视频地址:尚硅谷大数据Spark教程从入门到精通_哔哩哔哩_bilibili
- 尚硅谷大数据技术Spark教程-笔记01【SparkCore(概述、快速上手、运行环境、运行架构)】
- 尚硅谷大数据技术Spark教程-笔记02【SparkCore(核心编程,RDD-核心属性-执行原理-基础编程-并行度与分区-转换算子)】
- 尚硅谷大数据技术Spark教程-笔记03【SparkCore(核心编程,RDD-转换算子-案例实操)】
- 尚硅谷大数据技术Spark教程-笔记04【SparkCore(核心编程,RDD-行动算子-序列化-依赖关系-持久化-分区器-文件读取与保存)】
- 尚硅谷大数据技术Spark教程-笔记05【SparkCore(核心编程,累加器、广播变量)】
- 尚硅谷大数据技术Spark教程-笔记06【SparkCore(案例实操,电商网站)】
目录
01_尚硅谷大数据技术之SparkCore
第06章-Spark案例实操
P110【110.尚硅谷_SparkCore - 案例实操 - 数据准备 & 数据说明】12:03
P111【111.尚硅谷_SparkCore - 案例实操 - 需求一 - 需求设计 & 思路梳理】09:46
P112【112.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 分别统计点击,下单,支付的数量】09:55
P113【113.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 合并点击,下单,支付的数量】12:18
P114【114.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 第二种实现方式】12:18
P115【115.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 第三种实现方式】12:56
P116【116.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 第四种实现方式】18:29
P117【117.尚硅谷_SparkCore - 案例实操 - 需求二 - 功能实现】14:48
P118【118.尚硅谷_SparkCore - 案例实操 - 需求三 - 需求介绍】03:41
P119【119.尚硅谷_SparkCore - 案例实操 - 需求三 - 需求分析 - 图解】19:05
P120【120.尚硅谷_SparkCore - 案例实操 - 需求三 - 代码实现 - 分母的计算】05:59
P121【121.尚硅谷_SparkCore - 案例实操 - 需求三 - 代码实现 - 分子的计算并求转换率】15:27
P122【122.尚硅谷_SparkCore - 案例实操 - 需求三 - 代码实现 - 优化需求】08:30
