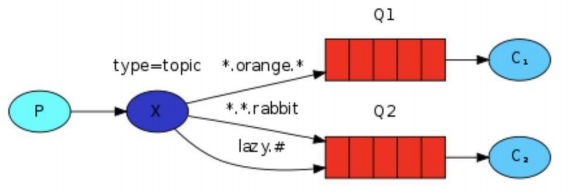
在本教程中,你将学习如何使用 Elastic 可观察性监控 Java 应用程序:日志、基础设施指标、APM 和正常运行时间。通过本教程,你将学到:
- 创建示例 Java 应用程序。
- 使用 Filebeat 提取日志并在 Kibana 中查看你的日志。
- 使用 Metricbeat Prometheus 模块获取指标并在 Kibana 中查看你的指标。
- 使用 Elastic APM Java 代理检测你的应用程序。
- 使用 Heartbeat 监控您的服务并在 Kibana 中查看您的正常运行时间数据。
在下面的展示中,我将使用最新的 Elastic Stack 8.5.2 来进行展示。
安装
如果你还没有安装好自己的 Elasticsearch 及 Kibana,那么请按照我之前的文章:
-
如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch
-
Kibana:如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana
在按照的时候,请参考 Elastic Stack 8.x 的安装指南进行安装。在安装的时候,我们需要针对 Elasticsearch 及 Kibana 做如下的调整:
Elasticsearch
我们需要在 config/elasticsearch.yml 文件中添加如下的部分:
config/elasticsearch.yml
xpack.security.authc.api_key.enabled: true我们把上面的配置添加到 config/elasticsearch.yml 文件的最后面。这个是为了能够我们使用 API key 的方式来访问 Elasticsearch。修改完毕后,我们重新启动 Elasticsearch。这个是为了在下面我们使用 Elastic Agent 来安装 APM 集成。
Kibana
我们还必须为 Kibana 做一项修正。我们首先在 Kibana 的安装目录中使用如下的命令:
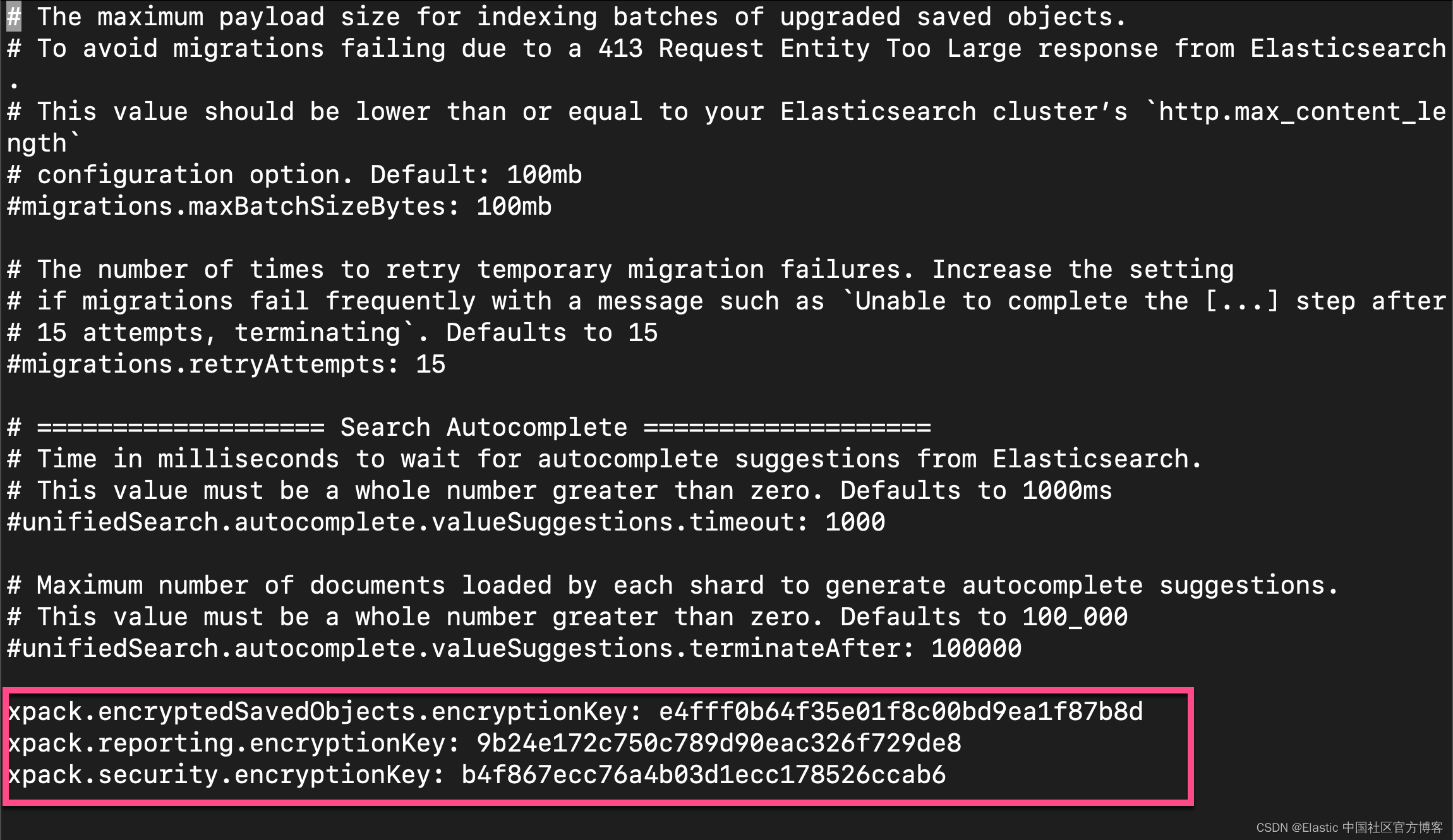
./bin/kibana-encryption-keys generate上面的命令将生成三个 keys:
Settings:
xpack.encryptedSavedObjects.encryptionKey: e4fff0b64f35e01f8c00bd9ea1f87b8d
xpack.reporting.encryptionKey: 9b24e172c750c789d90eac326f729de8
xpack.security.encryptionKey: b4f867ecc76a4b03d1ecc178526ccab6我们把上面的三个 keys 拷贝并粘贴到 config/kibana.yml 文件的最后面:
config/kibana.yml
添加完毕后,我们重新启动 Kibana。
这样我们就完成了 Elasticsearch 及 Kibana 的安装了。
创建一个 Java 应用
要创建 Java 应用程序,你需要 OpenJDK 14(或更高版本)和 Javalin Web 框架。 该应用程序将包括主要端点、一个人为长时间运行的端点和一个需要轮询另一个数据源的端点。 还会有一个后台作业在运行。我们按照如下的步骤来进行:
1)设置 Gradle 项目并创建以下 build.gradle 文件。
build.gradle
plugins {
id 'java'
id 'application'
}
repositories {
jcenter()
}
dependencies {
implementation 'io.javalin:javalin:3.10.1'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2'
}
application {
mainClassName = 'de.spinscale.javalin.App'
}
test {
useJUnitPlatform()
}$ pwd
/Users/liuxg/demos/apm/java_monitor
$ ls
build.gradle
$ java -version
java version "11.0.12" 2021-07-20 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.12+8-LTS-237)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.12+8-LTS-237, mixed mode)如上所示,我将使用 Java 11 来进行编译项目。
2)运行以下命令:
echo "rootProject.name = 'javalin-app'" >> settings.gradle
mkdir -p src/main/java/de/spinscale/javalin
mkdir -p src/test/java/de/spinscale/javalin$ ls
build.gradle settings.gradle src3)安装 Gradle 包装器。 安装 Gradle 的一种简单方法是使用 sdkman 并运行 sdk install gradle 6.5.1。 接下来在当前目录中运行 gradle wrapper 以安装 Gradle wrapper。我们也可以使用如下的命令来指定 gradle 的版本:
./gradlew wrapper --gradle-version 6.5.14)运行./gradlew clean check。 你应该会看到一个成功的构建,它还没有构建或编译任何内容。
$ ./gradlew clean check
Deprecated Gradle features were used in this build, making it incompatible with Gradle 8.0.
You can use '--warning-mode all' to show the individual deprecation warnings and determine if they come from your own scripts or plugins.
See https://docs.gradle.org/7.4.2/userguide/command_line_interface.html#sec:command_line_warnings
BUILD SUCCESSFUL in 1s
1 actionable task: 1 up-to-date5)要创建 Javalin 服务器及其第一个端点(主要端点),请创建 src/main/java/de/spinscale/javalin/App.java 文件。
package de.spinscale.javalin;
import io.javalin.Javalin;
public class App {
public static void main(String[] args) {
Javalin app = Javalin.create().start(8000);
app.get("/", ctx -> ctx.result("Appsolutely perfect"));
}
}$ tree -L 7
.
├── build.gradle
├── gradle
│ └── wrapper
│ ├── gradle-wrapper.jar
│ └── gradle-wrapper.properties
├── gradlew
├── gradlew.bat
├── settings.gradle
└── src
├── main
│ └── java
│ └── de
│ └── spinscale
│ └── javalin
│ └── App.java
└── test
└── java
└── de
└── spinscale
└── javalin在上面,我们的 web 服务器的端口地址为 8000。
6)运行 ./gradlew assemble
此命令编译了构建目录中的 App.class 文件。 但是,无法启动服务器。 让我们创建一个 jar,其中包含我们编译的类以及所有必需的依赖项。
$ ./gradlew assemble
Deprecated Gradle features were used in this build, making it incompatible with Gradle 8.0.
You can use '--warning-mode all' to show the individual deprecation warnings and determine if they come from your own scripts or plugins.
See https://docs.gradle.org/7.4.2/userguide/command_line_interface.html#sec:command_line_warnings
BUILD SUCCESSFUL in 4s
5 actionable tasks: 5 executed7)在 build.gradle 文件中,按此处所示编辑 plugins。
plugins {
id 'com.github.johnrengelman.shadow' version '6.0.0'
id 'application'
id 'java'
}8)运行./gradlew shadowJar。 此命令创建一个 build/libs/javalin-app-all.jar 文件。shadowJar 插件需要有关其主类的信息。
$ ./gradlew shadowJar
Deprecated Gradle features were used in this build, making it incompatible with Gradle 8.0.
You can use '--warning-mode all' to show the individual deprecation warnings and determine if they come from your own scripts or plugins.
See https://docs.gradle.org/7.4.2/userguide/command_line_interface.html#sec:command_line_warnings
BUILD SUCCESSFUL in 21s
2 actionable tasks: 1 executed, 1 up-to-date
$ ls build/libs/javalin-app-all.jar
build/libs/javalin-app-all.jar9)将以下代码片段添加到 build.gradle 文件中。
jar {
manifest {
attributes 'Main-Class': 'de.spinscale.javalin.App'
}
}10)在 builld.gradle 的 dependencies 里添加如下的项:
dependencies {
compile "org.slf4j:slf4j-simple:1.7.30"
...
}重新编译项目并启动服务器,并运行如下的命令:
java -jar build/libs/javalin-app-all.jar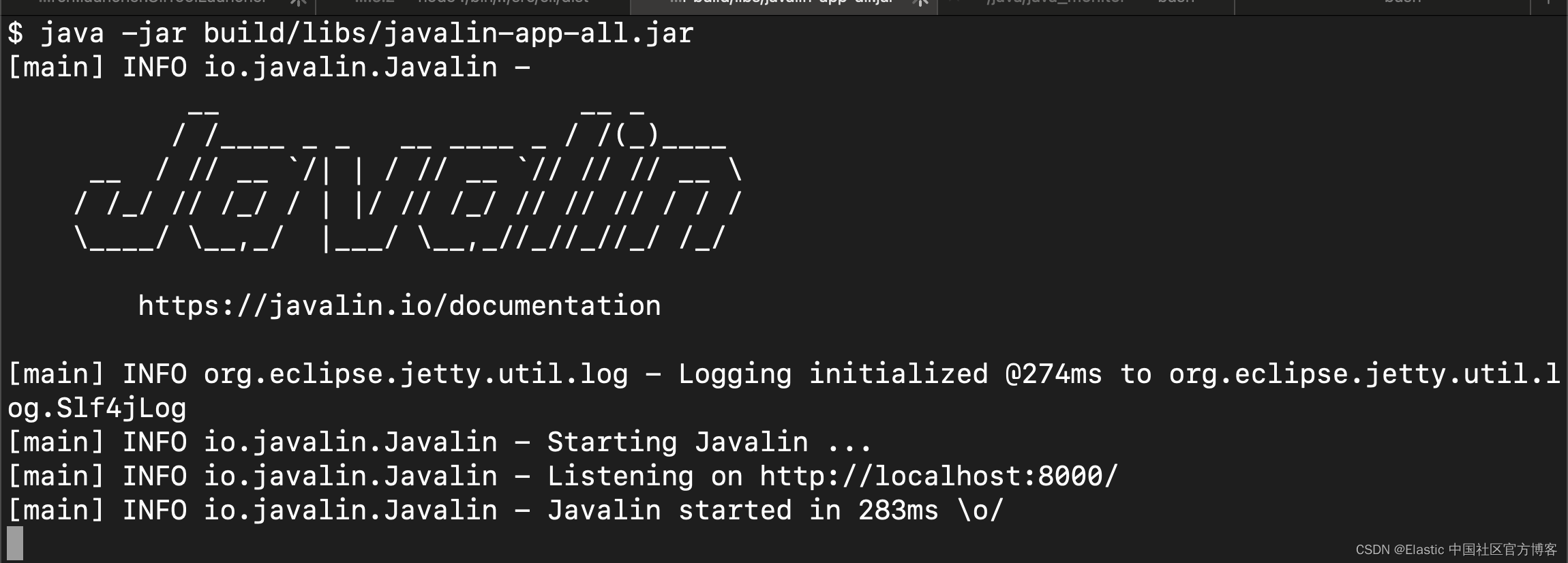
打开另一个终端并运行 curl localhost:8000 以显示 HTTP 响应。
$ curl localhost:8000
Appsolutely perfect$ 11)测试代码。 将所有内容都放入 main() 方法会使测试代码变得困难。 但是,专用处理程序可以解决此问题。重构 App 类。
App.java
package de.spinscale.javalin;
import io.javalin.Javalin;
import io.javalin.http.Handler;
public class App {
public static void main(String[] args) {
Javalin app = Javalin.create().start(8000);
app.get("/", mainHandler());
}
static Handler mainHandler() {
return ctx -> ctx.result("Appsolutely perfect");
}
}将 Mockito 和 Assertj 依赖项添加到 build.gradle 文件。
dependencies {
compile "org.slf4j:slf4j-simple:1.7.30"
implementation 'io.javalin:javalin:3.10.1'
testImplementation 'org.mockito:mockito-core:3.5.10'
testImplementation 'org.assertj:assertj-core:3.17.2'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2'
}在 src/test/java/de/spinscale/javalin 中创建 AppTests.java 类文件。
AppTest.java
package de.spinscale.javalin;
import io.javalin.http.Context;
import org.junit.jupiter.api.Test;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import static de.spinscale.javalin.App.mainHandler;
import static org.assertj.core.api.Assertions.assertThat;
import static org.mockito.Mockito.mock;
public class AppTests {
final HttpServletRequest req = mock(HttpServletRequest.class);
final HttpServletResponse res = mock(HttpServletResponse.class);
final Context ctx = new Context(req, res, new HashMap<>());
@Test
public void testMainHandler() throws Exception {
mainHandler().handle(ctx);
String response = resultStreamToString(ctx);
assertThat(response).isEqualTo("Appsolutely perfect");
}
private String resultStreamToString(Context ctx) throws IOException {
final byte[] bytes = ctx.resultStream().readAllBytes();
return new String(bytes, StandardCharsets.UTF_8);
}
}12)测试通过后,重新编译并打包应用程序。
./gradlew clean check shadowJar
摄入日志
日志可以是结帐、异常或 HTTP 请求等事件。 对于本教程,让我们使用 log4j2 作为我们的日志记录实现。
添加日志记录实现
1)将依赖项添加到 build.gradle 文件中。
dependencies {
implementation 'io.javalin:javalin:3.10.1'
implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.13.3'
...
