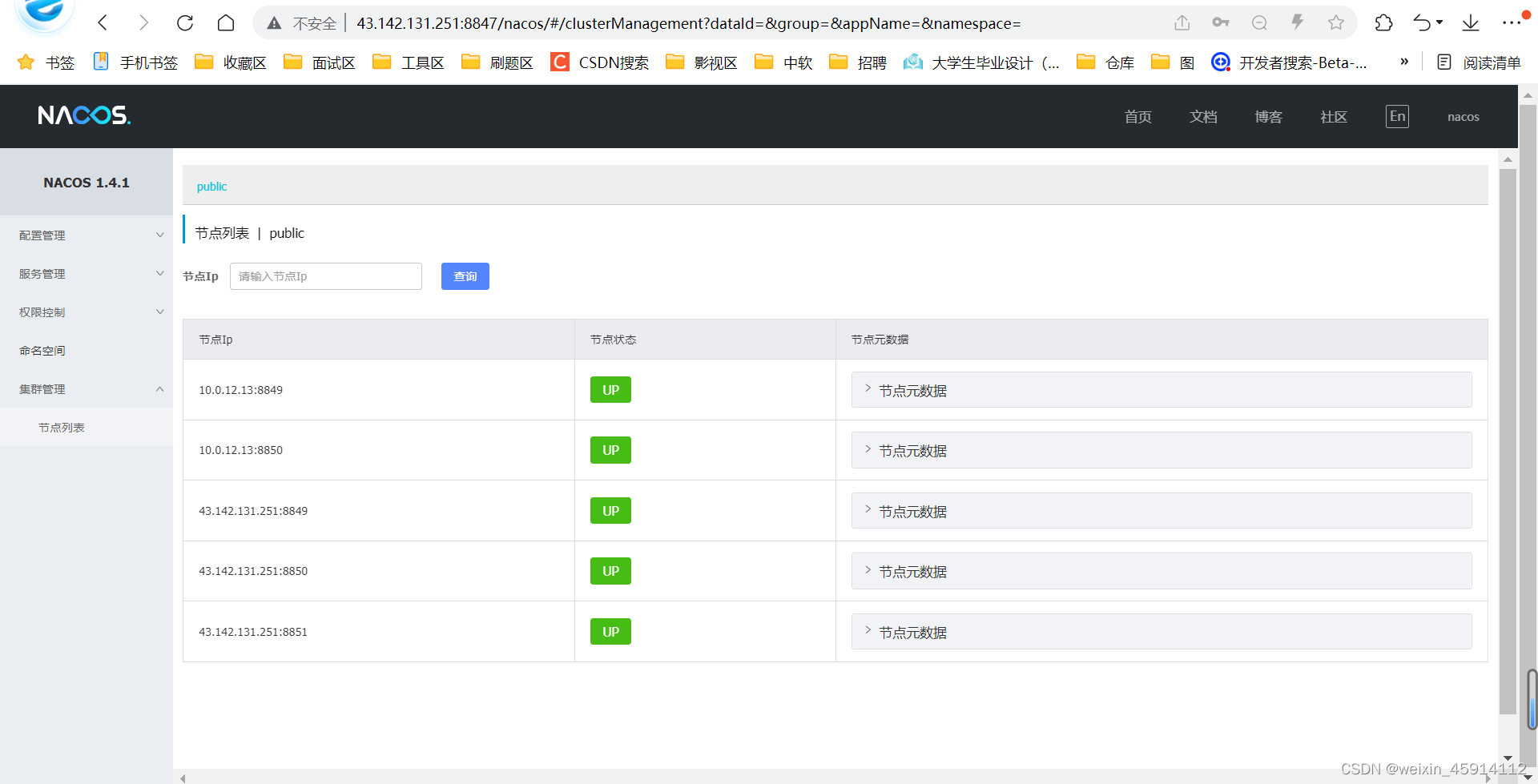
论文地址:BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework 论文学习
Github 地址:BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework 论文学习
1. 解决了什么问题?
