一、环境配置
import os
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ["PYSPARK_PYTHON"] = "/root/anaconda3/envs/pyspark_env/bin/python"
os.environ["PYSPARK_DRIVER_PYTHON"] = "/root/anaconda3/envs/pyspark_env/bin/python"
# 2、获取SparkContext对象
# 2.1 设置我们的任务运行的配置信息
conf = SparkConf().setMaster('local[2]').setAppName('wordcount01')
# 2.2 根据配置信息获取SparkContext对象
sc = SparkContext(conf=conf)上面是固定格式!
重点是学习,不要为了搞明白环境变量而耽误了正事。
二、RDD算子
1.(parallelize、map、filter)转换算子
list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# list2 = [('k1','v1'),('k2','v2'),('k3','v3')] #二元组列表
rdd1 = sc.parallelize(list)
rdd2 = rdd1.filter(lambda x: x > 3)
rdd3 = rdd2.map(lambda x: (x, 1))
# 将以上代码执行,然后打开http://node1.itcast.cn:18080/,查看是否生了job,没有job就没有触发任务
# 添加以下行为算子代码,再查看页面
list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# list2 = [('k1','v1'),('k2','v2'),('k3','v3')] #二元组列表
rdd1 = sc.parallelize(list)
rdd2 = rdd1.filter(lambda x: x > 3)
rdd3 = rdd2.map(lambda x: (x, 1))
# 将以上代码执行,然后打开http://node1.itcast.cn:18080/,查看是否生了job,没有job就没有触发任务
# 添加以下行为算子代码,再查看页面
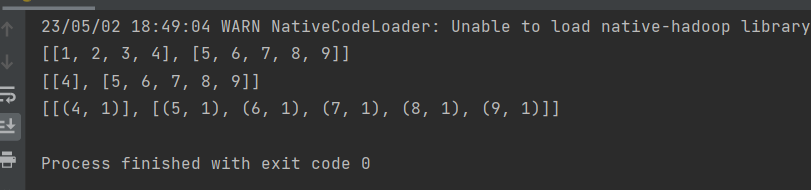
print(rdd1.glom().collect())
print(rdd2.glom().collect())
print(rdd3.glom().collect())


2.flatmap转换算子
list1 = ['夜曲/发如雪/东风破/七里香', '十年/爱情转移/你的背包',
'日不落/舞娘/倒带', '鼓楼/成都/吉姆餐厅/无法长大', '月亮之上/荷塘月色']
rdd1 = sc.parallelize(list1, 2)
print(rdd1.glom().collect())
rdd2 = rdd1.flatMap(lambda x: x.split('/'))
print(rdd2.glom().collect())
rdd2.foreach(lambda x:print(x)) #foreach对Yarn模式支持不够友好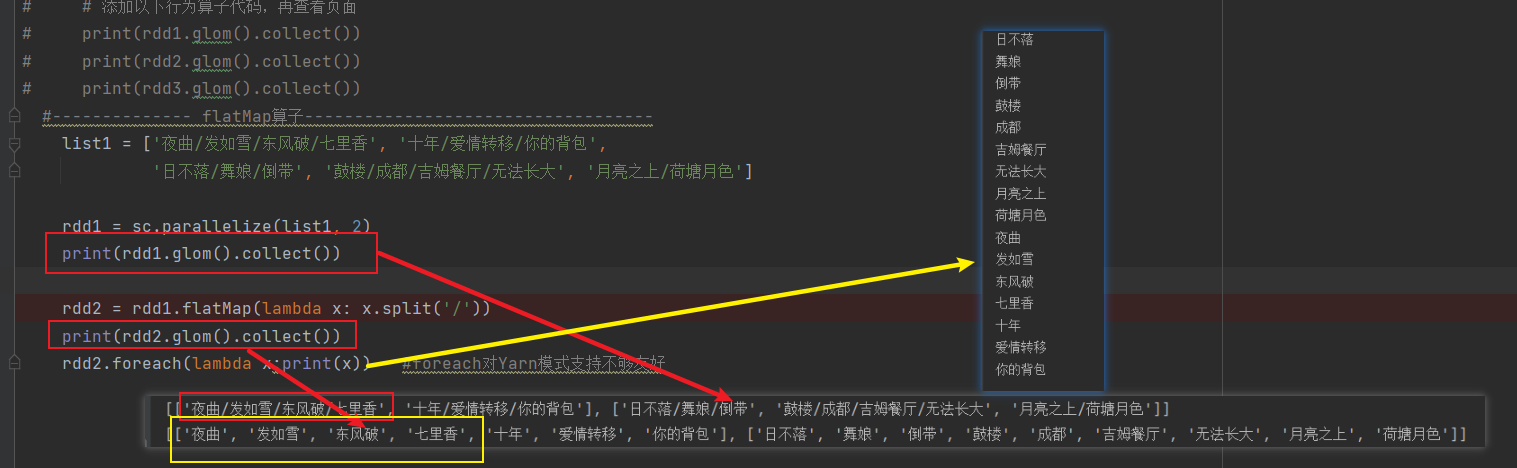
3.filter转换算子
rdd1 = sc.textFile('file:///root/test_filter')
print(rdd1.glom().collect())
# 使用filter算子过滤缺失和性别为-1的数据
# 记住后边一定写满足要求的条件
import re
rdd2 = rdd1.filter(lambda x: (len(re.split(' +', x)) == 4) and ((re.split(' +', x)[2]) != '-1'))
print(rdd2.glom().collect()) 踩坑1:
踩坑1:
并没有上传到HDFS,这里是读的本地文件。
![]()
踩坑2:
这里是有空格的,按一个或多个空格分开