}2)要开始记录,请编辑 App.java 文件并更改处 handler。
注意:记录器调用必须在 lambda 内。 否则,仅在启动期间记录日志消息
App.java
package de.spinscale.javalin;
import io.javalin.Javalin;
import io.javalin.http.Handler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class App {
private static final Logger logger = LoggerFactory.getLogger(App.class);
public static void main(String[] args) {
Javalin app = Javalin.create();
app.get("/", mainHandler());
app.start(8000);
}
static Handler mainHandler() {
return ctx -> {
logger.info("This is an informative logging message, user agent [{}]", ctx.userAgent());
ctx.result("Absolutely perfect");
};
}
}3)在 src/main/resources/log4j2.xml 文件中创建一个 log4j2 配置。 你可能需要先创建该目录。
mkdir -p src/main/resources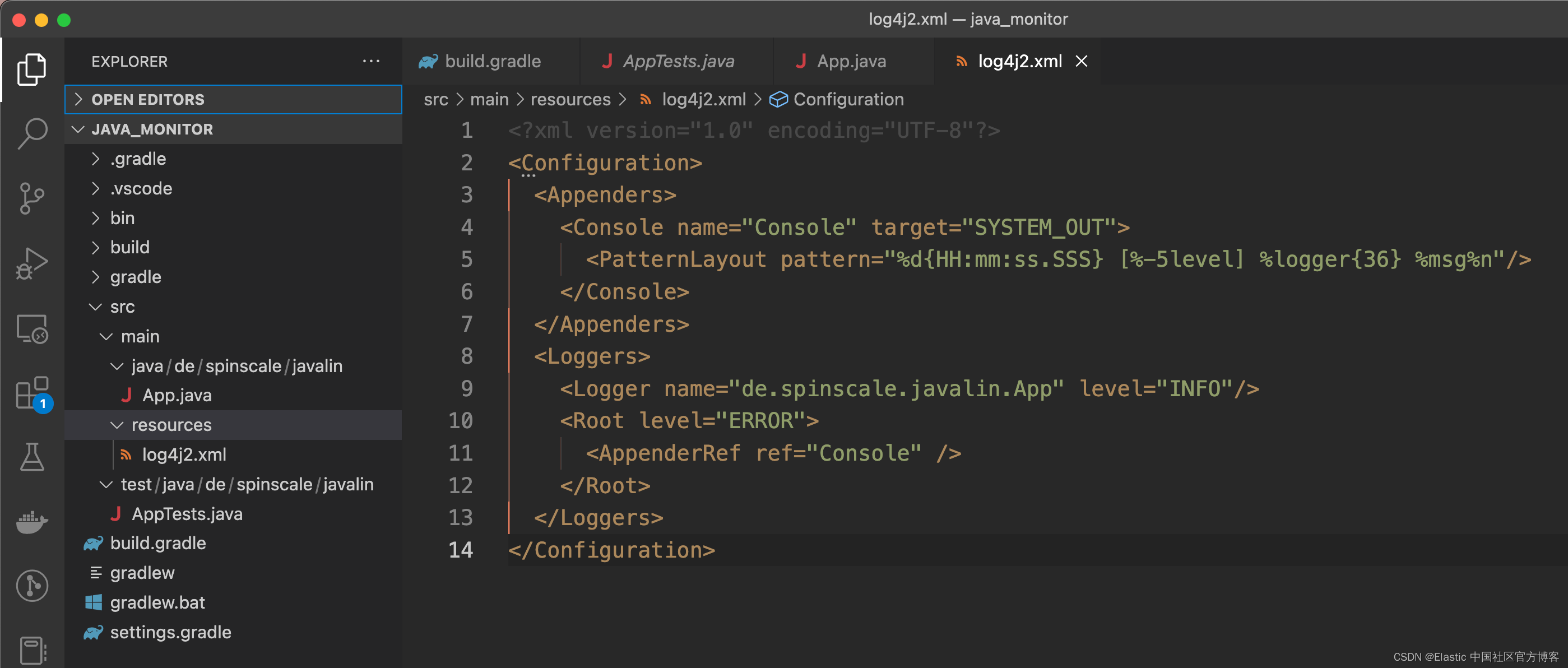
默认情况下,这会记录 ERROR 级别。 对于 App 类,有一个额外的配置,以便也记录所有 INFO 日志。 重新打包并重启后,日志信息显示在终端中。
./gradlew clean check shadowJar在 terminal 中启动应用:
java -jar build/libs/javalin-app-all.jar我们在另外一个 terminal 中执行如下的命令:
curl localhost:8000我们可以在 web 应用中看到如下的输出:

日志请求
根据应用程序流量及其是否发生在应用程序之外,在应用程序级别记录每个请求是有意义的。
1)在 App.java 文件中,编辑 App 类。
App.java
package de.spinscale.javalin;
import io.javalin.Javalin;
import io.javalin.http.Handler;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class App {
private static final Logger logger = LoggerFactory.getLogger(App.class);
public static void main(String[] args) {
Javalin app = Javalin.create(config -> {
config.requestLogger((ctx, executionTimeMs) -> {
logger.info("{} {} {} {} \"{}\" {}",
ctx.method(), ctx.url(), ctx.req.getRemoteHost(),
ctx.res.getStatus(), ctx.userAgent(), executionTimeMs.longValue());
});
});
app.get("/", mainHandler());
app.start(8000);
}
static Handler mainHandler() {
return ctx -> {
logger.info("This is an informative logging message, user agent [{}]", ctx.userAgent());
ctx.result("Absolutely perfect");
};
}
}2)重新编译并启动应用程序。 为每个请求记录日志消息。

创建 ISO8601 时间戳
在将日志提取到 Elasticsearch 服务之前,通过编辑 log4j2.xml 文件创建一个 ISO8601 时间戳。
注意: 创建 ISO8601 时间戳后,就无需在提取日志时对时间戳进行任何计算,因为这是一个唯一的时间点,包括时区。 一旦你在尝试跟踪数据流时跨数据中心运行,拥有时区就变得更加重要。
