1、引言
阿里巴巴Java开发手册在第一章节,编程规约中OOP规约的第15条提到:
**【强制】**序列化类新增属性时,请不要修改serialVersionUID字段,避免反序列失败;如果完全不兼容升级,避免反序列化混乱,那么请修改serialVersionUID值。
说明:注意serialVersionUID不一致会抛出序列化运行时异常
如果没接触过序列化的人,应该会有以下疑问:
- 序列化和反序列化到底是什么?
- 它的主要使用场景有哪些?
- Java 序列化常见的方案有哪些?
- 各种常见序列化方案的区别有哪些?
- 实际的业务开发中有哪些坑点?
2、什么是序列化和反序列化
序列化是将内存中的对象信息转化成可以存储或者传输的数据到临时或永久存储的过程。在Java中其实就是把Java对象转换为二进制内容,其本质就是一个byte[]数组
反序列化是从临时或永久存储中读取序列化的数据并转化成内存对象的过程。在Java中就是将一个byte[]转换为Java对象的过程
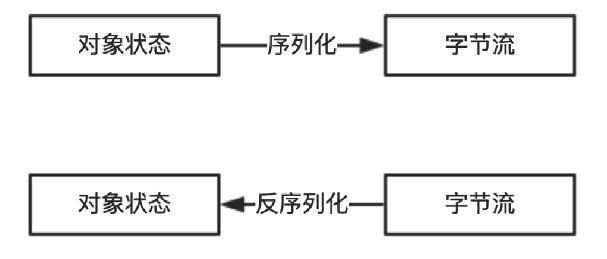
3、为什么需要序列化和反序列化呢?
大家可以回忆一下,平时都是如果将文字文件、图片文件、视频文件、软件安装包等传给小伙伴时,这些资源在计算机中存储的方式是怎样的。
进而再思考,Java 中的对象如果需要存储或者传输应该通过什么形式呢?
我们都知道,一个文件通常是一个 m 个字节的序列:B0, B1, …, Bk, …, Bm-1。所有的 I/O 设备(例如网络、磁盘和终端)都被模型化为文件,而所有的输入和输出都被当作对应文件的读和写来执行。
因此本质上讲,文本文件,图片、视频和安装包等文件底层都被转化为二进制字节流来传输的,对方得文件就需要对文件进行解析,因此就需要有能够根据不同的文件类型来解码出文件的内容的程序。
大家试想一个典型的场景:如果要实现 Java 远程方法调用,就需要将调用结果通过网路传输给调用方,如果调用方和服务提供方不在一台机器上就很难共享内存,就需要将 Java 对象进行传输。而想要将 Java 中的对象进行网络传输或存储到文件中,就需要将对象转化为二进制字节流,这就是所谓的序列化。存储或传输之后必然就需要将二进制流读取并解析成 Java 对象,这就是所谓的反序列化。
序列化的主要目的是:方便存储到文件系统、数据库系统或网络传输等。
4、序列化和反序列化的使用场景
- 远程方法调用(RPC)的框架里会用到序列化
- 将对象存储到文件中时,需要用到序列化
- 将对象存储到缓存数据库(如 Redis)时需要用到序列化
- 通过序列化和反序列化的方式实现对象的深拷贝
5、常见的序列化方式
常见的序列化方式包括 Java 原生序列化、Hessian 序列化、Kryo 序列化、JSON 序列化等。
1、Java原生序列化
学习的最好方式就是查看源码,我们接下来查看一下Serializable的源码
public interface Serializable {
}
源码非常简单,什么方法都没有,但是注释很长,其核心就是:
- Java 原生序列化需要实现 Serializable 接口。序列化接口不包含任何方法和属性等,它只起到序列化标识作用。
- 一个类实现序列化接口则其子类型也会继承序列化能力,但是实现序列化接口的类中有其他对象的引用,则其他对象也要实现序列化接口。序列化时如果抛出 NotSerializableException 异常,说明该对象没有实现 Serializable 接口。
- 每个序列化类都有一个叫 serialVersionUID 的版本号,反序列化时会校验待反射的类的序列化版本号和加载的序列化字节流中的版本号是否一致,如果序列化号不一致则会抛出 InvalidClassException 异常。
- 强烈推荐每个序列化类都手动指定其 serialVersionUID ,如果不手动指定,那么编译器会动态生成默认的序列化号,因为这个默认的序列化号和类的特征以及编译器的实现都有关系,很容易在反序列化时抛出 InvalidClassException 异常。建议将这个序列化版本号声明为私有,以避免运行时被修改。
- 实现序列化接口的类可以提供自定义的函数修改默认的序列化和反序列化行为。
上面注释也说明,建议序列化版本号声明为私有,以避免运行时被修改。
如果一个类文件序列化到文件后,类的结构发生了改变,是否能被正确的反序列化?
