目录
- 线程基础
- 静态链接
- 静态链接
- 装载与动态链接
- 库与运行库
关于隔离:
- 物理地址是实在存在的
- 虚拟地址是虚拟的,并不存在,每个进程都有自己独立的虚拟空间,而且每个进程只能访问自己的地址空间,这样就有效地做到了进程的隔离
分段:基本思路是把一段与程序所需的内存空间大小的虚拟空间映射到某个地址空间,解决了两个问题: - 首先做到了地址隔离;使不同进程的物理空间不会有任何重叠
- 不需要关系物理地址的变化
- 不足:内存效率使用问题:分段对内存的映射还是按照程序为单位,如果内存不足,被换入换出到磁盘的都是整个程序,势必会造成大量的磁盘访问操作
分页:把地址空间人为的分成固定大小的页,每一页的大小由硬件决定,或硬件支持多种大小的页,由操作系统选择决定页的大小;但在同一时刻只能选择一种大小,所以对整个系统来说,页是固定大小的 - 分类:虚拟空间中的页叫做虚拟页,物理内存中的页叫做物理页,磁盘中的页叫做磁盘页
- 虚拟地址空间有些页被映射到同一个物理页,这样就可以做到内存共享
- 如果进程用到页的时候这个页不在内存中,就会报页错误,然后操作系统接管进程,负责将页从磁盘中读取并装入内存。
- 查看linux内存页大小:getconf PAGE_SIZE,单位kb
线程基础
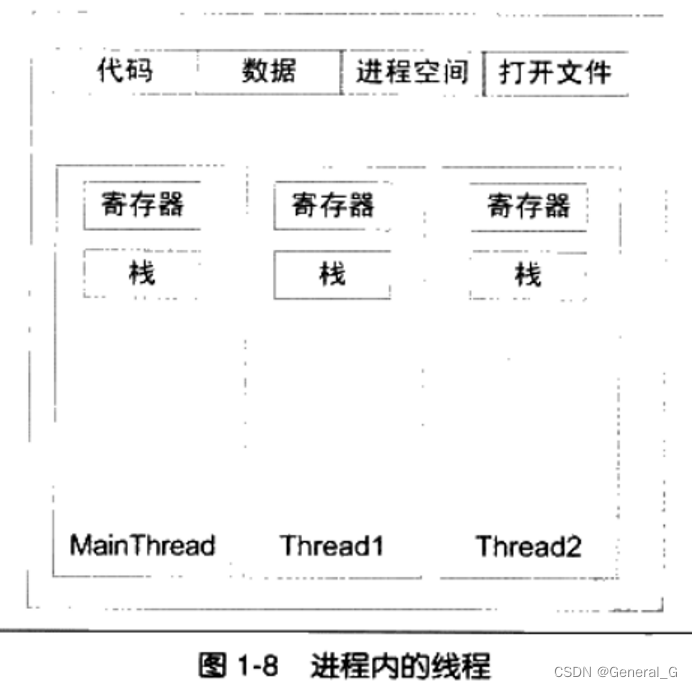
- 线程:一个标准线程由 线程ID,当前指令指针,寄存器集合和 堆栈 组成
线程私有存储,包括以下:
栈:尽管并非完全无法被其他线程访问,但一般情况下仍然可以认为是私有的数据
线程局部存储(TLS):线程局部存储的是某些操作系统为线程单独提供的私有空间,但通常只具有很有限的容量—具体有哪些—?
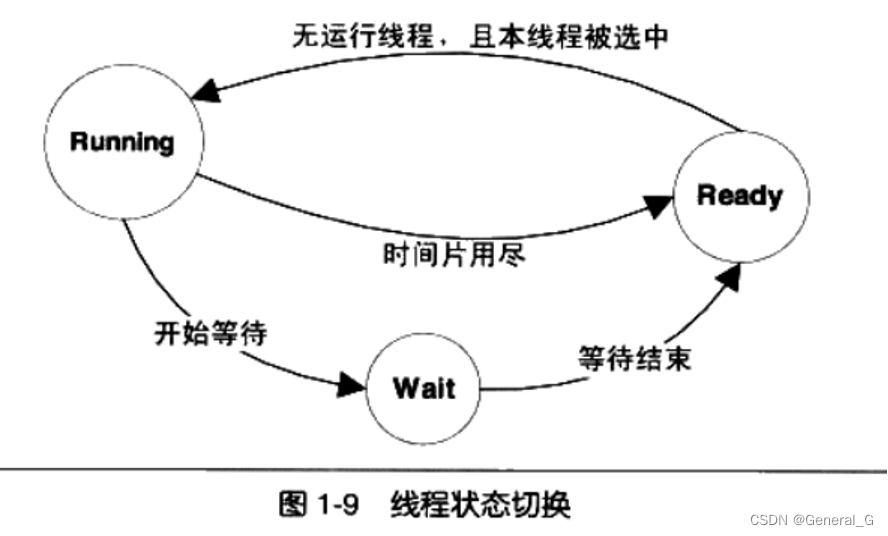
寄存器:寄存器是执行流的基本数据,因此为线程私有 - 线程至少有三种状态:
○ 运行:线程正在执行
○ 就绪:线程可以立刻运行,但CPU已经被占用
○ 等待:线程正在等待某一事件(通常是同步或IO)发生,无法执行 - 处于运行中的线程拥有一段可以执行的时间,这段时间称为时间片。当时间片用尽的时候该进程进入就绪状态——是不是每个线程都是这样的,不分优先级吗?
