1. Lambda 表达式
1.1 通过接口传递代码
针对接口而非具体类型进行编程,可以降低程序的耦合性,提高灵活性,提高复用性。接口常被用于传递代码,比如,我们知道 File 有如下方法:
public File[] listFiles(FilenameFilter filter)listFiles需要的其实不是FilenameFilter对象,而是它包含的如下方法:
boolean accept(File dir, String name);或者说,listFiles希望接受一段方法代码作为参数,但没有办法直接传递这个方法代码本身,只能传递一个接口。
再如,类Collections中的很多方法都接受一个参数Comparator,比如:
public static <T> void sort(List<T> list, Comparator<? super T> c)它们需要的也不是Comparator对象,而是它包含的如下方法:
int compare(T o1, T o2);但是,没有办法直接传递方法,只能传递一个接口。
Callable和Runnable接口也用于传递任务代码。
通过接口传递行为代码,就要传递一个实现了该接口的实例对象,在之前,最简洁的方式是使用匿名内部类,比如:
//列出当前目录下的所有扩展名为.txt的文件
File f = new File(".");
File[] files = f.listFiles(new FilenameFilter(){
@Override
public boolean accept(File dir, String name) {
if(name.endsWith(".txt")){
return true;
}
return false;
}
});将files按照文件名排序,代码为:
Arrays.sort(files, new Comparator<File>() {
@Override
public int compare(File f1, File f2) {
return f1.getName().compareTo(f2.getName());
}
});1.2 Lambda 语法
Java 8 提供了一种新的紧凑的传递代码的语法:Lambda表达式。
File f = new File(".");
File[] files = f.listFiles((File dir, String name) -> {
if(name.endsWith(".txt")) {
return true;
}
return false;
});可以看出,相比匿名内部类,传递代码变得更为直观,不再有实现接口的模板代码,不再声明方法,也没有名字,而是直接给出了方法的实现代码。Lambda表达式由->分隔为两部分,前面是方法的参数,后面{}内是方法的代码。上面的代码可以简化为:
File[] files = f.listFiles((File dir, String name) -> {
return name.endsWith(".txt");
});当主体代码只有一条语句的时候,括号和return语句也可以省略,上面的代码可以变为:
File[] files = f.listFiles((File dir, String name) -> name.endsWith(".txt"));注意:没有括号的时候,主体代码是一个表达式,这个表达式的值就是函数的返回值,结尾不能加分号,也不能加return语句。方法的参数类型声明也可以省略,上面的代码还可以继续简化为:
File[] files = f.listFiles((dir, name) -> name.endsWith(".txt"));之所以可以省略方法的参数类型,是因为Java可以自动推断出来,它知道listFiles接受的参数类型是FilenameFilter,这个接口只有一个方法accept,这个方法的两个参数类型分别是File和String。
排序的代码用Lambda表达式可以写为:
Arrays.sort(files, (f1, f2) -> f1.getName().compareTo(f2.getName()));参数只有一个的时候,参数部分的括号可以省略。比如,File还有如下方法:
public File[] listFiles(FileFilter filter)FileFilter的定义为:
public interface FileFilter {
boolean accept(File pathname);
}使用FileFilter重写上面的列举文件的例子,代码可以为:
File[] files = f.listFiles(path -> path.getName().endsWith(".txt"));与匿名内部类类似,Lambda表达式也可以访问定义在主体代码外部的变量,但对于局部变量,它也只能访问final类型的变量,与匿名内部类的区别是,它不要求变量声明为final,但变量事实上不能被重新赋值。
Java会将msg的值作为参数传递给Lambda表达式,为Lambda表达式建立一个副本,它的代码访问的是这个副本,而不是外部声明的msg变量。
Lambda表达式与匿名内部类很像,主要就是简化了语法,但它不是语法糖,内部实现不是内部类而是函数式接口。Java会为每个匿名内部类生成一个类,但Lambda表达式不会。
//普通方式1--------------------------------
class MThread implements Runnable {
@Override
public void run() {
System.out.println("Runnable------1-------------");
}
}
public class Test {
public static void main(String[] args) {
//方式1
MThread mThread = new MThread();
Thread thread = new Thread(mThread);
thread.setName("线程1");
thread.start();
}
}
//匿名内部类 方式2--------------------------------
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("Runnable------2-------------");
}
}, "线程2").start();
//lambda表达式 方式3--------------------------------
new Thread(() -> System.out.println("Runnable------3-------------"),"线程3").start();1.3 函数式接口
Java 8 引入了函数式接口的概念,函数式接口也是接口,但只能有一个抽象方法,前面提及的接口都只有一个抽象方法,都是函数式接口。之所以强调是“抽象”方法,是因为Java 8中还允许定义静态方法和默认方法。Lambda表达式可以赋值给函数式接口,比如:
FileFilter filter = path -> path.getName().endsWith(".txt");
FilenameFilter fileNameFilter = (dir, name) -> name.endsWith(".txt");
Comparator<File> comparator = (f1, f2) ->
f1.getName().compareTo(f2.getName());
Runnable task = () -> System.out.println("hello world");如果看这些接口的定义,会发现它们都有一个注解@FunctionalInterface,比如:

@FunctionalInterface用于清晰地告知使用者这是一个函数式接口,不过,这个注解不是必需的,不加,只要只有一个抽象方法,也是函数式接口。但如果加了,而又定义了超过一个抽象方法,Java编译器会报错,这类似于我们之前介绍的Override注解。
1.4 预定义的函数式接口
Java 8定义了大量的预定义函数式接口,用于常见类型的代码传递,这些函数定义在包java.util.function下,主要接口如下:
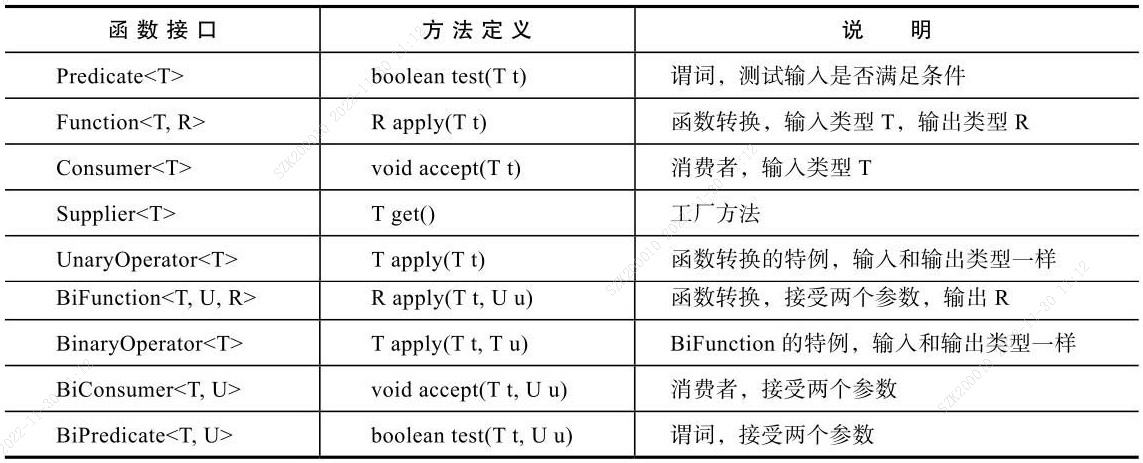
对于基本类型boolean、int、long和double,为避免装箱/拆箱,Java 8提供了一些专门的函数,比如,int相关的部分函数如下:
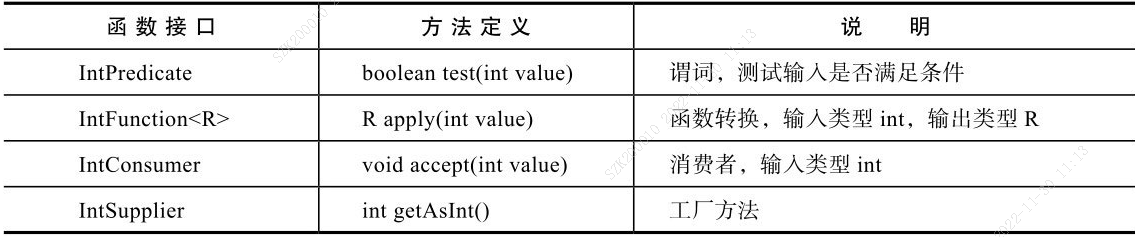
这些函数有什么用呢?它们被大量用于Java 8的函数式数据处理Stream相关的类中,即使不使用Stream,也可以在自己的代码中直接使用这些预定义的函数。
Function 示例
为便于举例,我们先定义一个简单的学生类Student,它有name和score两个属性,如下所示。
static class Student {
String name;
double score;
}我们省略了构造方法和getter/setter方法。有一个学生列表:
List<Student> students = Arrays.asList(new Student[] {
new Student("zhangsan", 89d), new Student("lisi", 89d),
new Student("wangwu", 98d) });列表处理的一个常见需求是转换。
比如,给定一个学生列表,需要返回名称列表,或者将名称转换为大写返回,可以借助Function写一个通用的方法,如下所示:
public static <T, R> List<R> map(List<T> list, Function<T, R> mapper) {
List<R> retList = new ArrayList<>(list.size());
for(T e : list) {
retList.add(mapper.apply(e));
}
return retList;
}根据学生列表返回名称列表的代码为:
List<String> names = map(students, t -> t.getName());将学生名称转换为大写的代码为:
students = map(students, t -> new Student(
t.getName().toUpperCase(), t.getScore()));以上示例主要用于演示函数式接口的基本概念,实际中可以直接使用流API。
1.5 方法引用
Lambda 表达式经常用于调用对象的某个方法,比如:
List<String> names = map(students, t -> t.getName());这时,它可以进一步简化,如下所示:
List<String> names = map(students, Student::getName);Student::getName 这种写法是 Java 8 引入的一种新语法,称为方法引用。它是 Lambda 表达式的一种简写方法,由 ::分隔为两部分,前面是类名或变量名,后面是方法名。方法可以是实例方法,也可以是静态方法,但含义不同。
Lambda 方法引用举例
还是以Student为例,先增加一个静态方法:
public static String getCollegeName(){
return "Laoma School";
}对于静态方法,如下两条语句是等价的:
1. Supplier<String> s = Student::getCollegeName;
2. Supplier<String> s = () -> Student.getCollegeName();它们的参数都是空,返回类型为String。
而对于实例方法,它的第一个参数就是该类型的实例,比如,如下两条语句是等价的:
1. Function<Student, String> f = Student::getName;
2. Function<Student, String> f = (Student t) -> t.getName();对于Student::setName,它是一个BiConsumer,即如下两条语句是等价的:
1. BiConsumer<Student, String> c = Student::setName;
2. BiConsumer<Student, String> c = (t, name) -> t.setName(name);如果方法引用的第一部分是变量名,则相当于调用那个对象的方法。比如,假定t是一个Student类型的变量,则如下两条语句是等价的:
1. Supplier<String> s = t::getName;
2. Supplier<String> s = () -> t.getName();下面两条语句也是等价的:
1. Consumer<String> consumer = t::setName;
2. Consumer<String> consumer = (name) -> t.setName(name);对于构造方法,方法引用的语法是<类名>::new,如Student::new,即下面两条语句等价:
1. BiFunction<String, Double, Student> s = (name, score) -> new Student(name, score);
2. BiFunction<String, Double, Student> s = Student::new;1.6 函数的复合
函数式接口和Lambda表达式还可用作方法的返回值,传递代码回调用者,将这两种用法结合起来,可以构造复合的函数,使程序简洁易读。
Comparator 中的复合方法
Comparator接口定义了如下静态方法:
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(
Function<? super T, ? extends U> keyExtractor) {
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}这个方法是什么意思呢?它用于构建一个Comparator,比如,在前面的例子中,对文件按照文件名排序的代码为:
Arrays.sort(files, (f1, f2) -> f1.getName().compareTo(f2.getName()));使用comparing方法,代码可以简化为:
Arrays.sort(files, Comparator.comparing(File::getName));这样,代码的可读性就大大增强了。
Comparator还有很多默认方法,我们看两个:
default Comparator<T> reversed() {
return Collections.reverseOrder(this);
}
default Comparator<T> thenComparing(Comparator<? super T> other) {
Objects.requireNonNull(other);
return (Comparator<T> & Serializable) (c1, c2) -> {
int res = compare(c1, c2);
return (res ! = 0) ? res : other.compare(c1, c2);
};
}reversed返回一个新的Comparator,按原排序逆序排。thenComparing也返回一个新的Comparator,在原排序认为两个元素排序相同的时候,使用传递的Comparator other进行比较。
看一个使用的例子,将学生列表按照分数倒序排(高分在前),分数一样的按照名字进行排序:
students.sort(Comparator.comparing(Student::getScore)
.reversed()
.thenComparing(Student::getName));2. 函数式数据处理:基本用法
Java 8 引入了一套新的类库,位于包 java.util.stream 下,称为 Stream API。
接口Stream类似于一个迭代器,但提供了更为丰富的操作,Stream API的主要操作就定义在该接口中。Java 8给Collection接口增加了两个默认方法,它们可以返回一个Stream,如下所示:
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
