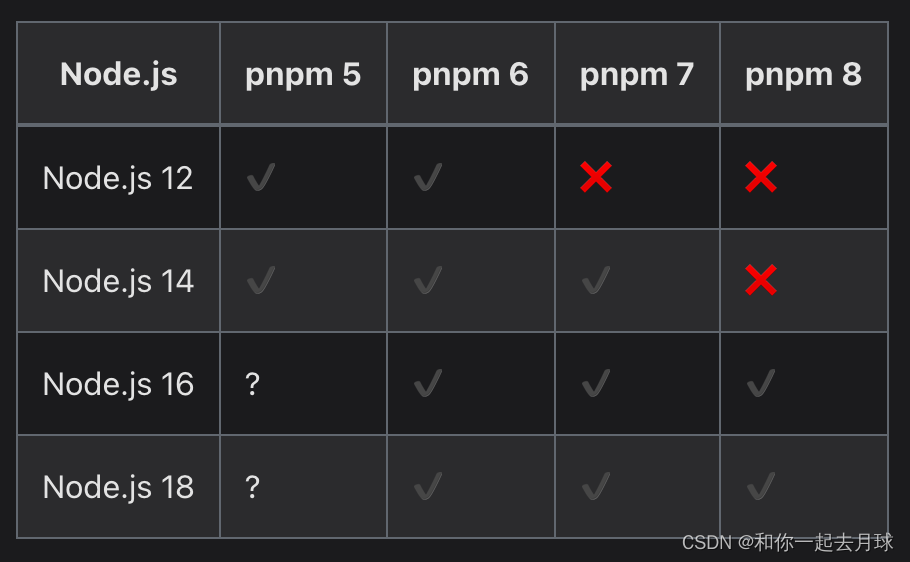
文章目录
- 一、前言
- 二、试玩效果
- 三、研究背景
- 四、模型结构
- 五、Pre-training objectives
- 六、CapFilt架构
- 七、Experiment
- 八、结论
一、前言
今天我们要介绍的论文是 BLIP,论文全名为 Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation。

论文地址为:
https://arxiv.org/pdf/2201.12086.pdf
代码地址为:
https://github.com/salesforce/BLIP
试玩地址为:
https://huggingface.co/spaces/akhaliq/BLIP
在开始正文之前,我们不妨先来试试试玩的效果如何。
二、试玩效果
BLIP 的效果如何呢?用户只需上传一张图像,或单击内置示例加载图像就可完成。
BLIP 模型具有两个功能:
- 图像标注
- 回答问题
BLIP 的 Gradio 演示:用于统一视觉-语言理解和生成的引导语言-图像预训练(Salesforce 研究)。 从 2023 年 3 月 23 日起,现在已禁用图像上传。单击其中一个示例以加载它们:
上传著名油画《星夜》,在图像标注功能下模型输出「caption: a painting with many clouds above the city」。
