数据库Mysql
内容管理
- MySQL填充亿级数据
- Insert into select
- 存储过程loop insert
- Loadfile 导入CVS文件
- MySQL基准测试: sysbench、mysqlslap
- sysbench
- mysqlslap
- SQL优化
- 分页查询优化
- 慢SQL日志工具mysqldumpslow
- MySQL主从复制
- MySQL主从复制 knowledge
- MySQL二进制日志
- log_bin和sql_log_bin
- 二进制文件操作
- 使用binary bin log 恢复MySQL
- MySQL主从复制架构
- show master status 查看主库状态
- show slave statsu 查看从库状态
- flush table with read lock 主库只读锁
- slave stop 停止从库备份行为
- mysqldump 轻量级备份【文件传输】
- scp 备份转移
- 从库新建空database
- 通过reset salve 命令方式将从库连接到主库
- mysql将备份导入从库的数据库
- set global read_only = 1 从库开启只读模式
- slave start 启动从库
- unlock tables 解锁主库增删改操作
- 检查主从复制是否
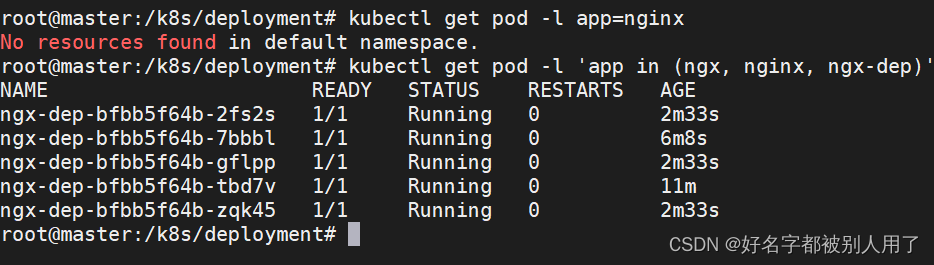
- SpringBoot整合MySQL主从架构【原生AOP]
- MySQL集群监控 Prometheus + Grafana
- 分库分表 【Sharding】
- 分库分表操作方式
- 垂直分表
- 垂直分库
- 水平分库
- 水平分表
- 数据分片
- 分片算法
- 分片策略
- 分库分表 的problem
- Sharding-JDBC 数据分片,读写分离
- Sharding-jdbc使用
- 数据源配置
- 分片策略配置 -- 完整配置,使用sharding
本文着重介绍分布式微服务环境下MySQL的高可用部署
前面的文章是基础bg,这篇文章将介绍微服务下的MySQL,亿级数据填充,高可用集群,慢查询日志,SQL的高并发测试
java中性能优化捉妖就是考虑GC,优化循环、业务,减少内存的开销OOM(比如20万长度的List)减少从数据源提取的数据量(提取一个上亿数据的大表)、多线程转为线程池,优化GC
微服务下讲究的就是分离解耦,包括动静分离、前后端分离、主动分离(读写分离)
开始之前举一个高性能的例子
场景需要获取User表所有的用户数量, 读出全部数据再List.size肯定没有直接MySQL中进行Count快
这里既然提高了性能,简单介绍性能测试要求微服务的基本要求:
- 模拟生产环境,95%用户的响应时间是否小于N秒, 一般来说,打开APP,初始化不应该超过3s,页面跳转不应该超过1s,跳转效益也等待不应该超过0.5s,搜索数据时间不应该超过0.5s
- 高并发场景,访问一个接口是否调用了过多的接口,比如登录要请求N个接口,高并发下,响应可能很慢
- 用户操作是否有监控功能,是否可以监控微服务的性能和服务端硬件性能
- 高并发下的慢连接、慢读取、慢请求 测试,保证不会因为客户端性能影响服务器性能 【 比如弱网条件下,APP网络差,要和服务端建立websocket长连接,java服务器推送数据后,APP未接收到,java服务器因为OOM而崩溃】
- 长时间大量用户连续登录退出是否会引发OOM、缓存失效、缓存穿透
开发业务时,需要关注的点:
分页处理技术: 单击加载更多,是否返回重复数据…
数据显示是否完整: 关注最后一页的数据
页面展示排序的方式: 后台服务器负责排序,前台JS负责排序,注重注意到底哪里承担排序职责
页面跳转是否正常: 尤其携带cookie等是否正常跳转
异常情况处理: 是否给前台用户返回过多的堆栈信息
程序可逆性: 保证增加数据后可以删除数据,删除数据后可以回滚
日志分割: 日志是否有效,是否按照日期分割方便提取
日志可读性: 日志存储信息是否有效,方便排查
程序灾备处理: 数据库渗透,是否有备份可以迅速恢复
程序高可用处理: 高并发导致服务器崩溃,是否可以继续提供服务
断网弱网处理: 弱网时是否包含超时约定,或者拒绝服务的约定
数据处理: 数据量较大时是否可以压缩,限流削峰处理
脱敏机制: 密码等意思信息是否正常脱敏
数据及时性: web控制台修改数据,APP是否及时有效更新
I/O阻塞会闲置CPU造成浪费,多线程增加锁之后会造成锁等待(SQL偶尔执行慢)、创建销毁维护大量线程,线程切换都很耗时,数据量过大、慢请求控制…
数据库的种类繁多,Cfeng接触的比较多的类型为Key-value数据库Redis、文档数据库MongoDB和ElasticSearch, 关系型数据库MySQL
对于MySQL来说,常用的相关工具包括:
- 性能基准测试工具: sysbench、mysqlslap
- 应用程序Web压测: JMeter
- MySQL服务器CPU监控: Grafana + Prometheus
- 集群分库: MyCat
- 统计工具: percona-toolkit
- 慢SQL查询: mysqldumpslow
- 分布式事务: Seata
- 事务处理测试: hammerDB
- 快速备份和恢复: mysqlhotcopy
- 常规备份和恢复: mysqldump
- 二进制日志(binlog)的解析工具: Maxwell
数据库作为应用性能的一个关键点,在使用时需要进行完备的性能测试:
1. 初始化架构,设计数据库表和接口后,对于数据表的结构进行基准性能测试,得到结构基准信息
2. 数据库主从复制、MyCat集群优化后,需要进行压力测试,保证MySQL的单节点性能
3. 编码结束对可能执行的SQL进行计划解读,进行索引优化
4. 对数据库作业务存储量测试, 存储不同的数据量的SQL响应时间
5. 数据库疲劳测试,数据库是否会内存泄露
6. 灾备测试: 主从结构如果机器挂了,是否可以正常提供服务
7.安全测试: 防火墙、脱敏.....