default Stream<E> parallelStream() {
return StreamSupport.stream(spliterator(), true);
}stream()返回的是一个顺序流,parallelStream()返回的是一个并行流。顺序流就是由一个线程执行操作。而并行流背后可能有多个线程并行执行,与之前介绍的并发技术不同,使用并行流不需要显式管理线程,使用方法与顺序流是一样的。
2.1 基本示例
1)基本过滤
返回学生列表中90分以上的,传统上的代码一般是这样:
List<Student> above90List = new ArrayList<>();
for(Student t : students) {
if(t.getScore() > 90) {
above90List.add(t);
}
}使用Stream API,代码可以这样:
List<Student> above90List = students.stream()
.filter(t->t.getScore()>90)
.collect(Collectors.toList());先通过stream()得到一个Stream对象,然后调用Stream上的方法,filter()过滤得到90分以上的,它的返回值依然是一个Stream,为了转换为List,调用了collect方法并传递了一个Collectors.toList(),表示将结果收集到一个List中。
2)基本转换
根据学生列表返回名称列表,传统上的代码一般是这样:
List<String> nameList = new ArrayList<>(students.size());
for(Student t : students) {
nameList.add(t.getName());
}使用Stream API,代码可以这样:
List<String> nameList = students.stream()
.map(Student::getName).collect(Collectors.toList());这里使用了 Stream 的 map 函数,它的参数是一个 Function 函数式接口,这里传递了方法引用。
3)基本的过滤和转换组合
返回90分以上的学生名称列表,传统上的代码一般是这样:
List<String> nameList = new ArrayList<>();
for(Student t : students) {
if(t.getScore() > 90) {
nameList.add(t.getName());
}
}使用Stream API,可以将基本函数filter()和map()结合起来,代码可以这样:
List<String> above90Names = students.stream()
.filter(t->t.getScore()>90).map(Student::getName)
.collect(Collectors.toList());这种组合利用基本函数、声明式实现集合数据处理功能的编程风格,就是函数式数据处理。
调用 filter() 和 map() 不会执行任何实际的操作,它们只是在构建操作的流水线,调用 collect 才会触发实际的遍历执行,在一次遍历中完成过滤、转换以及收集结果的任务。所以不用担心它的性能问题。
像 filter 和 map 这种不实际触发执行、用于构建流水线、返回 Stream 的操作称为中间操作(intermediate operation),而像 collect 这种触发实际执行、返回具体结果的操作称为终端操作(terminal operation)。
2.2 中间操作
除了 filter 和 map, Stream API 的中间操作还有 distinct、sorted、skip、limit、peek、mapToLong、mapToInt、mapToDouble、flatMap 等。
1)distinct
distinct返回一个新的Stream,过滤重复的元素,只留下唯一的元素,是否重复是根据equals方法来比较的,distinct可以与其他函数(如filter、map)结合使用。比如,返回字符串列表中长度小于3的字符串、转换为小写、只保留唯一的,代码可以为:
List<String> list = Arrays.asList(new String[]{"abc", "def", "hello", "Abc"});
List<String> retList = list.stream()
.filter(s->s.length()<=3).map(String::toLowerCase).distinct()
.collect(Collectors.toList());虽然都是中间操作,但distinct与filter和map是不同的。filter和map都是无状态的,对于流中的每一个元素,处理都是独立的,处理后即交给流水线中的下一个操作;distinct不同,它是有状态的,在处理过程中,它需要在内部记录之前出现过的元素,如果已经出现过,即重复元素,它就会过滤掉,不传递给流水线中的下一个操作。对于顺序流,内部实现时,distinct操作会使用HashSet记录出现过的元素,如果流是有顺序的,需要保留顺序,会使用LinkedHashSet。
2)sorted
有两个sorted方法:
Stream<T> sorted()
Stream<T> sorted(Comparator<? super T> comparator)它们都对流中的元素排序,都返回一个排序后的Stream。第一个方法假定元素实现了Comparable接口,第二个方法接受一个自定义的Comparator。比如,过滤得到90分以上的学生,然后按分数从高到低排序,分数一样的按名称排序,代码为:
List<Student> studentList = students.stream()
.filter(t -> t.getScore() > 90)
.sorted(Comparator.comparing(Student::getScore)
.reversed()
.thenComparing(Student::getName))
.collect(Collectors.toList());这里,使用了Comparator的comparing、reversed和thenComparing构建了Comparator。
与distinct一样,sorted也是一个有状态的中间操作,在处理过程中,需要在内部记录出现过的元素。其不同是,每碰到流中的一个元素,distinct都能立即做出处理,要么过滤,要么马上传递给下一个操作;sorted需要先排序,为了排序,它需要先在内部数组中保存碰到的每一个元素,到流结尾时再对数组排序,然后再将排序后的元素逐个传递给流水线中的下一个操作。
3)skip / limit
它们的定义为:
Stream<T> skip(long n)
Stream<T> limit(long maxSize)skip跳过流中的n个元素,如果流中元素不足n个,返回一个空流,limit限制流的长度为maxSize。比如,将学生列表按照分数排序,返回第3名到第5名,代码为:
List<Student> list = students.stream()
.sorted(Comparator.comparing(Student::getScore)
.reversed())
.skip(2)
.limit(3)
.collect(Collectors.toList());skip和limit都是有状态的中间操作。对前n个元素,skip的操作就是过滤,对后面的元素,skip就是传递给流水线中的下一个操作。limit的一个特点是:它不需要处理流中的所有元素,只要处理的元素个数达到maxSize,后面的元素就不需要处理了,这种可以提前结束的操作称为短路操作。
skip 和 limit 只能根据元素数目进行操作,Java 9 增加了两个新方法,相当于更为通用的 skip 和 limit:
//通用的skip,在谓词返回为true的情况下一直进行skip操作,直到某次返回false
default Stream<T> dropWhile(Predicate<? super T> predicate)
//通用的limit,在谓词返回为true的情况下一直接受,直到某次返回false
