18Spark中stage的划分 和 shuffle的概念
Stage的划分是根据宽依赖,当触发action算子时,按照从后往前的回溯算法,当遇到会发生shuffle算子的时候,就会切分stage。
Stage的划分本质是shuffle,即当遇到会发生shuffle算子的时候划分Stage。


Shufle又称洗牌,即将相同key按照一定的分配策略划分到同一个task中进行计算。当不同的节点上存在相同key的时候,这里会发生网络IO传输。
在大数据各种计算引擎技术中,一般都会遵循“移动数据不同移动计算”的原则。所以尽量减少shuffle的发生,因为会涉及到网络传输、序列和反序列等耗时操作,降低处理效率。
1、Spark的Shuffle借鉴了MapReduce的Shuffle
2、Spark的Shuffle过程是:上一个Stage的线程将处理的结果保存到磁盘上,由下一个Stage的线程来读取
3、由于Spark的Shuffle过程有磁盘IO操作,会影响Spark的处理速度
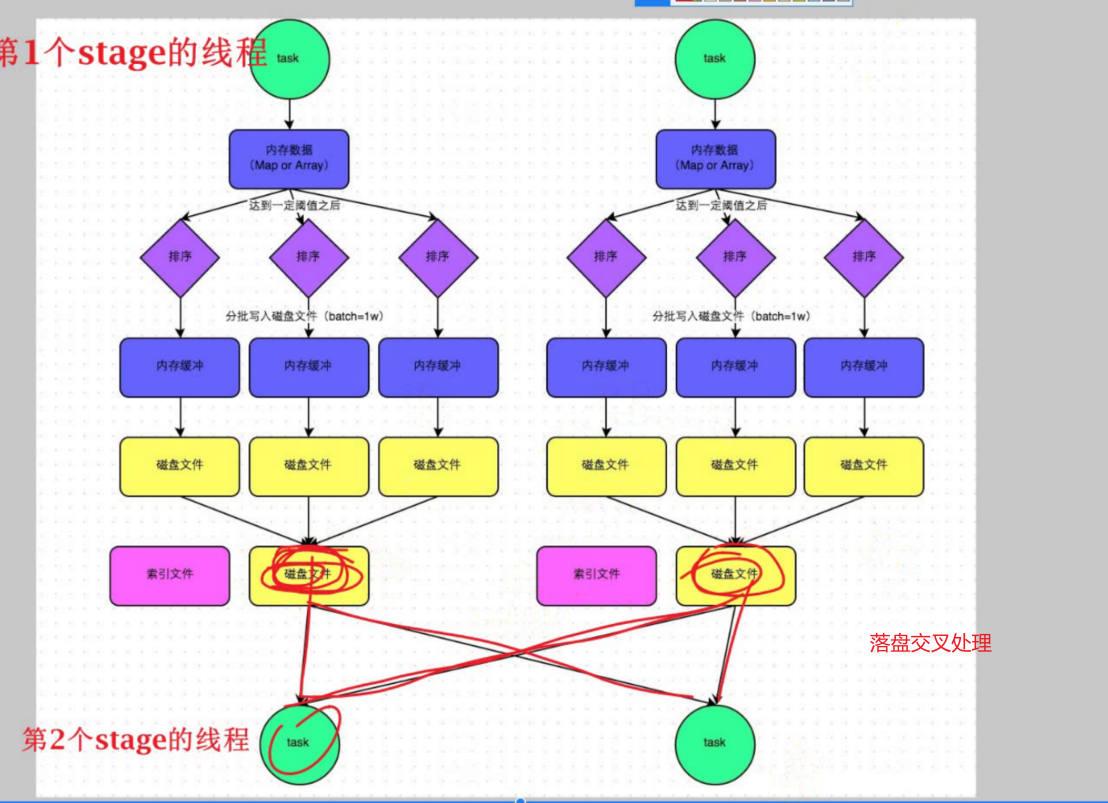

