文章目录
- 一、什么是大数据
- 二、大数据计算架构的发展
- 1.RDBMS阶段
- 2.Hadoop Map-Reduce阶段
- 3.Spark阶段
- 4.Flink阶段
- 参考
一、什么是大数据
大数据是指无法在有限时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合。
-
大数据的特点:
海量化:数据量规模巨大
多样性:数据源和数据种类具有多样性
快速化:数据产生和处理的速度很快
价值化:数据的价值密度低,但整体价值高 -
大数据体系:
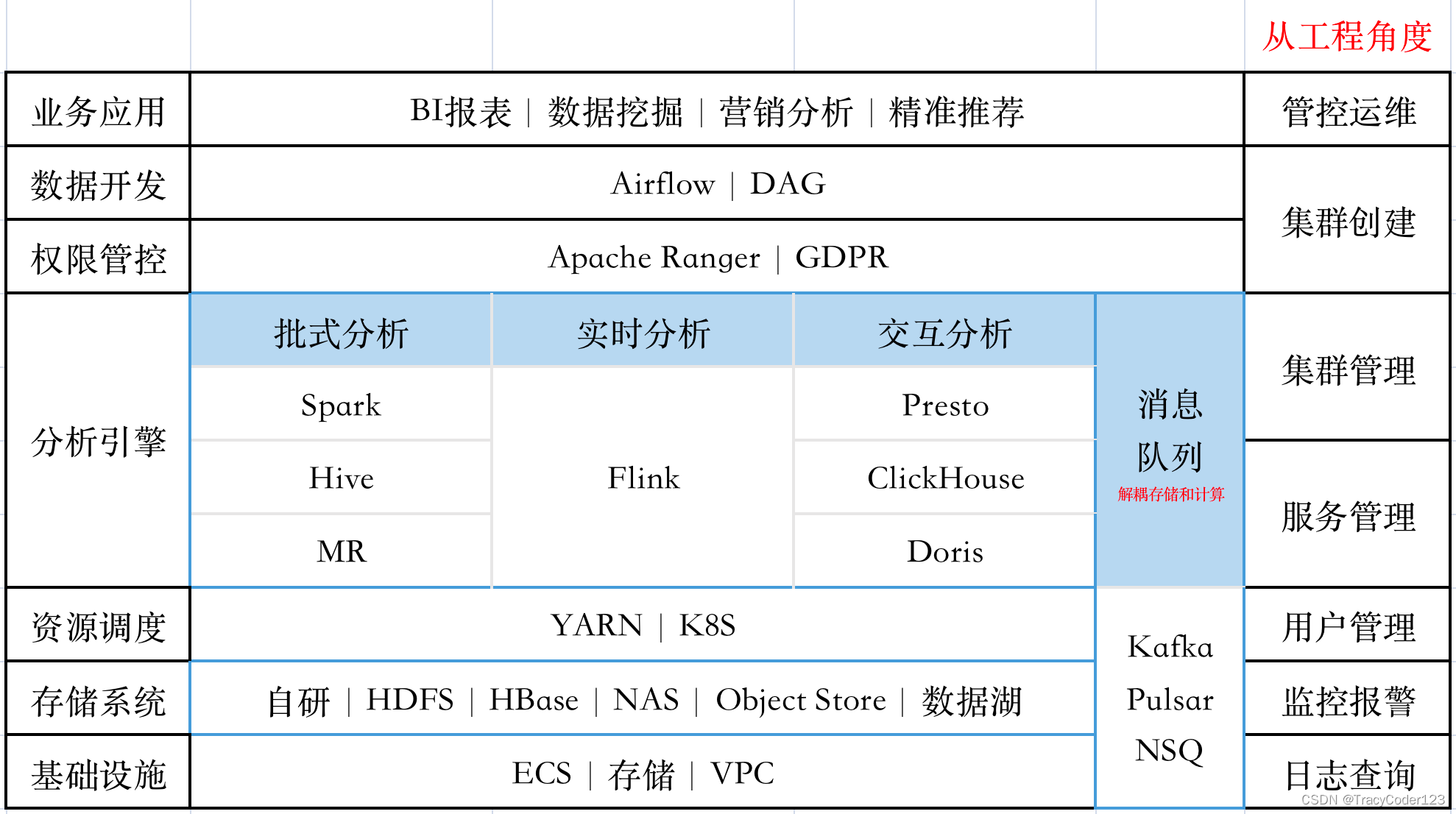
- 流式处理、批式处理、实时处理:
批处理: 静态数据集、离线计算、非实时、小时/天等周期性计算。批处理系统可以存取已经入库的所有数据,人们可以对数据进行复杂深入的分析,分析处理的延迟以分钟或者小时计。批处理是最通用的数据处理模式。传统的关系数据库系统、Hadoop以及Spark大数据处理平台等,都采用了这样的数据处理模式,或者以该处理模式为主。由于需要完整地保存整个数据集,并且在上面进行分析处理,比起流式数据处理系统,人们需要投入更多的硬件资源。