default Stream<T> takeWhile(Predicate<? super T> predicate)4)peek
peek的定义为:
Stream<T> peek(Consumer<? super T> action)它返回的流与之前的流是一样的,没有变化,但它提供了一个Consumer,会将流中的每一个元素传给该Consumer。这个方法的主要目的是支持调试,可以使用该方法观察在流水线中流转的元素,比如:
List<String> above90Names = students.stream()
.filter(t -> t.getScore() > 90)
.peek(System.out::println)
.map(Student::getName)
.collect(Collectors.toList());
System.out.println("above90Names结果:" + above90Names);
打印结果:
Student(name=liHua, score=100.0)
Student(name=wangwu, score=98.0)
above90Names结果:[liHua, wangwu]5)mapToLong / mapToInt / mapToDouble
map函数接受的参数是一个Function<T, R>,为避免装箱/拆箱,提高性能,Stream 还有如下返回基本类型特定流的方法:
DoubleStream mapToDouble(ToDoubleFunction<? super T> mapper)
IntStream mapToInt(ToIntFunction<? super T> mapper)
LongStream mapToLong(ToLongFunction<? super T> mapper)DoubleStream / IntStream / LongStream 是基本类型特定的流,有一些专门的更为高效的方法。比如,求学生列表的分数总和,代码为:
double sum = students.stream().mapToDouble(Student::getScore).sum();6)flatMap
flatMap 的定义为:
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper)它接受一个函数 mapper,对流中的每一个元素,mapper 会将该元素转换为一个流 Stream,然后把新生成流的每一个元素传递给下一个操作。比如:
List<String> lines = Arrays.asList(new String[]{"hello abc", "Janet Ruby"});
List<String> words = lines.stream()
.flatMap(line -> Arrays.stream(line.split("\\s+")))
.collect(Collectors.toList());
System.out.println(words); //[hello, abc, Janet, Ruby]这里的 mappe r将一行字符串按空白符分隔为了一个单词流,Arrays.stream可以将一个数组转换为一个流,输出为:
[hello, abc, Janet, Ruby]可以看出,实际上,flatMap完成了一个1到n的映射。
2.3 终端操作
中间操作不触发实际的执行,返回值是Stream,而终端操作触发执行,返回一个具体的值,除了collect, Stream API的终端操作还有max、min、count、allMatch、anyMatch、noneMatch、findFirst、findAny、forEach、toArray、reduce 等。
1)max / min
max / min 的定义为:
Optional<T> max(Comparator<? super T> comparator)
Optional<T> min(Comparator<? super T> comparator)它们返回流中的最大值/最小值,它们的返回值类型是Optional<T>,而不是T。
java.util.Optional是Java 8引入的一个新类,它是一个泛型容器类,内部只有一个类型为T的单一变量value,可能为null,也可能不为null。Optional有什么用呢?它用于准确地传递程序的语义,它清楚地表明,其代表的值可能为null,程序员应该进行适当的处理。
Optional定义了一些方法,比如:
//value不为null时返回true
public boolean isPresent()
//返回实际的值,如果为null,抛出异常NoSuchElementException
public T get()
//如果value不为null,返回value,否则返回other
public T orElse(T other)
//构建一个空的Optional, value为null
public static<T> Optional<T> empty()
//构建一个非空的Optional, 参数value不能为null
public static <T> Optional<T> of(T value)
//构建一个Optional,参数value可以为null,也可以不为null
public static <T> Optional<T> ofNullable(T value)在max/min的例子中,通过声明返回值为Optional,我们可以知道具体的返回值不一定存在,这发生在流中不含任何元素的情况下。
看个简单的例子,返回分数最高的学生,代码为:
// 这里,假定students不为空。
Student student = students.stream()
.max(Comparator.comparing(Student::getScore)
.reversed())
.get();2)count
count很简单,就是返回流中元素的个数。比如,统计大于90分的学生个数,代码为:
long above90Count = students.stream().filter(t -> t.getScore() > 90).count();3)allMatch/anyMatch/noneMatch
这几个函数都接受一个谓词Predicate,返回一个boolean值,用于判定流中的元素是否满足一定的条件。它们的区别是:
- allMatch:只有在流中所有元素都满足条件的情况下才返回true。
- anyMatch:只要流中有一个元素满足条件就返回true。
- noneMatch:只有流中所有元素都不满足条件才返回true。
如果流为空,那么这几个函数的返回值都是true。
比如,判断是不是所有学生都及格了(不小于60分),代码可以为:
boolean allPass = students.stream().allMatch(t -> t.getScore() >= 60);这几个操作都是短路操作,不一定需要处理所有元素就能得出结果,比如,对于all-Match,只要有一个元素不满足条件,就能返回false。
4)findFirst / findAny
它们的定义为:
Optional<T> findFirst()
Optional<T> findAny()它们的返回类型都是Optional,如果流为空,返回Optional.empty()。findFirst返回第一个元素,而findAny返回任一元素,它们都是短路操作。随便找一个不及格的学生,代码可以为:
Optional<Student> failStudent = students.stream()
.filter(t -> t.getScore() < 60)
.findAny();
if (failStudent.isPresent()) {
//处理不及格的学生
}5)forEach
有两个 forEach 方法:
void forEach(Consumer<? super T> action)
void forEachOrdered(Consumer<? super T> action)它们都接受一个Consumer,对流中的每一个元素,传递元素给Consumer。区别在于:在并行流中,forEach不保证处理的顺序,而forEachOrdered会保证按照流中元素的出现顺序进行处理。
