前言
本文节选UG474的第二章,进行整理翻译。CLB资源被FPGA综合工具自动有效地使用,不需要任何特殊的FPGA专用编码。一些HDL编码建议和技术可以帮助优化设计以获得最大效率。
设计检查清单
这些指南是为有效使用7系列CLB的设计建议提供的快速核对表。7系列CLB的设计建议:
-
资源利用
-
使用通用的HDL代码,让综合和映射工具选择特定的FPGA CLB资源。
-
只有在需要满足密度或性能要求时,才考虑实例化特定资源。或性能要求时才考虑实例化特定的资源。
-
将结果与估计的片数相比较,以验证设计效率。
-
如果一个设计在目标器件中的资源用完了,请检查哪种资源是限制因素,并考虑将其作为设计的一部分。资源是限制因素,并考虑使用替代资源,例如 将寄存器移至SRL或分布式RAM,或将分布式RAM移至块RAM、 或进位逻辑到DSP片上。
-
管道化
- 设计者应该使用顺序设计技术和流水线来利用丰富的触发器来提高性能。
-
控制信号
- 只在必要时使用控制信号。
- 避免使用路由全局复位信号,尽量减少使用局部复位,以最大限度地利用FPGA资源。
- 使用高电平的控制信号。
- 避免在同一个触发器上同时使用设置和复位。
- 避免在小型移位寄存器和存储阵列上使用控制信号,以便使用LUT而不是触发器,从而最大限度地提高利用率和减少功耗。
-
软件选项
- 为了自动提高性能,使用时序约束,并通过软件选项换取更长的执行运行时间。
使用CLB资源
赛灵思建议使用通用HDL代码,并允许工具推断CLB资源的使用情况。使用为7系列FPGA设计的IP解决方案可以帮助充分利用CLB资源尽管CLB中的任何功能都可以直接实例化,包括LUT、进位逻辑和顺序元素,但实例化应主要用于指定何时应使用CLB以外的资源,如DSP片。如果综合工具没有推断出所需的特殊CLB资源,如宽多路复用器、分布式RAM或SRL功能,也可能需要实例化。
原语
本节概述了最常用的CLB原语。
多路复用器
多路复用器原语为每个片中的专用多路复用器提供直接实例化,允许构建更宽的多路复用器。下表描述了这两个原语。
| Primitive | Inputs | Resource | Output Function |
|---|---|---|---|
| MUXF7 | LUT outputs (4:1 multiplexer) | F7AMUX or F7BMUX | 8:1 multiplexer |
| MUXF8 | F7AMUX and F7BMUX outputs (8:1 multiplexer) | F8MUX | 16:1 multiplexer |
两个多路复用器原语的端口信号是相同的。下图显示了MUXF7。
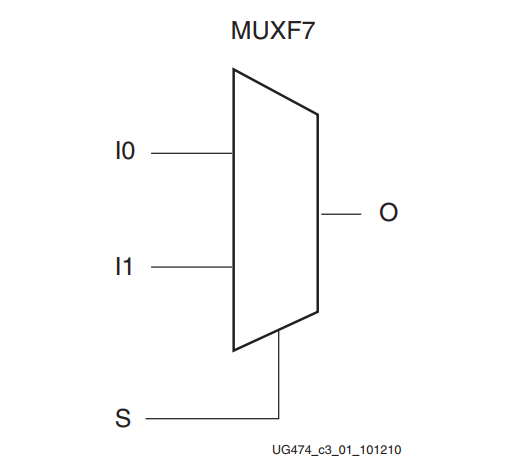
端口信号
- 数据输入 - I0, I1:数据输入提供由选择信号(S)选择的数据。
- 控制输入 - S:选择输入信号决定了要连接到输出O的数据输入信号。逻辑0选择I0输入,而逻辑1选择I1输入。