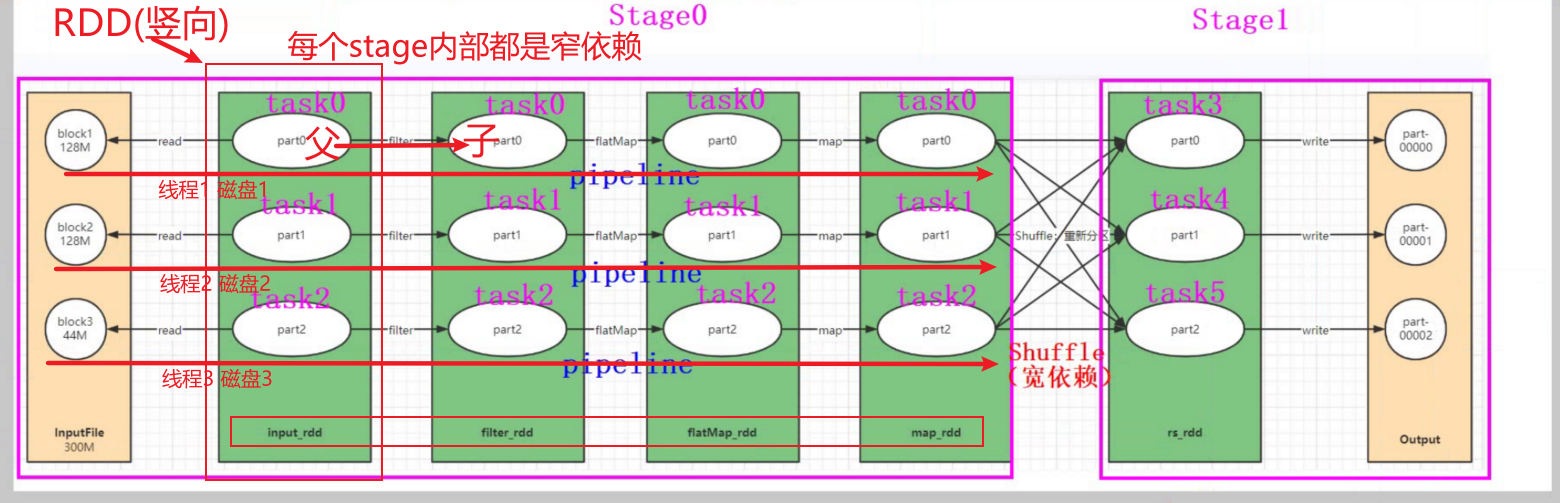
1、DAG基于宽依赖(Shuflle)被划分为多个State(阶段)
2、每个Stage阶段内部为窄依赖,可以组成PipLine
3、一个PipLine可以由一个Task所处理(一个线程),即每条PipLine的处理均是各自的线程处理,即内存中完成了PipLine的迭代
4、当第一个stage结束时,该stage的线程将会被释放,下一个stage重新开辟新的线程来处理。(数量经过处理后,大量减少,可以减小线程(分区))
19.RDD中数据的存储位置 和 特性
RDD中的数据在数据源,RDD只是一个抽象的数据集,我们通过对RDD的操作就相当于对数据进行操作。
RDD是Spark中最基本的数据抽象,是一个弹性分布式数据集,全称是Resilient Distributed DataSet。
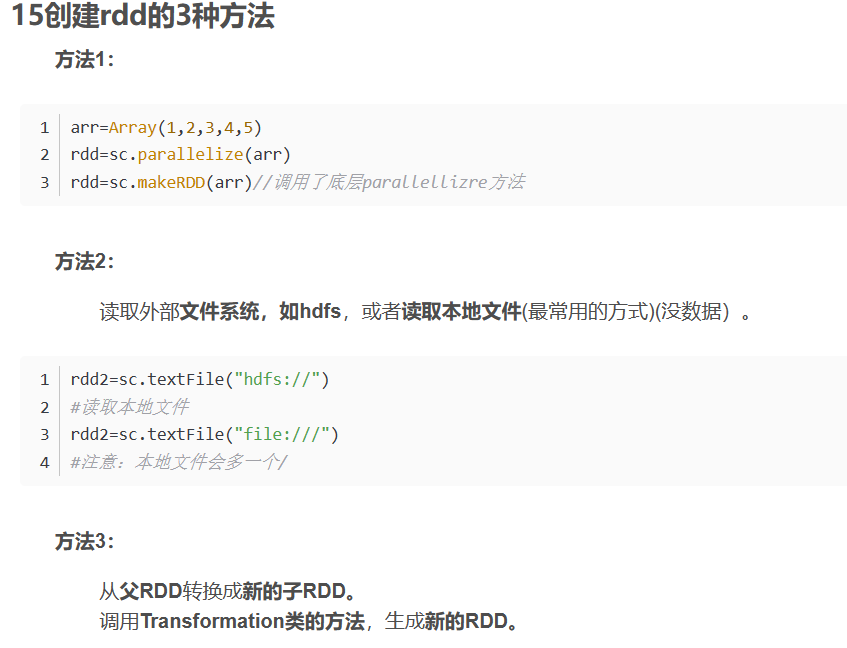


