2.1Netty是什么
是一个基于异步的(多线程处理结果和接收)、事件驱动的网络应用框架,用于基于快速开发可维护、高性能的网络服务器和客户端
异步是指调用时的异步,他的IO还是多路复用的IO
许多中间件都依赖与Netty
- zookper
- hadoop
- Spring 5.x - flux 抛弃了Tomact 使用netty作为服务器端
Netty优势
- 解决很多网络传输中的问题,比如黏包和半包
- 对API进行增强
- 防止epoll空轮询导致CPU100%
2.2Hello World
目标:
开发一个简单的服务器端和客户端
- 客户端向服务器发送hello world
- 服务器仅接收,不返回
- HelloServer
public class HelloServer {
public static void main(String[] args) {
//1. 启动器 负责组装netty组件 启动服务器
new ServerBootstrap()
//2.BossEventLoop WorkerEventLoop(selector,thread) 加入一个eventGroup组
//EventLoop用来处理数据的容器
.group(new NioEventLoopGroup())
//3. 选择服务器的实现
.channel(NioServerSocketChannel.class)
//4. boss 负责处理连接 worker(child)负责处理读写 决定了worker(child) 能执行哪些操作(handler)
.childHandler(
//5. channel代表和客户端进行数据读写的通道 Initializer初始化器 负责添加别的handler
new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
//6.添加具体的handler
//用于解码 将传输过来的数据类型(byteBuf) 转换成字符串
//服务器收到接收的结果后,调用handler的初始化方法 然后一步一步执行自己写的handler即可
nioSocketChannel.pipeline().addLast(new StringDecoder());
//自定义的handler
nioSocketChannel.pipeline().addLast(new ChannelInboundHandlerAdapter(){
//处理读事件
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
//打印上一步转换好的字符串
System.out.println(msg);
}
});
}
//7. 绑定 监听端口
}).bind(8080);
}
}
- HelloClient
public class HelloClient {
public static void main(String[] args) throws InterruptedException {
//1.创建启动器类 启动客户端
new Bootstrap()
//2.添加EventLoop //EventLoop用来处理数据的容器
.group(new NioEventLoopGroup())
//3.选择客户端的channel实现
.channel(NioSocketChannel.class)
//4.添加处理器
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override //连接建立后被调用
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
//编码器 将string -> byteBuf
nioSocketChannel.pipeline().addLast(new StringEncoder());
}
})
//5.连接到服务器
.connect(new InetSocketAddress("localhost",8080))
.sync() //阻塞方法 直到连接建立
.channel()
// 向客户端发送数据
.writeAndFlush("hello,world"); //收发数据都要走handler 这里将str -> ByteBuf 然后发给服务器
}
}
2.3组件
2.3.1EventLoop
本质是一个单线程执行器(同时维护了一个selectror),里面有run方法处理Channel上源源不断的io事件。
继承关系:
- juc.ScheduledExecutorService,所以包含了线程池中的所有方法
- 继承netty自己的OrderEventExecutor
- 提供了boolean inEventLoop(Thread thread)方法判断一个线程是否属于此EventLoop
- 提供了parent方法来看自己属于哪个EventLoop
事件循环组:
EventLoopGroup是一组EventGroup,Channel一般会调用EventLoopGroup
示例:
@Slf4j
public class TestEventLoop {
public static void main(String[] args) {
//1.NioEventLoopGroup功能比较全面:定时任务、Io、普通任务
//不指定参数,默认线程数为cpu核心数*2
EventLoopGroup group = new NioEventLoopGroup(2);
// System.out.println(NettyRuntime.availableProcessors());
//普通任务、定时任务
// EventLoopGroup group2 = new DefaultEventLoopGroup();
//2.获取下一个事件循环对象 每次调用得到下一个 然后回过头从第一个开始
System.out.println(group.next()); //NioEventLoop@d70c109
System.out.println(group.next()); //NioEventLoop@17ed40e0
System.out.println(group.next()); //NioEventLoop@d70c109
//3.执行普通任务 异步处理
// group.next().submit(()->{
// log.debug("new Runnable OK"); //[nioEventLoopGroup-2-1]
// });