- 优先级调度
○ 频繁等待的线程称为IO密集型线程,很少等待的线程称为CPU密集型线程;IO密集型线程总是比CPU密集型线程容易得到优先级的提升
○ 线程的优先级改变大体有三种方式:
1. 用户指定优先级
2. 根据等待状态的频繁程度提升或降低优先级
3. 长时间得不到执行而提升优先级,为避免饿死现象,调度系统常常会逐步提升等待了过长时间的得不到执行的线程的优先级 - 单指令的操作称为原子的,windows下的原子操作api:
○ InterlockedExchange:原子的原地交换两个值
○ InterlockedDecrement:原子的减少一个值
○ InterlockedIncrement:原子的增加一个值
○ InterlockedXor:原子的进行异或操作 - linux的多线程:linux内核中并不存在真正意义上的线程概念,linux所有的执行实体都称为任务,每个任务类似于单线程的进程,不过不同的任务之间可以选择共享内存空间,共享同一个内存空间的多个任务构成了一个进程。三种方法可以创建一个新任务:
○ fork:复制当前进程:产生新任务的速度非常快,因为fork不复制原任务的内存空间,二十和原任务一起共享一个写时复制的内存空间,需要exec配合才能启动别的任务
○ exec:使用新的可执行映像覆盖当前可执行映像
○ clone:创建子进程并从指定位置开始执行 - 线程安全:详见并发编程
○ 原子操作:以++i为例,分三步:读取i到某个寄存器x;x++;将x的内容存储回i;所以并发会产生问题
○ 同步与锁:
a. 互斥量
b. 临界区:是比互斥量更严格的同步手段;与互斥量和信号量的区别在于,互斥量和信号量在系统的任何进程都是可见的,临界区的作用返回仅限于本进程(这个区别怎么搞懂)除此而外具有相同的性质
c. 读写锁
d. 条件变量 - 多线程内部的情况:三种线程模型 问题:我们经常使用的是哪种模型?
○ 一对一模型:一个用户使用的线程唯一对应一个内核线程,线程之间的并发是真正的并发。一般直接使用api或系统调用的线程是一对一线程,如linux中的clone(带有CLONE_VM参数),windows中的CreateThread
○ 多对一线程:将多个用户线程映射到一个内核线程上,缺点是一个用户线程阻塞,所有的线程将无法执行,好处是高效的上下文切换和几乎无限制的线程数量
○ 多对多
静态链接
从代码到可执行文件经过:
• 预处理
○ .c文件被预编译成一个.i文件,cpp文件被预编译成一个.ii文件;预编译的过程相当于
gcc -E test.c -o test.i
○ 预编译主要处理以"#"开始的预编译指令。经过预编译后的.i文件不包含任何宏定义,通过以下信息可得知,当我们无法判断宏定义是否正确或头文件是否正确时可以查看预编译后的文件来确定问题
§ 删除#define,展开宏定义
§ 处理所有条件预编译指令如#if ,#ifdef,#elif,#else,#endif等
§ 处理#include,将被包含的文件插入到该预编译指令的位置,这个过程是递归的
§ 删除所有的注释
§ 添加行号和文件名标识,以便编译时编译器产生调试用的行号信息
§ 保留所有的#pragma编译器指令,因为编译器需要使用——使用这个干啥
• 编译:通过一系列此法分析,语法分析,语义分析以及优化后生成相应的汇编代码文件;一般分为6步:扫描,语法分析,语义分析,源代码优化,代码生成,目标代码优化
gcc -S test.i -o test.s
○ 现在版本的gcc把预编译和编译合成一个步骤,C使用cc1,C++使用cclplus(usr/lib/gcc/i486-linux-gun/4.1/),gcc只是这些后台程序的包装,它会根据不同的参数要求去调用预编译编译程序cc1,汇编as,链接器ld
• 汇编:将汇编代码转变成机器可以执行的指令;每一个汇编语句几乎都对应一条机器指令,使用汇编器as完成
as test.s -o test.o
或者:gcc -c test.s -o test.o
或者使用gcc命令从C源码开始,经过预编译,编译和汇编直接输出目标文件:gcc -c hello.c -o hello.o
• 链接:定义其他模块的全局变量和函数在最终运行时的绝对地址都要在最终链接的时候才能确定
○ 主要作用:把各个模块之间相互引用的部分都处理好,使得各个模块之间能够正确的衔接,
○ 链接过程:主要包括地址和空间分配,符号绑定,重定位;
○ 静态链接的最基本的过程和作用:使用链接器可以直接引用其他模块的函数和全局变量而无须知道他们的地址,因为链接器在链接时会根据所引用的符号自动去相应的模块中查找地址,再进行修正为可执行程序中真正的地址,这个地址修正的过程也被叫做重定位,每个要被修正的地方叫一个重定位入口
目标文件:从结构上讲是已经编译后的可执行文件格式,只是没有经过链接的过程,有些符号或地址还没有被调整