将相机和 LiDAR 融合已经成为 3D 检测任务事实上的标准方案,二者的特征可以互补。目前的方法依赖激光雷达点云作为 queries,然后再利用图像空间的特征。但人们发现,当激光雷达失灵时,这个底层假设会使当前的融合方案无法做预测。这就限制了算法在自动驾驶场景的部署。
视觉感知任务,如检测 3D 目标的边框,是 FSD 任务的重要方向。在车上感知系统所有的传感器中,激光雷达和相机是最重要的两个传感器,分别提供周遭环境的点云和图像特征。在早期的感知系统中,人们为每个传感器设计单独的深度模型,然后在后处理阶段融合各类信息。但由于图像缺乏深度信息,很难在纯图像上回归 3D 框。同样,当激光雷达没有接收到足够数量的点时,很难根据点云对目标做分类。
近来,人们设计了 LiDAR-相机融合算法,更好地利用多模态信息。这些算法主要包括:
- 给定点云的若干个点、LiDAR 到世界变换矩阵、相机到世界的变换矩阵;
- 将 LiDAR 点或候选框变换到相机坐标系,将它们作为 queries 来选取相应的图像特征。
这是目前 SOTA 3D BEV 感知的基本思路。
但人们忽视了一个底层假设,我们需要激光雷达点来生成图像 queries,目前的 LiDAR-相机融合方法依赖于 LiDAR 原始点云。在现实场景中,如果 LiDAR 输入丢失了,比如目标材质造成 LiDAR 点反射率很低,或者系统故障,或是因为硬件限制,LiDAR 无法看到
360
360
360度,那么现有的融合方案就不能输出有意义的结果。这就从根本上使这些工作无法实际应用。
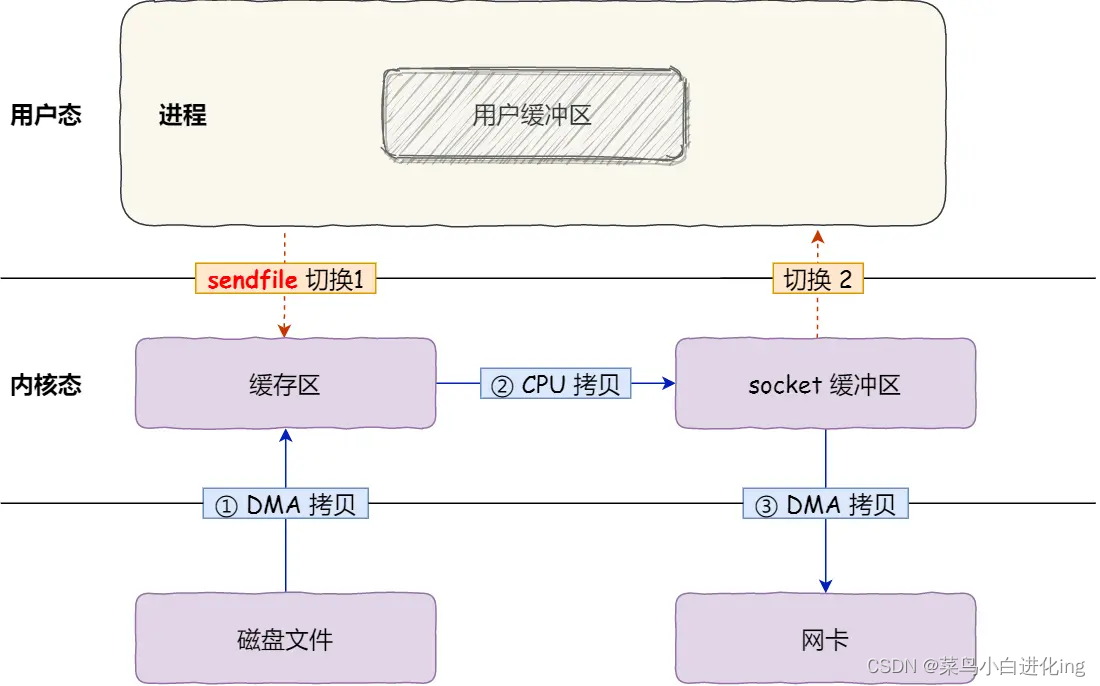
如下图所示,LiDAR-相机融合方法大致可以分为:
- 点级融合,将图像特征投影到原始点云,通过原始点云来查询图像特征,;
- 特征级融合,先将 LiDAR 点或候选框映射到特征空间,然后 query 关联相机的特征,提取 RGB 信息,这是目前 3D 检测的 SOTA 方案。

2. 提出了什么方法?
