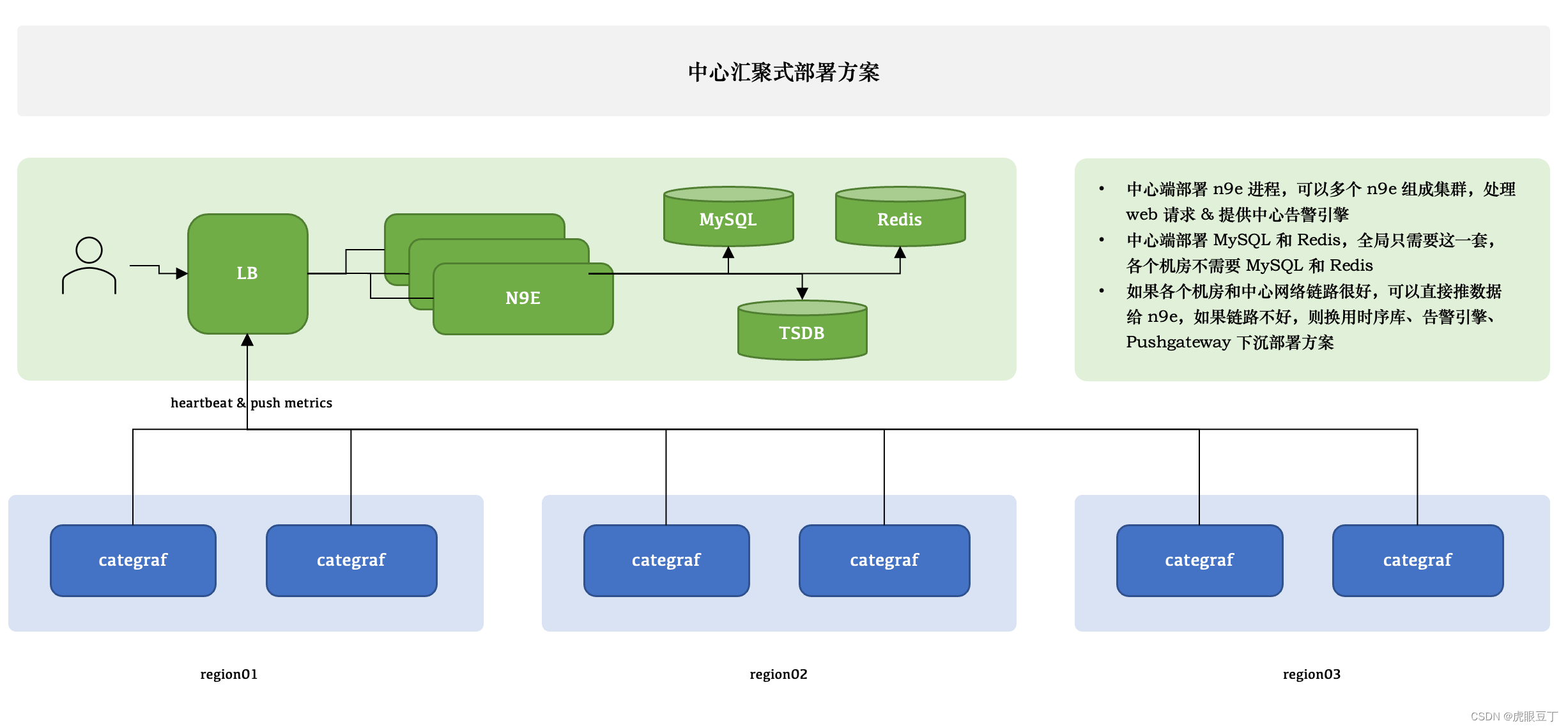
夜莺只有一个模块了,就是 n9e,可以部署多个 n9e 实例组成集群,n9e 依赖 2 个存储,数据库、Redis,数据库可以使用 MySQL 或 Postgres,自己按需选用。
n9e 提供的是 HTTP 接口,前面负载均衡可以是 4 层的,也可以是 7 层的。一般就选用 Nginx 就可以了。
n9e 这个模块接收到数据之后,需要转发给后端的时序库,相关配置是:
[Pushgw]
LabelRewrite = true
[[Pushgw.Writers]]
Url = "http://127.0.0.1:9090/api/v1/write"
相当于是,虽然数据源可以在页面配置了,但是上报转发链路,还是需要在配置文件指定。
所有机房的 agent( 比如 Categraf、Telegraf、 Grafana-agent、Datadog-agent ),都直接推数据给 n9e,这个架构最为简单,维护成本最低。当然,前提是要求机房之间网络链路比较好,一般有专线。如果网络链路不好,则要使用下面的部署方式了。
边缘下沉式混杂部署方案
针对已部署过Prometheus等监控程序的,进行融合监控;或者看老大视频说的因网络环境原因,为更好的自治做了拆分的处理等;上图:
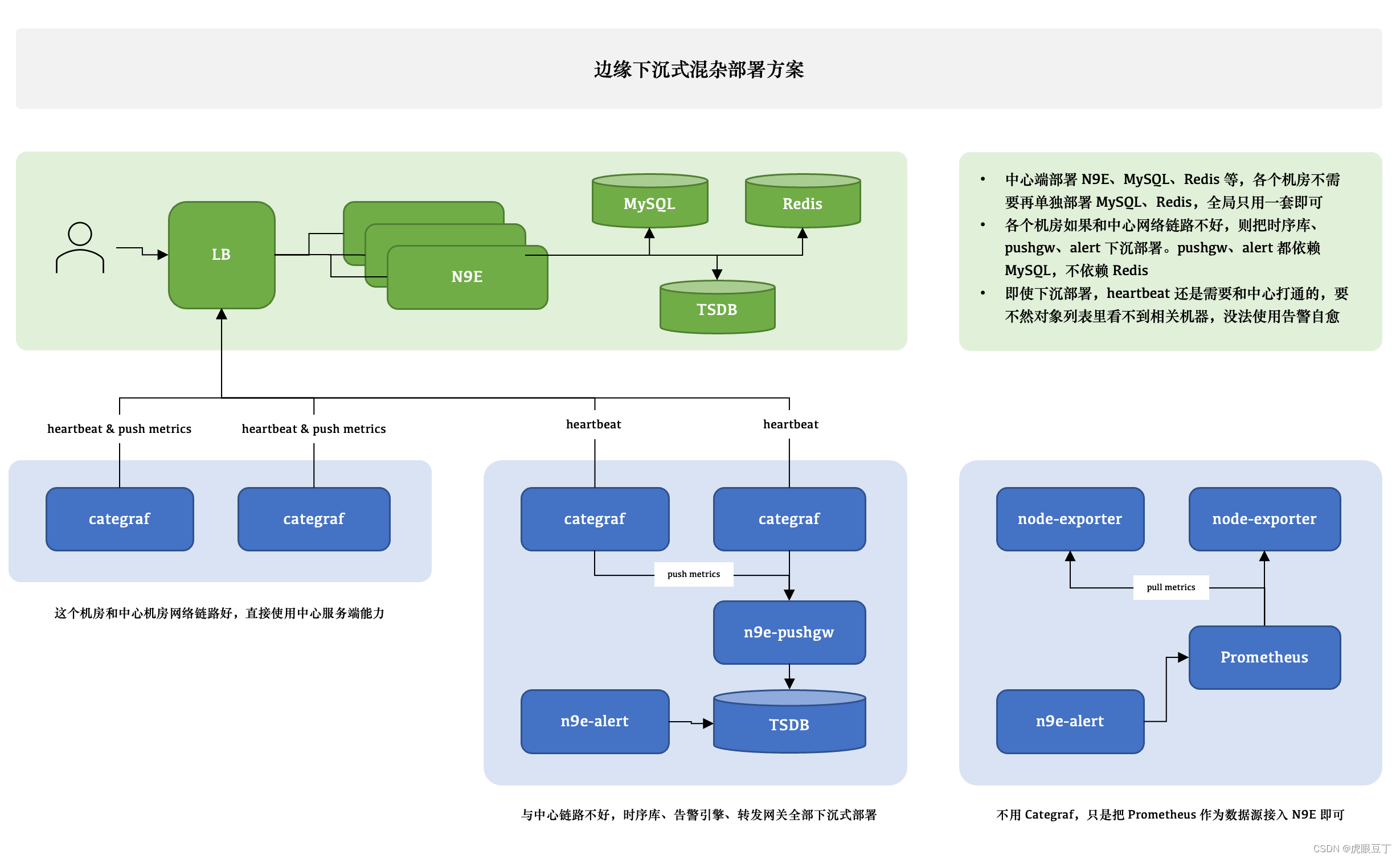
这个图尝试解释 3 种不同的情形,比如 A 机房和中心网络链路很好,Categraf 可以直接汇报数据给中心 n9e 模块,另一个机房网络链路不好,就需要把时序库下沉部署,时序库下沉了,对应的告警引擎和转发网关也都要跟随下沉,这样数据不会跨机房传输,比较稳定。但是心跳还是需要往中心心跳,要不然在对象列表里看不到机器的 CPU、内存使用率。还有的时候,可能是接入的一个已有的 Prometheus,数据采集没有走 Categraf,那此时只需要把 Prometheus 作为数据源接入夜莺即可,可以在夜莺里看图、配告警规则,但是就是在对象列表里看不到,也不能使用告警自愈的功能,问题也不大,核心功能都不受影响。
