半监督学习(SSL)
半监督学习(SSL). 让学习器不依赖外界交互、自动地利用未标记样本来提升学习性能. 即在少量样本标签的引导下, 能够充分利用大量无标签样本提高学习性能, 避免了数据资源的浪费, 同时解决了有标签样本较少时监督学习方法泛化能力不强和缺少样本标签引导时无监督学习方法不准确的问题.
具体介绍可见相关综述与博客:
【综述】半监督语义分割_m0_61899108的博客-CSDN博客
长文总结半监督学习(Semi-Supervised Learning) - 知乎 (zhihu.com)
半监督学习 - 知乎 (zhihu.com)
基本假设
- The Smoothness Assumption平滑假设:近朱者赤近墨者黑,两个样本在高密度空间特征相近,则label应该一致。优化方案如Mixup,一致性正则和对抗学习。
- The Cluster Assumption聚类假设:高维特征空间中,同一个簇的样本应该有相同的label,这个强假设其实是Smoothness的特例。
- Low-density Separation低密度分离假设:分类边界应该处于样本空间的低密度区。这个假设更多是以上假设的必要条件,如果决策边界处于高密度区,则无法保证簇的完整和边缘平滑。优化方案如MinEntropy。
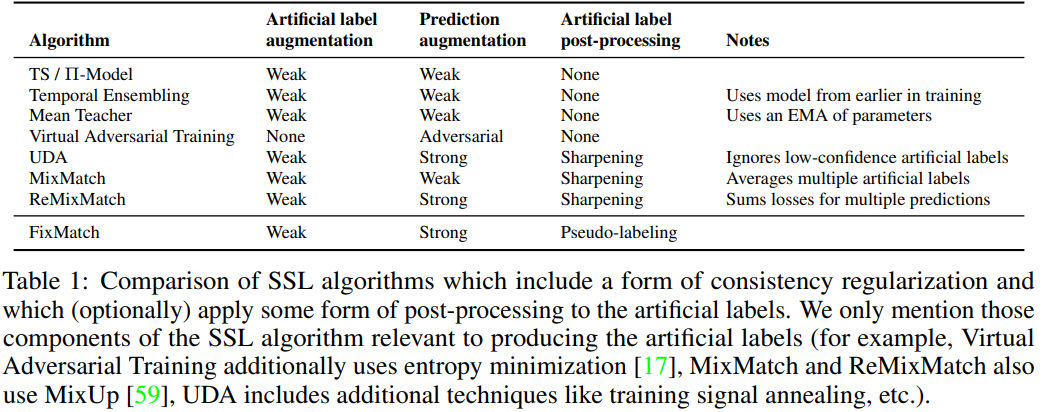
近来半监督图像分类任务有两大核心方法:一致性正则(Consistency Regularization)和打伪标签法(Pseudo-Label)。
本文简单介绍半监督算法中的Match系列方法:MixMatch(NIPS 2019),ReMixMatch(ICLR 2020),FixMatch(NIPS 2020),FeatMatch(ECCV 2020),FlexMatch(NlPS 2021)。
代码:https://github.com/TorchSSL/TorchSSL
MixMatch: A Holistic Approach to Semi-Supervised Learning, NeurIPS 2019
解读:超强半监督学习 MixMatch - 知乎 (zhihu.com)
MixMatch论文阅读 - 知乎 (zhihu.com)
半监督学习:MixMatch和ReMixMatch - 咖啡陪你 - 博客园 (cnblogs.com)
论文:https://arxiv.org/abs/1905.02249
代码:GitHub - YU1ut/MixMatch-pytorch: Code for "MixMatch - A Holistic Approach to Semi-Supervised Learning"
MixMatch,该算法为数据增强后产生的无标签示例猜测低熵标签,并使用MixUp混合有标签和无标签数据。许多半监督学习方法,通过在无标签数据上加一个损失项来使模型具有更好的泛化能力。损失项通常包含以下三种:1. 熵最小化(entropy minimization),鼓励模型在无标签数据上输出高置信度的预测结果;2. 一致性约束(consistency regularization),鼓励模型在数据有扰动之后输出相同的概率分布,3. 通用正则化(generic regularization),鼓励更好泛化和降低过拟合。MixMatch通过将现有方法融合到一个损失里面,取得好的效果.


ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring, ICLR 2020
解读:ReMixMatch论文阅读 - 知乎 (zhihu.com)
【ICLR2020】ReMixMatch - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/1911.09785
代码:GitHub - google-research/remixmatch
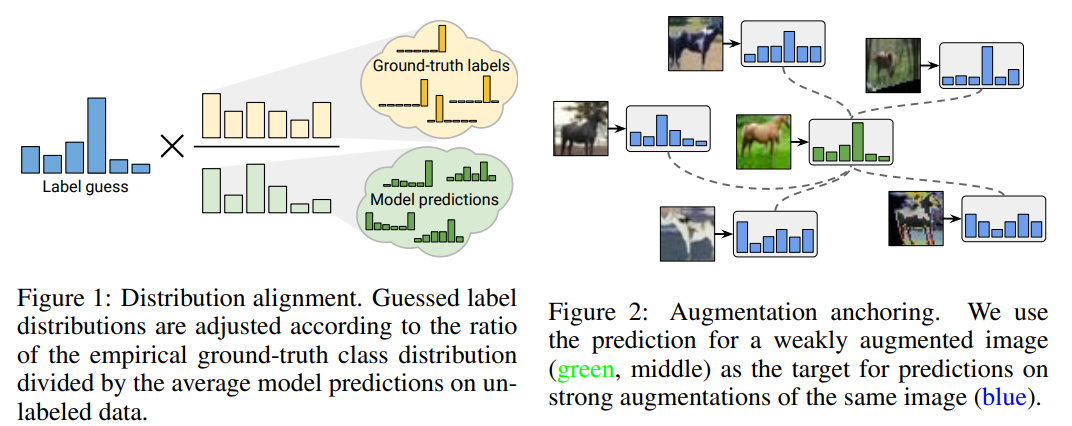
使用两种方式改进“MixMatch”算法:分布对齐(distribution alignment)和增强锚定(augmentation anchoring)。分布对齐鼓励对未标记数据的预测的边缘分布接近真实标签的边缘分布。增强锚定将input data的多个强增强版本输入到模型,并促使每个输出接近相同输入的弱增强版本的预测。

FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence, NeurIPS 2020
解读:论文笔记---“FixMatch” - 知乎 (zhihu.com)
FixMatch代码解析 - 知乎 (zhihu.com)
论文:https://arxiv.org/abs/2001.07685
代码:GitHub - google-research/fixmatch: A simple method to perform semi-supervised learning with limited data.
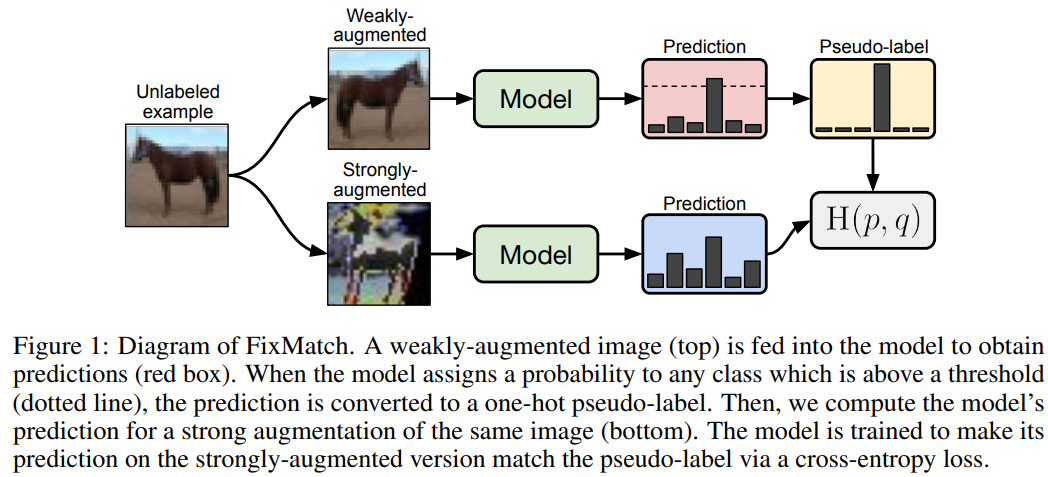
FixMatch,简单有效,主要创新在于一致性正则化和伪标签的组合,以及使用弱增强unlabel图像的预测生成伪标签,当作强增强unlabel图像的监督信号。

FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning, ECCV2020
解读:[半监督学习] FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning_码侯烧酒的博客-CSDN博客
论文:https://arxiv.org/abs/2007.08505
123630460.pdf (ecva.net)
代码:GitHub - GT-RIPL/FeatMatch: PyTorch code for the paper: "FeatMatch: Feature-Based Augmentation for Semi-Supervised Learning"
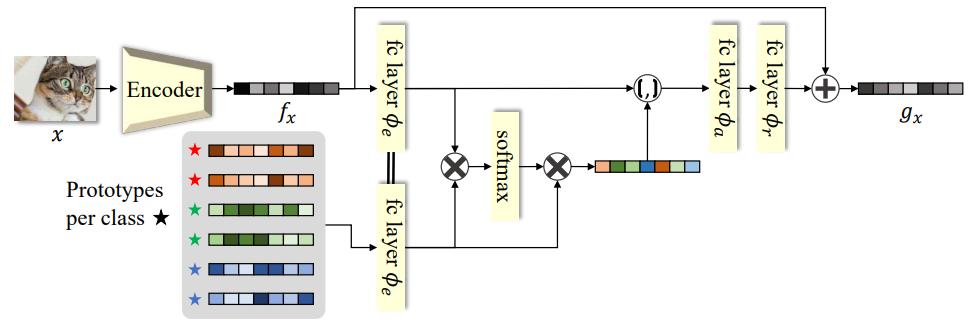
FeatMatch 中提出: 通过从其他图像的特征中提取的代表性原型的 soft-attention 来学习细化和增强输入图像特征.
