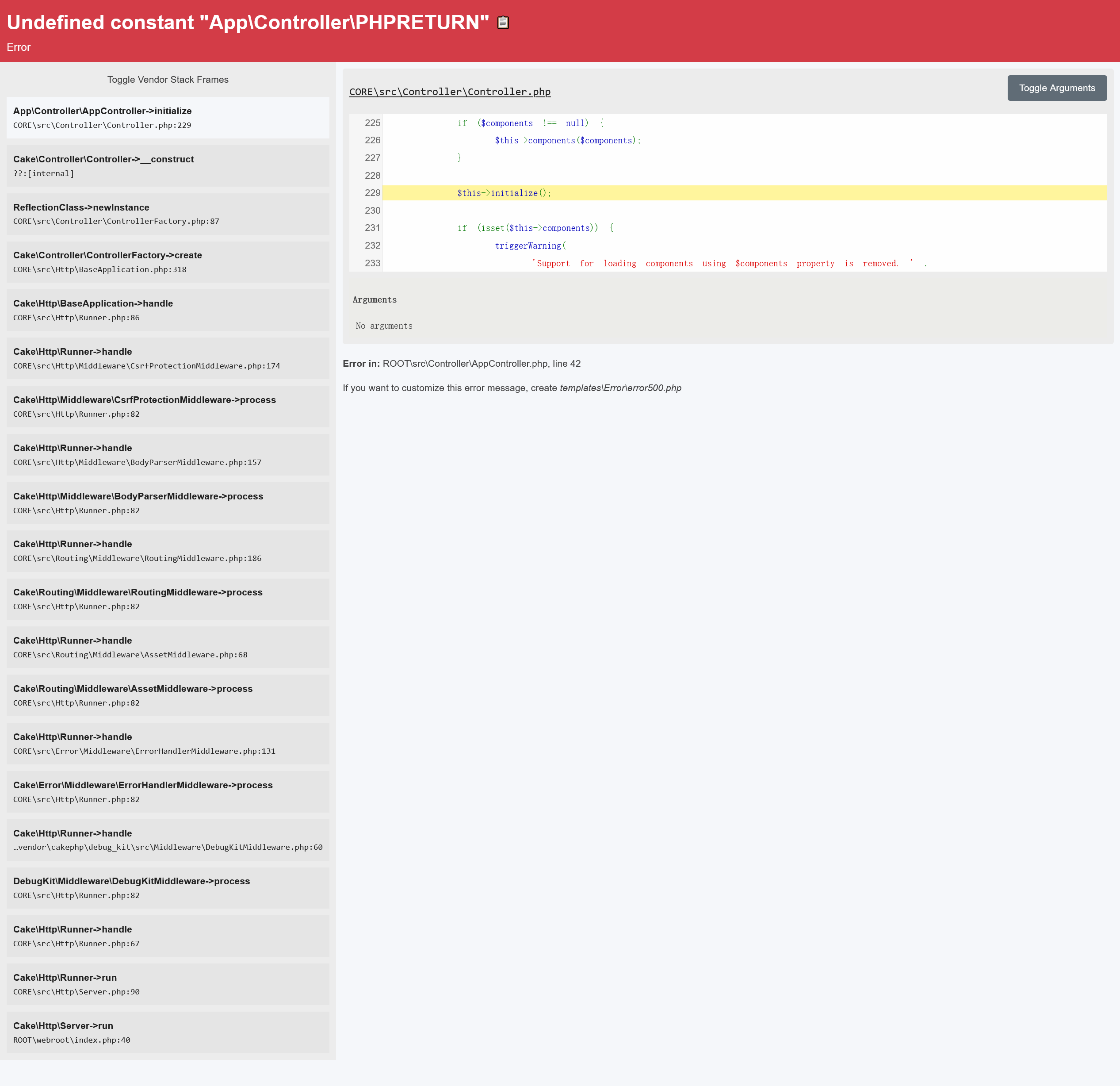
MySQL中,数据存到了什么地方?
存储到了硬盘的文件上,被称为:数据文件 或 表空间
每个数据库都是由 一组数据文件 组成,这些文件包含了:所有表、索引、其他相关对象的数据
MySQL 以什么样的方式访问?
MySQL 通过 存储引擎 来访问数据文件
什么是存储引擎?
存储引擎是一种插件式架构,定义了数据如何被存储、管理、检索
- Innodb:支持事务
- MylSAM:不支持事务,但执行快速
插件式架构是什么?
插件式架构(Plugin Architecture)是一种软件设计模式,它允许在不改变主程序结构的情况下,扩展和定制软件功能
使用插件式架构,用户可以在软件中添加新的功能模块或替换现有的模块,而无需修改主程序代码,从而提高了软件的灵活性、可维护性和可扩展性。
通常,插件式架构的基本思想是将软件划分成核心部分和插件部分两个部分
核心部分:负责提供基本的框架和服务
插件部分:为核心部分提供额外的功能或改善现有功能
插件部分通过接口和API与核心部分进行交互,从而实现了增强软件功能的目的
插件式架构广泛应用于各种软件系统中,例如:
- Web浏览器:用户可以安装不同的插件,如Flash、Java、广告拦截等,以实现特定的功能和定制化
- 文本编辑器:用户可以安装不同的插件,如自动补全、语法高亮显示、版本管理等,以提高开发效率
- 图形图像处理软件:用户可以安装不同的插件,如滤镜、图层、调色等,以改善图像处理质量
插件式架构是一种强大的软件设计模式,可以使软件具有更高的灵活性、可扩展性和可维护性
页:从表中获取记录的基本单位
磁盘可实现数据的持久化
但是,真正处理数据的过程,发生在内存上,所以需要将磁盘上的数据加载到内存中
磁盘读写速度非常慢,若想从表中获取记录,但交互的单位是一条条记录,会导致读取速度非常慢
InnoDB 采取的方式:将数据划分为多个页,以页作为与磁盘交互的基本单位
页大小,默认 16 KB,即一次最少从磁盘读取 16 KB 内容

