美国总统竞选活动即将到来。 现在是回顾拜登政府上任头两年的一些演讲的好时机。 搜索一些演讲记录以了解更多关于白宫迄今为止关于某些主题的信息不是很好吗?
假设我们要搜索演讲的内容。 我们该怎么做? 我们可以使用语义搜索。 语义搜索是目前人工智能 (AI) 中最热门的话题之一。 随着我们看到像 ChatGPT 这样的自然语言处理 (NLP) 应用程序越来越受欢迎,它变得越来越重要。 我们可以使用矢量数据库来缓存结果(例如使用 GPTCache),而不是重复 ping GPT,这在经济和生态上都是昂贵的。

推荐:用 NSDT设计器 快速搭建可编程3D场景。
在本教程中,我们将在本地启动一个矢量数据库,以便我们可以按内容搜索拜登从 2021 年到 2022 年的演讲。 我们使用“The White House (Speeches and Remarks) 12/10/2022”数据集,我们在 Kaggle 上找到了这个数据集,并且可以通过 Google Drive 下载这个例子。 GitHub 上提供了本教程的演练笔记本。
1、准备开发环境
在我们深入研究代码之前,请确保下载开发环境。 我们需要四个库:PyMilvus、Milvus、Sentence-Transformers 和 gdown。 可以通过运行以下命令从 PyPi 获取必要的库:
pip3 install pymilvus==2.2.5 sentence-transformers gdown milvus
2、准备白宫演讲数据集
与几乎所有基于真实世界数据集的人工智能/机器学习项目一样,我们首先需要准备数据。 我们使用 gdown 下载数据集并使用 zipfile 将其解压缩到本地文件夹中。 运行下面的代码后,我们希望在名为“white_house_2021_2022”的文件夹中看到一个名为“The white house speeches.csv”的文件。
import gdown
url = 'https://drive.google.com/uc?id=10_sVL0UmEog7mczLedK5s1pnlDOz3Ukf'
output = './white_house_2021_2022.zip'
gdown.download(url, output)
import zipfile
with zipfile.ZipFile("./white_house_2021_2022.zip","r") as zip_ref:
zip_ref.extractall("./white_house_2021_2022")
我们使用 pandas 加载和检查 CSV 数据。
import pandas as pd
df = pd.read_csv("./white_house_2021_2022/The white house speeches.csv")
df.head()
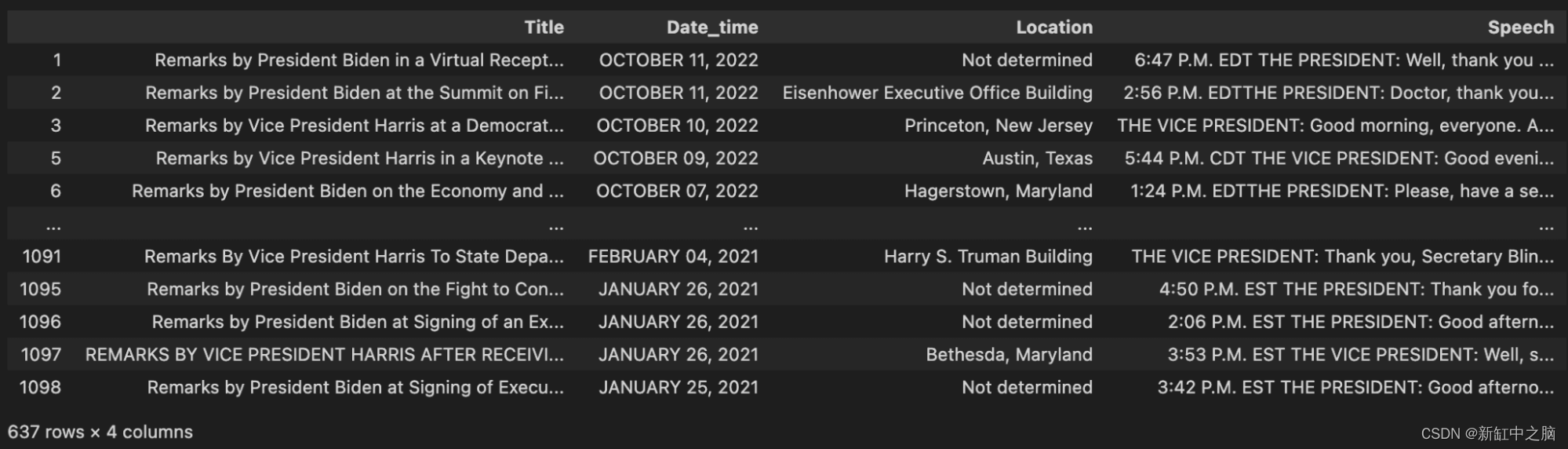
查看数据头部时,你会注意到什么? 我注意到的第一件事是数据有四列:标题、日期和时间、位置和演讲。 第二件事是有空值。 空值并不总是一个问题,但它们适用于我们的数据。

3、清理数据集
没有任何实质内容的演讲(“演讲”列中的空值)对我们来说完全没有用。 让我们删除空值并重新检查数据。
df = df.dropna()
df

现在我们看到实际上还有第二个问题,仅从数据的头部来看并不是很明显。 如果查看最后一个条目,会发现它只是一个时间; “中午 12 点 18 分。 EST”几乎不是演讲。 保存此条目没有意义。 我们无法从保存向量嵌入中获得任何价值。
让我们去掉所有小于一定长度的演讲。 对于此示例,我选择了 50,但你可以选择对你有意义的任何值。 在探索了许多不同的数字后,我选择了 50。 如果你查找 20 到 50 个字符之间的演讲记录,你会看到很多地点或时间都带有一些随机句子。