MySQL填充亿级数据
要正确模拟线上环境,需要给数据库填充亿级数据,传统插入Insert插入数据过慢
使用Java等语言连接数据库操作MySQL,除了语言本身损耗,还包括语言和数据库连接的损耗;所以要给数据库增大数据量,不推荐使用语言连接的方式
除了第三方工具,这里给出3种解决方案来填充亿级数据
Insert into select
该方式不涉及IO,所以速度最快,但是因为大多重复数据,自由度不高,【同时该方式不能用于数据库表迁移,因为SELECT 全表扫描,InnoDB行级锁会锁住大量数据,表的使用就崩溃】
Insert Into Select 语句可以先从一个表中复制数据,再将数据插入目标表,目标表已经存在的行不受影响
INSERT INTO target_table SELECT 字段1,2..... FROM origin_table
连续执行多次,因为是指数级增长,可以快速填充
但是数据会出现大量重复,并且执行该语句多次会越来越慢,因为一次性插入庞大数据【从最开始0.000Xms ----> 几分钟】
比如向一个s_id,s_name, s_birth, s_sex的student表填充上亿数据,就可以多执行几次
use cfengtest;
insert into student select null,s_name,s_birth,s_sex from student;
插入上百万数据时,执行很慢
16:26:50 insert into student select null,s_name,s_birth,s_sex from student 1572864 row(s) affected Records: 1572864 Duplicates: 0 Warnings: 0 28.844 sec
# 这里插入157万数据,耗时28s, 但是还是很快了,直接将查询结果插入,不涉及IO
cfeng迅速就将数据扩充到628万
mysql> select count(*) from student;
+----------+
| count(*) |
+----------+
| 6285728 |
+----------+
1 row in set (1.35 sec)
select * from studnet limit 6000000,10;
10 rows in set (4.91 sec) <----- Limit数值过大成为慢SQL
这里需要注意,Mysql的数据执行需要缓冲区,需要在InnoDB的buffer pool种处理缓存:
包括数据缓存、索引缓存、缓存数据、内部结构
当MySQL大批量执行INSERT INTO SELECT ,要求InnoDB的buffer pool足够大
解决缓存区异常的方案:
- INSET INTO SELECT 语句加上Limit 限制一次性插入的数量
- 增加innodb_buffer_size的值
查看默认的数据库引擎的参数:
show variables like ‘%innodb%’
innodb_buffer_pool_size | 8388608 默认大小8MB
修改大小为64MB, 在LINUX系统修改my.cnf, windows系统为my.ini,修改重新运行即可
存储过程loop insert
虽然存储过程不具有一致性,修改麻烦,不推荐使用,但是还是具有优势
存储过程就是数据库中可以完成某种特定功能的SQL语句集合
delimiter $$
CREATE PROCEDURE demo_in_parameter(in i int)
BEGIN
WHILE i < 10000000 DO
insert into student values ('','cfeng','2001-07-01','男');
SET i=i+1;
END WHILE
end$$
可以使用存储方案的随机函数创建数据,如果要使用事务,提交事务不要太频繁,避免磁盘IO异常
调用该存储过程 call demo_in_parameter(0)
Loadfile 导入CVS文件
Loadfile就是利用java语言或者python先创建CVS、txt,再将数据存放在文件中,通过MySQL的loadfile命令,将文件数据导入
- 准备文件,利用java编写相应的CVS文件,内容
\N cfeng 2001/1/1 男
\N cLEI 1999/12/1 男
.....
-
将文件导入Mysql
通过Load data infile xxx into table 命令导入数据
load data local infile '/xxxx/xxx' into table student
第三方的解决方案还包括DataFactory、DataFaker, 专业服务,当然数据自由度更高
大数据量表的查询要么优化索引,要么优化代码和网络
MySQL基准测试: sysbench、mysqlslap
填充大数据量之后,可能会存在问题:
- MySQL单表数据过亿,返回数据速度极慢是正确的吗?
- 单台MySQL数据库最大承载访问量?
- 主从复制如何选择策略减少对单台数据库的性能影响?
- 如何为MySQL数据库配置参数达到最优?
要想了解主从复制对于数据库性能的影响,就可以分别测试主从复制集群和单节点访问,得到两种响应结果
从代码上说:MySQL单表数据量过大确实更消耗性能,但是类似HashMap(超4000慢),但还是可以满足应用需求,速度也不一定是极慢(如果只是返回10条数据,还是ms级别 ---- cfeng验证过)
sysbench
模块化、跨平台、开源的多线程基准测试锅具,可以执行CPU、内存、线程、IO、数据库等方面的测试
CPU --- 处理器性能 threads--- 线程调度性能 mutex --- 互斥锁性能
memory --- 内存分配和传输速度性能 fileio --- 文件IO性能 oltp -- 数据库性能(OLTP基准测试)
对于数据库,主要测试不同系统参数下数据库的负载情况,支持MySQL等少量数据库
使用方式 :
- prepare: 造数据
- run : 执行脚本进行测试
- cleanup: 删除测试数据
sysbench需要从mysql官网下载https://github.com/akopytov/sysbench
wget https://downloads.mysql.com/source/dbt2-0.37.50.16.tar.gz
tar -zvxf sysbench-0.4.12.14.tar.gz
cd sysbench-0.4.12.14
./configure
yum install mysql-devel
make
make install
通过sysbench --version 查看是否按照成功
Sysbench的命令参数
sysbench [options] ...[testname] [command]
options是sysbench的基本参数,指定sysbench的并发度,压测时长,线程数、总等待数…
testname是sysbench的基准测试名称,可选项包括fileio、memory、cpu,捆绑的Lua脚本名称或者定制的Lua脚本
command指定sysbench执行哪些测试命令,包括prepare、run、cleanup
- 压测CPU
sysbench --test=cpu run
压测过程使用top发现CPU使用率飙升
- 压测内存
sysbench --test=memory run
- 压测磁盘IO, 需要prepare、run、cleanup
sysbench --test=fileio --file-total-size=1G prepare
sysbench --test=fileio --file-total-size=1G --file-test-mode=rndrw run
sysbench --test=fileio --file-total-size=1G cleanup
- 压测MySQL
sysbench \
--test=oltp \
--db-dirver=mysql \
--mysql-table-engine=myisam \
--mysql-db=mytest \
--oltp-table-size=100 \
--mysql-socket=/var/lib/mysql/myslq.sock \
--mysql-host=192.168.204.100 \
--mysql-user=cfeng \
--mysql-password=cfeng \
prepare
sysbench \
--test=oltp \
--db-dirver=mysql \
--mysql-table-engine=myisam \
--mysql-db=mytest \
--oltp-table-size=100 \
--mysql-socket=/var/lib/mysql/myslq.sock \
--mysql-host=192.168.204.100 \
--mysql-user=cfeng \
--mysql-password=cfeng \
run
sysbench \
--test=oltp \
--db-dirver=mysql \
--mysql-table-engine=myisam \
--mysql-db=mytest \
--oltp-table-size=100 \
--mysql-socket=/var/lib/mysql/myslq.sock \
--mysql-host=192.168.204.100 \
--mysql-user=cfeng \
--mysql-password=cfeng \
cleanup
压测数据库TPS性能
sysbench \
--db-dirver=mysql \
--time=180 \
--thread=4 \
--report-interval=1
--mysql-host=192.168.204.100 \
--mysql-port=3306 \
--mysql-user=cfeng \
--mysql-password=cfeng \
--oltp_read_write \
--db-ps-mode=disable\
run
这里只是简单介绍一下,开拓一下,如果详细使用后会出文章🎄
mysqlslap
mysqlslap是MySQL提供的压测工具,模拟多个并发客户访问MySQL执行压测,提供高负荷攻击MySQL的数据性能报告
C:\Users\OME>mysqlslap --help
mysqlslap Ver 8.0.27 for Win64 on x86_64 (MySQL Community Server - GPL)
Copyright (c) 2005, 2021, Oracle and/or its affiliates.
MySQL5版本之后安装之后就会携带mysqlslap工具,不管是windows或者Linux版本
mysqlslap的命令
mysqlslap [options]
参数包括–auto-generate-sql等,具体可仔细搜索
mysqlslap -a -u root --onle-print
测试100个并发自动生成的SQL测试脚本,执行1000次查询
mysqlslap -u root -p -a --concurrency=100 --number-of-queries 1000
自定义数据压测
mysqlslap \
-u root \
-p \
--delimiter=';' \
--create="create table a (b int) ; inset into a values 23" \
--query="select * from a" \
--concurrency=50 \
--iterations=200
处理Sysbench之外,还有很多的Linux压测工具,比如磁盘IO压测工具fio
SQL优化
当场景的响应速度不满意时,可以对SQL进行优化,这个时候需要考虑问题: 当前SQL如何扫描MySQL,导致反应速度慢? 如何增加索引,怎么增加?
