😛作者:日出等日落
📘 专栏:数据结构
在最黑暗的那段人生,是我自己把自己拉出深渊。没有那个人,我就做那个人。 ——中岛美嘉

😩快速排序:
Hoare版本(递归):
基本思想:
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,这个排序很重要
其基本思想为:
任取待排序元素序列中 的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
(官方语言,接下来请看详细解释)
动图演示:
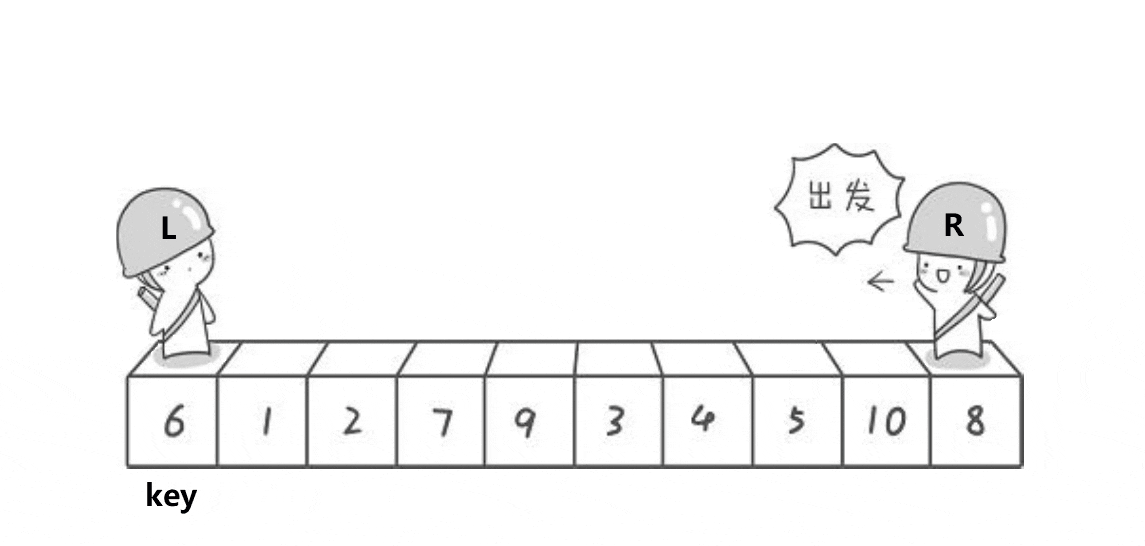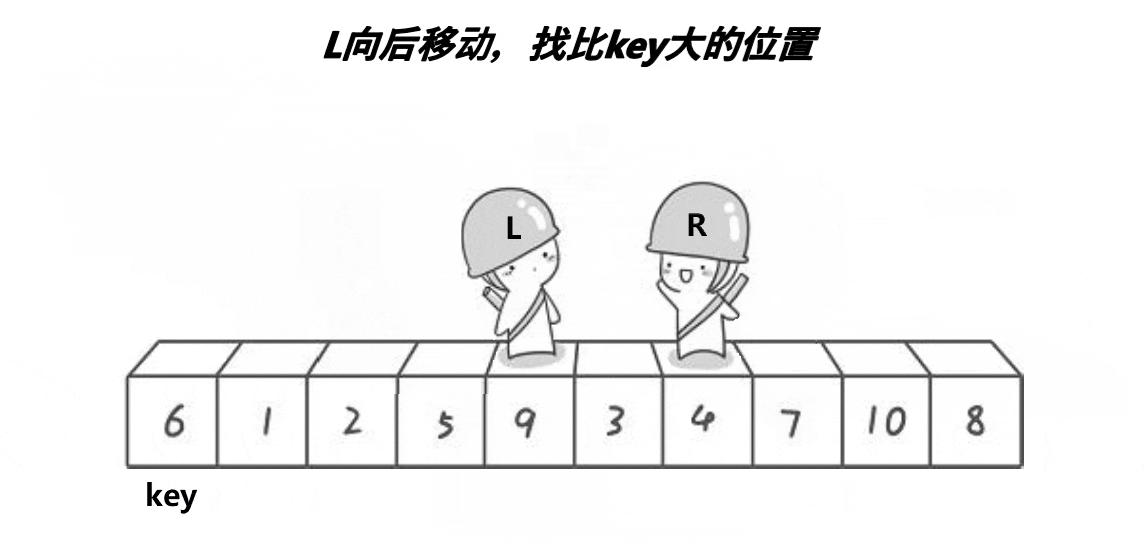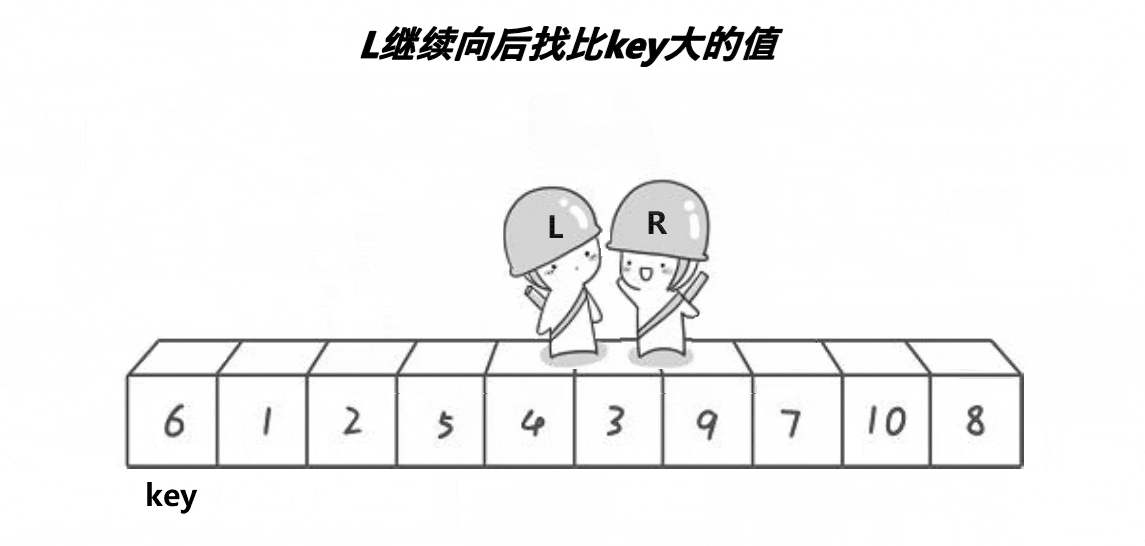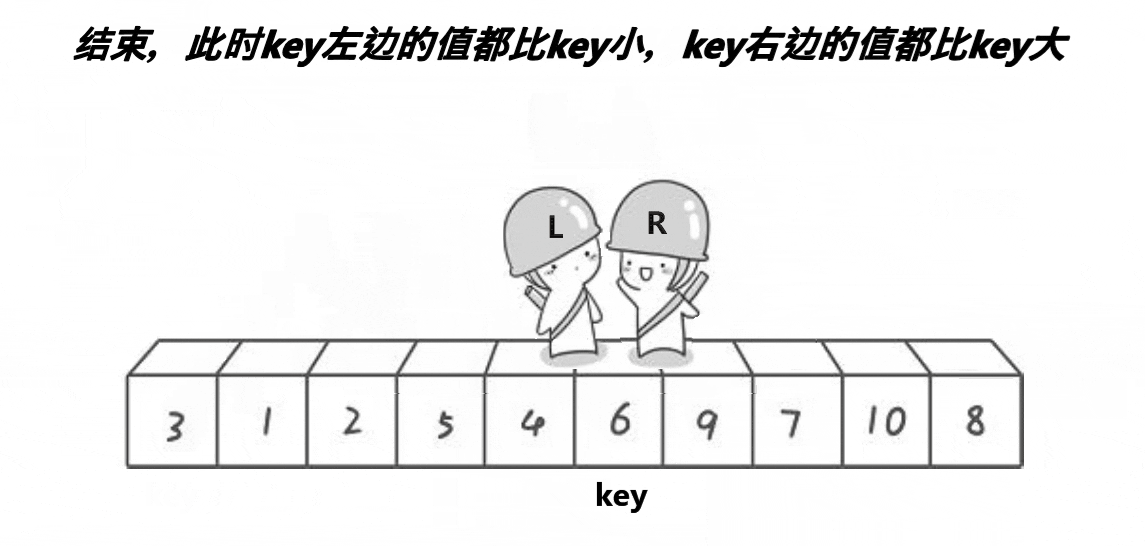
基本思路:
单趟排序,key一般选最左边或者最右边
★首先令key为最左边,右边先走找小,然后左边找大,然后交换位置继续,相遇则停止,相遇的值跟key对应的值交换
当左区间有序,右区间有序那整体就ok了,如果左右区间不有序,左右区间就是单趟的子问题
当区间只有一个值,就不排了,返回
代码展示:
//快速排序
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int left = begin;
int right = end;
int keyi = left;
while (left < right)
{
//右边先走,找小
while (left < right && a[right] >= a[keyi])
{
right--;
}
//左边找大
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
//相遇后随便一个下标,然后交换
Swap(&a[left], &a[keyi]);
keyi = left;
//左区间递归
QuickSort(a, begin, keyi - 1);
//右区间递归
QuickSort(a, keyi + 1, end);
