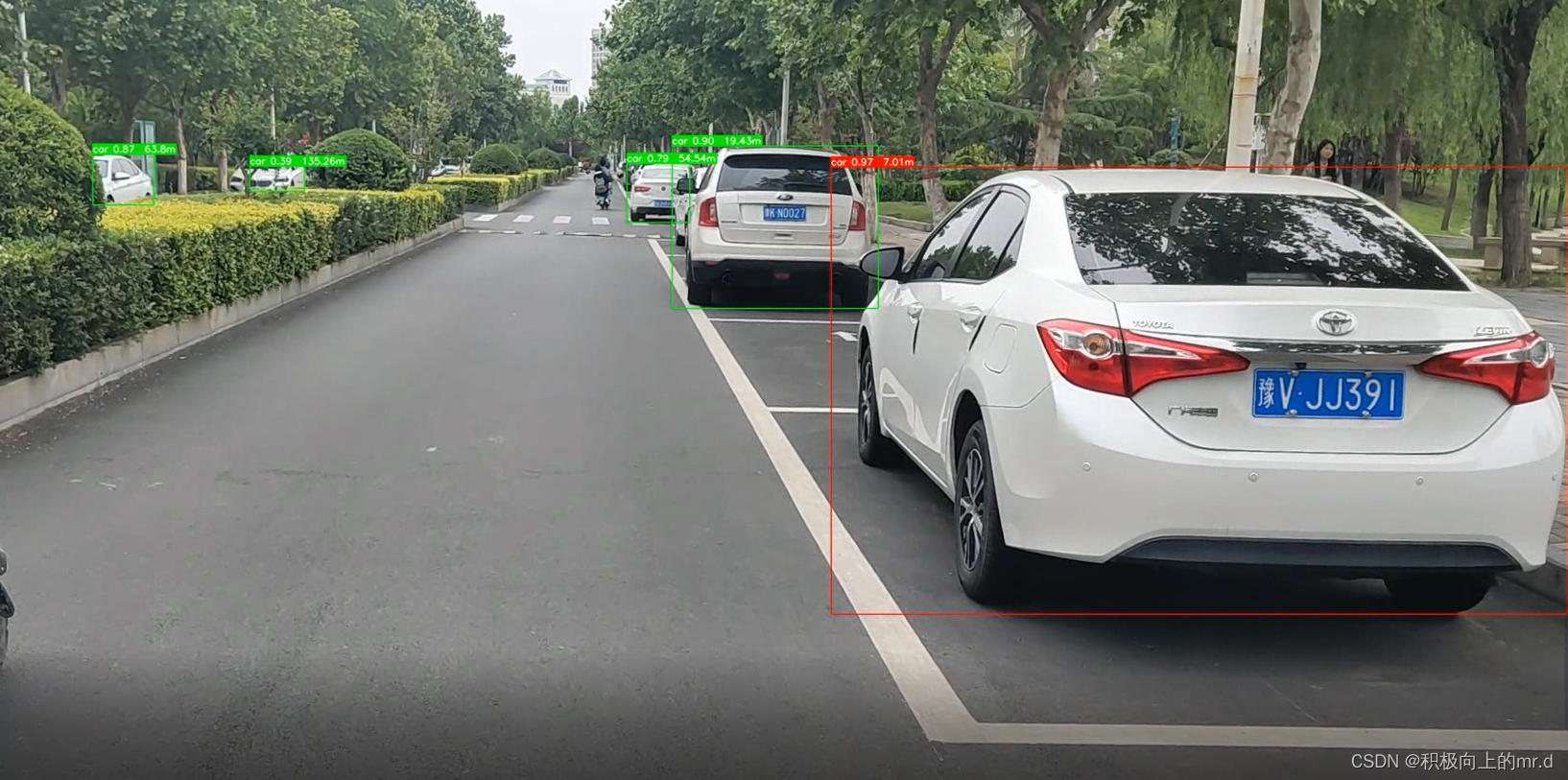
将用户输入与预定义的领域进行匹配
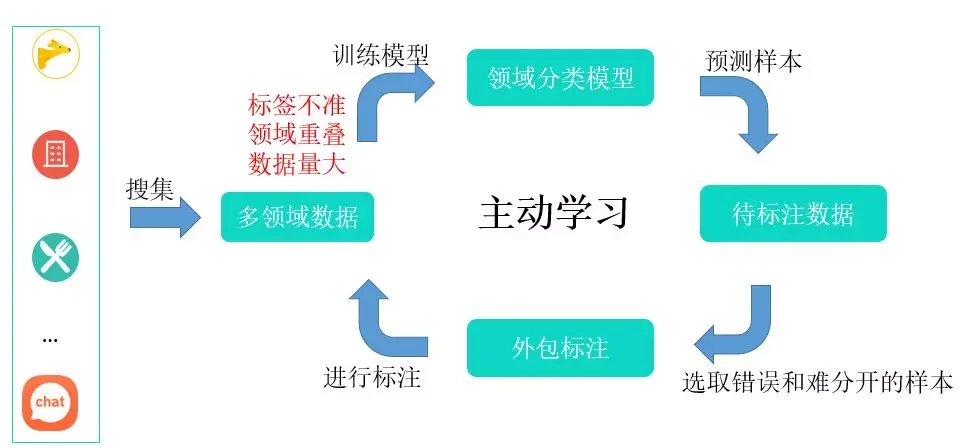
针对领域分类任务,如上图所示,我们首先会从不同的业务中收集大量的业务数据,作为基础的训练数据,虽然这些数据来自不同的业务,但是依然存在一些问题,主要有以下两方面:
- 标签不准:用户有可能会在某个业务对话中提问其它领域的问题;
- 领域重叠:某些问题可能会在多个领域中出现。
所以,原始数据不能直接拿来作为训练数据,必须要经过人工筛选和标注方可使用。
当前方案:https://git.longhu.net/yuanzihan/it_domain
- 用分类模型训,目标是这个query属于哪个baseCode,保存编码模型;
- 计算domainEmb:同一领域下所有主问题emb beding的平均作为类中心;
- 预测时,计算 query 跟 domainEmb 的cosin相似度,返回分值大于 domainEmbThreshold 的结果
-----> 106
source activate whenv
-----> 144
source activate yzh
----->
cd /data/ningshixian/work/new-it-domain
# 0、根据 sql.txt 拉取 data.csv 和 IT所有basecode.csv
# 1、数据增强
python 221209_data_aug.py
# 2、训练分类模型 BERT+MLP
python 221209_cw_classifier.py --batch_size 128 --total_epoch 20 --gpu_id 0
# 3、计算类向量,并存入ES(记得修改es连接环境)
python 221209_es_index_update.py
# 起emb服务(记得端口修改20193→20190)
nohup python emb_server.py > emb.log 2>&1 &
# 起定时更新任务
nohup python new_class_emb_update.py > task.log 2>&1 &
----->
起emb服务;PROD的话是这个:
PROD:
nohup python emb_server.py -e pre -ap /etc/apollo/apollo_private_key -ak 7f3251a5-4e15-4542-84be-cd99e9f6ba54 -at 41581c4771d2c39ba9eff7f644d99eb21824c529 --apollo_app_id=aicare --apollo_uri=https://apolloconfig.longhu.net --apollo_namespace=nlu_domain --apollo_cluster=prod --model_path=chatbot/nlu-domain/prod/model/1027_cw_model_1 > emb.log 2>&1 &
PROD的服务器应该是
http://10.9.192.144:20190/embedding
SIT:
nohup python emb_server.py -e sit -ap /etc/apollo/apollo_private_key -ak 26f577d6-1d6c-48d8-b355-5029337c2c69 -at 4324dcafc46201ce85772250b583050df8f37de1 --apollo_app_id=aicare --apollo_uri=http://apolloconfig.longfor.sit/ --apollo_namespace=nlu_domain --apollo_cluster=sit --model_path=chatbot/nlu-domain/prod/model/1027_cw_model_1 > emb.log 2>&1 &
SIT的服务器应该是
http://10.231.135.106:20193/embedding优化方案:
- 根据用户的历史信息和上下文来进行更加精准的领域识别 --
- 单标签多分类任务:在模型的最后用一个全连接层输出每个类的分数,然后用softmax激活并用交叉熵作为损失函数。只能学习从n个候选类别中选1个目标类别×
- 多标签分类:
-
- 将“softmax+交叉熵”推广到多标签分类问题。n个二分类 → Circle Loss,解决类别不均衡问题。需标注,费时费×
- 多标签二分类方法:将每个标签视为一个二元分类任务,将每个标签的预测结果独立计算,最终将所有标签的预测结果组合起来得到最终的预测结果 ̄□ ̄