传统的基于图像的数据增强与基于特征的数据增强对比如下:
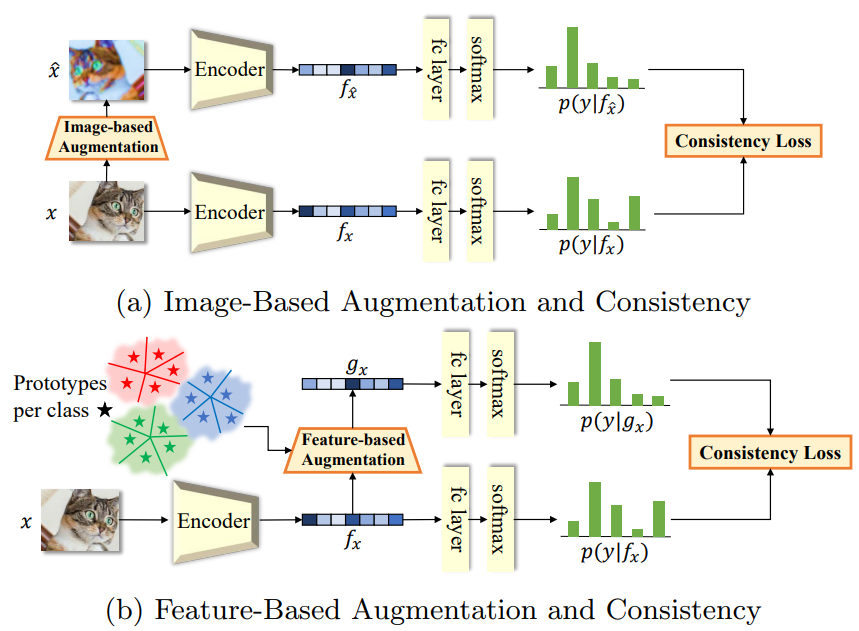


传统的基于图像的增强存在以下两个限制:
- 在图像空间中操作, 限制了图像内对纹理或几何的可能转换.
- 在单个实例中操作, 无法使用其他实例的知识, 无论是在同一类别的内部还是外部.
一些使用 Mixup 的算法仅部分解决了第二个限制, 因为 mixup 仅在两个实例之间运行, 如 ICT MixMatch, ReMixMatch. 另一方面, Manifold Mixup 通过在特征空间中执行 Mixup 来接近第一个限制, 但仅限于两个样本的简单凸组合.
为了同时解决这两个限制, 本文提出一种新方法FeatMatch, 可以在抽象特征空间而不是图像空间中细化和增强图像特征. 为了有效地利用其他类的知识, 通过在特征空间中执行聚类来将每个类的信息浓缩成一个原型集合. 然后通过从所有类的原型传播的信息来细化和增强图像特征.
原型选择(Prototype Selection):K-Means 在每个 epoch 都进行原型提取, 特征细化和增强模块在训练循环中使用新提取的原型更新现有的原型.
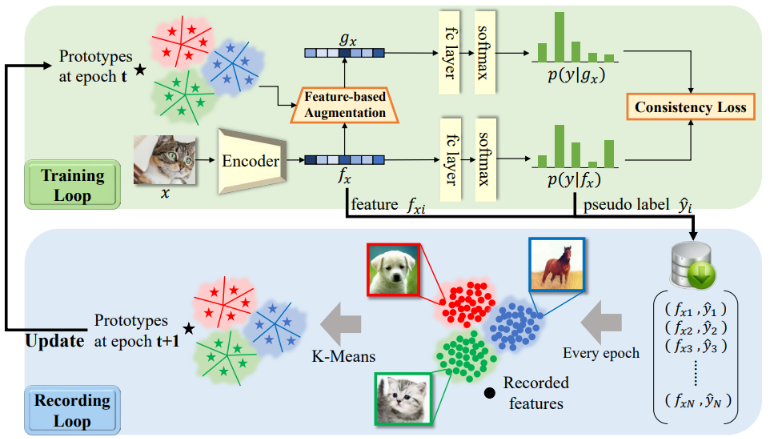

特征增强(Feature Augmentation):选择出的新的原型集合后, 通过 soft-attention 对原型集进行特征细化和增强.