(30条消息) 正则表达式中的*,+,?以及\w和\W的区别等常见问题的总结_正则表达式\w_Miles-的博客-CSDN博客
加了’\s‘也能分,不过加了tab键,会出现’\t'.
rdd1 = sc.textFile('file:///root/test_filter')
print(rdd1.glom().collect())
# 使用filter算子过滤缺失和性别为-1的数据
# 记住后边一定写满足要求的条件
import re
rdd2 = rdd1.filter(lambda x: (len(re.split(r'\s+', x)) == 4) and ((re.split(' +', x)[2]) != '-1'))
print(rdd2.glom().collect())![]()
踩坑3:
filter()保留的是符合条件的数据。
踩坑4:分区的问题
至少两个分区。

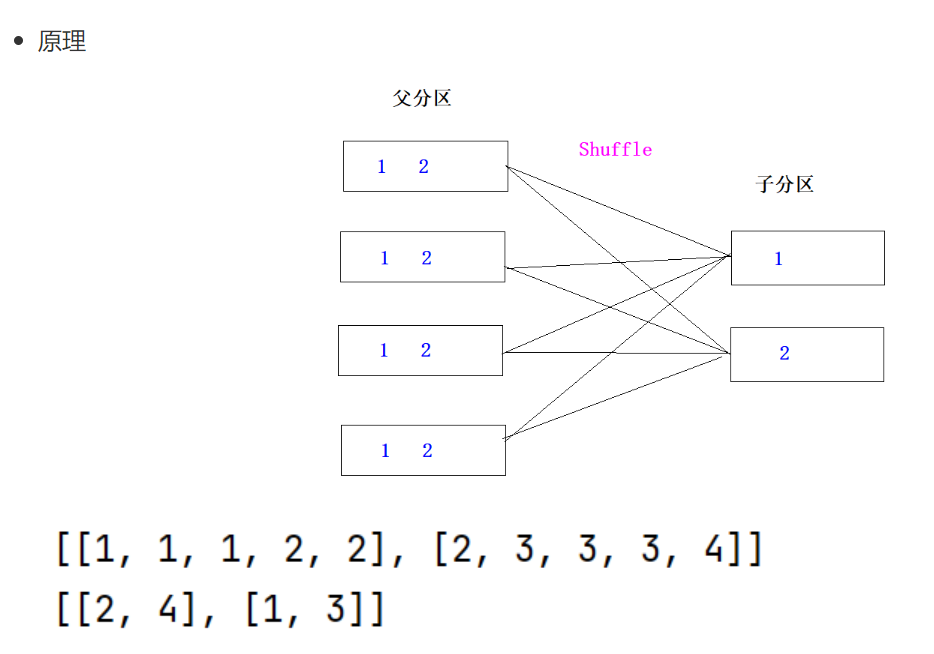
4.union转换算子(会引发shuffle)