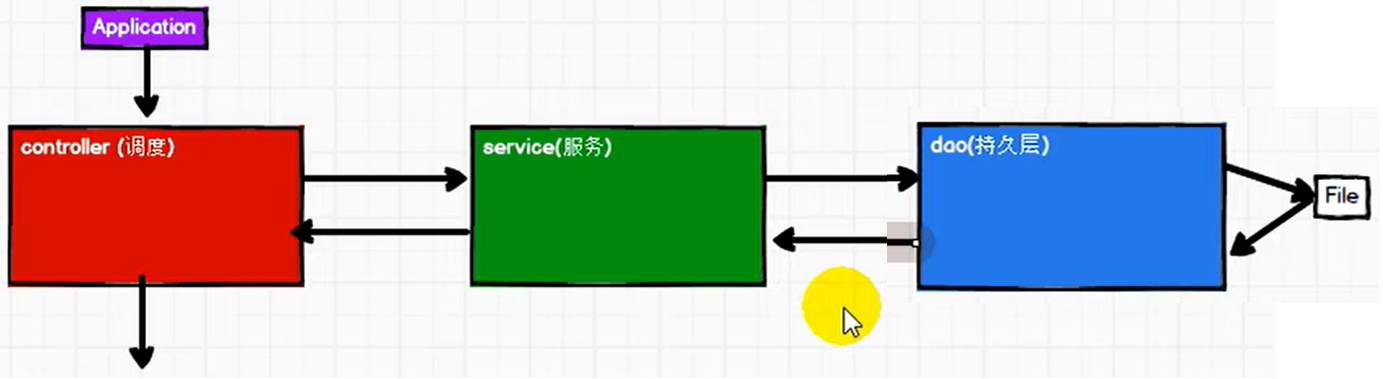
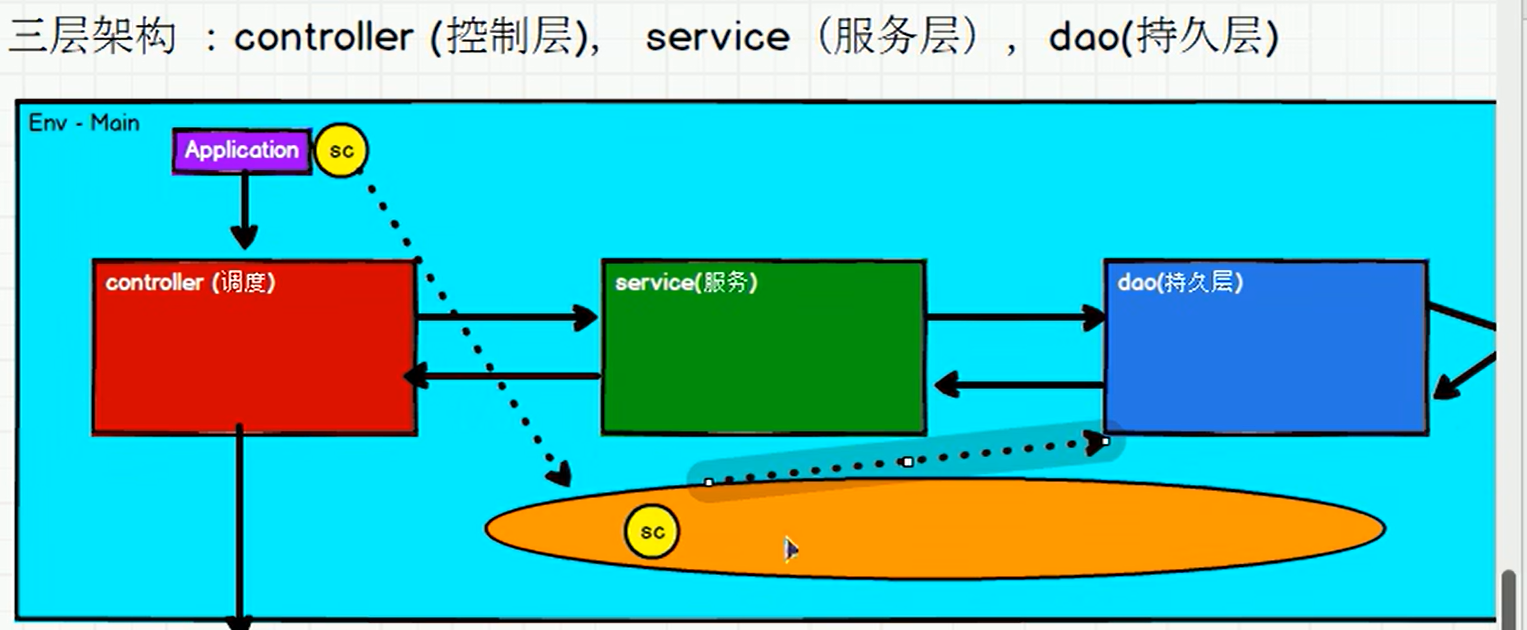
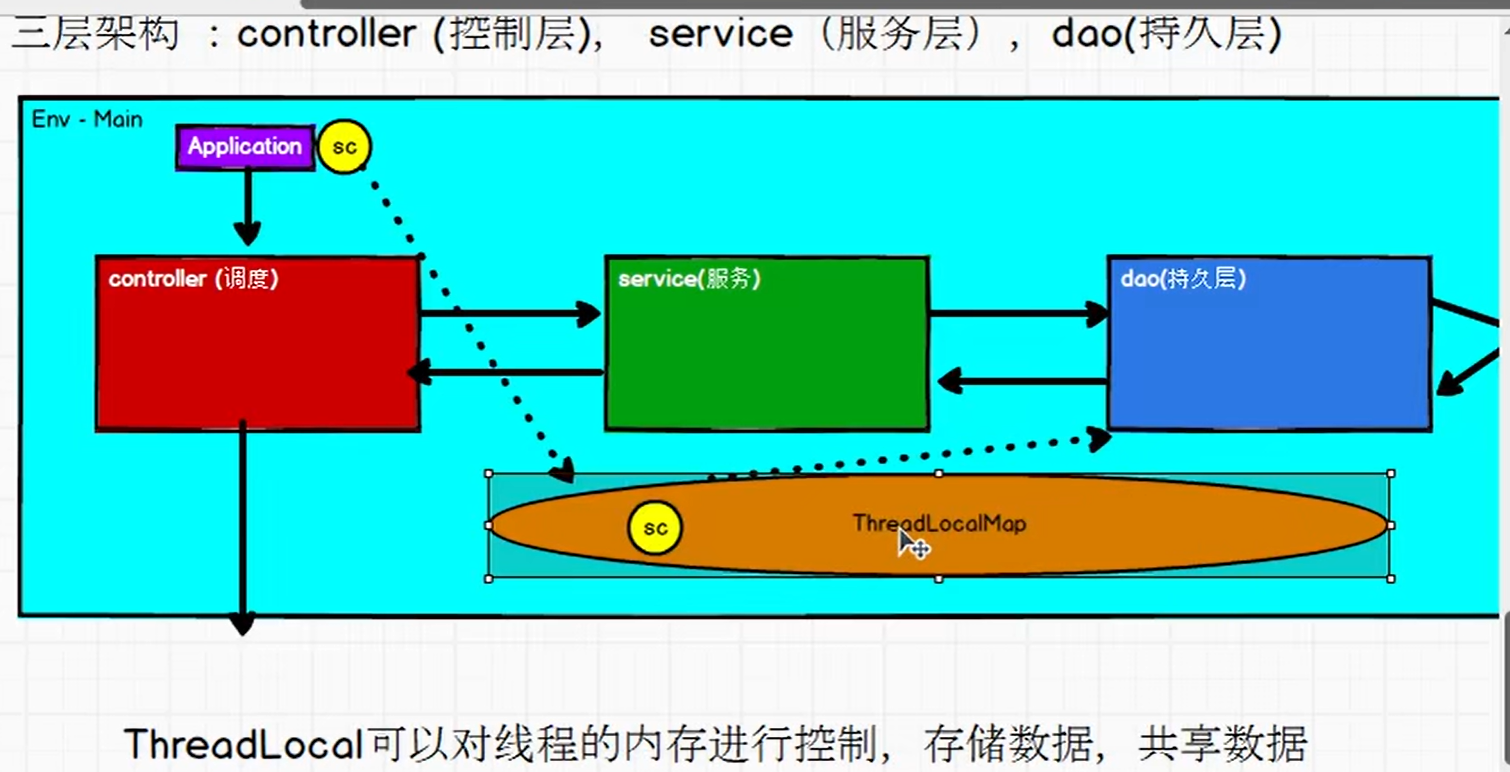
P123【123.尚硅谷_SparkCore - 工程化代码 - 架构模式 - 三层架构介绍】11:04
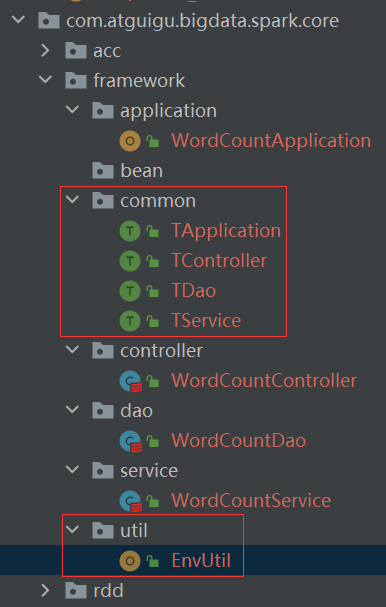
P124【124.尚硅谷_SparkCore - 工程化代码 - 架构模式 - 三层架构代码实现】13:47
P125【125.尚硅谷_SparkCore - 工程化代码 - 架构模式 - 架构代码优化】17:48
P126【126.尚硅谷_SparkCore - 工程化代码 - 架构模式 - ThreadLocal解释】04:31
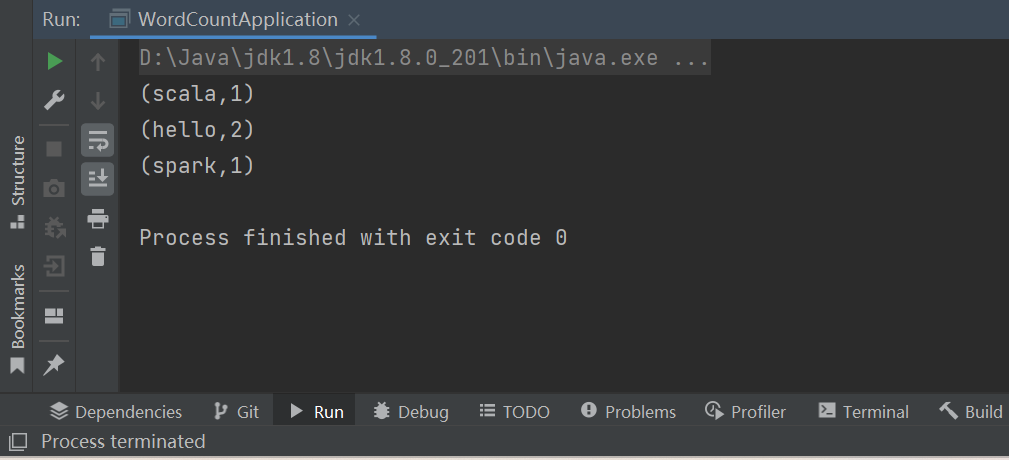
P127【127.尚硅谷_SparkCore - 总结 - 课件梳理】30:09
01_尚硅谷大数据技术之SparkCore
第06章-Spark案例实操
P110【110.尚硅谷_SparkCore - 案例实操 - 数据准备 & 数据说明】12:03
第6章 Spark案例实操
在之前的学习中,我们已经学习了 Spark 的基础编程方式,接下来,我们看看在实际的工作中如何使用这些 API 实现具体的需求。这些需求是电商网站的真实需求,所以在实现功能前,咱们必须先将数据准备好。

P111【111.尚硅谷_SparkCore - 案例实操 - 需求一 - 需求设计 & 思路梳理】09:46
6.1 需求1:Top10热门品类
6.1.1 需求说明
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_Req1_HotCategoryTop10Analysis {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 1. 读取原始日志数据
// 2. 统计品类的点击数量:(品类ID,点击数量)
// 3. 统计品类的下单数量:(品类ID,下单数量)
// 4. 统计品类的支付数量:(品类ID,支付数量)
// 5. 将品类进行排序,并且取前10名
// 点击数量排序,下单数量排序,支付数量排序
// 元组排序:先比较第一个,再比较第二个,再比较第三个,依此类推
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
// 6. 将结果采集到控制台打印出来
}
}P112【112.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 分别统计点击,下单,支付的数量】09:55