边缘机房,下沉部署时序库、告警引擎、转发网关的时候,要注意,告警引擎需要依赖数据库,因为要同步告警规则,转发网关也要依赖数据库,因为要注册对象到数据库里去,需要打通相关网络,告警引擎和转发网关都不用Redis,所以无需为Redis打通网络。
尝试部署
资源
- 🔧Linux服务器(Centos7.9.2009 好像最后一版了吧✨):http://isoredirect.centos.org/centos/7/isos/x86_64/
- 🔧MySQL(5.7.37-log)根据自己需求装吧,我这是用的之前的,
- 🔧N9e-v6最新版以是(v6.0.0-ga.6):https://flashcat.cloud/download/nightingale
- 🔧Categraf(v0.3.2):https://flashcat.cloud/download/categraf
- 🔧VictoriaMetrics(v1.90.0):https://github.com/VictoriaMetrics/VictoriaMetrics/releases
- 🔧Redis(v-6.2.6,已出7版本了,我这里用的旧的):https://download.redis.io/releases/redis-6.2.6.tar.gz
开始整活
啥也不说,直接各个程序撸起来;当然了Centos和MySQL我就不写了,网络上很多介绍的自己搜搜就行。
Redis
mkdir /data/monitor/redis
cd redis/
tar zxvf redis-6.2.6.tar.gz
cd redis-6.2.6
# 直接启动即可
nohup ./bin/redis-server &
# 看看起来了吗?
ps aux |grep redis
# 看到下面这么一行说明启动成功,并且端口使用6379
root 15129 0.0 0.0 162516 3340 pts/2 Sl 17:26 0:04 ./bin/redis-server *:6379