}可能就有小伙伴问为什么是key为最左边时,右边先走,最右边做key时,左边先走
原因是左边做key时,右边先走,可以保证相遇位置比key要小
此时有两种情况:
1.相遇时,left停住,right遇到left,相遇的位置是left停住的位置
2.相遇时,right停住,left遇到right,相遇的位置是right停住的位置
单趟排序的意义
1.分割出左右区间,左区间比key小,右区间比key大
2.key到了正确位置(排序后的最终位置)
优化方案:
三数取中:
在前面的快速排序中,
在理想情况下,我们每次进行完单趟排序后,key的左序列与右序列的长度都相同:
若每趟排序所选的key都正好是该序列的中间值,即单趟排序结束后key位于序列正中间,那么快速排序的时间复杂度就是O(NlogN)。

但事实上可能会遇到极端情况:就是我们每次取到的都是最大值或者最小值,那么快排的时间复杂度达到最低O(N^2)
那这样就和插入排序、冒泡排序时间复杂度一样了

这种情况下,快速排序的时间复杂度退化为O(N^2)。其实,对快速排序效率影响最大的就是选取的key,若选取的key越接近中间位置,则效率越高。
为了避免这种极端情况的发生,于是出现了三数取中:
三数取中,当中的三数指的是:最左边的数、最右边的数以及中间位置的数。三数取中就是取这三个数当中,值的大小居中的那个数作为该趟排序的key。这就确保了我们所选取的数不会是序列中的最大或是最小值了。
代码实现:
//三数取中
int GetmidIndex(int* a, int begin, int end)
{
int mid = (begin + end) / 2;
// a[begin] a[mid] a[end]
// a[begin[ < a[mid[
if (a[begin] < a[mid])
{
//a[begin] < a[mid] < a[end]
if (a[mid] < a[end])
{
return mid;
}
//a[mid] > a[end] 再次判断
else if (a[begin] > a[end])
{
return begin;
}
else
{