//4.执行定时任务 初始延迟1s后 2s打印一次
group.next().scheduleAtFixedRate(()->{
log.debug("data ok");
},1,2, TimeUnit.SECONDS);
log.debug("Main OK");
}
}
接收和发送案例
- client
@Sl4j
public class EventLoopClient {
public static void main(String[] args) throws InterruptedException {
//1.创建启动器类 启动客户端
Channel channel = new Bootstrap()
//2.添加EventLoop EventLoop用来处理数据的容器
.group(new NioEventLoopGroup())
//3.选择客户端的channel实现
.channel(NioSocketChannel.class)
//4.添加处理器
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override //连接建立后被调用
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
//编码器 将string -> byteBuf
nioSocketChannel.pipeline().addLast(new StringEncoder());
}
})
//5.连接到服务器
.connect(new InetSocketAddress("localhost", 8080))
.sync() //阻塞方法 直到连接建立
.channel();
// 向客户端发送数据
System.out.println(channel);
System.out.println(""); //此处断点 右键断点选择Thread模式
}
}
- server
@Slf4j
public class EventLoopServer {
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
nioSocketChannel.pipeline().addLast(new ChannelInboundHandlerAdapter(){
@Override //没有数据转化的处理器 此处msg是ByteBuf类型
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buffer = (ByteBuf) msg;
log.debug(buffer.toString(Charset.defaultCharset()));
}
});
}
})
.bind(8080);
}
}
断点处右键 发送不同的案例 跑多个client
10:29:30.078 [nioEventLoopGroup-2-3] DEBUG com.rpc.netty.test2.EventLoopServer - 1
10:30:00.447 [nioEventLoopGroup-2-3] DEBUG com.rpc.netty.test2.EventLoopServer - 2
10:30:37.059 [nioEventLoopGroup-2-3] DEBUG com.rpc.netty.test2.EventLoopServer - 2cccc
10:33:34.727 [nioEventLoopGroup-2-4] DEBUG com.rpc.netty.test2.EventLoopServer - 122222
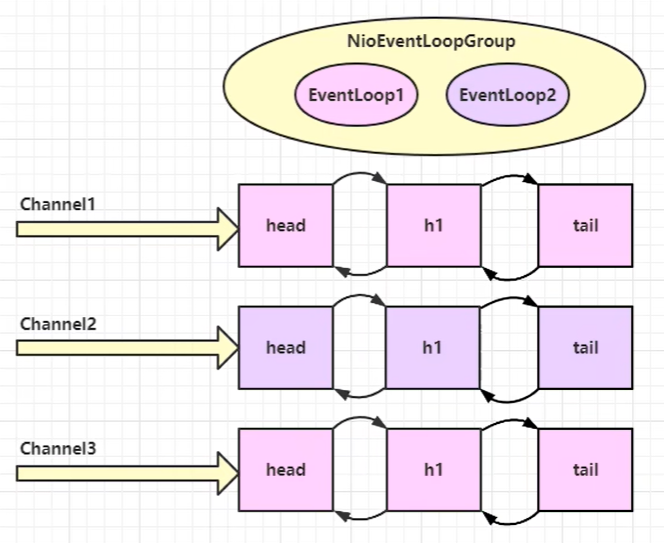
不同的client绑定的nioEventLoopGroup不同,一个client只绑定一个,固定的绑定一个,所以从这可以看到,nioEventLoopGroup其实就像一个大的线程池,里面包含了不同的和client连接的线程,用来处理任务
流程图:
对server的改进:
当多个线程来的时候,有的是accept,有的是读写操作,我们现在想将他们区分开。那么区分开后会不会有什么问题呢?因为我们使用的是NIO模型,所以当一个线程耗时比较长的时候,可能就会造成其他线程无法处理问题,这个时候怎么办呢?
我们的解决办法都是用不同的EventLoop去处理不同的问题:
@Slf4j
public class EventLoopServer {
public static void main(String[] args) {
//改进2: 防止一个线程等待时间过长影响其他线程 创一个独立的EventLoopGroup去处理
DefaultEventLoopGroup group = new DefaultEventLoopGroup();
new ServerBootstrap()
//改进1,负责accept和read
//boos 和 worker boos只负责处理accept事件 worker只负责读写
.group(new NioEventLoopGroup(),new NioEventLoopGroup(2))//worker 只有两个 可以一个线程连接多个client
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
//todo 改进2:命名为handler1 和handler2进行对比
nioSocketChannel.pipeline().addLast("handler1",new ChannelInboundHandlerAdapter(){
@Override //没有数据转化的处理器 此处msg是ByteBuf类型
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buffer = (ByteBuf) msg;
log.debug(buffer.toString(Charset.defaultCharset()));
log.debug("handler1被{}线程处理",Thread.currentThread().getName());
//todo 将消息传递给下一个handler
ctx.fireChannelRead(msg);
}
//todo 改进2:使用group里的线程进行处理,命名为handler2
}).addLast(group,"handler2",new ChannelInboundHandlerAdapter(){
@Override //没有数据转化的处理器 此处msg是ByteBuf类型
