前言
最近在工作中接触redis,但实际应用不多,可用场景也不是很明确,所以想借机多多学习下redis相关知识,一下内容都是通过自己找资源学习之后归纳总结的知识,若有相关错误点,请指正。
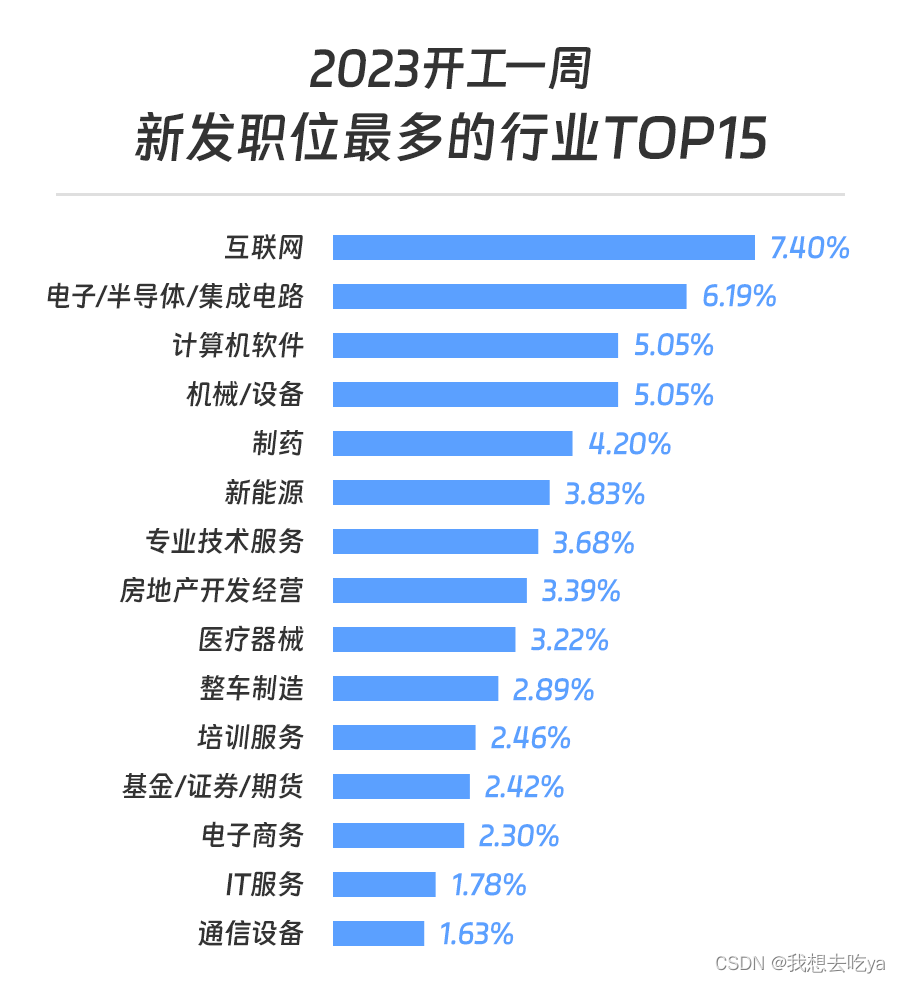
一、redis介绍
1.redis为什么效率很高
1)高速的存储介质,redis内容就是存储在内存条中

2)优良的底层数据结构

3)高效的网络IO模型

4)高效的线程模型
二、redis的底层数据结构说明
问题一:redis底层得数据结构是怎样得呢?
答:
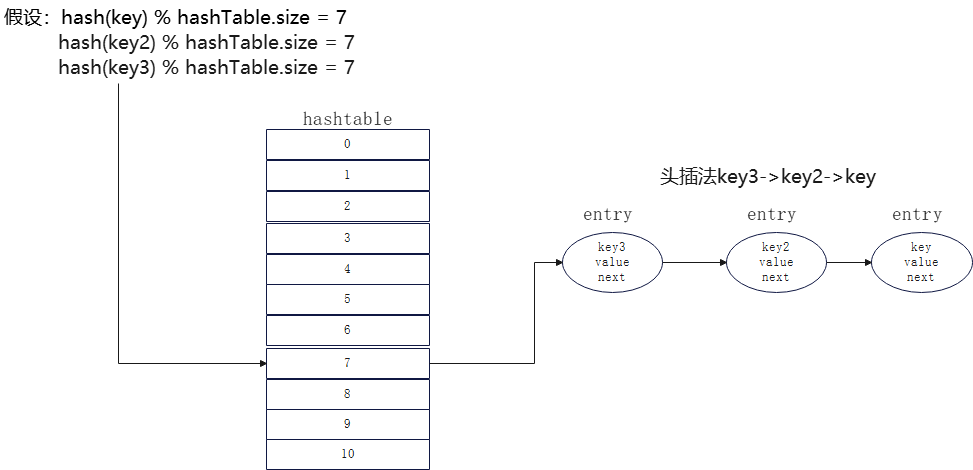
在redis底层采用的数据结构是HashTasble方式,HashTasble就是一个数组,我们把redis一个键值对数据称为数据对象entry,那么HashTasble存放的是各个entry的索引,那么这个索引值是怎么得出来的呢?它是对entry中的key值进行求hash值(hash函数),再将hash值进行求模得出索引值,公式如下:hash(key) % hashTable.size = 索引值 得到得这个索引值会指向entry,即存储具体得键值对数据。