return end;
}
}
// a[begin] > a[mid]
else
{
//a[mid] > a[end]
if (a[mid] > a[end])
{
return mid;
}
//a[mid] < a[end]
else if (a[begin] < a[end])
{
return begin;
}
else
{
return end;
}
}
}
完整快速排序代码:
//Hoare 版本
int PartSort1(int* a , int begin , int end)
{
int mid = GetmidIndex(a, begin, end);
Swap(&a[begin], &a[mid]);
int left = begin;
int right = end;
int keyi = left;
while (left < right)
{
//右边先走,找小
while (left < right && a[right] >= a[keyi])
{
right--;
}
//左边找大
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
//相遇后随便一个下标,然后交换
Swap(&a[left], &a[keyi]);
keyi = left;
return keyi;
}
//快速排序
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
if ((end - begin + 1) < 15)
{
//小区间用直接插入排序,减少递归调用次数
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = PartSort1(a, begin, end);
//左区间递归
QuickSort(a, begin, keyi - 1);
//右区间递归
QuickSort(a, keyi + 1, end);
}
}挖坑法:
基本思想:
挖坑法的思想很简单:
一开始先将left下标对应的值保存起来,然后left位置空出来的位置就是一个坑位,右边先走,找大,找到后将右边的值的数据填进去,这个right的位置就是新的坑,左边找小,再将左边找到的填进坑位,这个left对应下标的位置就是新的坑位,最后left和right一定会在坑的位置相遇
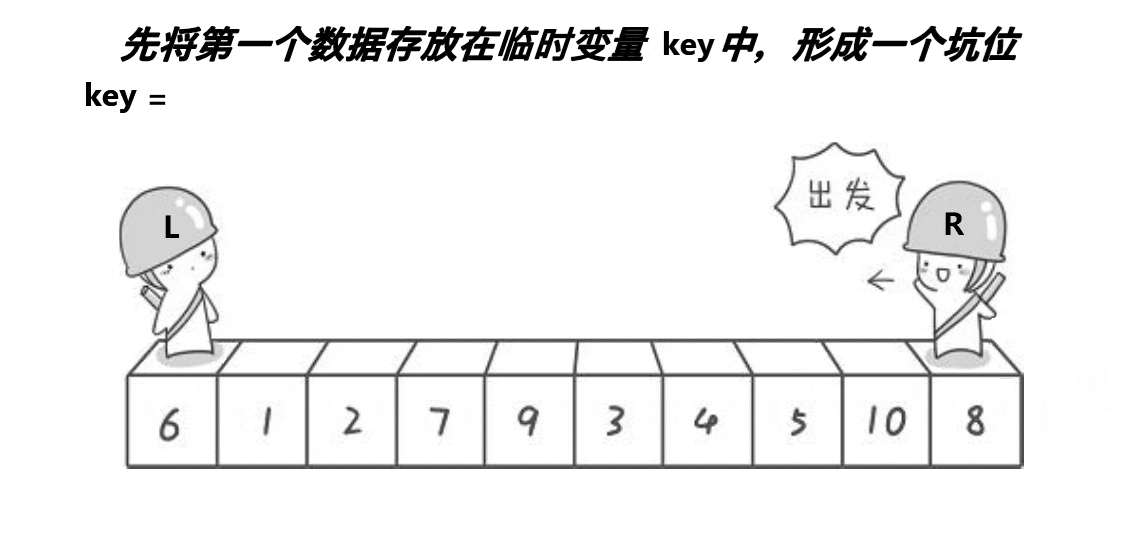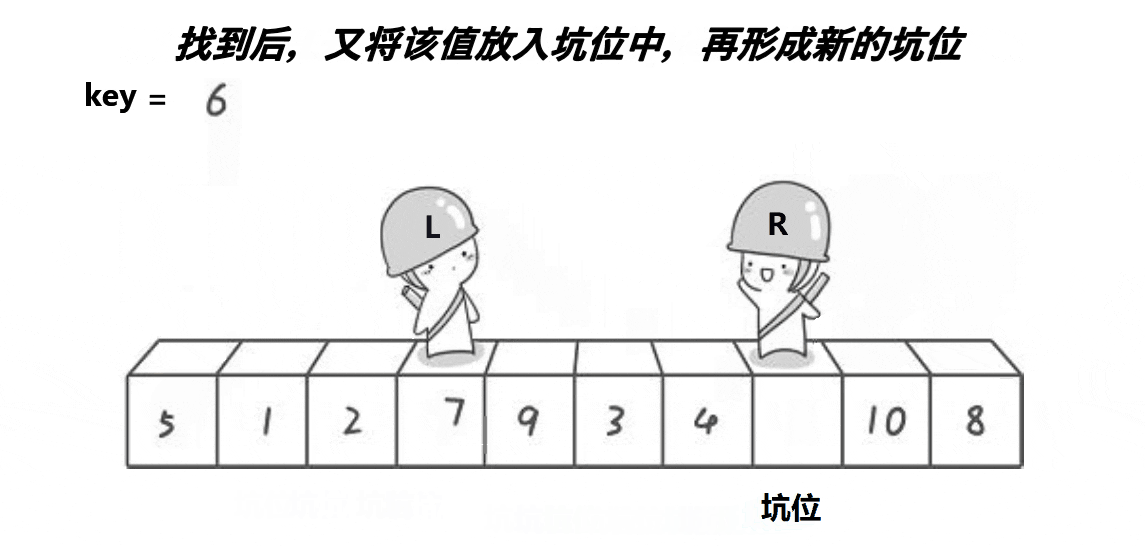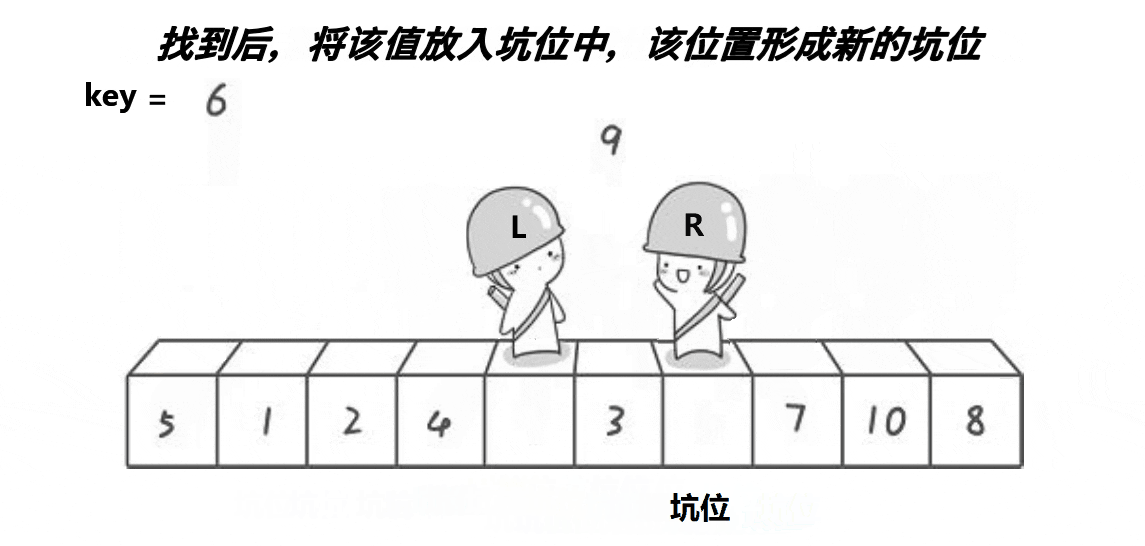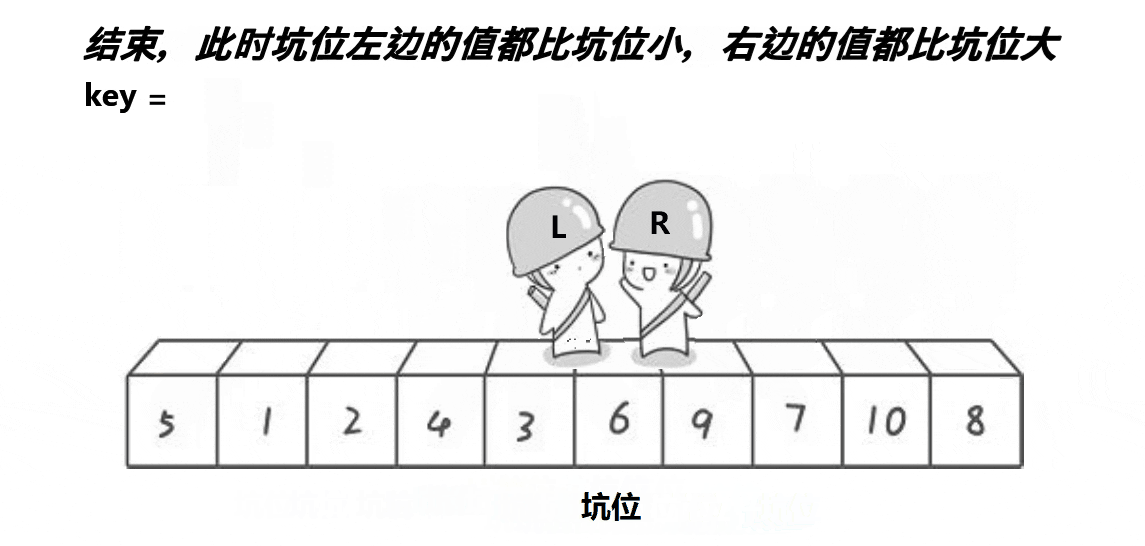
代码展示:
//挖坑法
int PartSort2(int* a, int begin, int end)
{
int mid = GetmidIndex(a, begin, end);
Swap(&a[begin], &a[mid]);
int left = begin;
int right = end;
int key = a[left];
int hole = left;
while (left < right)
{
//右边先走,找小于key的
while (left < right && a[right] >= key)
{
right--;
}
a[hole] = a[right];
hole = right;
//左边找大于key的;
while (left < right && a[left] <= key)
{
left++;
}
a[hole] = a[left];
hole = left;
}
a[hole] = key;
return hole;
}
//快速排序
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
if ((end - begin + 1) < 15)
{
//小区间用直接插入排序,减少递归调用次数
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = PartSort2(a, begin, end);
//左区间递归
QuickSort(a, begin, keyi - 1);
//右区间递归
QuickSort(a, keyi + 1, end);