本文认为,在 LiDAR-相机融合方案中,不管另一模态是否有效,单模态算法也应该正常工作,而两个模态一起工作时,能进一步提高感知准确率。于是,本文提出了一个简单但新颖的融合架构,BEVFusion,相机流不依赖于 LiDAR 数据的输入,从而弥补了之前方法的缺陷。BEVFusion 有两个独立的流,将相机和激光雷达的原始输入编码为同一个 BEV 空间的特征。然后设计了一个简单的模块来融合这些 BEV 特征,再将最终的特征输入预测 head。
该框架是通用的,可以在该框架中加入相机或激光雷达的单模态 BEV 模型。在相机流使用了 LSS,将多视角图像特征映射成 3D 自车坐标系特征,生成相机 BEV 特征。在 LiDAR 流,选择了三个主流模型,两个 voxel-based 和一个 pillar-based,将 LiDAR 特征编码到 BEV 空间。
此外,提出了一个新的数据增强技术,以
50
%
50\%
50%的概率随机丢弃目标框内的激光雷达点。

上图展示了 BEVFusion 架构。输入是点云和多视角图像,两个流分别提取特征,并转换到 BEV 空间。i) 将相机视角特征投影到 3D 自车坐标系,生成相机 BEV 特征;ii) 3D 主干网络从点云提取 LiDAR BEV 特征。然后,使用融合模块整合这两个特征。最终,使用检测 head 预测 3D 目标的值。蓝框是预测框,红圈表示 false positive 的预测。
2.1 相机流架构:从多视角图像到 BEV 空间
因为该架构可以融合任意的相机流,作者采用了 LSS 算法。LSS 原本用于 BEV 语义分割任务,而非 3D 检测。作者发现直接使用 LSS 效果并不好,因此将 LSS 架构做了适配,提升其表现。在上图(top) 部分,作者展示了相机流的细节,image-view encoder 将原始图像编码为深度特征,view projector 模块将这些特征变换到 3D 自车坐标系,然后 BEV encoder 将这些特征转换到 BEV 空间。
Image-view encoder
将输入图像编码为语义丰富的深度特征,包括一个提取特征的 2D 主干和多尺度表征目标的 neck。LSS 使用了 ResNet 作为主干,本文则使用的是 Dual-Swin-Tiny 作为主干,它提取的特征更具表征性。然后使用标准的 FPN 提取多尺度分辨率特征。为了更好地对齐这些特征,首先提出了特征自适应模块(ADP)来优化上采样特征。对每个上采样特征使用自适应平均池化和 1 × 1 1\times 1 1×1卷积,然后 concat 操作。
View projector module
图像特征仍在 2D 图像坐标系,作者设计了一个 view projector 模块将图像特征变换到 3D 自车坐标系。使用2D$\rightarrow$3D 视角投影,构建相机 BEV 特征。该 view projector 将图像视角特征作为输入,以分类的方式密集地预测深度信息。然后根据相机外参和预测的图像深度值,可以得到图像视角的特征,在预定义的点云中做渲染,得到一个 pseudo voxel V ∈ R X × Y × Z × C V\in \mathbb{R}^{X\times Y\times Z\times C} V∈RX×Y×Z×C。
BEV encoder module
为了进一步将 voxel 特征 V ∈ R X × Y × Z × C V\in \mathbb{R}^{X\times Y\times Z\times C} V∈RX×Y×Z×C编码到 BEV 空间特征 F Camera ∈ R X × Y × C C a m e r a \mathbf{F}_{\text{Camera}}\in \mathbb{R}^{X\times Y\times C_{Camera}} FCamera∈RX×Y×CCamera,作者设计了一个简单的编码模块。作者没有采用池化操作或步长为 2 2 2的 3D 卷积来压缩 z z z维度,而是使用了空间到通道(S2C)操作,通过 reshpe 将 V V V从 4D 张量变换为 3D 张量 V ∈ R X × Y × ( Z C ) V\in \mathbb{R}^{X\times Y\times (ZC)} V∈RX×Y×(ZC),保留语义信息、降低计算成本。然后使用四个 3 × 3 3\times 3 3×3卷积,逐步降低通道维度为 C Camera C_\text{Camera} CCamera,提取高层级语义信息。LSS 对低分辨率特征做下采样,提取高层级特征,而本文方法则直接在全分辨率相机 BEV 特征上操作,保留了空间信息。