• 目标文件的格式:windows下是PE,linux下的ELF(linux下使用file来查看文件格式),他们都是COFF格式的变种,包括:
○ 可重定位文件:linux的.o和Windows的.obj
○ 可执行文件:linux下的可执行文件和win下的exe
○ 共享库:linux下的 .so和windwos下的 .dll
○ 核心转储文件:linux下的core dump文件
• 目标文件是什么样的:总体来说程序源代码被编译以后主要分成两种段:程序指令和程序数据。代码段属于程序指令,而数据段和.bass段属于程序数据
○ 代码段(.code或.text):存放编译后的机器指令
○ 数据段(.data):存放已经初始化了的全局变量和局部静态变量
○ .bss段:未初始化的全局变量和局部静态变量,预留位置而已,并没有内容,所以在文件中也不占据空间——什么意思?这个段不占磁盘空间(哪是存储在哪?),存放未初始化的全局变量和局部静态变量,通过验证可以看到.c文件编译后的.o只有未初始化的局部静态变量在该段中,全局变量则没有,这和不同的编译器有关;编译单元内部可见的静态变量的确存放在bss段
○ 只读数据段(.rodata):只存放只读数据,如字符串常量,全局const数据等
○ .rela.xxx:重定位表,链接器在处理目标文件时对目标文件中的某些部位进行重定位,即代码段和数据段中那些对绝对地址的引用的位置,这些重定位的信息都记录在重定位表里面,对于每个需要重定位的代码段或数据段,都会有一个相应的重定位表,.xxx就是对应的要重定位的段
○ .symtab:符号表的段
○ 堆栈提示段(.note.GNU-stack):
○ 其他段如下:
• binutils工具
○ objdump:查看各种目标文件的结构和内容
§ -h:把ELF各个段的基本信息打印出来,只显示了关键段,如果要查看详细的段信息使用readelf -S
§ -s:将所有段的内容以十六进制的形式打印出来
§ -d:将所有包含指令的段反汇编
§ -x:更多的信息打印出来,内容比较多而杂
§ -r:查看ELF里需要重定位的地方——可以查看.o但看不了.so?
§ -t:显示符号表——是不是所有符号?
○ readelf:专门针对ELF文件格式的解析器,可以和objdump相互对照
§ -h:查看ELF文件头
§ -s:查看elf文件的符号表:导出的符号,还有一堆其他符号
§ -S xx.o 查看详细
§ -l:查看表头,ELF可执行文件和共享库文件都有,目标文件没有
§ -D:
§ -r:查看一个动态链接库的重定位表
§ -n:显示note段的信息
○ size:用来查看ELF文件的代码段,数据段和BSS段的长度,显示结果中的dec和hex表示三个段的长度和的十进制和十六进制
○ objcopy:将一个二进制文件作为目标文件中的一个段可以使用这个工具
○ nm:查看符号
§ 命令:
□ -D:导出动态库的符号(导出符号包含哪些,导出的很多);可以用这个看出模板实例化了几个实体定义;内联函数是导不出来的
□ -C:去掉修饰之后的符号
□ -u:打印出未定义的符号
□ 如果不是动态库,如.o文件,就直接用nm查看,如:nm ust_public.o | c++filt |grep GetBizSysStatus看看有没有定义GetBizSysStatus这个函数
§ 显示:
□ A: 符号绝对,链接过程不会改变 The symbol's value is absolute, and will not be changed by further linking.
□ B/b: 非初始化符号,放在bss段 The symbol is in the uninitialized data section (known as BSS).
□ C: 该符号为common,common段是未初始化的段,链接时会被同名符号覆盖
□ D/d: 位于初始化数据段中的符号,一般是在data段中
□ G/g: 初始化符号,面向小数据访问优化 The symbol is in an initialized data section for small objects.
□ I: 其它符号的间接引用 The symbol is an indirect reference to another symbol.
□ N:调试符号
□ P: 栈区符号(清空) The symbols is in a stack unwind section.
□ R/r: 该符号位于只读数据区
□ S/s: 非初始化符号,面向小数据访问优化 The symbol is in an uninitialized data section for small objects.
□ T/t: 代码区符号(通常是全局非静态函数,类的成员函数也是T)
□ U: 未定义或在外部定义的符号 (需要通过其他对象文件链接进来) The symbol is undefined.