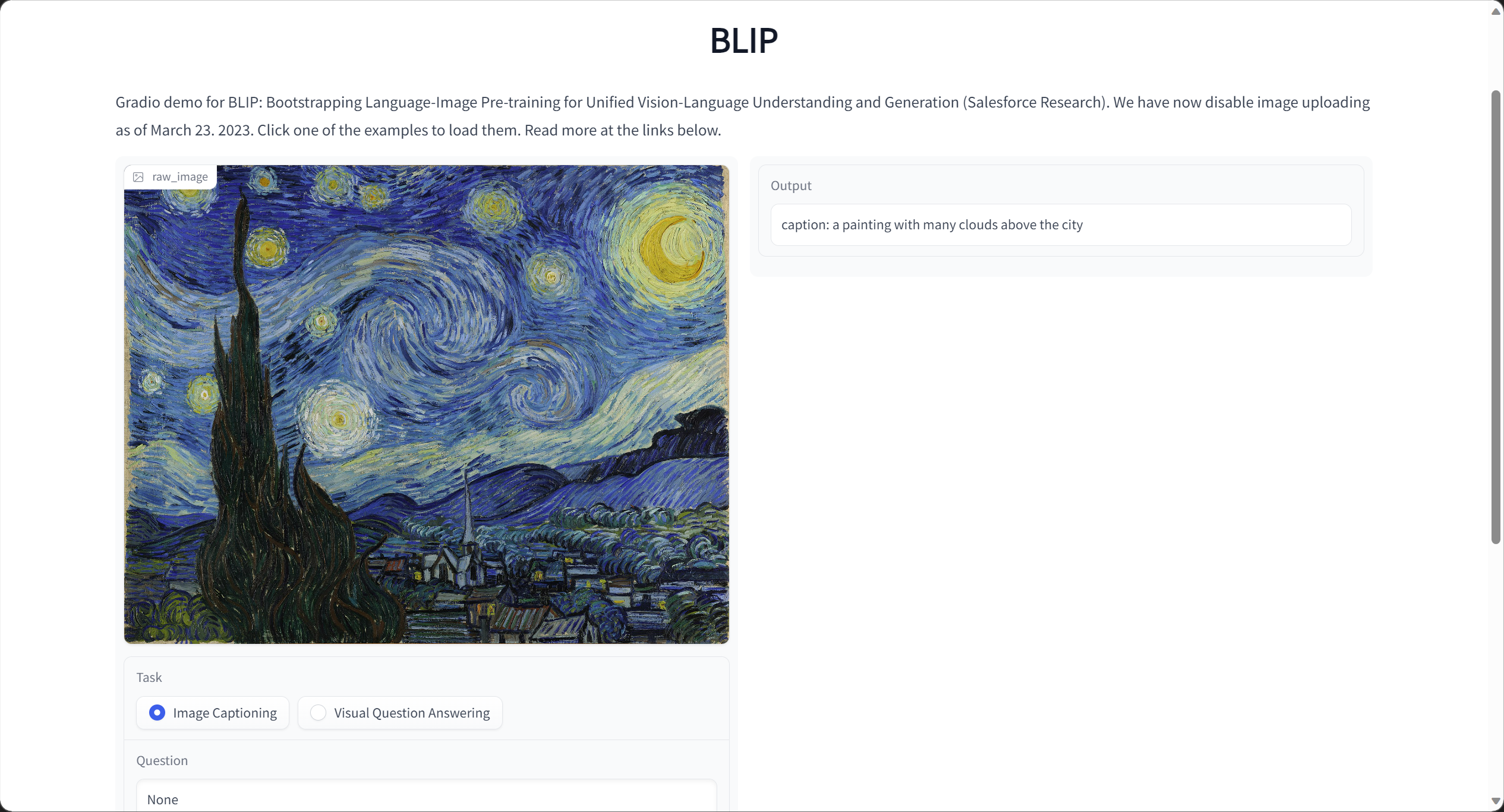
我们看一下之前其他博主测试的一些效果:
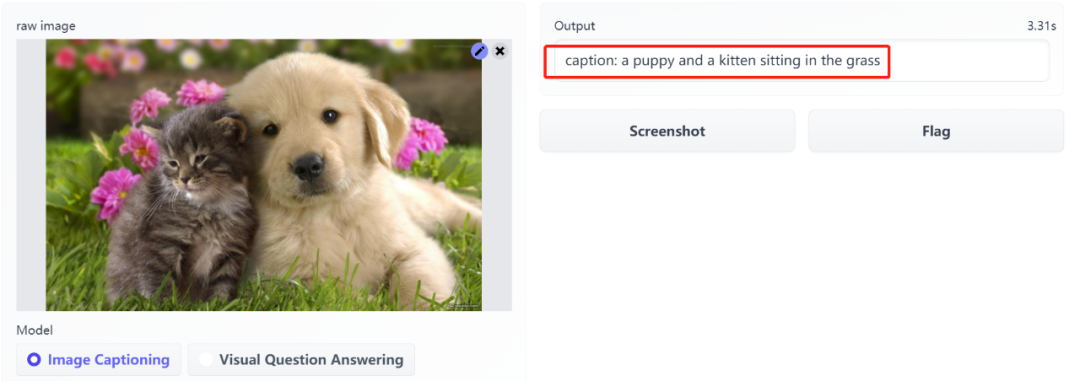

根据试玩效果来看还是不错的。
三、研究背景
视觉 - 语言预训练 (Vision-Language Pre-training,VLP) 提高了许多视觉 - 语言任务的性能。然而,大多数现有的预训练模型只能在基于理解任务(understanding-based tasks)或基于生成任务(generation-based tsaks)中表现出色。
但很少在这两方面都能取得较好的结果。
现有的 VLP 方法主要存在两个局限性:
- 从模型角度来讲,大多数方法采用基于编码器的模型,或者采用基于编码器 - 解码器模型。然而,基于编码器的模型很难直接转换到文本生成任务中,而编码器 - 解码器模型还没有成功地用于图像 - 文本检索任务;
- 从数据角度来讲,像 CLIP、SimVLM 等 SOTA 模型通过在 web 上收集的图像 - 文本对进行预训练,尽管扩大数据集获得了性能提升,但 web 上的文本具有噪声,对 VLP 来说并不是最优。
近日,来自 Salesforce Research 的研究者提出了 BLIP(Bootstrapping Language-Image Pre-training),用于统一视觉 - 语言理解和生成任务。