优化一条复杂的SQL语句,可以将SQL语句拆开测试,检测每一行的运行时间,分析较慢的位置,可以使用explain查看执行任务【使用index与否】
SHOW WARNINGS优化只能作为参考,比如可能只是将* 变为了所有的字段,不是很智能
之前提过SQL优化主要就是合理的使用索引,恰当使用索引可以提升查询的效率
分页查询优化
当表中的数据量过大时,分页查询limit的耗时可能非常长
mysql> SELECT COUNT(*) FROM student;
+----------+
| COUNT(*) |
+----------+
| 6285728 |
+----------+
1 row in set (1.61 sec)
mysql> explain select * from student limit 3000000,3000;
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
| 1 | SIMPLE | student | NULL | ALL | NULL | NULL | NULL | NULL | 6267580 | 100.00 | NULL |
+----+-------------+---------+------------+------+---------------+------+---------+------+---------+----------+-------+
1 row in set, 1 warning (0.01 sec)
按照之前提过的SQL的执行顺序,是SELECT之后才会进行Limit,所以会直接进行全表扫描,并不会过滤
随着LimitM,N的增大,分页速度会越来越慢, 可以优化分页查询
- 可以先查询相关结果的主键, 再进行连接查询 【这样会走主键Index】回表扫描
- 或者可以直接将ID作为where条件过滤,先将结果滤出,避免全表扫描
mysql> explain select * from (select s_id from student limit 3000000,3000) t, student s where t.s_id = s.s_id;
+----+-------------+------------+------------+--------+---------------+---------+---------+--------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+--------+---------------+---------+---------+--------+---------+----------+-------------+
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 3003000 | 100.00 | NULL |
| 1 | PRIMARY | s | NULL | eq_ref | PRIMARY | PRIMARY | 4 | t.s_id | 1 | 100.00 | NULL |
| 2 | DERIVED | student | NULL | index | NULL | PRIMARY | 4 | NULL | 6267580 | 100.00 | Using index |
+----+-------------+------------+------------+--------+---------------+---------+---------+--------+---------+----------+-------------+
3 rows in set, 1 warning (0.01 sec)
优化之后,会走主键索引,提升效率
或者直接通过where过滤掉结果,走主键索引,不会全表扫描,效率一下就提升
慢SQL日志工具mysqldumpslow
分析MySQL性能时,需要查看数据库的哪些SQL的效率低下,需要使用数据库的慢查询,会记录所有的超过long_query_time的语句,便于进行优化
常用的慢SQL日志分析工具包含mysqldumpslow,mysqlsla,mysql-explain-slow-log、myprofi等工具
mysqldumpslow是官方自带的命令
可以检查慢查询功能是否开启: 使用show variables like “%slow”
mysql> show variables like "%slow%";
+-----------------------------+--------------------------+
| Variable_name | Value |
+-----------------------------+--------------------------+
| log_slow_admin_statements | OFF |
| log_slow_extra | OFF |
| log_slow_replica_statements | OFF |
| log_slow_slave_statements | OFF |
| slow_launch_time | 2 |
| slow_query_log | ON |
| slow_query_log_file | DESKTOP-4A4BD0R-slow.log |
+-----------------------------+------
要开启慢查询功能,需要再配置文件中修改,/etc/my.cnf中修改slow_query
slow_query_log=1 #开启慢查询日志
long_query_time=1 #查过多少s认为为慢SQL
show_query_log_file #慢SQL日志文件位置
log_queries_not_using_indexed #记录未使用SQL的记录
重启服务,可以看到慢SQL功能已经开启
检查延时多少s后返回的SQL作为慢SQL
show variables like "%long%"
当执行慢SQL之后,相关的记录会放入日志
mysqldumpslow的命令解释:
-h : 帮助
-r : 返回记录
-t: 返回前面多少记录
-g: 正则表达式
-s : 排序参数 【c 大到小,t,l,at,al,ar】
mysqldumpslow -s c /var/run/mysqld/mysqld-slow.log
开启慢SQL功能会导致MySQL性能损耗上升,导致性能不足,速度下降,对于高并发程序,在生产环境不要开启慢SQL,在测试环境中使用即可; 要避免生产事故
MySQL主从复制
随着数据量的增大,单台机器已经不能承受压力,同时为了高可用性,需要使用集群
在Redis使用时,最常见的就是主从复制的集群,Redis主从复制,读写分离,采用哨兵进行监控,实现宕机后的自动化选举 【数据RDB通过socket传输给集群内其余的机器】
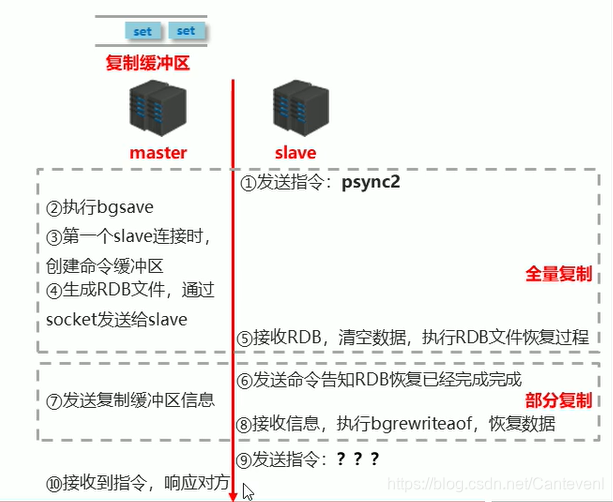
MySQL同样支持集群,MySQL主从复制也是解决单台实例瓶颈问题,业务量增大后,IO密集,单台实例是不能支撑的,多库存储,降低磁盘IO次数,提高单台机器的IO访问性能
MySQL主从复制 knowledge
MySQL主从复制是将数据从一台MySQL服务器复制到从节点,包括所有数据库实例、特定数据库实例或者特定表,采用异步的复制方式,,从节点不需要一直访问主机,在远程服务上更新自己的数据
主服务器就是master服务器,当数据更改时,会将数据的更改记录在二进制日志中
从服务器就是slave服务器,从服务器slave会定期对主服务器的二进制文件进行探测,观测是否发生改变,如果发生改变,那么从服务器会启动一个IO线程,请求更新数据
客户端SQL更新命令
主服务器执行SQL语句
主服务器写二进制日志
从服务器启动IO线程
从服务器从IO线程写盘 relay-log
从服务器启动SQL线程读
从服务器执行更新命令relay-info
- 在进行集群搭建时,需要保证主从数据库的版本相同,避免位置异常
- 主服务器和从服务器的时间必须同步,否则二者线程时间不一致,导致数据同步失败
- 从服务器最好有多台,可以进行数据参考,同时增加可用性
集群架构拓扑结构
(1)一主一从: 从服务器只能读取数据,主服务器可以写入或者读取数据,少见,一般采用多从
(2)主主复制: 将两台服务器都设置master,都可以读取或者写入数据,可能会出现混乱
(3)联级复制: master A —> slave B -----> slave C , slaveB和slave C会替换掉旧的master A,同时B和C构成新的主从关系,适合数据迁移
(4)多主一从: 适合写多读少,只有一台从服务器读取数据
