【力扣周赛】第344场周赛
- 6416:找出不同元素数目差数组
- 题目描述
- 解题思路
- 6417:频率跟踪器
- 题目描述
- 解题思路
- 6418:有相同颜色的相邻元素数目
- 题目描述
- 解题思路
- 6419:使二叉树所有路径值相等的最小代价
- 题目描述
- 解题思路
6416:找出不同元素数目差数组
题目描述
描述:给你一个下标从 0 开始的数组 nums ,数组长度为 n 。
nums 的 不同元素数目差 数组可以用一个长度为 n 的数组 diff 表示,其中 diff[i] 等于前缀 nums[0, …, i] 中不同元素的数目 减去 后缀 nums[i + 1, …, n - 1] 中不同元素的数目。
返回 nums 的 不同元素数目差 数组。
注意 nums[i, …, j] 表示 nums 的一个从下标 i 开始到下标 j 结束的子数组(包含下标 i 和 j 对应元素)。特别需要说明的是,如果 i > j ,则 nums[i, …, j] 表示一个空子数组。
输入:nums = [1,2,3,4,5]
输出:[-3,-1,1,3,5]
解释:
对于 i = 0,前缀中有 1 个不同的元素,而在后缀中有 4 个不同的元素。因此,diff[0] = 1 - 4 = -3 。
对于 i = 1,前缀中有 2 个不同的元素,而在后缀中有 3 个不同的元素。因此,diff[1] = 2 - 3 = -1 。
对于 i = 2,前缀中有 3 个不同的元素,而在后缀中有 2 个不同的元素。因此,diff[2] = 3 - 2 = 1 。
对于 i = 3,前缀中有 4 个不同的元素,而在后缀中有 1 个不同的元素。因此,diff[3] = 4 - 1 = 3 。
对于 i = 4,前缀中有 5 个不同的元素,而在后缀中有 0 个不同的元素。因此,diff[4] = 5 - 0 = 5 。
输入:nums = [3,2,3,4,2]
输出:[-2,-1,0,2,3]
解释:
对于 i = 0,前缀中有 1 个不同的元素,而在后缀中有 3 个不同的元素。因此,diff[0] = 1 - 3 = -2 。
对于 i = 1,前缀中有 2 个不同的元素,而在后缀中有 3 个不同的元素。因此,diff[1] = 2 - 3 = -1 。
对于 i = 2,前缀中有 2 个不同的元素,而在后缀中有 2 个不同的元素。因此,diff[2] = 2 - 2 = 0 。
对于 i = 3,前缀中有 3 个不同的元素,而在后缀中有 1 个不同的元素。因此,diff[3] = 3 - 1 = 2 。
对于 i = 4,前缀中有 3 个不同的元素,而在后缀中有 0 个不同的元素。因此,diff[4] = 3 - 0 = 3 。
解题思路
难度:简单。
思路:最直观的想法是,使用一个数组prefix[i]表示前缀nums[0…i]中不同元素的数目,使用一个数组postfix[i]表示后缀nums[i+1…n-1]中不同元素的数目,使用一个数组res[i]表示前缀数目减去后缀数目,使用一个uset1存储从前向后遍历的不重复的元素,使用一个uset2存储从后向前遍历的不重复的元素。首先从前向后遍历填充prefix,若当前元素在uset1中找不到则prefix[i]=prefix[i-1]+1并将其插入uset1,反之则prefix[i]=prefix[i-1];接着从后向前遍历填充postfix,若当前元素在uset2中找不到则prefix[i]=prefix[i+1]+1并将其插入uset2,反之则postfix[i]=postfix[i+1];最后从前向后遍历填充res,其为res[i]=prefix[i]-postfix[i]。注意边界条件的处理喔!