□ u: 全局唯一,GNU保留符 The symbol is a unique global symbol.
□ V/v: 弱定义符(详见C++强弱符号定义) The symbol is a weak object.
□ W/w:未明确指定的弱链接符号,同链接的其他对象文件中有定义就用上,否则就用一个系统特别指定的默认值,类中的模板成员函数就是,模板函数也是;什么情况下是这个符号?The symbol is a weak symbol that has not been specifically tagged as a weak object symbol.
□ -: stabs格式符号
□ ?: NM也不认识的符号
○ ldd:查看一个程序或共享库依赖于哪些共享库
§ -r:查看未定义的符号
○ c++filt:解析被修饰符过的名称
○ 在进程运行起来之后, 使用pmap查看加载了哪些动态库,和动态库的映射位置
§ pmap -x 进程号
○ 如果想知道打开的是哪个动态库,想知道动态库的路径,
1. 使用lsof: lsof 进程号
2. 使用pmap -p 进程号
○ ar:(vs也提供了类似ar的工具:lib.exe)
§ x:把.a中打进去的.o都解压出来
§ -t:打印出.a中包含的.o
○ 查看ELF文件各个段的属性标签的含义:
§ SIZE:表示该段的大小
§ File Off:表示该段的偏移地址,即下一个段的FIle Off=上一个段的FIleOff+上一个段的SIZE
§ CONTENTS:表示该段在文件中存在
• __attribute__:用来设置函数、变量、类型的属性
○ 语法格式:__attribute__((attribute_list))
○ 属性:
§ alias:给函数起个别名,如 int test() __attribute__((alias("test1"))); 对test的调用就是对test1的调用
§ weak:
§ noreturn
§ aligned
§ noinline
• 自定义段:gcc提供了一个扩展机制,使得程序员可以指定变量所处的段:在全局变量或函数之前加上"__attribute__((section("name")))"就可以把相应的变量或函数存放到“name”作为段名的段中了
attribute((section(“FOO”))) int global = 42; // 针对变量
attribute((section(“BAR”))) void foo() {} // 针对函数
• ELF文件结构如下:ELF文件头结构及相关常数被定义在usr/include/elf.h里
• 符号:每一个目标文件都有一个相应的符号表,表中记录了目标文件所用到的所有符号,每个符号有一个对应值叫符号值,对变量和函数来说就是地址;(段名叫 .symtab)
○ 符号表中包含以下:对于链接来说,只关心全局符号和外部符号
§ 定义在本目标文件中的全局符号,可以被其他目标文件引用
§ 外部符号:在本目标文件中引用,但不定义在本目标文件中
§ 段名:这种符号由编译器产生,值是该段的起始地址
§ 局部符号:这类符号只在编译单元内部可见,如静态变量,在链接过程中没什么作用
§ 行号信息
○ 特殊符号:只有使用ld链接生成最终可执行文件的时候这些符号才会存在,在程序中无须定义但可以声明它们并且使用。几个代表性的特殊符号如下:
§ __executable_start:该符号为程序起始地址,注意不是入口地址,是程序的最开始的地址
§ __etext或_etext或etext:该符号为代码段结束地址,即代码段最末尾的地址
§ _edata或edata:该符号为数据段结束地址,即数据段最末尾的地址
§ _end或end:该符号为程序结束地址
○ 符号修饰与函数签名:C++名称修饰方法如下(应该只在gcc下是这样):
§ 所有的方法都以_Z开头
§ 对于嵌套的名字(在名称空间或类中)_Z后紧跟“N”
§ 然后是各个名称空间和类的名字,每个名字前是名字字符串的长度,再以E结尾(如果不属于名称空间或类就不以E结尾)
§ 对于一个函数来说,参数列表紧跟在“E”后面,对于int来说,就是字母“i”
○ extern "C": C++为了与C兼容(编译器为C和C++编译出的内容不同),用"extern "C""来声明或定义一个C的符号,前面不用加下划线。
§ 用extern修饰后,windows下会按C语言进行修饰(在符号前加"_"),在linxu下extern "C"里面的符号都是修饰后的符号(和导出符号一样);
§ __cplusplus:对C++来说必须使用extern "C"声明C函数,但C不支持该语法,所以使用这个宏来判断当前编译单元是不是C++代码。C++编译器在编译C++程序的时候默认定义这个宏
§ C语言不支持函数重载,所以无法重载具有外部"C"链接的函数——?