- 多输出模型方法:使用一个深度神经网络来直接预测所有标签,输出层有多个节点,每个节点对应一个标签。此方法可以同时优化所有标签的预测结果,相比其他方法具有更高的预测精度。但针对仅一个标签情况下,可能会导致倾向于某一类领域;√
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=input_shape))
model.add(Dense(num_labels, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit(x_train, y_train, epochs=10, batch_size=64)
y_pred = model.predict(x_test)
y_pred = (y_pred > 0.5).astype(int)- 向量相似度匹配:√
-
- 多分类任务训练,保存编码模型,最后向量相似度检索;
- 度量学习的 Classification-based 思路,存储压力大;
二分类器集成学习代码示例:
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
# 生成一个二分类数据集
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2)
# 将标签转化为 one-hot 编码
y = to_categorical(y)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 定义一个基础模型,包含 3 个全连接层
def create_model(input_dim, output_dim):
model = Sequential()
model.add(Dense(32, input_dim=input_dim, activation='relu'))
model.add(Dense(16, activation='relu'))
model.add(Dense(output_dim, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
# 定义一个集成模型,包含多个二分类器
def create_ensemble_models(n_models, input_dim, output_dim):
models = []
for i in range(n_models):
model = create_model(input_dim, output_dim)
models.append(model)
return models
# 训练集成模型
def train_ensemble_models(models, X_train, y_train, epochs, batch_size):
for model in models:
model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=0)
# 预测测试集并返回集成结果
def predict_ensemble_models(models, X_test):
y_preds = []
for model in models:
y_pred = model.predict(X_test)
y_preds.append(y_pred)
return np.mean(y_preds, axis=0)
# 创建集成模型
n_models = 5
input_dim = X_train.shape[1]
output_dim = y_train.shape[1]
models = create_ensemble_models(n_models, input_dim, output_dim)
# 训练集成模型
epochs = 10
batch_size = 32
train_ensemble_models(models, X_train, y_train, epochs, batch_size)
# 预测测试集并计算准确率
y_pred_ensemble = predict_ensemble_models(models, X_test)
y_pred_ensemble = np.argmax(y_pred_ensemble, axis=1)
y_test = np.argmax(y_test, axis=1)
accuracy = accuracy_score(y_test, y_pred_ensemble)
print("Ensemble model accuracy: {:.2f}%".format(accuracy * 100))