BLIP 是一个新的 VLP 框架,可以支持比现有方法更广泛的下游任务。
BLIP 通过自展标注(bootstrapping the captions),可以有效地利用带有噪声的 web 数据,其中标注器(captioner)生成标注,过滤器(filter)去除有噪声的标注。
该研究在视觉 - 语言任务上取得了 SOTA 性能,例如在图像 - 文本检索任务上, recall@1 提高 2.7%;在图像标注任务上,CIDEr 提高 2.8%、VQA 提高 +1.6%。
当将 BLIP 以零样本的方式直接迁移到视频 - 语言任务时,BLIP 也表现出很强的泛化能力。
四、模型结构
研究者提出的 BLIP 是一个统一的视觉语言预训练(vision-language pre-training, VLP)框架,从有噪声的图像文本对中学习。
接下来详细解读模型架构 MED(mixture of encoder-decoder)、它的预训练目标以及用于数据集自展的方法 CapFilt。
下图为 BLIP 的预训练模型架构和目标:
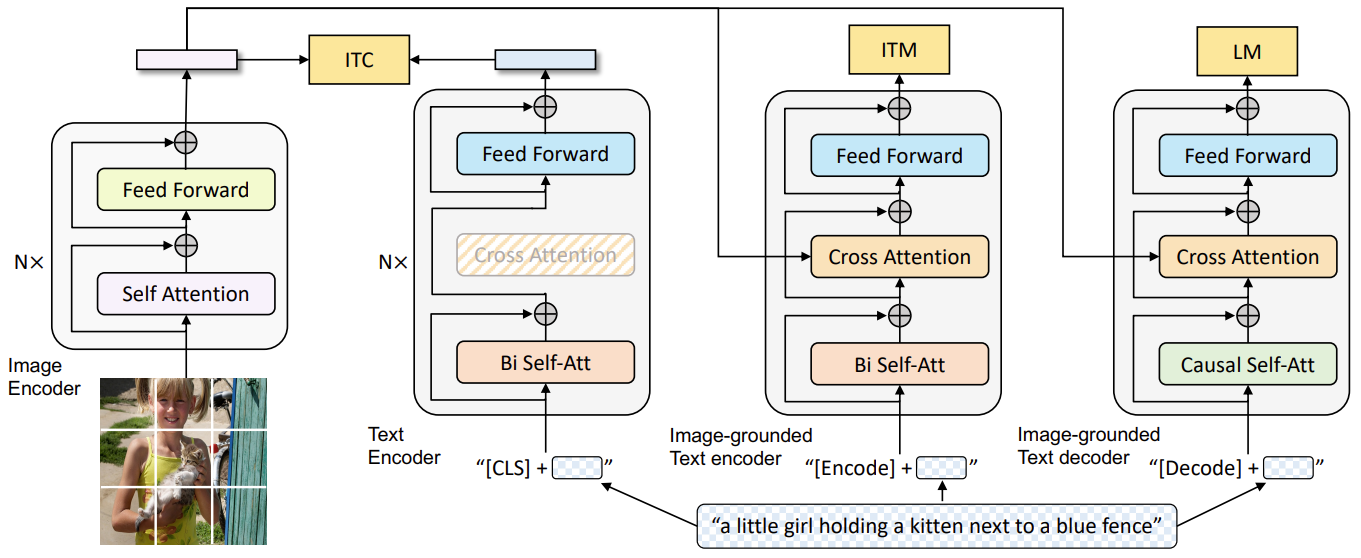
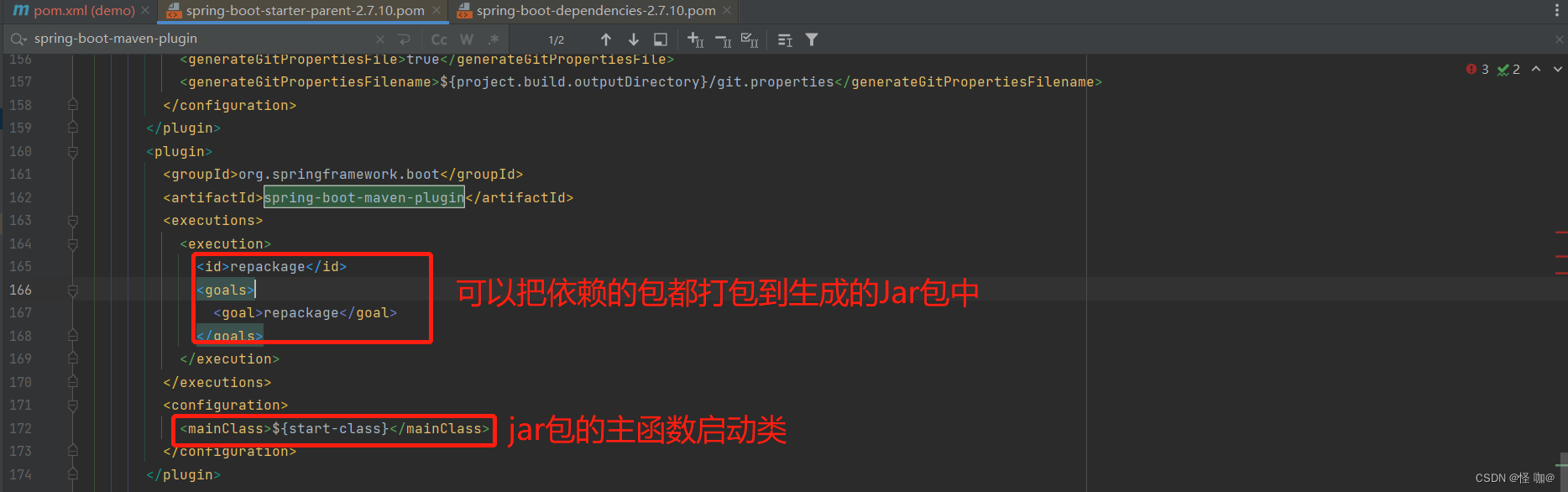