§ 当命名空间与extern “C”组合在一起时,生成的函数代码其实是C风格的,没有命名空间修饰,这是因为C风格里函数里没有命名空间这一概念,所以命名空间自动会被链接器忽略。
#ifdef __cplusplus
extern “C”
{
#endif
…
#ifdef __cplusplus
}
#endif
extern “C” int func(int); // 如果单独修饰某个符号为C语言的符号
○ 强符号和弱符号:是针对定义来说的,不是针对符号的引用;强弱符号对于库来说十分有用——还有待继续深入理解
§ 编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号;
§ 可以通过GCC的"attribute((weak))"来定义任何一个强符号为弱符号
§ attribute((weakref)) 这个关键字来声明一个外部函数的引用为弱引用
attribute((weakref)) void foo();
int main()
{
foo();
}
// 编译链接不会报错,但运行会报错,改进如下:
attribute((weakref)) void foo();
int main()
{
if(foo) foo();
}
• 链接器按如下规则处理被多次定义的全局符号:
1. 不允许强符号被多次定义,如果多次定义报重复定义错误
2. 如果一个符号在某个目标文件中是强符号,在其他文件中是弱符号则选择强符号
3. 如果一个符号在所有目标文件中都是弱符号,那么选择其中占用空间最大的一个——哪个占用空间最大?因为每个定义都是相同的
• 强若符号规则如下:
§ 函数是强符号
§ 有初始化的变量是强符号
§ 无初始化的变量是弱符号
§ 成员函数如果定义在类里面,那么是弱符号(用 nm 可以查看到确实是)
§ 成员函数如果定义在类外面,那么是强符号
§ 模板类中的成员函数无论定义在类内还是类外,都是弱类型(非特别说明,本文中类都是非模板类)[nm 验证]
○ 模板函数是弱类型[亲验]
○ 模板函数的特化版本是强的 [亲验]
• 调试信息:GCC编译时加-g,会产生debug相关的段;strip命令去掉ELF文件中的调试信息:strip foo
静态链接
• 空间和地址的分配:一般是相似段合并,链接器采用两步链接法:空间与地址分配和符号解析与重定位
• 重定位:链接器如何知道哪些指令要被调整?在ELF文件中有一个叫重定位表的结构专门用来保存这些与重定位相关的信息。对于每个要被重定位的ELF段都有一个对应的重定位表,一个重定位表往往就是ELF文件中的一个段,如代码段 .text如果有要被重定位的地方就会有个相应的 .rel.text段,如 .data有重定位的地方就会有 .rel.data段
○ 各符号在段内的相对位置是固定的,链接期间链接器只需要给每个符号加上偏移量就能够得到正确的虚拟地址
○ 为什么要将弱符号放到bss段?如果编译器将一个编译单元编译成目标文件时如果该编译单元包含了弱符号,该弱符号最终所占空间在此时是未知的,因为可能其他编译单元中该符号所占空间比本编译单元该符号所占空间要大,因此无法为该符号在BSS段分配空间,但在链接过程中是可以确知的——待验证
○ COMMON块:GCC的"-fno-common"允许把所有未初始化的全局变量不以COMMON块的形式处理,或者使用 "__attribute__"扩展:int global __attribute__((nocommon)); 一旦一个未初始化的全局变量不适宜COMMON块的形式存在,就相当于一个强符号
• C++相关问题:最主要的有两个问题:重复代码消除和全局的构造和析构
○ 重复代码的消除:C++编译器会产生重复代码,如模板,外部内联函数,虚函数表等;一个比较有效的办法是将每个模板的实例代码都单独放在一个段里,每个段只包含一个模板实例;GCC把这种类似的需要在最终链接时合并的段叫"Link Once",命名为".gnu.linkonce.name",这种做法目前为主流编译器所使用;对外部内联函数和虚函数表的做饭也是类似
○ 函数级别的链接:“-ffunction-sections”和“-fdata-sections”,这两个选项的作用就是将每个函数或变量分别保持到独立的段中
○ 全局构造和析构:C++的全局对象的构造是在main之前被执行,析构函数是在main之后被执行。linux系统下一般程序的入口是“_start”,这个函数是Glic的一部分。ELF文件还定义了两种特殊的段,利用这两个段,C++的全局构造和析构就由此实现
§ .init:保存的可执行指令构成了进程的初始化代码,在main之前执行
§ .fini:保存进程终止代码指令,在main正常退出时执行
○ C++与ABI:以下几个方面会决定目标文件之间是否二进制兼容:
§ 内置类型的大小和在存储器中的放置方式(大小端,对齐方式等)
§ 组合类型的存储方式和内存分布
§ 外部符号与用户定义的符号之间的命名方式和解析方式
§ 函数调用方式:如参数入栈顺序,返回值如何保持等
§ 堆栈的分布方式
§ 寄存器使用约定
§ 。。。
○ C++要做到二进制兼容比C更不容易:——待验证
§ 继承类体系的内存分布,如基类,虚基类在继承类中的位置等
§ 指向成员函数的指针的内存分布:如何通过指向成员函数的指针调用成员函数?如何传递this指针?