流处理: 动态数据集、可看作实时计算、7*24小时不断运行、流批一体。数据持续到达,系统及时处理新到达的数据,并不断产生输出。处理过的数据一般丢弃掉,当然也可以保存起来。流式数据处理模式强调数据处理的速度。完成分析处理的时间,需要达到实时或者接近实时的响应时间要求。
实时处理: 在数据生成或收到后立即进行处理的过程。在这种处理方式中,数据处理的延迟非常低,以便及时作出响应。
二、大数据计算架构的发展

1.RDBMS阶段
在最早期,关系型数据库(RDBMS)能解决一切问题,这些数据库集数据计算、数据存储于一体。使用者只需要将原始数据保存到一张数据源表中,后续再根据自己的业务需求写SQL将结果再次保存到另一张表中就可以了,这是传统数据库最常见的数据处理模型。
特点: 这种架构方式简单易用,但是这种单机的、一体的架构方式效率低下,而且一旦其中某一个环节出错,就会导致整个系统崩溃。
2.Hadoop Map-Reduce阶段
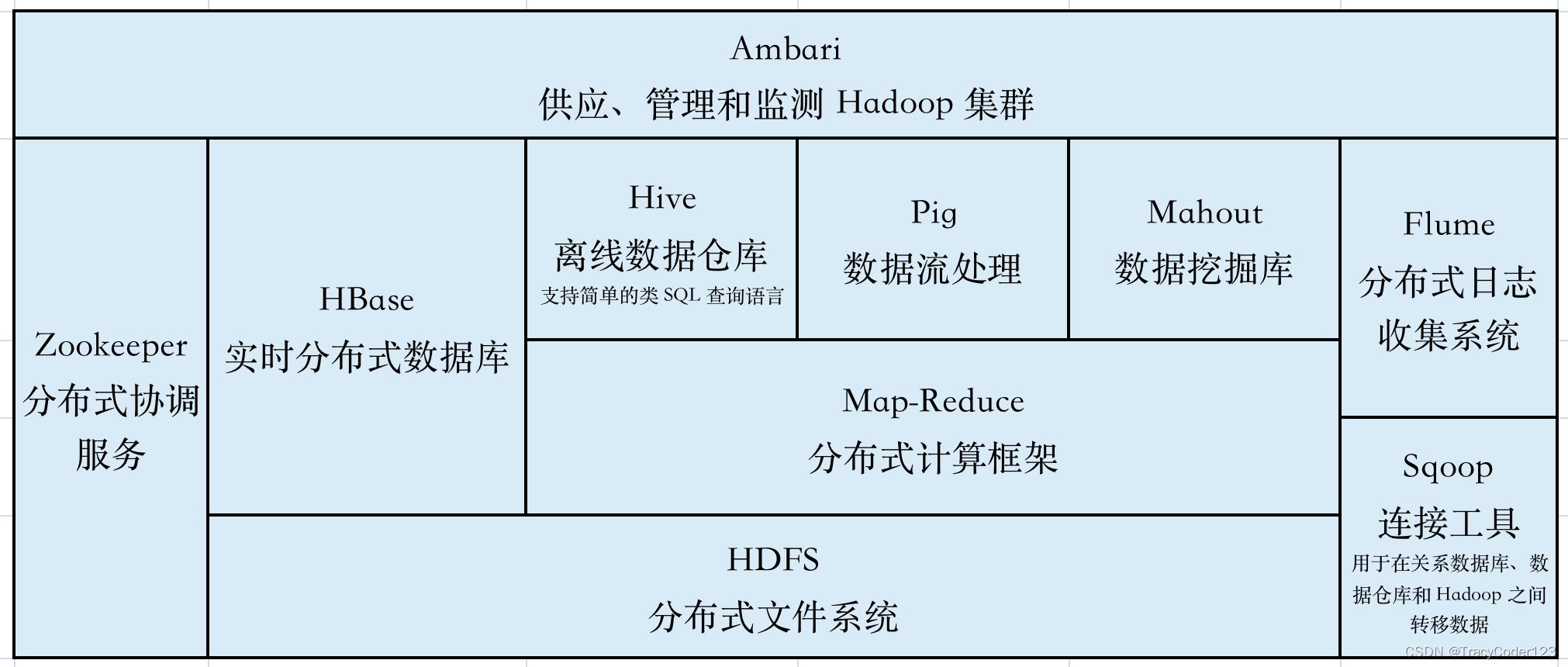
Hadoop不是某个单一技术的软件,它是一个大数据处理系统和生态的总称,Hadoop最初出现在大众视野中时,指的是:HDFS文件系统 + Map-Reduce计算引擎 + HBASE数据库(BigTable 原理)。
-
Hadoop特点:
解耦: 从HDFS读取原始数据,再用MapReduce计算引擎进行计算,最后用HBASE来存储计算后的结果。
分布式: 数据从HDFS读取是分治的——同时存储在多台机器上;通过MapReduce计算引擎来计算是分治的——多台机器一起计算,每台机器计算一小部分;最后将结果保存到HBASE也是分治的——结果会分布存储到多台机器中。
低成本: 软件低成本——开源使用;硬件低成本——几乎适配所有操作系统。 -
Hadoop生态系统:
3.Spark阶段
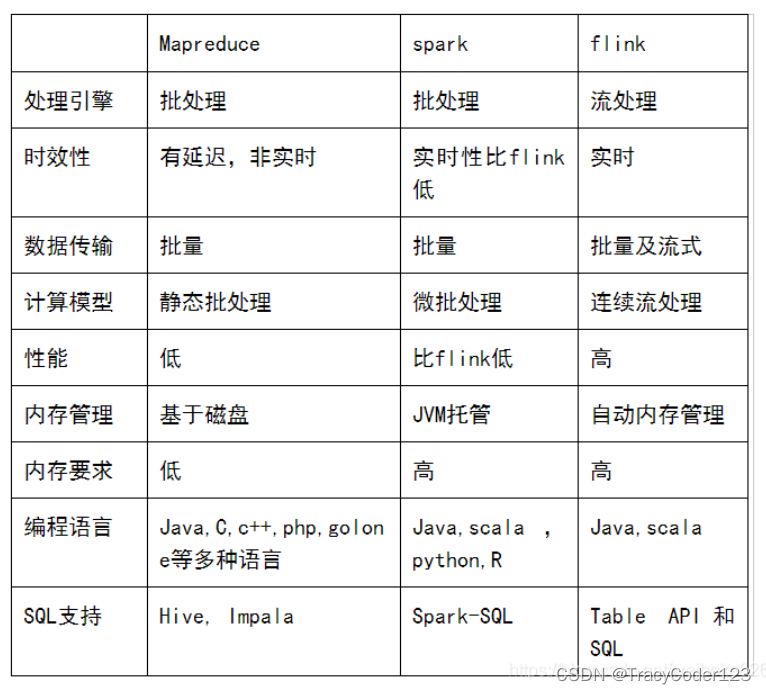
- Hadoop MapRedcue 缺点:
延迟过高,无法胜任实时、快速计算需求的问题,使得需要进行多路计算和迭代算法的用例的作业过程不够高效。
Spark 基于MapReduce技术,继承了 Hadoop MapReduce 其分布式并行计算的优点,并改进了 MapReduce 明显的缺陷,基于内存迭代计算,可以融入Hadoop生态系统。
Spark基于 微批量处理 ,把流数据看成是一个个小的批处理数据块分别处理,所以延迟性能做到秒级。
4.Flink阶段
Flink是一个流式计算框架,实效性达到了实时级别。
- Hadoop Map-Reduce、Spark、Flink区别:
参考
blog1
blog2
blog3
blog4