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf buffer = (ByteBuf) msg;
log.debug(buffer.toString(Charset.defaultCharset()));
log.debug("handler2被{}线程处理",Thread.currentThread().getName());
}
});
}
})
.bind(8080);
}
}
用三个不同的客户端发消息,结果:
14:35:15.206 [nioEventLoopGroup-4-1] DEBUG com.rpc.netty.test2.EventLoopServer - 1
14:35:15.206 [nioEventLoopGroup-4-1] DEBUG com.rpc.netty.test2.EventLoopServer - handler1被nioEventLoopGroup-4-1线程处理
14:35:15.207 [defaultEventLoopGroup-2-1] DEBUG com.rpc.netty.test2.EventLoopServer - 1
14:35:15.207 [defaultEventLoopGroup-2-1] DEBUG com.rpc.netty.test2.EventLoopServer - handler2被defaultEventLoopGroup-2-1线程处理
14:37:33.377 [nioEventLoopGroup-4-1] DEBUG com.rpc.netty.test2.EventLoopServer - 2
14:37:33.377 [nioEventLoopGroup-4-1] DEBUG com.rpc.netty.test2.EventLoopServer - handler1被nioEventLoopGroup-4-1线程处理
14:37:33.377 [defaultEventLoopGroup-2-3] DEBUG com.rpc.netty.test2.EventLoopServer - 2
14:37:33.377 [defaultEventLoopGroup-2-3] DEBUG com.rpc.netty.test2.EventLoopServer - handler2被defaultEventLoopGroup-2-3线程处理
14:37:42.990 [nioEventLoopGroup-4-2] DEBUG com.rpc.netty.test2.EventLoopServer - 3
14:37:42.990 [nioEventLoopGroup-4-2] DEBUG com.rpc.netty.test2.EventLoopServer - handler1被nioEventLoopGroup-4-2线程处理
14:37:42.990 [defaultEventLoopGroup-2-4] DEBUG com.rpc.netty.test2.EventLoopServer - 3
14:37:42.990 [defaultEventLoopGroup-2-4] DEBUG com.rpc.netty.test2.EventLoopServer - handler2被defaultEventLoopGroup-2-4线程处理
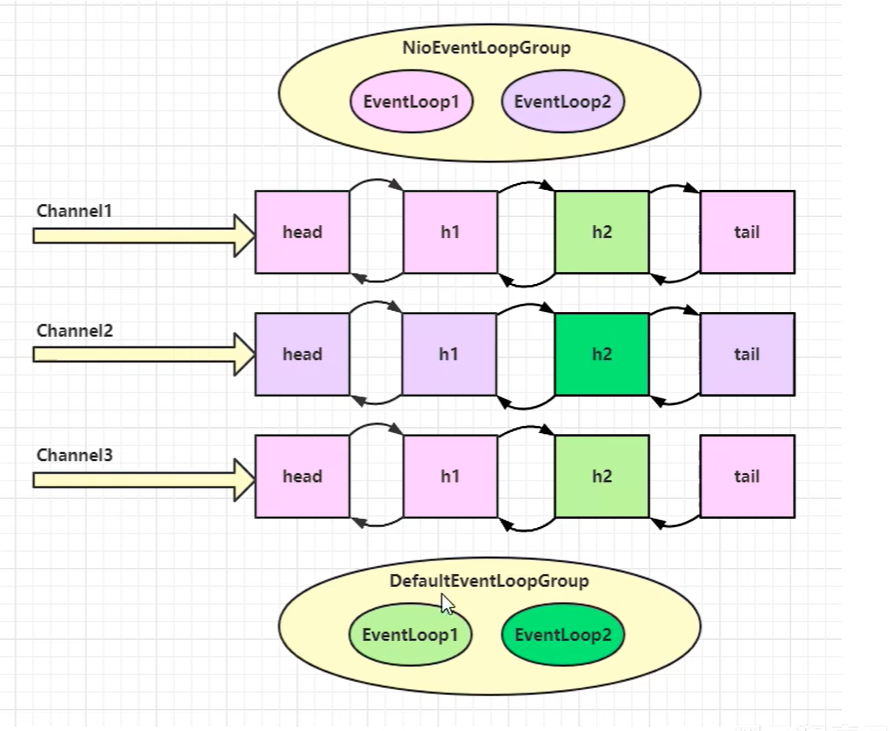
其实可以看到,读写操作给一个EventLoop去执行了,hander2用的也是另外一个eventLoop去执行的
流程图:
handler执行过程中如何切换给不同EventLoop处理handler的呢?
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
//下一个handler的时间循环是否与当前的事件循环是一个线程
EventExecutor executor = next.executor();
//是 直接调用
if (executor.inEventLoop()) { //是否是同一个线程
next.invokeChannelRead(m);
} else {
//不是 将要执行的diamante作为任务提交给下一个事件循环处理
executor.execute(new Runnable() {
public void run() {
next.invokeChannelRead(m);
}
});
}
}
- 如果两个handler绑定的是同一个线程,那么直接调用
- 如果不是,那么将会作为一个runnable传递给下一个handler的线程来调用
2.3.2Channel
channle主要作用:
- close可以用来关闭channel
- closeFuture用来处理channel的关闭
- sync方法作用是同步等待channel的关闭
- 而addList方法是异步等待channel关闭
- plpeline方法添加处理器
- write方法将数据写入
- writeAndFlush方法将数据写入
Channel常用方法
1.处理异步连接
我们思考一个问题,为什么要用sync方法?
我们先看这样一个初始化客户端的写法:
@Slf4j
public class EventLoopClient {
public static void main(String[] args) throws InterruptedException {
//xxxFuture、Promise基本都是和异步方法配合使用,用来处理结果
ChannelFuture channelFuture = new Bootstrap()
.group(new NioEventLoopGroup())
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override //连接建立后被调用
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
nioSocketChannel.pipeline().addLast(new StringEncoder());
}
})
//1.连接到服务器
//异步非阻塞 main 调用该方法 但是真正连接服务器的 是另一个线程 Nio线程
.connect(new InetSocketAddress("localhost", 8080)); //可能1s后执行
}
返回了一个ChannelFuture对象,那么他有什么用呢?
