原文地址
6.0 Language SQL与PL/pgSQL
PL / PgSQL是基于SQL的特定于PostgreSQL的过程语言 。它有循环,variables,错误/exception处理等等。并不是所有的SQL都是有效的PL / PgSQL,正如你发现的那样,例如,你不能在没有INTO或RETURN QUERY情况下使用SELECT 。PL / PgSQL也可以在DO块中用于一次性程序。
sql函数只能使用纯SQL,但通常效率更高,写起来更简单,因为您不需要BEGIN … END; 块等.SQL函数可以内联,这对于PL / PgSQL来说是不正确的。
人们经常使用PL / PgSQL,因为它们习惯于程序思考。在大多数情况下,当你认为你需要PL / PgSQL时,你可能不需要。recursionCTE,横向查询等通常满足大多数需求。
PL/pgSQL结构
PL/pgSQL是一种块结构(block-structured)的语言。函数定义的所有文本都必须是一个 块。一个块用下面的方法定义:
1 [ <<Label>> ] -- 注意这个地方
2 [ DECLARE
3 declarations ] -- 声明部分
4 BEGIN
5 statements
6 END [ label ];
块中的每个声明和每条语句都是用一个分号终止的, 如果一个子块在另外一个块里, 那么 END 后面必须有个分号,如上所述;不过结束函数体的最后的 END 可以不要这 个分号。提示:BEGIN后边是不需要分号的
所有的关键字和标识符(identifiers)可以大小写混用。如果没有双引号,标识 符默认转换为小写。
在块前面的位于声明部分的变量会在每次块载入的时候(不是每次函数被调 用的时候)被初始化为默认值。
一个示例如下:
1 CREATE FUNCTION somefunc() RETURNS integer AS $$
2 << outerblock >> -- 外部标签
3 DECLARE
4 quantity integer := 30;
5 BEGIN
6 RAISE NOTICE 'Quantity here is %', quantity; -- Prints 30
7 quantity := 50;
8 --
9 -- 创建一个子块
10 --
11 DECLARE
12 quantity integer := 80;
13 BEGIN
14 RAISE NOTICE 'Quantity here is %', quantity; -- Prints 80
15 --使用外部标签
RAISE NOTICE 'Outer quantity here is %', outerblock.quantity; -- Prints 50
16 END;
17 RAISE NOTICE 'Quantity here is %', quantity; -- Prints 50
18 RETURN quantity;
19 END;
20 $$ LANGUAGE plpgsql;
PL/pgSQL基本语句
赋值
为一个PL/pgSQL变量赋一个值可以被写为:
1 variable { := | = } expression;
正如以前所解释的,这样一个语句中的表达式被以一个 SQL SELECT命令被发送到主数据库引擎的方式计算。 该表达式必须得到一个单一值(如果该变量是一个行或记录变量, 它可能是一个行值)。该目标变量可以是一个简单变量( 可以选择用一个块名限定)、一个行或记录变量的域或是一个简单 变量或域的数组元素。 等号=可以被用来代替 oracle PL/SQL兼容的 := 。
执行一个有单一行结果的查询
一个产生单一行(可能有多个列)的 SQL 命令的结果可以被赋值给一个记录变量、行类型变量或标量变量列表。
1 SELECT select_expressions INTO [STRICT] target FROM ...;
2 INSERT ... RETURNING expressions INTO [STRICT] target;
3 UPDATE ... RETURNING expressions INTO [STRICT] target;
4 DELETE ... RETURNING expressions INTO [STRICT] target;
其中target可以是一个记录变量、一个行变量或一个有逗号分隔的简单变量和记录/行域列表。
如果STRICT没有在INTO子句中被指定,那么target将被设置为该查询返回的第一个行,或者在该查询不返回行时设置为空(注意除非使用了ORDER BY,否则“第一行”的界定并不清楚)
1 SELECT * INTO myrec FROM emp WHERE empname = myname;
2 IF NOT FOUND THEN
3 RAISE EXCEPTION 'employee % not found', myname;
4 END IF;
如果指定了STRICT选项,该查询必须刚好返回一行或者将会报告一个运行时错误,该错误可能是NO_DATA_FOUND(没有行)或TOO_MANY_ROWS(多于一行)。成功执行一个带STRICT的命令总是会将FOUND置为真。
1 BEGIN
2 SELECT * INTO STRICT myrec FROM emp WHERE empname = myname;
3 EXCEPTION
4 WHEN NO_DATA_FOUND THEN
5 RAISE EXCEPTION 'employee % not found', myname;
6 WHEN TOO_MANY_ROWS THEN
7 RAISE EXCEPTION 'employee % not unique', myname;
8 END;
1 CREATE FUNCTION get_userid(username text) RETURNS int
2 AS $$
3 #print_strict_params on