cleaned_df = df.loc[(df["Speech"].str.len() > 50)]cleaned_df
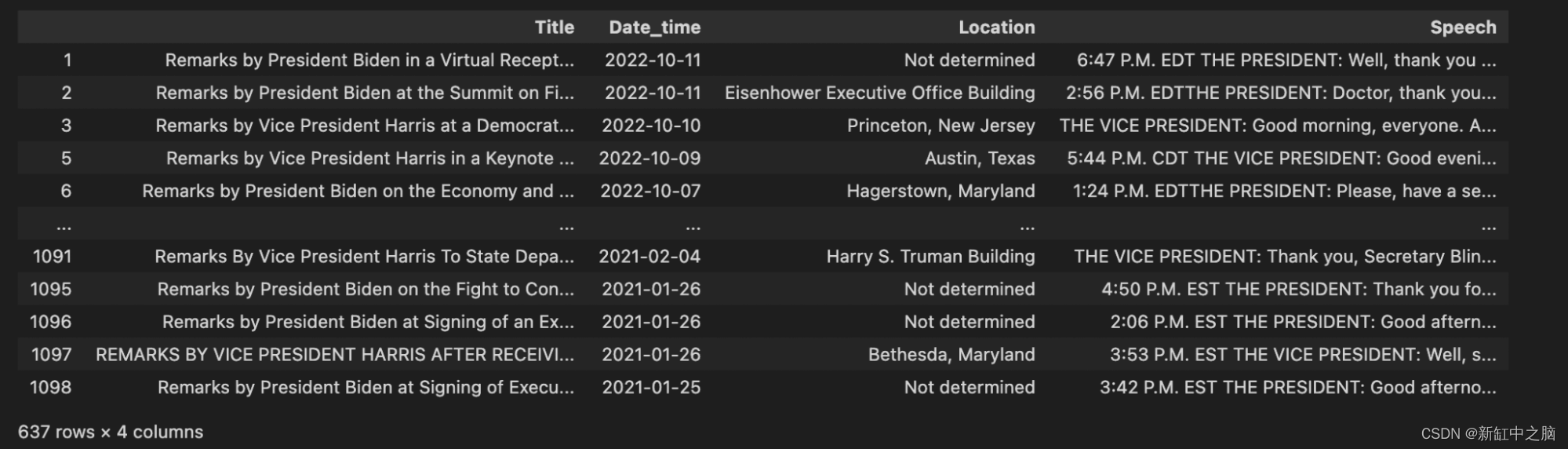
处理完简短、无实质内容的演讲后,我们再次查看我们的数据并注意到另一个问题。 许多演讲都包含 \r\n 值——换行符和回车符。 这些字符用于格式化,但不包含任何语义值。 我们数据清理过程的下一步是摆脱这些。
cleaned_df["Speech"] = cleaned_df["Speech"].str.replace("\r\n", "")
cleaned_df
这样看起来好多了。 最后一步是将“Date_time”列转换为更好的格式,以便将其存储在我们的矢量数据库中,并与其他日期时间进行比较。 我们使用日期时间库将这种日期时间格式简单地转换为通用的 YYYY-MM-DD 格式。
import datetime
# Convert the 'date' column to datetime objects
cleaned_df["Date_time"] = pd.to_datetime(cleaned_df["Date_time"], format="%B %d, %Y")
cleaned_df
4、为语义搜索建立矢量数据库
我们的数据现在是干净的,可以使用了。 下一步是建立一个矢量数据库,以根据内容实际搜索演讲。 对于这个例子,我们使用 Milvus Lite,这是 Milvus 的精简版,你可以在没有 Docker、Kubernetes 或处理任何类型的 YAML 文件的情况下运行。
我们做的第一件事是定义一些常量。 我们需要一个集合名称(用于向量数据库)、嵌入向量中的维数、批量大小和一个定义搜索时希望接收多少结果的数字。 此示例使用 MiniLM L6 v2 句子转换器,它生成 384 维嵌入向量。
COLLECTION_NAME = "white_house_2021_2022"
DIMENSION = 384
BATCH_SIZE = 128
TOPK = 3
我们使用 Milvus 的 default_server。 然后我们使用 PyMilvus SDK 连接到我们本地的 Milvus 服务器。 如果我们的矢量数据库中有一个集合与我们之前定义的集合名称同名,我们将删除该集合以确保我们从空白开始。
from milvus import default_server
from pymilvus import connections, utility
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
与大多数其他数据库一样,我们需要一个模式来将数据加载到 Milvus 矢量数据库中。 首先,我们定义希望每个对象具有的数据字段。 幸好我们之前查看了数据。 我们使用五个数据字段,我们之前有四个列和一个 ID 列。 但是这一次,我们使用语音的向量嵌入而不是实际的文本。
from pymilvus import FieldSchema, CollectionSchema, DataType, Collection
# object should be inserted in the format of (title, date, location, speech embedding)
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=500),