}
}前后指针法:
动图演示:
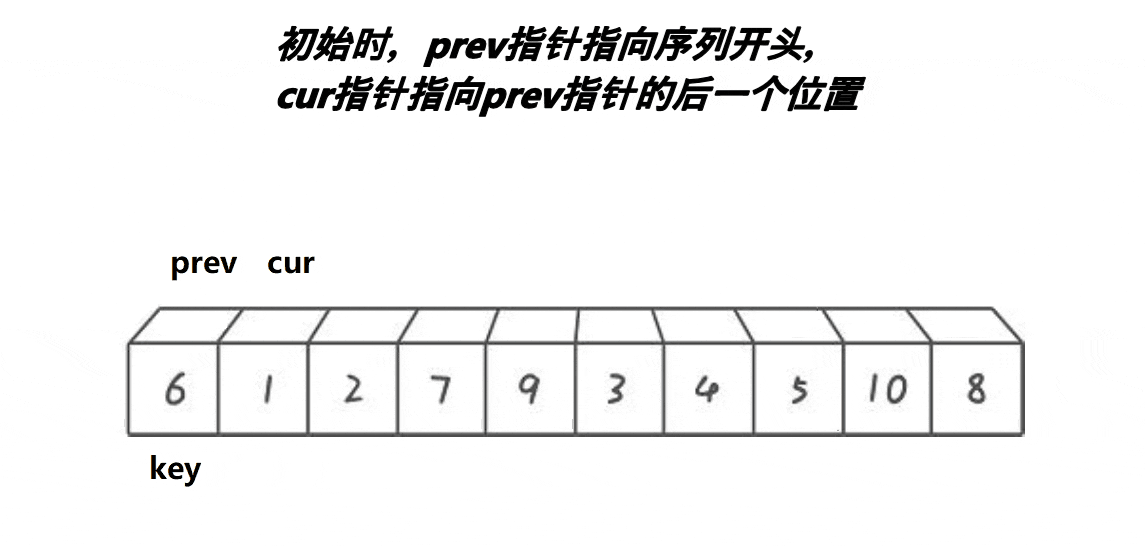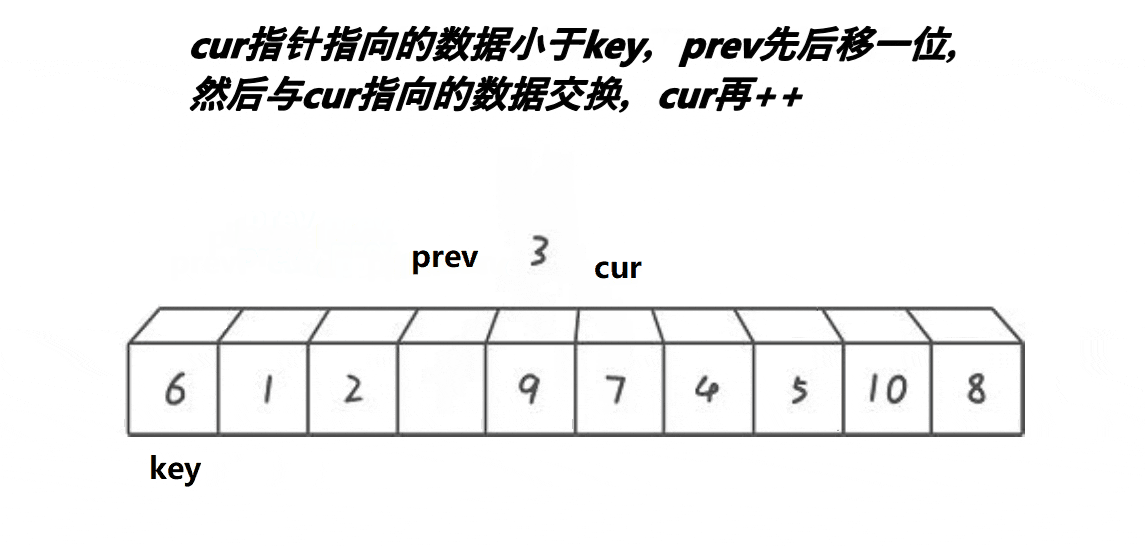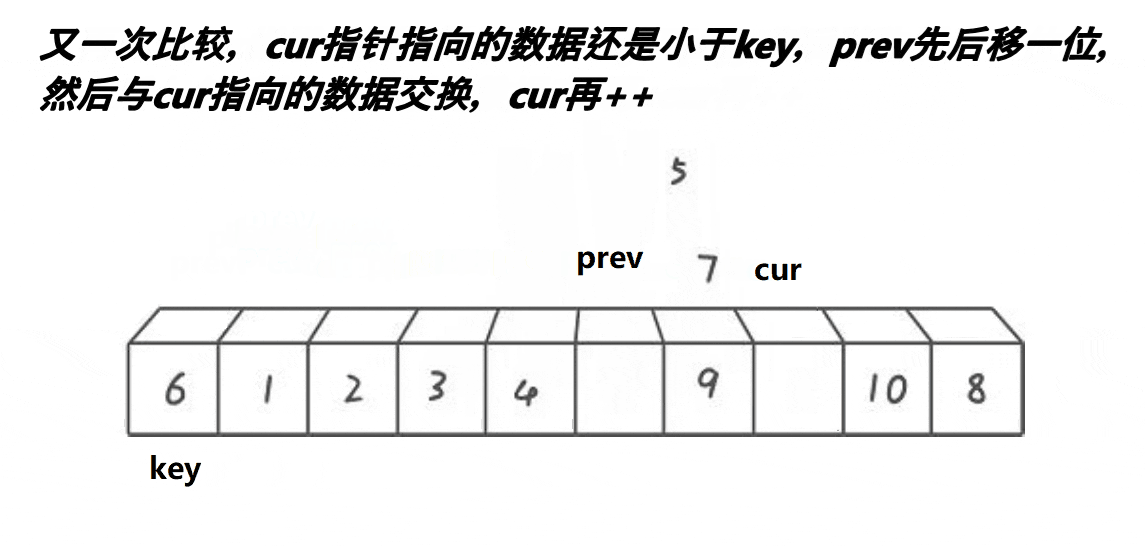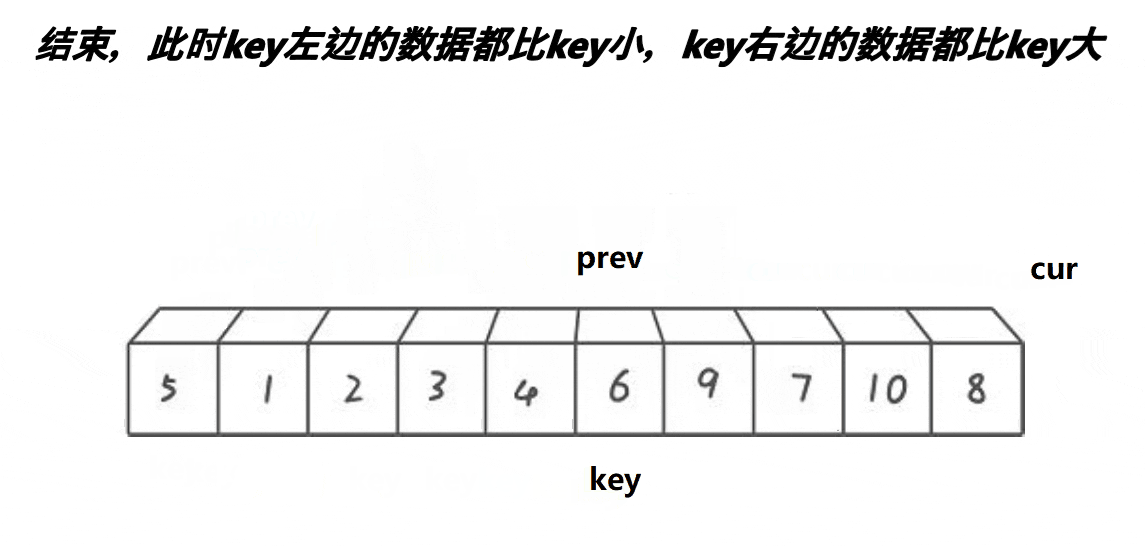
基本思路:
1、cur下标对应的值找比key小的,找到后停下来
2、然后++prev, 交换prev位置和cur位置的值最后重复上述操作
时间复杂度:O(NlogN)
//前后指针法
int PartSort3(int* a, int begin, int end)
{
int prev = begin;
int cur = begin + 1;
int keyi = begin;
while (cur <= end)
{
//cur 先走
if (a[cur] <= a[keyi] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
//快速排序
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
if ((end - begin + 1) < 15)
{
//小区间用直接插入排序,减少递归调用次数
InsertSort(a + begin, end - begin + 1);
}
else
{
int keyi = PartSort3(a, begin, end);
//左区间递归
QuickSort(a, begin, keyi - 1);
//右区间递归
QuickSort(a, keyi + 1, end);
}
}非递归写法:
基本思路:
借用栈来实现
通过非递归的方式实现递归的情况的话,快速排序递归是先排左区间再排右区间,以此类推,因此写非递归我们就需要反过来,因为栈是后入先出的。
借助栈的内存结构让先入的后出,所以要先压begin再压end,取出来的话就是先出end再出begin,然后先排右区间顺序再排左区间顺序。
代码实现:
//前后指针法