class Solution {
public:
vector<int> distinctDifferenceArray(vector<int>& nums) {
int n=nums.size();
vector<int> prefix(n,0);
prefix[0]=1;
vector<int> postfix(n,0);
postfix[n-1]=1;
vector<int> res(n,0);
if(n==1)
{
res[0]=prefix[0]-0;
return res;
}
unordered_set<int> uset1;
uset1.emplace(nums[0]);
unordered_set<int> uset2;
uset2.emplace(nums[n-1]);
//填充前缀数组
cout<<"prefix:";
for(int i=1;i<n;i++)
{
//出现重复
if(uset1.find(nums[i])!=uset1.end())
prefix[i]=prefix[i-1];
//第一次出现
else
{
prefix[i]=prefix[i-1]+1;
uset1.emplace(nums[i]);
}
cout<<prefix[i]<<" ";
}
cout<<endl;
//填充后缀数组
cout<<"postfix:";
for(int i=n-2;i>=0;i--)
{
//出现重复
if(uset2.find(nums[i])!=uset2.end())
postfix[i]=postfix[i+1];
//第一次出现
else
{
postfix[i]=postfix[i+1]+1;
uset2.emplace(nums[i]);
}
cout<<postfix[i]<<" ";
}
cout<<endl;
for(int i=0;i<n-1;i++)
res[i]=prefix[i]-postfix[i+1];
res[n-1]=prefix[n-1]-0;
return res;
}
};
优化:其实可以使用prefix.size()表示前缀数目,使用postfix.size()表示后缀数目。既然prefix和res均是从前向后遍历,则可以将其合并处理,即先后向遍历推出postfix,然后前向遍历推出prefix和res。
vector<int> distinctDifferenceArray(vector<int>& nums)
{
int n=nums.size();
vector<int> prefix(n,0); //前缀数目
vector<int> postfix(n,0); //后缀数目
vector<int> res(n,0); //结果数组
unordered_set<int> uset1; //前向遍历不重复元素
unordered_set<int> uset2; //后向遍历不重复元素
//后向遍历填充后缀数组
for(int i=n-1;i>=0;i--)
{
postfix[i]=uset2.size();
uset2.emplace(nums[i]); //存在则插入 不存在则啥也不做
}
//前向遍历填充前缀数组和结果数组
for(int i=0;i<n;i++)
{
uset1.emplace(nums[i]);
prefix[i]=uset1.size();
res[i]=prefix[i]-postfix[i];
}
return res;
}
6417:频率跟踪器
题目描述
描述:请你设计并实现一个能够对其中的值进行跟踪的数据结构,并支持对频率相关查询进行应答。
实现 FrequencyTracker 类:
FrequencyTracker():使用一个空数组初始化 FrequencyTracker 对象。
void add(int number):添加一个 number 到数据结构中。
void deleteOne(int number):从数据结构中删除一个 number 。数据结构 可能不包含 number ,在这种情况下不删除任何内容。
bool hasFrequency(int frequency): 如果数据结构中存在出现 frequency 次的数字,则返回 true,否则返回 false。
输入
["FrequencyTracker", "add", "add", "hasFrequency"]
[[], [3], [3], [2]]
输出
[null, null, null, true]
解释
FrequencyTracker frequencyTracker = new FrequencyTracker();
frequencyTracker.add(3); // 数据结构现在包含 [3]
frequencyTracker.add(3); // 数据结构现在包含 [3, 3]
frequencyTracker.hasFrequency(2); // 返回 true ,因为 3 出现 2 次
输入
["FrequencyTracker", "add", "deleteOne", "hasFrequency"]
[[], [1], [1], [1]]
输出
[null, null, null, false]
解释
FrequencyTracker frequencyTracker = new FrequencyTracker();
frequencyTracker.add(1); // 数据结构现在包含 [1]
frequencyTracker.deleteOne(1); // 数据结构现在为空 []
frequencyTracker.hasFrequency(1); // 返回 false ,因为数据结构为空
输入
["FrequencyTracker", "hasFrequency", "add", "hasFrequency"]
[[], [2], [3], [1]]
输出
[null, false, null, true]
解释