2.2 LiDAR 流架构:从点云到 BEV 空间
该架构可以使用任意的将 LiDAR 点云变换为 BEV 特征的网络, F LiDAR ∈ R X × Y × C LiDAR \mathbf{F}_{\text{LiDAR}}\in\mathbb{R}^{X\times Y\times C_\text{LiDAR}} FLiDAR∈RX×Y×CLiDAR,作为 LiDAR 流使用。常用的方法是对原始点云学习参数化的 voxel,降低 z z z维度,利用由稀疏 3D 卷积组成的网络高效地产生 BEV 空间的特征。作者采用了三个主流算法,PointPillars、CenterPoint 和 TransFusion 作为 LiDAR 流的算法,证明本文架构具有足够的泛化能力。
2.3 动态融合模块
为了从相机(
F
Camera
∈
R
X
×
Y
×
C
C
a
m
e
r
a
\mathbf{F}_{\text{Camera}}\in \mathbb{R}^{X\times Y\times C_{Camera}}
FCamera∈RX×Y×CCamera)和 LiDAR 传感器(
F
LiDAR
∈
R
X
×
Y
×
C
LiDAR
\mathbf{F}_{\text{LiDAR}}\in\mathbb{R}^{X\times Y\times C_\text{LiDAR}}
FLiDAR∈RX×Y×CLiDAR)有效地融合 BEV 特征,作者提出了一个动态融合模块。给定相同空间维度下的两个特征,可以将二者 concat 起来,用可学习的静态权重来融合它们。受到 Squeeze-and-Excitation 机制启发,作者使用了一个简单的通道注意力机制,选择重要的融合特征。该融合模块可以表示为:
F
fused
=
f
adaptive
(
f
static
(
[
F
Camera
,
F
LiDAR
]
)
)
\mathbf{F}_{\text{fused}}=\mathcal{f}_\text{adaptive}(\mathcal{f}_\text{static}([\mathbf{F}_\text{Camera}, \mathbf{F}_\text{LiDAR}]))
Ffused=fadaptive(fstatic([FCamera,FLiDAR]))
[
⋅
,
⋅
]
[\cdot,\cdot]
[⋅,⋅]表示通道维度的 concat 操作。
f
static
\mathcal{f}_\text{static}
fstatic表示由
3
×
3
3\times 3
3×3卷积层实现的静态通道和空间融合函数,将 concat 后特征的通道维度降低为
C
LiDAR
C_\text{LiDAR}
CLiDAR。有了输入特征
F
∈
R
X
×
Y
×
C
LiDAR
\mathbf{F}\in\mathbb{R}^{X\times Y\times C_\text{LiDAR}}
F∈RX×Y×CLiDAR,
f
adaptive
\mathcal{f}_\text{adaptive}
fadaptive可以表示为:
f
adaptive
(
F
)
=
σ
(
W
f
avg
(
F
)
)
⋅
F
\mathcal{f}_\text{adaptive}(\mathbf{F})=\sigma(\mathbf{W}f_\text{avg}(\mathbf{F}))\cdot \mathbf{F}
fadaptive(F)=σ(Wfavg(F))⋅F
其中,
W
\mathbf{W}
W表示线性变换矩阵(如
1
×
1
1\times 1
1×1卷积),
f
avg
\mathcal{f}_\text{avg}
favg表示全局平均池化,
σ
\sigma
σ表示 Sigmoid 函数。

2.4 检测 Head