问题二:通过hash求值得到得索引会存在经典得hash碰撞问题,即不同得输入也可能会得到相同得hash值,那么就会导致不同得key所处得hashtable位置相同。在redis中是如何避免这种问题得呢?
答:
redis中所存储得entry,不仅仅有key、value两个值,还有next,用来存储下一个entry得指向,当遇到hash冲突时候redis就会将值放在已有entry得next中,形成链表结构,链表增加元素有两种方式,其一:可以放在链表头,称为头插法,如下:
其二:可以放在链尾,称为尾插法,如下:
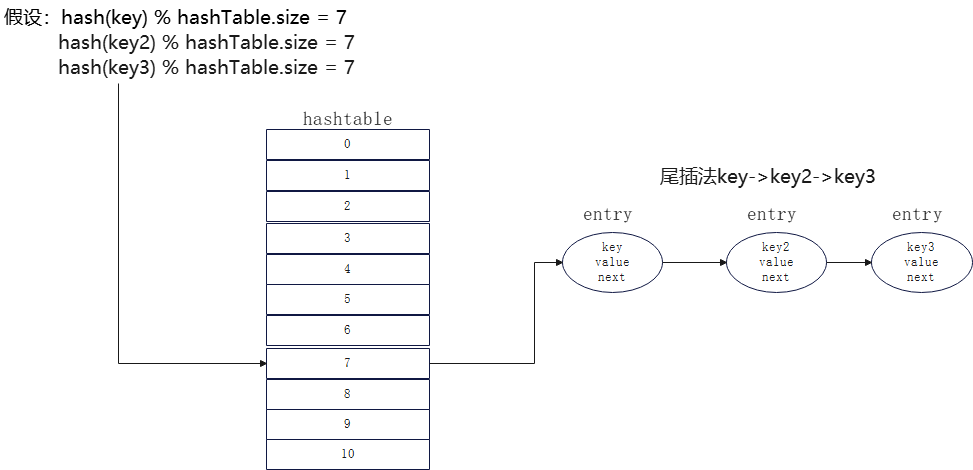
而redis采用得便是头插法,原因是为了更快得访问到元素。
问题三:正因为hash冲突得存在,就会使得链表得元素变多,就会使得元素访问变慢,那么redis是如何避免解决这样的问题呢?
答:
在redis中是这样避免链表中元素过多而导致元素检索变慢得。当元素entry个数大于hashtable.size时,redis就会进行扩容,扩容得倍数是原来得一倍,即原来hashtable.size=11,扩容之后新的hashtable.size=22,那扩容之后有了空间就需要进行元素得迁移,即rehash。
当键值对过多时,一次性移动所有键值对会导致Redis在一段时间内无法对外提供服务,所以redis采用得是渐进式 rehash,redis扩容之后便有两个hashtable,原hashtable成为hashtable[0],长度为11,另一个hashtable称为hashtable[1],长度为22,每次对redis执行增删改查操作时,程序在执行指定操作之外,还会将 hashtable[0] 在 rehashidx 索引上的所有键值对,依据hashtable[1]得大小进行重新计算索引位置,然后rehash 到 hashtable[1],之后将 rehashidx 的值加一;rehashidx初始为0,全部迁移完成之后rehashidx便设为-1,并释放hashtable[0]空间。
特别的,在渐进式 rehash 操作过程中,因为同时存在两个哈希表,所以对redis的删除,查找,更新操作会在两个哈希表上进行。程序会先尝试在 ht[0] 中寻找目标键值对,如果没有找到则会在 ht[1] 再次进行寻找,然后进行具体操作。但是新增操作只会在 ht[1] 上进行,这保证了 ht[0] 中的已经被清空的单向链表不会新增元素。
详细得源码分析看《Redis底层设计与源码分析(二)__底层数据结构源码分析》