比如,逐行打印大于90分的学生,代码可以为:
students.stream().filter(t -> t.getScore() > 90).forEach(System.out::println);![]()
6)toArray
toArray 将流转换为数组,有两个方法:
Object[] toArray()
<A> A[] toArray(IntFunction<A[]> generator)不带参数的toArray返回的数组类型为Object[],这通常不是期望的结果,如果希望得到正确类型的数组,需要传递一个类型为IntFunction的generator。IntFunction的定义为:
public interface IntFunction<R> {
R apply(int value);
}generator接受的参数是流的元素个数,它应该返回对应大小的正确类型的数组。
比如,获取90分以上的学生数组,代码可以为:
Student[] above90Arr = students.stream()
.filter(t -> t.getScore() > 90)
.toArray(Student[]::new);Student[]::new 就是一个类型为 IntFunction<Student[]>的generator。
7)reduce
reduce代表归约或者叫折叠,它是 max/min/count 的更为通用的函数,将流中的元素归约为一个值。有三个reduce函数:
Optional<T> reduce(BinaryOperator<T> accumulator);
T reduce(T identity, BinaryOperator<T> accumulator);
<U> U reduce(U identity, BiFunction<U, ? super T, U> accumulator, BinaryOperator<U> combiner);第一个reduce函数基本等同于调用:
boolean foundAny = false;
T result = null;
for(T element : this stream) {
if(! foundAny) {
foundAny = true;
result = element;
}
else
result = accumulator.apply(result, element);
}
return foundAny ? Optional.of(result) : Optional.empty();比如,使用 reduce 函数求分数最高的学生,代码可以为:
Student topStudent = students.stream()
.reduce((accu, t) -> {
if (accu.getScore() >= t.getScore()) {
return accu;
} else {
return t;
}
})
.get();第二个reduce函数多了一个identity参数,表示初始值,它基本等同于调用:
T result = identity;
for(T element : this stream)
result = accumulator.apply(result, element)
return result;第一个和第二个reduce函数的返回类型只能是流中元素的类型,而第三个reduce函数更为通用,它的归约类型可以自定义,另外,它多了一个combiner参数。combiner用在并行流中,用于合并子线程的结果。对于顺序流,它基本等同于调用:
U result = identity;
for(T element : this stream)
result = accumulator.apply(result, element)
return result;注意与第二个reduce函数相区分,它的结果类型不是T,而是U。
比如,使用reduce函数计算学生分数的和,代码可以为:
double sumScore = students.stream().reduce(0d,
(sum, t) -> sum += t.getScore(),
(sum1, sum2) -> sum1 += sum2
);从以上可以看出,reduce 函数虽然更为通用,但比较费解,难以使用,一般情况下应该优先使用其他函数。collect函数比reduce函数更为通用、强大和易用。
2.4 构建流
前面我们主要使用的是Collection的stream方法,换做parallelStream方法,就会使用并行流,接口方法都是通用的。但并行流内部会使用多线程,线程个数一般与系统的CPU核数一样,以充分利用CPU的计算能力。
进一步来说,并行流内部会使用Java 7引入的fork/join框架,即处理由fork和join两个阶段组成,fork就是将要处理的数据拆分为小块,多线程按小块进行并行计算,join就是将小块的计算结果进行合并。使用并行流,不需要任何线程管理的代码,就能实现并行。
除了通过Collection接口的stream/parallelStream获取流,还有一些其他方式可以获取流。Arrays有一些stream方法,可以将数组或子数组转换为流,比如:
public static IntStream stream(int[] array)
public static DoubleStream stream(double[] array, int startInclusive, int endExclusive)
public static <T> Stream<T> stream(T[] array)输出当前目录下所有普通文件的名字,代码可以为:
File[] files = new File(".").listFiles();
Arrays.stream(files).filter(File::isFile).map(File::getName)
.forEach(System.out::println);Stream也有一些静态方法,可以构建流,比如:
//返回一个空流
public static<T> Stream<T> empty()
//返回只包含一个元素t的流
public static<T> Stream<T> of(T t)
//返回包含多个元素values的流
public static<T> Stream<T> of(T... values)
//通过Supplier生成流,流的元素个数是无限的
public static<T> Stream<T> generate(Supplier<T> s)
//同样生成无限流,第一个元素为seed,第二个为f(seed),第三个为f(f(seed)),以此类推
public static<T> Stream<T> iterate(final T seed, final UnaryOperator<T> f)输出10个随机数,代码可以为:
Stream.generate(()->Math.random()).limit(10).forEach(System.out::println);输出100个递增的奇数,代码可以为:
Stream.iterate(1, t->t+2).limit(100).forEach(System.out::println);3. 函数式数据处理:强大方便的收集器
对于 collect 方法,前面只是演示了其最基本的应用,它还有很多强大的功能,比如,可以分组统计汇总,实现类似数据库查询语言 SQL 中的 group by 功能。
在上节中,过滤得到90分以上的学生列表,代码是这样的:
List<Student> above90List = students.stream().filter(t->t.getScore()>90)
.collect(Collectors.toList());collect(Collectors.toList()) 背后的伪代码如下所示:
List<T> container = new ArrayList<>();
for(T t : data)
container.add(t);
return container;3.1 容器收集器
与 toList 类似的容器收集器还有 toSet、toCollection、toMap 等
1)toSet