特性:分区,不可变,并行操作。
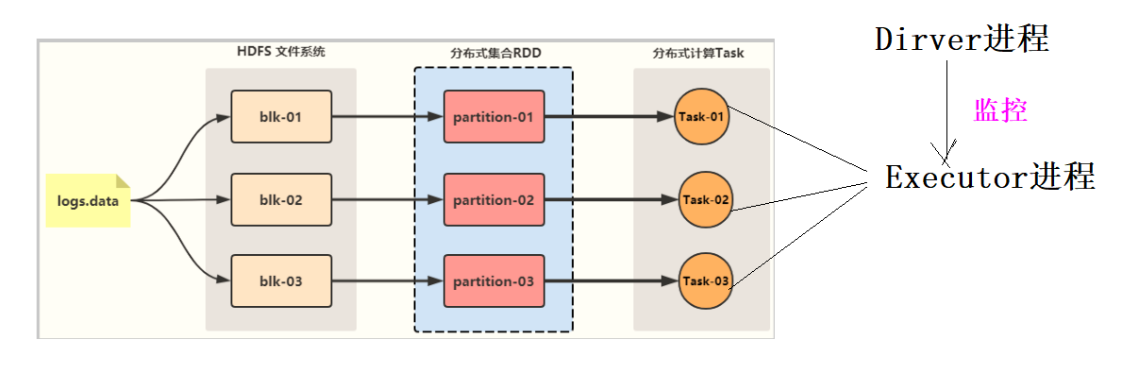
1)RDD是由一系列partition组成,textFile底层调用的是MR 读取HDFS上的数据的方法。
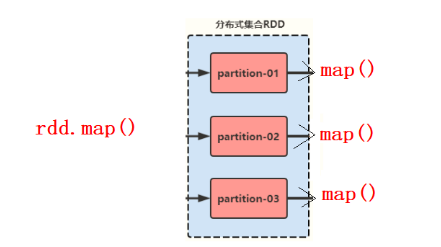
2)函数作用在每一个partition (split) 上(RDD调用算子本质是RDD的每个分区在调用算子)
3)RDD之间有一系列的依赖关系 (容错机制),每个RDD都会保存与其他RDD之间的依赖关系:血缘关系。
1、每一个RDD都会记录该RDD的血缘关系(知道它是怎么来的,它的上一级是什么)
2、每次要获取一个RDD时,必须根据学院关系,从头开始执行
4)可选的,如果是二元组【KV】类型的RDD,在Shuffle过程中可以自定义分区器。
5)RDD提供一系列最佳的计算位置。
1、Driver在分配每个Task给Executor时,会看看哪个Executor所在主机的数据离哪个Task最近,就会优先分配。

20.对RDD进行cache操作后,数据存储位置
数据在第一次执行cache算子时会被加载到各个Executor(真正计算的地方)进程的内存中,第二次就会直接从内存中读取而不会读取磁盘。

21.引起shuffle的算子分类
1)大部分含有byKey的算子都会发生shuffle,如reduceByKey、groupByKey、sortByKey,combineByKey 等
2)重分区类的算子:如repartition (其底层调用的是coalesce(shuffle=true)),coalesce等
3) join类的算子:比如join、cogroup等
4)去重类算子,如distinct