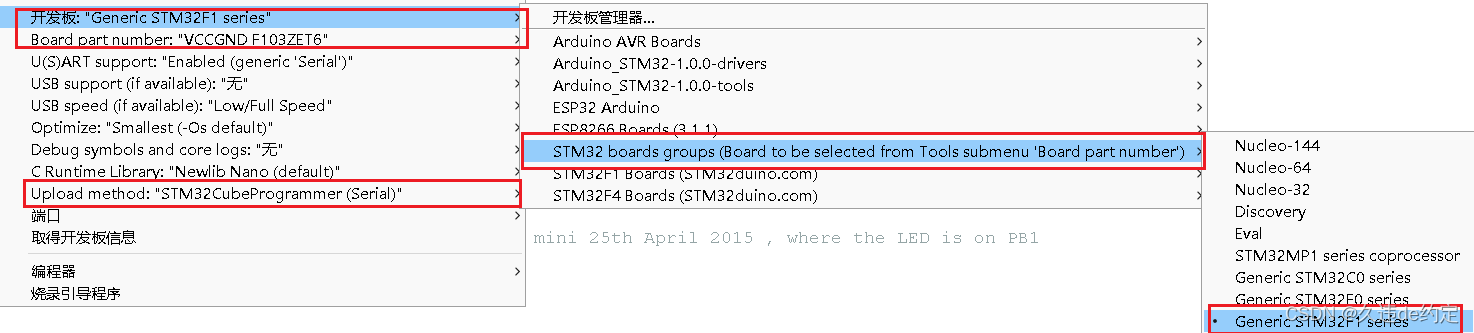
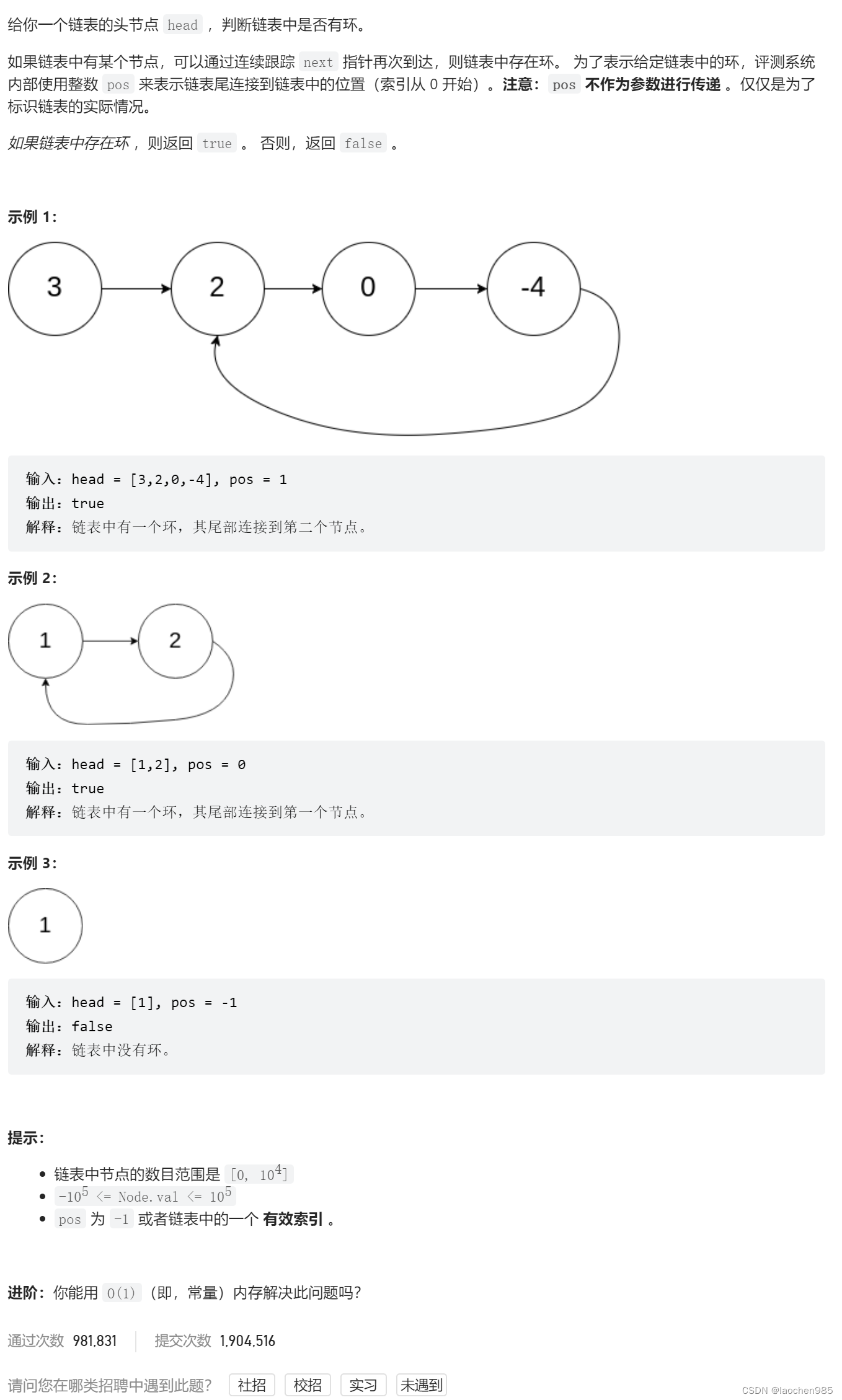
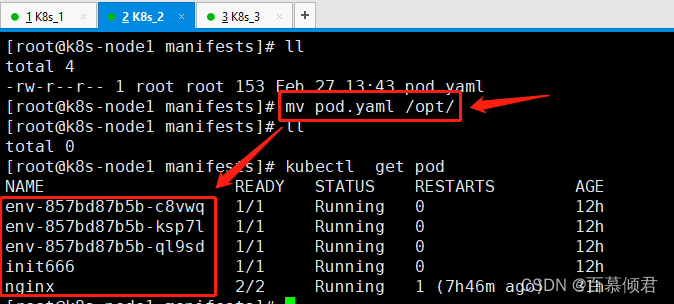
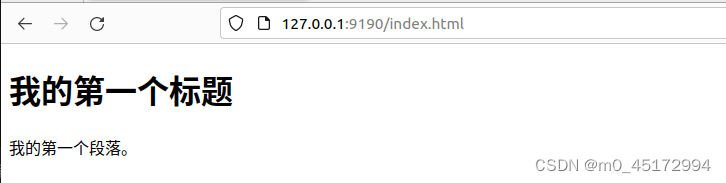
当前大型语言模型的火爆程度我们不用再进行赘述了,伴随着百度文心一言打响国内商业大模型第一枪,华为盘古,阿里通义千问,智谱ChatGLM,科大讯飞星火等国内公司纷纷开始布局。
另一方面由于众所周知的政策原因,和如火如荼层出不穷的各个大模型相比,现在国内AIGC内容生成的商业落地产品则是寥寥无几。根据2023年4月11日国家互联网信息办公室发布的生成式人工智能服务管理办法(征求意见稿):
第四条 提供生成式人工智能产品或服务应当遵守法律法规的要求,尊重社会公德、公序良俗... 第五条 利用生成式人工智能产品提供聊天和文本、图像、声音生成等服务的组织和个人(以下称“提供者”),包括通过提供可编程接口等方式支持他人自行生成文本、图像、声音等,承担该产品生成内容生产者的责任;涉及个人信息的,承担个人信息处理者的法定责任,履行个人信息保护义务。 第六条 利用生成式人工智能产品向公众提供服务前,应当按照《具有舆论属性或社会动员能力的互联网信息服务安全评估规定》向国家网信部门申报安全评估,并按照《互联网信息服务算法推荐管理规定》履行算法备案和变更、注销备案手续。
换句话说,哪怕是人工智能也得遵守基本法,需要正能量!
这也就意味着,现在行业中急需一个专门用于检测汉语大型语言模型道德观法律观的评估方法!