int PartSort3(int* a, int begin, int end)
{
int prev = begin;
int cur = begin + 1;
int keyi = begin;
while (cur <= end)
{
//cur 先走
if (a[cur] <= a[keyi] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[prev], &a[keyi]);
keyi = prev;
return keyi;
}
//快速排序(非递归)
void QuickSortNonR(int* a, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
int right = StackTop(&st);
StackPop(&st);
int left = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(a, left, right);
// [left , keyi-1] keyi [keyi+1 , right]
if (keyi + 1 < right)
{
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
if (keyi - 1 > left)
{
StackPush(&st, left);
StackPush(&st, keyi - 1);
}
}
StackDestroy(&st);
}🤦♂️归并排序:
递归算法:
基本思想:
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤:
动图演示:


代码实现:
void _MergeSort(int* a ,int begin ,int end,int* tmp)
{
if (begin >= end)
return;
int mid = (begin + end) / 2;
//[begin , mid] [ mid +1 , end] 递归子区间有序
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
//归并
int begin1 = begin;
int end1 = mid;
int begin2 = mid + 1;
int end2 = end;
int i = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}
//归并排序
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc: fail ");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}非递归算法:
非递归算法需要注意的是越界问题:
1.end1越界 begin2越界end2越界
2.begin2越界end2越界
3.end2越界
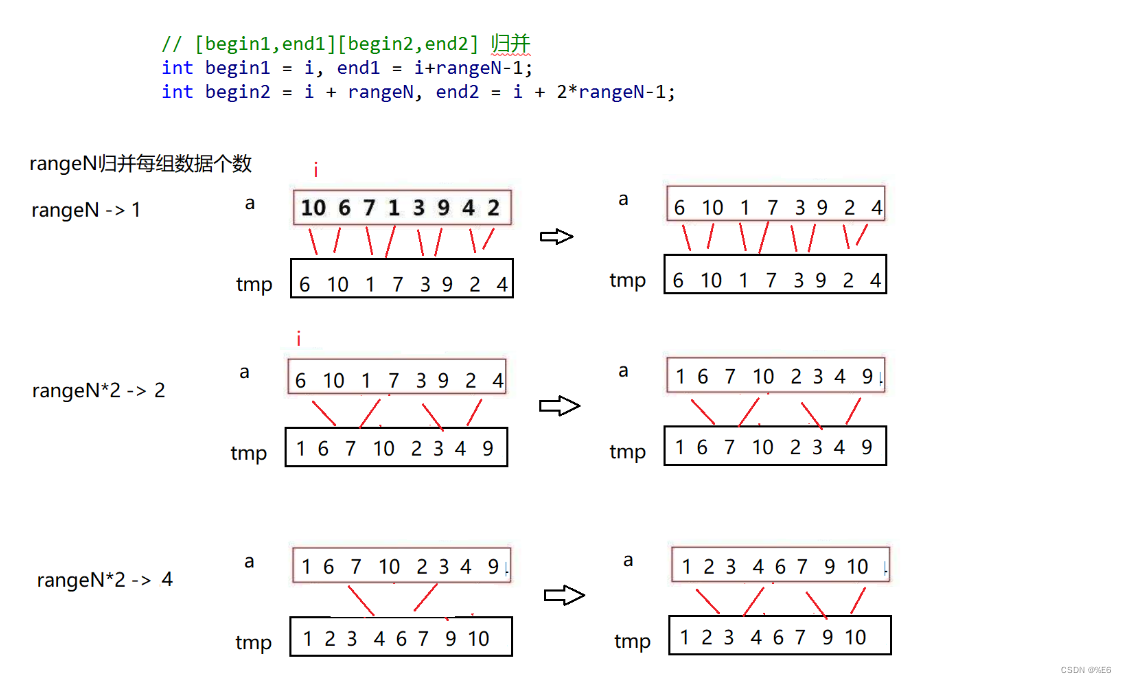
代码实现:
//归并非递归排序
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc: fail ");
exit(-1);
}
// 归并每组数据个数,从1开始,
//因为1个认为是有序的,可以直接归并
int rangeN = 1;
while (rangeN < n)
{
for (int i = 0; i < n; i += 2 * rangeN)
{
// [begin1,end1] [begin2,end2] 归并
int begin1 = i;
int end1 = i + rangeN - 1;
int begin2 = i + rangeN;
int end2 = i + 2 * rangeN - 1;
int j = i;
//end1越界
if(end1 >=n)
{
end1 = n - 1;
begin2 = n;
end2 = n - 1;
}
//begin2 , end2越界
else if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
//end2越界
else if (end2 >= n)
{