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_Req1_HotCategoryTop10Analysis {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 1. 读取原始日志数据
val actionRDD = sc.textFile("datas/user_visit_action.txt")
// 2. 统计品类的点击数量:(品类ID,点击数量)
val clickActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(6) != "-1"
}
)
val clickCountRDD: RDD[(String, Int)] = clickActionRDD.map(
action => {
val datas = action.split("_")
(datas(6), 1)
}
).reduceByKey(_ + _)
// 3. 统计品类的下单数量:(品类ID,下单数量)
val orderActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(8) != "null"
}
)
// orderid => 1,2,3
// 【(1,1),(2,1),(3,1)】
val orderCountRDD = orderActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(8)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 4. 统计品类的支付数量:(品类ID,支付数量)
val payActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(10) != "null"
}
)
// orderid => 1,2,3
// 【(1,1),(2,1),(3,1)】
val payCountRDD = payActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(10)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 5. 将品类进行排序,并且取前10名
// 点击数量排序,下单数量排序,支付数量排序
// 元组排序:先比较第一个,再比较第二个,再比较第三个,依此类推
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
// 6. 将结果采集到控制台打印出来
sc.stop()
}
}P113【113.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 合并点击,下单,支付的数量】12:18
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_Req1_HotCategoryTop10Analysis {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 1. 读取原始日志数据
val actionRDD = sc.textFile("datas/user_visit_action.txt")
// 2. 统计品类的点击数量:(品类ID,点击数量)
val clickActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(6) != "-1"
}
)
val clickCountRDD: RDD[(String, Int)] = clickActionRDD.map(
action => {
val datas = action.split("_")
(datas(6), 1)
}
).reduceByKey(_ + _)
// 3. 统计品类的下单数量:(品类ID,下单数量)
val orderActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(8) != "null"
}
)
// orderid => 1,2,3
// 【(1,1),(2,1),(3,1)】
val orderCountRDD = orderActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(8)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 4. 统计品类的支付数量:(品类ID,支付数量)
val payActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(10) != "null"
}
)
// orderid => 1,2,3
// 【(1,1),(2,1),(3,1)】
val payCountRDD = payActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(10)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 5. 将品类进行排序,并且取前10名
// 点击数量排序,下单数量排序,支付数量排序
// 元组排序:先比较第一个,再比较第二个,再比较第三个,依此类推
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
//
// cogroup = connect + group
val cogroupRDD: RDD[(String, (Iterable[Int], Iterable[Int], Iterable[Int]))] =
