CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Learning Locally Editable Virtual Humans

标题:学习本地可编辑虚拟人
作者:Hsuan-I Ho, Lixin Xue, Jie Song, Otmar Hilliges
文章链接:https://arxiv.org/abs/2305.00121
项目代码:https://custom-humans.github.io/


摘要:
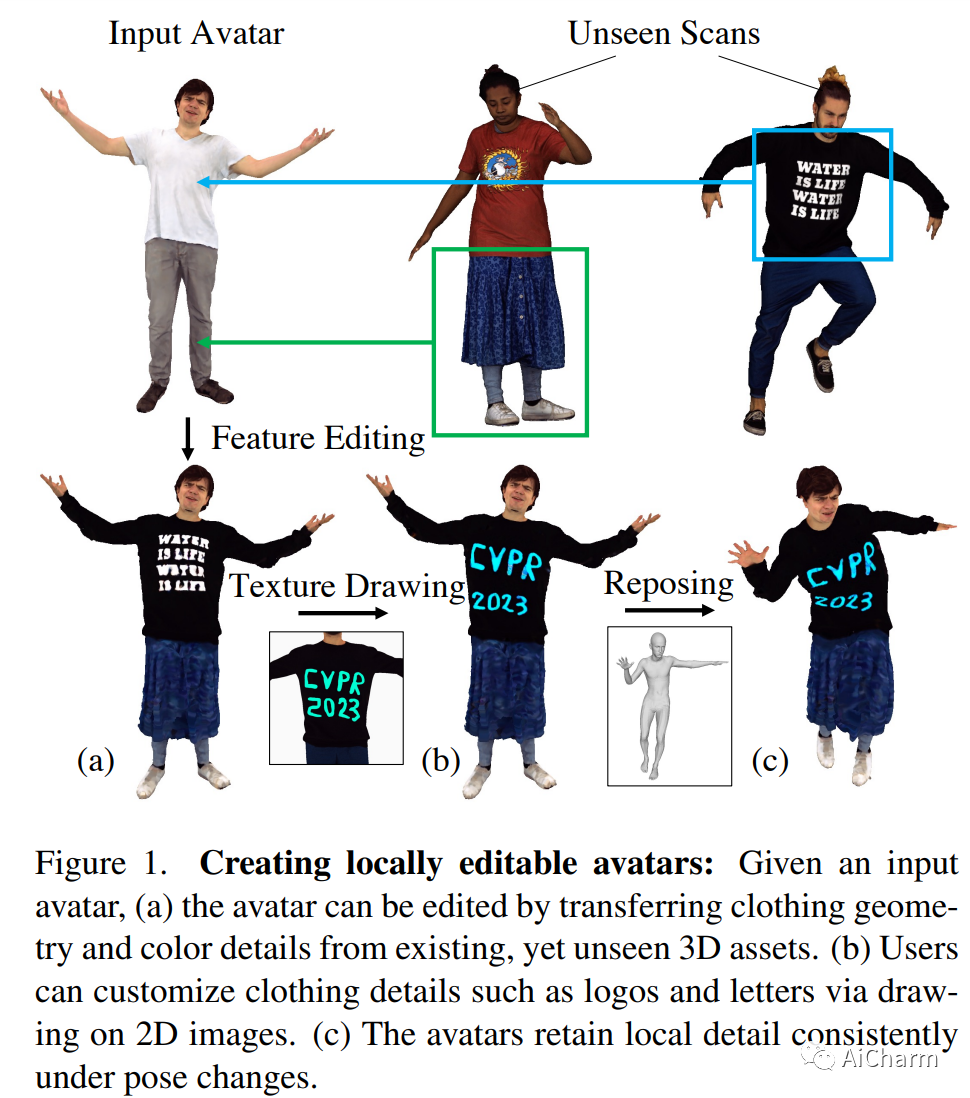
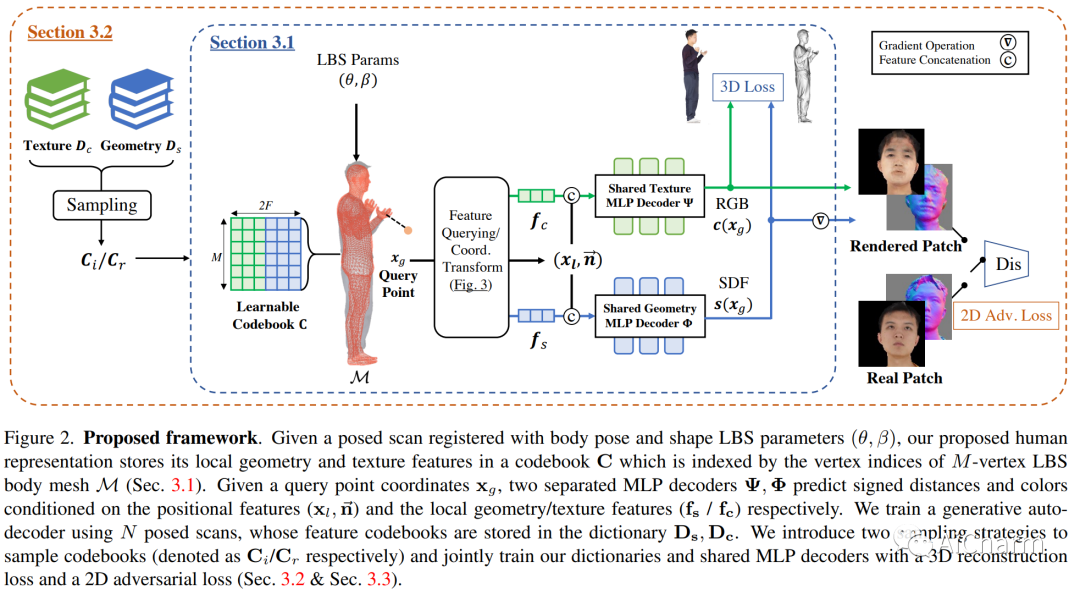