- 数据输出 - O:数据输出O提供由控制输入选择的数据值(一个比特)。
进位链
CARRY4原语实例化了每个slice中可用的快速进位逻辑。这个基元与LUT一起工作,构建加法器和乘法器。下图显示了CARRY4基元。综合工具通常从算术HDL代码中推断出这个逻辑,自动正确连接这个功能。
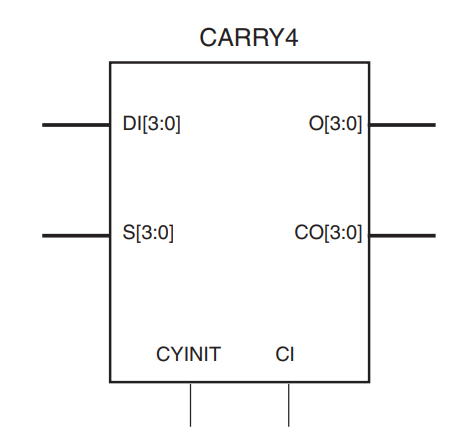
端口信号
-
总和输出 - O[3:0]:总和输出提供加/减法的最终结果。它们连接到slice 的AMUX/BMUX/CMUX/DMUX输出。
-
进位输出 - CO[3:0]:进位输出为每个位提供进位。CO[3]等同于COUT。如果CO[3]通过COUT连接到另一个CARRY4原语的CI输入,并通过专用路由将进位链连接到一列slice上,就可以创建一个较长的进位链。进位输出还可选择连接到slice的AMUX/BMUX/CMUX/DMUX输出。
-
进位输入 - CI:进位输入,也叫CIN,用于级联片,形成更长的进位链。
-
数据输入 - DI [3:0]:数据输入被用作 "生成 "信号,用于前级进位逻辑。产生信号的来源是LUT输出。
-
选择输入 - S [3:0]:选择输入作为 "传播 "信号,用于前级进位逻辑。传播信号的来源是LUT输出。、
-
进位初始化 - CYINIT:进位初始化输入用于选择进位链中的第一个位。这个引脚的值是0(用于加法)、1(用于减法)或AX输入(用于动态的第一个进位)。
SLICEM分布式RAM
下表中显示了八个原语。三个原语是单端口RAM,三个原语是双端口RAM,还有两个原语是四端口RAM。
| Primitive | RAM Size | Type | Address Inputs |
|---|---|---|---|
| RAM32X1S | 32-bit | Single-port | A[4:0] (read/write) |
| RAM32M | 32-bit | Quad-port | ADDRA[4:0] (read) ADDRB[4:0] (read) ADDRC[4:0] (read) ADDRD[4:0] (read/write) |
| RAM64X1S | 64-bit | Single-port | A[5:0] (read/write) |
| RAM64X1D | 64-bit | Dual-port | A[5:0] (read/write) DPRA[5:0] (read) |
| RAM64M | 64-bit | Quad-port | ADDRA[5:0] (read) ADDRB[5:0] (read) ADDRC[5:0] (read) ADDRD[5:0] (read/write) |
| RAM128X1S | 128-bit | Single-port | A[6:0] (read/write) |
| RAM128X1D | 128-bit | Dual-port | A[6:0], (read/write) DPRA[6:0] (read) |