4 DECLARE
5 userid int;
6 BEGIN
7 SELECT users.userid INTO STRICT userid
8 FROM users WHERE users.username = get_userid.username;
9 RETURN userid;
10 END;
11 $$ LANGUAGE plpgsql;
STRICT选项完全匹配 Oracle PL/SQL 的SELECT INTO和相关语句的行为。
PL/pgSQL 执行动态命令
很多时候你将想要在PL/pgSQL函数中产生动态命令,也就是每次执行中会涉及到不同表或不同数据类型的命令。PL/pgSQL通常对于命令所做的缓存计划尝试在这种情境下无法工作。要处理这一类问题,需要提供EXECUTE语句:
1 EXECUTE command-string [ INTO [STRICT] target ] [ USING expression [, ... ] ];
在计算得到的命令字符串中,不会做PL/pgSQL变量的替换。任何所需的变量值必须在命令字符串被构造时被插入其中,或者你可以使用下面描述的参数。 命令字符串可以使用参数值,它们在命令中用$1、$2等引用。这些符号引用在USING子句中提供的值。这种方法常常更适合于把数据值作为文本插入到命令字符串中:它避免了将该值转换为文本以及转换回来的运行时负荷,并且它更不容易被 SQL 注入攻击,因为不需要引用或转义。一个例子是:
1 EXECUTE 'SELECT count(*) FROM mytable WHERE inserted_by = $1 AND inserted <= $2'
2 INTO c
3 USING checked_user, checked_date;
需要注意的是,参数符号只能用于数据值 — 如果想要使用动态决定的表名或列名,你必须将它们以文本形式插入到命令字符串中。例如,如果前面的那个查询需要在一个动态选择的表上执行,你可以这么做:
1 EXECUTE 'SELECT count(*) FROM '
2 || quote_ident(tabname)
3 || ' WHERE inserted_by = $1 AND inserted <= $2'
4 INTO c
5 USING checked_user, checked_date;
一种更干净的方法是为表名或者列名使用format()的 %I规范(被新行分隔的字符串会被串接起来):
1 EXECUTE format('SELECT count(*) FROM %I '
2 'WHERE inserted_by = $1 AND inserted <= $2', tabname)
3 INTO c
4 USING checked_user, checked_date;
在动态查询中引用值, 如:动态值需要被小心地处理,因为它们可能包含引号字符。一个使用 format()的例子(这假设你用美元符号引用了函数 体,因此引号不需要被双写)
1 EXECUTE format('UPDATE tbl SET %I = $1 '
2 'WHERE key = $2', colname) USING newvalue, keyvalue;
3 EXECUTE 'UPDATE tbl SET '
4 || quote_ident(colname)
5 || ' = '
6 || quote_literal(newvalue)
7 || ' WHERE key = '
8 || quote_literal(keyvalue);
为了安全,在进行一个动态查询中的插入之前,包含列或表标识符的表达式应该通过quote_ident被传递。如果表达式包含在被构造出的命令中应该是字符串的值时,它应该通过quote_literal被传递。这些函数采取适当的步骤来分别返回被封闭在双引号或单引号中的文本,其中任何嵌入的特殊字符都会被正确地转义。
动态 SQL 语句也可以使用format函数来安全地构造。例如:
1 EXECUTE format('UPDATE tbl SET %I = %L '
2 'WHERE key = %L', colname, newvalue, keyvalue);
%I等效于quote_ident并且 %L等效于quote_nullable。 format函数可以和 USING子句一起使用:
1 EXECUTE format('UPDATE tbl SET %I = $1 WHERE key = $2', colname)
2 USING newvalue, keyvalue;
这种形式更好,因为变量被以它们天然的数据类型格式处理,而不是无 条件地把它们转换成文本并且通过%L引用它们。这也效率 更高。
获得结果状态
有好几种方法可以判断一条命令的效果。第一种方法是使用GET DIAGNOSTICS命令,其形式如下:
1 GET [ CURRENT ] DIAGNOSTICS variable { = | := } item [ , ... ];
这条命令允许检索系统状态指示符。每个item是一个关键字, 它标识一个要被赋予给指定变量的状态值(变量应具有正确的数据类型来接收状态值), 如:
1 GET DIAGNOSTICS integer_var = ROW_COUNT;
可用的诊断项
名称 类型 描述
ROW_COUNT bigint 最近的SQL命令处理的行数
PG_CONTEXT text 描述当前调用栈的文本行
第二种判断命令效果的方法是检查一个名为FOUND的boolean类型的特殊变量。在每一次PL/pgSQL函数调用时,FOUND开始都为假。它的值会被下面的每一种类型的语句设置:
如果一个SELECT INTO语句赋值了一行,它将把FOUND设置为真,如果没有返回行则将之设置为假。
如果一个PERFORM语句生成(并且抛弃)一行或多行,它将把FOUND设置为真,如果没有产生行则将之设置为假。
