同质与异质
1.异质模型:把不同类型的算法集成在一起,基础模型要有足够大差异性(可以找出最适合当前数据的模型)
- 同质模型:通过一个基础算法生成的同类型学习器。
Boosting概念介绍¶
Boosting本意就是提升,这是一种刻意训练弱模型的肌肉将其提升为强学习模型的算法。
- Bagging独立生成N个相同基模型对预测结果进行集成(模型相同,但是训练数据有差异。而且是并行运算)
- Boosting持续通过新模型来优化同一个基准模型,新模型的训练,将一直聚焦于之前的模型的误差点(出错样本权重高),目标是不断减少模型的预测误差(串型运算)
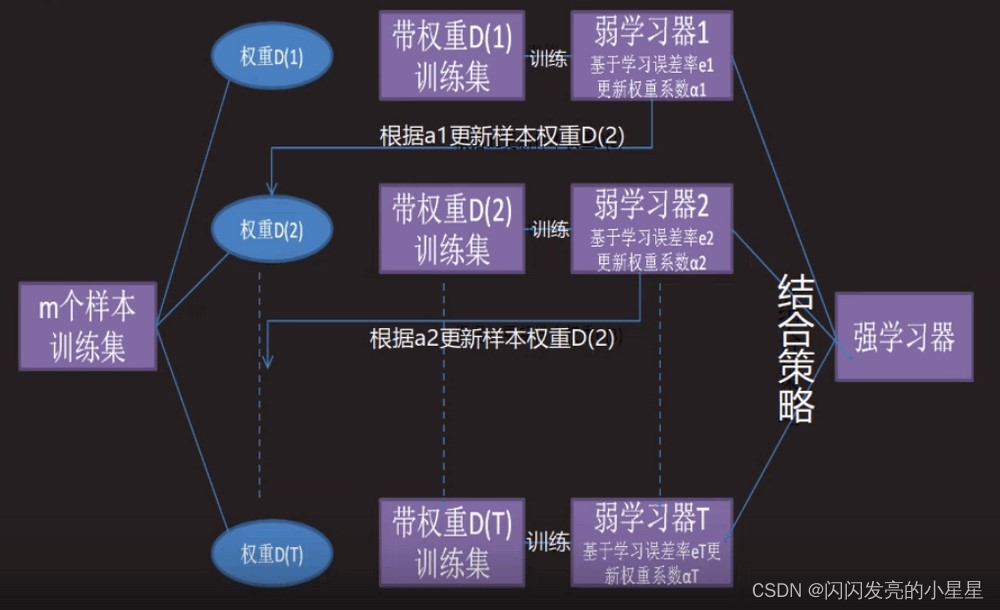
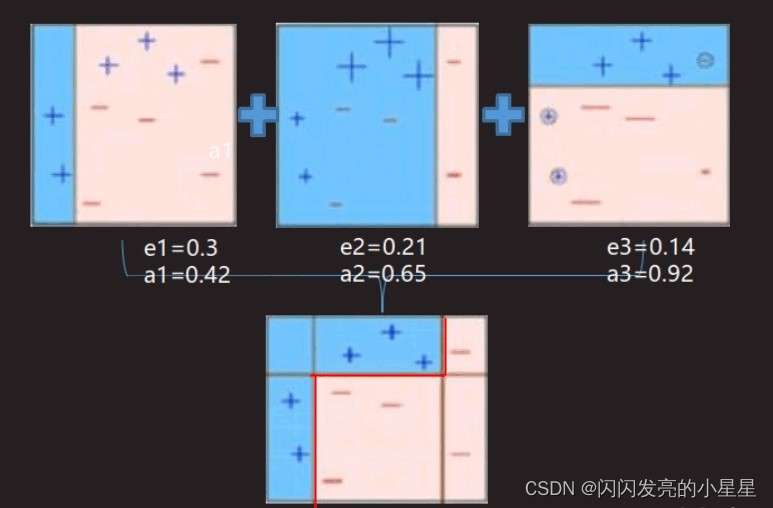
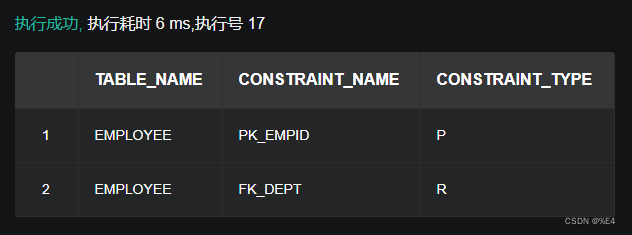
整个Adaboost 迭代算法就3步
1.初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
2.训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3.将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的权重较大,否则较小。
优缺点
1.优点:能够自适应调整弱学习算法的错误率,对多个弱模型进行博采众长,甚至不用进行特征工程处理
2.缺点:串行运算,效率不高。且容易受到异常值干扰(数据清洗需要做好)
import pandas as pd
# 读取文件
df_bank = pd.read_csv("../data/BankCustomer.csv")
# 显示数据结构信息
print(df_bank.info())
# 把二元类别文本数字化
df_bank['Gender'].replace('Female',0,inplace=True)
df_bank['Gender'].replace('Male',1,inplace=True)
# 显示数据类别
d_city = pd.get_dummies(df_bank['City'],prefix='City')
print(d_city)
df_bank = pd.concat([df_bank,d_city],axis=1)
# 构建特征标签集合
y = df_bank['Exited']
X = df_bank.drop(['Name','Exited','City'],axis=1)
from sklearn.model_selection import train_test_split # 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=1)
from sklearn.ensemble import AdaBoostClassifier,AdaBoostRegressor # 导入AdaBoost模型
from sklearn.tree import DecisionTreeClassifier # 选择决策树作为AdaBoost基准算法
dt = DecisionTreeClassifier()
ada = AdaBoostClassifier(dt) # AdaBoost模型
# 使用网格搜索优化参数
ada_param_grid = {'base_estimator__criterion':['gini','entropy'],
'base_estimator__max_depth':[6,12,15],
'n_estimators':[5,10,12],
'learning_rate':[0.01,0.1,0.2,0.3,1.0]}
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import f1_score