这个答案是不确定的。
通常我们是通过加密算法对文件进行前面,根据签名判断文件是否被修改;但Java序列化的场景并不适用于上述的方案,如果在类文件的某个地方加个空格,执行等符号类的结构,没有发生变化,这个时候签名就不应该发生变;还有一个类新增一个属性,之前的属性都是有值的,之前都被序列化到对象文件中,有些场景下还希望反序列化时可以正常解析,怎么办呢?
序列化测试代码:
public class SerializationTest {
public static void main(String[] args) throws IOException {
ByteArrayOutputStream buffer = new ByteArrayOutputStream();
try (ObjectOutputStream output = new ObjectOutputStream(buffer)) {
// 写入byte:
output.writeBytes("小熊学Java");
// 写入String:
output.writeUTF("Hello");
// 写入Object:
output.writeObject("javaxiaobear");
}
System.out.println(Arrays.toString(buffer.toByteArray()));
}
}
2、Hessian 序列化
Hessian 是一个动态类型,二进制序列化,也是一个基于对象传输的网络协议。Hessian 是一种跨语言的序列化方案,序列化后的字节数更少,效率更高。Hessian 序列化会把复杂对象的属性映射到 Map 中再进行序列化。
官方介绍👉Hessian 2.0 Serialization Protocol
和JDK自带的序列化方式类似,Hessian采用的也是二进制协议,只不过Hessian序列化之后,字节数更小,性能更优。目前Hessian已经出到2.0版本,相较于1.0的Hessian性能更优。相较于JDK自带的序列化,Hessian的设计目标更明确👇
Hessian 是动态类型的、紧凑的,并且可以跨语言移植。Hessian 协议有以下设计目标:
- 它必须是单次可读或可写的。
- 它必须尽可能紧凑。
- 它必须简单,以便可以有效地测试和实施。
- 它必须尽可能快。
- 它必须支持 Unicode 字符串。
- 它必须支持 8 位二进制数据而不转义或使用附件。
- 它必须支持加密、压缩、签名和事务上下文信封。
Hessian的序列化速度相较于JDK序列化才更快。只不过Java序列化会把要序列化的对象类的元数据和业务数据全部序列化从字节流,并且会保留完整的继承关系,因此相较于Hessian序列化更加可靠。
不过相较于JDK的序列化,Hessian另一个优势在于,这是一个跨语言的序列化方式,这意味着序列化后的数据可以被其他语言使用,兼容性更好。
基础使用
引入pom依赖
<!-- https://mvnrepository.com/artifact/com.caucho/hessian -->
<dependency>
<groupId>com.caucho</groupId>
<artifactId>hessian</artifactId>
<version>4.0.65</version>
</dependency>
不服,咱跑个分
public class SerializationTest {
public static void main(String[] args) throws IOException {
String javaxiaobear = "小熊学Java";