toSet 的使用与 toList 类似,只是它可以排重。
toList 背后的容器是 ArrayList,toSet 背后的容器是 HashSet。
2)toCollection
toCollection 是一个通用的容器收集器,可以用于任何 Collection 接口的实现类,它接受一个工厂方法 Supplier 作为参数。
比如,如果希望排重但又希望保留出现的顺序,可以使用 LinkedHashSet, Collector 可以这么创建:
Collectors.toCollection(LinkedHashSet::new)3)toMap
toMap将元素流转换为一个Map,我们知道,Map有键和值两部分,toMap至少需要两个函数参数,一个将元素转换为键,另一个将元素转换为值。
举例,将学生流转换为学生名称和分数的Map,代码可以为:
Map<String, Double> nameScoreMap = students.stream().collect(
Collectors.toMap(Student::getName, Student::getScore));这里,Student::getName 是 keyMapper, Student::getScore 是 valueMapper。
再比如,假定Student的主键是id,希望转换学生流为学生id和学生对象的Map,代码可以为:
Map<String, Student> byIdMap = students.stream().collect(
Collectors.toMap(Student::getId, t -> t));t->t是valueMapper,表示值就是元素本身。这个函数用得比较多,接口Function定义了一个静态函数identity表示它。也就是说,上面的代码可以替换为:
Map<String, Student> byIdMap = students.stream().collect(
Collectors.toMap(Student::getId, Function.identity()));上面的toMap假定元素的键不能重复,如果有重复的,会抛出异常。
比如 希望得到字符串与其长度的Map,但由于包含重复字符串"abc",程序会抛出异常。这种情况下,我们希望的是程序忽略后面重复出现的元素,这时,可以使用另一个toMap函数(相比前面的toMap,它接受一个额外的参数mergeFunction,它用于处理冲突):
Map<String, Integer> strLenMap = Stream.of("abc", "hello", "abc").collect(
Collectors.toMap(Function.identity(), t->t.length(), (oldValue, value)->value));有时,我们可能希望合并新值与旧值,比如一个联系人列表,对于相同的联系人,我们希望合并电话号码,mergeFunction可以定义为:
BinaryOperator<String> mergeFunction = (oldPhone, phone)->oldPhone+", "+phone;3.2 字符串收集器
除了将元素流收集到容器中,另一个常见的操作是收集为一个字符串。比如,获取所有的学生名称,用逗号连接起来,传统上代码看上去像这样:
StringBuilder sb = new StringBuilder();
for(Student t : students){
if(sb.length()>0){
sb.append(", ");
}
sb.append(t.getName());
}
return sb.toString();针对这种常见的需求,Collectors提供了joining收集器,比如:
public static Collector<CharSequence, ? , String> joining()
public static Collector<CharSequence, ? , String> joining(CharSequence delimiter, CharSequence prefix, CharSequence suffix)第一个就是简单地把元素连接起来,第二个支持一个分隔符,还可以给整个结果字符串加前缀和后缀,比如:
String result = Stream.of("Janet", "Ruby", "Leo")
.collect(Collectors.joining(", ", "[", "]"));
System.out.println(result); //[Janet, Ruby, Leo]
String result1 = students.stream().map(t -> t.getName()).collect(Collectors.joining());
System.out.println(result1); //liHuawangwulisizhangsanXiaoMei
String result2 = students.stream().map(Student::getName).collect(Collectors.joining(",", "[", "]"));
System.out.println(result2); //[liHua,wangwu,lisi,zhangsan,XiaoMei]3.3 分组
分组类似于数据库查询语言SQL中的group by语句,它将元素流中的每个元素分到一个组,可以针对分组再进行处理和收集。
为便于举例,我们先修改下学生类Student,增加一个字段grade表示年级:
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private String name; //名字
private double score; //分数
private String grade; //年级
public static String getCollegeName() {
return "Laoma School";
}
}1)基本用法
将学生流按照年级进行分组,代码为:
Map<String, List<Student>> groups = students.stream()
.collect(Collectors.groupingBy(Student::getGrade));
System.out.println(groups); //{1=[Student(name=zhangsan, score=89.0, grade=1), Student(name=lisi, score=89.0, grade=1)], 2=[Student(name=liHua, score=100.0, grade=2), Student(name=wangwu, score=98.0, grade=2)], 3=[Student(name=XiaoMei, score=59.0, grade=3)]}
代码等同于:
Map<String, List<Student>> groups = new HashMap<>();
for(Student t : students) {
String key = t.getGrade();
List<Student> container = groups.get(key);
if(container == null) {
container = new ArrayList<>();
groups.put(key, container);
}
container.add(t);
}2)分组计数、找最大/最小元素
为了便于使用 Collectors 中的方法,我们将其中的方法静态导入:
import static java.util.stream.Collectors.*;统计每个年级的学生个数,代码可以为:
Map<String, Long> gradeCountMap = students.stream().collect(
groupingBy(Student::getGrade, counting()));
System.out.println(gradeCountMap); //{1=2, 2=2, 3=1}统计一个单词流中每个单词的个数,按出现顺序排序,代码可以为:
Map<String, Long> wordCountMap =