在本文中,我们提出了一种新颖的混合表示和端到端可训练网络架构来对完全可编辑和可定制的神经化身进行建模。我们工作的核心在于将神经场的建模能力与蒙皮网格的易用性和固有 3D 一致性相结合的表示。为此,我们构建了一个可训练的特征码本来存储可变形身体模型顶点上的局部几何和纹理特征,从而利用其在关节下的一致拓扑结构。然后将这种表示用于生成式自动解码器架构,该架构允许适合看不见的扫描和对具有不同外观和几何形状的逼真化身进行采样。此外,我们的表示允许通过在 3D 资产之间交换局部特征来进行局部编辑。为了验证我们的头像创建和编辑方法,我们贡献了一个新的高质量数据集,称为 CustomHumans,用于训练和评估。我们的实验定量和定性地表明,与最先进的方法相比,我们的方法生成了多种详细的化身并实现了更好的模型拟合性能。我们的代码和数据集可在此 https URL 上获得。
2.It is all about where you start: Text-to-image generation with seed selection

标题:这一切都与您的起点有关:通过种子选择生成文本到图像
作者:Dvir Samuel, Rami Ben-Ari, Simon Raviv, Nir Darshan, Gal Chechik
文章链接:https://arxiv.org/abs/2304.14530
项目代码:https://github.com/microsoft/AdaM
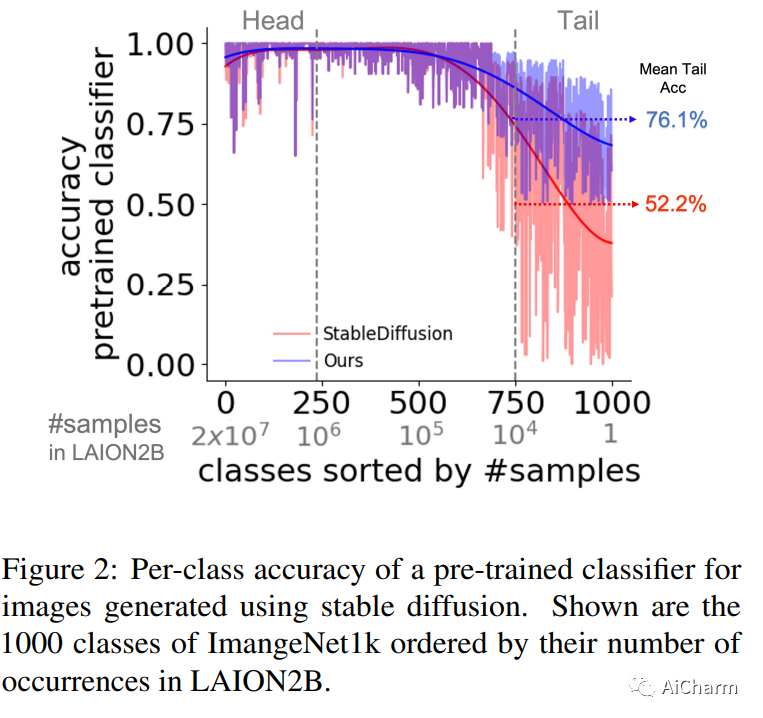
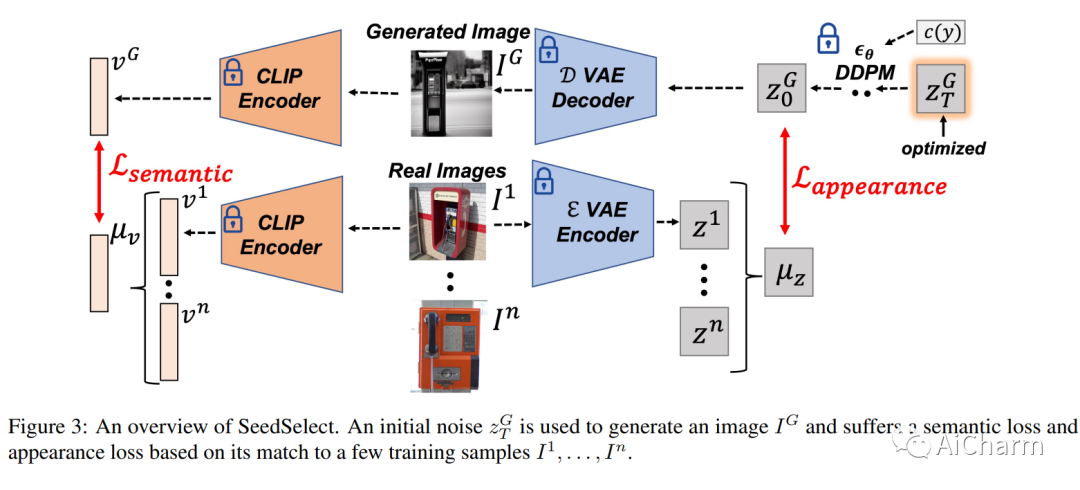
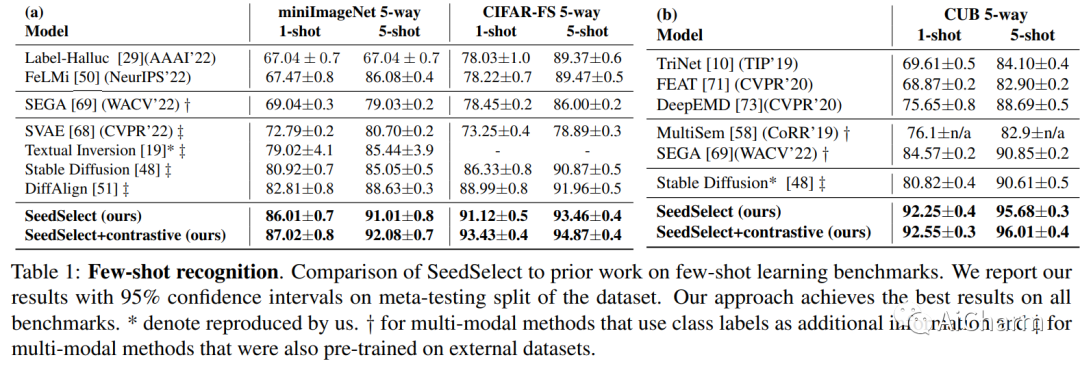
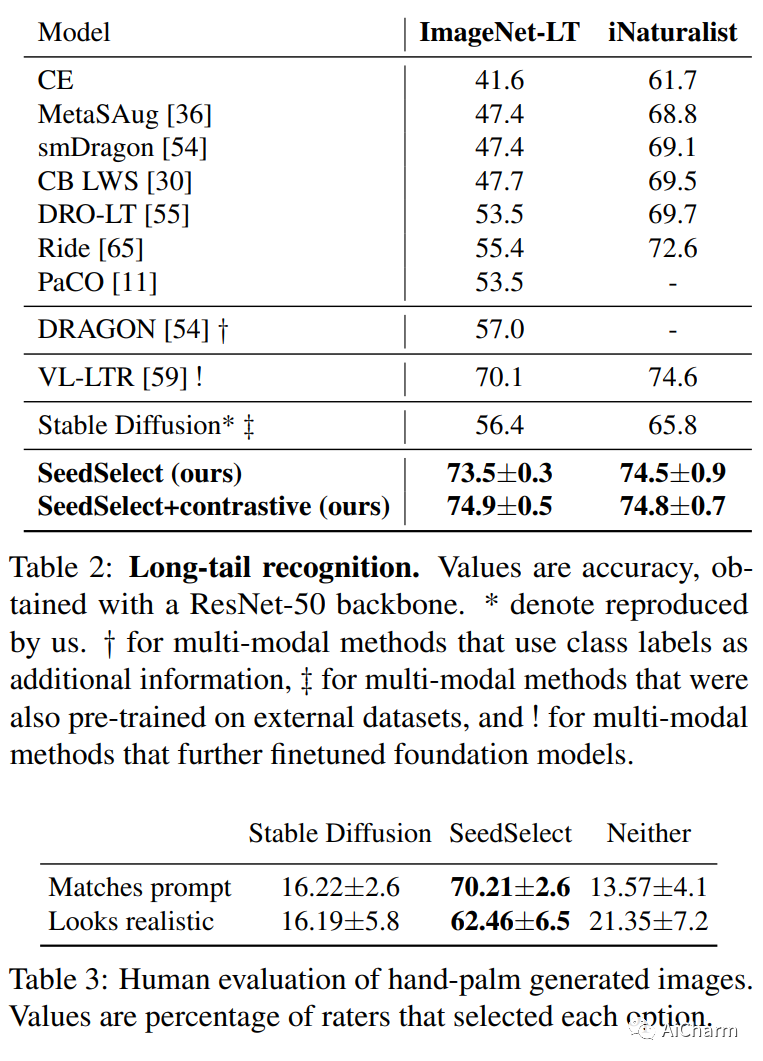