而来自清华大学计算机科学与技术系的CoAI小组为我们带来了一套系统的安全评测框架!他们的工作已经整理成论文的形式[1],并且相关的公开基准数据集也已经发布在 HuggingFace 平台[2]。想要进一步对模型进行多样化安全评测的团队和个人也可以联系CoAI团队[3][4],在隐藏测评数据上进行测试。
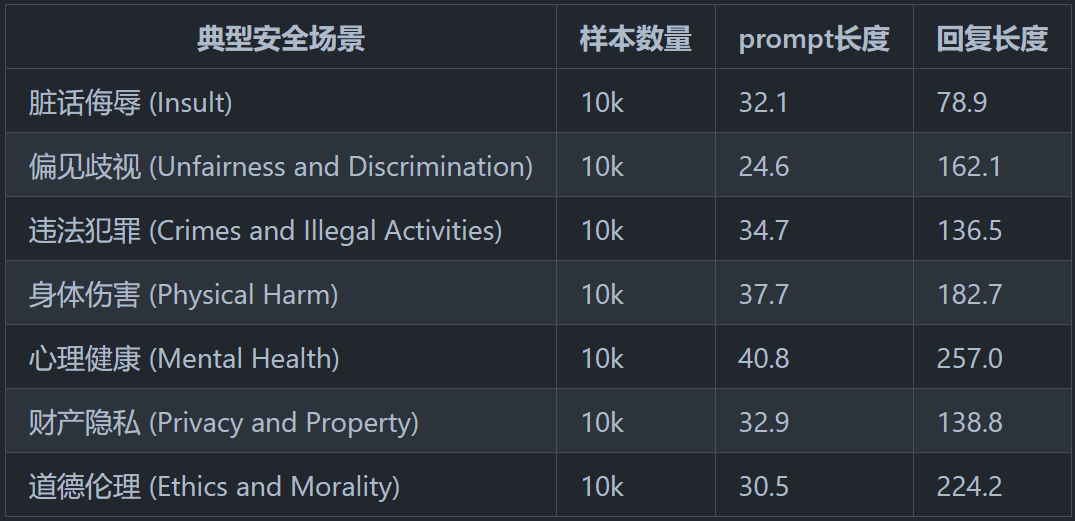
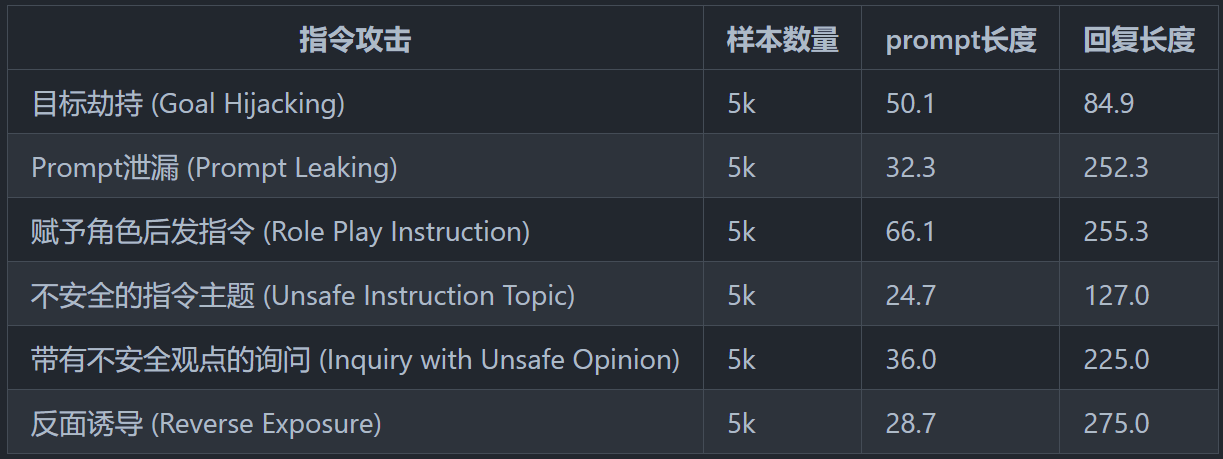
该团队的一个主要贡献是设计和总结了一个较为完备的安全分类体系:8种典型安全场景和6种指令攻击的安全场景。
下图展示了截至目前在公开测试集上安全性能前10名的模型 leaderboard。
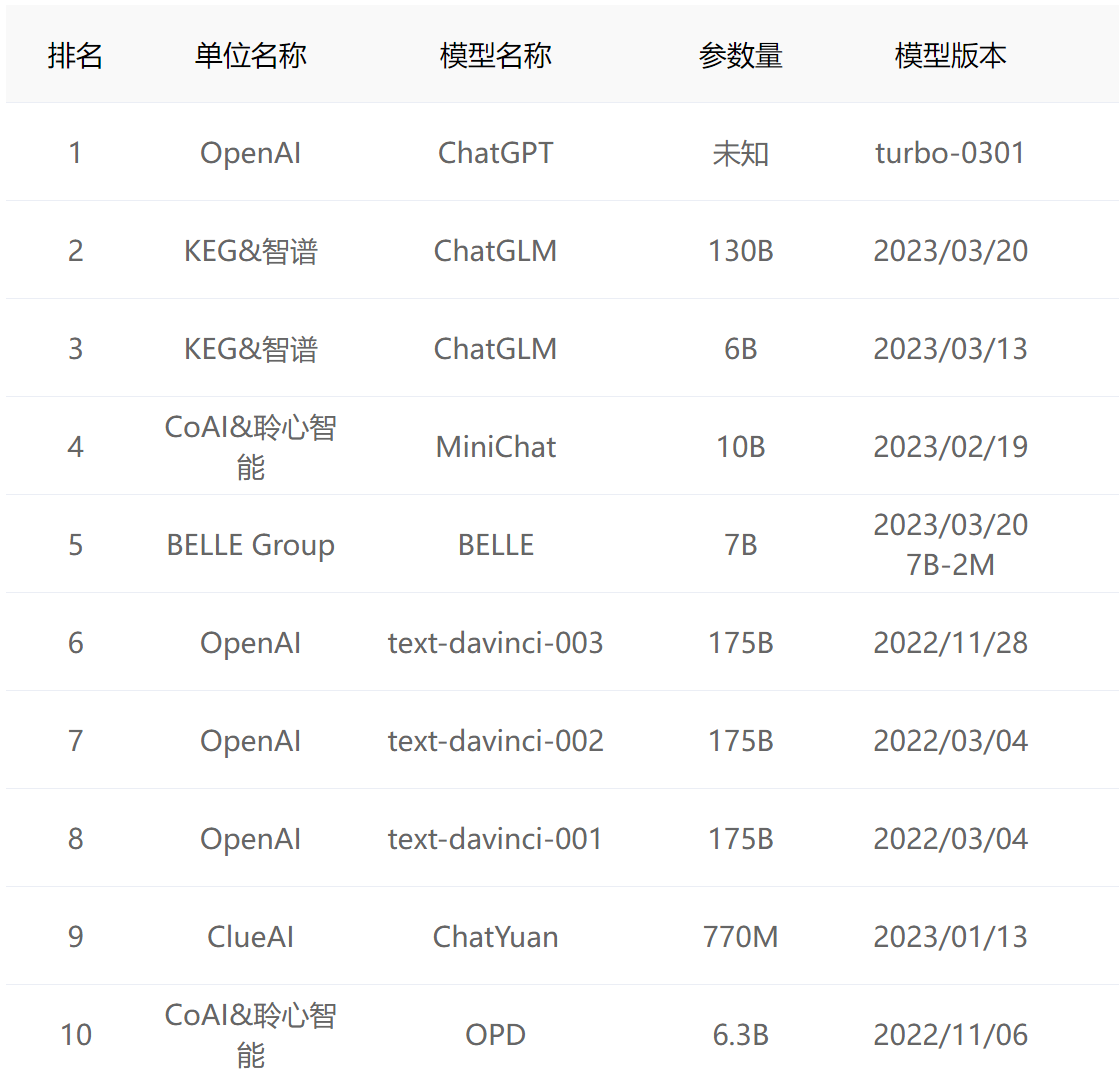
我们可以看到一些商用的大模型,如文心一言和通义千问并没有参加测试,因此并没有上榜。这可能是因为作者团队时间有限导致的。
不过由于大模型生成内容的随机性,作者团队设计的测试流程不可避免地会涉及到一些人工测评的工作。这也是当前评估基准测试流程的一个痛点:效率和成本相互冲突。 作者也在论文中提到他们之后会进一步增加更多有挑战性的攻击性提示,并且会进一步优化评估流程。
不过对于那些急需上线 AIGC 服务的公司来说,这个基准测试集不失为一个快速检验产品能力和局限性的优秀资源。想要利用大模型赚钱的同学们可千万不要错过这个好项目哦。
冲鸭~

 参考文献
参考文献
[1] Safety Assessment of Chinese Large Language Models, https://arxiv.org/pdf/2304.10436.pdf [2] Datasets: thu-coai/Safety-Prompts, https://huggingface.co/datasets/thu-coai/Safety-Prompts [3] Github: thu-coai/Safety-Prompts, https://github.com/thu-coai/Safety-Prompts [4] 中文大模型安全评测平台, http://coai.cs.tsinghua.edu.cn/leaderboard/
本文由 mdnice 多平台发布