目录
一.Map------------双列集合-----------一次添加一对元素,如: 小明 99岁
1.特点:
2.Map中常见的API
3.Map集合的遍历方式
4.HashMap
5.LinkedHashMap
6.TreeMap
一.Map------------双列集合-----------一次添加一对元素,如: 小明 99岁
1.特点:
(1)双列集合一次需要存一对数据, 分别是键和值
(2)键不能重复, 但值可以重复
(3)键和值是一一对应的, 每一个键只能找到自己对应的值
(4)键 + 值这个整体我们称为键值对或者键值对对象, 在Java中叫做Entry对象
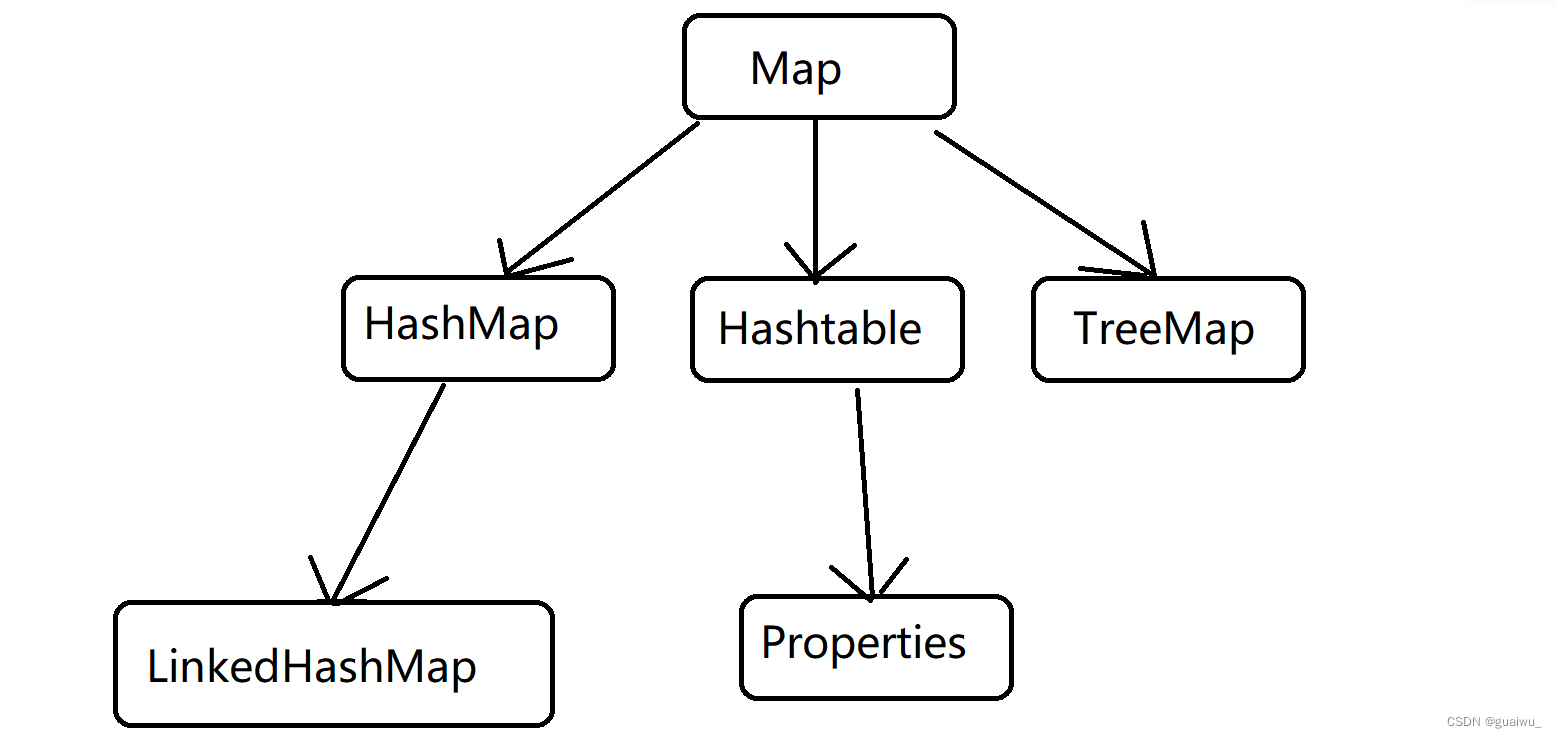
双列集合的体系结构
2.Map中常见的API
Map是双列集合的顶层接口,它的功能是全部双列集合都可以继承使用的
方法名称 作用
V put(K key,V value) 添加元素
V remove(object key) 根据键删除键值对元素
void clear() 移除所有的键值对元素