他会异步非阻塞的去连接服务器,如果我们不写channel.sync方法,我们尝试去连接服务器发数据,我们的数据是没办法发送成功的
Channel channel = channelFuture.channel();
log.debug("{}",channel);
channel.writeAndFlush("hello world");
原因也很简单,因为他是异步的,所以当channelFuture.channel();先被执行时,因为没连接到,所以此时的channel是个空的,自然无法连接到服务器。
针对这个原因,我们提供了如下两个方法:
//todo 1.使用sync同步处理结果,sync的作用就是等待connect连接成功,再继续执行下面的方法
// channelFuture.sync(); //阻塞住 等待nio连接建立完成
// Channel channel = channelFuture.channel();
// log.debug("{}",channel);
// channel.writeAndFlush("hello world");
//todo 2: 使用addListener(回调对象) 方法异步处理结果
channelFuture.addListener(new ChannelFutureListener(){
@Override //在nio线程连接建立完之后,会调用该方法
public void operationComplete(ChannelFuture channelFuture) throws Exception {
//调用下面的 发送的不是主线程 是nio线程
Channel channel = channelFuture.channel();
log.debug("{}",channel);
channel.writeAndFlush("222");
}
});
方式2日志结果:
21:45:24.571 [nioEventLoopGroup-2-1] DEBUG com.rpc.netty.test3.EventLoopClient - [id: 0xc70019e8, L:/127.0.0.1:1752 - R:localhost/127.0.0.1:8080]
可见,是个nio的线程进行处理的
⎛⎝≥⏝⏝≤⎛⎝
2.处理异步关闭后的操作
我们现在有另一个需求,我们需要让客户端断开连接之后,继续执行一些操作,我们现在有这样的想法:
@Slf4j
public class CloseFutureClient {
public static void main(String[] args) throws InterruptedException {
NioEventLoopGroup group = new NioEventLoopGroup();
ChannelFuture channelFuture = new Bootstrap()
.group(group)
.channel(NioSocketChannel.class)
.handler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
nioSocketChannel.pipeline().addLast(new LoggingHandler(LogLevel.DEBUG)); //日志级别 debug
nioSocketChannel.pipeline().addLast(new StringEncoder());
}
})
.connect(new InetSocketAddress("localhost", 8080));
Channel channel = channelFuture.sync().channel();
log.debug("{}",channel);
new Thread(()->{
Scanner scanner = new Scanner(System.in);
while (true){
String next = scanner.next();
if("q".equals(next)){
channel.close();
break;
}
channel.writeAndFlush(next);
}
},"input").start();
log.debug("处理关闭之后的操作");
}
}
当我们将这个客户端启动之后,我们就可以看见已经开始处理关闭在之后的操作了,显然,这不是我们需要的,原因就是因为客户端的连接以及在线程里进行收取信息,这些其实都是异步的,而主线程在启动之后就会打印日志内容了。
那么我们在channel.close();之后处理可以吗?
这也是不行的,因为close也是异步方法,所有后面的也不一定会被处理掉。
那该怎么办?
其实和1内连接类似,提供下面两种方法:
//todo 3.正确写法:
//获取CloseFuture对象
ChannelFuture closeFuture = channel.closeFuture();
System.out.println("waiting close....");
//3.1同步模式处理关闭
// closeFuture.sync();
// log.debug("处理关闭之后的操作"); //main线程打印
//3.2 异步关闭 类似channel的
closeFuture.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture channelFuture) throws Exception {
log.debug("处理关闭之后的操作"); //[nioEventLoopGroup-2-1] 线程执行
}
});
这些都可以实现
但是新的问题又来了,我们close之后,客户端并不会自动的停止运行,这是怎么回事?
因为NioEventLoopGroupe内还有些线程在运行,所以我们需要在处理关闭之后的操作后单独的调用一下他的关闭方法
//优雅关闭Nio线程,拒绝接收新的任务
group.shutdownGracefully();
他将会拒绝接收新的任务,然后优美的结束
为什么netty需要异步?
异步效率高?
