基本概念:


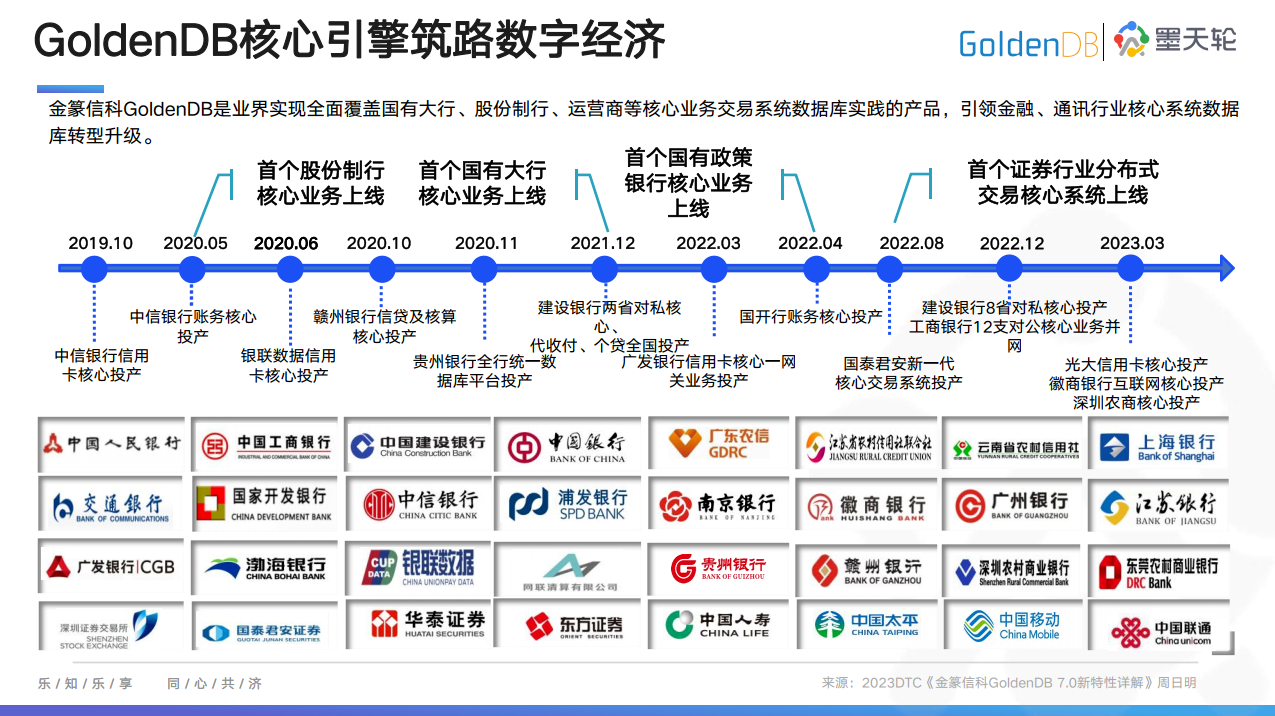
一、基本流程 b站王树森老师课程笔记
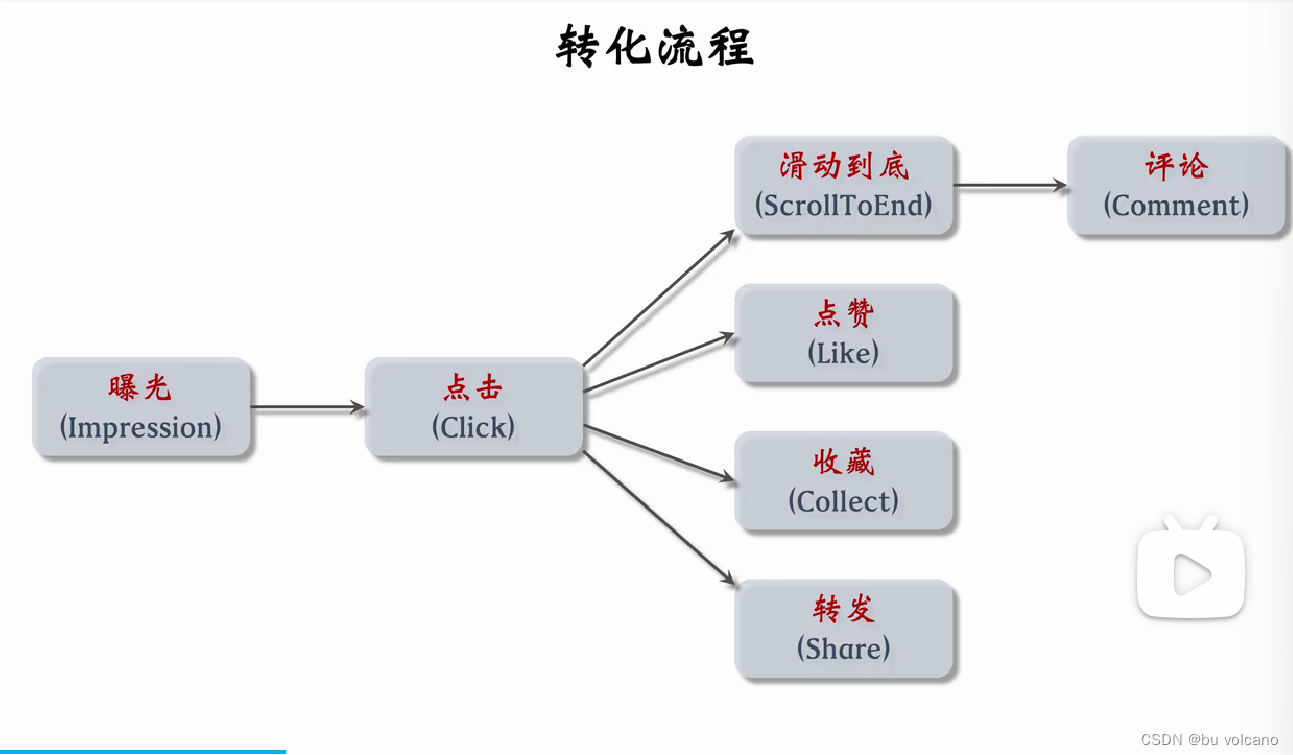
召回(retrieval):快速从海量数据中取回几千个用户可能感兴趣的物品。
方法:
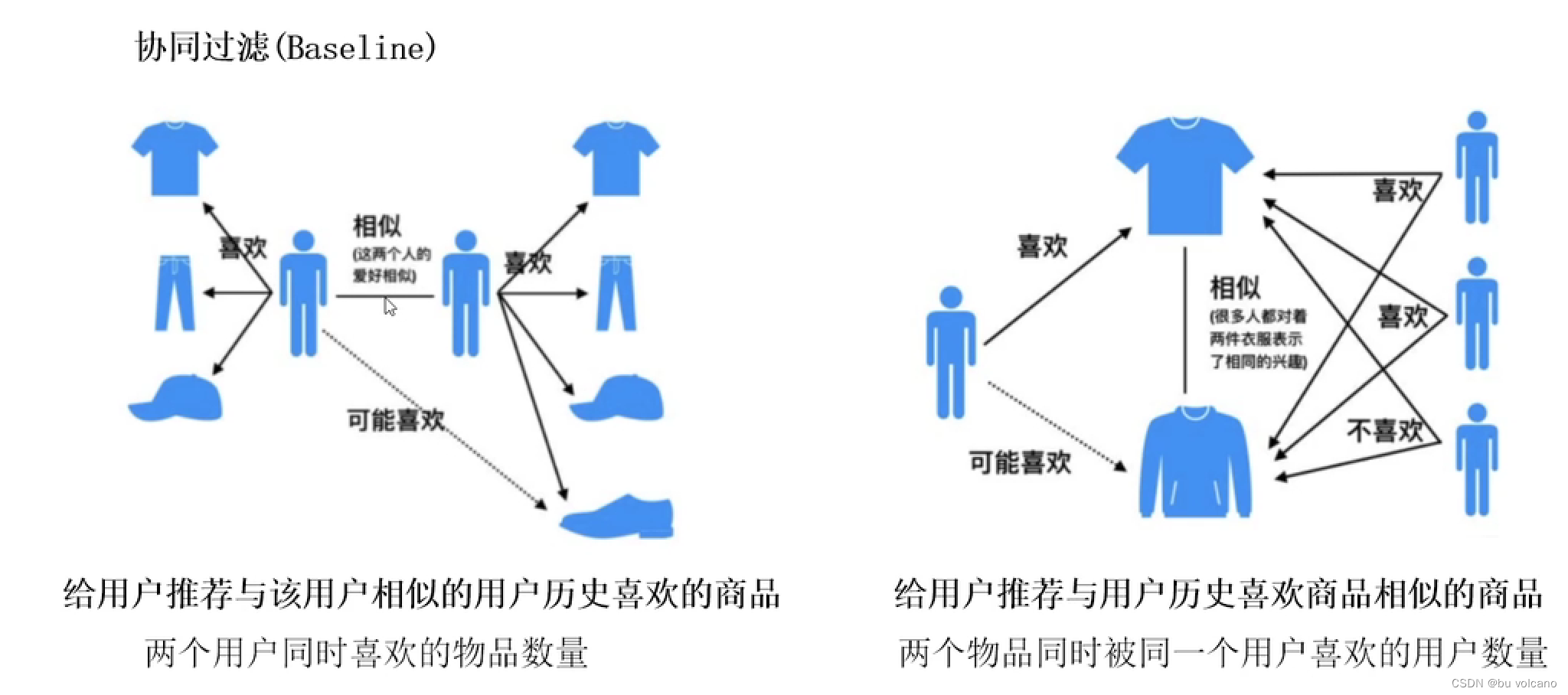
协同过滤
相似度计算:
余弦,
杰卡德
矩阵分解:
将一个稀疏的用户评分矩阵MxN分解为MxK KxN,分解出来的K就是隐语义特征
BiasSVD方法