FrequencyTracker frequencyTracker = new FrequencyTracker();
frequencyTracker.hasFrequency(2); // 返回 false ,因为数据结构为空
frequencyTracker.add(3); // 数据结构现在包含 [3]
frequencyTracker.hasFrequency(1); // 返回 true ,因为 3 出现 1 次
解题思路
难度:中等。
思路:最直观的想法是,使用一个umap存储元素以及其对应的次数。add则直接将number对应次数加一;deleteOne则先判断umap中是否存在该元素,如果存在,如果该元素出现的次数大于等于1则将其对应次数减一,如果该元素出现的次数等于0则将其从umap中删除;hasFrequency则遍历umap,如果其对应的次数等于frequency,则直接返回true,反之如果遍历完umap还未找到则返回false。(超出时间限制:有两个测试案例无法通过)
unordered_map<int,int> umap;
FrequencyTracker()
{
}
void add(int number)
{
umap[number]++;
}
void deleteOne(int number)
{
if(umap.find(number)!=umap.end())
{
if(umap[number]>=1)
umap[number]--;
if(umap[number]==0) //减完后剩余0
umap.erase(number);
}
}
bool hasFrequency(int frequency)
{
for(auto it:umap)
{
if(it.second==frequency)
return true;
}
return false;
}
优化:既然上述超时,那么推测可能是因为hasFrequency函数的一层循环,那么是否可以不用循环也能判断呢?第一想法是使用空间换时间!用两个哈希!一开始想的是存储次数和对应的元素,但是写着写着发现太复杂了,后来一想根本不需要关心对应的元素有哪些,只需要关心次数出现的个数啦,于是第二个哈希就是次数以及对应的个数。注意,使用两个哈希在删除时需要额外小心!只有大于等于1才减去,且减完后等于0则要删除。
unordered_map<int,int> umap; //<数值,次数>
unordered_map<int,int> nmap; //<次数,个数>
FrequencyTracker()
{
}
void add(int number)
{
if(umap[number]>=1) //以前出现过则将以前出现过的次数的个数减一
{
nmap[umap[number]]--;
if(nmap[umap[number]]==0)
nmap.erase(umap[number]);
}
umap[number]++; //更改出现过的次数
nmap[umap[number]]++; //将当前出现过的次数的个数加一
}
void deleteOne(int number)
{
if(umap.find(number)!=umap.end())
{
if(umap[number]>=1) //出现次数大于等于1
{
nmap[umap[number]]--; //将出现过的次数的个数减一
if(nmap[umap[number]]==0)
nmap.erase(umap[number]);
umap[number]--; //更改出现过的次数
if(umap[number]==0) //减完后剩余0
umap.erase(number);
else if(umap[number]>0) //如果减完后还有次数
nmap[umap[number]]++; //将当前出现过的次数的个数加一
}
}
}
bool hasFrequency(int frequency)
{
if(nmap.find(frequency)!=nmap.end())
return true;
return false;
}
优化:其实该题可以直接使用双map,但是不需要上述这么复杂,直接对出现的次数的个数进行加减处理即可,同时在删除时对元素出现的次数进行特殊判断,即小于等于0则返回。
unordered_map<int,int> umap;
unordered_map<int,int> nmap;
FrequencyTracker()
{
}
void add(int number)
{
nmap[umap[number]]--;
nmap[++umap[number]]++;
}
void deleteOne(int number)
{
if(umap[number]<=0) return; //为0不做任何处理
nmap[umap[number]]--;
nmap[--umap[number]]++;
}
bool hasFrequency(int frequency)
{
return nmap[frequency]>=1?true:false;
}
6418:有相同颜色的相邻元素数目
题目描述
描述:给你一个下标从 0 开始、长度为 n 的数组 nums 。一开始,所有元素都是 未染色 (值为 0 )的。
给你一个二维整数数组 queries ,其中 queries[i] = [indexi, colori] 。
对于每个操作,你需要将数组 nums 中下标为 indexi 的格子染色为 colori 。
请你返回一个长度与 queries 相等的数组 answer ,其中 answer[i]是前 i 个操作 之后 ,相邻元素颜色相同的数目。
更正式的,answer[i] 是执行完前 i 个操作后,0 <= j < n - 1 的下标 j 中,满足 nums[j] == nums[j + 1] 且 nums[j] != 0 的数目。