FieldSchema(name="date", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=200),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
collection = Collection(name=COLLECTION_NAME, schema=schema)
在准备好将数据加载到矢量数据库之前,我们需要定义的最后一件事是索引。 有许多矢量索引和模式,但对于本例,我们使用具有 128 个簇的 IVF_FLAT 索引。 较大的应用程序通常使用超过 128 个集群,但无论如何我们只有略多于 600 个条目。 对于我们的距离,我们使用 L2 范数进行测量。 一旦我们定义了我们的索引参数,我们就在我们的集合中创建索引并加载它以供使用。
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
collection.create_index(field_name="embedding", index_params=index_params)
collection.load()
5、从演讲中获取向量嵌入
到目前为止,我们所讨论的大部分内容都适用于几乎所有数据库。 我们清理了一些数据,启动了一个数据库实例并为我们的数据库定义了一个模式。 除了定义索引之外,我们还需要为矢量数据库做的另一件事是获取嵌入。
首先,我们得到句子转换器模型MiniLM L6 v2,如上所述。 然后我们创建一个函数,对数据执行转换并将其插入到集合中。 此函数获取一批数据,获取语音转录本的嵌入,创建一个要插入的对象并将其插入到集合中。
对于上下文,此函数执行批量更新。 在此示例中,我们一次批量插入 128 个条目。 我们在插入中所做的唯一数据转换是将演讲文本转换为嵌入。
from sentence_transformers import SentenceTransformer
transformer = SentenceTransformer('all-MiniLM-L6-v2')
# expects a list of (title, date, location, speech)
def embed_insert(data: list):
embeddings = transformer.encode(data[3])
ins = [
data[0],
data[1],
data[2],
[x for x in embeddings]
]
collection.insert(ins)
6、填充矢量数据库
有了创建批量嵌入和插入的功能,我们就可以填充数据库了。 对于此示例,我们循环遍历数据框中的每一行并附加到我们用于批处理数据的列表列表中。 一旦我们达到批量大小,我们就会调用 embed_insert 函数并重置我们的批量。
如果在我们完成循环后数据批中有任何剩余数据,我们将嵌入并插入剩余数据。 最后,为了完成填充我们的矢量数据库,我们调用 flush 来确保数据库被更新和索引。
data_batch = [[], [], [], []]
for index, row in cleaned_df.iterrows():
data_batch[0].append(row["Title"])
data_batch[1].append(str(row["Date_time"]))
data_batch[2].append(row["Location"])
data_batch[3].append(row["Speech"])
if len(data_batch[0]) % BATCH_SIZE == 0:
embed_insert(data_batch)
data_batch = [[], [], [], []]