§ 如何调用虚函数,vptb的内容和分布形式,vptr在对象中的位置
§ 模板如何实例化
§ 外部符号的修饰,全局对象的构造和析构,异常,RTTI等
• 链接过程控制:ld链接器:gcc中的内嵌汇编
○ -verbose:查看ld默认的链接脚本,默认是放在/usr/lib/ldscripts/下
○ -static:表示ld使用静态链接的方式来链接程序而不是使用默认的动态链接的方式
○ 链接脚本语法:待学习
装载与动态链接
装载:
• 动态装载
○ 基本原理:将程序中常用的部分驻留在内存中,将一些不常用的数据存放在磁盘中
○ 覆盖装入和页映射:典型的动态装载方法,原则上都是利用了程序的局部性原理,动态装入的思想是用到哪个就装载哪个
• 进程的建立:一个进程最关键的特征是它拥有独立的虚拟地址空间
○ 创建一个独立的虚拟地址空间:由一组页映射函数将虚拟空间的各个页映射至相应的物理空间
○ 读取可执行文件头,并且建立虚拟空间和可执行文件的映射关系
○ 将CPU指令寄存器设置成可执行文件入口,启动运行
• 进程虚拟空间分布:操作系统通过给进程空间划分出一个个VMA来管理进程的虚拟空间;基本原则是将相同权限属性,有相同映像文件的映射成一个VMA;
○ 段的权限:
§ 以代码段为代表的权限为可读可执行
§ 以数据段和BSS段为代表的权限为可读可写的段
§ 以只读数据段为代表的权限为只读的段
○ 对于相同权限的段,把它们合并到一起当作一个段进行映射
○ 一个进程基本上可以分为如下几种VMA区域:
§ 代码VMA:权限只读,可执行;有映像文件
§ 数据VMA:权限可读写,可执行;有映像文件
§ 堆VMA:可读写,可执行,无映像文件,匿名,可向上扩展
§ 栈VMA:可读写,不可执行;无映像文件,匿名,可向下扩展
○ 堆中最大申请数量:有的操作系统使用了随即地址空间分配技术
动态链接:
• 为什么要动态链接:
○ 静态链接的缺点:
§ 空间浪费
§ 静态链接对程序的更新,部署和发布有很大的影响
○ 如果某个符号是定义在动态链接库中的符号,链接器就会将这个符号的引用标记为一个动态链接库的符号,不对它进行重定位,把这个过程留到装载时再进行
○ 共享对象的最终装载地址在编译时是不确定的,而是在装载时装载器根据当前地址空间的空闲情况动态分配一块足够大小的虚拟地址空间给相应的共享对象
• 什么是动态链接:不对组成程序的目标文件进行链接,等到程序运行时才进行链接,也就是说把链接这个过程推迟到运行时再进行
• 地址无关代码:
○ 装载时重定位:链接时对所有绝对地址的引用不作重定位,而是把这一步推迟到装载时才完成,一旦模块装载地址确定,即目标地址确定,系统就对程序中所有绝对地址引用进行重定位
○ gcc参数:
§ -shared:输出的共享对象使用装载时重定位的方法
§ -fPIC:
• 显示运行时链接
○ API:
§ dlopen
§ dlsym
§ dlerror
§ dlclose
共享库:
• C/C++的兼容问题:
○ C共享库ABI改变而导致不兼容的行为:
§ 导出函数的行为发生变化,也就是说调用这个函数产生的结果和以前不一样,不再满足旧版本规定的函数行为准则——??
§ 导出函数被删除
§ 导出数据的结构发生变化,如共享库定义的结构体变量的结构发生变化,删除,改变顺序等;(尾部增加可以吗?)
§ 导出接口发生变化
○ 对于C++来说,ABI的兼容问题更严重,开发C++ ABI兼容的共享库需要满足以下(完全遵守还是不一定):
§ 不在接口中使用虚函数;万不得已时不要添加或删除虚函数,这会导致虚表发生变化;
§ 不改变任何成员变量的类型和位置
§ 不删除非内嵌的public或protected成员函数——(什么是内嵌的public或protected成员函数,是不是内联)
§ 不将非内嵌的成员函数改成内嵌的成员函数
§ 不改变成员函数的访问权限
§ 不在接口中使用模板
§ 不改变接口的任何部分,或者干脆不要使用C++做为共享库接口!