5.distinct算子(会引发shuffle)

6.groupByKey算子(会引发shuffle)
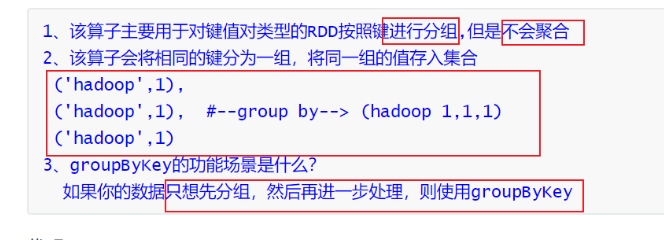
list1 = [
('hadoop', 1),
('hadoop', 1), # --group by--> hadoop 1,1,1
('hadoop', 1)]
rdd1 = sc.parallelize(list1, 2)
# print(rdd1.collect())
print(rdd1.glom().collect())
rdd2 = rdd1.groupByKey()
print(rdd2.glom().collect())
rdd3 = rdd2.map(lambda x: (x[0], *x[1]))
print(rdd3.glom().collect())

踩坑1:
不加glom(),结果不会出现分区;加了glom(),结果会出现分区。
list = [1, 2, 3, 4, 5, 6, 7, 8, 9]
# list2 = [('k1','v1'),('k2','v2'),('k3','v3')] #二元组列表
rdd1 = sc.parallelize(list)
rdd2 = rdd1.filter(lambda x: x > 3)
rdd3 = rdd2.map(lambda x: (x, 1))
print(rdd1.glom().collect())
print(rdd1.collect()) 
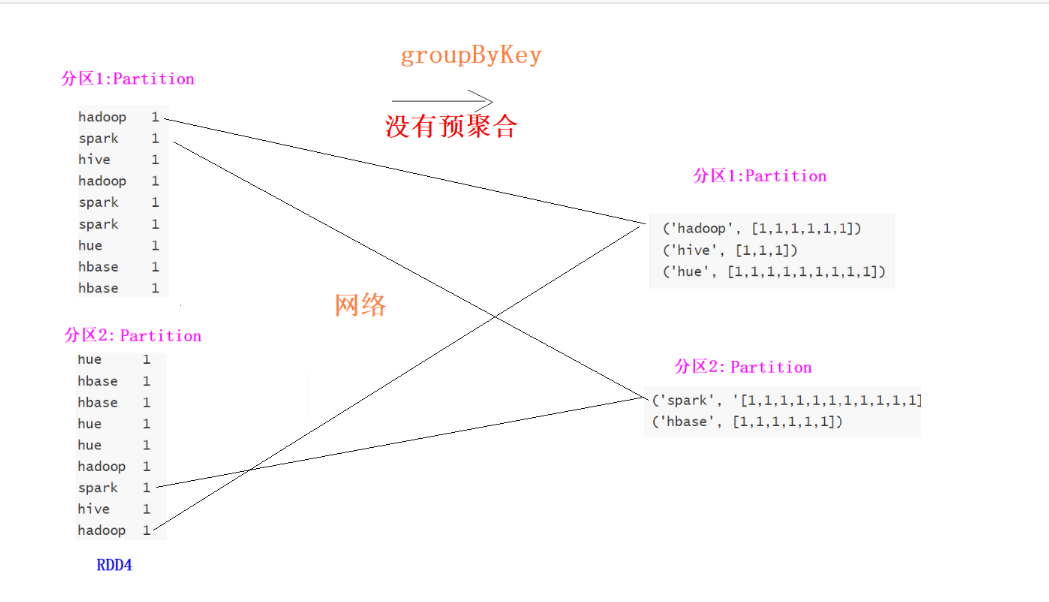
6.reduceByKey算子(会引发shuffle)