最终的特征都在 BEV 空间,我们可以利用流行的检测 head 模块。这进一步证明了本架构的泛化性。作者采用了三种检测 head,anchor-based、anchor-free 和 transform-based。
2.5 自适应模块
下图展示了在 FPN 上自适应模块的结构。自适应模块用在 FPN 之上。每个视角的图像的输入形状是
H
×
W
×
3
H\times W\times 3
H×W×3,主干和 FPN 输出多尺度特征
F
2
,
F
3
,
F
4
,
F
5
F_2,F_3,F_4,F_5
F2,F3,F4,F5,形状分别是
H
/
4
×
W
/
4
×
C
H/4\times W/4\times C
H/4×W/4×C、
H
/
8
×
W
/
8
×
C
H/8\times W/8\times C
H/8×W/8×C、
H
/
16
×
W
/
16
×
C
H/16\times W/16\times C
H/16×W/16×C、
H
/
32
×
W
/
32
×
C
H/32\times W/32\times C
H/32×W/32×C。自适应模块对该特征做上采样,使用
torch.nn.Upsample
\text{torch.nn.Upsample}
torch.nn.Upsample,
torch.nn.AdaptiveAvgPool2d
\text{torch.nn.AdaptiveAvgPool2d}
torch.nn.AdaptiveAvgPool2d操作和
1
×
1
1\times 1
1×1卷积层,得到形状为
H
/
4
×
W
/
4
×
C
H/4\times W/4\times C
H/4×W/4×C的特征图。然后,将采样特征 concate 到一起,使用
1
×
1
1\times 1
1×1卷积得到
H
/
4
×
W
/
4
×
C
H/4\times W/4\times C
H/4×W/4×C形状的该视角的特征图。

2.6 消融实验
Components for camera stream
在下表,作者验证了相机流中每个组成的贡献。在基线模型中,多视角图像编码器采用 ResNet50 和 FPN,BEV 编码器延续了 LSS,使用的是 ResNet18,检测 head 为 PointPillars,只取得了
13.9
%
13.9\%
13.9%mAP 和
24.5
%
24.5\%
24.5%NDS。
通过下表,可以有多个发现:
- 将 ResNet18 BEV 编码器替换为本文简单的 BEV 编码模块,mAP 和 NDS 分别提升了 4 % 4\% 4%和 2.5 % 2.5\% 2.5%。
- 在 FPN 中加入自适应特征对齐模块可以提升检测效果 0.1 % 0.1\% 0.1%。
- 使用更大的 2D 主干 Dual-Swin-Tiny 可提升
4.9
%
4.9\%
4.9% mAP 和
4
%
4\%
4% NDS。
搭配了 PointPillars 下相机流最终取得了 22.9 % 22.9\% 22.9%mAP 和 31.1 % 31.1\% 31.1%NDS。

Dynamic fusion module
为了体现本文融合策略的优势,作者在三个不同的 3D 检测器上做了实验:PointPillars、CenterPoint、TransFusion。如下表,使用简单的 Channel & Spatial Fusion,BEVFusion 极大地提升了 PointPillars 的 LiDAR 流(mAP
35.1
%
→
51.6
%
35.1\%\rightarrow 51.6\%
35.1%→51.6%)、CenterPoint(mAP
57.1
%
→
63.0
%
57.1\%\rightarrow 63.0\%
57.1%→63.0%)、TransFusion(mAP
64.9
%
→
67.3
%
64.9\%\rightarrow 67.3\%
64.9%→67.3%)。当使用了自适应特征选取后,PointPillars、CenterPoint 和 TransFusion 分别又提升了
1.9
%
,
1.2
%
,
0.6
%
1.9\%, 1.2\%, 0.6\%
1.9%,1.2%,0.6%。这些结果证明了融合相机和 LiDAR BEV 特征的必要性,以及本文 dynamic fusion module 选取重要的融合特征的有效性。