(5)一主多从: 适合读多写少,master写入,多台slave进行读取
MySQL二进制日志
在Redis中,持久化方式为RDB和AOF,RDB日志文件就是redis进行主从复制的参照, 在MySQL中,主从复制的数据传送依靠的是MySQL的二进制文件
mysql二进制日志是一个二进制文件,记录了修改数据或者可能引起数据变更的SQL语句,记录了更改的所有的操作,同时记录的语句发生时间、执行时长等信息,不记录SELECT等不会更改数据的操作,二进制日志是主从复制的基础
之前的慢查询的变量为long,二进制日志可以查询变量log_bin
show variables like "log_bin"
mysql> show variables like "log_bin";
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON |
+---------------+-------+
1 row in set, 1 warning (0.04 sec)
+---------------------------------+--------------------------------------------------------+
| Variable_name | Value |
+---------------------------------+--------------------------------------------------------+
| log_bin | ON |
| log_bin_basename | D:\MySQL\Data Directory\Data\DESKTOP-4A4BD0R-bin |
| log_bin_index | D:\MySQL\Data Directory\Data\DESKTOP-4A4BD0R-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+--------------------------------------------------------+
6 rows in set, 1 warning (0.00 sec)
ON 代表开启了二进制日志,模糊查询其他的参数可以看到二进制文件的存放位置等
log_bin和sql_log_bin
log_bin主要 数据恢复,主从服务器同步数据,可以通过配置文件开启日志,log_bin只是报告当前二进制文件的状态,不能修改,只能通过配置文件修改后重启服务
sql_log_bin 是一个动态变量, 可以是局部变量,也可以是全局变量,其可以修改,【相当于log_bin只能查看,sql_log_bin可以修改】,如果在一个会话中设置为OFF,则所有的更新操作都不会记录日志,所以使用log_bin还原数据,为了避免将还原的UPDATE操作写入日志,出现循环复制,关闭sql_log_bin
二进制文件操作
- 查看二进制文件 直接show binary logs即可
mysql> show binary logs;
+----------------------------+-----------+-----------+
| Log_name | File_size | Encrypted |
+----------------------------+-----------+-----------+
| DESKTOP-4A4BD0R-bin.000549 | 179 | No |
| DESKTOP-4A4BD0R-bin.000623 | 156 | No |
+----------------------------+-----------+-----------+
75 rows in set (0.52 sec)
或者也可以使用show master logs 查看
- 删除某个日志前的所有的二进制文件
通过expire_logs_days设定后会依据时间自动删除二进制日志, 同时也可以使用purge命令手动删除
purge binary logs to "DESKTOP-4A4BD0R-bin.000623"
执行后就会删除DESKTOP-4A4BD0R-bin.000623 日志
- 删除 某个节点前的二进制日志文件
直接purge before 时间即可
purge binary logs before '2022-11-19 12:00:00'
删除7天前的二进制日志文件
purge binary logs before date_sub(now(), interval 7 days)
- 删除所有的二进制日志文件
reset master
- 查看二进制日志
直接system命令即可查看
system mysqlbinlog /var/lib/mysql-bin.000001
其中就会包含对表的各种操作,比如创建表等,但是是整个冗杂在一起
还可以使用show binlog events in “” 进行观察
mysql> show binlog events in "DESKTOP-4A4BD0R-bin.000623";
+----------------------------+-----+----------------+-----------+-------------+-----------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+----------------------------+-----+----------------+-----------+-------------+-----------------------------------+
| DESKTOP-4A4BD0R-bin.000623 | 4 | Format_desc | 1 | 125 | Server ver: 8.0.27, Binlog ver: 4 |
| DESKTOP-4A4BD0R-bin.000623 | 125 | Previous_gtids | 1 | 156 | |
+----------------------------+-----+----------------+-----------+-------------+-----------------------------------+
2 rows in set (0.01 sec)
可以通过pos 参数,指定查询某个节点之后的数据, 如果数据十分庞大,还可以使用分页参数limit
show binlog events in "DESKTOP..." from 475 limit 2
- 复制二进制日志将其转为文本文件
mysqlbinlog /var/lib/mysql/mysql-bin.000001 > /log.txt
就是 定向符 > 指定文件的位置
之后使用linux命令cat /log.txt | grep “drop” 就可以正常查询所有的drop内容
使用binary bin log 恢复MySQL
使用二进制日志恢复MySQL,使用的是mysqlbinlog命令
直接版本回滚,–stop-pos即可
1. 删除mytest.zfx_tbl表
drop table mytest.zfx_tbl;
show tables;
2.执行mysqlbinlog ,查看需要将数据回滚到哪个时间节点
mysqlbinlog /var/lib/mysql/mysql-bin.00002
3.执行回滚, 指定sotp pos 回滚到哪一行
mysqlbinlog /var/lib/mysql/mysql-bin.00001 /var/lib/mysql/mysql-bin.00002 --stop-pos=65488 |mysql -u root -p
4. 数据恢复成功
MySQL主从复制架构
首先需要构建主从复制架构,准备多台MySQL机器,每台机器数据库中包含亿级测试数据
192.168.204.100 Master
192.168.204.101 slave
192.168.204.102 slave
搭建主从复制架构,需要配置机器的配置文件
主库Master的配置文件/etc/my.cnf
[mysqld]
datadir= .........
# 这些配置Cfeng之前的博客包含,只给出主从架构的配置
....
server-id=1 #主从复制ID
log-bin =mysql-bin #二进制日志生成的日志名称
binlog-format= ROW #主从复制的模式与配置
binlog-do-db= cfengtest #主从复制数据库的库名
从库Slave的配置文件/etc/my.cnf
[mysqld]
datadir= .........
# 这些配置Cfeng之前的博客包含,只给出主从架构的配置
....