System.out.println("JDK序列化长度:" + jdkSerialize(javaxiaobear).length);
System.out.println("hessian序列化长度:" + hessianSerialize(javaxiaobear).length);
}
/**
* jdk序列化测试
* @param str
* @return
* @param <T>
*/
public static <T> byte[] jdkSerialize(T str){
byte[] data = null;
try{
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
ObjectOutputStream output = new ObjectOutputStream(byteArrayOutputStream);
output.writeObject(str);
output.flush();
output.close();
data = byteArrayOutputStream.toByteArray();
}catch (Exception e){
e.printStackTrace();
}
return data;
}
/**
* hessian序列化测试
* @param str
* @return
* @param <T>
*/
public static <T> byte[] hessianSerialize(T str){
byte[] data = null;
try{
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
Hessian2Output output = new Hessian2Output(byteArrayOutputStream);
output.writeObject(str);
output.flush();
output.close();
data = byteArrayOutputStream.toByteArray();
}catch (Exception e){
e.printStackTrace();
}
return data;
}
}
输出结果:
//JDK序列化长度:20
//hessian序列化长度:14
3、Kryo 序列化
Kryo 是一个快速高效的 Java 序列化和克隆工具。Kryo 的目标是快速、字节少和易用。Kryo 还可以自动进行深拷贝或者浅拷贝。Kryo 的拷贝是对象到对象的拷贝而不是对象到字节,再从字节到对象的恢复。Kryo 为了保证序列化的高效率,会提前加载需要的类,这会带一些消耗,但是这是序列化后文件较小且反序列化非常快的重要原因。
官方地址:kryo
基础使用
这里只作为基础使用,不作为重点讲解,需要了解的可以去查看官方文档哈
- 引入pom依赖,这里需要JDK11编译哦
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>5.4.0</version>
</dependency>
测试demo
public static void main(String[] args) throws IOException {
String javaxiaobear = "小熊学Java";
System.out.println("JDK序列化长度:" + jdkSerialize(javaxiaobear).length);
System.out.println("hessian序列化长度:" + hessianSerialize(javaxiaobear).length);