如果UPDATE、INSERT以及DELETE语句影响了至少一行,它们会把FOUND设置为真,如果没有影响行则将之设置为假。
如果一个FETCH语句返回了一行,它将把FOUND设置为真,如果没有返回行则将之设置为假。
如果一个MOVE语句成功地重定位了游标,它将会把FOUND设置为真,否则设置为假。
如果一个FOR或FOREACH语句迭代了一次或多次,它将会把FOUND设置为真,否则设置为假。当循环退出时,FOUND用这种方式设置;在循环执行中,尽管FOUND可能被循环体中的其他语句的执行所改变,但它不会被循环语句修改。
如果查询返回至少一行,RETURN QUERY和RETURN QUERY EXECUTE语句会把FOUND设为真, 如果没有返回行则设置为假。
其他的PL/pgSQL语句不会改变FOUND的状态。尤其需要注意的一点是:EXECUTE会修改GET DIAGNOSTICS的输出,但不会修改FOUND的输出。
FOUND是每个PL/pgSQL函数的局部变量;任何对它的修改只影响当前的函数。
捕获错误
默认情况下,PL/pgSQL函数中发生的任何错误都会中止函数和周围事务的执行。你可以使用一个带有EXCEPTION子句的BEGIN块俘获错误并且从中恢复。其语法是BEGIN块通常的语法的一个扩展:(https://www.postgresql.org/docs/14/errcodes-appendix.html, http://postgres.cn/docs/14/errcodes-appendix.html)
1 [ <<label>> ]
2 [ DECLARE
3 declarations ]
4 BEGIN
5 statements
6 EXCEPTION
7 WHEN condition [ OR condition ... ] THEN
8 handler_statements
9 [ WHEN condition [ OR condition ... ] THEN
10 handler_statements
11 ... ]
12 END;
如果没有发生错误,这种形式的块只是简单地执行所有statements, 并且接着控制转到END之后的下一个语句。但是如果在statements内发生了一个错误,则会放弃对statements的进一步处理,然后控制会转到EXCEPTION列表。系统会在列表中寻找匹配所发生错误的第一个condition。如果找到一个匹配,则执行对应的handler_statements,并且接着把控制转到END之后的下一个语句。如果没有找到匹配,该错误就会传播出去,就好像根本没有EXCEPTION一样:错误可以被一个带有EXCEPTION的闭合块捕捉,如果没有EXCEPTION则中止该函数的处理。
condition的名字可以是附录 A中显示的任何名字。一个分类名匹配其中所有的错误。特殊的条件名OTHERS匹配除了QUERY_CANCELED和ASSERT_FAILURE之外的所有错误类型(虽然通常并不明智,还是可以用名字捕获这两种错误类型)。条件名是大小写无关的。一个错误条件也可以通过SQLSTATE代码指定,例如以下是等价的:
1 WHEN division_by_zero THEN ...
2 WHEN SQLSTATE '22012' THEN ...
如果在选中的handler_statements内发生了新的错误,那么它不能被这个EXCEPTION子句捕获,而是被传播出去。一个外层的EXCEPTION子句可以捕获它。
当一个错误被EXCEPTION捕获时,PL/pgSQL函数的局部变量会保持错误发生时的值,但是该块中所有对持久数据库状态的改变都会被回滚。例如,考虑这个片段:
1 INSERT INTO mytab(firstname, lastname) VALUES('Tom', 'Jones');
2 BEGIN
3 UPDATE mytab SET firstname = 'Joe' WHERE lastname = 'Jones';
4 x := x + 1;
5 y := x / 0;
6 EXCEPTION
7 WHEN division_by_zero THEN
8 RAISE NOTICE 'caught division_by_zero';
9 RETURN x;
10 END;
当控制到达对y赋值的地方时,它会带着一个division_by_zero错误失败。这个错误将被EXCEPTION子句捕获。而在RETURN语句中返回的值将是x增加过后的值。但是UPDATE命令的效果将已经被回滚。不过,在该块之前的INSERT将不会被回滚,因此最终的结果是数据库包含Tom Jones但不包含Joe Jones。
提示:进入和退出一个包含EXCEPTION子句的块要比不包含EXCEPTION的块开销大的多。因此,只在必要的时候使用EXCEPTION。
e.g. UPDATE/INSERT的异常
这个例子使用异常处理来酌情执行UPDATE或 INSERT。我们推荐应用使用带有 ON CONFLICT DO UPDATE的INSERT 而不是真正使用这种模式。下面的例子主要是为了展示 PL/pgSQL如何控制流程:
1 CREATE TABLE db (a INT PRIMARY KEY, b TEXT);
2
3 CREATE FUNCTION merge_db(key INT, data TEXT) RETURNS VOID AS
4 $$
5 BEGIN
6 LOOP
7 -- 首先尝试更新键
8 UPDATE db SET b = data WHERE a = key;
9 IF found THEN
10 RETURN;
11 END IF;
12 -- 不在这里,那么尝试插入该键
13 -- 如果其他某人并发地插入同一个键,
14 -- 我们可能得到一个唯一键失败
15 BEGIN
16 INSERT INTO db(a,b) VALUES (key, data);
17 RETURN;