<PatternLayout pattern="%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n"/>把 log4j2.xml 文件中的 PatternLayout 替换为上面的句子。提取的日志条目包含如下时间戳:

从上面的输出中,我们可以看到有一个时间戳在日志中。
记录到文件和标准输出
1)要读取日志输出,让我们将数据写入文件和标准输出。 这是一个新的 log4j2.xml 文件。
log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%highlight{%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n}"/>
</Console>
<File name="JavalinAppLog" fileName="/tmp/javalin/app.log">
<PatternLayout pattern="%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n"/>
</File>
</Appenders>
<Loggers>
<Logger name="de.spinscale.javalin.App" level="INFO"/>
<Root level="ERROR">
<AppenderRef ref="Console" />
<AppenderRef ref="JavalinAppLog" />
</Root>
</Loggers>
</Configuration>2)重新启动应用程序并发送请求。 日志将发送到 /tmp/javalin/app.log。

我们可以在 /tmp/javalin/app.log 查看日志的内容:
$ cat /tmp/javalin/app.log
2022-11-30T19:56:36,308+08:00 [INFO ] de.spinscale.javalin.App This is an informative logging message, user agent [curl/7.82.0]
2022-11-30T19:56:36,320+08:00 [INFO ] de.spinscale.javalin.App GET http://localhost:8000/ 127.0.0.1 200 "curl/7.82.0" 14安装及配置 Filebeat
我们可以根据自己的系统来按照及配置 Filebeat。为了方便起见,我们可以直接到 Download Filebeat • Lightweight Log Analysis | Elastic 去下载适合自己操作系统的 Filebeat 安装包。根据我的 macOS,我使用如下的命令来进行下载:
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.2-darwin-aarch64.tar.gz我们使用如下的命令来进行解压缩:
tar xzf filebeat-8.5.2-darwin-aarch64.tar.gz我们可以在 Filebeat 的安装目录下找到一个配置文件 filebeat.yml:
$ pwd
/Users/liuxg/elastic/filebeat-8.5.2-darwin-aarch64
$ ls filebeat.yml
filebeat.yml为了能配置我们的 filebeat.yml,我们可以先来创建一个 API key 来进行访问:
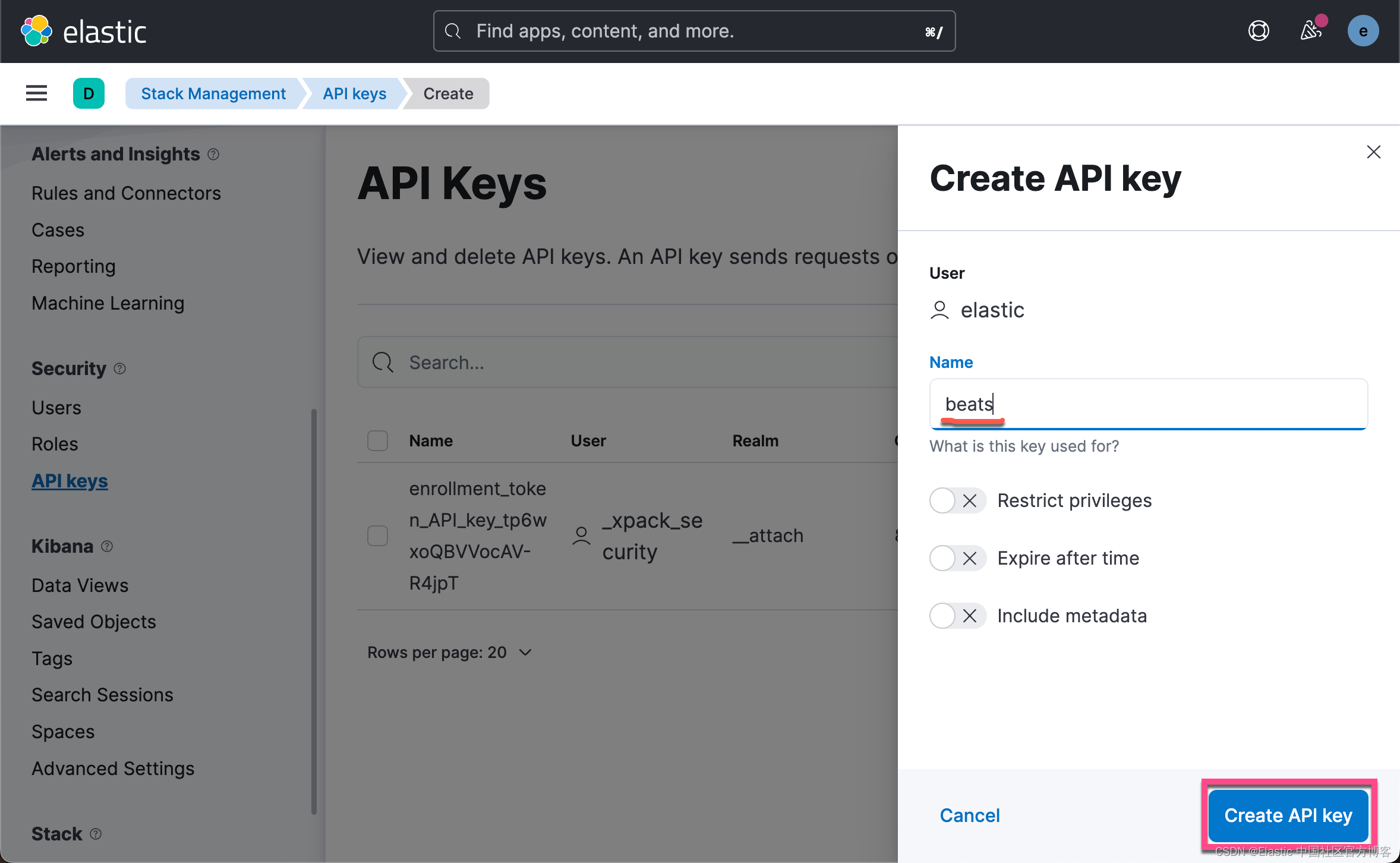
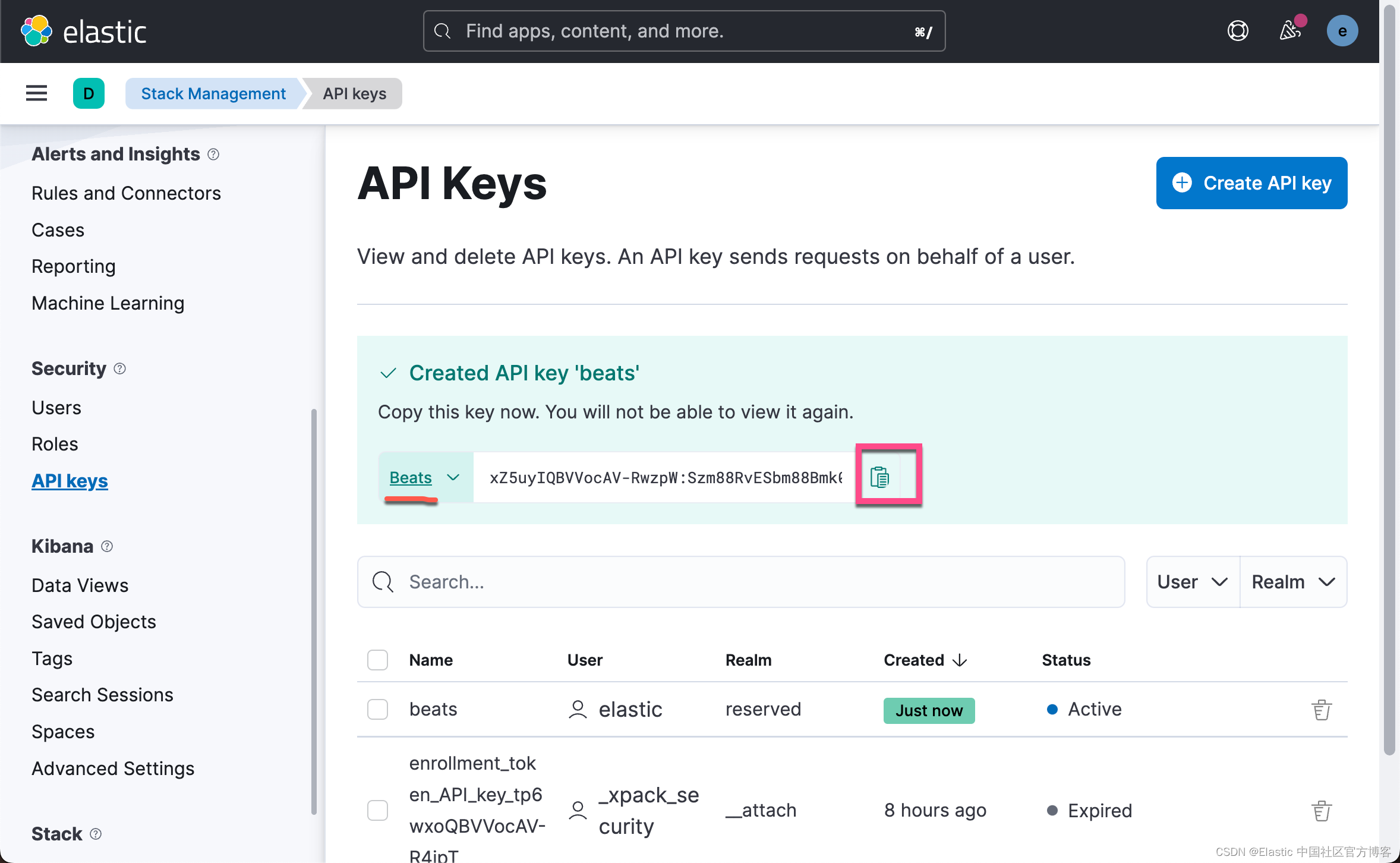
我们先把上面的 API key 拷贝下来,然后我们进行如下的配置:
filebeat.yml
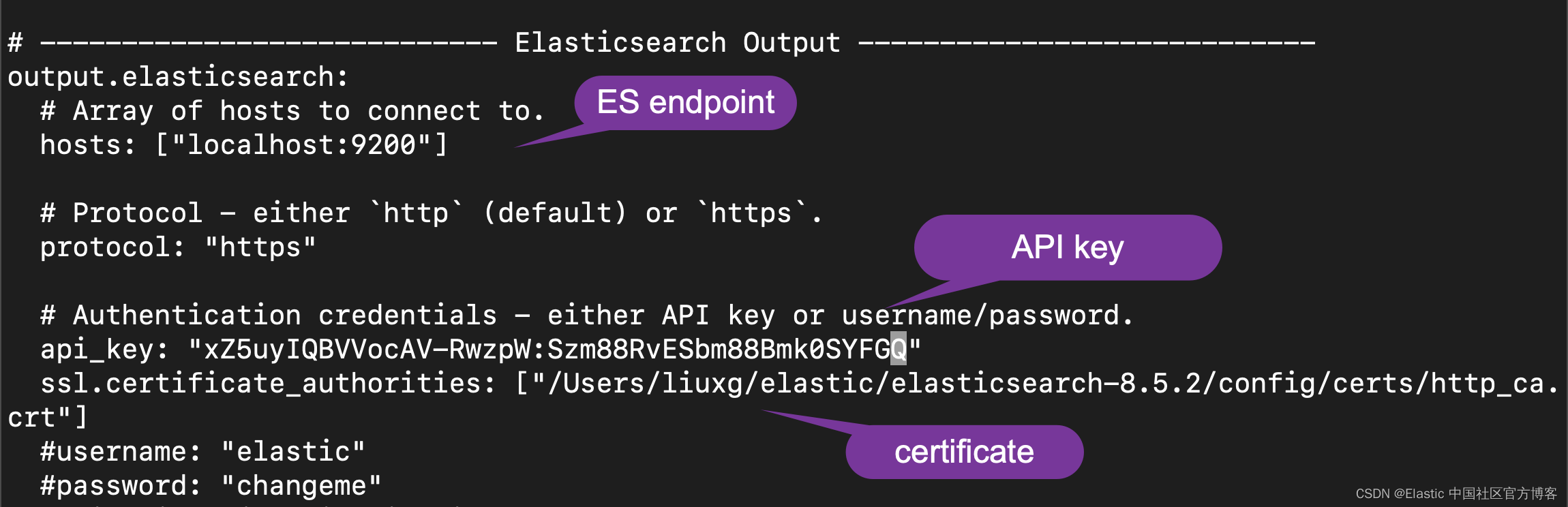
我们还需要在 filebeat.yml 的开头部分进行如下的修改:
name: javalin-app-shipper
filebeat.inputs:
- type: log
paths:
- /tmp/javalin/*.log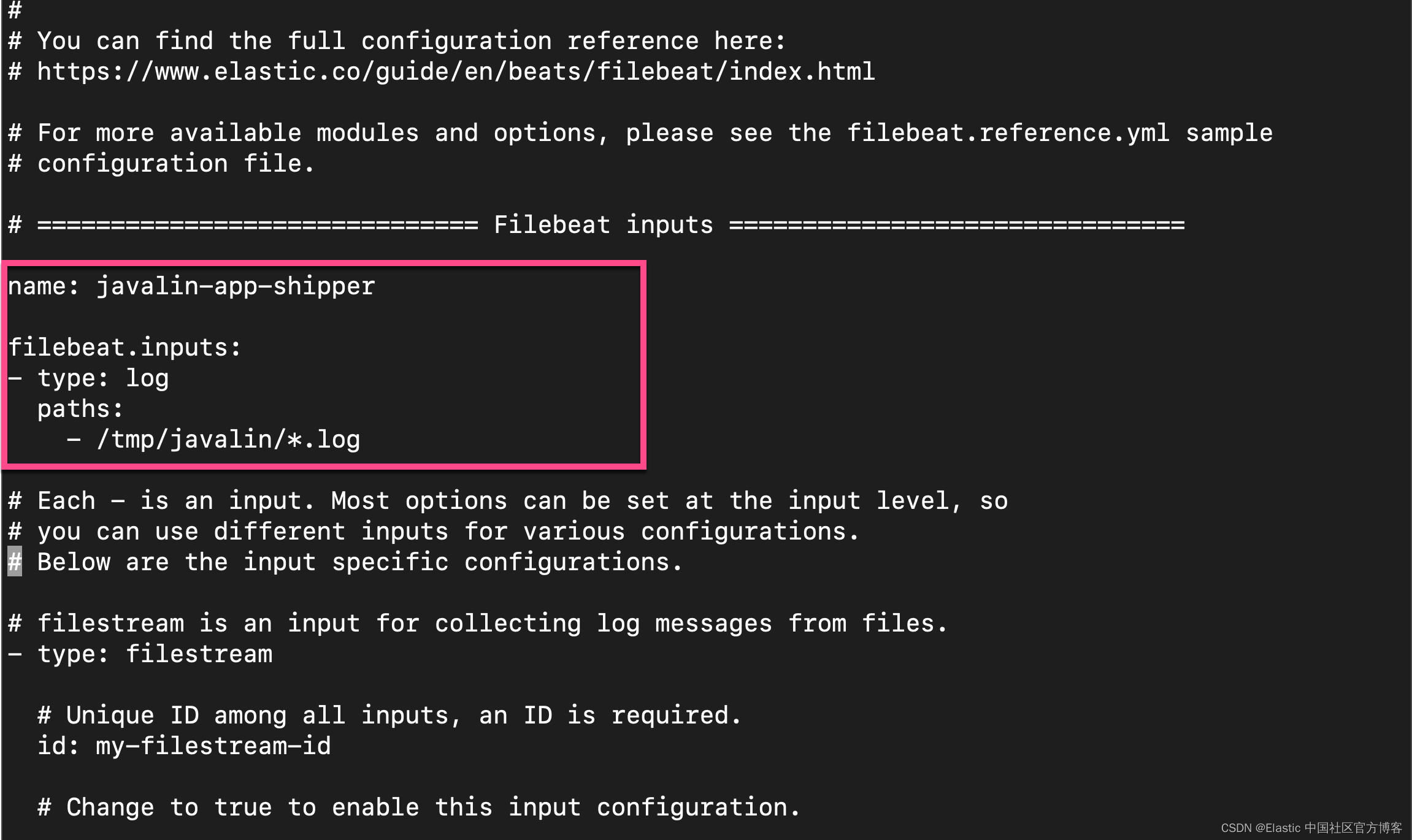
修改完上的部分后,我们进行如下的测试:
$ ./filebeat test config
Config OK
$ ./filebeat test output
elasticsearch: https://localhost:9200...
parse url... OK