相比于只使用一个一个的线程去处理相同的事情,不如用相同的线程,每个线程只处理一个事件,就像 医院的挂号、看病、结账、拿药一样,分派给不同的人去做。
- 单线程没有办法异步提高效率,必须配合多线程、多核CPU才能发挥异步的优势
- 异步没有缩短响应时间,反而有所增加
- 合理进行任务拆分,也是利用异步的关键
2.3.3Future & Promise
异步处理常用的两个接口
netty的Futrue继承自jdk的Futrue,而Promise继承netty的Future
- jdk:Future只能同步等待任务结束(成功或失败),才能得到结果
- netty:
- Future可以同步等待任务结束结果,也可以异步获取结果,但是都要等待任务结束
- Promise:不仅有netty Future 的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器
jdk Future 、Netty Future & Promise
具体例子:
- jdk Future
@Slf4j
public class TestJdkFuture {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//1.jdk的future主要关联线程池使用
ExecutorService pool = Executors.newFixedThreadPool(2);
//2.提交任务
Future<Integer> future = pool.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("执行计算");
Thread.sleep(1000);
return 50;
}
});
//3.main线程通过future获取结果
log.debug("等待结果");
Integer res = future.get();
log.debug("结果是:{}",res);
}
}
- netty Future
@Slf4j
public class TestNettyFuture {
public static void main(String[] args) throws ExecutionException, InterruptedException {
NioEventLoopGroup eventLoop = new NioEventLoopGroup();
EventLoop next = eventLoop.next();
Future<Integer> future = next.submit(new Callable<Integer>() {
@Override
public Integer call() throws Exception {
log.debug("处理结果");
Thread.sleep(1000);
return 100;
}
});
log.debug("等待结果");
// log.debug("结果{}",future.get()); //同步方式获取结果
//异步获取结果
future.addListener(new GenericFutureListener<Future<? super Integer>>() {
@Override
public void operationComplete(Future<? super Integer> future) throws Exception {
log.debug("接收结果:{}",future.getNow()); //立刻获取结果 非阻塞
}
});
}
}
- Netty Promise
@Slf4j
public class TestNettyPromise {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//1.准备eventLoop对象
EventLoop eventLoop = new NioEventLoopGroup().next();
//2.主动拿到promise对象 结果容器
DefaultPromise<Integer> promise = new DefaultPromise<>(eventLoop);
//3.线程执行计算,像promise对象填充结果
new Thread(()->{
log.debug("开始计算1");
try {
int i = 1/0;
Thread.sleep(1000);
//计算成功结果放入容器
promise.setSuccess(80);
} catch (InterruptedException e) {
e.printStackTrace();
//异常 将异常也放进容器
promise.setFailure(e);
}
}).start();
//4.接收结果的线程
log.debug("等待结果");
log.debug("结果:{}",promise.get());
}
}
2.3.4Handler & Pipeline
业务处理主要在Handler工作
ChannelHandler用来处理Channel上的各种事件,分为入站和出站。所有ChannelHandler连成一起,就是Pipeline
看看他们之间的关系吧
@Slf4j
public class TestPipeline {
public static void main(String[] args) {
new ServerBootstrap()
.group(new NioEventLoopGroup())
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
//1.通过nio拿到pipeline(pipeline)
ChannelPipeline pipeline = nioSocketChannel.pipeline();
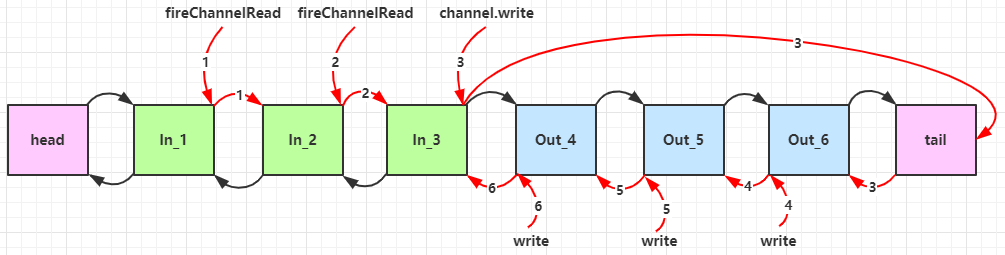
//2.添加处理器 handler链(双向链表):head -> h1 -> h2 -> h3 -> tail
pipeline.addLast("handler1",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("1");
ByteBuf buf = (ByteBuf) msg;
String name = buf.toString(Charset.defaultCharset());
//传递给h2 用来往下走 此时用来传递处理的是name 也就是这里处理过的
super.channelRead(ctx, name);
}
});
pipeline.addLast("handler2",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
log.debug("2");
//获取到name后 转换成student
Student student = new Student(msg.toString());
super.channelRead(ctx, student);
//作用和super.channelRead效果一样
// ctx.fireChannelRead(student);
}
});
pipeline.addLast("handler3",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object student) throws Exception {
log.debug("3,结果:{},类型:{}",student,student.getClass());
//后面没有入站处理器,所以写出操作
//为了触发下面的出站处理器4 5 6 否则下面的只有写入操作才会触发
//ctx是从当前处理器,向前去找出站处理器,不是往后找,所以下面的出站处理器不会被执行
ctx.writeAndFlush(ctx.alloc().buffer().writeBytes("hello".getBytes()));
//下面的这个可以往后调用整条
// nioSocketChannel.writeAndFlush(ctx.alloc().buffer().writeBytes("server".getBytes()));