18 EXCEPTION WHEN unique_violation THEN
19 -- 什么也不做,并且循环再次尝试 UPDATE
20 END;
21 END LOOP;
22 END;
23 $$
24 LANGUAGE plpgsql;
25
26 SELECT merge_db(1, 'david');
27 SELECT merge_db(1, 'dennis');
这段代码假定unique_violation错误是INSERT造成,并且不是由该表上一个触发器函数中的INSERT导致。如果在该表上有多于一个唯一索引,也可能会发生不正确的行为,因为不管哪个索引导致该错误它都将重试该操作。通过接下来要讨论的特性来检查被捕获的错误是否为所预期的会更安全。
得到有关某个错误的信息
异常处理器经常被用来标识发生的特定错误。有两种方法来得到PL/pgSQL中当前异常的信息:特殊变量和GET STACKED DIAGNOSTICS命令。 在一个异常处理器内,特殊变量SQLSTATE包含了对应于被抛出异常的错误代码(可能的错误代码列表见表 A.1)。特殊变量SQLERRM包含与该异常相关的错误消息。这些变量在异常处理器外是未定义的。
在一个异常处理器内,我们也可以用GET STACKED DIAGNOSTICS命令检索有关当前异常的信息,该命令的形式为:
1 GET STACKED DIAGNOSTICS variable { = | := } item [ , ... ];
每个item是一个关键词,它标识一个被赋予给指定变量(应该具有接收该值的正确数据类型)的状态值。表 43.2中显示了当前可用的状态项。
错误诊断项
名称 类型 描述
RETURNED_SQLSTATE text 该异常的 SQLSTATE 错误代码
COLUMN_NAME text 与异常相关的列名
CONSTRAINT_NAME text 与异常相关的约束名
PG_DATATYPE_NAME text 与异常相关的数据类型名
MESSAGE_TEXT text 该异常的主要消息的文本
TABLE_NAME text 与异常相关的表名
SCHEMA_NAME text 与异常相关的模式名
PG_EXCEPTION_DETAIL text 该异常的详细消息文本(如果有)
PG_EXCEPTION_HINT text 该异常的提示消息文本(如果有)
PG_EXCEPTION_CONTEXT text 描述产生异常时调用栈的文本行
如果异常没有为一个项设置值,将返回一个空字符串。
1 DECLARE
2 text_var1 text;
3 text_var2 text;
4 text_var3 text;
5 BEGIN
6 -- 某些可能导致异常的处理
7 ...
8 EXCEPTION WHEN OTHERS THEN
9 GET STACKED DIAGNOSTICS text_var1 = MESSAGE_TEXT,
10 text_var2 = PG_EXCEPTION_DETAIL,
11 text_var3 = PG_EXCEPTION_HINT;
12 END;
获得执行位置信息
GET DIAGNOSTICS命令检索有关当前执行状态的信息(反之上文讨论的GET STACKED DIAGNOSTICS命令会把有关执行状态的信息报告成一个以前的错误)。它的PG_CONTEXT状态项可用于标识当前执行位置。状态项PG_CONTEXT将返回一个文本字符串,其中有描述该调用栈的多行文本。第一行会指向当前函数以及当前正在执行GET DIAGNOSTICS的命令。第二行及其后的行表示调用栈中更上层的调用函数。例如:
1 CREATE OR REPLACE FUNCTION outer_func() RETURNS integer AS $$
2 BEGIN
3 RETURN inner_func();
4 END;
5 $$ LANGUAGE plpgsql;
6
7 CREATE OR REPLACE FUNCTION inner_func() RETURNS integer AS $$
8 DECLARE
9 stack text;
10 BEGIN
11 GET DIAGNOSTICS stack = PG_CONTEXT;
12 RAISE NOTICE E'--- Call Stack ---\n%', stack;
13 RETURN 1;
14 END;
15 $$ LANGUAGE plpgsql;
16
17 SELECT outer_func();
18
19 NOTICE: --- Call Stack ---
20 PL/pgSQL function inner_func() line 5 at GET DIAGNOSTICS
21 PL/pgSQL function outer_func() line 3 at RETURN
22 CONTEXT: PL/pgSQL function outer_func() line 3 at RETURN
23 outer_func
24 ------------
25 1
26 (1 row)
GET STACKED DIAGNOSTICS … PG_EXCEPTION_CONTEXT返回同类的栈跟踪,但是它描述检测到错误的位置而不是当前位置。
6.3 事务管理
在由CALL命令调用的过程中以及匿名代码块(DO命令)中,可以用命令COMMIT和ROLLBACK结束事务。在一个事务被使用这些命令结束后,一个新的事务会被自动开始,因此没有单独的START TRANSACTION命令(注意BEGIN和END在PL/pgSQL中有不同的含义)
1 CREATE PROCEDURE transaction_test1()
2 LANGUAGE plpgsql
3 AS $$
4 BEGIN
5 FOR i IN 0..9 LOOP
6 INSERT INTO test1 (a) VALUES (i);
7 IF i % 2 = 0 THEN