jieba是中文分词包
hanlp情感分析工具包
关注的作者…
粗排:用小规模的模型的神经网络给召回的物品打分,然后做截断,选出分数最高的几百个物品。
精排:用大规模神经网络给粗排选中的几百个物品打分,可以做截断,也可以不做截断。
重拍:对精排结果做多样性抽样,得到几十个物品,然后用规则调整物品的排序。
方法:MMR、DPP
AB测试
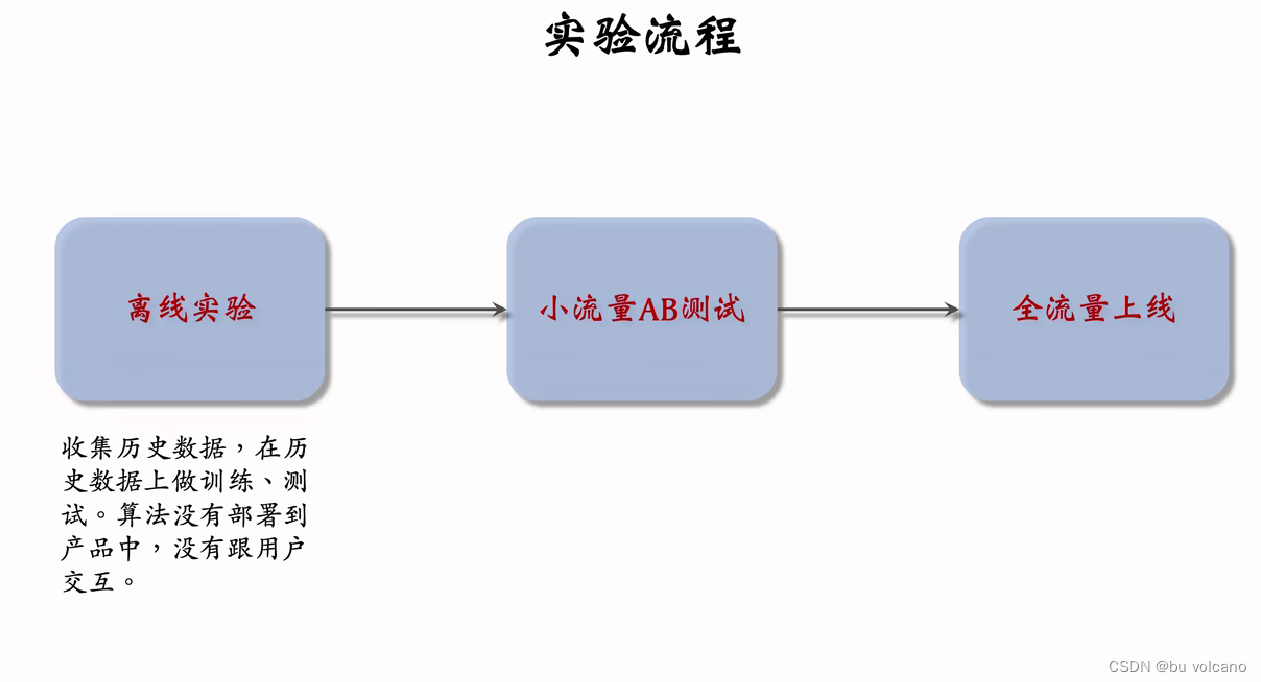
推荐系统算法工程师的日常工作就是改进模型和策略,目标是提升推荐系统的业务指标。所有对模型和策略的改进,都需要经过线上 AB 测试,用实验数据来验证模型和策略是否有效。