• 命名规则:linux规定系统中的共享库文件名必须为:libname.so.x.y.z;最前是lib,中间位库名,后缀.so,后面为三个数字:
○ x:主版本号,表示库的重大升级,不同主版本号的库之间是不兼容的,必须重新编译
○ y:次版本号,表示库的增量升级,即增加一些新的接口符号,且保持原符号不变,高的次版本号向低的次版本号兼容
○ z:发布版本号,表示库的一些错误修正,性能改进等,不添加也不更改接口
• 共享库系统路径(开源系统遵从一个标准 FHS,规定有如下几个位置存放共享库):
○ /lib:存放系统最关键和基础的共享库,如动态链接器,C语音运行库等
○ /usr/lib:保存非系统运行时所需要的关键性的共享库,主要是一些开发时用到的共享库
○ /usr/local/lib:用来放置和操作系统本身不十分相关的库,主要是一些第三方的应用程序的库
• 共享库的查找过程:
• 环境变量:改变共享库查找路径最简单的方法是使用 LD_LIBRARY_PATH环境变量;另一种实现与LD_LIBRARY_PATH类似的功能是直接运行动态链接器启动程序
○ 动态链接器的查找顺序:
§ 由环境变量LD_BLBRARY_PATH指定的路径,它里面包含的目录相当于链接时GCC的"-L" 参数
§ 由路径缓存文件 /etc/ld.so.cache指定的路径
§ 默认共享库目录,先/usr/lib,然后 /lib
○ LD_LIBRARY_PATH
○ LD_PRELOAD:在此指定的文件会在动态链接器按照固定规则搜索共享库之前装载;正常情况下应避免使用
○ LD_DEBUG:这个变量可以打开动态链接器的调试功能,值可以为以下:
§ files:
§ bindings:显示动态链接的符号绑定过程
§ versions:显示符号的版本依赖关系
§ reloc:显示重定位过程
§ symbols:显示符号表查找过程
§ statistics:显示动态链接过程中的各种统计信息
§ all:显示以上所有信息
§ help:显示以上各种可选值的帮助信息
• 创建:最关键的是使用两个参数 -shared(表示输出结果是共享库类型的), -fPIC(表示使用地址无关代码)
○ 清除符号文件:
§ ld的"-s"和"-S"使得链接器生成输出文件时就不产生符号信息。-s和-S的区别是-S消除调试符号信息而-s消除所有符号信息,也可以在gcc中通过"-Wl, -s"和"-Wl,-S"给ld传递这两个参数
§ strip(binutils的一部分)清除掉共享库或可执行文件的所有符号和调试信息
○ 共享库的构造和析构:gcc提供
§ 共享库的构造函数,函数声明时加上"attribute((constructor))"属性,即指定该函数为共享库构造函数,拥有这种属性的函数会在共享库加载时被执行,即main之前执行。如果使用dlopen打开,会在dlopen返回前被执行
§ 共享库的析构函数:函数声明时加上"attribute((destructor))"的属性,main之后执行。如果是运行时加载的,使用dlclose来卸载库时,析构函数会在dlclose返回之前执行
§ 如果有多个构造,默认情况下执行顺序是没有规定的,可以指定构造或析构的优先级
void attribute((constructor)) init_function(void); // 声明
void attribute((constructor(3))) int_function1(void); // 指定优先级,对构造来说数字越小越先执行,对析构相反
库与运行库
内存
一般来说,应用程序使用的内存空间有如下默认区域:
• 栈:用于维护函数调用的上下文,离开了栈函数调用就没法实现,栈通常在用户空间的最高地址分配,ulimit -s查看默认栈大小
• 堆:用来容纳动态分配的内存区域,堆通常在栈下方
• 可执行文件映像:存储着可执行文件在内存中的映像
• 保留区
• 栈:
○ 向下增长
○ 栈保存了一个函数调用所需要的维护信息,通常被称为堆栈帧,一般包含:
§ 函数的返回地址和参数
§ 临时变量:包含非静态局部变量和编译器自动生成的其他临时变量
§ 保存的上下文:包括在函数调用前后需要保持不变的寄存器
○ linux下默认栈的大小,可以用ulimit -s 查询,单位是kb, 一般默认大小为8k
§ 设置默认栈的大小:
□ ulimit -s 102400:设置大小临时改变栈空间的大小
□ 永久修改:
® 可以在/etc/rc.local 内加入 ulimit -s 102400 则可以开机就设置栈空间大小,任何用户启动的时候都会调用。
® 修改配置文件/etc/security/limits.conf
• 调用惯例:
○ 函数参数的传递顺序和方式:最常见的一种是通过栈传递,函数调用方将参数压入栈中,函数从栈中取参。对多参函数,调用惯例要规定函数调用方将参数压栈的顺序;有些调用惯例还允许使用寄存器传递参数以提高性能
○ 栈的维护方式:栈在函数参数的入栈和出栈前后要保持一致,参数弹出的工作可由函数的调用方来完成,也可由函数本身来完成—出栈方是什么意思—?
○ 名字修饰:在C语言中存在多个调用惯例,不同的调用惯例有不同的名字修饰策略。默认是cdecl,
如对foo函数的声明完整形式是 int _cdcel foo(int n, float m);具体堆栈操作如下:
1.将m压入栈中
2.将n压入栈中
3.调用_foo,这一步又分两步:
(1)将返回地址压入栈中
(2)跳转到_foo执行
• 如果我们的函数使用了_cdecl,那么栈的清除工作是由函数调用方,这样带来了一个棘手的问题,不同的编译器产生栈的方式不尽相同,那么调用者能否正常的完成清除工作呢?答案是不能。——函数调用方怎么清除?
