一、结构
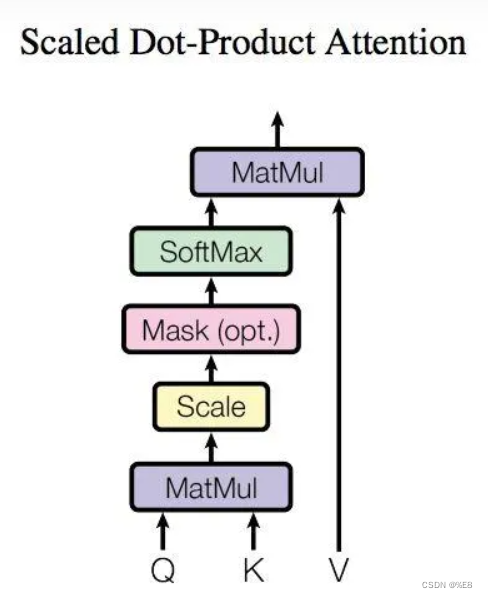
上面那个图其实不是那么重要,只要知道将输入的x矩阵转换成三个矩阵进行计算即可。自注意力结构的输入为 输入矩阵的三个变形 Q(query矩阵)、K(key矩阵)、V(value矩阵)构成,那么Q、K、V是如何得到的呢?
假设输入矩阵是 M*N的一个矩阵,也就是意味着输入有M个单词,则:
1.1 Q矩阵:

1.2 K矩阵:
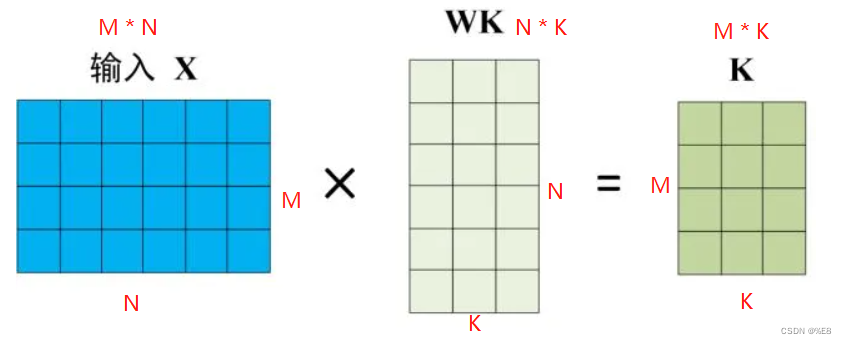
1.3 V矩阵:

注:作为中间矩阵的行数必须是N的,否则不能做矩阵乘法,且Q、K两个矩阵必须行列一致,否则不能保持最后的Q、K、V矩阵行列一致。
二、self-Attention输出
计算公式如下:

即计算Q矩阵与K矩阵的乘积,得到了一个N * N的矩阵,N为单词个数:

为了避免数值过大,除了向量维度的平方根。
接着计算每个单词对于其他单词的注意力系数,由于是对每一行过Softmax函数,则每行之和为1.
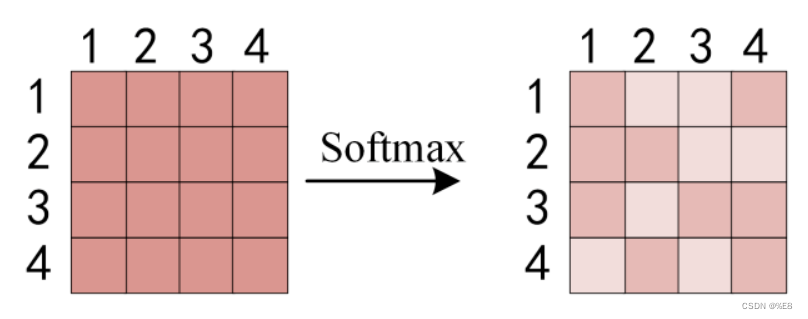
最后将得到的注意力系数矩阵与V矩阵相乘:
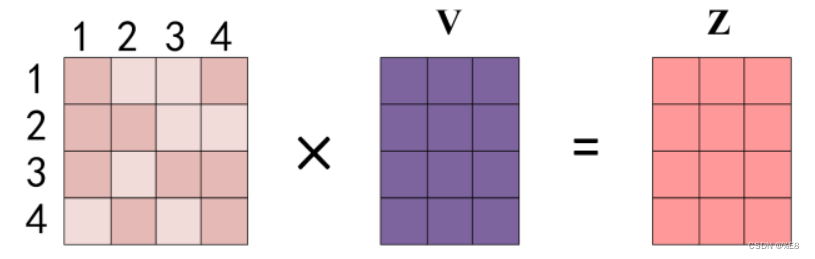
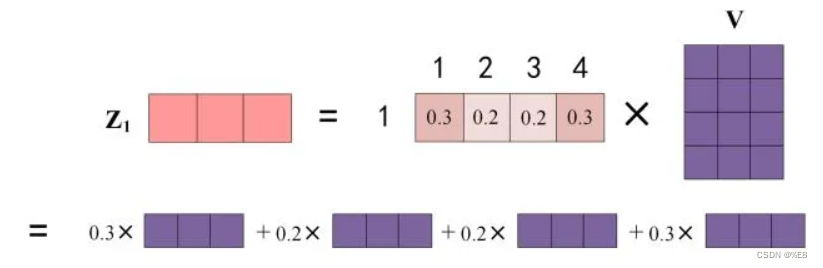
eg:word1如何计算得到z1:
Reference:Transformer模型详解(图解最完整版) - 知乎

![[面试题] 判断二维空间中一点是否在旋转矩形内部](https://img-blog.csdnimg.cn/1964d59bcacc4fd48835628ba3881bef.png)