8 COMMIT;
9 ELSE
10 ROLLBACK;
11 END IF;
12 END LOOP;
13 END;
14 $$;
15
16 CALL transaction_test1();
新事务开始时具有默认事务特征,如事务隔离级别。在循环中提交事务的情况下,可能需要以与前一个事务相同的特征来自动启动新事务。 命令COMMIT AND CHAIN和ROLLBACK AND CHAIN可以完成此操作。
只有在从顶层调用的CALL或DO中才能进行事务控制 ,在没有任何其他中间命令的嵌套CALL或DO调用中也能进行事务控制 。
例如,如果调用栈是CALL proc1() → CALL proc2() → CALL proc3(),那么第二个和第三个过程可以执行事务控制动作。但是如果调用栈是CALL proc1() → SELECT func2() → CALL proc3(),则最后一个过程不能做事务控制,因为中间有SELECT。
对于游标循环有特殊的考虑。看看这个例子:
1 CREATE PROCEDURE transaction_test2()
2 LANGUAGE plpgsql
3 AS $$
4 DECLARE
5 r RECORD;
6 BEGIN
7 FOR r IN SELECT * FROM test2 ORDER BY x LOOP
8 INSERT INTO test1 (a) VALUES (r.x);
9 COMMIT;
10 END LOOP;
11 END;
12 $$;
13
14 CALL transaction_test2();
通常,游标会在事务提交时被自动关闭。但是,一个作为循环的组成部分创建的游标会自动被第一个COMMIT或ROLLBACK转变成一个可保持游标。这意味着该游标在第一个COMMIT或ROLLBACK处会被完全计算出来,而不是逐行被计算。该游标在循环后仍会被自动删除,因此这通常对用户是不可见的。
有非只读命令(UPDATE … RETURNING)驱动的游标循环中不允许有事务命令。
事务在一个具有异常处理部分的块中不能被结束。
6.5 存储过程与函数区别
PostgreSQL 11 版本一个重量级新特性是对存储过程的支持,同时支持存储过程嵌入事务
尽管PostgreSQL提供函数可以实现大多数存储过程的功能,但函数不支持部分提交。而存储过程可以实现
1 create table t2 (id int, col2 varchar(64));
2 CREATE OR REPLACE PROCEDURE p_insert_data2(id integer, name character varying)
3 AS $$
4 BEGIN
5 INSERT INTO public.t2 VALUES (id, name);
6 if id % 2 = 0 then
7 commit;
8 else
9 rollback;
10 end if;
11 END;
12 $$ LANGUAGE plpgsql;
13
14 call p_insert_data2(5, 'jkdalsjfd');
15 call p_insert_data2(6, 'jkdalsjfd');
16
17 CREATE OR REPLACE function f_insert_data2(id integer, name character varying) returns integer
18 AS $$
19 BEGIN
20 INSERT INTO public.t2 VALUES (id, name);
21 if id % 2 = 0 then
22 commit;
23 else
24 rollback;
25 end if;
26 return id;
27 END;
28 $$ LANGUAGE plpgsql;
29
30 mydb=# select f_insert_data2(1, 'wang');
31 ERROR: invalid transaction termination
32 CONTEXT: PL/pgSQL function f_insert_data2(integer,character varying) line 7 at ROL
触发器函数
数据改变触发器
PL/pgSQL可以被用来在数据更改或者数据库事件上定义触发器函数。触发器函数用CREATE FUNCTION命令创建,它被声明为一个没有参数并且返回类型为trigger(对于数据更改触发器)或者event_trigger(对于数据库事件触发器)的函数。名为PG_something的特殊局部变量将被自动创建用以描述触发该调用的条件。
一个数据更改触发器被声明为一个没有参数并且返回类型为trigger的函数。注意,如下所述,即便该函数准备接收一些在CREATE TRIGGER中指定的参数 — 这类参数通过TG_ARGV传递,也必须把它声明为没有参数。
当一个PL/pgSQL函数当做触发器调用时,在顶层块会自动创建一些特殊变量。它们是:
NEW
数据类型是RECORD;该变量为行级触发器中的INSERT/UPDATE操作保持新数据行。在语句级别的触发器以及DELETE操作,这个变量是null。
OLD
数据类型是RECORD;该变量为行级触发器中的UPDATE/DELETE操作保持新数据行。在语句级别的触发器以及INSERT操作,这个变量是null。
TG_NAME
数据类型是name;该变量包含实际触发的触发器名。
TG_WHEN
数据类型是text;是值为BEFORE、AFTER或INSTEAD OF的一个字符串,取决于触发器的定义。
TG_LEVEL
数据类型是text;是值为ROW或STATEMENT的一个字符串,取决于触发器的定义。
TG_OP
数据类型是text;是值为INSERT、UPDATE、DELETE或TRUNCATE的一个字符串,它说明触发器是为哪个操作引发。
TG_RELID
数据类型是oid;是导致触发器调用的表的对象 ID。