| RAM256X1S | 256-bit | Single-port | A[7:0] (read/write) |
输入和输出数据的宽度为1位(四端口RAM除外)。
下图显示了通用的单端口、双端口和四端口分布式RAM原语。A、ADDR和DPRA信号是地址总线。
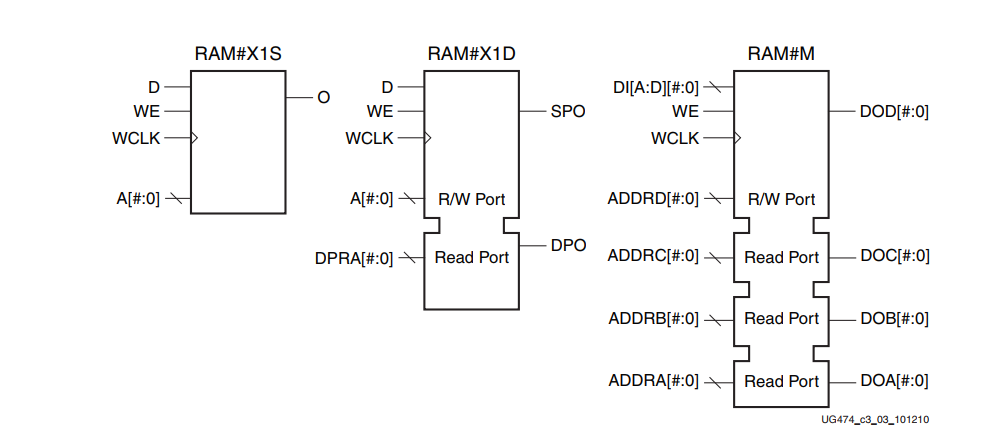
实例化几个分布式RAM基元可用于实现宽内存块。
端口信号
每个分布式RAM端口在读取同一组内存单元时都是独立运行的。
时钟 - WCLK
该时钟用于同步写入。数据和地址输入引脚的设置时间与WCLK有关。
设置时间参照WCLK引脚。时钟引脚(WCLK)在slice级有一个反转选项。时钟信号可以在时钟的负边沿或时钟的正边沿有效,而不需要其他逻辑资源。默认是在时钟的正边沿。
使能 - WE/WED
使能引脚影响端口的写入功能。一个非活动的写入使能可以防止对存储单元的任何写入。一个有效的写入使能会使时钟沿将数据输入信号写入地址输入所指向的内存位置。
地址 - A[#:0], DPRA[#:0], 和 ADDRA[#:0] - ADDRD[#:0]
地址输入A[#:0](用于单端口和双端口)、DPRA[#:0](用于双端口)和ADDRA[#:0]-ADDRD[#:0](用于四端口)选择用于读取或写入的存储单元。端口的宽度决定了所需的地址输入。有些地址输入在VHDL或Verilog实例中不是总线。
数据输入 - D, DID[#:0]
数据输入D(对于单端口和双端口)和DID[#:0](对于四端口)提供要写入RAM的新数据值。
数据输出 - O、SPO、DPO和DOA[#:0] - DOD[#:0]
数据输出O(单端口)、DPO(双端口)和DOA[#:0] - DOD[#:0](四端口)反映了地址输入所引用的存储单元的内容。在一个有效的写时钟边沿之后,数据输出(O、SPO或DOD[#:0])反映新写入的数据。
SLICEM SRL移位寄存器
32位移位寄存器(SRLC32E)有一个原语,它在一个SLICEM中使用一个LUT。下图显示了32位移位寄存器结构。
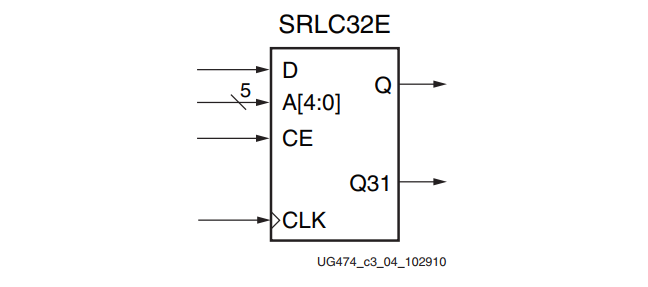
端口信号
时钟 - CLK
时钟的上升沿或下降沿都用于同步移位操作。数据和时钟使能输入引脚的设置时间参照CLK的选定边缘。时钟引脚(CLK)在片级有一个反转选项。时钟信号可以在负边或正边激活,而不需要其他逻辑资源。默认的是正的时钟边缘。
数据输入 - D
数据输入提供新的数据(一个比特),以移入移位寄存器。
时钟使能 - CE
时钟使能引脚会影响移位功能。一个未激活的时钟使能引脚不会将数据移入移位寄存器,也不会写入新数据。激活时钟使能允许(D)中的数据被写入第一个位置,所有数据被移位一个位置。当可用时,新的数据会出现在输出引脚(Q)和可级联的输出引脚(Q31)上。
地址 - A[4:0]
地址输入选择要读的位(范围0到31)。第n个位可以在输出引脚(Q)上使用。地址输入对可级联的输出引脚(Q31)没有影响。Q31总是移位寄存器的最后一位(位31)。
