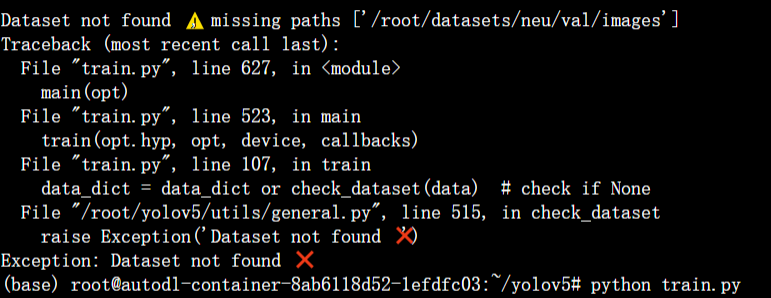
这里是直接没有找到数据集,说明是路径错误。经过设置yaml后,
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../autodl-tmp/datasets/neu # dataset root dir
train: train/images # train images (relative to 'path') 118287 images
val: val/images # val images (relative to 'path') 5000 images
test: test/images # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 6
names:
0: crazing
1: inclusion
2: patches
3: pitted_surface
4: rolled-in_scale
5: scratches出现了新的错误。

这里显示找不到标签,就非常困惑,然后开始了一些无用 的尝试,以为是数据集的问题,甚至想换个数据集,但是还是再尝试了一下,把数据集放在yolov5下面,以及看train.py等配置文件,都没有很好的办法,然后就开始查,划分的数据集,train下的labels和images 是不是一一对应的,发现是对应的,不知道咋办,再然后发现,train下的labels文件夹,我命名出错了,我打成了lables.改正后,跑了起来。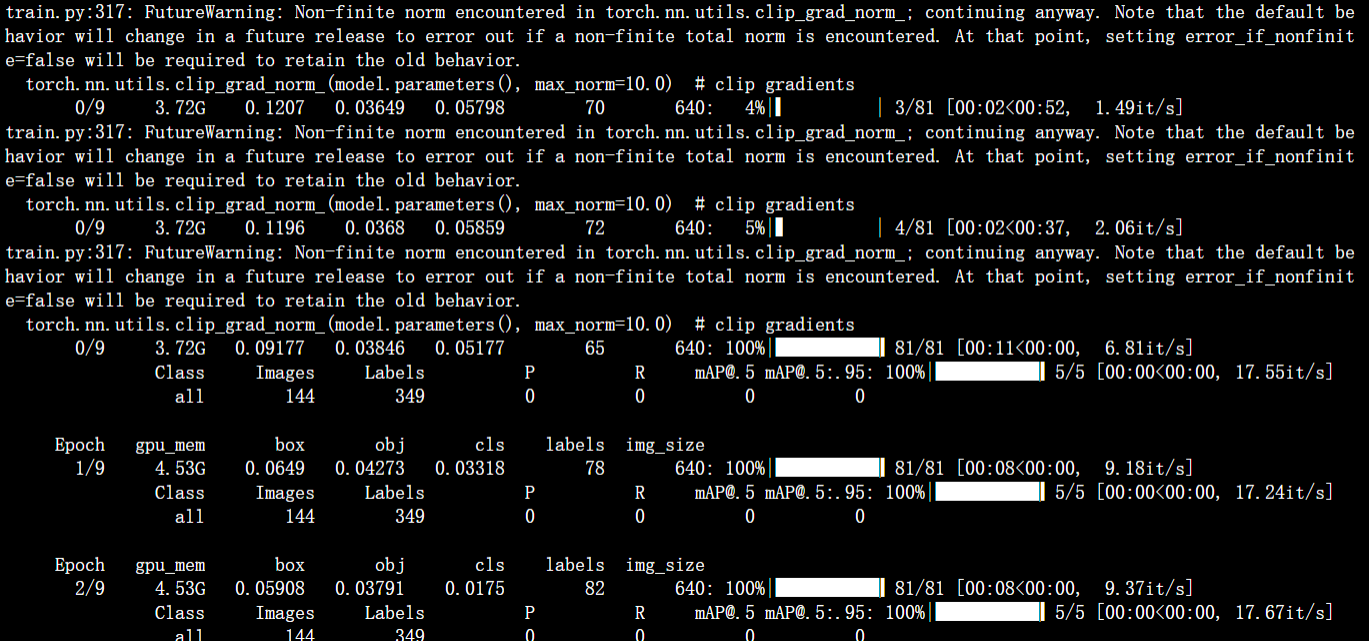
但是又遇到了,数据为0 的情况。
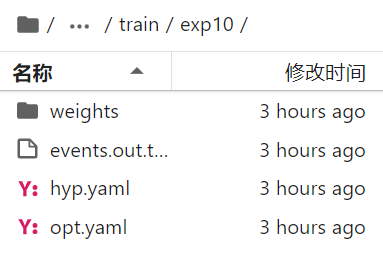
runs下面生成的exp文件里面都是空的。没有数据。
一开始是想法是,根本没有动这个yolov5的代码,这个问题一般是在损失函数方面的,就很困惑,于是只能根据报错去查。
然后根据上面的报错:FutureWarning: Non-finite norm encountered in torch.nn.utils.clip_grad_norm_; continuing anyway. 进行了查找。
这是来自PyTorch深度学习框架的警告消息。这个警告表示在使用torch.nn.utils.clip_grad_norm_()函数时,出现了非有限值(norm)。在深度学习中,这个函数通常用于梯度裁剪(gradient clipping)以避免梯度爆炸(gradient explosion)问题。当计算梯度的范数(norm)为无穷大或非数值值时,就会触发这个警告。通常,这个问题是由梯度中存在的NaN或Inf值引起的,可以通过检查模型代码中的数据输入和处理过程来解决这个问题。此外,也可以尝试减小学习率或减小模型的复杂度来避免梯度爆炸问题。
然后就怀疑是数据的问题,因为Non-finite norm encountered这个就是指遇到非有限范数,也就是越界了。一查果然如此:
1.脏数据:训练数据(包括label)中有无异常值(nan, inf等)。
2.除0问题。这里实际上有两种可能,一种是被除数的值是无穷大,即 Nan,另一种就是0作为了除数(分母可以加一个eps=1e-8)。之前产生的 Nan 或者0,有可能会被传递下去,造成后面都是 Nan。请先检查一下神经网络中有可能会有除法的地方,例 softmax 层,再认真的检查一下数据。可以尝试加一些日志,把神经网络的中间结果输出出来,看看哪一步开始出现 Nan 。
3.可能0或者负数作为自然对数,或者 网络中有无开根号(torch.sqrt), 保证根号下>=0
4.初始参数值过大:也有可能出现 Nan 问题。输入和输出的值,最好也做一下归一化。
5.学习率设置过大:初始学习率过大,也有可能造成这个问题。如果在迭代的100轮以内,出现NaN,一般情况下的原因是因为你的学习率过高,需要降低学习率。可以不断降低学习率直至不出现NaN为止,一般来说低于现有学习率1-10倍即可。如果为了排除是不是学习率的原因,可以直接把学习率设置为0,然后观察loss是否出现Nan,如果还是出现就不是学习率的原因。需要注意的是,即使使用 adam 之类的自适应学习率算法进行训练,也有可能遇到学习率过大问题,而这类算法,一般也有一个学习率的超参,可以把这个参数改的小一些。
6.梯度过大,造成更新后的值为 Nan 。如果当前的网络是类似于RNN的循环神经网络的话,在序列比较长的时候,很容易出现梯度爆炸的问题,进而导致出现NaN,一个有效的方式是增加“gradient clipping”(梯度截断来解决):对梯度做梯度裁剪,限制最大梯度,
7.需要计算loss的数组越界(尤其是自定义了一个新的网络,可能出现这种情况)
8.在某些涉及指数计算,可能最后算得值为 INF(无穷)(比如不做其他处理的softmax中分子分母需要计算exp(x),值过大,最后可能为INF/INF,得到NaN,此时你要确认你使用的softmax中在计算exp(x)做了相关处理(比如减去最大值等等)
然后就开始逐项排查。暂时还未解决,解决方案将放在下篇文章中。
参考文章:
Pytorch训练模型损失Loss为Nan或者无穷大(INF)原因_loss为inf_ytusdc的博客-CSDN博客
Pytorch计算Loss值为Nan的一种情况【exp计算溢出,利用softmax计算的冗余性解决】_futurewarning: non-finite norm encountered in torc_PuJiang-的博客-CSDN博客
Pytorch计算Loss值为Nan的一种情况【exp计算溢出,利用softmax计算的冗余性解决】_futurewarning: non-finite norm encountered in torc_PuJiang-的博客-CSDN博客

![[面试题] 判断二维空间中一点是否在旋转矩形内部](https://img-blog.csdnimg.cn/1964d59bcacc4fd48835628ba3881bef.png)