connection...
parse host... OK
dns lookup... OK
addresses: ::1, 127.0.0.1
dial up... OK
TLS...
security: server's certificate chain verification is enabled
handshake... OK
TLS version: TLSv1.3
dial up... OK
talk to server... OK
version: 8.5.2上面表明:我们的配置是没有任何问题的,并且它可以正确地连接到 Elasticsearch。
我们接下来使用如下的命令来进行配置:
./filebeat setup$ ./filebeat setup
Overwriting ILM policy is disabled. Set `setup.ilm.overwrite: true` for enabling.
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Loaded Ingest pipelines上面的命令将生成 index pattern, ingest pipeline, index template 及 dashboard。针对我们的情况,因为是自定义的日志格式,它生成的 filebeat-* 索引模式对我们是有用的。
发送数据到 Elasticsearch
我们接下来运行如下的命令:
./filebeat -e在日志输出中,你应该看到以下行。
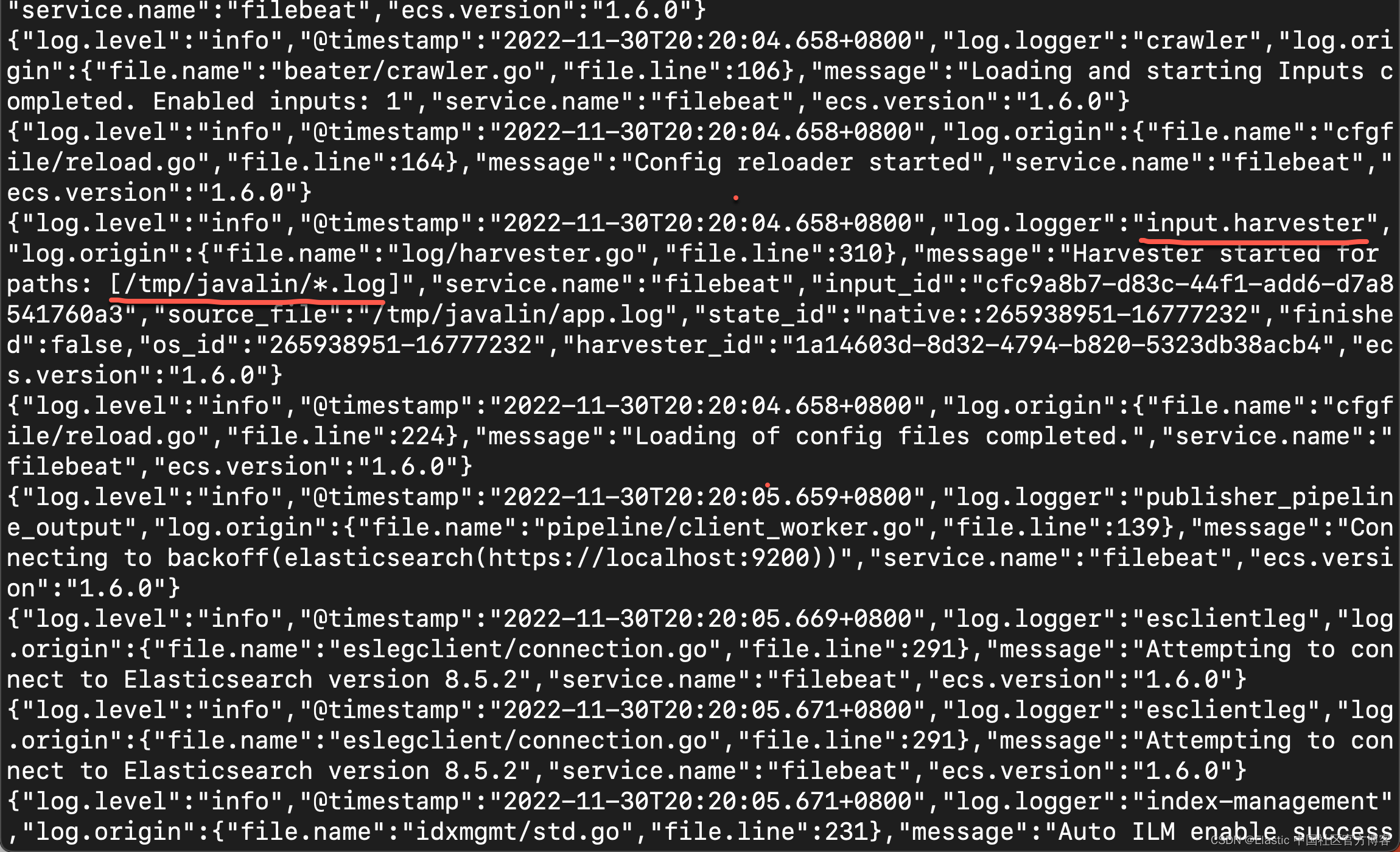
让我们为应用程序创建一些日志条目。 你可以使用 wrk 之类的工具并运行以下命令向应用程序发送请求。
wrk -t1 -c 100 -d10s http://localhost:8000$ wrk -t1 -c 100 -d10s http://localhost:8000
Running 10s test @ http://localhost:8000
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 41.59ms 78.47ms 763.72ms 88.69%
Req/Sec 12.39k 12.17k 42.90k 69.47%
117212 requests in 10.04s, 15.31MB read
Socket errors: connect 0, read 188, write 0, timeout 0
Requests/sec: 11677.54
Transfer/sec: 1.53MB到 Kibana 中进行查看
1)打开 Discover:
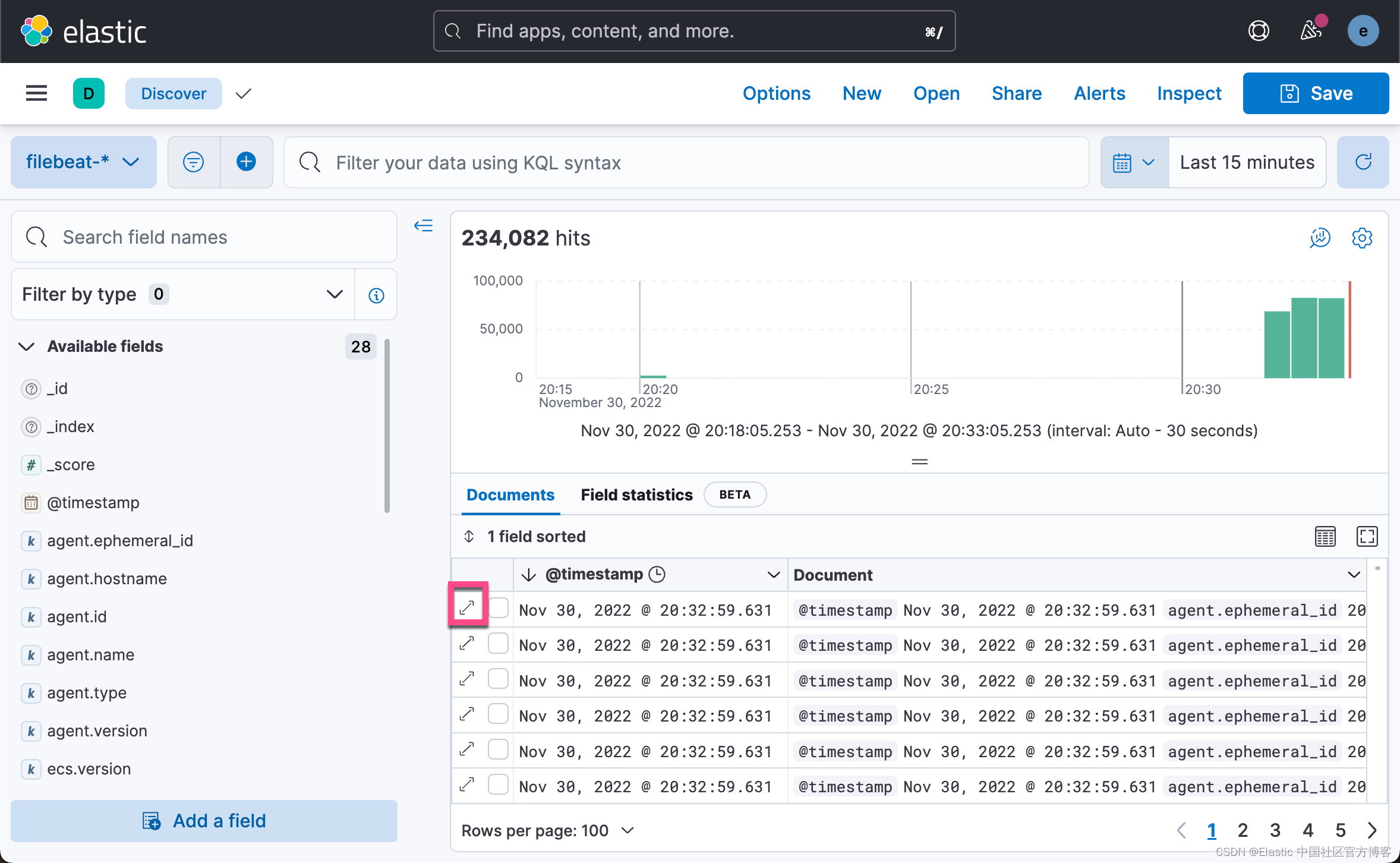 我们可以在 Discover 中进行查看。我们可以看到有12,900 多个文档被写入。我们展开上面的日志:
我们可以在 Discover 中进行查看。我们可以看到有12,900 多个文档被写入。我们展开上面的日志:
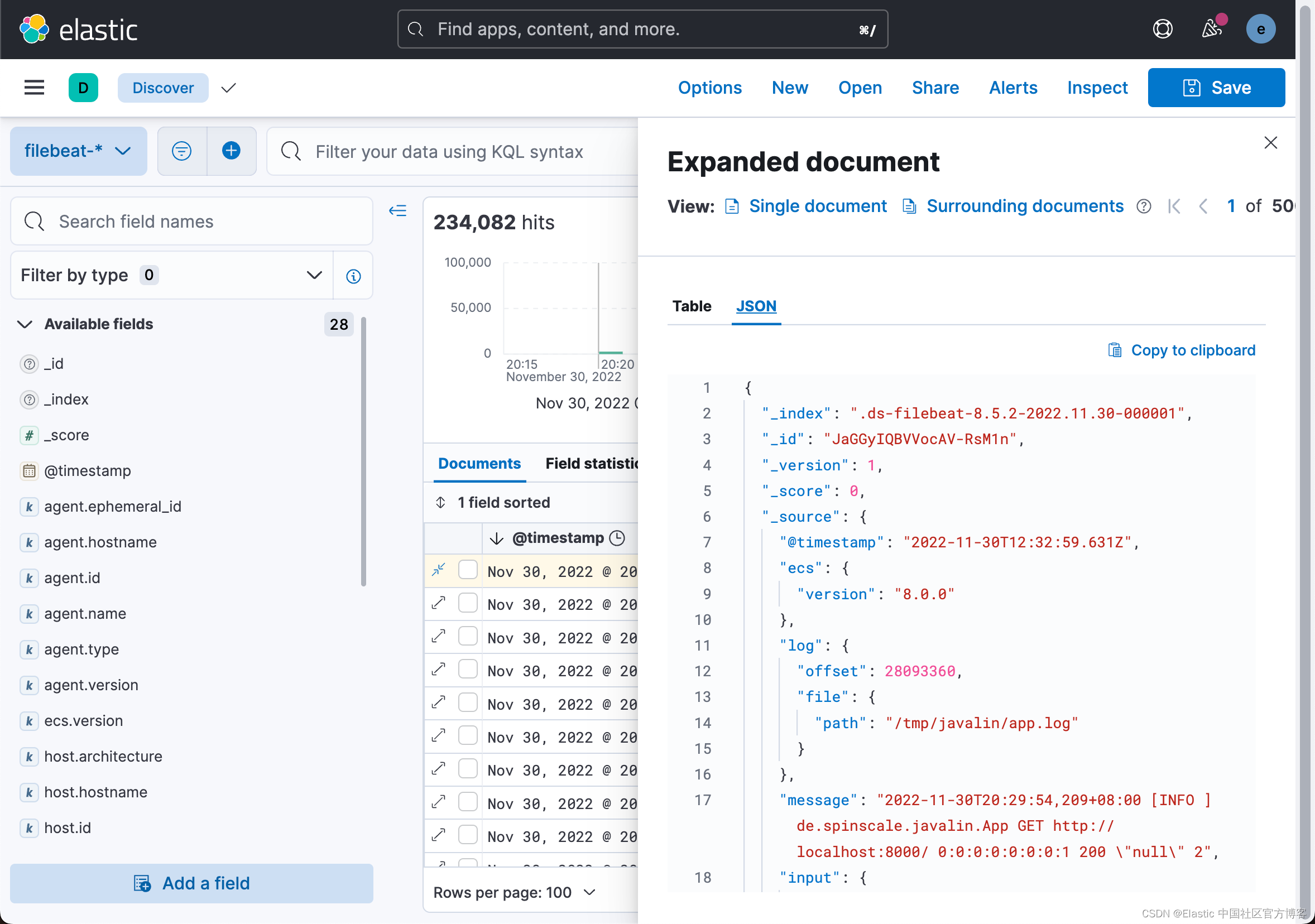
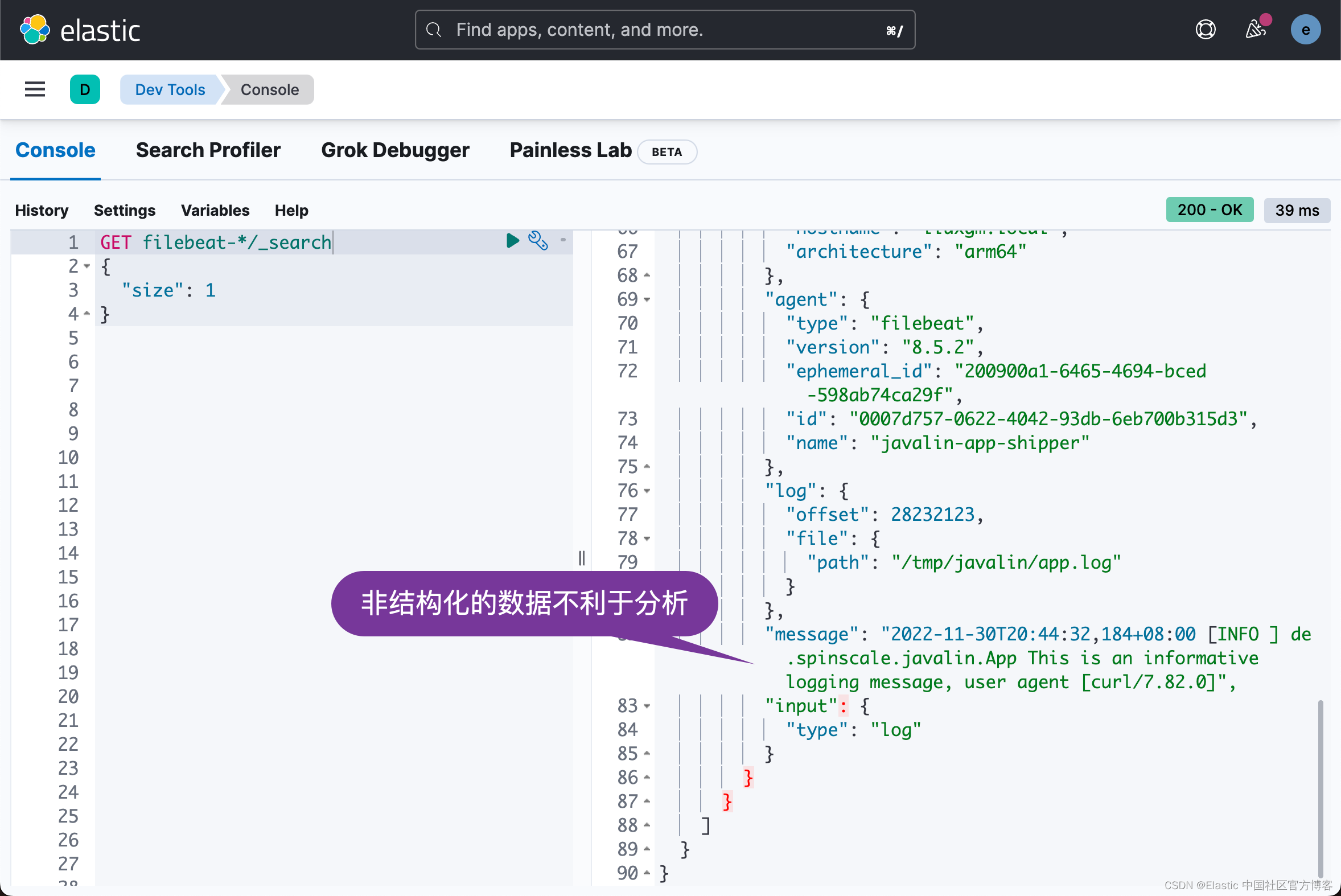
你可以看到索引的数据不仅仅是事件。 文件中有关于偏移量的信息,关于运送日志的组件的信息,输出中有运送者姓名的名称,还有一个包含日志行内容的消息字段。
你可以看到请求记录中存在缺陷。 如果用户代理为 null,则返回 null 以外的内容。 阅读我们的日志至关重要; 然而,仅仅索引它们对我们没有任何好处。 为了解决这个问题,这里有一个新的请求记录器。
Javalin app = Javalin.create(config -> {
config.requestLogger((ctx, executionTimeMs) -> {
String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-";
logger.info("{} {} {} {} \"{}\" {}",
ctx.method(), ctx.req.getPathInfo(), ctx.res.getStatus(),
ctx.req.getRemoteHost(), userAgent, executionTimeMs.longValue());
});
});你可能还想在主处理程序的日志消息中修复此问题。
static Handler mainHandler() {
return ctx -> {