TG_RELNAME
数据类型是name;是导致触发器调用的表的名称。现在已经被废弃,并且可能在未来的一个发行中消失。使用TG_TABLE_NAME替代。
TG_TABLE_NAME
数据类型是name;是导致触发器调用的表的名称。
TG_TABLE_SCHEMA
数据类型是name;是导致触发器调用的表所在的模式名。
TG_NARGS
数据类型是integer;在CREATE TRIGGER语句中给触发器函数的参数数量。
TG_ARGV[]
数据类型是text数组;来自CREATE TRIGGER语句的参数。索引从 0 开始记数。非法索引(小于 0 或者大于等于tg_nargs)会导致返回一个空值。
一个触发器函数必须返回NULL或者是一个与触发器为之引发的表结构完全相同的记录/行值。
BEFORE引发的行级触发器可以返回一个空来告诉触发器管理器跳过对该行剩下的操作(即后续的触发器将不再被引发,并且不会对该行发生INSERT/UPDATE/DELETE)。如果返回了一个非空值,那么对该行值会继续操作。返回不同于原始NEW的行值将修改将要被插入或更新的行。因此,如果该触发器函数想要触发动作正常成功而不修改行值,NEW(或者另一个相等的值)必须被返回。要修改将被存储的行,可以直接在NEW中替换单一值并且返回修改后的NEW,或者构建一个全新的记录/行来返回。在一个DELETE上的前触发器情况下,返回值没有直接效果,但是它必须为非空以允许触发器动作继续下去。注意NEW在DELETE触发器中是空值,因此返回它通常没有意义。在DELETE中的常用方法是返回OLD.
INSTEAD OF触发器(总是行级触发器,并且可能只被用于视图)能够返回空来表示它们没有执行任何更新,并且对该行剩余的操作可以被跳过(即后续的触发器不会被引发,并且该行不会被计入外围INSERT/UPDATE/DELETE的行影响状态中)。否则一个非空值应该被返回用以表示该触发器执行了所请求的操作。对于INSERT 和UPDATE操作,返回值应该是NEW,触发器函数可能对它进行了修改来支持INSERT RETURNING和UPDATE RETURNING(这也将影响被传递给任何后续触发器的行值,或者被传递给带有ON CONFLICT DO UPDATE的INSERT语句中一个特殊的EXCLUDED别名引用)。对于DELETE操作,返回值应该是OLD。
一个AFTER行级触发器或一个BEFORE或AFTER语句级触发器的返回值总是会被忽略,它可能也是空。不过,任何这些类型的触发器可能仍会通过抛出一个错误来中止整个操作。
一个用于审计的 PL/pgSQL 触发器函数
这个例子触发器保证了在emp表上的任何插入、更新或删除一行的动作都被记录(即审计)在emp_audit表中。当前时间和用户名会被记录到行中,还有在其上执行的操作类型。
1 CREATE TABLE emp (
2 empname text NOT NULL,
3 salary integer
4 );
5
6 CREATE TABLE emp_audit(
7 operation char(1) NOT NULL,
8 stamp timestamp NOT NULL,
9 userid text NOT NULL,
10 empname text NOT NULL,
11 salary integer
12 );
13
14 CREATE OR REPLACE FUNCTION process_emp_audit() RETURNS TRIGGER AS $emp_audit$
15 BEGIN
16 --
17 -- 在 emp_audit 中创建一行来反映 emp 上执行的动作,
18 -- 使用特殊变量 TG_OP 来得到操作。
19 --
20 IF (TG_OP = 'DELETE') THEN
21 INSERT INTO emp_audit SELECT 'D', now(), user, OLD.*;
22 ELSIF (TG_OP = 'UPDATE') THEN
23 INSERT INTO emp_audit SELECT 'U', now(), user, NEW.*;
24 ELSIF (TG_OP = 'INSERT') THEN
25 INSERT INTO emp_audit SELECT 'I', now(), user, NEW.*;
26 END IF;
27 RETURN NULL; -- 因为这是一个 AFTER 触发器,结果被忽略
28 END;
29 $emp_audit$ LANGUAGE plpgsql;
30
31 CREATE TRIGGER emp_audit
32 AFTER INSERT OR UPDATE OR DELETE ON emp
33 FOR EACH ROW EXECUTE FUNCTION process_emp_audit();
34
前一个例子的一种变体使用一个视图将主表连接到审计表来展示每一项最后被修改是什么时间。这种方法还是记录了对于表修改的完整审查跟踪,但是也提供了审查跟踪的一个简化视图,只为每一个项显示从审查跟踪生成的最后修改时间戳。例 43.5展示了在PL/pgSQL中一个视图上审计触发器的例子。
tablefunc (插件) 扩展
上边的递归语法,可以用类似connect by的形式来表达。为了与Oracle语法兼容,PostgreSQL自带tablefunc扩展。
1 create extension tablefunc;
http://postgres.cn/docs/14/tablefunc.html 基本语法 如下:
1 connectby ( relname text,
2 keyid_fld text,
3 parent_keyid_fld text
4 [, orderby_fld text ],
5 start_with text,
6 max_depth integer
7 [, branch_delim text ] )