}
});
//出站处理器 出站处理器会从后往前走 所以流程是6-> 5 -> 4
pipeline.addLast("handler4",new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("4");
super.write(ctx, msg, promise);
}
});
pipeline.addLast("handler5",new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("5");
super.write(ctx, msg, promise);
}
});
pipeline.addLast("handler6",new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
log.debug("6");
super.write(ctx, msg, promise);
}
});
}
})
.bind(8080);
}
@Data
@AllArgsConstructor
static class Student{
private String name;
}
}
客户端使用CloseFutureClient
整个调用结果:
10:06:11.458 [nioEventLoopGroup-2-2] DEBUG com.rpc.netty.test5.TestPipeline - 1
10:06:11.460 [nioEventLoopGroup-2-2] DEBUG com.rpc.netty.test5.TestPipeline - 2
10:06:11.461 [nioEventLoopGroup-2-2] DEBUG com.rpc.netty.test5.TestPipeline - 3,结果:TestPipeline.Student(name=jj),类型:class com.rpc.netty.test5.TestPipeline$Student
因为里面ctx的操作问题,具体看里面的注释
下面是整个调用链的结构:
2.3.5ByteBuf
对字节数据的封装
创建
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import static io.netty.buffer.ByteBufUtil.appendPrettyHexDump;
import static io.netty.util.internal.StringUtil.NEWLINE;
/**
* @author 我见青山多妩媚
* @date 2023/5/3 0003 11:03
* @Description TODO
*/
public class TestByteBuf {
public static void main(String[] args) {
//不知道容量为256
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer();
log(buffer); //read index:0 write index:0 capcacity:256
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 32; i++) {
builder.append("a");
}
buffer.writeBytes(builder.toString().getBytes());
log(buffer); //read index:0 write index:300 capcacity:512
}
private static void log(ByteBuf buffer){
int len = buffer.readableBytes();
int rows = len/16 + (len % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capcacity:").append(buffer.capacity())
.append(NEWLINE);
appendPrettyHexDump(buf,buffer);
System.out.println(buf.toString());
}
}
直接内存 vs 堆内存
直接内存:
NIO的Buffer提供了一个可以不经过JVM内存直接访问系统物理内存的类——DirectBuffer。 DirectBuffer类继承自ByteBuffer,但和普通的ByteBuffer不同,普通的ByteBuffer仍在JVM堆上分配内存,其最大内存受到最大堆内存的限制;而DirectBuffer直接分配在物理内存中,并不占用堆空间,其可申请的最大内存受操作系统限制。
堆内存:
Java 虚拟机具有一个堆,堆是运行时数据区域,所有类实例和数组的内存均从此处分配。堆是在 Java 虚拟机启动时创建的。对象的堆内存由称为垃圾回收器的自动内存管理系统回收。
区别:
- 直接内存的读写操作比普通Buffer快,但它的创建、销毁比普通Buffer慢。
- 因此直接内存使用于需要大内存空间且频繁访问的场合,不适用于频繁申请释放内存的场合。
可以用下面的代码创建池化基于堆的ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.heapBuffer(10);
也可以使用下面的代码来创建池化基于直接内存的ByteBuff
ByteBuf buffer = ByteBufAllocatoe.DEFAULT.directBuffer(10);
- 直接内存创建和销毁代价昂贵,但读写性能高(少一次内存复制,适合配合池化功能一起使用)
- 直接内存对GC内存压力小,因为这部分内存不受JVM垃圾回收的管理,但也要注意及时主动释放
池化 vs 非池化
池化的最大意义在于可以重用ByteBuf,优点包括
- 没有池化,则每次都得创建新的ByteBuf实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加GC压力
- 有了池化,则可以重用池中ByteBuf实例,并且采用了与jemalloc类似的内存分配算法提升分配效率
- 高并发时,池化功能更节约内存,减少内存溢出的可能
池化功能是否开启,可以通过下面的系统环境变量来设置
-Dio,netty.allocator.type={unpooled|pooled}
- 4.1以后,非安卓平台默认开启池化实现,安卓采用非池化
- 4.1之前,池化不成熟,都是非池化ww
组成
ByteBuf由四部分组成:
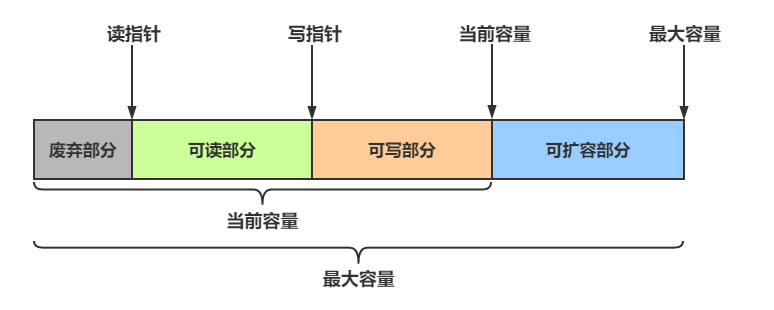
最开始读写指针都在0位置
写入
常用方法如下
| 方法签名 | 含义 | 备注 |
|---|---|---|
| writeBoolean(boolean value) | 写入 boolean 值 | 用一字节 01|00 代表 true|false |
| writeByte(int value) | 写入 byte 值 | |
| writeShort(int value) | 写入 short 值 | |
| writeInt(int value) | 写入 int 值 | Big Endian(大端写入),即 0x250,写入后 00 00 02 50 |
| writeIntLE(int value) | 写入 int 值 | Little Endian(小端写入),即 0x250,写入后 50 02 00 00 |
| writeLong(long value) | 写入 long 值 | |
| writeChar(int value) | 写入 char 值 | |
| writeFloat(float value) | 写入 float 值 | |
| writeDouble(double value) | 写入 double 值 | |
| writeBytes(ByteBuf src) | 写入 netty 的 ByteBuf | |
| writeBytes(byte[] src) | 写入 byte[] | |