String userAgent = ctx.userAgent() != null ? ctx.userAgent() : "-";
logger.info("This is an informative logging message, user agent [{}]", userAgent);
ctx.result("Absolutely perfect");
};
}2)现在让我们看一下 Kibana 中的日志应用程序。 选择可 Observability → Logs。
如果你想在工作中看到流功能,请在 sleep 时循环运行以下 curl 请求。
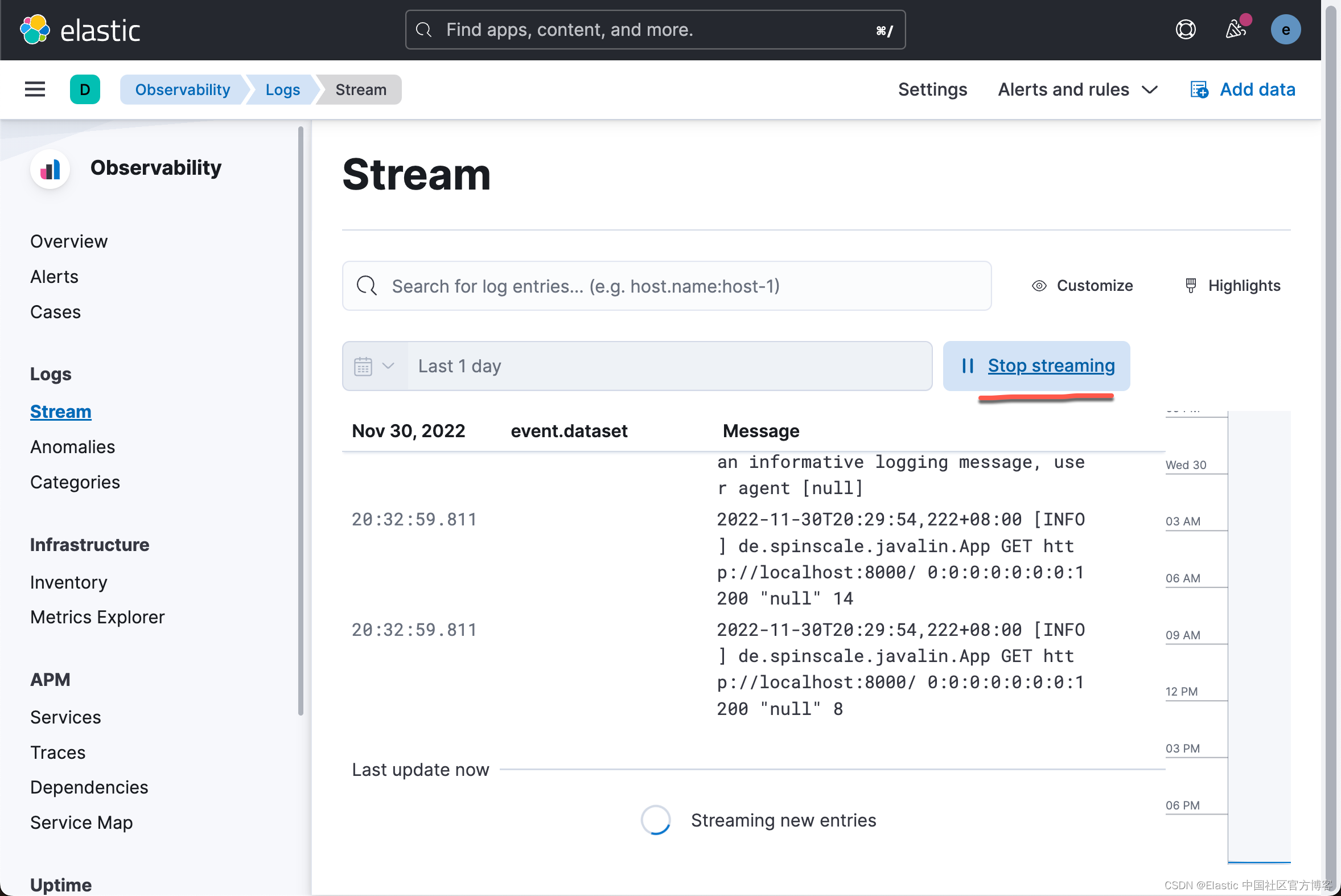
我们执行如下的命令:
while $(sleep 0.7) ; do curl localhost:8000 ; done 
在 Logs 应用中,我们可以看到不断进来的日志。
查看其中一个被索引的文档,你可以看到日志消息包含在一个字段中。 通过查看其中一份文件来验证这一点。
GET filebeat-*/_search
{
"size": 1
}
注意事项:
- 当你将 @timestamp 字段与日志 message 的 timestamp 进行比较时,你会注意到它的不同。 这意味着在基于 @timestamp 字段进行过滤时,你得不到预期的结果。 当前的 @timestamp 字段反映了在 Filebeat 中创建事件时的 timestamp,而不是日志事件在应用程序中发生时的 timestamp。
- 无法过滤特定字段,例如 HTTP 谓词、HTTP 状态代码、日志级别或生成日志消息的类
处理你的日志
结构化日志
要从单个日志行中将更多数据提取到多个字段中,需要对日志进行额外的结构化。
让我们再看看我们的应用程序生成的日志消息。
2022-11-30T20:44:32,184+08:00 [INFO ] de.spinscale.javalin.App This is an informative logging message, user agent [curl/7.82.0]这条消息有四个部分:timestamp、log level、class 和 message。 拆分规则也很明显,因为它们中的大多数都涉及空格。
好消息是,所有 Beats 都可以在使用处理器将日志行发送到 Elasticsearch 之前对其进行处理。 如果这些处理器的能力不够,你始终可以让 Elasticsearch 使用摄入节点(ingest node)来完成繁重的工作。 Filebeat 中的许多模块就是这样做的。 Filebeat 中的模块是一种为特定软件解析特定日志文件格式的方法。
让我们通过使用几个处理器和一个 Filebeat 配置来尝试一下。
processors:
- add_host_metadata: ~
- dissect:
tokenizer: '%{timestamp} [%{log.level}] %{log.logger} %{message_content}'
field: "message"
target_prefix: ""
- timestamp:
field: "timestamp"
layouts:
- '2006-01-02T15:04:05.999Z0700'
test:
- '2020-07-18T04:59:51.123+0200'
- drop_fields:
fields: [ "message", "timestamp" ]
- rename:
fields:
- from: "message_content"
- to: "message"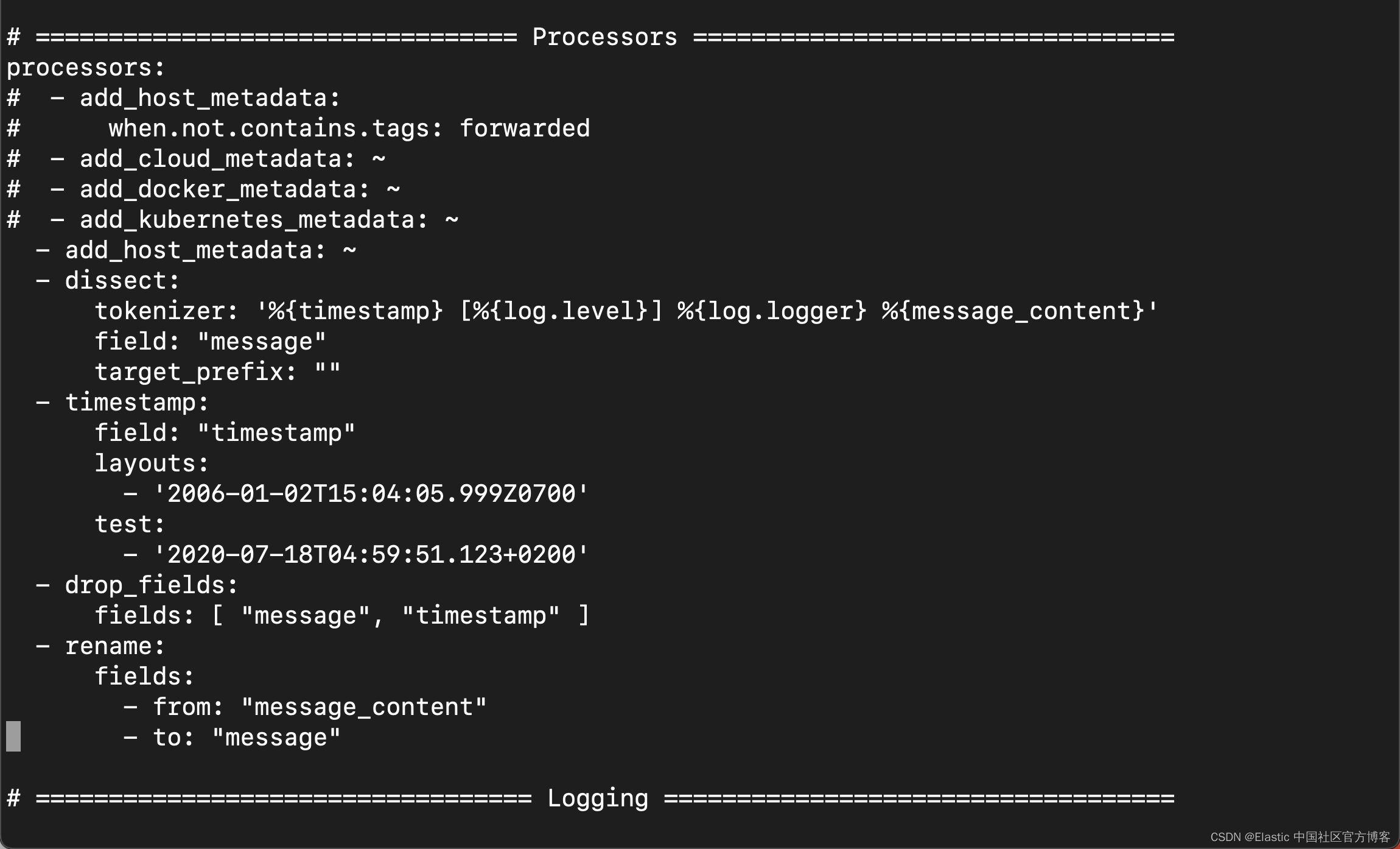
dissect 处理器将日志 message 分成四个部分。 如果要在消息字段中保留原始 message 的最后一部分,则需要先删除旧 message 字段,然后重命名该字段。 dissect 过滤器没法在里面替换 message。
还有一个专门的 timestamp 解析,以便 @timestamp 字段包含一个解析值。 删除重复的字段,但确保原始 message 的一部分在消息字段中仍然可用。
重要:删除部分原始 message 是有争议的。 保留原始 message 对我来说很有意义。 对于上面的示例,如果解析 timestamp 没有按预期工作,调试可能会出现问题。
timestamp 的解析也略有不同,因为运行时间解析器只接受点作为秒和毫秒之间的分隔符。 尽管如此,我们 log4j2 的默认输出仍然使用逗号。