# Embed and insert the remainder
if len(data_batch[0]) != 0:
embed_insert(data_batch)
# Call a flush to index any unsealed segments.
collection.flush()
7、语义搜索白宫演讲
假设我有兴趣找到总统在国家可再生能源实验室 (NREL) 发表的关于可再生能源影响的演讲,以及美国副总统和加拿大总理发表的演讲。 我可以使用我们刚刚创建的矢量数据库找到 2021-2022 年白宫成员发表的最相似演讲的标题。
我们可以在我们的矢量数据库中搜索与我们的描述最相似的演讲。 然后,我们所要做的就是使用与获取语音嵌入相同的模型将描述转换为向量嵌入,然后搜索向量数据库。
一旦我们将描述转换为向量嵌入,我们就可以在我们的集合上使用搜索功能。 我们将嵌入作为搜索数据传入,传入我们要查找的字段,添加一些关于如何搜索的参数、结果数量限制和我们要返回的字段。 在此示例中,我们需要传递的搜索参数是度量类型,它必须与我们在创建索引时使用的类型(L2 范数)和我们要搜索的聚类数(将 nprobe 设置为 10)相同。
import time
search_terms = ["The President speaks about the impact of renewable energy at the National Renewable Energy Lab.", "The Vice President and the Prime Minister of Canada both speak."]
# Search the database based on input text
def embed_search(data):
embeds = transformer.encode(data)
return [x for x in embeds]
search_data = embed_search(search_terms)
start = time.time()
res = collection.search(
data=search_data, # Embeded search value
anns_field="embedding", # Search across embeddings
param={"metric_type": "L2",
"params": {"nprobe": 10}},
limit = TOPK, # Limit to top_k results per search
output_fields=["title"] # Include title field in result
)
end = time.time()
for hits_i, hits in enumerate(res):
当我们搜索这个例子中的句子时,我们希望看到如下图所示的输出。 这是一次成功的搜索,因为标题正是我们期望看到的。 第一个描述返回拜登总统在 NREL 发表的演讲的标题,第二个描述返回反映副总统卡马拉哈里斯和总理贾斯汀特鲁多的演讲的标题。

8、结束语
在本教程中,我们学习了如何使用向量数据库对拜登政府在 2022 年中期选举前发表的演讲进行语义搜索。 语义搜索让我们可以通过模糊来寻找语义相似的文本,而不仅仅是句法相似的文本。 这使我们能够搜索对演讲的一般描述,而不是根据特定的句子或引语搜索演讲。 对于我们大多数人来说,这使得寻找我们感兴趣的演讲变得更加容易。
原文链接:Milvus应用开发实战 — BimAnt








![C++——类和对象[下]](https://img-blog.csdnimg.cn/img_convert/40e304b83f7e81354eeb0aee2f96075c.png)