1.对用户进行随机分桶 用哈希函数映射到一个整数范围中
分层实验:(同层互斥,不同层正交)
在每一个阶段可以单独使用100%的全部用户,即同一层中某一用户不能受两种召回实验
Holdout :保留10%的用户﹐完全不受实验影响﹐可以考察整个部门对业务指标的贡献。
实验推全∶新建一个推全层﹐与其他层正交。
反转实验︰在新的推全层上﹐保留一个小的反转桶﹐使用旧策略·长期观测新旧策略的diff o
一、召回

协同压缩算法
基于用户的

log为了缩小最热门和最冷门的差距
基于物品的:
同时喜欢物品1,2的人÷喜欢物品1和物品2人的总和
Swing:
额外考虑重合的用户是否来自一个小圈子。
·同时喜欢两个物品的用户记作集合V 。
·对于V中的用户u1和u2,重合度记作overlap(u1,u2)
·两个用户重合度大,则可能来自一个小圈子,放在公式分母上来降低权重。
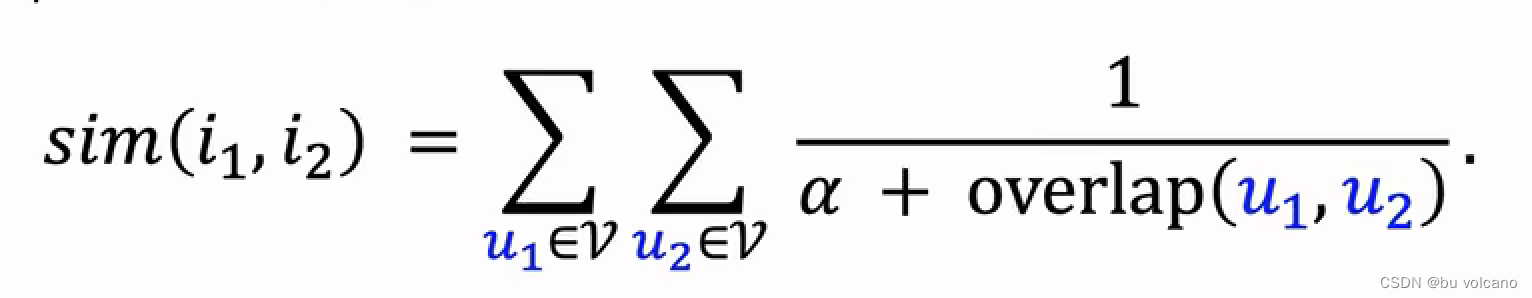
矩阵补充模型【5.8】
双塔模型:也叫 DSSM,是推荐系统中最重要的召回通道,没有之一
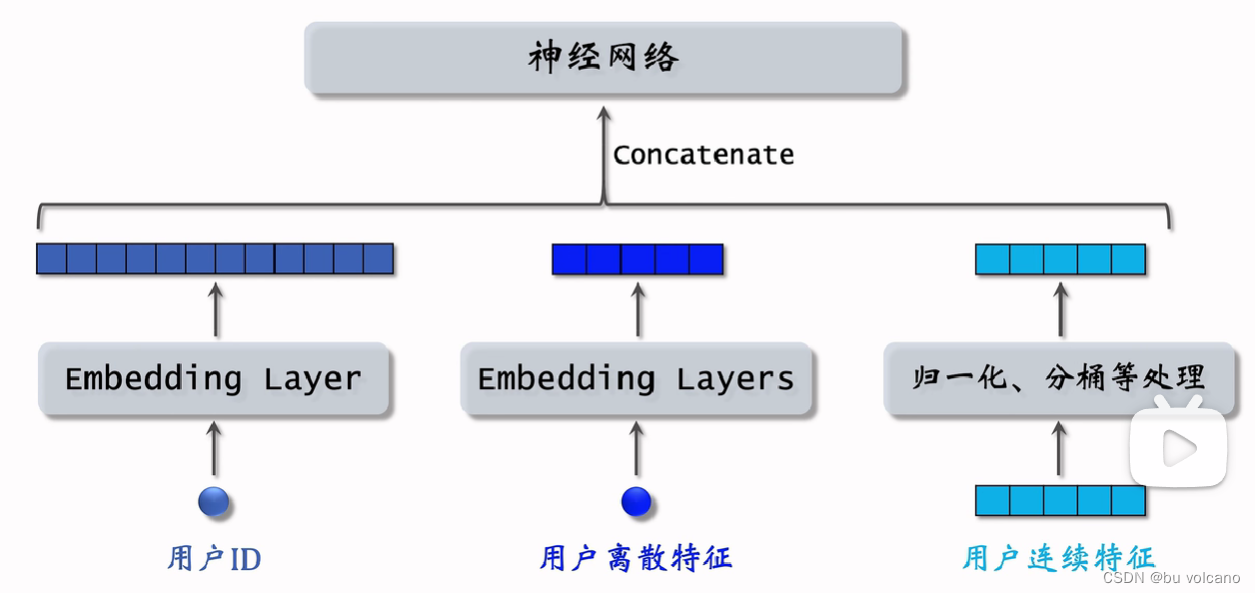