任何一个都可以修复日志输出中的 timestamp,使其看起来像 Filebeat 所期望的那样。 这导致以下图 pattern layout。
log4j2.xml
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%-5level] %logger{36} %msg%n"/>修复 timestamp 解析是另一种方法,因为你并不总是可以完全控制日志并更改其格式。你可以使用一些第三方软件来解决这个问题。 现在,这就足够了。
更改后重新启动 Filebeat,并通过运行此搜索(并索引另一条日志消息)来查看索引 JSON 文档中的更改内容。
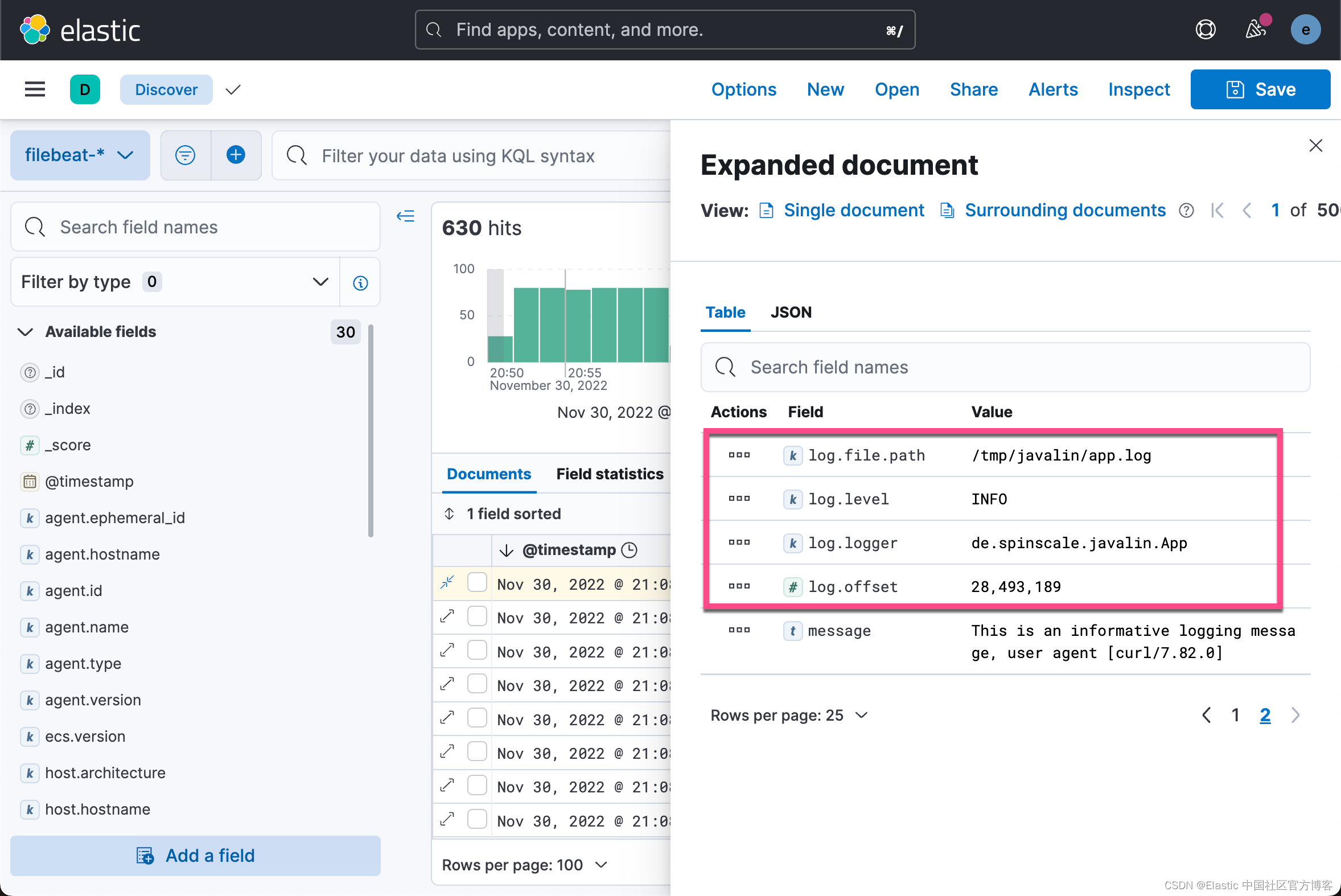
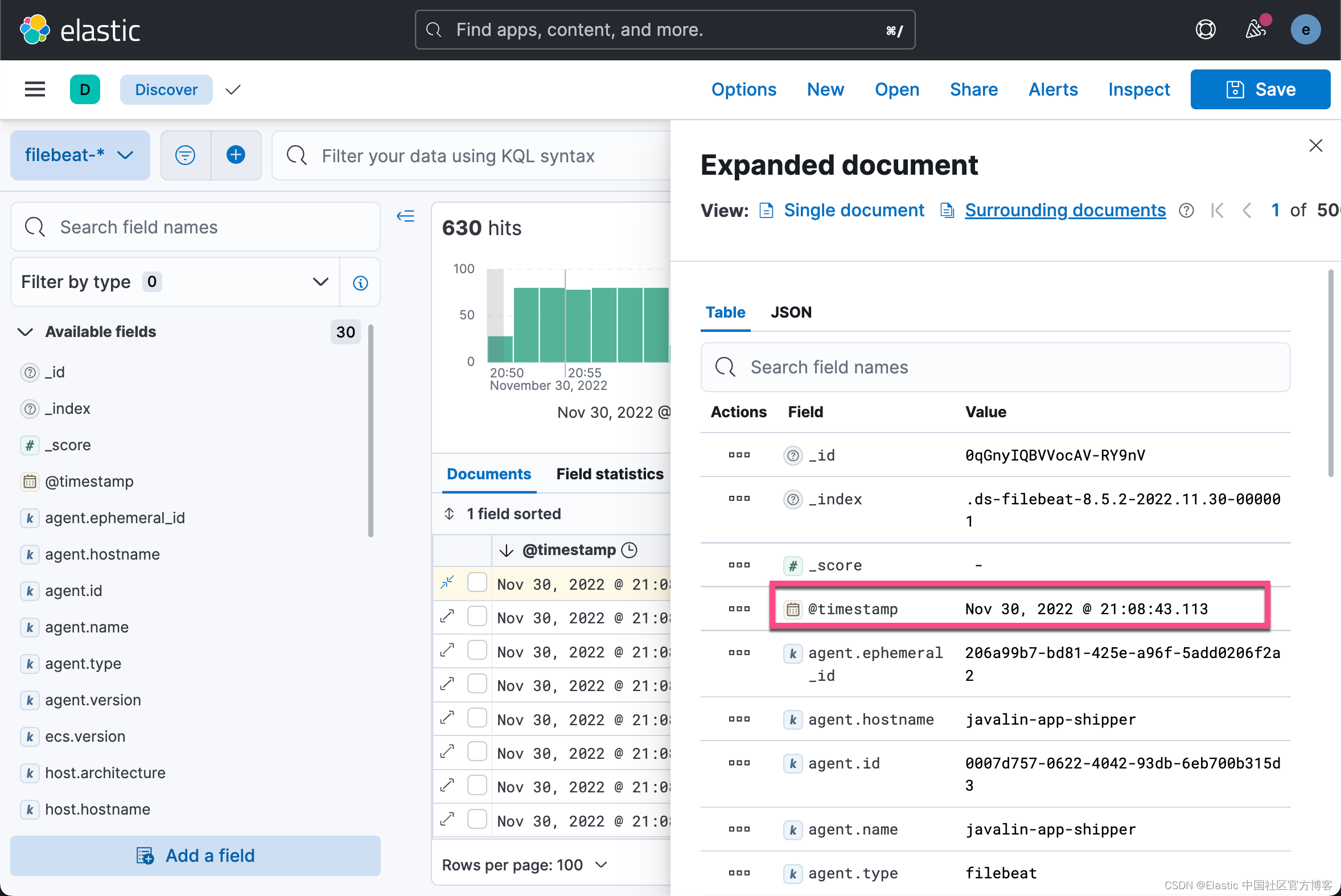
很显然,我们现在看到的是结构化的数据。它更利用我们分析数据。你可以看到 message 字段只包含我们日志消息的最后一部分。 此外,还有一个 log.level 和 log.logger 字段。
当日志级别为 INFO 时,它会在末尾添加额外的空间。 你可以使用 script 处理器并调用 trim()。 但是,无论日志级别长度如何,将我们的日志记录配置修复为不总是发出 5 个字符可能更容易。 在写入标准输出时你仍然可以保留它。
log4j2.xml
<File name="JavalinAppLog" fileName="/tmp/javalin/app.log">
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%level] %logger{36} %msg%n"/>
</File>解析异常
在日志记录的情况下,异常是一种特殊对待。 它们跨越多行,因此在异常中不存在每行一条消息的旧规则。
在 App.java 中添加一个首先触发异常的端点,并确保使用异常映射器记录它。
app.get("/exception", ctx -> {
throw new IllegalArgumentException("not yet implemented");
});
app.exception(Exception.class, (e, ctx) -> {
logger.error("Exception found", e);
ctx.status(500).result(e.getMessage());
});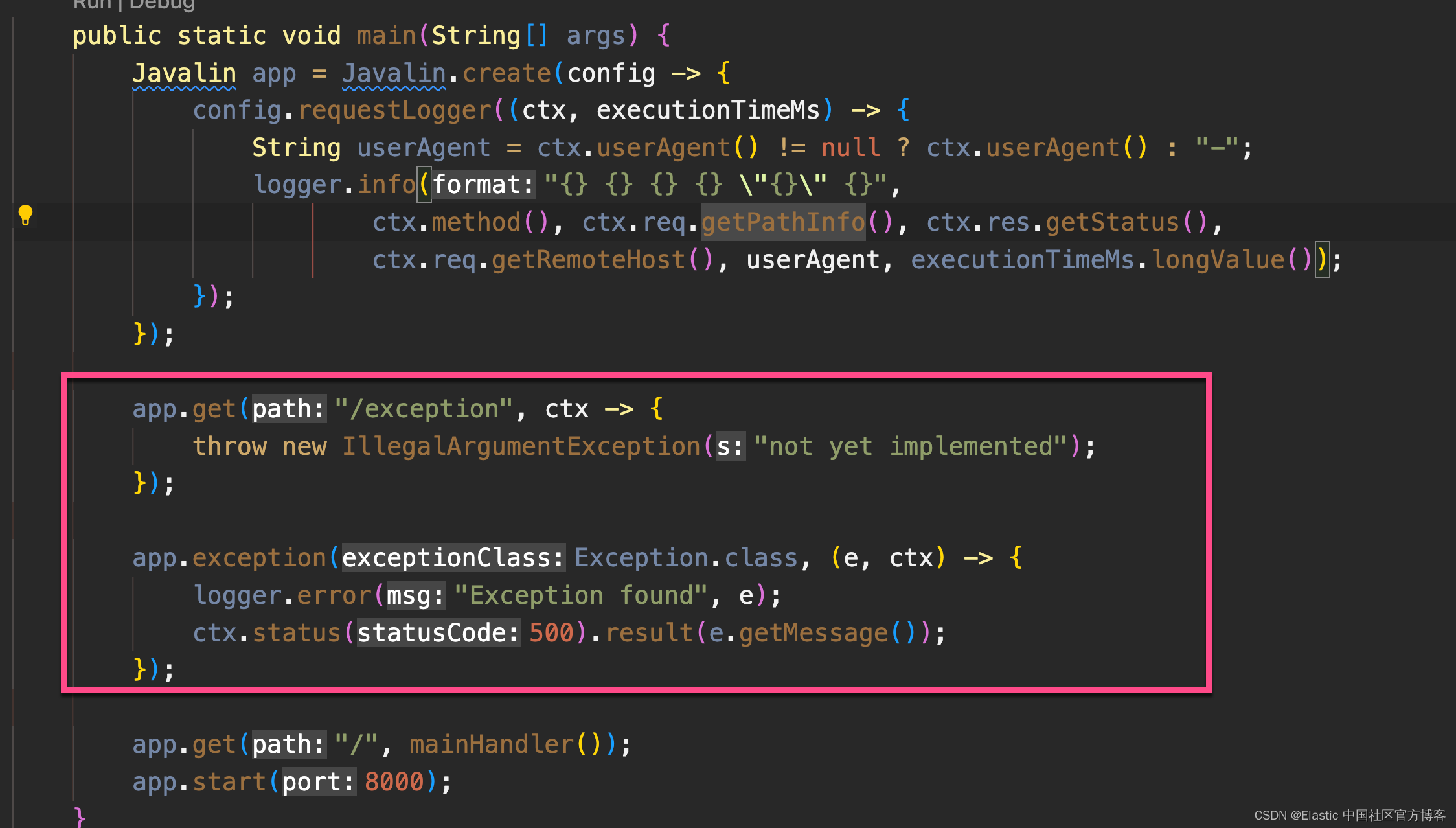
调用 /exception 会向客户端返回一个 HTTP 500 错误,但它会像这样在日志中留下堆栈跟踪。
curl http://localhost:8000/exception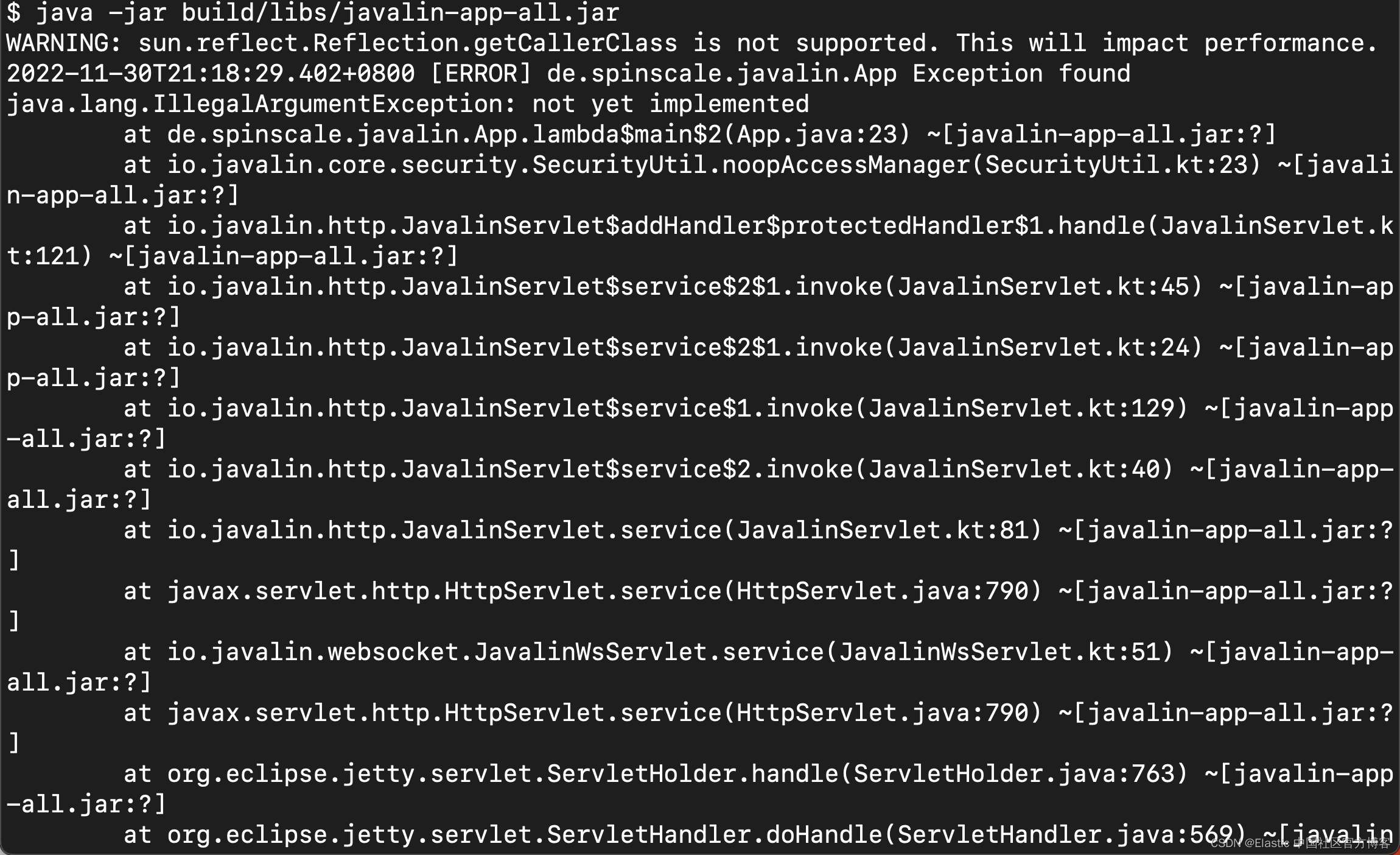
有一个属性有助于解析此堆栈跟踪。 与常规日志消息相比,它似乎有所不同。 每个新行都以空格开头,因此不同于以日期开头的日志消息。 让我们将此逻辑添加到我们的 Beats 配置中。
- type: log
enabled: true
paths:
- /tmp/javalin/*.log
multiline.pattern: ^20
multiline.negate: true
multiline.match: after因此,上述设置的逐字翻译表示将所有内容都视为现有消息的一部分,而不是以一行 20 开头。 20 看起来像是你的时间戳的开始。 一些用户喜欢将日期包裹在 [] 中以使其更易于理解。
注意:这会将状态引入你的日志记录中。 你现在无法在多个处理器之间拆分日志文件,因为每个日志行仍可能属于当前事件。 这不是一件坏事,但同样需要注意。
重新启动 Filebeat 和你的 Javalin 应用程序后,触发异常,你将在日志的消息字段中看到一个长堆栈跟踪。
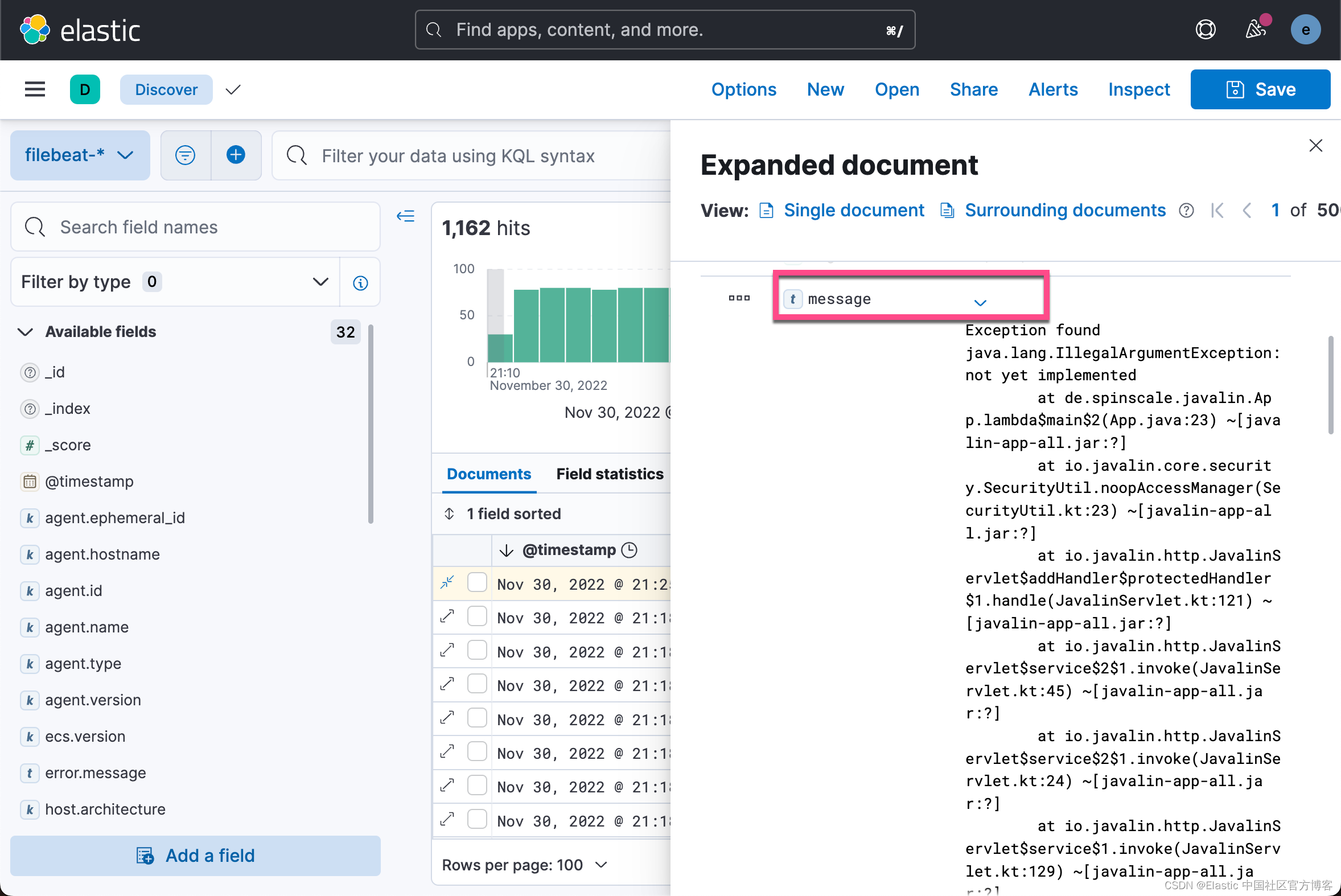
配置日志轮换
为确保日志不会无限增长,让我们在日志配置中添加一些日志轮换。
log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration>
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%highlight{%d{ISO8601_OFFSET_DATE_TIME_HHCMM} [%-5level] %logger{36} %msg%n}"/>
</Console>
<RollingFile name="JavalinAppLogRolling" fileName="/tmp/javalin/app.log" filePattern="/tmp/javalin/%d{yyyy-MM-dd}-%i.log.gz">