server-id=2 #主从复制ID
binlog-do-db= cfengtest #主从复制数据库的库名
relay-log=relay-log
show master status 查看主库状态
可以通过show master status查看主库状态
mysql> show master status;
+----------------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+----------------------------+----------+--------------+------------------+-------------------+
| DESKTOP-4A4BD0R-bin.000623 | 156 | | | |
+----------------------------+----------+--------------+------------------+-------------------+
1 row in set (0.01 sec)
当指定主从复制的数据库时,就会进行主从复制, 为了保证除此主从复制的数据完整性, 可以如下操作
停止主库的增删改
停止从库的复制行为
清空从库的所有数据
将主库的日志文件mysql-bin… 全量复制到从库
检查当前主库的Pos参数写到多少行
不从00001开始备份,改变量master_log_pos改成当前的行数
开启从库的只读模式
开启从库复制行为
开启主库的增删改行为
show slave statsu 查看从库状态
通过show slave status可以查看从库的状态,缓存性质的语句,如果服务崩溃、异常、重启,那么涵盖的数据就不准确,可能会消失
mysql> show slave status;
Empty set, 1 warning (0.01 sec)
因为此时还没有开始主从复制,所以从库的状态就是空,当主从复制之后,就会显式Master Host、Mater User等信息,Relay_log_File为从库中继器中存储的已同步的数据内容,Slave_IO_Running和Slave_SQL_Running都是YES,代表主从复制部署成功
flush table with read lock 主库只读锁
主从复制过程中,停止主库的更新操作 ---- 给数据库全局加上只读锁🔒
flush table with read lock
mysql> flush table with read lock
Query OK, 0 rows affected (0.00 sec)
数据库的所有表都变为只读模式,更新操作(增,删,改) 都会失败
该命令获取锁也是需要等待其他的操作释放锁,如果其他的语句包括显式锁SELECT占用锁,那么命令就会阻塞等待完成
slave stop 停止从库备份行为
在从库的控制台输入slave stop 就可以停止备份行为
mysqldump 轻量级备份【文件传输】
mysqldump备份: 通过协议连接MySQL,将需要备份的数据查询出来,将这些查询出来的数据转换为对应的insert语句,当需要还原时,执行INSERT语句即可
直接mysqldump [选项] 数据库 > (位置)文件名.sql 就可以备份
C:\Users\OMEY-PC>mysqldump -u cfeng -p cfengrest > D:\Webstudy\cfengrest.sql
Enter password: ************
mysqldump当数据为浮点类型时,会出现精度丢失,逻辑备份慢于物理备份,其是串行化备份,并行可以使用mydumper
数据量大时,不推荐使用效率低下的mysqldump
数据备份的方式:
- 完整备份: 备份整库数据
- 部分备份:
- 增量备份: 备份最近一次完整备份或者增量备份后更改的数据
- 差异备份: 备份最近一次完整备份后修改的数据
数据库的备份的方式:
- 冷备份: 读写操作都不可执行
- 温备份: 读操作可以执行,但是不能进行写操作
- 热备份: 读写操作都可以执行
MyISAM不支持热备份,InnoDB都是支持的
scp 备份转移
scp: secure copy, 基于ssh的远程文件拷贝命令,scp加密,rcp不加密
比如使用scp命令将主库的cfengrest文件传输到从库服务器的root文件夹下: 使用root账号
scp cfengrest.sql root@192.168.204.101:/root/
输入密码后就可以传输文件,可视化界面工具xftp是在windows中使用
从库新建空database
要使用备份数据,先新建一个空的数据库
create database XXX default charset uft8
通过reset salve 命令方式将从库连接到主库
配置cnf之后,重启Mysql,除此之外,还可以通过MySQL命令的方式连接主库
需要注意,主库的user@password需要允许外部连接,同时主库的mysql端口开放
在从库的mysql控制台输入:
reset slave;
CHANGE MASTER TO MASTER_HOST = '192.168.204.100', MASTER_PORT=3306, MASTER_USER='cfeng', MASTER_PASSWORD='XXX', MASTER_LOG_FILE='mysql_bin.000004',MASTER_LOG_POS=1558;
slave start;
mysql将备份导入从库的数据库
直接通过mysql命令即可
mysql -u root -p xxxx< 文件.sql
set global read_only = 1 从库开启只读模式
set global read_only = 1就可以开启只读模式, =0 就是关闭只读模式,只读模式不会影响从库的同步复制,普通用户不能进行数据修改操作,如果super_read_only=on,那么管理员也是只读
slave start 启动从库
可以通过slave stop 暂停主从,使用reset重置关系,使用start开启主从复制
unlock tables 解锁主库增删改操作
可以通过unlock tables 解锁之前的flush table with read lock, 之后就可以正常进行修改操作
检查主从复制是否
直接在主库插入一个值,再在从库中查询该值是否存在
可以show slave status,如果Running参数为YES也说明生效
主从架构过程可能存在问题:
- 数据不同步: show slave status 出现1032,如果数据同步需要一致,那么停止所有的复制行为,执行stop slave,重新同步主库已有数据到从库; 如果不需要一致,那么停止从库复制行为,跳过一次错误
stop slave set global sql_slave_skip_counter = 1 start slave
- 接收包过小 1236, 可以设置一下,比如4MB
slave stop reset slave set global max_allowed_packet = 1*1024*1024*1024
- 连接错误: 1045, 无法连接到主库,那就重新使用命令连接到主库
下面给出Cfeng具体使用CentOS的操作
首先192.168.204.100上面包含mysql、redis等, 为了快速搭建集群,使用虚拟机克隆的方式直接克隆两台虚拟机
克隆时,选择创建完整实例
因为源主机采用的静态IP,所以克隆出的虚拟机需要修改MAC、uuid和静态IP值【网卡名称】
点击NAT设置,高级—> 生成新的MAC地址 (MAC如果相同则会冲突不能访问网络】
之后进入/etc/sysconfig/network-scripts
将原网卡名称ens33改为新的网卡名称比如eth1, 修改之后进入该文件, 修改HDADDR = 新的MAC地址
同时修改UUID为新的UUID (使用命令uuidgen可以生成)
修改静态IP为新的IP: 192.168.204.101
之后reboot ,ping 成功
之后cfeng使用204.100作为master, 101和102作为slave为虚拟机克隆,数据库配置文件和auto.cnf的配置都克隆了,需要修改为不同的
进入/usr/local/etc/myMysql.cnf (也就是mysql配置文件位置)
进入修改server-id 【这类似分布式系统的唯一标识】,开启日志mysql-bin; cfeng依次修改为100,101,102
之后进入auto.cnf修改UUID,这里可以先find -name auto.cnf; 找到后,使用uuidgen生成新的UUID写入
之后重启服务systemctl restart mysql
重置主机日志【清除所有的日志】
reset master;
show master status;
+------------------+----------+--------------+------------------+-------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------+
| mysql-bin.000001 | 156 | | | |
+------------------+----------+--------------+------------------+-------------------+
1 row in set (0.00 sec)
这里的pos和file都是从机连接的参数
查询从机状态show slave status,如果不为空,那么先stop slave,之后reset slave, 连接主机
mysql> change master to master_host='192.168.204.100',master_user='cfeng',
-> master_port=3306,master_password='aXXXXXXXX0X',
-> master_log_file='mysql-bin.000001',master_log_pos=156;
Query OK, 0 rows affected, 9 warnings (0.01 sec)
连接之后,就可以开启主从复制了,直接start slave
这个时候可以查看状态
mysql> show slave status\G;
*************************** 1. row ***************************
Slave_IO_State: Waiting for source to send event