数据输出 - Q
数据输出Q提供由地址输入选择的数据值(1位)。
触发器
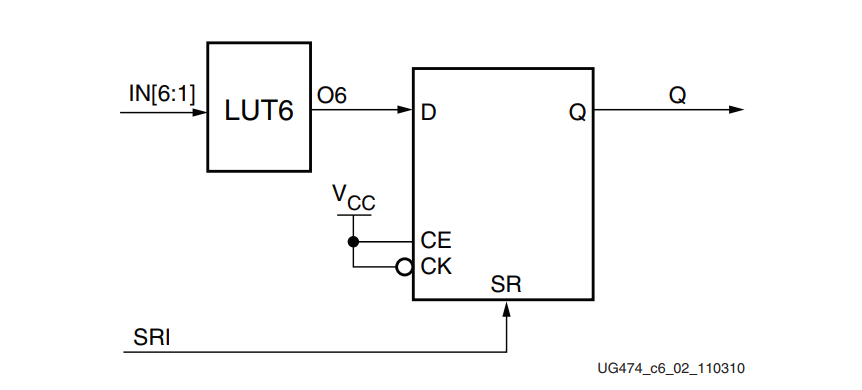
CLB存储元件有几个基元,包括触发器和锁存器,有不同的控制信号组合可用。下图中显示了FDRE的例子。
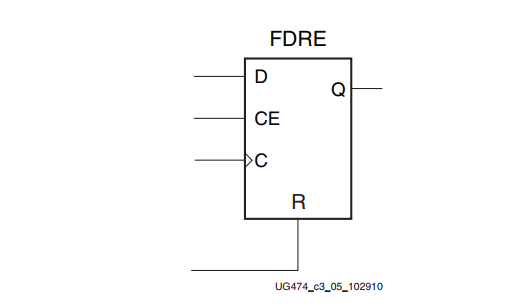
端口信号
数据输入 - D
数据输入提供新的数据(一个比特),并将其作为时钟输入触发器。
数据输出 - Q
Q是来自触发器的一位寄存数据输出。
时钟 - C
时钟的上升沿或下降沿都用于捕获数据和切换输出。数据和时钟使能输入引脚的设置时间参照所选择的时钟边缘。时钟引脚(C)在片级有一个反转选项。时钟信号可以在时钟的负边或正边激活而不需要其他逻辑资源。默认的是时钟的正边。一个片中的所有触发器必须使用相同的时钟和相同的时钟极性。
时钟使能 - CE
当CE为低电平时,相对于D输入,时钟转换被忽略。设置和复位输入的优先级高于时钟使能。
同步复位 - R
当R为高电平时,所有其他输入被覆盖,数据输出(Q)在有效时钟转换时被驱动为低电平。这个信号在FDRE组件中可用。FDRE触发器在上电时也被默认清零。
同步设置 - S
当S为高电平时,所有其他输入被覆盖,数据输出(Q)在有效时钟转换时被驱动为高电平。这个信号在FDSE组件中可用。FDSE触发器在上电时也被默认为预置。
异步清除 - CLR
当CLR为高电平时,所有其他输入被覆盖,数据输出(Q)被驱动为低电平。这个信号在FDCE组件中可用。FDCE触发器在上电时也被默认为清零。
异步预置 - PRE
当PRE为高电平时,所有其他输入被覆盖,数据输出(Q)被驱动为高电平。这个信号在FDPE组件中可用。FDPE触发器在上电时也被默认预置。
在同一个触发器上同时使用异步清零和预置,需要额外的资源和定时路径。
应用实例
本节提供了关于使用CLB资源作为大型功能的一部分的指导。描述了实现这些功能的替代方法之间的权衡。
分布式RAM的应用
分布式RAM提供了一种权衡,即使用存储元素来处理非常小的阵列和使用块状RAM来处理较大的阵列。建议在可能的情况下推断内存,以提供最大的灵活性。分布式RAM也可以通过实例化或通过使用Xilinx LogiCORE™ IP来实现。
一般来说,分布式RAM应该用于所有由64位或更少组成的存储器,除非目标器件的SLICEM或逻辑资源短缺。分布式RAM在资源、性能和功率方面更有效率。
对于深度大于64位但小于或等于128位的存储器,决定使用哪种最佳资源取决于这些因素:
- 额外块RAM的可用性:如果没有,应该使用分布式RAM。
- 延迟的要求:如果需要异步读取能力,必须使用分布式RAM。
- 数据宽度:宽度大于16位的应使用块状RAM,如果有的话。
- 必要的性能要求:与块RAM相比,分布式RAM通常具有更短的时钟到输出时间和更少的放置限制。
移位寄存器的应用
同步移位寄存器