BLIP 采用 Visual Transformer 作为图像编码器,将输入的图像划分为 patch,然后将 patches 编码为一个 embedding 序列,并用一个额外的 [CLS] 标记来代表全局图像特征。与使用预训练的目标检测器进行视觉特征提取相比,使用 ViT 更便于计算,并且已经逐渐成为主流。
为了预训练一个具有理解和生成能力的统一模型,研究人员提出了多模态混合编码器-解码器(MED),能够用于多任务。
- 单模态编码器(Unimodal encoder),对图像和文本分别进行编码。文本编码器(text encoder)与 BERT 相同,在文本输入的开头附加一个 [CLS] 标记,以总结句子。
- 以图像为基础的文本编码器(Image-grounded text encoder),通过在自注意力(SA)层和前馈网络(FFN)之间为文本编码器的每个 Transformer 块插入一个额外的交叉注意力(CA)层来注入视觉信息。一个特定任务的 [Encode] 标记被附加到文本上,[Encode] 的输出 embedding 被用作图像-文本对的多模态表示。
- 以图像为基础的文本解码器(Image-grounded text decoder),用因果自注意力层(causal self-attention layer)替代编码器中的双向自注意力层。用 [Decode] 标记来表示一个序列的开始和结束。
显然,经由上述的三个模块,这个 MED 模型就拥有了同时匹配 generation-based tasks 和 understanding-based tasks 的能力。