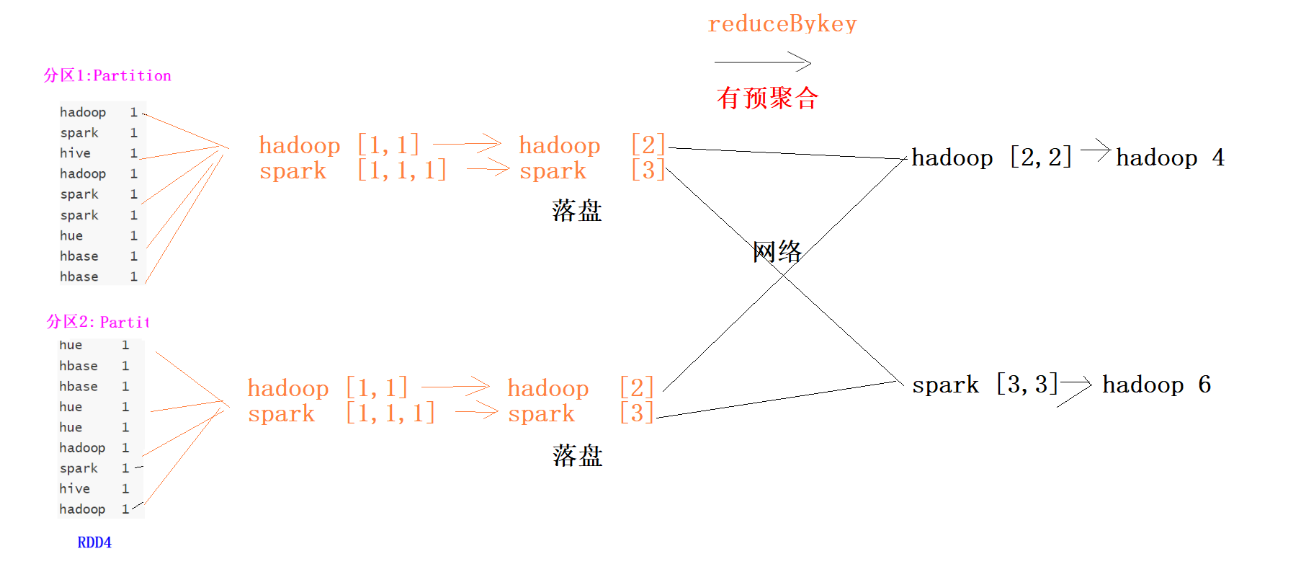
list1 = [
('hadoop',1),
('hadoop',1),
('hadoop',1),
('spark',1),
('spark',1),
]
rdd1 = sc.parallelize(list1, 2)
print(rdd1.collect())
#使用reduceByKey对数据进行分组聚合
rdd2 = rdd1.reduceByKey(lambda x,y : x + y)
print(rdd2.collect())