移位寄存器原语不使用同一个slice中的可用寄存器。为了实现一个完全同步的读写移位寄存器,输出引脚Q必须连接到一个触发器。如下图所示,移位寄存器和触发器都共享同一个时钟。

静态长度移位寄存器
可级联的32位移位寄存器实现了任何静态长度模式的移位寄存器,不需要专用的多路复用器(F7AMUX、F7BMUX和F8MUX)。下图展示了一个72位移位寄存器。
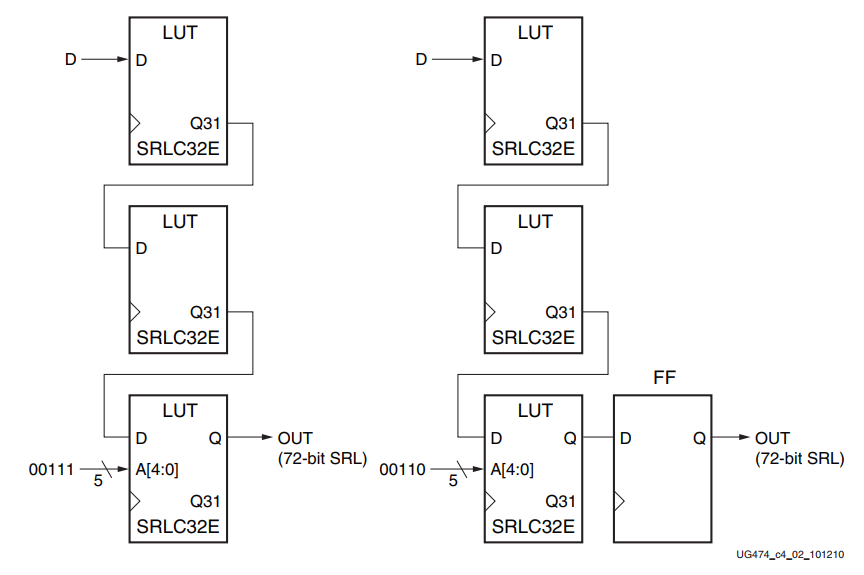
只有最后一个SRLC32E基元需要将其地址输入与0b00111绑定。另外,移位寄存器的长度可以限制为71位(地址与0b00110绑定),并且可以使用一个触发器作为最后一个寄存器。(在SRLC32E基元中,移位寄存器的长度是地址输入+1)。
进位逻辑应用
CLB中的专用进位逻辑改善了算术功能的性能,如加法器、计数器和比较器。包括简单的计数器或加/减法器的设计会自动推断出进位逻辑。包括乘法器在内的更复杂的功能可以用单独的DSP48E1片来实现。
每个器件中的DSP48E1片都支持许多独立的功能,包括乘法、乘法累加、乘法加法、三输入加法、桶式移位、宽总线复用、幅度比较器、位逻辑功能、模式检测和宽计数器。该架构还支持级联多个DSP48E1片,以形成宽数学功能、DSP滤波器和复杂算术。
在使用CLB进位逻辑和DSP48E1片之间的选择取决于应用。一个小的算术函数使用CLB携带逻辑而不是使用整个DSP48E1片,可以更快、更低功率。当DSP48E1片被完全利用时,CLB片和携带逻辑提供了一个有效的替代方案。
高级专题
将锁存器功能作为逻辑使用
因为锁存器函数是电平敏感的,所以它可以被用作等同于逻辑门的功能。如下图所示,指定这个函数的基元是AND2B1L(一个有一个输入反相的2输入AND门)和OR2L(一个2输入的OR门)。
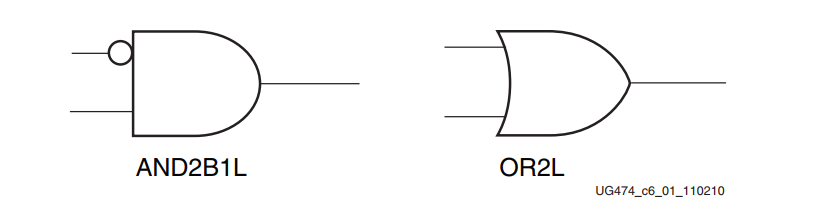
如下图所示,当AND2B1L和OR2L基元实例化时,锁存器的数据和SR输入以及Q输出被使用,并且CK门和CE门使能被保持为高电平。AND2B1L将锁存器的数据输入(门上的反相输入,DI)与异步清零输入(SRI)相结合。OR2L将锁存数据输入与异步预置相结合。一般来说,锁存器的数据输入来自同一片内的LUT的输出,将逻辑能力扩展到另一个外部输入。因为每个片只有一个SR输入,所以每个片断使用一个以上的AND2B1L或OR2L需要一个共享的公共外部输入。
设备模型将这些功能显示为存储元件的AND2L和OR2L配置。
AND2B1L和OR2L两输入门节省了LUT资源,并在上电和GSR断言(全局设置/复位)时被初始化为已知状态。通过用寄存器/锁存器资源换取逻辑,使用这些基元可以降低逻辑电平,提高器件的逻辑密度。然而,由于时钟和时钟使能输入需要静态输入,指定一个或多个AND2B1L或OR2L基元可能导致片中的寄存器包装和密度问题,不允许使用其余的寄存器和锁存器。
互连资源
互连是FPGA内功能元素的输入和输出之间的可编程信号通路网络,如IOB、CLB、DSP片和块RAM。互连,也称为路由,是为了实现最佳的连接性而划分的。赛灵思的布局和布线工具利用丰富的互连阵列来提供最佳的系统性能和最快的编译时间。