v摘要:
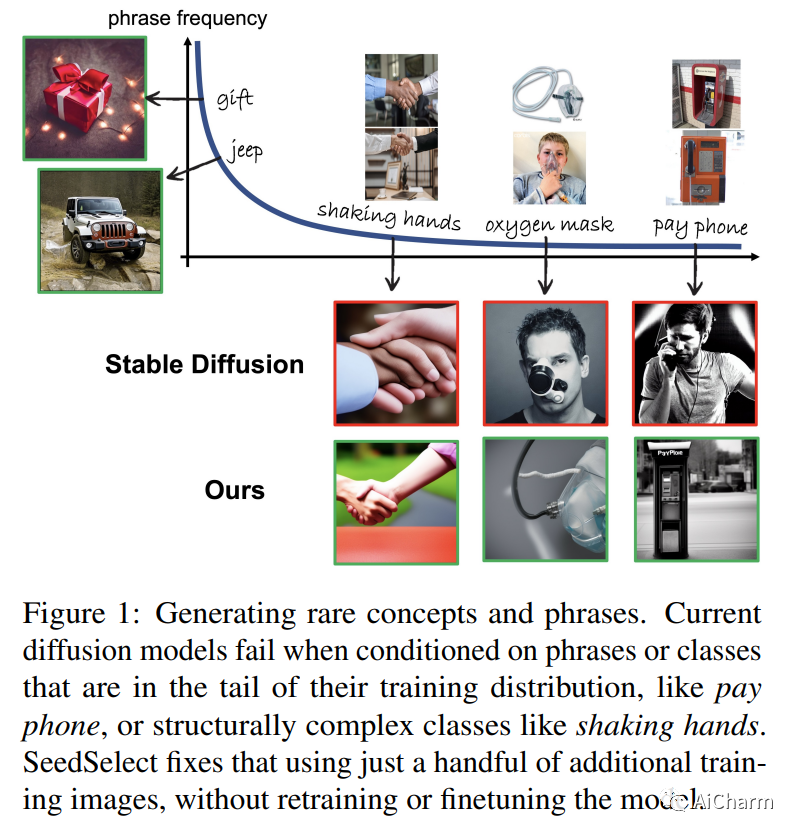
文本到图像的扩散模型可以在新的构图和场景中综合各种概念。然而,他们仍然难以生成不常见的概念、罕见的不寻常组合或像手掌这样的结构化概念。它们的局限性部分是由于其训练数据的长尾性质:网络抓取的数据集非常不平衡,导致模型无法充分代表分布尾部的概念。在这里,我们描述了不平衡训练数据对文本到图像模型的影响,并提供了补救措施。我们表明,通过在噪声空间中仔细选择合适的生成种子,可以正确生成稀有概念,我们称之为 SeedSelect 的技术。SeedSelect 是高效的,不需要重新训练扩散模型。我们评估了 SeedSelect 在一系列问题上的优势。首先,在少样本语义数据增强中,我们为少样本和长尾基准生成语义正确的图像。我们展示了所有类别的分类改进,包括扩散模型训练数据的头部和尾部。