User user = new User("小熊学Java");
byte[] bytes = kryoSerialize(user);
System.out.println("kryo序列化的长度:" + bytes.length);
}
/**
* kryo序列化
* @param user
* @return
*/
public static byte[] kryoSerialize(User user) {
Kryo kryo = new Kryo();
kryo.register(user.getClass());
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Output output = new Output(bos);
//写入null时会报错
kryo.writeObject(output,user);
output.close();
return bos.toByteArray();
}
结果:kryo序列化的长度:14
4、JSON 序列化
JSON (JavaScript Object Notation) 是一种轻量级的数据交换方式。JSON 序列化是基于 JSON 这种结构来实现的。JSON 序列化将对象转化成 JSON 字符串,JSON 反序列化则是将 JSON 字符串转回对象的过程。常用的JSON 序列化和反序列化的库有 Jackson、GSON、Fastjson 等。
1、GSON
Gson提供了fromJson() 和toJson() 两个直接用于解析和生成的方法,前者实现反序列化,后者实现了序列化;同时每个方法都提供了重载方法。
跑个demo
/**
* Gson 序列化 与反序列化
* @param user
*/
public static void gsonSerialize(User user){
//gson序列化
String userJson = new Gson().toJson(user);
System.out.println("gson序列化后的值:" + userJson);
//gson反序列化
User user1 = new Gson().fromJson(userJson, User.class);
System.out.println("gson反序列化后:" + user1.toString());
}
6、Java 常见的序列化方案对比
实验的版本:kryo-shaded 使用 5.4.0版本,gson 使用 2.8.5 版本,hessian 用
4.0.65版本。
实验的数据:构造 50 万 User 对象运行多次。
大致得出一个结论:
从二进制流大小来讲:JSON 序列化 > Java 序列化 > Hessian2 序列化 > Kryo 序列化 > Kryo 序列化注册模式;
从序列化耗时而言来讲:GSON 序列化 > Java 序列化 > Kryo 序列化 > Hessian2 序列化 > Kryo 序列化注册模式;
从反序列化耗时而言来讲:GSON 序列化 > Java 序列化 > Hessian2 序列化 > Kryo 序列化注册模式 > Kryo序列化;
从总耗时而言:Kryo 序列化注册模式耗时最短。
7、序列化引发的一个血案
我们看下面的一个案例
前端调用服务 A,服务 A 调用服务 B,服务 B 首次接到请求会查 DB,然后缓存到 Redis(缓存 1 个小时)。服务 A 根据服务 B 返回的数据后执行一些处理逻辑,处理后形成新的对象存到 Redis(缓存 2 个小时)。服务 A 通过 Dubbo 来调用服务 B,A 和 B 之间数据通过 Map<String,Object> 类型传输,服务 B 使用Fastjson 来实现 JSON 的序列化和反序列化。