8 →
9 setof record
10
11 Produces a representation of a hierarchical tree structure.
产生一个层次树结构的表达。
参数解释:
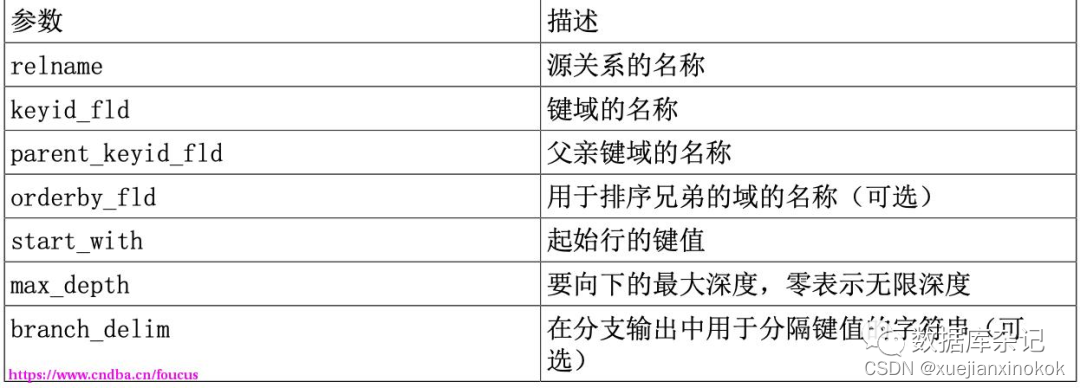
1 select * from connectby('testarea', 'id', 'parentid', '1', 0, ',') AS t(keyid int, parent_keyid int, level int, branch text);
2 keyid | parent_keyid | level | branch
3 -------+--------------+-------+-----------
4 1 | | 0 | 1
5 2 | 1 | 1 | 1,2
6 4 | 2 | 2 | 1,2,4
7 7 | 4 | 3 | 1,2,4,7
8 8 | 4 | 3 | 1,2,4,8
9 5 | 2 | 2 | 1,2,5
10 3 | 1 | 1 | 1,3
11 6 | 3 | 2 | 1,3,6
12 9 | 1 | 1 | 1,9
13 10 | 9 | 2 | 1,9,10
14 12 | 10 | 3 | 1,9,10,12
15 11 | 9 | 2 | 1,9,11
16 (12 rows)
6.7 WITH使用(Common Table Expressions, CTE)
WITH RECURSIVE
1 WITH RECURSIVE t(n) AS (
2 VALUES (1)
3 UNION ALL
4 SELECT n+1 FROM t WHERE n < 100
5)
6 SELECT sum(n) FROM t;
7
8 zdb-> select sum(n) from t;
9 5050
10 (1 row)
一个递归WITH查询的通常形式总是一个非递归项,然后是UNION(或者UNION ALL),再然后是一个递归项,其中只有递归项能够包含对于查询自身输出的引用。
一个实例:
1 表testarea:
2 CREATE TABLE testarea(id int, name varchar(32), parentid int);
3 INSERT INTO testarea VALUES
4 (1, '中国', 0),
5 (2, '辽宁', 1),
6 (3, '山东', 1),
7 (4, '沈阳', 2),
8 (5, '大连', 2),
9 (6, '济南', 3),
10 (7, '和平区', 4),
11 (8, '沈河区', 4),
12 (9, '北京', 1),
13 (10, '海淀区', 9),
14 (11, '朝阳区', 9),
15 (12, '苏家坨', 10);
当id = 7时,想得到完整的地名:中国辽宁沈阳和平区;当id =12时,想得到中国北京海淀区苏家坨。
可以使用查询查到id为7以及以上的所有父节点,如下:
1 WITH RECURSIVE r AS (
2 SELECT * FROM testarea WHERE id = 7
3 UNION ALL
4 SELECT a.* FROM testarea a, r WHERE a.id = r.parentid
5 )
6 SELECT * FROM r ORDER BY id;
7
8 mydb-# SELECT * FROM r ORDER BY id;
9 id | name | parentid
10 ----+--------+----------
11 1 | 中国 | 0
12 2 | 辽宁 | 1
13 4 | 沈阳 | 2
14 7 | 和平区 | 4
1 5(4 rows)
接下来可以将name字段值进行合并。利用string_agg()函数可以达到目的。如取id=12的完整名称。
1 WITH RECURSIVE r AS (
2 SELECT * FROM testarea WHERE id = 12
3 UNION ALL
4 SELECT a.* FROM testarea a, r WHERE a.id = r.parentid
5 )
6 SELECT string_agg(name, '') FROM (SELECT * FROM r ORDER BY id) t;
7 string_agg
8 ----------------------
9 中国北京海淀区苏家坨
上边,利用string_agg()将id=12及其所有父结点按序拼接到一起,组成最后的结果。
WITH中的DML语句
你可以在WITH中使用数据修改语句(INSERT、UPDATE或DELETE)。这允许你在同一个查询中执行多个不同操作。一个例子:
1 WITH moved_rows AS (
2 DELETE FROM products
3 WHERE
4 "date" >= '2010-10-01' AND
5 "date" < '2010-11-01'
6 RETURNING *