注意:我这里测试没有改啥,真正用于生产环境记得修改密码。
VictoriaMetrics
老大推荐的TSDB,可以使用Prometheus也是可以的,n9e配置文件中默认还是用的Prometheus配的,一会儿启动n9e时需要改一下.
mkdir /data/monitor/vm
cd vm/
tar zxvf victoria-metrics-linux-amd64-v1.90.0.tar.gz
# 解压完毕直接启动就可以;
nohup ./victoria-metrics-prod &> stdout.log &
看一下端口8428,看到就可以了
netstat -ntlp|grep 8428
tcp 0 0 0.0.0.0:8428 0.0.0.0:* LISTEN 18546/./victoria-me
n9e
主程序来了,启动就可以看到界面了;
mkdir /data/monitor/n9e-v6
tar zxvf n9e-v6.0.0-ga.6-linux-amd64.tar.gz -C /data/monitor/n9e-v6
这个不能直接启动了;需要改下配置文件
vim /etc/config.toml
# 找到82行[DB]下的DSN 将密码改一下;
82 DSN="root:dbn9e.1234@tcp(127.0.0.1:3306)/n9e_v6?charset=utf8mb4&parseTime=True&loc=Local&allowNativePasswords=true"
# 再找到153行,把9090改为 8428
153 Url = "http://127.0.0.1:8428/api/v1/write"
# 保存修改,启动即可
nohup ./n9e &> stdout.log &
Categraf
话说Categraf和Telegraf 类似,反正都没用过,根据老大介绍直接启动就完活.