clickCountRDD.cogroup(orderCountRDD, payCountRDD)
val analysisRDD = cogroupRDD.mapValues {
case (clickIter, orderIter, payIter) => {
var clickCnt = 0
val iter1 = clickIter.iterator
if (iter1.hasNext) {
clickCnt = iter1.next()
}
var orderCnt = 0
val iter2 = orderIter.iterator
if (iter2.hasNext) {
orderCnt = iter2.next()
}
var payCnt = 0
val iter3 = payIter.iterator
if (iter3.hasNext) {
payCnt = iter3.next()
}
(clickCnt, orderCnt, payCnt)
}
}
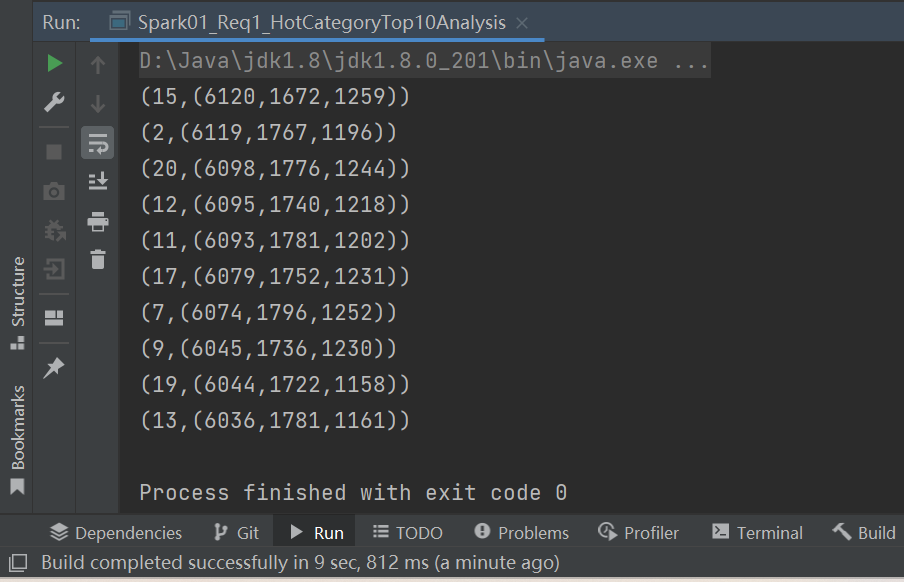
val resultRDD = analysisRDD.sortBy(_._2, false).take(10)
// 6. 将结果采集到控制台打印出来
resultRDD.foreach(println)
sc.stop()
}
}P114【114.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 第二种实现方式】12:18
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_Req1_HotCategoryTop10Analysis1 {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// Q : actionRDD重复使用
// Q : cogroup性能可能较低
// 1. 读取原始日志数据
val actionRDD = sc.textFile("datas/user_visit_action.txt")
actionRDD.cache()
// 2. 统计品类的点击数量:(品类ID,点击数量)
val clickActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(6) != "-1"
}
)
val clickCountRDD: RDD[(String, Int)] = clickActionRDD.map(
action => {
val datas = action.split("_")
(datas(6), 1)
}
).reduceByKey(_ + _)
// 3. 统计品类的下单数量:(品类ID,下单数量)
val orderActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(8) != "null"
}
)
// orderid => 1,2,3
// 【(1,1),(2,1),(3,1)】
val orderCountRDD = orderActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(8)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// 4. 统计品类的支付数量:(品类ID,支付数量)
val payActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
datas(10) != "null"
}
)
// orderid => 1,2,3
// 【(1,1),(2,1),(3,1)】
val payCountRDD = payActionRDD.flatMap(
action => {
val datas = action.split("_")
val cid = datas(10)
val cids = cid.split(",")
cids.map(id => (id, 1))
}
).reduceByKey(_ + _)
// (品类ID, 点击数量) => (品类ID, (点击数量, 0, 0))
// (品类ID, 下单数量) => (品类ID, (0, 下单数量, 0))
// => (品类ID, (点击数量, 下单数量, 0))
// (品类ID, 支付数量) => (品类ID, (0, 0, 支付数量))
// => (品类ID, (点击数量, 下单数量, 支付数量))
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
// 5. 将品类进行排序,并且取前10名
// 点击数量排序,下单数量排序,支付数量排序
// 元组排序:先比较第一个,再比较第二个,再比较第三个,依此类推
// ( 品类ID, ( 点击数量, 下单数量, 支付数量 ) )
//
val rdd1 = clickCountRDD.map {
case (cid, cnt) => {
(cid, (cnt, 0, 0))
}
}
val rdd2 = orderCountRDD.map {
case (cid, cnt) => {
(cid, (0, cnt, 0))
}
}
val rdd3 = payCountRDD.map {
case (cid, cnt) => {
(cid, (0, 0, cnt))
}
}
// 将三个数据源合并在一起,统一进行聚合计算
val soruceRDD: RDD[(String, (Int, Int, Int))] = rdd1.union(rdd2).union(rdd3)