boolean containsKey(object key) 判断集合是否包含指定的键
boolean containsValue(obiect value) 判断集合是否包含指定的值boolean isEmpty() 判断集合是否为空
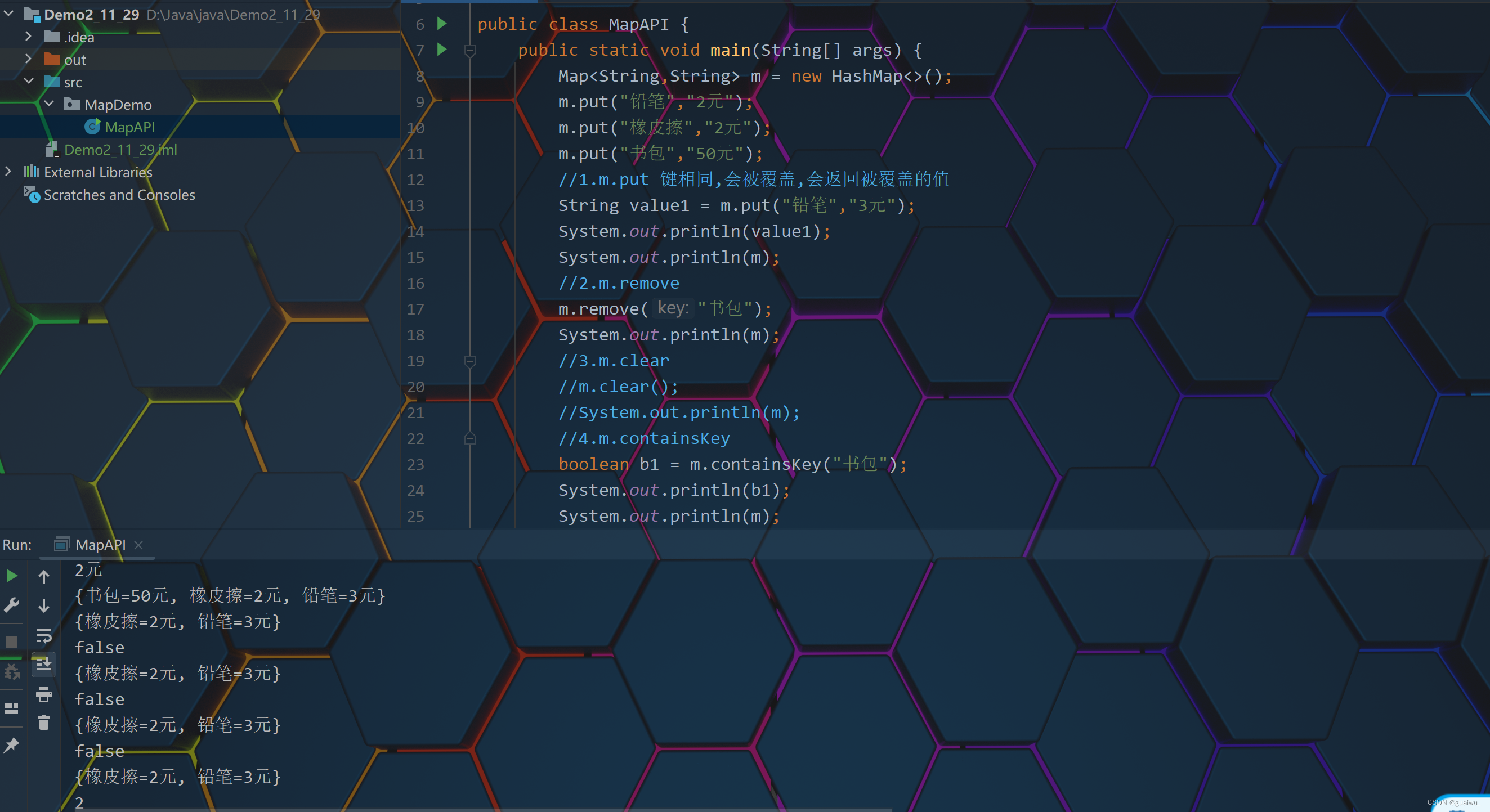
int size() 集合的长度,也就是集合中键值对的个数代码示范:
{ public static void main(String[] args) { Map<String,String> m = new HashMap<>(); m.put("铅笔","2元"); m.put("橡皮擦","2元"); m.put("书包","50元"); //1.m.put 键相同,会被覆盖,会返回被覆盖的值 String value1 = m.put("铅笔","3元"); System.out.println(value1); System.out.println(m); //2.m.remove m.remove("书包"); System.out.println(m); //3.m.clear //m.clear(); //System.out.println(m); //4.m.containsKey boolean b1 = m.containsKey("书包"); System.out.println(b1); System.out.println(m); //5.m.containsValue boolean b2 = m.containsValue("50元"); System.out.println(b2); System.out.println(m); //6.m.isEmpty boolean b3 = m.isEmpty(); System.out.println(b3); System.out.println(m); //m.size System.out.println(m.size()); } }结果展示:
3.Map集合的遍历方式
(1)键找值
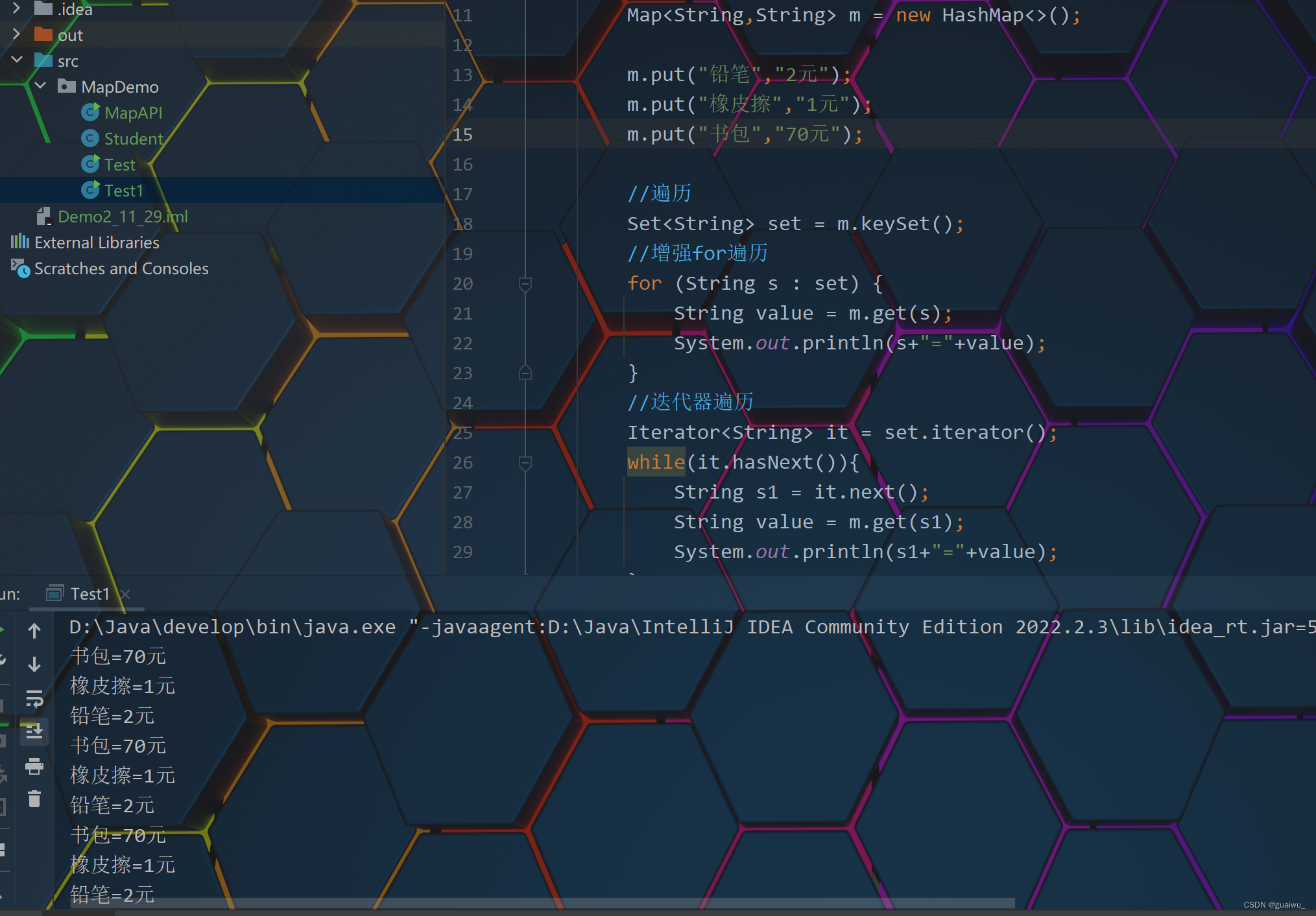
代码示范:
package MapDemo; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class Test1 { public static void main(String[] args) { Map<String,String> m = new HashMap<>(); m.put("铅笔","2元"); m.put("橡皮擦","1元"); m.put("书包","70元"); //遍历 Set<String> set = m.keySet(); //增强for遍历 for (String s : set) { String value = m.get(s); System.out.println(s+"="+value); } //迭代器遍历 Iterator<String> it = set.iterator(); while(it.hasNext()){ String s1 = it.next(); String value = m.get(s1); System.out.println(s1+"="+value); } //Lambda表达式遍历 set.forEach(s -> { String value = m.get(s); System.out.println(s+"="+value); }); } }结果展示:
(2)通过键值对对象进行遍历
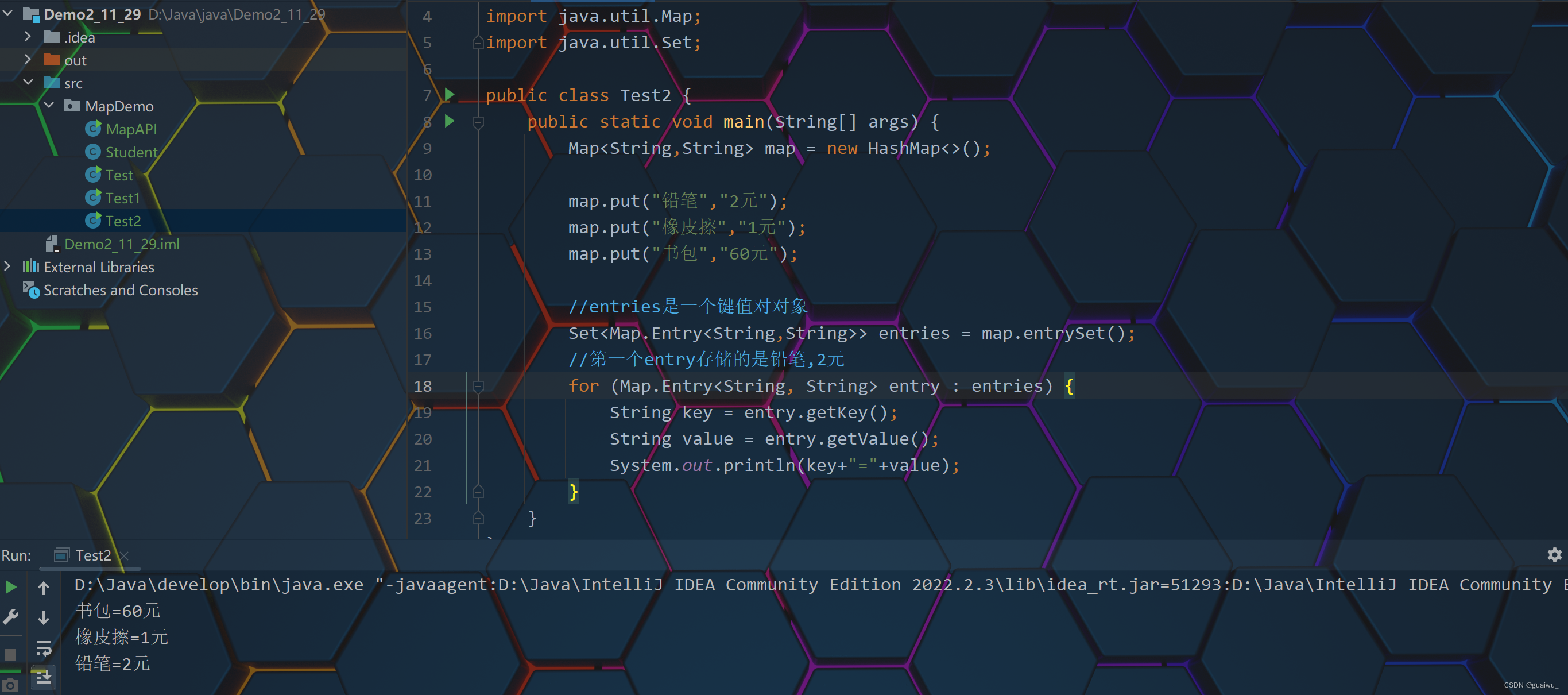
代码示范:
package MapDemo; import java.util.HashMap; import java.util.Map; import java.util.Set; public class Test2 { public static void main(String[] args) { Map<String,String> map = new HashMap<>(); map.put("铅笔","2元"); map.put("橡皮擦","1元"); map.put("书包","60元"); //entries是一个键值对对象 Set<Map.Entry<String,String>> entries = map.entrySet(); //第一个entry存储的是铅笔,2元 for (Map.Entry<String, String> entry : entries) { String key = entry.getKey(); String value = entry.getValue(); System.out.println(key+"="+value); } } }结果展示:
(3)Lambda表达式
代码示范:
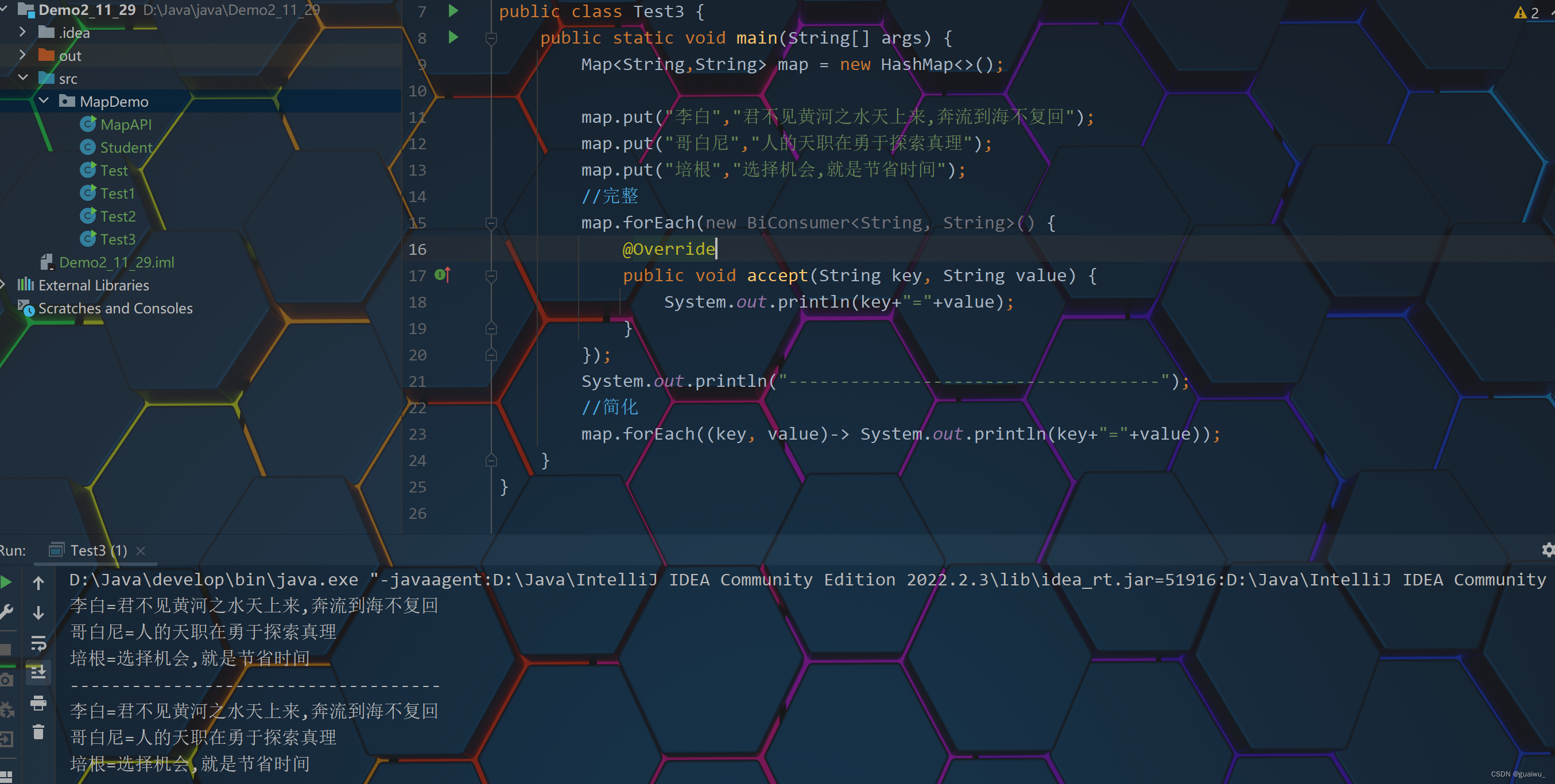
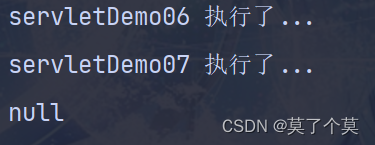
package MapDemo; import java.util.HashMap; import java.util.Map; import java.util.function.BiConsumer; public class Test3 { public static void main(String[] args) { Map<String,String> map = new HashMap<>(); map.put("李白","君不见黄河之水天上来,奔流到海不复回"); map.put("哥白尼","人的天职在勇于探索真理"); map.put("培根","选择机会,就是节省时间"); //完整 