InnoDB 行格式

CREATE TABLE my_table (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(50) NOT NULL,
age INT NOT NULL,
sex TINYINT(4) DEFAULT 0,
phone VARCHAR(20),
address VARCHAR(100),
PRIMARY KEY (id)
);
INSERT INTO my_table
( id, name, age, sex, phone, address )
VALUES ( 1, 'zhangsan', 18, 0, '131', '上海市' );
页结构
从数据文件中,返回的数据页,可以被划分成多个不同的部分,比如
- User Records:用户记录
- Free Space:空闲记录
当插入一条新记录时,会从 Free Space 申请一个记录大小的空间,划分到 User Records 中去
INSERT INTO page_demo
VALUES(1, 100, 'aaaa'), (2, 200, 'bbbb'), (3, 300, 'cccc'), (4, 400, 'dddd');

- heap_no:当前记录,在页中的,相对位置
- record_type:当前记录的类型(0 普通记录、2 Infimum 记录、3 Supremum 记录)
- next_record:当前记录的真实数据,到下一条记录的真实数据
比如 32 表示:从
当前记录的真实数据地址开始,向后找 32 字节,便是下一条记录的真实数据
0 表示无下一条记录
负数表示:向前寻找
- n_owned:“殿后的带头大哥”所记录的,所有组中的,所有记录的条数
比如
Infimum中n_owned为 1,表示:以Infimum记录为最后一个节点,这个分组只有 1 条记录(它自己)Supremum中n_owned为 5,表示:以Supremum记录为最后一个节点,这个分组有 5 条记录(自己 + 插入的 4 条记录)
Infimum记录所在的分组,只能有 1 条记录
Supremum记录所在的分组,只能有 1 ~ 8 条记录
剩下的分组,条数范围:只能是 4 ~ 8 条记录
MySQL,会自动在每个页中,添加 2 条记录,可以被称为虚拟记录
- 最小记录:Infimum
- 最大记录:Supremum

页目录是什么?
一种数据结构,可以
- 存储
数据页位置信息 - 管理
碎片空间
通过页目录可以快速定位到某个数据页,并知道该页中哪些空间是可用的
一个组,对应一个槽,槽中存放每个组中,最大的那条记录,在页面中的地址偏移量