| writeBytes(ByteBuffer src) | 写入 nio 的 ByteBuffer | |
| int writeCharSequence(CharSequence sequence, Charset charset) | 写入字符串 | CharSequence为字符串类的父类,第二个参数为对应的字符集 |
注意
- 这些方法的未指明返回值的,其返回值都是 ByteBuf,意味着可以链式调用来写入不同的数据
- 网络传输中,默认习惯是 Big Endian,使用 writeInt(int value)
使用方法
public class ByteBufStudy {
public static void main(String[] args) {
// 创建ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16, 20);
ByteBufUtil.log(buffer);
// 向buffer中写入数据
buffer.writeBytes(new byte[]{1, 2, 3, 4});
ByteBufUtil.log(buffer);
buffer.writeInt(5);
ByteBufUtil.log(buffer);
buffer.writeIntLE(6);
ByteBufUtil.log(buffer);
buffer.writeLong(7);
ByteBufUtil.log(buffer);
}
}
运行结果
read index:0 write index:0 capacity:16
read index:0 write index:4 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 |.... |
+--------+-------------------------------------------------+----------------+
read index:0 write index:8 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 00 00 00 05 |........ |
+--------+-------------------------------------------------+----------------+
read index:0 write index:12 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 00 00 00 05 06 00 00 00 |............ |
+--------+-------------------------------------------------+----------------+
read index:0 write index:20 capacity:20
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 00 00 00 05 06 00 00 00 00 00 00 00 |................|
|00000010| 00 00 00 07 |.... |
+--------+-------------------------------------------------+----------------+
还有一类方法是 set 开头的一系列方法,也可以写入数据,但不会改变写指针位置
扩容
当ByteBuf中的容量无法容纳写入的数据时,会进行扩容操作
buffer.writeLong(7);
ByteBufUtil.log(buffer);
// 扩容前
read index:0 write index:12 capacity:16
...
// 扩容后
read index:0 write index:20 capacity:20
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 00 00 00 05 06 00 00 00 00 00 00 00 |................|
|00000010| 00 00 00 07 |.... |
+--------+-------------------------------------------------+----------------+
扩容规则
-
如何写入后数据大小未超过 512 字节,则选择下一个 16 的整数倍进行扩容
- 例如写入后大小为 12 字节,则扩容后 capacity 是 16 字节
-
如果写入后数据大小超过 512 字节,则选择下一个 2
n
- 例如写入后大小为 513 字节,则扩容后 capacity 是 210=1024 字节(29=512 已经不够了)
-
扩容不能超过 maxCapacity,否则会抛出
java.lang.IndexOutOfBoundsException异常
Exception in thread "main" java.lang.IndexOutOfBoundsException: writerIndex(20) + minWritableBytes(8) exceeds maxCapacity(20): PooledUnsafeDirectByteBuf(ridx: 0, widx: 20, cap: 20/20)
...
读取
读取主要是通过一系列read方法进行读取,读取时会根据读取数据的字节数移动读指针
如果需要重复读取,需要调用buffer.markReaderIndex()对读指针进行标记,并通过buffer.resetReaderIndex()将读指针恢复到mark标记的位置
public class ByteBufStudy {
public static void main(String[] args) {
// 创建ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16, 20);
// 向buffer中写入数据
buffer.writeBytes(new byte[]{1, 2, 3, 4});
buffer.writeInt(5);
// 读取4个字节
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
System.out.println(buffer.readByte());
ByteBufUtil.log(buffer);
// 通过mark与reset实现重复读取
buffer.markReaderIndex();
System.out.println(buffer.readInt());
ByteBufUtil.log(buffer);
// 恢复到mark标记处
buffer.resetReaderIndex();
ByteBufUtil.log(buffer);
}
}
结果:
1
2
3
4
read index:4 write index:8 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 05 |.... |
+--------+-------------------------------------------------+----------------+
5
read index:8 write index:8 capacity:16
read index:4 write index:8 capacity:16
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 00 00 00 05 |.... |
+--------+-------------------------------------------------+----------------+
还有以 get 开头的一系列方法,这些方法不会改变读指针的位置
释放
由于 Netty 中有堆外内存(直接内存)的 ByteBuf 实现,堆外内存最好是手动来释放,而不是等 GC 垃圾回收。
- UnpooledHeapByteBuf 使用的是 JVM 内存,只需等 GC 回收内存即可