ada_gs = GridSearchCV(ada,param_grid=ada_param_grid,scoring='f1')
ada_gs.fit(X_train,y_train) # 拟合模型
print(ada_gs.best_estimator_) # 最佳模型
y_pred = ada_gs.predict(X_test) # 进行预测
print(f'预正:{ada_gs.score(X_train,y_train)},测正:{ada_gs.score(X_test,y_test)},F1 score:{f1_score(y_test,y_pred)}')
GBDT
GBDT主要由三个概念组成:Regression Decistion Tree(即DT),Gradient Boosting(即GB),Shrinkage(衰减)由多课决策树组成,所有的树的结果累加起来就是最终结果
1.除了向AdaBoost样本加权之外,GBDT算法还会定义一个损失函数,并对损失和机器学习模型所形成的函数进行求导。
2.决策树分为两大类,回归树和分类树。前者用于预测实数值,如明天的温度、用户的年龄、后者用于分类标签值。
- 预测值与真实值之间值称为”残差”,如果采用均方误差作为损失函数,是可以通过求导来优化残差的。
import pandas as pd
# 读取文件
df_bank = pd.read_csv("../data/BankCustomer.csv")
# 显示数据结构信息
print(df_bank.info())
# 把二元类别文本数字化
df_bank['Gender'].replace('Female',0,inplace=True)
df_bank['Gender'].replace('Male',1,inplace=True)
# 显示数据类别
d_city = pd.get_dummies(df_bank['City'],prefix='City')
print(d_city)
df_bank = pd.concat([df_bank,d_city],axis=1)
# 构建特征标签集合
y = df_bank['Exited']
X = df_bank.drop(['Name','Exited','City'],axis=1)
from sklearn.model_selection import train_test_split # 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,random_state=1)
from sklearn.ensemble import GradientBoostingClassifier # 导入AdaBoost模型
# 添加了求导函数,默认与随机森林相同基于决策树(回归数)
# 不同于AdaBoost知识对样本进行加权,GBDT算法还会定义一个损失函数.并对损失和机器学习模型形成的函数进行求导
# 梯度提升算法,对于回归问题是目前被认为最优算法之一
gbdt = GradientBoostingClassifier()
# 使用网格搜索优化参数
ada_param_grid = {'max_depth':[4,8],
'n_estimators':[50,70,100],
'max_features':[0.3,0.1],
'learning_rate':[0.01,0.05,0.01]}
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import f1_score
gbdt_gs = GridSearchCV(gbdt, param_grid=ada_param_grid, scoring='f1')
gbdt_gs.fit(X_train,y_train) # 拟合模型
print(gbdt_gs.best_estimator_) # 最佳模型
y_pred = gbdt_gs.predict(X_test) # 进行预测