服务 B 的接口返回的 Map 值中存在一个 Long 类型的 id 字段,服务 A 获取到 Map ,取出 id 字段并强转为 Long 类型使用。
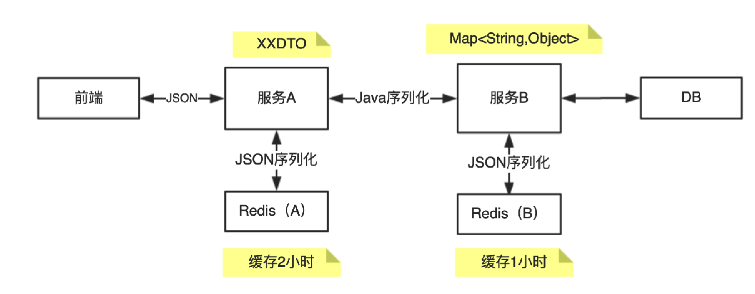
通过分析我们发现,服务 A 和服务 B 的 RPC 调用使用 Java 序列化,因此类型信息不会丢失。
但是由于服务 B 采用 JSON 序列化进行缓存,第一次访问没啥问题,其执行流程如下:
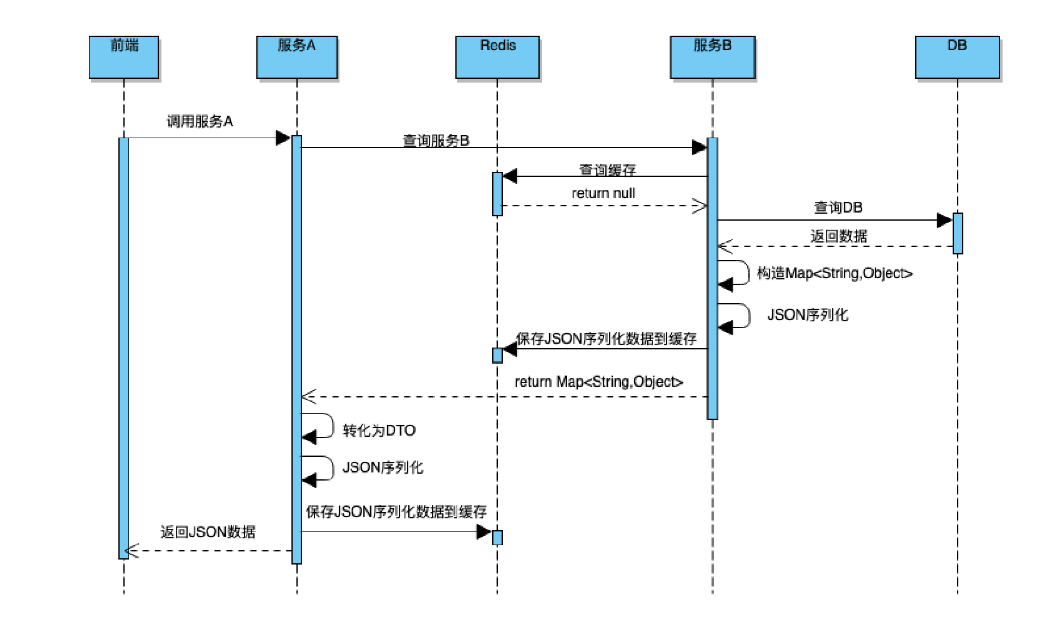
如果服务 A开启了缓存 ,服务 A 在第一次请求服务 B 后,缓存了运算结果,且服务 A 缓存时间比服务 B 长,因此不会出现错误。
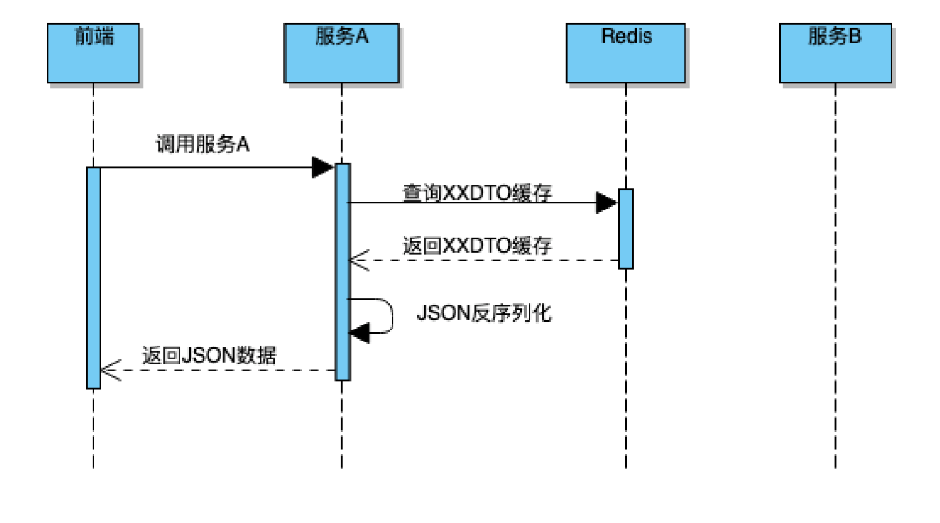
如果服务 A 不开启缓存 ,服务 A 会请求服务 B ,由于首次请求时,服务 B 已经缓存了数据,服务 B 从Redis(B)中反序列化得到 Map 。流程如下图所示:
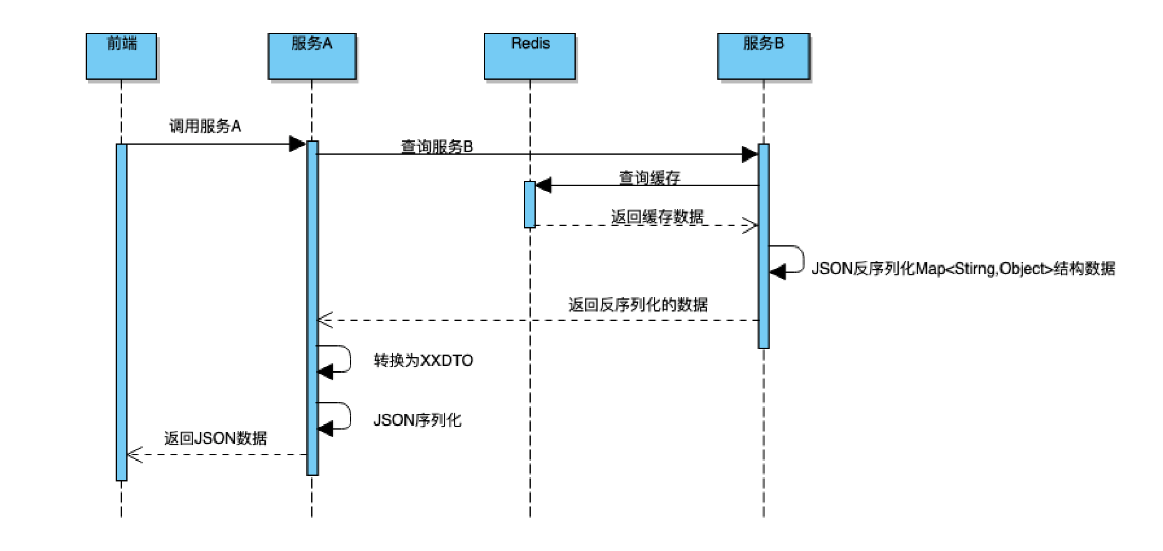
然而问题来了: 服务 A 从 Map 取出此 Id 字段,强转为 Long 时会出现类型转换异常。
最后定位到原因是 Json 反序列化 Map 时如果原始值小于 Int 最大值,反序列化后原本为 Long 类型的字段,变为了 Integer 类型,服务 B 的同学紧急修复。
服务 A 开启缓存时, 虽然采用了 JSON 序列化存入缓存,但是采用 DTO 对象而不是 Map 来存放属性,所以JSON 反序列化没有问题。
因此大家使用二方或者三方服务时,当对方返回的是 Map<String,Object> 类型的数据时要特别注意这个问题。
作为服务提供方,可以采用 JDK 或者 Hessian 等序列化方式;
作为服务的使用方,我们不要从 Map 中一个字段一个字段获取和转换,可以使用 JSON 库直接将 Map 映射成所需的对象,这样做不仅代码更简洁还可以避免强转失败。
来个demo
@Test
public void testFastJsonObject() {
Map<String, Object> map = new HashMap<>();
final String name = "name";
final String id = "id";
map.put(name, "张三");
map.put(id, 20L);
String fastJsonString = FastJsonUtil.getJsonString(map);
// 模拟拿到服务B的数据
Map<String, Object> mapFastJson = FastJsonUtil.parseJson(fastJsonString,map.getClass());
// 转成强类型属性的对象而不是使用map 单个取值
User user = new JSONObject(mapFastJson).toJavaObject(User.class);
// 正确
Assert.assertEquals(map.get(name), user.getName());
// 正确
Assert.assertEquals(map.get(id), user.getId());
}
8、总结
主要描述了Java序列化的场景和使用,以及案例分析,在开发中我们还是要注意细节,避开趟坑!

![[数据库系统] 四、分组操作符与聚集函数](https://img-blog.csdnimg.cn/60660ebbc88d42d6a69912bb1cef925e.png)