Master_Host: 192.168.204.100
Master_User: cfeng
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000001
Read_Master_Log_Pos: 497
Relay_Log_File: hadoopbase2-relay-bin.000002
Relay_Log_Pos: 665
Relay_Master_Log_File: mysql-bin.000001
Slave_IO_Running: Yes
当slave_IO和SQL都是YES代表开启成功, 当然设置只读状态就是在配置文件中设置read_only =1; 或者全局加上只读锁,flush … read lock
这个时候就是正常的主从复制了,体系正常运转,slave 机器定时探测主机的mysql-bin二进制日志,发生改变就会将更改操作通过relay-log拉入本地执行,达到同步【主从复制的关键就是binlog】
在主库中插入数据,从机可以正常读取
mysql> insert into test_user values (7,34,'HC1987','masterAndSlave','123456');
Query OK, 1 row affected (0.02 sec)
mysql> select * from test_user;
+----+----------+------------+----------------+----------+
| id | user_age | user_class | user_name | user_pwd |
+----+----------+------------+----------------+----------+
| 1 | 12 | HC2005 | Cfeng | a123456 |
| 2 | 12 | HC11班 | KDJGHAG | 1234 |
| 3 | 18 | HC19班 | HJCKHHH | iuuuihh |
| 4 | 21 | HC1987 | 小X | gdgfsh |
| 5 | 23 | HC1990 | SMall huan | joihihih |
| 6 | 23 | HC1878 | 小XDChat | iihhhlk |
| 7 | 34 | HC1987 | masterAndSlave | 123456 |
+----+----------+------------+----------------+----------+
7 rows in set (0.00 sec)
主从架构搭建成功,主从复制,主写从读,读写分离
之前提过redis主从复制有所区别
reids复制原理:
初次建立连接时,master生成RDB快照发送给slave,slave加载所有数据
之后就和mysql一样进行增量复制,只是redis是通过长连接的方式, 主机执行写命令,会通过长连接同步发送给salve, 二者维护一个
同步的偏移量,当连接断掉,就直接断点续传即可, 这个offset复制偏移量如果不一致,那么就会重新进行全量复制
mysql是slave定时扫描master的binlog, redis是master和slave长连接,master执行写操作将命令主动发送给从机执行 【mysql是从机主导,redis是主机操作】
redis的高可用使用哨兵模式,通过哨兵集群,定期进行心跳检测,自动进行故障处理,选举新的master
mysql也可以利用类似的模式,比如MHA工具,通过MHA实例检测Mysql集群,健康检测心跳,当主机宕机后,MHA会选取relay-log的POS最大的作为master来尽量保证一致性
SpringBoot整合MySQL主从架构【原生AOP]
整合主从架构,首先就是需要配置数据源,这里使用Druid(可视化)数据源,在配置文件中指定master和slave结构
###### mysql 主从复制架构 #####
spring:
datasource:
druid:
master:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.204.100:3306/test_user?useUnicode=true&characterEncoding=utf-8&useSSL=true&servertimezone=GMT%2B8
username: cfeng
password: 1234556
slave1:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.204.101:3306/test_user?useUnicode=true&characterEncoding=utf-8&useSSL=true&servertimezone=GMT%2B8
username: cfeng
password: 1234556
slave2:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.204.102:3306/test_user?useUnicode=true&characterEncoding=utf-8&useSSL=true&servertimezone=GMT%2B8
username: cfeng
password: 1234556
..... 其余的druid本身配置省略
之后编写数据源配置文件MySQLDatasourceConfig,将上面配置的数据源注入
@Configuration
@Slf4j
public class MysqlDatasourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource masterDataSource() {
log.info("select master data source");
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave1")
public DataSource slaveDataSource() {
log.info("select slave datasource");
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.slave2")
public DataSource slave2DataSource() {
log.info("select slave2 datasource");
return DruidDataSourceBuilder.create().build();
}
}
编写一个ThreadLocal本地线程管理类,设置当前线程使用的数据源
ThreadLocal的主要作用是实现数据隔离,运行时数据区分为私有的虚拟机栈和本地方法栈、PC ,以及共享的堆Heap、元数据区MeataSpace、直接内存DM;
而当并发访问共享数据时,可能出现安全问题,常见的丢失修改,库存超卖等, 一种解决方案就是锁 ---- 串行化操作 【比如单机的JUC、AQS、synchronized; 分布式的分布式锁 redis的SETNX、zookeeper的临时节点、包括乐观锁也可以】
另外一种解决方案就是使用ThreadLocal,数据隔离,一个Thread会维护一个ThreadLocalMap,Map中就是数据键值对,key是弱引用在虚拟机栈,存在内存泄露、以及OOM等风险(Map在堆中),如果不手动清理remove,那么很有可能会泄露【线程结束,对象还是存在】
线程栈中的ThreadLocals是本地变量,所以Heap中的对象只有本线程才能访问,自然不存在安全问题;对于一个Local,每一个线程都是具有对应的资源副本, 只是注意OOM
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-489iotDe-1669793698548)(https://tse1-mm.cn.bing.net/th/id/OIP-C.RJ0_VGu-qckeFW2DpLPMegHaEt?pid=ImgDet&rs=1)]
在ThreadLocal中存储当前线程使用的数据源,切面After之后需要清理,避免内存泄露,【当然进行主从分离可以使用成熟的Sharding-JDBC】
* AOP切面管理: 主写从读,读写分离
*/
@Aspect
@Order(1)
@Component
@Slf4j
public class DataSourceAop {
//读取类型的数据库
@Pointcut("execution(* indv.cfeng.service..*.select*(..))" +
"||execution(* indv.cfeng.service..*.find*(..))" +
"||execution(* indv.cfeng.service..*.get*(..))")
public void readPointcut() {
log.info("read only operate");
}
@Pointcut("execution(* indv.cfeng.service..*.insert*(..))" +
"||execution(* indv.cfeng.service..*.add*(..))" +
"||execution(* indv.cfeng.service..*.delete*(..))"+
"||execution(* indv.cfeng.service..*.update*(..))")
public void writePointcut() {
log.info("write opreate,into masterdb");
}
//Before
@Before("readPointcut()")
public void read() {
log.info("read");
//当前线程设置为Slave数据源, 多台从机,需要进行负载均衡
}
@Before("writePointcut()")
public void write() {
log.info("write");
//当前线程设置为Master数据源
}
@After("writePointcut(),readPointcut()")
public void clean() {
//service操作结束需要清除本地线程的该对象,避免内存泄露OOM
//DBContextHolder.cleanAll();
}
}
MySQL集群监控 Prometheus + Grafana