输入:n = 4, queries = [[0,2],[1,2],[3,1],[1,1],[2,1]]
输出:[0,1,1,0,2]
解释:一开始数组 nums = [0,0,0,0] ,0 表示数组中还没染色的元素。
- 第 1 个操作后,nums = [2,0,0,0] 。相邻元素颜色相同的数目为 0 。
- 第 2 个操作后,nums = [2,2,0,0] 。相邻元素颜色相同的数目为 1 。
- 第 3 个操作后,nums = [2,2,0,1] 。相邻元素颜色相同的数目为 1 。
- 第 4 个操作后,nums = [2,1,0,1] 。相邻元素颜色相同的数目为 0 。
- 第 5 个操作后,nums = [2,1,1,1] 。相邻元素颜色相同的数目为 2 。
输入:n = 1, queries = [[0,100000]]
输出:[0]
解释:一开始数组 nums = [0] ,0 表示数组中还没染色的元素。
- 第 1 个操作后,nums = [100000] 。相邻元素颜色相同的数目为 0 。
解题思路
有相同颜色的相邻元素数目:最直观的想法是,使用nums数组表示染色数组,初始化为0表示未染色,使用res表示结果数组,使用ans表示结果项,其表示相邻元素颜色相同的数目,初始化为0。遍历queries数组,使用index接收下标,使用color接收染色值。首先把原来的颜色去掉,即如果原本已经染色并且其与相邻元素相等,则将ans减一;然后修改颜色;最后加上修改后的颜色,即如果修改后已经染色并且其与相邻元素相等,则将ans加一。
vector<int> colorTheArray(int n, vector<vector<int>>& queries)
{
// 长度为n的nums初始元素均为0
vector<int> nums(n,0); //染色数组 初始为0表示未染色
vector<int> res; //结果数组
int ans = 0; //结果项 表示相邻元素颜色相同的数目
for(auto query:queries) //遍历数组 修改颜色只会影响相邻元素
{
//query=[index,color] //下标 染色值
int index = query[0];
int color = query[1];
//把原来的颜色去掉 未染色才能比较是否相等
if(nums[index]!=0&&index-1>=0&&nums[index]==nums[index-1]) ans--;
if(nums[index]!=0&&index+1<n&&nums[index]==nums[index+1]) ans--;
//修改颜色
nums[index]=color;
//加上修改后的颜色
if(nums[index]!=0&&index-1>=0&&nums[index]==nums[index-1]) ans++;
if(nums[index]!=0&&index+1<n&&nums[index]==nums[index+1]) ans++;
res.push_back(ans);
}
return res;
}
6419:使二叉树所有路径值相等的最小代价
题目描述
描述:给你一个整数 n 表示一棵 满二叉树 里面节点的数目,节点编号从 1 到 n 。根节点编号为 1 ,树中每个非叶子节点 i 都有两个孩子,分别是左孩子 2 * i 和右孩子 2 * i + 1 。
树中每个节点都有一个值,用下标从 0 开始、长度为 n 的整数数组 cost 表示,其中 cost[i] 是第 i + 1 个节点的值。每次操作,你可以将树中 任意 节点的值 增加 1 。你可以执行操作 任意 次。
你的目标是让根到每一个 叶子结点 的路径值相等。请你返回 最少 需要执行增加操作多少次。
注意:
满二叉树 指的是一棵树,它满足树中除了叶子节点外每个节点都恰好有 2 个节点,且所有叶子节点距离根节点距离相同。
路径值 指的是路径上所有节点的值之和。
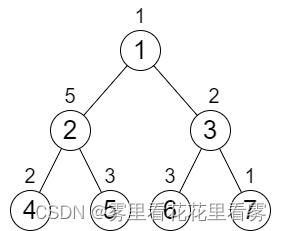
输入:n = 7, cost = [1,5,2,2,3,3,1]
输出:6
解释:我们执行以下的增加操作:
- 将节点 4 的值增加一次。
- 将节点 3 的值增加三次。
- 将节点 7 的值增加两次。
从根到叶子的每一条路径值都为 9 。
总共增加次数为 1 + 3 + 2 = 6 。
这是最小的答案。
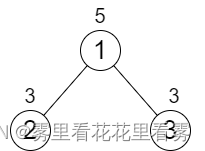
输入:n = 3, cost = [5,3,3]
输出:0
解释:两条路径已经有相等的路径值,所以不需要执行任何增加操作。
解题思路
使二叉树所有路径值相等的最小代价:最直观的想法是,使用ans表示最少操作次数。首先从满二叉树的最后一个非叶子节点开始遍历,取其两个子结点的差值绝对值加入ans中,即表明操作使得其子结点均为两者中的最大值,接着将两者中的最大值加入到其父节点的代价cost中,继续向上传递,直到传到根节点为止。
int minIncrements(int n, vector<int>& cost)
{
// 满二叉树 可以使用数组表示
int ans=0; //表示最少操作次数
for(int i=n/2;i>0;i--) //i表示节点编号 如果对应数组的话要减一
{
ans+=abs(cost[2*i-1]-cost[2*i]); //取兄弟节点的差值绝对值
cost[i-1]+=max(cost[2*i-1],cost[2*i]); //将子节点代价加上
}
return ans;
}

![数青蛙、[USACO10FEB]Chocolate Giving S](https://img-blog.csdnimg.cn/e71c826a97104009a2c74f288f3db98d.png)
![[mini LCTF 2023] 西电的部分](https://img-blog.csdnimg.cn/7cd0c91779834e17ae306eebad047ac7.png)