map.forEach(new BiConsumer<String, String>() { @Override public void accept(String key, String value) { System.out.println(key+"="+value); } }); System.out.println("------------------------------------"); //简化 map.forEach((key, value)-> System.out.println(key+"="+value)); } }结果展示:
4.HashMap
HashMap是Map里面的一个实现类
直接使用Map里面的方法就可以了
特点由键决定: 无序, 不重复, 无索引
依赖hashCode方法和equals方法保证键的唯一
如果键存储的是自定义对象, 需要重写hashCode和equals方法
如果值存储的是自定义对象, 不需要重写hashCode和equals方法
5.LinkedHashMap
由键决定: 有序, 不重复, 无索引
有序指的是存储和取出元素的顺序一致
代码示范:
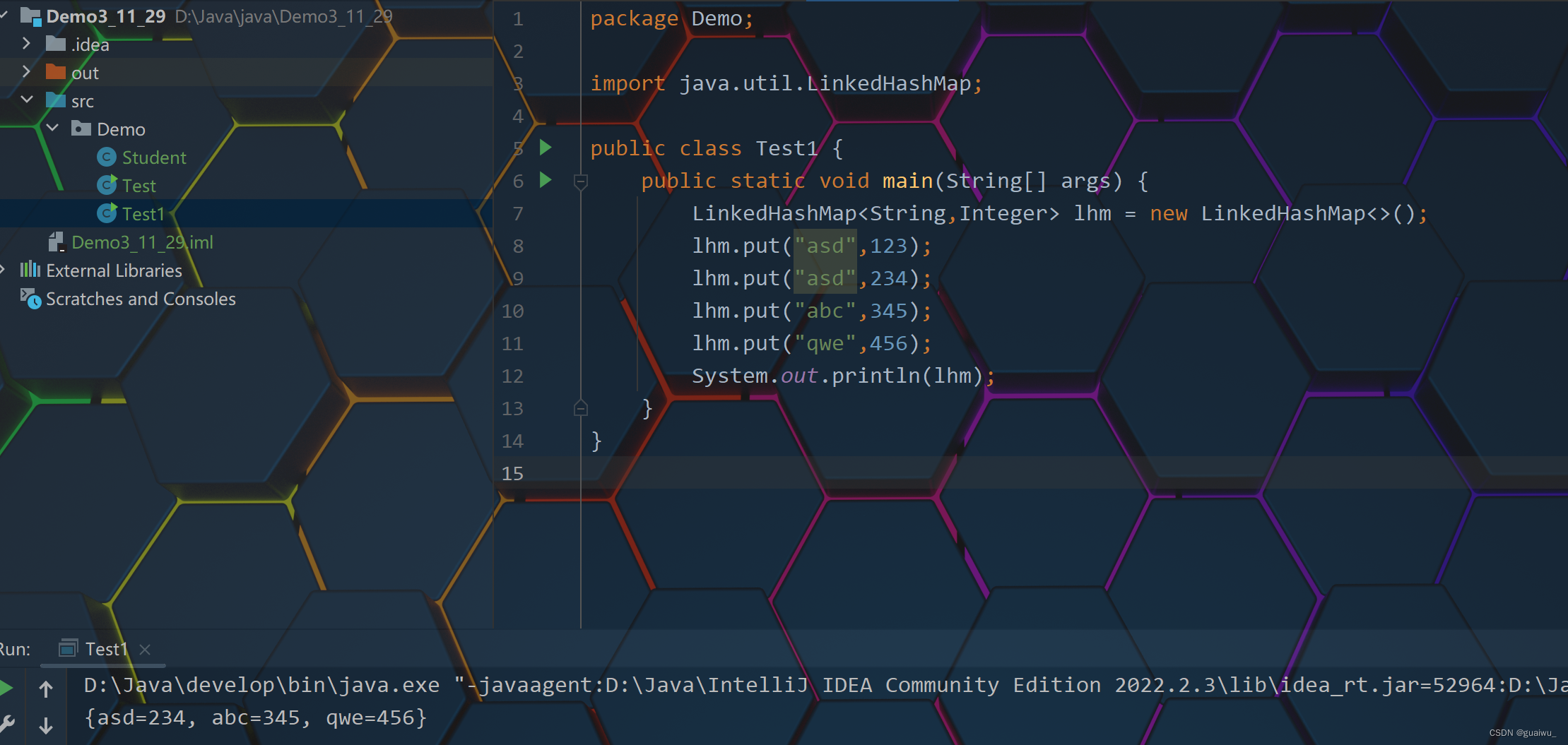
package Demo; import java.util.LinkedHashMap; public class Test1 { public static void main(String[] args) { LinkedHashMap<String,Integer> lhm = new LinkedHashMap<>(); lhm.put("asd",123); lhm.put("asd",234); lhm.put("abc",345); lhm.put("qwe",456); System.out.println(lhm); } }结果展示:
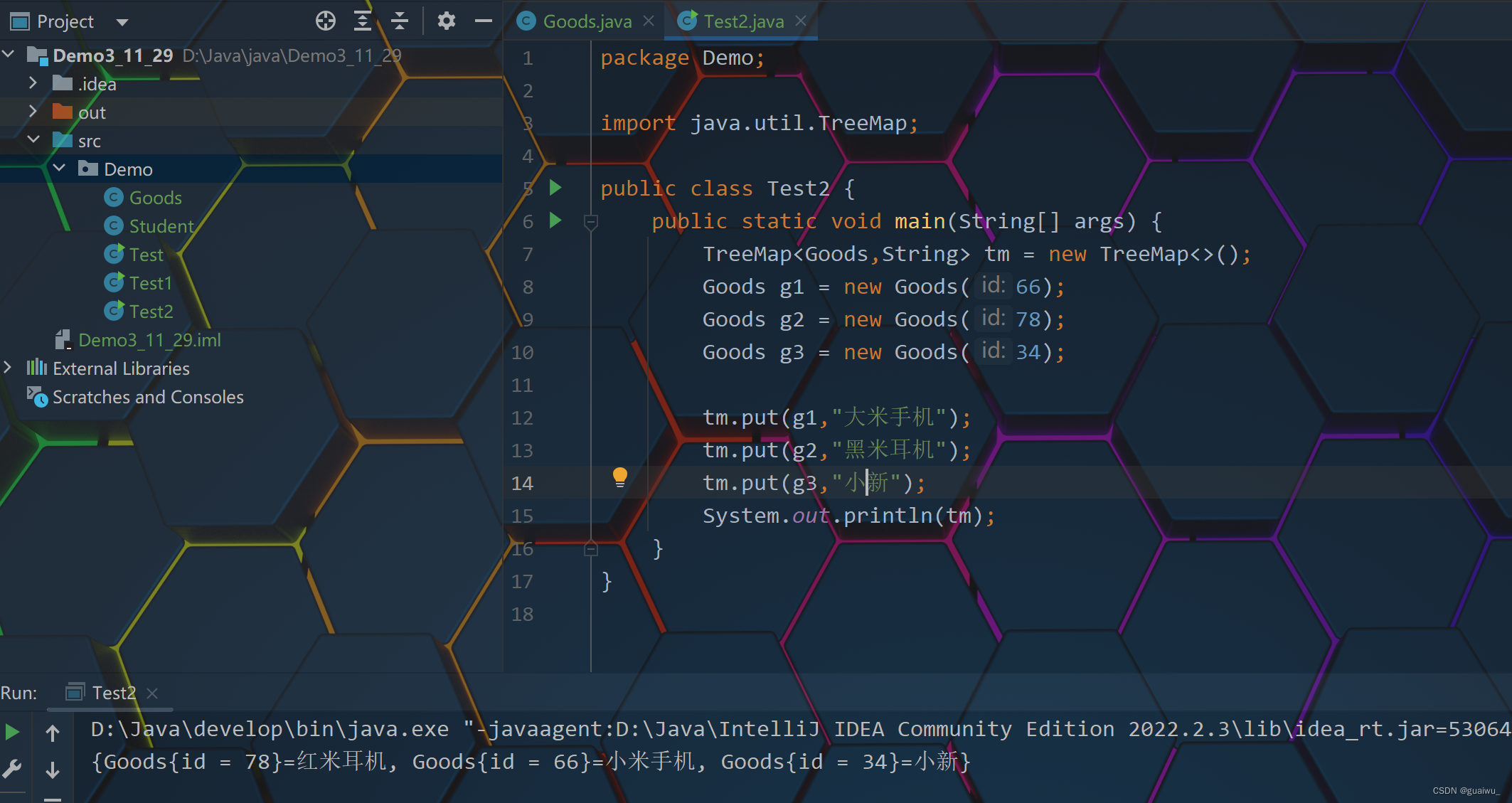
6.TreeMap
由键决定特性: 不重复, 无索引, 可排序
可排序: 对键进行排序(默认从小到大进行排序, 也可以自己规定键的排序规则)
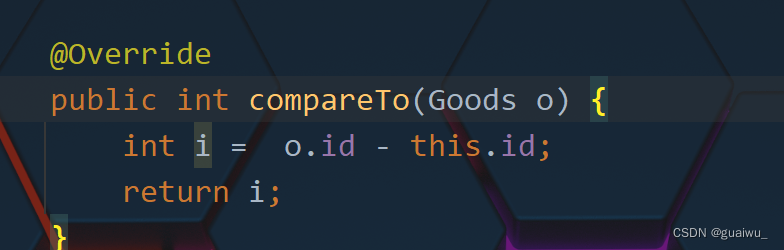
(自己规定排列顺序,让它从大到小排序)