7系列CLB在FPGA内排列成一个规则的阵列。每个CLB连接到一个开关矩阵,用于访问一般的布线资源,这些资源在CLB的行和列之间垂直和水平地运行。一个类似的开关矩阵连接其他资源,如DSP片和块RAM资源。
大多数互连功能对FPGA设计者来说是透明的。对互连细节的了解可以用来指导设计技术,但对于高效的FPGA设计来说并不是必须的。只有选定的互连类型是由用户控制的。其中包括时钟路由资源,它是通过使用时钟缓冲器来选择的。两个全局控制信号,即GSR和GTS,通过使用STARTUPE2基元选择。
全局控制信号GSR和GTS
除了通用互连外,7系列FPGA还有两个全局逻辑控制信号,如下表所述。
| Global Control Input | Description |
|---|---|
| GSR | Global Set/Reset:高电平时,异步地将所有寄存器和触发器置于初始状态。 |
| GTS | Global 3-State: 高电平时,异步迫使所有I/O引脚进入高阻抗状态(高Z,3态)。 |
如果设计中的每个触发器都需要一个共同的初始化信号,那么在设计中使用GSR控制,而不是单独路由的全局复位信号,以使CLB输入可用,这将使设计更小更有效。GSR信号必须总是重新初始化每个触发器。使用GSR和GTS并不使用任何通用的路由资源。在FPGA配置过程中,GSR信号被自动断定,保证了FPGA在已知状态下启动。在配置时,由于触发器是由配置时钟启用的,然后由用户时钟时钟化,建议在配置后在用户时钟上启用关键触发器或关键时钟信号。
STARTUPE2
GSR 和 GTS 信号源是使用 STARTUPE2 原理定义和连接的。此基元允许用户定义这些专用网路的源。配置期间,GSR 和 GTS 始终处于活动状态,在 STARTUPE2 基元上将信号连接到它们,定义了配置后如何控制它们。默认情况下,它们在启动阶段的选定时钟周期配置后被禁用,启用器件中的触发器和I/O。STARTUPE2基元还包括配置期间专门使用的其他信号。
互连优化
互连延迟根据设计中的具体实现和负载而变化。互连的类型、在设备中所需要的距离以及需要穿越的开关矩阵的数量都是影响总延迟的因素。大多数时序问题是通过检查块的延迟和确定使用更少的层次或更快的路径的影响来解决的。如果互连延迟看起来太长,增加实施工作水平或迭代,以改善性能,同时确保所需的时序在约束文件中。
具有关键时序的网络或负载较重的网络通常可以通过复制网络的源头来改善。切片的双5输入LUT配置简化了同一切片中的逻辑复制,这使源函数的输入上的任何额外负载最小化。在多个片断中复制逻辑使软件有更大的灵活性来独立放置源。
平面规划是指定用户放置限制的过程。地面规划可以在自动放置和布线之前或之后进行,但在指定用户地面规划之前,总是建议先进行自动放置和布线。赛灵思的实现工具提供了一个图形化的放置视图。它帮助设计者在RTL编码和综合实现之间进行选择,并具有广泛的设计探索和分析功能。
reference
- UG474