Stream.of("hello", "world", "abc", "hello").collect(
groupingBy(Function.identity(), LinkedHashMap::new, counting()));
System.out.println(wordCountMap); //{hello=2, world=1, abc=1}获取每个年级分数最高的一个学生,代码可以为:
Map<String, Optional<Student>> topStudentMap = students.stream().collect(
groupingBy(Student::getGrade,
maxBy(Comparator.comparing(Student::getScore))));
System.out.println(topStudentMap); //{1=Optional[Student(name=zhangsan, score=89.0, grade=1)], 2=Optional[Student(name=liHua, score=100.0, grade=2)], 3=Optional[Student(name=XiaoMei, score=59.0, grade=3)]}需要说明的是,这个分组收集结果是Optional<Student>,而不是Student,这是因为maxBy处理的流可能是空流,但对我们的例子,这是不可能的。为了直接得到Student,可以使用Collectors的另一个收集器collectingAndThen,在得到Optional<Student>后调用Optional的get方法,如下所示:
Map<String, Student> topStudentMap1 = students.stream().collect(
groupingBy(Student::getGrade, collectingAndThen(
maxBy(Comparator.comparing(Student::getScore)), Optional::get)));
System.out.println(topStudentMap1); //{1=Student(name=zhangsan, score=89.0, grade=1), 2=Student(name=liHua, score=100.0, grade=2), 3=Student(name=XiaoMei, score=59.0, grade=3)}3)分组数值统计
除了基本的分组计数,还经常需要进行一些分组数值统计,比如求学生分数的和、平均分、最高分、最低分等、针对int、long和double类型,Collectors提供了专门的收集器,如:
//求平均值,int和long也有类似方法
public static <T> Collector<T, ? , Double> averagingDouble(ToDoubleFunction<? super T> mapper)
//求和,long和double也有类似方法
public static <T> Collector<T, ? , Integer> summingInt(ToIntFunction<? super T> mapper)
//求多种汇总信息,int和double也有类似方法
//LongSummaryStatistics包括个数、最大值、最小值、和、平均值等多种信息
public static <T> Collector<T, ? , LongSummaryStatistics> summarizingLong(ToLongFunction<? super T> mapper)比如,按年级统计学生分数信息,代码可以为:
Map<String, DoubleSummaryStatistics> gradeScoreStat =
students.stream().collect(groupingBy(Student::getGrade,
summarizingDouble(Student::getScore)));
System.out.println(gradeScoreStat); //{1=DoubleSummaryStatistics{count=2, sum=178.000000, min=89.000000, average=89.000000, max=89.000000}, 2=DoubleSummaryStatistics{count=2, sum=198.000000, min=98.000000, average=99.000000, max=100.000000}, 3=DoubleSummaryStatistics{count=1, sum=59.000000, min=59.000000, average=59.000000, max=59.000000}}
4)分组内的 map
对于每个分组内的元素,我们感兴趣的可能不是元素本身,而是它的某部分信息。在Stream API中,Stream有map方法,可以将元素进行转换,Collectors也为分组元素提供了函数mapping。
如,对学生按年级分组,得到学生名称列表,代码可以为:
Map<String, List<String>> gradeNameMap =
students.stream().collect(groupingBy(Student::getGrade,
mapping(Student::getName, toList())));
System.out.println(gradeNameMap); //{1=[zhangsan, lisi], 2=[liHua, wangwu], 3=[XiaoMei]}5)分组结果处理(filter / sort / skip / limit)
对分组后的元素,我们可以计数,找最大/最小元素,计算一些数值特征,还可以转换(map)后再收集,那可不可以像Stream API一样,排序(sort)、过滤(filter)、限制返回元素(skip/limit)呢?Collector没有专门的收集器,但有一个通用的方法:
public static<T, A, R, RR> Collector<T, A, RR> collectingAndThen( Collector<T, A, R> downstream, Function<R, RR> finisher)将学生按年级分组,分组内的学生按照分数由高到低进行排序,利用这个方法,代码可以为:
代码附录:
第一部分,Student 类加 grade 属性之前:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private String name; //名字
private double score; //分数
public static String getCollegeName() {
return "Laoma School";
}
} public static void main(String[] args) {
//创建学习数组
List<Student> students = Arrays.asList(new Student[]{
new Student("zhangsan", 89d),
new Student("lisi", 89d),
new Student("liHua", 100d),
new Student("XiaoMei", 59d),
new Student("wangwu", 98d)});
//---------------中间操作----------------------------------
//1. 将学生列表按照分数倒序排(高分在前),分数一样的按照名字进行排序
students.sort(Comparator.comparing(Student::getScore)
.reversed()
.thenComparing(Student::getName));
//System.out.println(students); //[Student(name=liHua, score=100.0), Student(name=wangwu, score=98.0), Student(name=lisi, score=89.0), Student(name=zhangsan, score=89.0), Student(name=XiaoMei, score=59.0)]