<PatternLayout pattern="%d{yyyy-MM-dd'T'HH:mm:ss.SSSZ} [%level] %logger{36} %msg%n"/>
<Policies>
<TimeBasedTriggeringPolicy />
<SizeBasedTriggeringPolicy size="50 MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingFile>
</Appenders>
<Loggers>
<Logger name="de.spinscale.javalin.App" level="INFO"/>
<Root level="ERROR">
<AppenderRef ref="Console" />
<AppenderRef ref="JavalinAppLogRolling" />
</Root>
</Loggers>
</Configuration>该示例向我们的配置添加了一个 JavalinAppLogRolling appender,它使用与以前相同的日志记录模式,但如果新的一天开始或日志文件达到 50 兆字节,则会滚动。
如果创建了一个新的日志文件,旧的日志文件也会被 gzip 压缩以减少磁盘空间。 50 兆字节的大小是指解压后的文件大小,因此磁盘上可能存在的 20 个文件每个都将小得多。
摄取节点
内置模块(modules)几乎完全使用 Elasticsearch 的 Ingest 节点功能,而不是 Beats 处理器。
摄取管道最有用的部分之一是能够使用模拟管道 API 进行调试。
1)让我们使用 Kibana 中的 Dev Tools 面板编写一个类似于我们的 Filebeat 处理器的管道,运行以下命令:
# Store the pipeline in Elasticsearch
PUT _ingest/pipeline/javalin_pipeline
{
"processors": [
{
"dissect": {
"field": "message",
"pattern": "%{@timestamp} [%{log.level}] %{log.logger} %{message}"
}
},
{
"trim": {
"field": "log.level"
}
},
{
"date": {
"field": "@timestamp",
"formats": [
"ISO8601"
]
}
}
]
}
# Test the pipeline
POST _ingest/pipeline/javalin_pipeline/_simulate
{
"docs": [
{
"_source": {
"message": "2020-07-06T13:39:51,737+02:00 [INFO ] de.spinscale.javalin.App This is an informative logging message"
}
}
]
}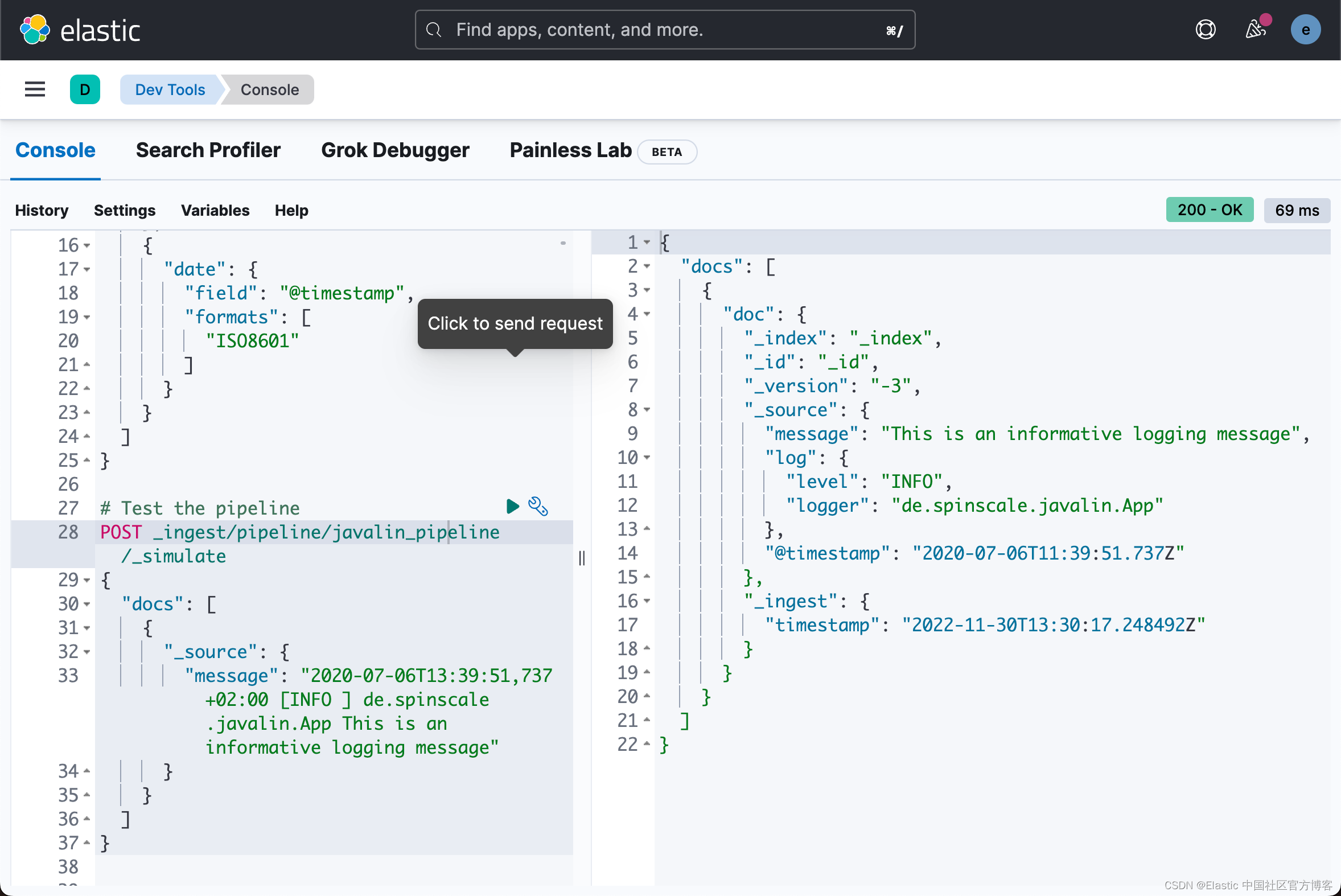
你可以在输出中看到管道创建的字段,现在看起来像早期的 Filebeat 处理器。 由于摄取管道在文档级别工作,你仍然需要检查生成日志的异常情况,并让 Filebeat 从中创建一条消息。 你甚至可以使用单个处理器实现 log level 的 trim,并且日期解析也非常简单,因为 Elasticsearch ISO8601 解析器在拆分秒和毫秒时正确识别逗号而不是点。
2)现在,进入 Filebeat 配置。 首先,让我们删除除 add_host_metadata 处理器之外的所有处理器,以添加一些主机信息,如主机名和操作系统。
processors:
- add_host_metadata: ~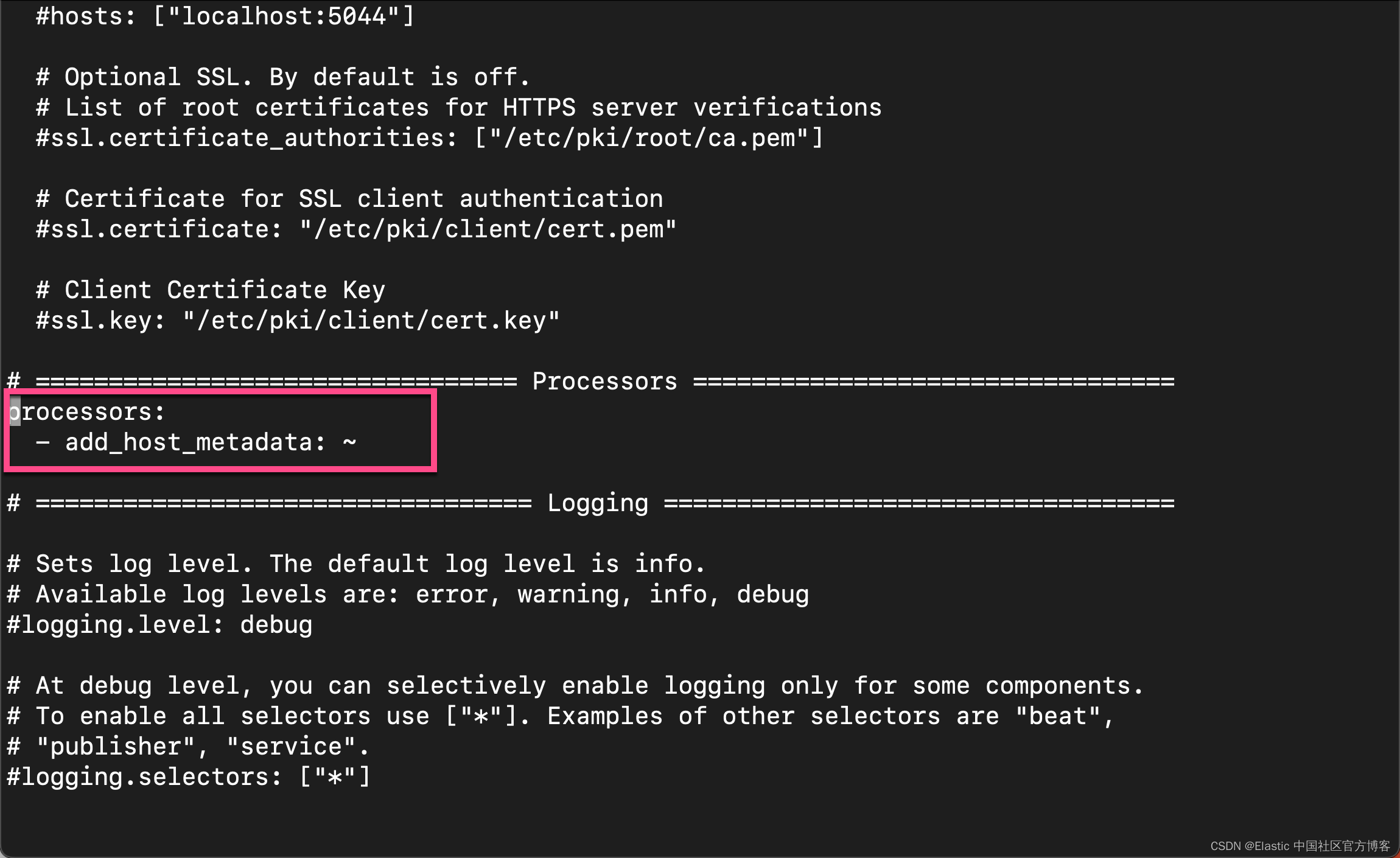
3)编辑 Elasticsearch 输出以确保在从 Filebeat 为文档编制索引时将引用管道。
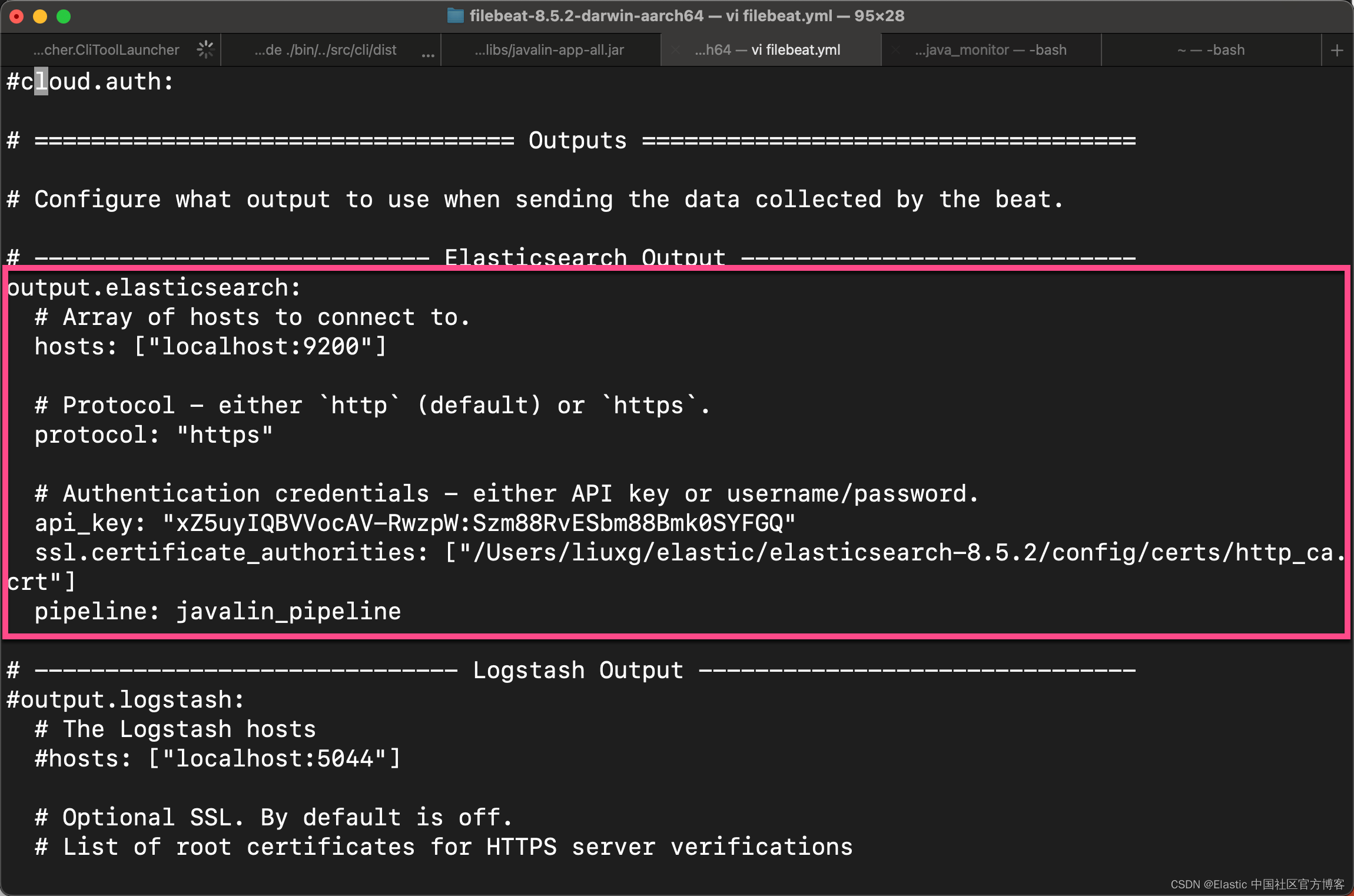
4)重新启动 Filebeat 并查看日志是否按预期流入。
curl http://localhost:8000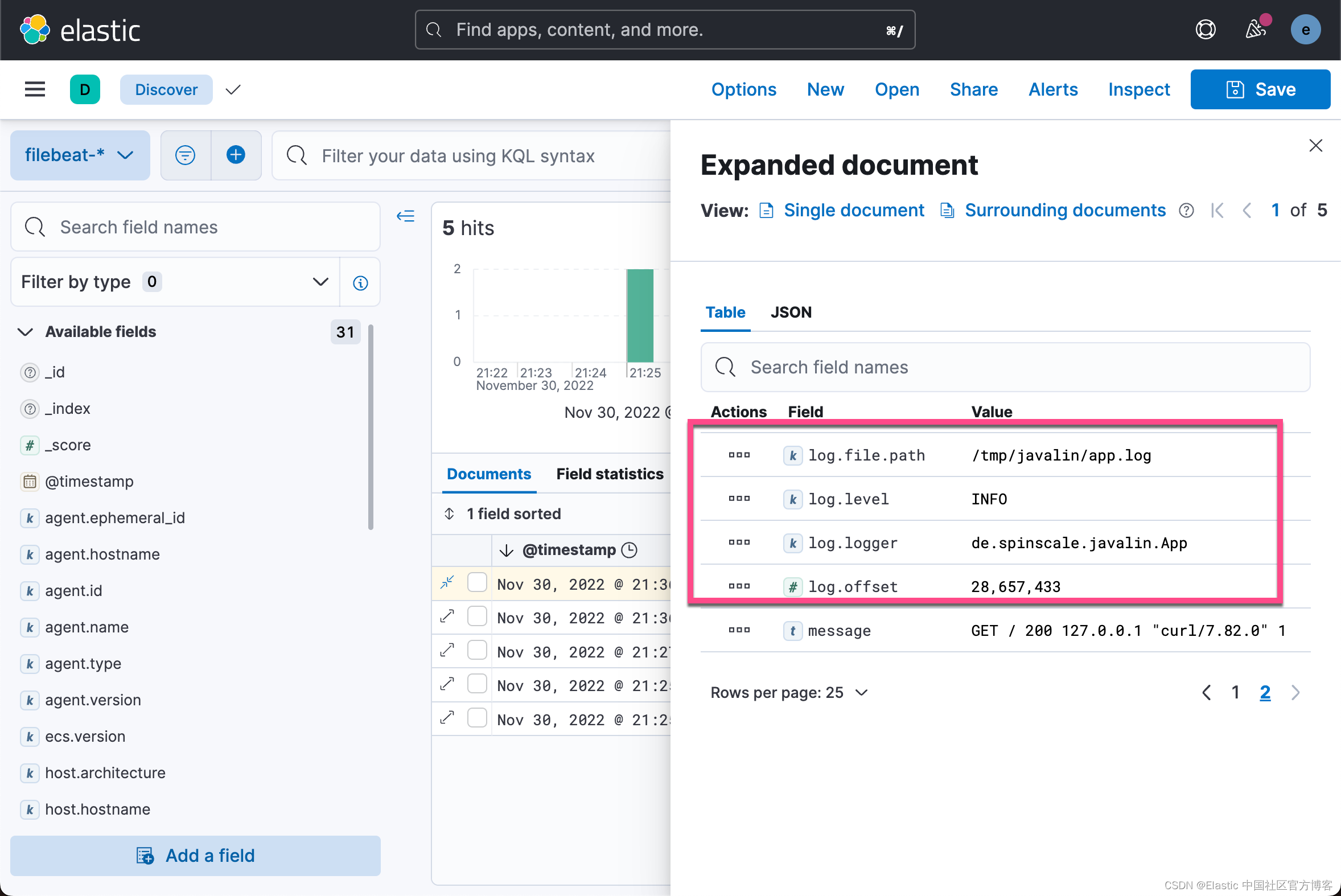
将日志写入 JSON
你现在已经了解了如何在 Beats 或 Elasticsearch 中解析日志。 如果我们不需要考虑手动解析日志和提取数据怎么办?