- UnpooledDirectByteBuf 使用的就是直接内存了,需要特殊的方法来回收内存
- PooledByteBuf 和它的子类使用了池化机制,需要更复杂的规则来回收内存
Netty 这里采用了引用计数法来控制回收内存,每个 ByteBuf 都实现了 ReferenceCounted 接口
- 每个 ByteBuf 对象的初始计数为 1
- 调用 release 方法计数减 1,如果计数为 0,ByteBuf 内存被回收
- 调用 retain 方法计数加 1,表示调用者没用完之前,其它 handler 即使调用了 release 也不会造成回收
- 当计数为 0 时,底层内存会被回收,这时即使 ByteBuf 对象还在,其各个方法均无法正常使用
释放规则
因为 pipeline 的存在,一般需要将 ByteBuf 传递给下一个 ChannelHandler,如果在每个 ChannelHandler 中都去调用 release ,就失去了传递性(如果在这个 ChannelHandler 内这个 ByteBuf 已完成了它的使命,那么便无须再传递)
基本规则是,谁是最后使用者,谁负责 release
-
起点,对于 NIO 实现来讲,在 io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe.read 方法中首次创建 ByteBuf 放入 pipeline(line 163 pipeline.fireChannelRead(byteBuf))
-
入站 ByteBuf 处理原则
- 对原始 ByteBuf 不做处理,调用 ctx.fireChannelRead(msg) 向后传递,这时无须 release
- 将原始 ByteBuf 转换为其它类型的 Java 对象,这时 ByteBuf 就没用了,必须 release
- 如果不调用 ctx.fireChannelRead(msg) 向后传递,那么也必须 release
- 注意各种异常,如果 ByteBuf 没有成功传递到下一个 ChannelHandler,必须 release
- 假设消息一直向后传,那么 TailContext 会负责释放未处理消息(原始的 ByteBuf)
-
出站 ByteBuf 处理原则
- 出站消息最终都会转为 ByteBuf 输出,一直向前传,由 HeadContext flush 后 release
-
异常处理原则
-
有时候不清楚 ByteBuf 被引用了多少次,但又必须彻底释放,可以循环调用 release 直到返回 true
while (!buffer.release()) {}
-
当ByteBuf被传到了pipeline的head与tail时,ByteBuf会被其中的方法彻底释放,但前提是ByteBuf被传递到了head与tail中
TailConext中释放ByteBuf的源码
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug("Discarded inbound message {} that reached at the tail of the pipeline. Please check your pipeline configuration.", msg);
} finally {
// 具体的释放方法
ReferenceCountUtil.release(msg);
}
}
判断传过来的是否为ByteBuf,是的话才需要释放
public static boolean release(Object msg) {
return msg instanceof ReferenceCounted ? ((ReferenceCounted)msg).release() : false;
}
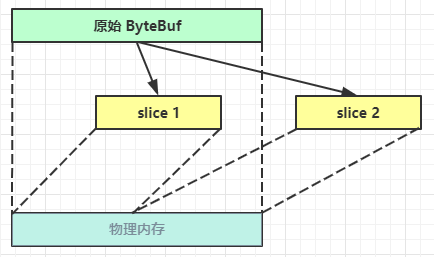
切片
ByteBuf切片是【零拷贝】的体现之一,对原始 ByteBuf 进行切片成多个 ByteBuf,切片后的 ByteBuf 并没有发生内存复制,还是使用原始 ByteBuf 的内存,切片后的 ByteBuf 维护独立的 read,write 指针
得到分片后的buffer后,要调用其retain方法,使其内部的引用计数加一。避免原ByteBuf释放,导致切片buffer无法使用
修改原ByteBuf中的值,也会影响切片后得到的ByteBuf
public class TestSlice {
public static void main(String[] args) {
// 创建ByteBuf
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16, 20);
// 向buffer中写入数据
buffer.writeBytes(new byte[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10});
// 将buffer分成两部分
ByteBuf slice1 = buffer.slice(0, 5);
ByteBuf slice2 = buffer.slice(5, 5);
// 需要让分片的buffer引用计数加一
// 避免原Buffer释放导致分片buffer无法使用
slice1.retain();
slice2.retain();
ByteBufUtil.log(slice1);
ByteBufUtil.log(slice2);
// 更改原始buffer中的值
System.out.println("===========修改原buffer中的值===========");
buffer.setByte(0,5);
System.out.println("===========打印slice1===========");
ByteBufUtil.log(slice1);
}
}
运行结果
read index:0 write index:5 capacity:5
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 01 02 03 04 05 |..... |
+--------+-------------------------------------------------+----------------+
read index:0 write index:5 capacity:5
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 06 07 08 09 0a |..... |
+--------+-------------------------------------------------+----------------+
===========修改原buffer中的值===========
===========打印slice1===========
read index:0 write index:5 capacity:5
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 05 02 03 04 05 |..... |
+--------+-------------------------------------------------+----------------+
优势
- 池化思想 - 可以重用池中 ByteBuf 实例,更节约内存,减少内存溢出的可能
- 读写指针分离,不需要像 ByteBuffer 一样切换读写模式
- 可以自动扩容
- 支持链式调用,使用更流畅
- 很多地方体现零拷贝,例如
- slice、duplicate、CompositeByteBuf
关于零拷贝

![JavaWeb07(MVC应用01[家居商城]连接数据库)](https://img-blog.csdnimg.cn/6ae1e3e29d924f06b6dc6eb4e4570fee.png)








![WIN10安装CUDA保姆级教程[2023.5.7更新]](https://img-blog.csdnimg.cn/cfa0912708814e4bab44c40ef5d68ed1.png)