mkdir /data/monitor/categraf
cd categraf/
tar zxvf categraf-v0.3.2-linux-amd64.tar.gz
cd categraf-v0.3.2-linux-amd64
# 解压完毕直接启动就可以;
nohup ./categraf &> stdout.log &
界面
打开浏览器输入IP:17000就看到如下界面,证明你已经配置好了,如图:
输入账号密码:
root root.2020
一进来是啥也没有的,需要我们配置数据源;
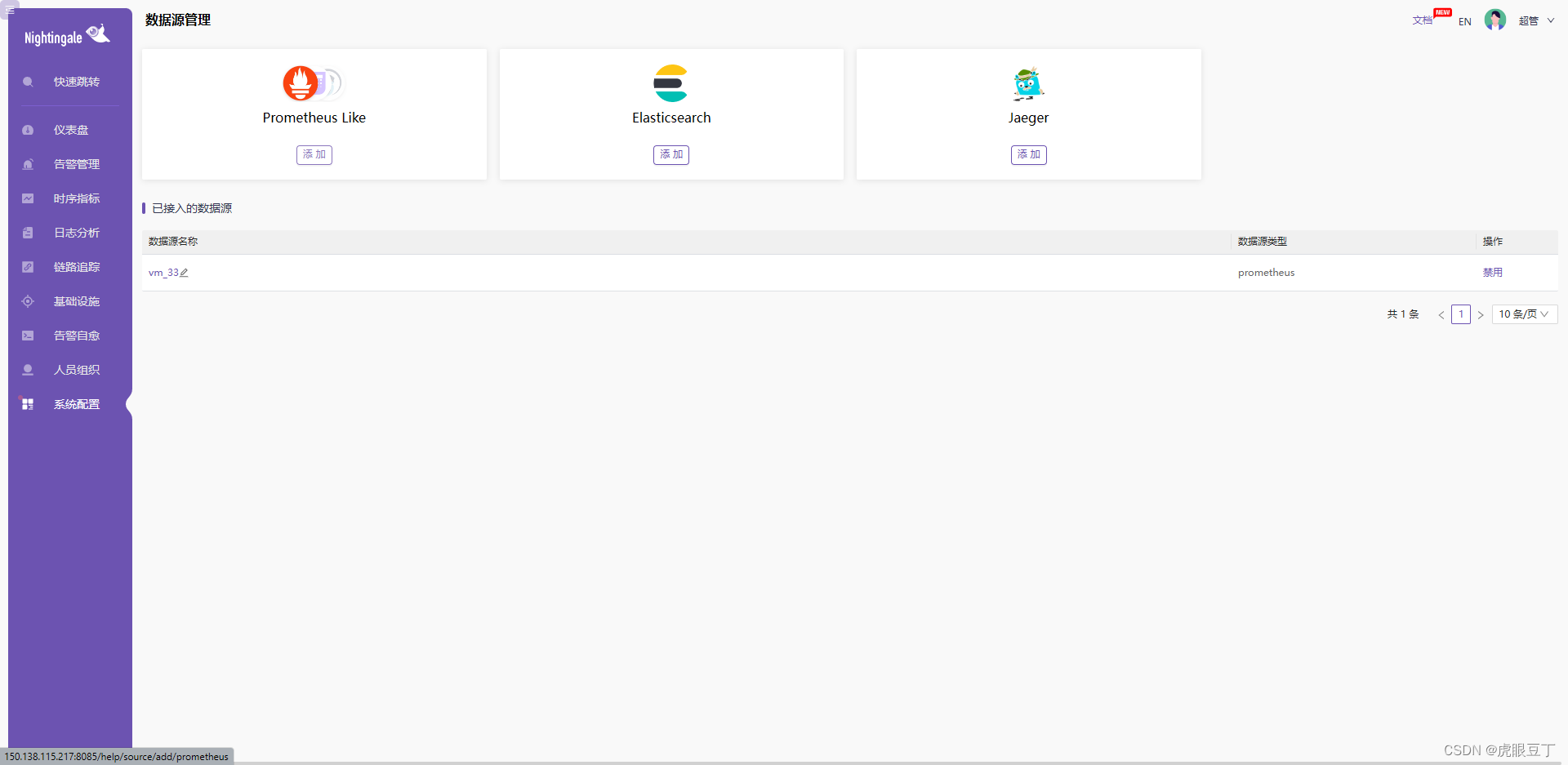
注意:我们用了
VictoriaMetrics需要选择Prometheus Like;
点击Prometheus Like下的添加按钮,根据提示添加必填即可;
看基础的在基础设施> 机器列表中看到你的服务器简单的信息了。
要看到详细信息;
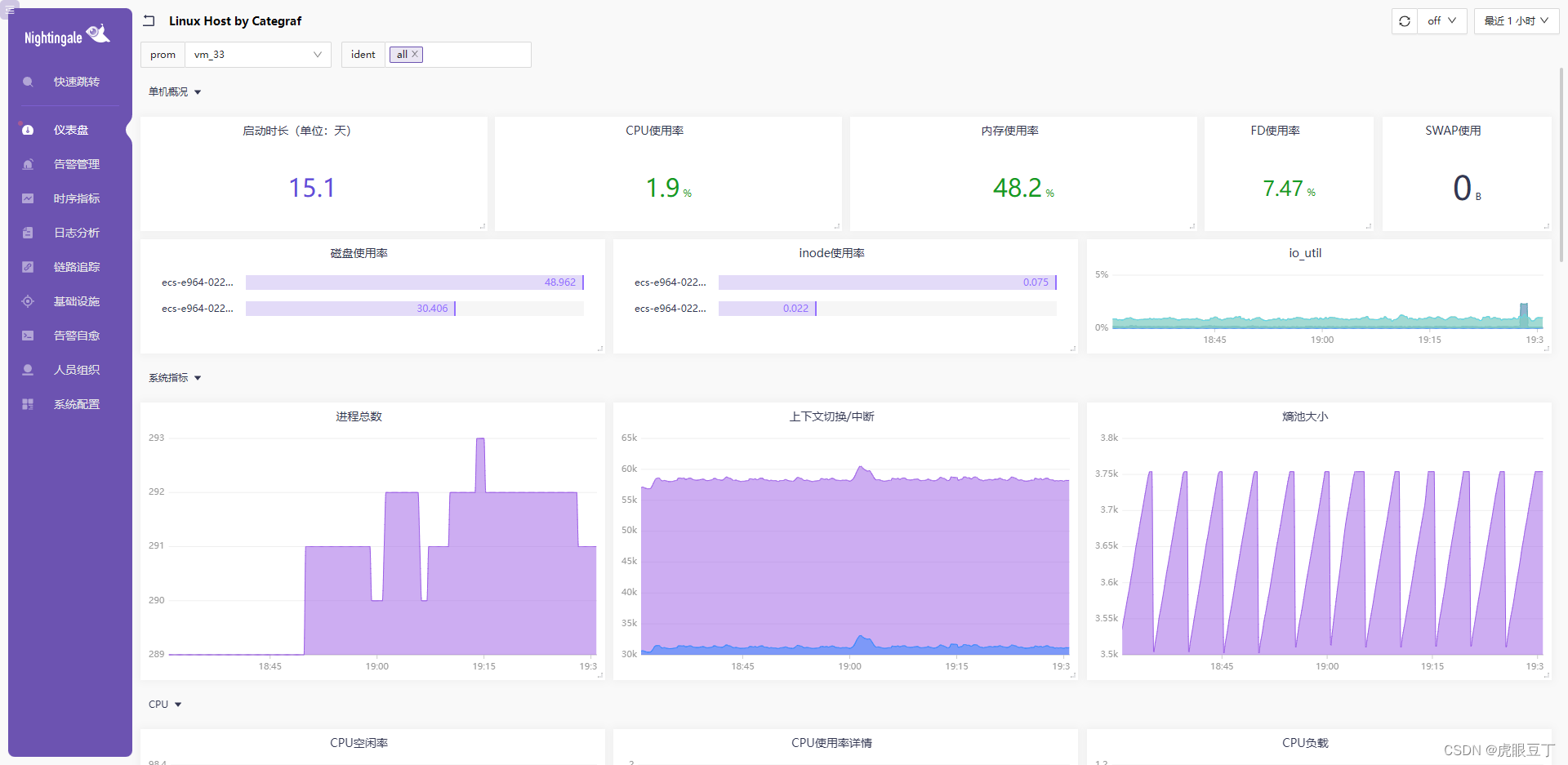
我们需要看到仪表盘中的 内置仪表盘中,找到Linux下选择Linux Host by Categraf后的查看。
你的服务器监控信息将映入眼帘;

总结
总结啥,简单咔咔一顿就出效果了;最初看监控是想着APM去的,后面会介绍``的相关信息;

查监控的资料找到一堆,Prometheus、Grafana、DATADOG、Zabbix等很多;支持国产;Skywalking、夜莺看了一通;
可观测性(Observability)是一种软件开发和系统构建的哲学,是对系统内部状态及行为的度量和推断能力,通常包括日志、指标、链路追踪等多个度量维度。也就是说,在软件开发和运维领域中,可观测性是指对于一个复杂的系统,能够通过监控、日志、指标、追踪等手段,快速地发现、诊断、解决问题的能力。
后期可观测将都会朝朝All-in-one;metrics、logs、 traces都汇总的反向发展;
看到夜莺也是如此就在此尝试了,不止于监控,夜莺 V6 全新升级为开源观测平台
后面会继续跟进课程及时使用出相关博文。