槽,所指的记录,对应的主键值大小排序:从小到大,因此可以用二分查找
通过二分,寻找主键值为 6 的记录
e n d − s t a r t = 4 − 0 = 4 中间槽的位置 = s t a r t + e n d 2 = 0 + 4 2 = 2 槽 2 所指的记录,主键值为 8 ∵ 8 > 6 ,后面多了, e n d 缩小 ∴ e n d = 2 end -start = 4 - 0 = 4 \\ 中间槽的位置 = \frac{start + end}{2} = \frac{0 + 4}{2} = 2 \\ ~ \\ 槽2所指的记录,主键值为 ~ 8 \\ \because 8 > 6,后面多了,end ~ 缩小 \\ \therefore end = 2 end−start=4−0=4中间槽的位置=2start+end=20+4=2 槽2所指的记录,主键值为 8∵8>6,后面多了,end 缩小∴end=2
e n d − s t a r t = 2 − 0 = 2 中间槽的位置 = s t a r t + e n d 2 = 0 + 2 2 = 1 槽 1 所指的记录,主键值为 4 ∵ 4 < 6 ,前面多了, s t a r t 变大 ∴ s t a r t = 1 end -start = 2 - 0 = 2 \\ 中间槽的位置 = \frac{start + end}{2} = \frac{0 + 2}{2} = 1 \\ ~ \\ 槽1所指的记录,主键值为 ~ 4 \\ \because 4 < 6,前面多了,start ~ 变大 \\ \therefore start = 1 end−start=2−0=2中间槽的位置=2start+end=20+2=1 槽1所指的记录,主键值为 4∵4<6,前面多了,start 变大∴start=1
因为:
e
n
d
−
s
t
a
r
t
=
2
−
1
=
1
end -start = 2 - 1 = 1
end−start=2−1=1
只相差 1 位
因此,如果主键值为 6 的记录,在表中存在
则一定在槽 1 开始,槽 2 结束的位置之间
从 槽1 开始的位置,依次遍历,即可找到主键值为 6 的记录
目录项的由来
一个页中的数据存储有限,若想存储更多数据,就需要更多的页
如何从众多页中,快速获取所需主键值的记录?给每个页,建立一个目录项
目录项包含两个部分:
- key:记录当前页中,最小的主键值
- page_no:页号,通过页号,可定位到对应页
在多个页中,查找主键值为 20 的记录
- 先到
存储目录项记录的页中,根据二分,找到 12 < 20 < 209,定位到页 9 (一个例子) - 在页 9 中,根据二分,获取对应记录
可以为存储目录项记录的页,生成一个更高级的目录项记录(套娃)
假设每个页可以存放 100 条数据记录,1000 条目录项记录
- B+树有一层:最多存放 100 条数据记录
- B+树有二层:最多存放 100 × 1000 = 100000 = 10 万 100 \times 1000 = 100000 = 10万 100×1000=100000=10万 条数据记录
- B+树有三层:最多存放 100 × 1000 × 1000 = 100000000 = 1 亿 100 \times 1000 \times 1000 = 100000000 = 1亿 100×1000×1000=100000000=1亿 条数据记录
- B+树有四层:最多存放 100 × 1000 × 1000 × 1000 = 100000000000 = 1000 亿 100 \times 1000 \times 1000 \times 1000 = 100000000000 = 1000亿 100×1000×1000×1000=100000000000=1000亿 条数据记录
索引
索引的定义
从基本层面来看,数据库,只做两件事
- 当插入时,它就保存数据
- 当查询时,它会返回数据
索引:额外的元数据,帮助快速的定位想要查询的数据
它是一种,空间换取查找时间的权衡
聚簇索引
- 使用记录的
主键值大小,进行记录和页的排序 - B+树叶子节点,存储完整的用户记录(这个记录,存储了所有的列的值)
每个表只能有一个聚簇索引,因为每个表只能按照一种排序方式来存储数据
通常情况下,聚簇索引会针对主键列进行创建,这样可以保证主键唯一性,并且可以根据主键值来快速查找、排序和分组数据。
与非聚簇索引不同,聚簇索引不仅包含了索引值,还包含了整个数据行的信息
因此,在使用聚簇索引查询时,如果需要扫描多个行,则需要读取多次磁盘操作,这可能会影响查询效率。
但是由于聚簇索引将具有相似键值的行存储在一起,因此对于特定范围的查询,聚簇索引比非聚簇索引更高效。
InnoDB存储引擎,会自动创建聚簇索引
没有索引的查找
- 如果查找条件为
主键,则可通过页目录,使用二分,快速定位到槽 - 如果查找条件为
非主键,需从头到尾的遍历,直到找到对应记录
非主键的查找条件,在页中的记录,没有规律,因此需全量遍历
针对非主键的搜索条件,能否有一种高效的查询方式? 二级索引
我们可以多建几颗 B+ 树,不同 B+ 树中的数据,采用不同的排序规则
二级索引
相对于聚簇索引而言,二级索引并不会直接影响到数据行的物理存储位置,而是将索引值映射到具体的记录行
因此,在使用二级索引查询时,需要先根据二级索引找到匹配的记录行,然后再通过主键或聚簇索引查找对应的数据
由于二级索引不需要按照特定顺序组织数据,因此通常比聚簇索引更容易创建和更加灵活
但是相对于聚簇索引而言,二级索引的查询效率可能会更低,特别是在需要扫描大量记录时
因此,在设计和使用二级索引时需要特别注意优化查询语句,避免对性能造成过大的影响
参考:《MySQL 是怎样运行的》第四章、第五章、第六章