之前cfeng在SpringBoot部分就介绍过这个两个工具,结合进行可视化监控,功能强大
Prometheus是开源的服务监控系统和时序数据库,K8s内部就使用该数据库,Prometheus数据访问快,具有高效的数据压缩算法,减少IO瓶颈
可以部署监控服务器,提供7 * 24 监控; 问题预警、告警
Prometheus不依赖分布式存储,但服务器节点是自主的,通过中间网关支持push模型,支持多种多样的图表和界面展示 : Grafana
监控MySQL可以直接下载mysqld_exporter插件,安装启动后,重启Prometheus, 就可以看到Mysql信息
安装Grafana后,配置DataSource为Prometheus,再自定义图标Graph,可视化监控mysql
具体安装部署流程就不详细说明,这里只是给出集群监控的解决方案🎄
分库分表 【Sharding】
随着数据库存储内容增加,比如成长为亿级数据的单表,就算主从复制也是无法很好的解决数据量过大的问题,此时就需要进行表切割,将过大的表切割存储在不同的MySQL节点中,以便存储更多的内容
该问题的解决方案就是分库分表 ---- 对应的就是分布式微服务;
单体项目比如DB中包含商品表,商家表,订单表, 拆分为微服务之后,数据库可能就变为商品服务的DB,商家服务的DB,订单服务的DB,数据库中存放的可能就是原始的大表拆分的多个小数据量的表(比如20W【offerCampus微服务项目就进行了分库分表 — 垂直分库,水平分表】
分库分表操作方式
分库分表的方式有很多:
垂直分表
比如商品表中包含: 名称、封面、价格、描述等信息字段, 垂直分表就是将表垂直切割,将字段进行划分
比如划分为商品基础信息表: 名称、封面、价格 … ; 商品描述信息表: 描述…
按照数据库的设计,如果是自然主键,那么二者只要对应的ID同,就可以进行信息的合并; 这样就划分成了两个表, 但是表的元组数量是不变的, 同时表的数量增加了,增加了IO
为了减少表的数量,可以进行垂直分库
垂直分库
垂直分库就是将部分表划分到另外的数据库中,不同的数据库可能部署在不同的服务器;分库一般就是按照业务需求进行拆分,常见的比如商城系统,分为订单服务的订单DB、商家DB、商品DB…
分库之后可以减少IO操作,提升访问效率
水平分库
垂直分库之后其实对应的就是不同的微服务,但是垂直划分,数据量还是很大,因为数据行不断增加,为解决这个问题,可以水平分库
比如将商品DB划分为商品DB1,和商品DB2, 将商品ID为奇数的存进DB1,将商品ID为偶数的记录存入DB2, 这样原大数据量的数据库就变为两个1/2数据量的DB
水平分表
水平分库会导致数据库数量增加,可能会导致服务器数量需求增加,提高了硬件成本,运维不易
除了水平分库,还可以水平分表,比如商品DB的商品表,按照ID奇偶性,划分为两个表商品1表,商品2表
虽然增加了数据库中表的数量,但是单表的数据量减少,访问效率提升
水平拆分后的数据库表(相同逻辑和数据结构)的总称就是逻辑表,比如Order拆分的Order1,Order2,逻辑表就是Order
在分片的数据库中真实存在的物理表 ---- 真实表, 比如Order1,Order2,他们是真实存在的,而原来的Order逻辑表已经不存在了,被拆分了
数据分片的最小单元 ----- 数据节点,数据源名称 + 数据表组成,也就是在分库分表后的一张数据库表,比如水平拆分的数据库中的数据表: offershow-user1.sysUser0
所有数据源都存在的表 ---- 广播表,表结构、表中的数据在每一个数据库中都完全一致,适用于数据量不大但是与海量数据进行关联查询的表,比如数据字典表dict
分片规则一致的主表和子表为绑定表,比如垂直分表Order成Oder和Order_item,都是按照ID进行拆分,互为绑定关系,关联查询不会出现笛卡尔积关联
SELECT i.* from t_order o join t_order_item i ON o.order_id = i.order_id WHERE o.order_id IN (10,11)
主键查询一定要避免索引失效
如果将这两张表进行水平分表,也就是说这两张表只是逻辑表,真实表如果各有2个,那就是t_order0,t_order1, t_order_item0,t_oreder_item1
不配置绑定关系,那就是自由组合,路由的SQL一共4条: 2 * 2
配置之后,真实表0和0组合,1和1组合 — 这也才符合要求
数据分片
分片Sharding是一种与水平切分相关的数据库架构模式。是数据库分区的一种,将大型数据库划分为更小、更快的部分,部分就是数据碎片。
用于分片的数据库字段就是分片键, 是将数据库表水平拆分的关键字段; 比如将Order订单按照ID尾数取模分片,则ID就是分片键,如果没有分片键,那么全路由,性能差;Sharding-JDBC支持多个字段分片
分片算法
通过分片算法依靠分片键将数据分片,支持=, >=, <=,BETWEEN和IN分片,分片算法可以自行实现, 分片算法和业务紧密关联,没有内置算法, 只是通过分片策略提供Interface
精确分片算法: 对应的就是PreciseSHardingAlgorithm, 用于处理使用单一字段作为分片键的 使用 =, 或者IN 进行分片, 配合StandardShardingStategy使用
范围分片算法: 对应的就是RangeShardingAlgorithm, 用于单一字段作为分片键的BETWEEN AND、 > , < , >= , <=, 配合StandardShardingStrategy使用
复合分片算法: 对应的ComplexKeysShardingAlgothm, 处理多个字段作为分片键, 需要自行实现相关的逻辑,配合ComplexShardingStrategy策略
Hint分片 算法: 对应的就是HintShardingAlgorithm, 处理通过Hint指定分片值而非从SQL提取分片值,配合HintShardingStrategy策略
分片策略
包含分片键和分片算法,真正用于分片操作的就是分片键 + 分片算法, 就是分片策略
- 标准分片策略 StandShardingStrategy: 也就是SQL语句中 =, > =等分片操作支持,只支持单一字段作为分片键,算法包括精确分片算法和范围分片算法,**PreciseShardingAlgorithm是必选的,也就是精确算法,而范围算法可选
- 复合分片策略: ComplexShardingStrategy, 提供SQL的=, > , < …等分片操作支持,支持多分片键,并未过多封装,需要手动实现
- 行表达式分片策略 InlineShardingStrategy: 使用Groovy表达式,对SQL中=和IN提供支持,支持单分片键,是精确分片算法的简易版
- Hint分片策略: HintShardingStrategy, 通过Hint指定分片值,不是从SQL中提取分片值
分布式主键: 用于在分布式环境下生成全局唯一的id,Sharding-JDBC提供内置的分布式主键生成器,还提供主键生成器接口,为保证数据库性能,主键ID必须自增,避免造成数据页面分裂
分库分表 的problem
分布式微服务分库分表,相较与单机项目,需要考虑 :
- 分布式事务解决方案
- 跨界点连接查询(分页、排序…)
- 多数据源的管理 【集群可用性】
可以借助第三方的工具作为解决方案,比如Seata,Sharding-JDBC、MHA, 连接查询则可以进行服务调用再补填【外键会失效】
集群高可用可以使用MHA,或者HAProxy
HAProxy是C编写,提供高可用性、负载均衡、基于TCP和HTTP的服务代理,HAProxy运行在当前硬件上,可以支持数万的并发连接,保护Web服务器不暴露到网络中
除此之外,还有许多高可用架构方案: 比如Nginx、LVX、Keepalived…
Keepalived + HAProxy + MySQL: 基于HAProxy和Keepalived负载均衡,容易发生脑裂 — 联系两个节点的心跳线断开,整体HA系统会分裂为两个独立服务,互相认为对方故障,争夺资源,导致故障
Sharding-JDBC 数据分片,读写分离
Sharding-JDBC不是用来进行分库分表的,主要是进行数据分片和读写分离,通过sql语义分析,将读操作和写操作分别路由到主、从DB(就是上面的AOP),主要就是提供透明化的读写分离
主要就是简化了读写分离和数据源管理的操作【原生方式需要AOP】
提供一主多从的架构,配合分库分表,同一线程同一数据库连接,如果包含写操作,那么之后的读操作都直接从主库读取【Connection为重量级对象,切换浪费时间, 同时保证数据的一致性 — 同步有一定延迟】,事务的读写使用主库
Sharding-jdbc使用
Sharing-JDBC主要就是解析配置文件,进行SQL解析、优化、路由、改写, 之后将结果集汇总返回客户端。
Sharding-JDBC就是一个增强的JDBC(JDBC的编程6步:Datasource、Connection、Statement(PS)、ResultSet), 而Sharding-jdbc实现了上面几个接口 : ShardingDatasource、ShardingConnection、ShardingStatement(PS)、ShardingResultSet
通过ShardingDataSource获取到一个ShardingConnection
DatasourceUtil.fetchConnection();
Connection con = dataSoure.getConnection();
基于这个ShardingConnection,可以获取ShardingPS对象
stmt = handler.prepare(connetion,transaction.getTimeout());
SQL执行handler.query(stmt, resultHandler),返回结果集
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PrepareStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
执行的核心的ps的execute()方法,其中执行了clear、prepare等
public boolean execute() throws SQLException() {
try {
clearPrevious();
prepare();
initPrepareStatementExecutor();
return preparedStatementExecutor.execute();
} finally {
....