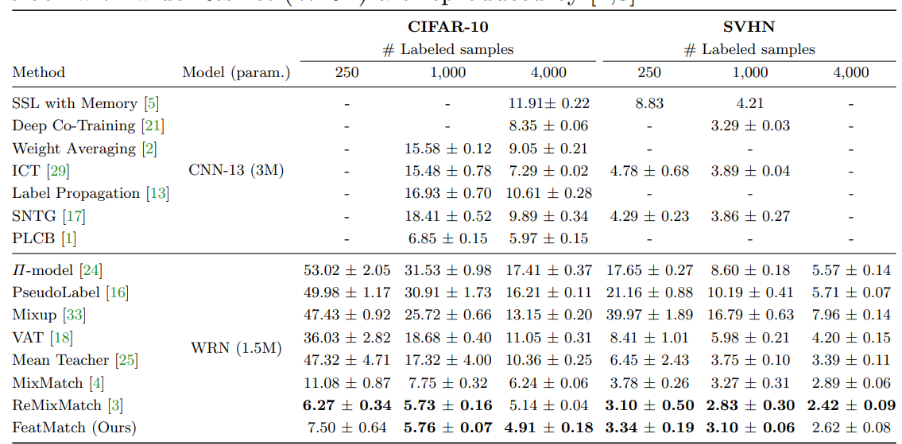
FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling, NeurIPS 2021
解读:FlexMatch论文阅读 - 知乎 (zhihu.com)
NeurIPS 2021 | 助力半监督学习:课程伪标签方法FlexMatch和统一开源库TorchSSL - 知乎 (zhihu.com)
论文:[2110.08263] FlexMatch: Boosting Semi-Supervised Learning with Curriculum Pseudo Labeling (arxiv.org)
代码:GitHub - TorchSSL/TorchSSL: A PyTorch-based library for semi-supervised learning (NeurIPS'21)
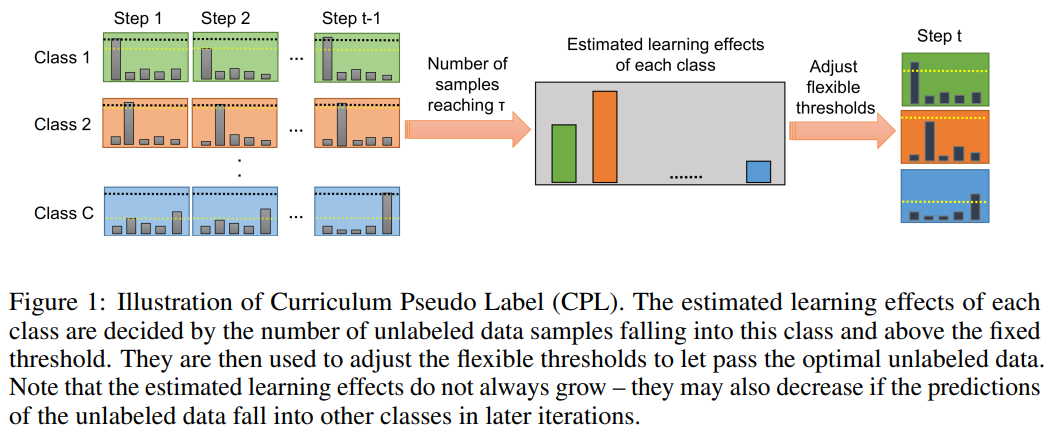
FixMatch对所有类使用预定义好的常量阈值来选择对训练有用的未标记数据,没有考虑到不同的学习状态和不同类别在判断上的困难。为了解决这个问题,本文提出课程伪标签(Curriculum Pseudo Labeling, CPL),一种根据模型的学习状态利用未标记数据的课程学习方法。CPL的核心是在每个时间步对不同的类灵活调整阈值,让有信息的无标签数据及其伪标签通过。CPL不引入额外的参数或计算(向前或向后传播)。将CPL应用于FixMatch,并命名改进的算法为FlexMatch。阈值会随着网络的训练逐步提升,不同的类别有不同的阈值。