SimCLS:摘要总结的对比学习(1)
- 写在最前面
- 2 抽象总结的对比学习框架
写在最前面
SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization(2021ACL会议)
https://arxiv.org/abs/2106.01890
论文:https://arxiv.org/pdf/2106.01890.pdf

预期写几篇博客详细展示该论文
2 抽象总结的对比学习框架
给定一个源文档D和一个参考摘要Sˆ,抽象摘要模型f的目标是生成候选摘要S = f(D),以便它获得由评估度量M分配的最高分数m = M(S, Sˆ)。
在这项工作中,我们将整体生成过程分为两个阶段,其中包括:
1、生成模型g,用于生成候选摘要,
2、评估模型h,用于评分和选择最佳候选摘要。
第一阶段:
候选摘要生成 生成模型g(·)是一个经过训练的Seq2Seq模型,在给定源文档D的情况下最大限度地提高参考摘要Sˆ的可能性。
然后使用预先训练的g(·)生成多个候选摘要S1, · · · , Sn,并使用Beam Search等抽样策略,其中n是抽样候选的数量。
第二阶段:
无参考评价高级的想法是,一个更好的候选摘要Si应该比源文档D获得更高的质量分数。
我们通过对比学习来接近上述思想,
并定义了一个评价函数h(·)的目的是仅根据源文档和候选人Si之间的相似性为生成的候选人分配不同的分数r1, · · · , rn,即ri = h(Si , D)。最终输出总结S是得分最高的候选:
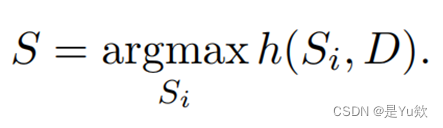
在这里,我们将h(·)实例化为一个预先训练好的大型自我注意模型RoBERTa (Liu et al., 2019)。它被用来分别编码Si和D,第一个令牌编码之间的余弦相似度被用作相似度得分ri。
对比训练而不是明确地构建一个积极或消极的例子,大多数现有的工作与对比学习已经采用(Chen et al., 2020; Wu et al., 2020),这里的“对比”反映在自然生成的总结的不同品质评估参数化模型h(·)。具体来说,我们为h(·)引入一个排名损失:
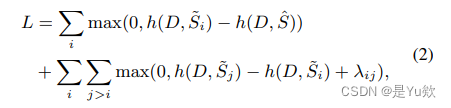
其中S˜ 1, · · · , S˜ n按M(S˜ i , Sˆ)向下排序。
这里,λij = (j − i) * λ是我们在Zhong et al. (2020)后面定义的相应的边距,λ是一个超参数。1
M可以是任何自动评估指标或人类判断,这里我们使用ROUGE (Lin, 2004)。
1由于它不敏感,我们在实验中将其设置为0.01。
![[GFCTF 2021] day2](https://img-blog.csdnimg.cn/b1be61f140f8408f9e5e21fcf350aee5.png)






![数青蛙、[USACO10FEB]Chocolate Giving S](https://img-blog.csdnimg.cn/e71c826a97104009a2c74f288f3db98d.png)
![[mini LCTF 2023] 西电的部分](https://img-blog.csdnimg.cn/7cd0c91779834e17ae306eebad047ac7.png)