clearBatch();
}
}
在prepare()方法中,prepareEngine.prepare会调用Route执行路由
private RouteContext executeRoute(String sql, List<Object> clonedParamenters) {
this.registerRouteDecorator();
return this.route(this.router,sql,cloneParameters);
}
Sharding-jdbc的执行过程: SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并

- SQL解析: 主要就是词法解析和语法解析,比如一个SQL,分析select等判断是什么类型,Shrading-jdbc之前使用Druid作为解析引擎,1.5之后使用自研的
- 执行器优化: 这和原生的MySQL的优化器一样,会对SQL进行优化,比如联合索引的顺序会自动调整…
- SQL路由: 也就是根据分片的规则配置解析上下文的分片条件,将SQL定位到真正的数据源,分为直接路由(Hint)、简单路由、笛卡尔积路由 【分片路由和广播路由】 其实就是之前的AOP,会解析出相关的执行行为和分片键值路由到对应的数据库
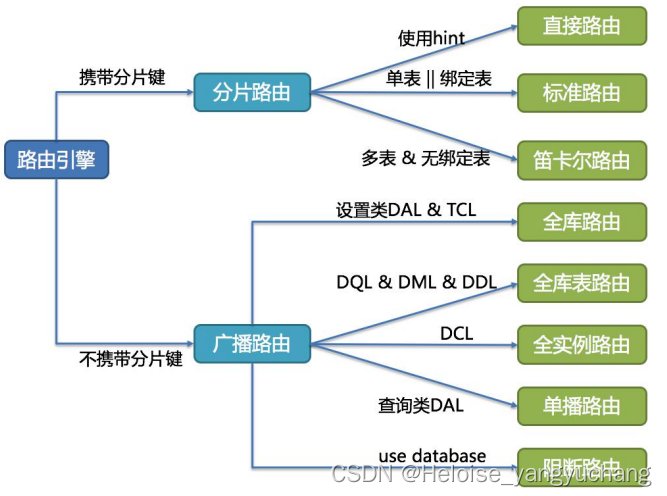
其实就是数据库是否分片,如果没有进行分片,那么就是广播路由,只需要将其路由到master或者slave, 如果进行分片,那么需要判断是单表或者绑定表…
- SQL改写 : 因为程序中的SQL语句是逻辑表名,而实际是分片存储的,所以需要将SQL逻辑表改为真实表,同时会优化分页查询
- SQL执行: 改写完成就能够正确执行,因为可能会链接多个数据源(集群),所以Sharding-JDBC使用多线程方式执行SQL
- 结果归并: 从各数据节点中获取结果后,进行数据的封装,分页、排序…
要在项目中使用Sharding-jdbc,需要引入相关的starter
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding.version}</version>
</dependency>
其他的依赖比如mysql、druid、mybatis-plus等引入即可
数据源配置
如果数据源使用sharding配置,那么会自动将数据源注入到spring容器
也就是直接使用shardingsphere进行配置,但是一般项目都是直接配置的数据源,没有使用shardingsphere配置,这个时候,需要禁用sharding的自动装配,改写数据源配置
启动类上面exclude自动装配
@SpringBootApplication(exclude = {org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration.class})
public class XXXX {
}
之后定义一个Datasource的配置类,将数据源改写为Sharding
@Configuration
@Slf4j
@EnableConfigurationProperties({
SpringBootShardingRuleConfigurationProperties.class,
SpringBootMasterSlaveRuleConfigurationProperties.class, SpringBootEncryptRuleConfigurationProperties.class, SpringBootPropertiesConfigurationProperties.class})
@AutoConfigureBefore(DataSourceConfiguration.class)
public class DataSourceConfig implements ApplicationContextAware {
@Autowired
private SpringBootShardingRuleConfigurationProperties shardingRule;
@Autowired
private SpringBootPropertiesConfigurationProperties props;
private ApplicationContext applicationContext;
@Bean("shardingDataSource")
@Conditional(ShardingRuleCondition.class)
public DataSource shardingDataSource() throws SQLException {
// 获取其它方式配置的数据源
Map<String, DruidDataSourceWrapper> beans = applicationContext.getBeansOfType(DruidDataSourceWrapper.class);
Map<String, DataSource> dataSourceMap = new HashMap<>(4);
beans.forEach(dataSourceMap::put);
// 创建shardingDataSource
return ShardingDataSourceFactory.createDataSource(dataSourceMap, new ShardingRuleConfigurationYamlSwapper().swap(shardingRule), props.getProps());
}
@Bean
public SqlSessionFactory sqlSessionFactory() throws SQLException {
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
// 将shardingDataSource设置到SqlSessionFactory中
sqlSessionFactoryBean.setDataSource(shardingDataSource());
// 其它设置
return sqlSessionFactoryBean.getObject();
}
}
自定义分布式ID生成器
@Data
public class SeqShardingKeyGenerator implements ShardingKeyGenerator {
private Properties properties = new Properties();
@Override
public String getType() {
return "SEQ";
}
@Override
public synchronized Comparable<?> generateKey() {
// 获取分布式id逻辑
}
}
分片策略配置 – 完整配置,使用sharding
也就是分片之后,要进行正确的路由,或者进行主从的路由
这里演示的数据源直接就使用Sharding配置
spring:
datasource:
# driver-class-name: com.mysql.jdbc.Driver
# url: jdbc:mysql://127.0.0.1:3306/yiciyu?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
# username: root
# password: 123456
## 需要druid监控页面
type: com.alibaba.druid.pool.DruidDataSource
druid:
stat-view-servlet:
enabled: true
loginUsername: admin
loginPassword: 123456
web-stat-filter:
enabled: true
# 使用sharding配置数据源,同时配置多个,names指定即可,比如主从,或者分片
shardingsphere:
datasource:
##common配置,不需要放在druid中
common:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
initial-size: 6
min-idle: 3
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
#Oracle需要打开注释
#validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
# 打开PSCache,并且指定每个连接上PSCache的大小
poolPreparedStatements: true
maxPoolPreparedStatementPerConnectionSize: 20
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
filters: stat,wall,slf4j
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
connectionProperties: druid.stat.mergeSql\=true;druid.stat.slowSqlMillis\=5000
wall:
multi-statement-allow: true
#配置分片数据源
names: ds0,ds1
ds0:
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/sharding_db_0?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
username: root
password: 123456
ds1:
driver-class-name: com.mysql.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3308/sharding_db_1?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&useSSL=false&zeroDateTimeBehavior=convertToNull
username: root
password: 123456
##配置分片路由的策略或者数据节点选择, 使用tables指定具体的数据库表
sharding:
tables:
XXX:
actual-data-nodes: msds$->{0..1}.XXX$->{0..1}
database-strategy:
inline:
sharding-column: merchant_id
#计算方式:value % [库数]
algorithm-expression: msds$->{merchant_id % 2}
table-strategy:
inline:
sharding-column: merchant_id
#计算方式:value / [库数] % [表数],示例中仅通过merchant_id后两位路由,为保障
algorithm-expression: cms_merchant_$->{((int) (Integer.parseInt(Long.toString(merchant_id).substring(1)) / 2)) % 2}
#可缺省,缺省时走单库方式, 配置主从架构,指定master数据源,和slave数据源节点
master-slave-rules:
msds0:
master-data-source-name: ds0
slave-data-source-names:
- ds0
- ds0
msds1:
master-data-source-name: ds1
slave-data-source-names:
- ds1
- ds1
mybatis-plus:
mapper-locations: classpath:mapper/**/*.xml
type-aliases-package: com.yiciyu.*.entity,com.yiciyu.*.model
global-config:
db-config:
id-type: auto
table-underline: true
这里注意,数据源使用sharding配置,Druid又会报错,需要将Druid的数据源自动装配给exclude
spring:
autoconfigure:
exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
同时引入将自动配置排除了,所以监控页面可能显示不出,显示的核心类为DruidDynamicDataSourceConfiguration, 其上的注解会Import DruidWebStatFilterConfiguration
将这个类复制出来,自定义名称,主要是Import上面Filter
@Configuration
@ConditionalOnClass(DruidDataSourceAutoConfigure.class)
@EnableConfigurationProperties({DruidStatProperties.class})
@Import({
DruidSpringAopConfiguration.class,
DruidStatViewServletConfiguration.class,
DruidWebStatFilterConfiguration.class,
DruidFilterConfiguration.class})
public class DruidShardingJdbcDataSourceConfiguration {
}
在项目中的代码正常编写即可
@Test
void multQueryTests() {
//inline不支持range(即between、大于小于等范围查询)
List<MerchantEntity> list = merchantDao.selectList(new QueryWrapper<MerchantEntity>()
.in("merchant_id", Arrays.asList(100L, 101L, 102L, 103L)));
System.out.println("list===" + JsonUtils.toString(list));
}
也就是正常按照Mybatis-plus之前的格式编写接口,Sharding-JDBC就是为了进行透明化操作,需要链接数据库时,或自动AOP🚡

![[附源码]计算机毕业设计springboot考试系统](https://img-blog.csdnimg.cn/2423133070524477aa4d19cf66b3be74.png)


![[Power Query] 快速计算列](https://img-blog.csdnimg.cn/caca787cb5cd4c1a8e8defd9705d92d7.png)