五、Pre-training objectives
本文在 pre-training 的时候使用了三个 objectives,分别是两个 understanding-based objectives 和一个 generatin-based objectives。
- Image-Text Contrastive Loss (ITC):通过 contrastive learning 的思想,对齐视觉 transformer 和文本 transformer 的特征空间,目的是为了获得更加优质的 image 和 text 的 representation。
- Image-Text Matching Loss (ITM):旨在学习 image-text multimodal representation,来捕获视觉和语言的细粒度对齐。简单的来啊说就是图文匹配,最后输出一个二分类,positive or negative。
- Image-Text Matching Loss (ITM):三个 tasks 中的生成任务,为给定的图片生成对应的 description。广泛用于 VLP 的 MLM 损失相比,LM 使模型具有将视觉信息转换为连贯字幕的泛化能力。
六、CapFilt架构
由于大规模预训练的文本-图片对通常是从 web 上找出来的,该文本通常无法准确描述图像的视觉内容,从而使它们成为嘈杂的信号,对于学习视觉语言对齐不是最佳的。
由此,作者提出了一个 CapFilt 架构用来提高 image-text pair 的质量。
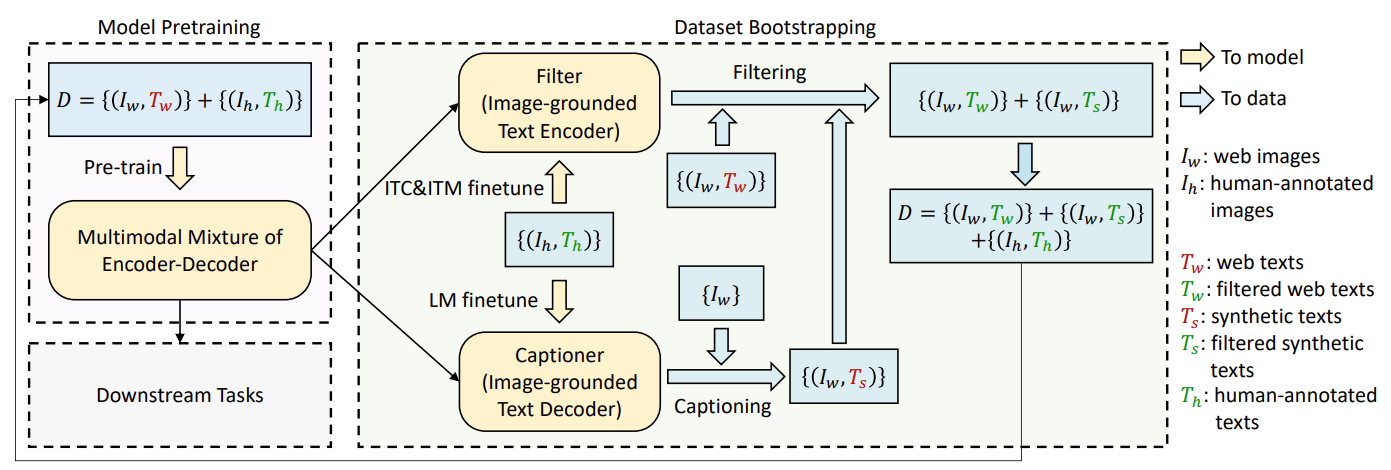
如上图所示,其中 I w I_w Iw和 T w T_w Tw代表 web image-text pair, ( I h , T h ) (I_h, T_h) (Ih,Th)代表高质量的手工标注的 image-text pair。
它引入了两个模块:一个基于 web 图像生成 caption 的 captioner ,以及一个用于去除 image-text pair 噪声的 filter。captioner 和 filter 都是从同一个预训练过的 MED 模型中初始化的,并在 COCO 数据集上单独微调。微调是一个轻量级的过程。
整个过程大概为:先进行 pre_train,之后利用 I h I_h Ih, T h T_h Th分别对 captioner 和 filter 进行 finetune,captioner 给定 web 图片生成对应的 caption,filter 利用ITM判断 web 图片-文字对和 web 图片-生成 caption 对是否 match,如果不 match,则过滤掉,最后将过滤后剩余的图片-文字对和 I h I_h Ih, T h T_h Th合在一起 pre_train 一个新 model。个人理解比较像一个新颖的 online self-knowledge distillation。