7. repartition转换算子(会引起shuffle)
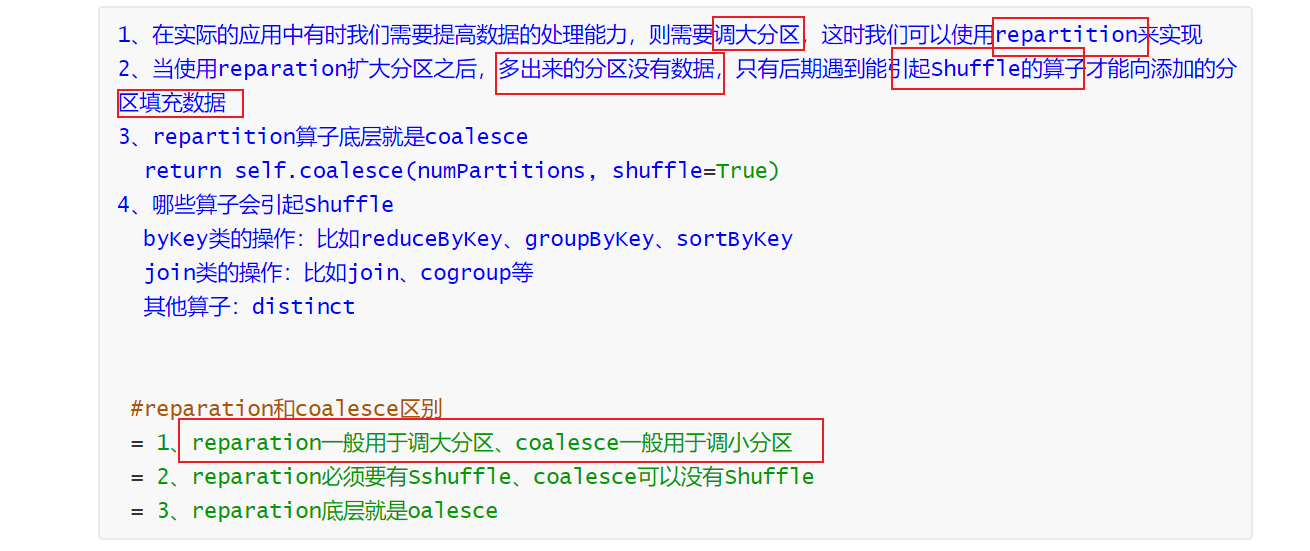
list1 = ['hadoop','spark','hadoop','hive','hdfs','hadoop','spark','hive','hive','hdfs'
'123','zookeeper','flink','flink','presto','mysql','hbase']
#将列表转RDD
rdd1 = sc.parallelize(list1,2)
print(rdd1.glom().collect())
#使用reparation将分区调大
rdd2 = rdd1.repartition(5)
print(rdd2.glom().collect())
rdd3 = rdd2.distinct()
print(rdd3.glom().collect())
8. coalesce 转换算子(建议不使用shuffle)
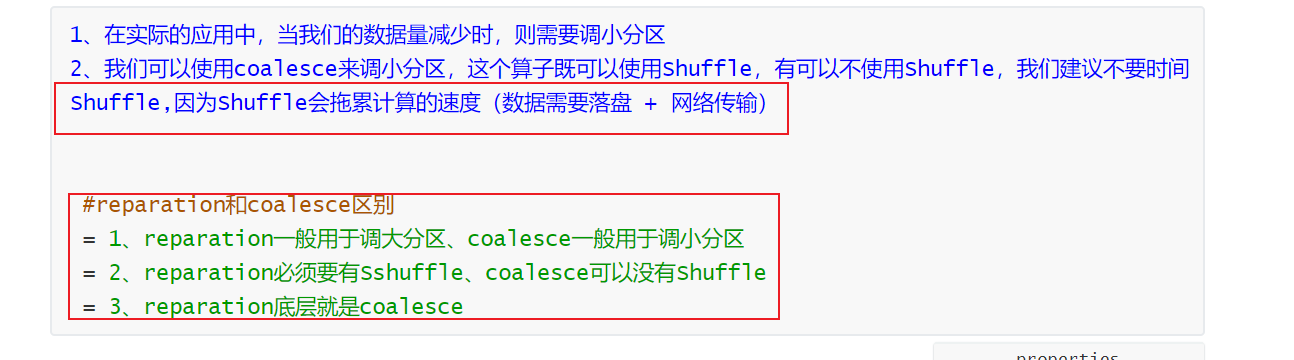
list1 = ['hadoop', 'spark', 'hadoop', 'hadoop', 'hadoop', 'hadoop', 'hadoop', 'hadoop', 'hadoop', 'hadoop']
# 将列表转RDD
rdd1 = sc.parallelize(list1, 10)
print(rdd1.glom().collect())
# 将单词映射为(单词,1)
rdd2 = rdd1.map(lambda x: (x, 1))
print(rdd2.glom().collect())
# 使用reduceByKey进行单词统计
rdd3 = rdd2.reduceByKey(lambda x, y: x + y)
print(rdd3.glom().collect())
# 因为聚合之后,我们的数据量减少,则需要调小分区
rdd4 = rdd3.coalesce(2)
print(rdd4.glom().collect())

9.reduce行为算子

list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
rdd1 = sc.parallelize(list1, 3)
print(rdd1.glom().collect())
#reduce算子根据你提供的函数对数据进行累计统计,这里是累加
#作用:就是对RDD中的每一个元素进行求和
result1 = rdd1.reduce(lambda x,y: x+y)
result2 = rdd1.reduce(lambda x,y: x*y)
print(result1)
print(result2) 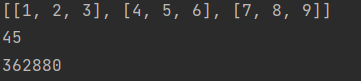

![JavaWeb07(MVC应用01[家居商城]连接数据库)](https://img-blog.csdnimg.cn/6ae1e3e29d924f06b6dc6eb4e4570fee.png)








![WIN10安装CUDA保姆级教程[2023.5.7更新]](https://img-blog.csdnimg.cn/cfa0912708814e4bab44c40ef5d68ed1.png)