我们进一步评估了 SeedSelect 在校正手部图像时的效果,这是当前扩散模型的一个众所周知的缺陷,并表明它显着改善了手部生成。
3.GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation

标题:GeneFace++:通用且稳定的实时音频驱动 3D 说话人脸生成
作者:Zhenhui Ye, Jinzheng He, Ziyue Jiang, Rongjie Huang, Jiawei Huang, Jinglin Liu, Yi Ren, Xiang Yin, Zejun Ma, Zhou Zhao
文章链接:https://arxiv.org/abs/2305.00787
项目代码:https://genefaceplusplus.github.io/
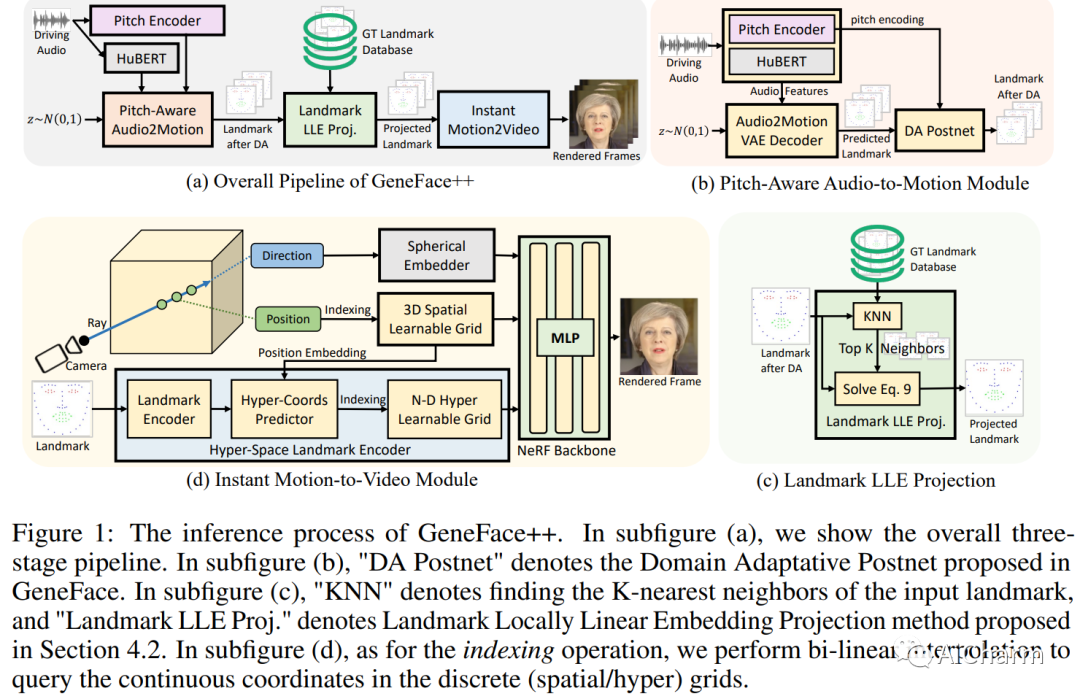
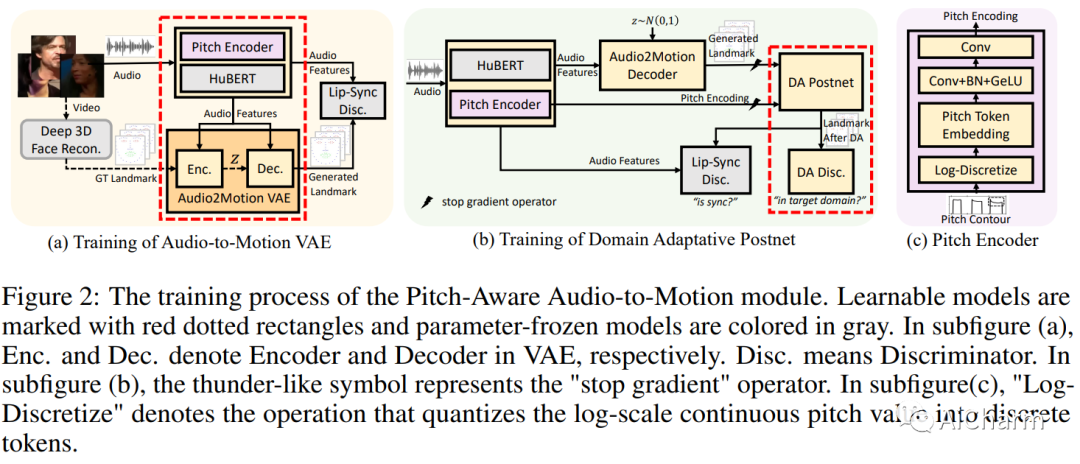
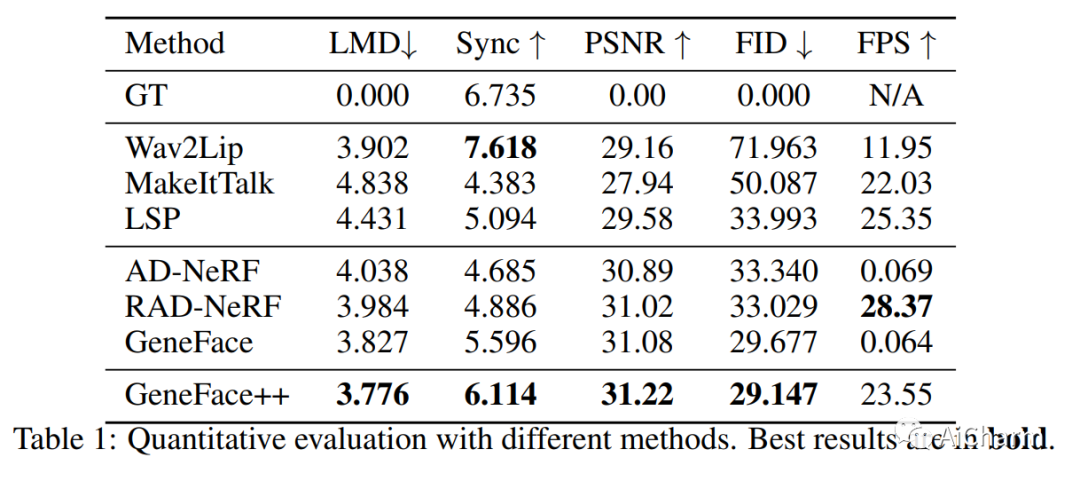
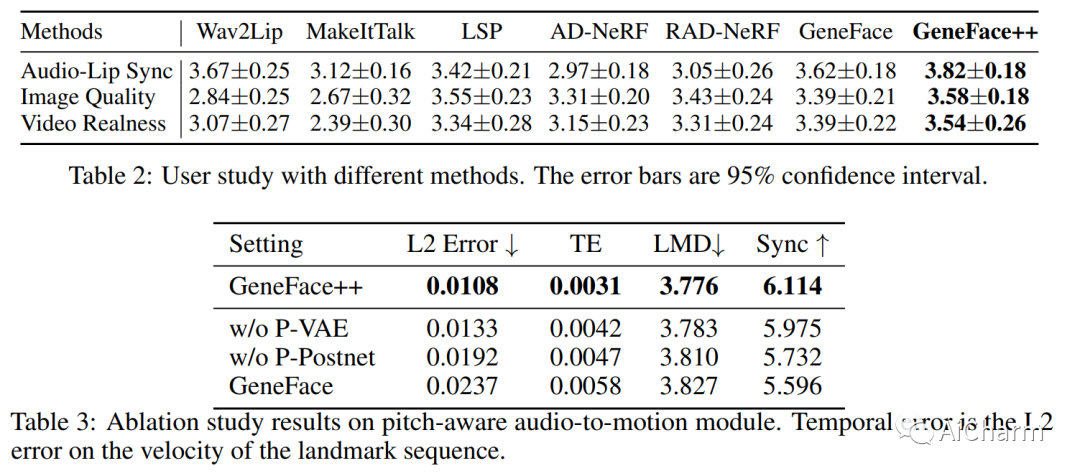
摘要:
用任意语音音频生成说话人肖像是数字人和虚拟世界领域的一个关键问题。一种现代的说话人脸生成方法有望实现通用的音频-嘴唇同步、良好的视频质量和高系统效率的目标。最近,神经辐射场(NeRF)成为该领域流行的渲染技术,因为它可以通过几分钟的训练视频实现高保真和 3D 一致的说话人脸生成。然而,基于 NeRF 的方法仍然存在一些挑战:1)对于口型同步,很难生成具有高时间一致性和音频口型精度的长面部运动序列;2)在视频质量方面,由于用于训练渲染器的数据有限,容易受到域外输入条件的影响,偶尔会产生糟糕的渲染结果;3) 至于系统效率,vanilla NeRF 缓慢的训练和推理速度严重阻碍了它在实际应用中的使用。在本文中,我们提出了 GeneFace++ 来应对这些挑战:1)利用音调轮廓作为辅助特征,并在面部运动预测过程中引入时间损失;2) 提出一种地标局部线性嵌入方法来调节预测运动序列中的异常值,以避免鲁棒性问题;3) 设计一个计算高效的基于 NeRF 的运动到视频渲染器,以实现快速训练和实时推理。通过这些设置,GeneFace++ 成为第一个基于 NeRF 的方法,可以通过广义的音频-嘴唇同步实现稳定和实时的说话人脸生成。大量实验表明,我们的方法在主观和客观评估方面优于最先进的基线。此 https URL 提供了视频示例。
更多Ai资讯:公主号AiCharm