end2 = n - 1;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
rangeN *= 2;
}
free(tmp);
tmp = NULL;
}归并排序总结:
归并排序的特性总结:
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
😢计数排序:
计数排序是一种非比较排序。它的主要思想是建立一个临时数组 CountArr ,用来统计序列中每个元素出现的次数,
例如若序列元素 n 一共出现了 m 次,则使 CountArr [n] = m;统计完毕后。根据统计的结果,将序列按顺序插入到原数组中即完成排序。

代码实现:
//计数排序
void CountSort(int* a, int n)
{
int max = a[0], min = a[0];
//找出最大值,最小值
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
min = a[i];
if (a[i] > max)
max = a[i];
}
//开一个数组
int range = max - min + 1;
int* countArr = (int*)calloc(range, sizeof(int) * range);
if (countArr == NULL)
{
perror("calloc fail");
exit(-1);
}
//1.统计次数
for (int i = 0; i < n; ++i)
{
countArr[a[i] - min]++;
}
//2.排序
int k = 0;
for (int i = 0; i < range; ++i)
{
while (countArr[i]--)
{
a[k++] = i + min;
}
}
free(countArr);
}











![【PWN刷题__ret2syscall】[Wiki] ret2syscall](https://img-blog.csdnimg.cn/9559d7bdc9bc40bea2e6c5c65c9f5ec1.png)