//2.返回学生列表中90分以上的
List<Student> above90List = students.stream()
.filter(t -> t.getScore() > 90).collect(Collectors.toList());
//System.out.println(above90List); //[Student(name=liHua, score=100.0), Student(name=wangwu, score=98.0)]
//3.根据学生列表返回名称列表
List<String> nameList = students.stream()
.map(Student::getName).collect(Collectors.toList());
//System.out.println(nameList); //[liHua, wangwu, lisi, zhangsan, XiaoMei]
//4. 返回字符串列表中长度小于3的字符串、转换为小写、只保留唯一的 (distinct:过滤)
List<String> list = Arrays.asList(new String[]{"abc", "def", "hello", "Abc"});
List<String> retList = list.stream()
.filter(s -> s.length() <= 3)
.map(String::toLowerCase)
.distinct()
.collect(Collectors.toList());
//System.out.println(retList); //[abc, def]
//5. 过滤得到90分以上的学生,然后按分数从高到低排序,分数一样的按名称排序
List<Student> studentList = students.stream()
.filter(t -> t.getScore() > 90)
.sorted(Comparator.comparing(Student::getScore)
.reversed()
.thenComparing(Student::getName))
.collect(Collectors.toList());
//System.out.println(studentList); //[Student(name=liHua, score=100.0), Student(name=wangwu, score=98.0)]
//6. 将学生列表按照分数排序,返回第3名到第5名
List<Student> sList = students.stream()
.sorted(Comparator.comparing(Student::getScore)
.reversed())
.skip(2)
.limit(3)
.collect(Collectors.toList());
//System.out.println(sList); //[Student(name=lisi, score=89.0), Student(name=zhangsan, score=89.0), Student(name=XiaoMei, score=59.0)]
//7. 求学生列表的分数总和
double studentSum = students.stream().mapToDouble(Student::getScore).sum();
//System.out.println("学生列表的分数总和:"+studentSum); //学生列表的分数总和:435.0
//---------------终端操作----------------------------------
//1. 返回分数最高的学生 这里,假定students不为空。
Student student = students.stream()
.max(Comparator.comparing(Student::getScore)
.reversed())
.get();
//System.out.println(student); //Student(name=XiaoMei, score=59.0)
//2. 统计大于90分的学生个数
long above90Count = students.stream().filter(t -> t.getScore() > 90).count();
//System.out.println(above90Count); //2
//3. 判断是不是所有学生都及格了(不小于60分)
boolean allPass = students.stream().allMatch(t -> t.getScore() >= 60);
//System.out.println(allPass); //false
//4. 随便找一个不及格的学生
Optional<Student> failStudent = students.stream()
.filter(t -> t.getScore() < 60)
.findAny();
if (failStudent.isPresent()) {
//处理不及格的学生
//System.out.println("这个人不及格:"+failStudent); //这个人不及格:Optional[Student(name=XiaoMei, score=59.0)]
}
//5. 逐行打印大于90分的学生
//students.stream().filter(t -> t.getScore() > 90).forEach(System.out::println);
//6. 获取90分以上的学生数组
Student[] above90Arr = students.stream()
.filter(t -> t.getScore() > 90)
.toArray(Student[]::new);
//---------------字符串收集器----------------------------------
//9. 获取所有的学生名称,用逗号连接起来
String result = Stream.of("Janet", "Ruby", "Leo")
.collect(Collectors.joining(", ", "[", "]"));
System.out.println(result); //[Janet, Ruby, Leo]
String result1 = students.stream().map(t -> t.getName()).collect(Collectors.joining());
System.out.println(result1); //liHuawangwulisizhangsanXiaoMei
String result2 = students.stream().map(Student::getName).collect(Collectors.joining(",", "[", "]"));
System.out.println(result2); //[liHua,wangwu,lisi,zhangsan,XiaoMei]
}第二部分,加 grade 之后:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Student {
private String name; //名字
private double score; //分数
private String grade; //年级
public static String getCollegeName() {
return "Laoma School";
}
}





![[附源码]计算机毕业设计springboot旅游度假村管理系统](https://img-blog.csdnimg.cn/0112040053aa4e77abe8afae3a75f4b1.png)





![[附源码]计算机毕业设计springboot家庭整理服务管理系统](https://img-blog.csdnimg.cn/fe13971d4f0349998ae33121fa517989.png)