• 如果使用__stdcall,上面的问题就解决了,函数自己解决清除工作。所以,在跨平台的调用中,我们都使用__stdcall。那么为什么还需要_cdecl呢?当我们遇到这样的函数如fprintf()它的参数是可变的,不定长的,被调用者事先无法知道参数的长度,事后的清除工作也无法正常的进行,因此,这种情况我们只能使用_cdecl。到这里我们有一个结论,如果你的程序中没有涉及可变参数,最好使用__stdcal
• 堆与内存管理
运行库:
• 查看运行库的版本:
○ ldd --version:ldd是glibc提供的命令,由此可知glic的版本号
○ glic版本查看:rpm -qa | grep glibc
○ 使用命令 getconf GNU_LIBC_VERSION
• 程序的运行库:C库源码:http://ftp.gnu.org/gnu/glibc/
1. 操作系统在创建进程后将控制权交给程序的入口,这个入口是运行时库中的某个入口函数
2. 入口函数对运行库和程序运行环境进程初始化,包括堆,IO,线程,全局变量构造等
3. 入口函数在完成初始化之后调用main函数,开始执行程序主体部分
4. main函数执行完成后返回到入口函数,入口函数进行清理工作,包括全局变量的析构,堆销毁,关闭IO等,然后进行系统调用结束进程
• C/C++运行时库
○ 一个C语言运行库大致包含了如下功能:
§ 启动与退出
§ 标准函数:C标准库
§ I/O
§ 堆:堆的封装和实现
§ 语言实现:语言中一些特殊功能的实现——具体哪些?
§ 调试:实现调试功能的代码
○ C语言标准库:比较轻量,仅包含数学函数,字符/字符串处理,I/O等基本方面
§ 标准输入输出;文件操作;字符操作/字符串操作;数学函数;资源管理;格式转换;时间/日期;断言;各种类型上的常数
§ 特殊库:变长参数;非局部跳转
○ glic:在每个目标文件中引入两个与初始化相关的段:“.init"和”.finit",保证位于这两个段中的代码先/后于main函数执行,所以用它们实现全局构造和析构;但C++全局对象的构造和析构并不是直接放在.init和.finit段里,而是把一个执行所有构造和析构的函数的调用放在里面。
○ 多线程
§ 线程的私有存储空间:
□ 栈(尽管并非完全无法被其他线程访问,但一般情况下仍然可以认为是私有的数据)
□ 线程局部存储(TLS):定义一个全局变量为TLS类型
__thread int number; // gcc,在前加上关键字__thread
__declspec(thread) int number; //msvc,msvc为__declspec(thread)
□ 寄存器:寄存器是执行流的基本数据,因此为线程私有
• 涉及的函数调用:
○ int atexit(void (*func)(void)) #include<stdlib.h>:注册函数,这些函数将由exit调用,调用顺序与它们注册顺序相反
系统调用:
• 运行库包装系统调用,实现了跨平台,一旦程序用到了CRT之外的接口就很难保持各平台之间的兼容性了
内部链接与外部链接:
内部链接: 如果一个名称对于他的编译单元是局部的,并且在链接时不会与其他的编译单元中同样的名字冲突,那么这个名称就拥有内部链接
gcc/g++中的编译:
参考:https://www.cnblogs.com/lsgxeva/p/7605141.html
编译优化:
• -fno-builtin:gcc提供了很多内置函数,将一些常用的C库函数替换成编译器的内置函数,以达到优化功能
• -fno-elide-constructors:C++标准允许一种(编译器)实现省略创建一个只是为了初始化另一个同类型对象的临时对象。指定这个参数(-fno-elide-constructors)将关闭这种优化,强制g++在所有情况下调用拷贝构造函数。什么时候使用该优化?如果你的代码依赖于拷贝构造函数的副作用,那么你的代码就写的很烂。你编写的拷贝构造函数就应该保证这样的优化是安全的。
编译命令:
• -c:编译,汇编到目标代码,但不链接——用来生成.o文件
• -E:仅做预处理,不进行编译,汇编,链接——没用过
• -S:仅编译到汇编语言,不进行汇编和链接——没用过
• -Dname:预定义一个名为name 的宏,值为1
• -Dname=value:预定义名为name,值为value 的宏
__builtin_expect 这个指令是gcc引入的,作用是允许程序员将最有可能执行的分支告诉编译器。这个指令的写法为:__builtin_expect(EXP, N),意思是:EXP==N的概率很大。一般的使用方法是将__builtin_expect指令封装为likely和unlikely宏。这两个宏的写法如下.
#define likely(x) __builtin_expect(!!(x), 1) //x很可能为真
#define unlikely(x) __builtin_expect(!!(x), 0) //x很可能为假
if(likely(value)) //等价于 if(value) if(unlikely(value)) //也等价于 if(value)




![[Leetcode] 0705. 设计哈希集合](https://img-blog.csdnimg.cn/img_convert/1ae0a7e423eb5000858b85acd161be50.png)