以纯文本形式写出日志是可行的,并且易于人类阅读。 然而,首先将它们写成纯文本,使用解剖处理器解析它们,然后再次创建一个 JSON 听起来很乏味并且会消耗不必要的 CPU 周期。
虽然 log4j2 有一个 JSONLayout,但你可以更进一步使用名为 ecs-logging-java 的库。 ECS 日志记录的优势在于它使用 Elastic Common Schema。 ECS 定义了在 Elasticsearch 中存储事件数据时使用的一组标准字段,例如日志和指标。
1)不要编写我们的日志记录标准,而是使用现有的标准。 让我们将日志记录依赖项添加到我们的 Javalin 应用程序中。
dependencies {
compile "org.slf4j:slf4j-simple:1.7.30"
implementation 'io.javalin:javalin:3.10.1'
implementation 'org.apache.logging.log4j:log4j-slf4j18-impl:2.13.3'
implementation 'co.elastic.logging:log4j2-ecs-layout:0.5.0'
testImplementation 'org.mockito:mockito-core:3.5.10'
testImplementation 'org.assertj:assertj-core:3.17.2'
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2'
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.6.2'
}
// this is needed to ensure JSON logging works as expected when building
// a shadow jar
shadowJar {
transform(com.github.jengelman.gradle.plugins.shadow.transformers.Log4j2PluginsCacheFileTransformer)
}log4j2-ecs-layout 附带一个自定义 <EcsLayout> ,可用于滚动文件附加程序的日志记录设置
log4j2.xml
<RollingFile name="JavalinAppLogRolling" fileName="/tmp/javalin/app.log" filePattern="/tmp/javalin/%d{yyyy-MM-dd}-%i.log.gz">
<EcsLayout serviceName="my-javalin-app"/>
<Policies>
<TimeBasedTriggeringPolicy />
<SizeBasedTriggeringPolicy size="50 MB"/>
</Policies>
<DefaultRolloverStrategy max="20"/>
</RollingFile>当你重新启动你的应用程序时,你将看到纯 JSON 写入您的日志文件。 当你触发异常时,你会看到堆栈跟踪已经在你的单个文档中。 这意味着 Filebeat 配置可以变得无状态甚至更轻量级。 另外,Elasticsearch 端的 ingest pipeline 可以再次删除。
在运行之前,我们可以先删除之前的 app.log 文件以看得更加清楚:
rm -rf /tmp/javalin/app.log curl http://localhost:8000/exception我们再次查看 /tmp/javalin/app.log 文件:
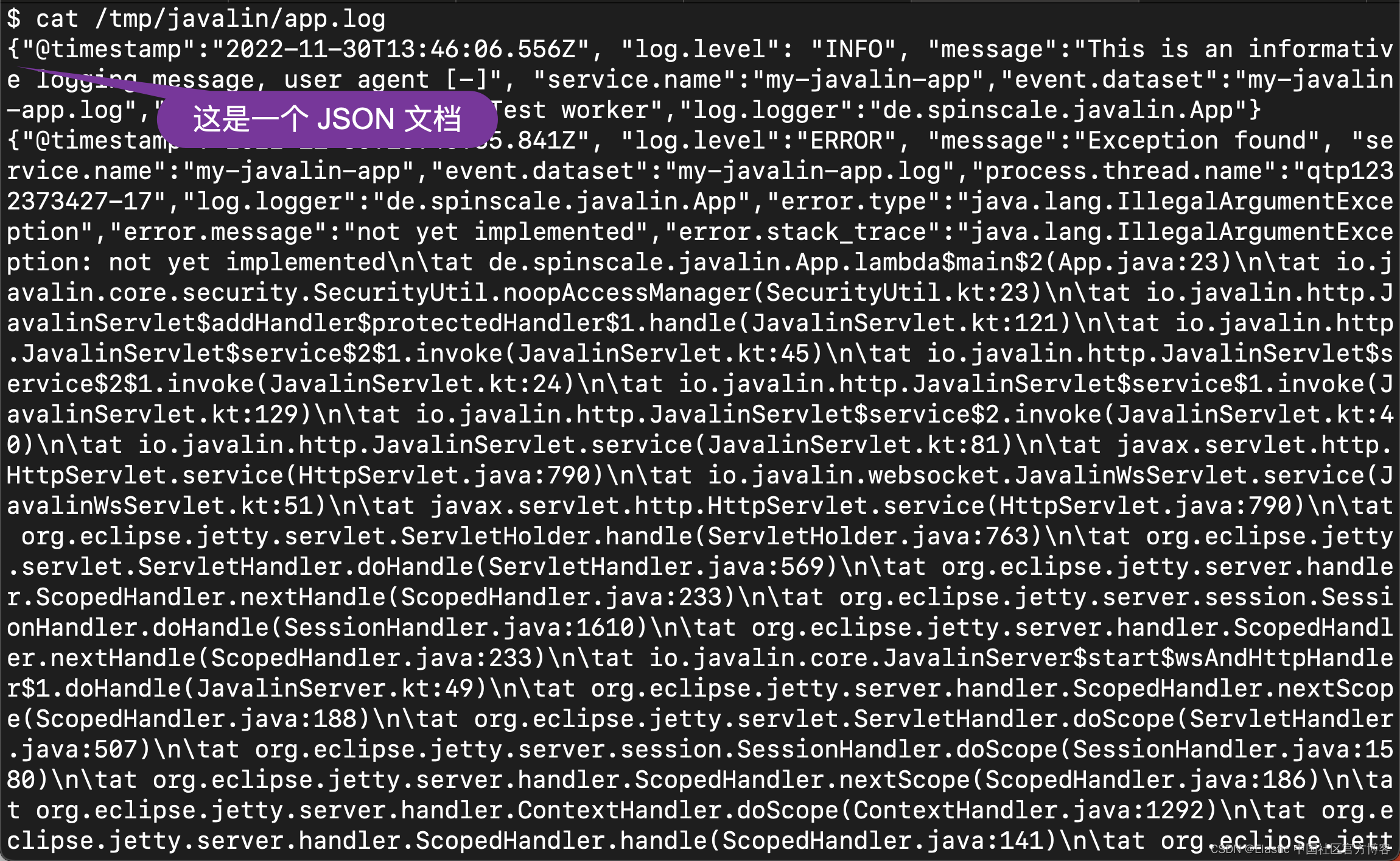
2)你可以为 EcsLayout 配置更多参数,但明智地选择了默认值。 让我们修复 Filebeat 配置并删除多行设置以及管道:
filebeat.yml
filebeat.inputs:
- type: log
paths:
- /tmp/javalin/*.log
json.keys_under_root: true 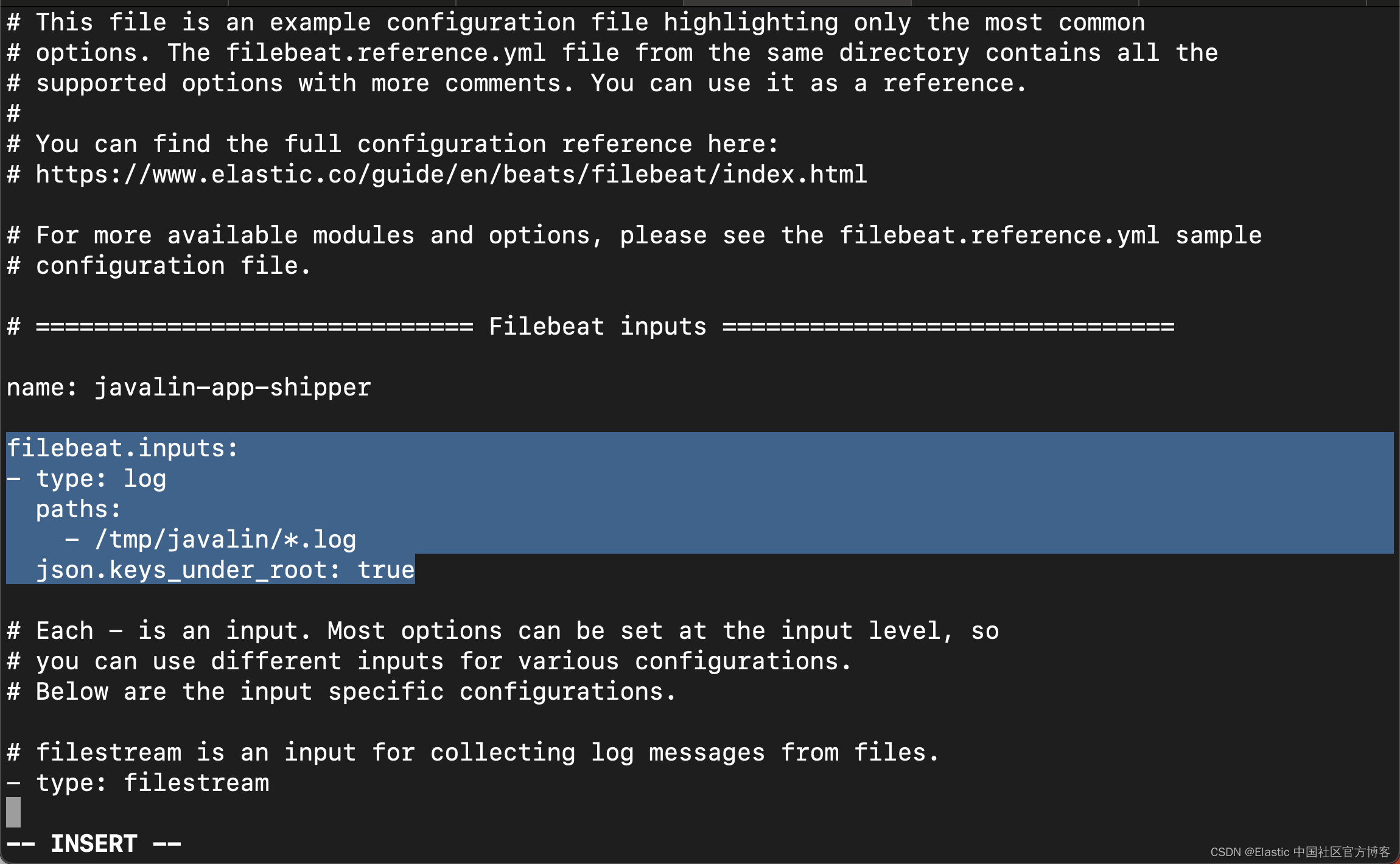
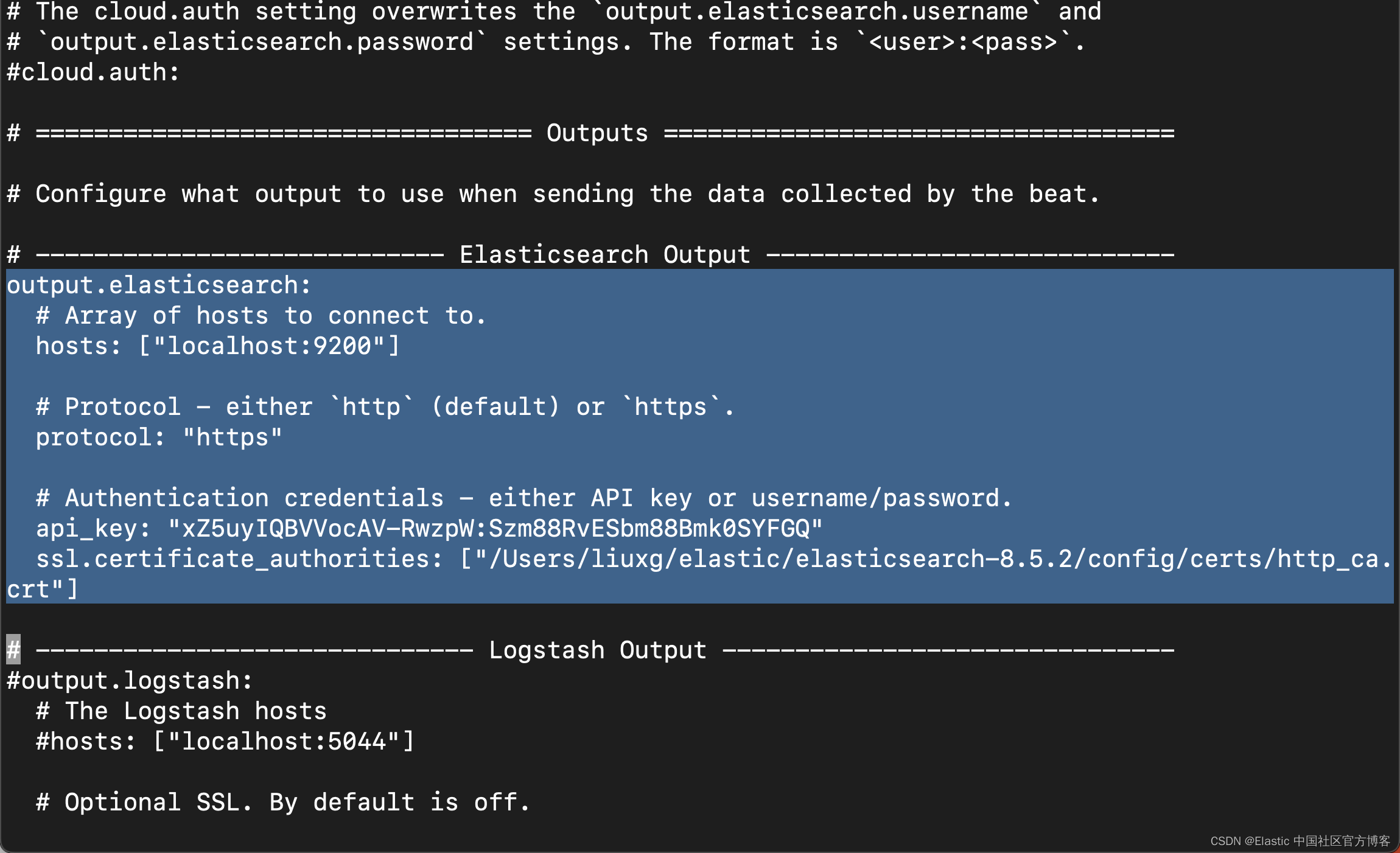
processors:
- add_host_metadata: ~
如你所见,仅通过将日志写成 JSON,我们的整个日志记录设置就变得容易了很多,因此只要有可能,请尝试直接将日志写成 JSON。
重新运行 Filebeat,并在 Kibana 中进行查看:
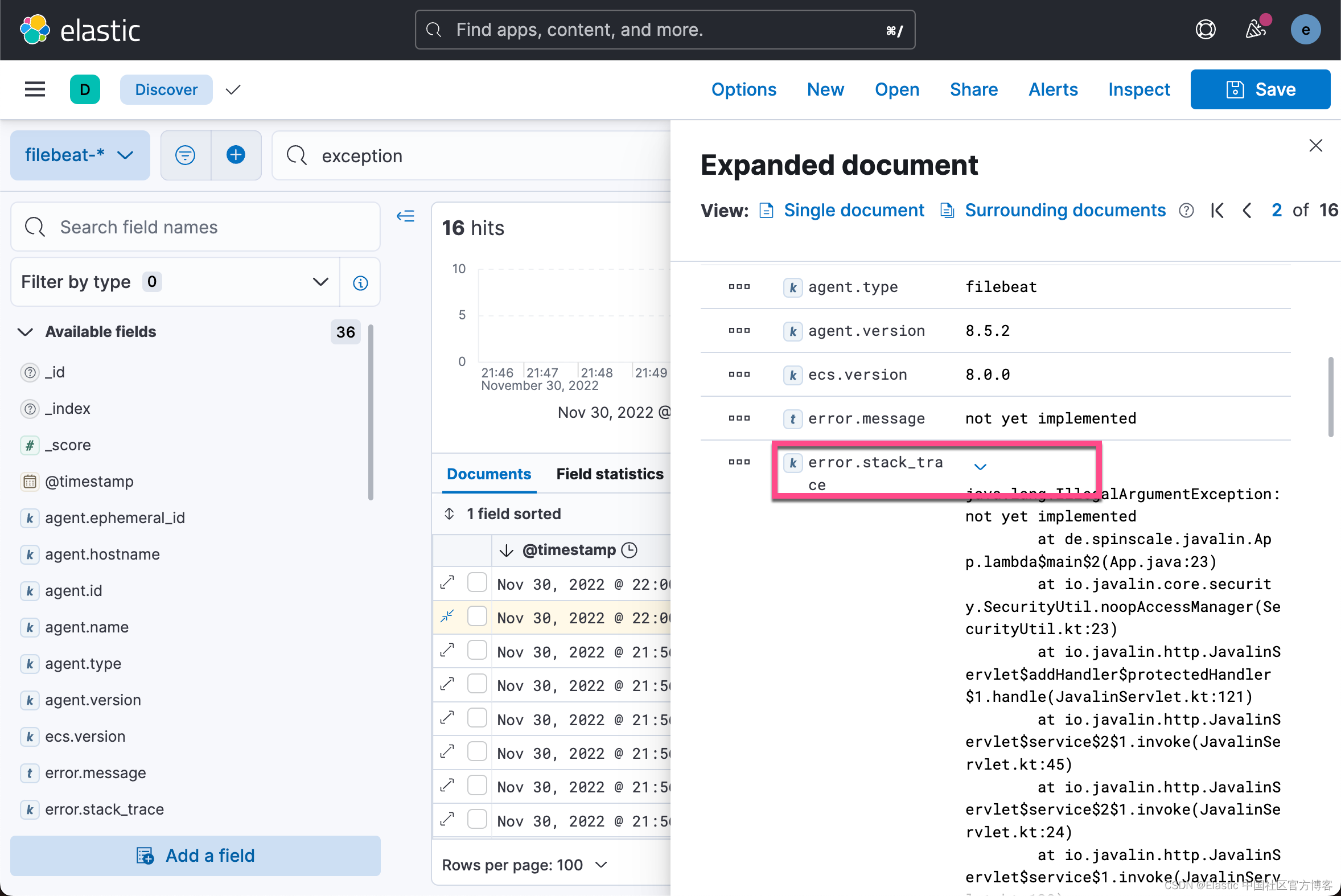
好了,我今天就先讲到这里。在接下来的文章中,我将展示如何为这个 web 网站收集指标。敬请期待!






![[附源码]计算机毕业设计springboot基于VUE的网上订餐系统](https://img-blog.csdnimg.cn/094d730cd08449afb27184fbf14e6abe.png)