7 )
8 INSERT INTO products_log
9 SELECT * FROM moved_rows;
这个查询实际上将products中的行移动到products_log。WITH中的DELETE删除来自products的指定行,以RETURNING子句返回被删除的内容,然后主查询读该输出并将它插入到products_log。
WITH中的子语句和其他子语句以及主查询被并发执行。因此在使用WITH中的数据修改语句时,无法预知实际更新顺序。所有的语句都使用同一个snapshot执行(参见第 13 章),因此它们不能“看见”目标表上另一个执行的效果。这减轻了行更新的实际顺序的不可预见性的影响,并且意味着RETURNING数据是在不同WITH子语句和主查询之间传达改变的唯一方法。其例子
1 WITH t AS (
2 UPDATE products SET price = price * 1.05
3 RETURNING *
4 )
5 SELECT * FROM products;
外层SELECT可以返回在UPDATE动作之前的原始价格,而在
1 WITH t AS (
2 UPDATE products SET price = price * 1.05
3 RETURNING *
4 )
5 SELECT * FROM t;
外部SELECT将返回更新过的数据。
关于排序规则 COLLATE,以mysql 为例
各种COLLATE的区别
COLLATE通常是和数据编码(CHARSET)相关的,一般来说每种CHARSET都有多种它所支持的COLLATE,并且每种CHARSET都指定一种COLLATE为默认值。
例如Latin1编码的默认COLLATE为latin1_swedish_ci,GBK编码的默认COLLATE为gbk_chinese_ci,utf8mb4编码的默认值为utf8mb4_general_ci。
很多COLLATE都带有_ci字样,这是Case Insensitive的缩写,即大小写无关,也就是说"A"和"a"在排序和比较的时候是一视同仁的。selection * from table1 where field1="a"同样可以把field1为"A"的值选出来。与此同时,对于那些_cs后缀的COLLATE,则是Case Sensitive,即大小写敏感的。
所谓utf8_unicode_ci,其实是用来排序的规则。对于mysql中那些字符类型的列,如VARCHAR,CHAR,TEXT类型的列,都需要有一个COLLATE类型来告知mysql如何对该列进行排序和比较。简而言之,COLLATE会影响到ORDER BY语句的顺序,会影响到WHERE条件中大于小于号筛选出来的结果,会影响DISTINCT、GROUP BY、HAVING语句的查询结果。另外,mysql建索引的时候,如果索引列是字符类型,也会影响索引创建,只不过这种影响我们感知不到。总之,凡是涉及到字符类型比较或排序的地方,都会和COLLATE有关。
很多国家的语言自己的排序规则。在国内比较常用的是utf8mb4_general_ci(默认)、utf8mb4_unicode_ci、utf8mb4_bin这三个。我们来探究一下这三个的区别:
首先utf8mb4_bin的比较方法其实就是直接将所有字符看作二进制串,然后从最高位往最低位比对。所以很显然它是区分大小写的。
而utf8mb4_unicode_ci和utf8mb4_general_ci对于中文和英文来说,其实是没有任何区别的。对于我们开发的国内使用的系统来说,随便选哪个都行。只是对于某些西方国家的字母来说,utf8mb4_unicode_ci会比utf8mb4_general_ci更符合他们的语言习惯一些,general是mysql一个比较老的标准了。例如,德语字母“ß”,在utf8mb4_unicode_ci中是等价于"ss"两个字母的(这是符合德国人习惯的做法),而在utf8mb4_general_ci中,它却和字母“s”等价。不过,这两种编码的那些微小的区别,对于正常的开发来说,很难感知到。本身我们也很少直接用文字字段去排序,退一步说,即使这个字母排错了一两个,真的能给系统带来灾难性后果么?从网上找的各种帖子讨论来说,更多人推荐使用utf8mb4_unicode_ci,但是对于使用了默认值的系统,也并没有非常排斥,并不认为有什么大问题。结论:推荐使用utf8mb4_unicode_ci,对于已经用了utf8mb4_general_ci的系统,也没有必要花时间改造。
另外需要注意的一点是,从mysql 8.0开始,mysql默认的CHARSET已经不再是Latin1了,改为了utf8mb4(参考链接),并且默认的COLLATE也改为了utf8mb4_0900_ai_ci。utf8mb4_0900_ai_ci大体上就是unicode的进一步细分,0900指代unicode比较算法的编号( Unicode Collation Algorithm version),ai表示accent insensitive(发音无关),例如e, è, é, ê 和 ë是一视同仁的。
文章来源