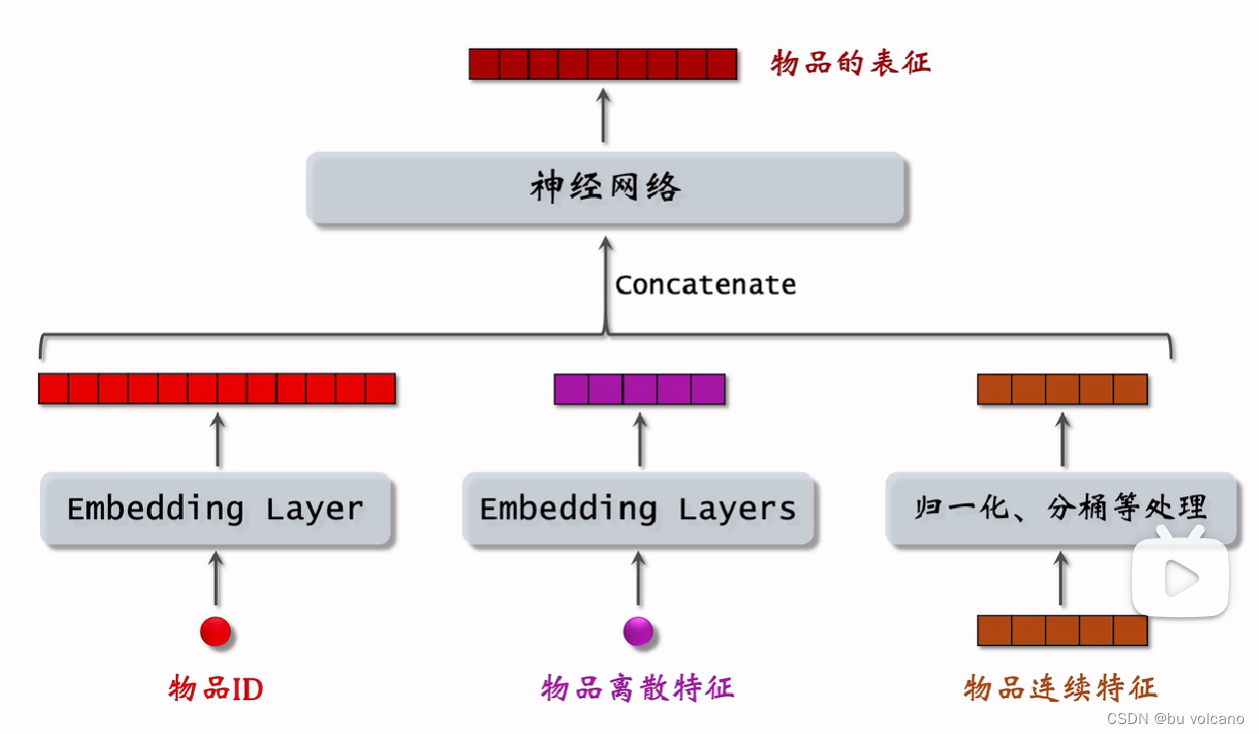
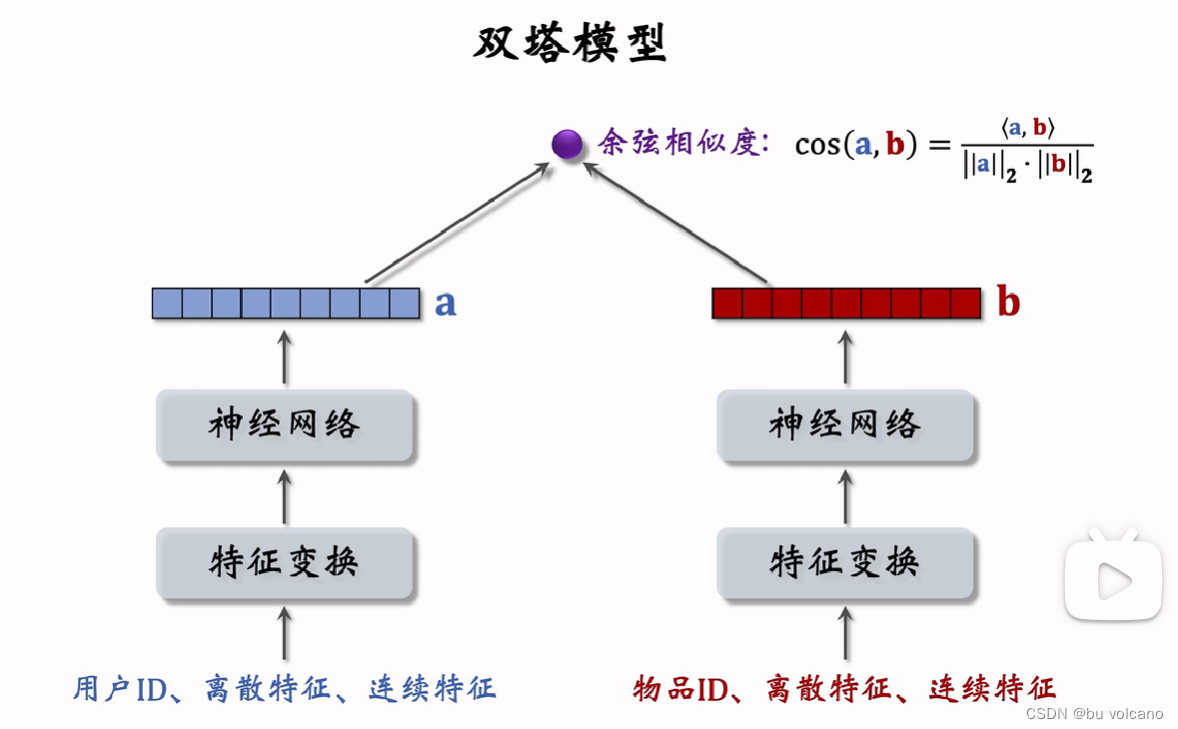


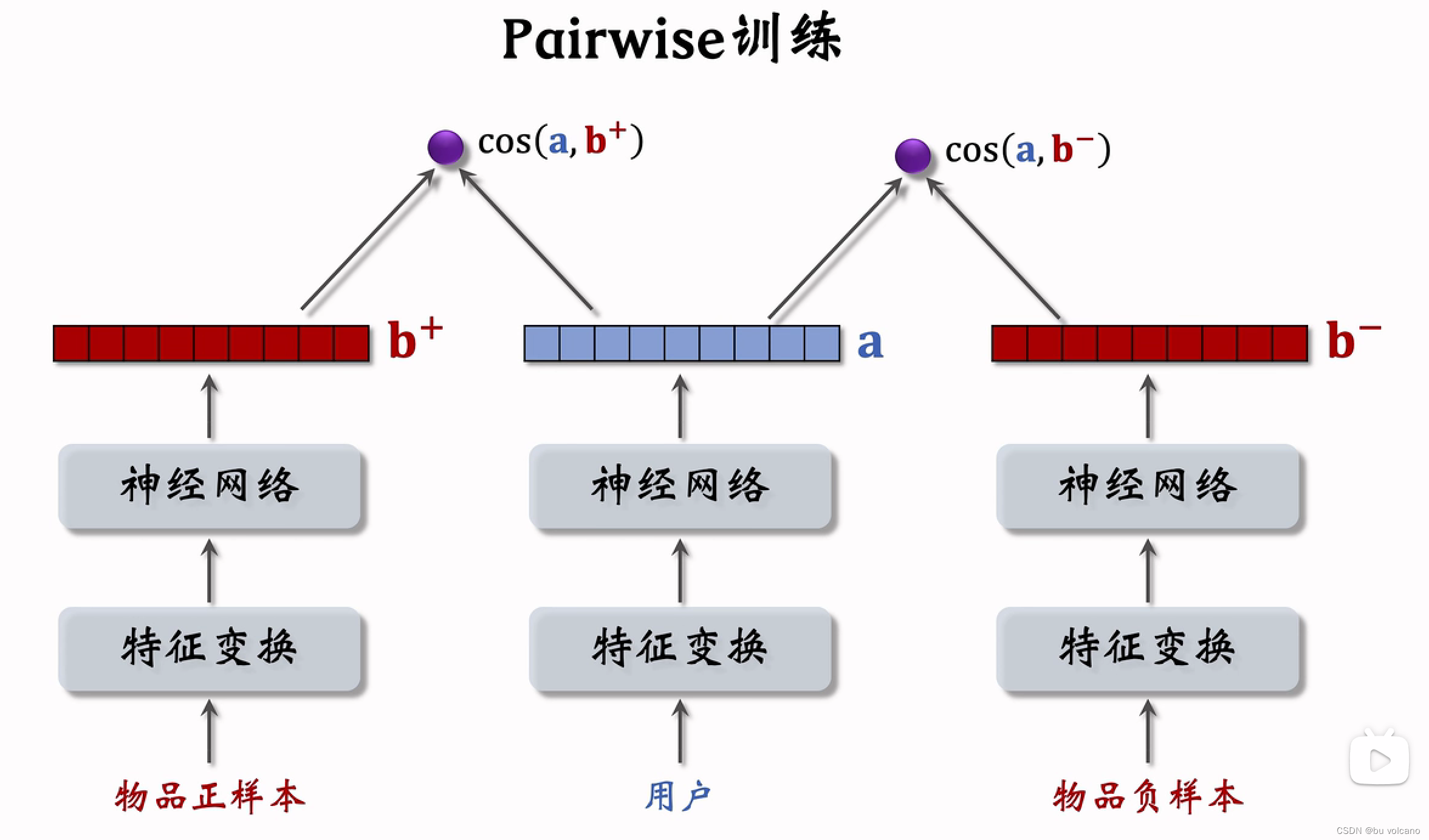

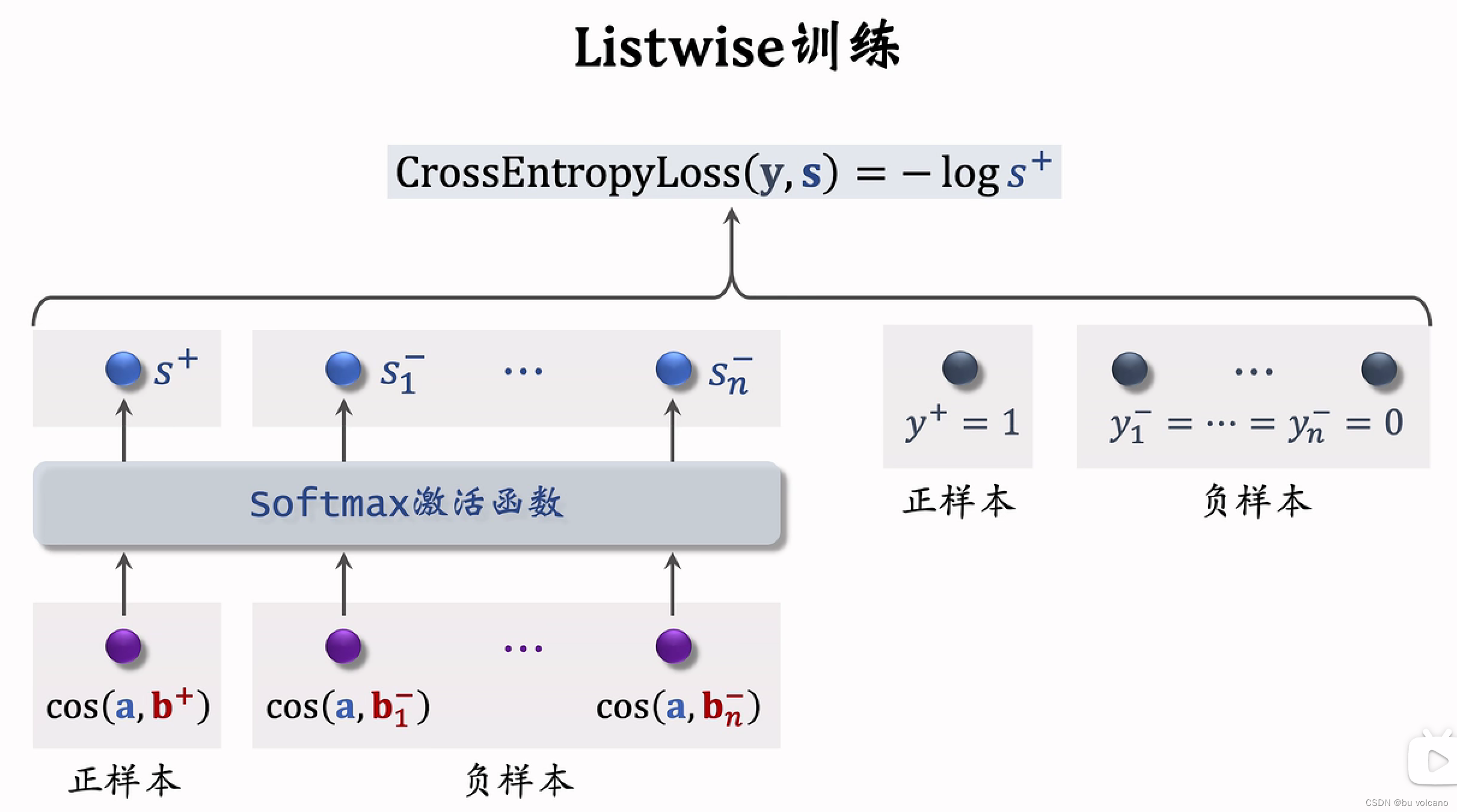
后期融合是召回
前期融合是粗排或精排
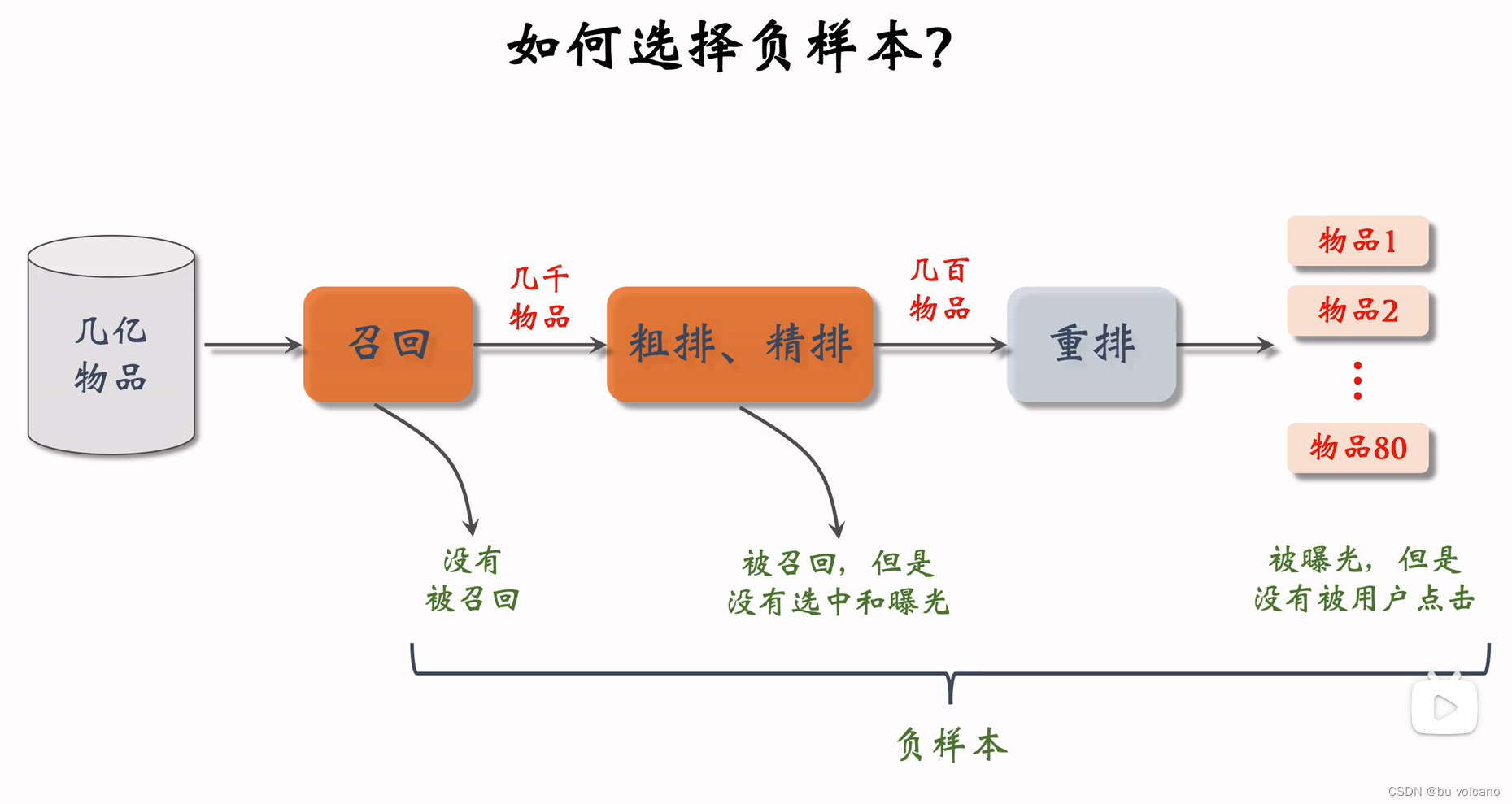
不能拿最后曝光用户没有点击的当做召回模型训练的负样本,因为这个推荐已经非常精确了