七、Experiment
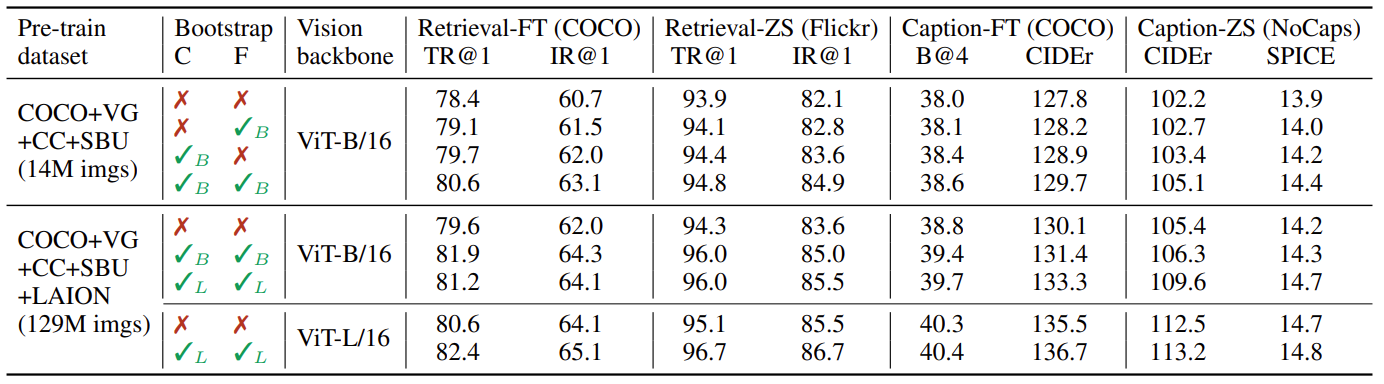
上图是提出的 captioner 和 filter 对最后结果的影响。

上图是 parameters sharing 策略对最后结果的影响。
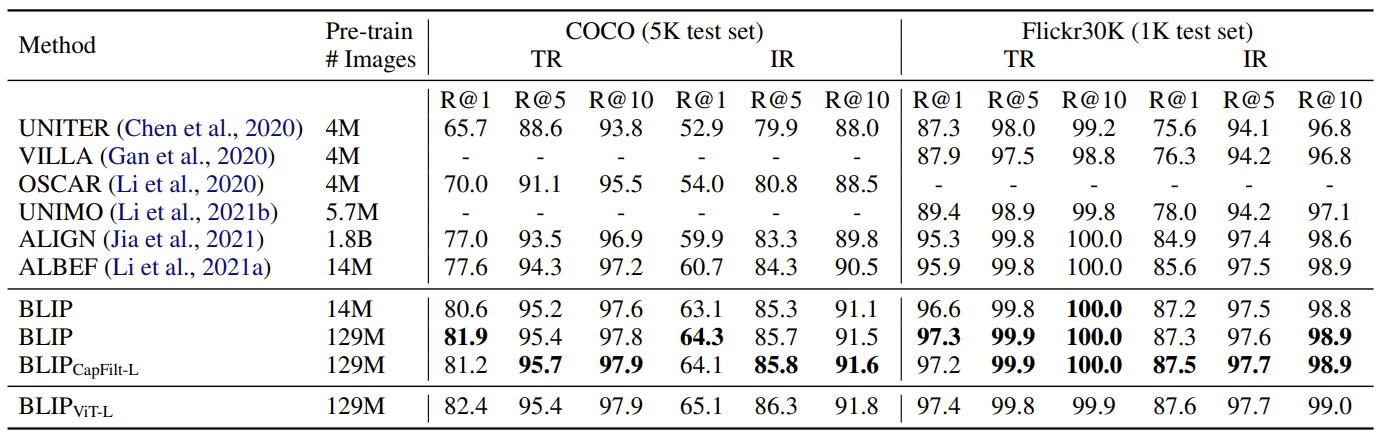
上图是 image-text retirval 中与其他 SOTA 任务的对比,可以看出有较大提升。
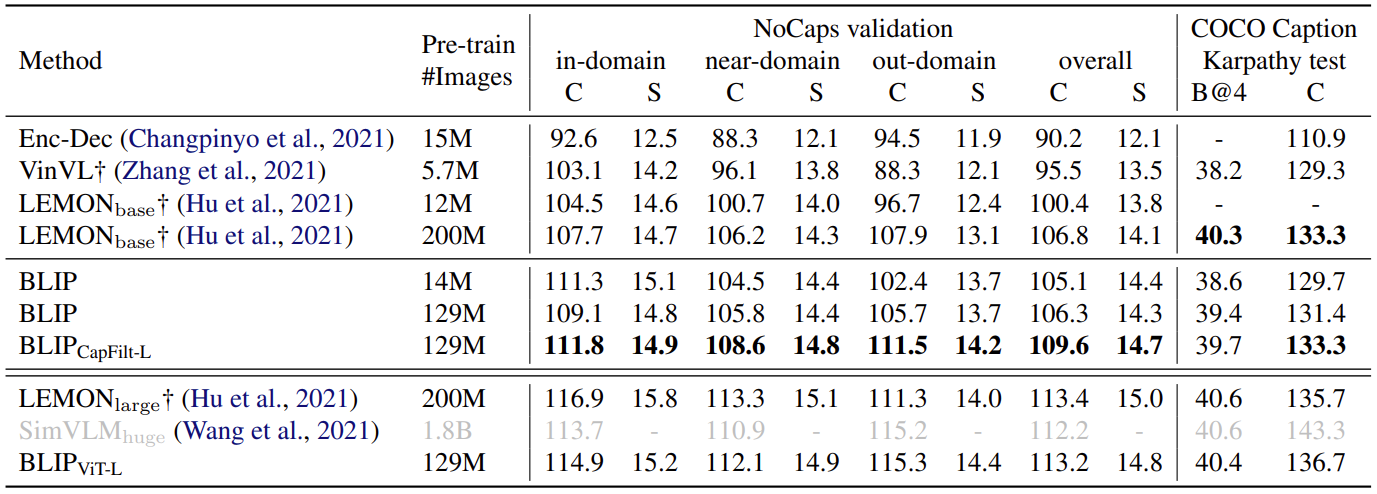
上图是与其他 image caption SOTA 方法的对比。
八、结论
作者提出的 BLIP 架构在大范围的 downstream 任务上达到了 SOTA 的效果,其中包括了 understanding-based tasks 和 generation-based tasks。同时模型使用了一种 dataset bootstrapping 的方法来解决 web 中收集的大量 noisy 数据的问题。
作者还提出有几个潜在的方法可能可以提高BLIP的性能:
- 进行多轮的 dataset bootstrapping
- 为每幅图片生成多个 caption,来扩大语料库
- 训练多个 captioner 和 filter,并进行 model ensemble