可以将这个当做排序的负样本,用来训练用户非常感兴趣样本和一般感兴趣样本的区别



双塔模型有缺点:
·推荐系统的头部效应严重∶
·少部分物品占据大部分点击。·大部分物品的点击次数不高。
·高点击物品的表征学得好﹐长尾物品的表征学得不好。
·自监督学习∶做data augmentation,更好地学习长尾物品的向量表征。
其余召回方式:
GeoHash:对经纬度的编码,地图上一个长方形区域,相当于同城召回
作者召回
有交互的作者
相似作者召回
缓存召回
二、排序
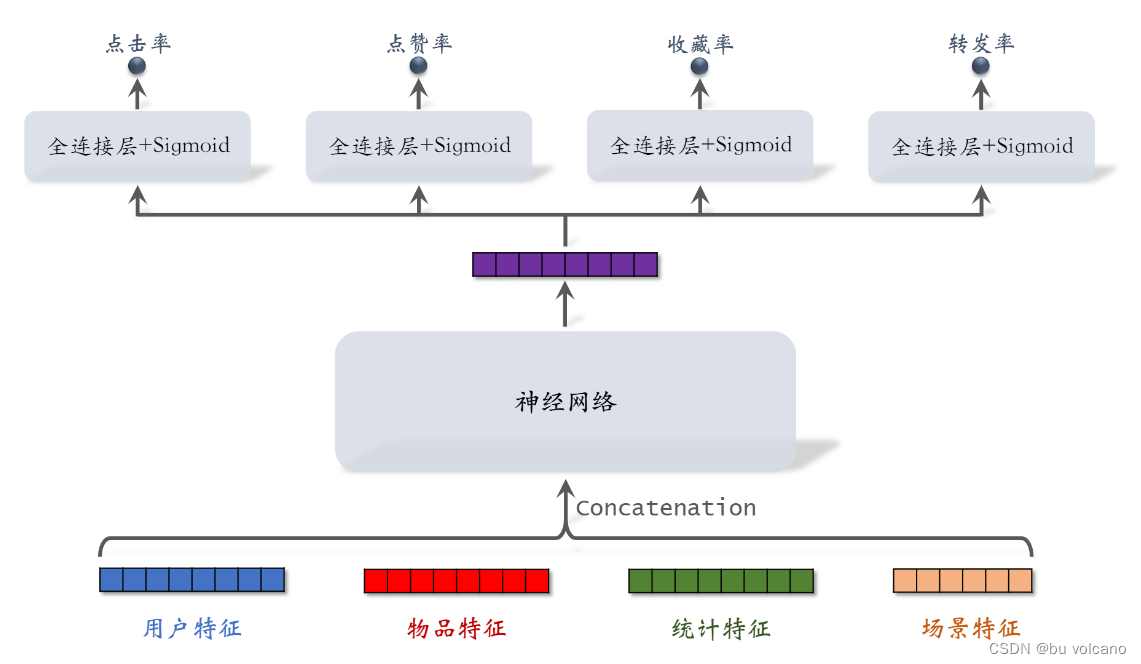
依据排序模型对点击率、点赞率、收藏率、转发率的预估分数,然后进行加权融合的总分数进行排序
多目标模型
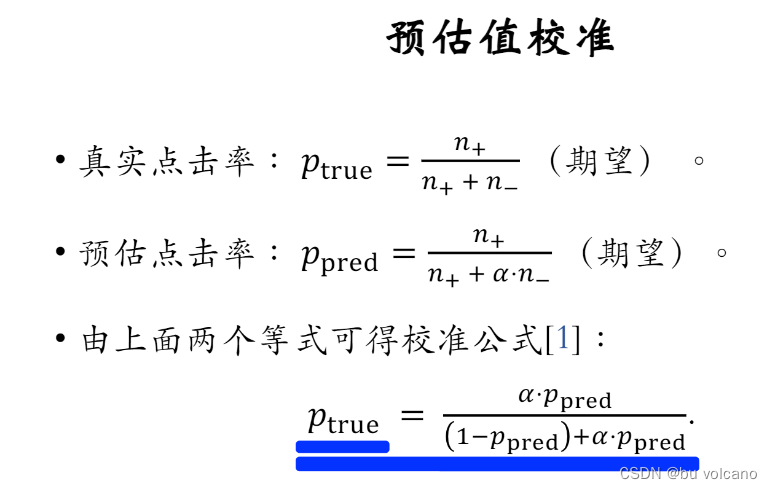
对负样本进行随机降采样,来消除样本的不平衡,但是因为负样本比真实时少了特别多,模型对点击率的预估会偏大,因此要对预测出来的值进行校准
MMOE
八、比赛实战-新闻推荐
1.分析理解过程
1.1题目理解
1.2数据集理解
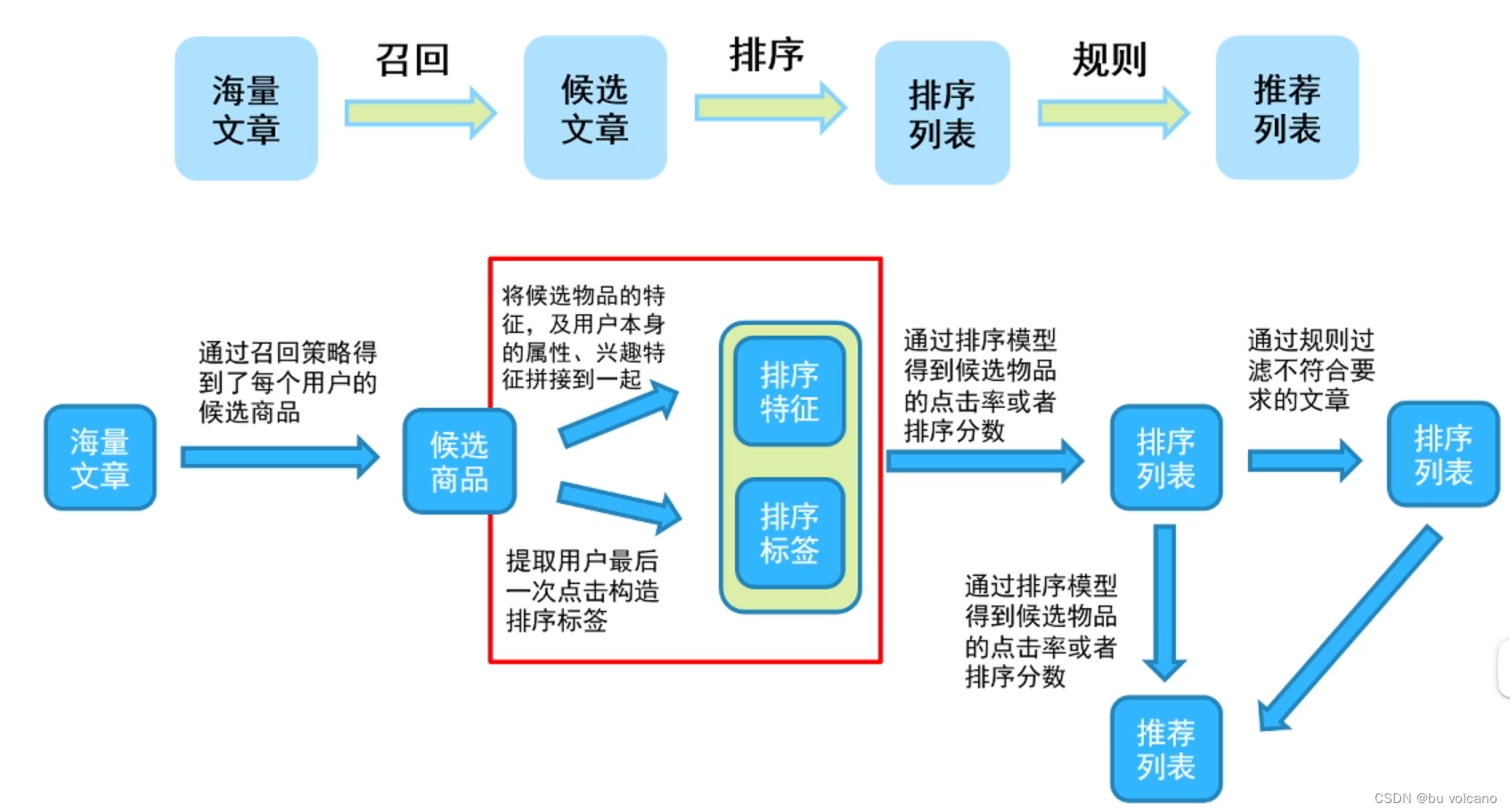
2.召回阶段
计算新闻相似度时,因为很多新闻没有被访问到,所以出现了很多0。因此采用循环访问每个人的新闻列表计算相似度。
3.特征工程
对召回得到的候选文章通过特征工程再次筛选达到一个比较精确的推荐结果.
因为召回时使用的模型比较简单且用户特征较少,仅使用了新闻之间的相似度;所以得出的候选文章不够精确。
因此对得出结果加上题目所给其余特征构造一个有监督的学习(每一个候选结果的label可以通过train_clieck_log的已知最后一次结果来构建)。
上一步结束后训练集仅有召回的特征,因此我们采用以下思路构造特征