val analysisRDD = soruceRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
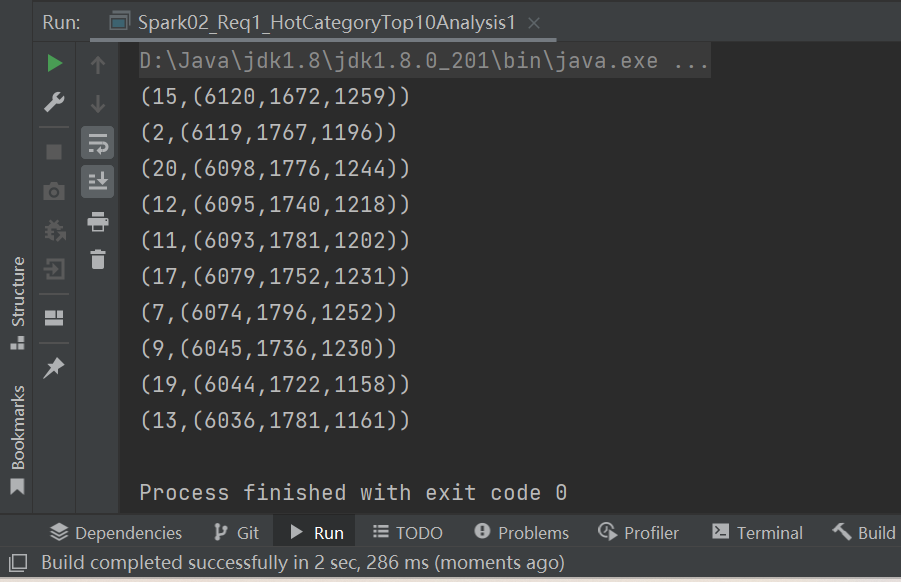
val resultRDD = analysisRDD.sortBy(_._2, false).take(10)
// 6. 将结果采集到控制台打印出来
resultRDD.foreach(println)
sc.stop()
}
}P115【115.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 第三种实现方式】12:56
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_Req1_HotCategoryTop10Analysis2 {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// Q : 存在大量的shuffle操作(reduceByKey)
// reduceByKey 聚合算子,spark会提供优化,缓存
// 1. 读取原始日志数据
val actionRDD = sc.textFile("datas/user_visit_action.txt")
// 2. 将数据转换结构
// 点击的场合 : ( 品类ID,( 1, 0, 0 ) )
// 下单的场合 : ( 品类ID,( 0, 1, 0 ) )
// 支付的场合 : ( 品类ID,( 0, 0, 1 ) )
val flatRDD: RDD[(String, (Int, Int, Int))] = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
)
// 3. 将相同的品类ID的数据进行分组聚合
// ( 品类ID,( 点击数量, 下单数量, 支付数量 ) )
val analysisRDD = flatRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
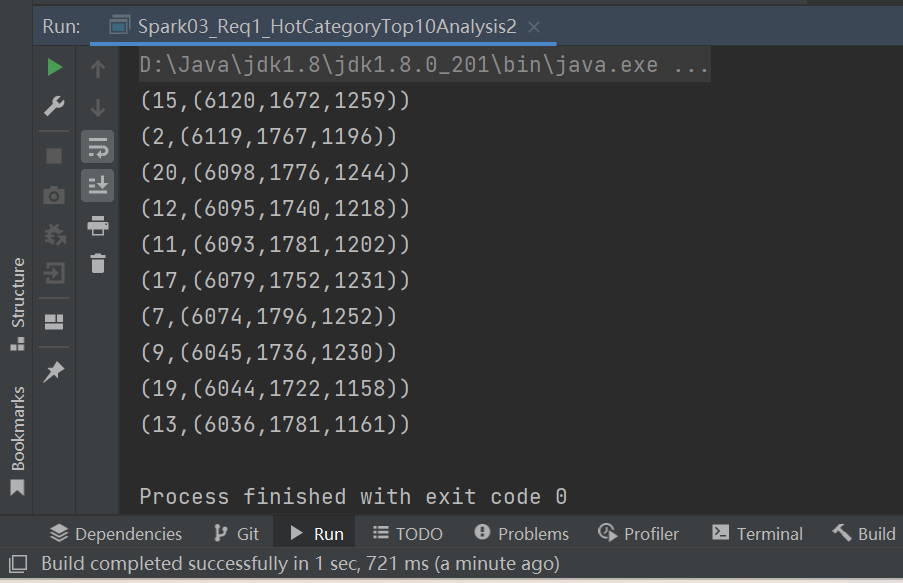
// 4. 将统计结果根据数量进行降序处理,取前10名
val resultRDD = analysisRDD.sortBy(_._2, false).take(10)
// 5. 将结果采集到控制台打印出来
resultRDD.foreach(println)
sc.stop()
}
}P116【116.尚硅谷_SparkCore - 案例实操 - 需求一 - 功能实现 - 第四种实现方式】18:29
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.util.AccumulatorV2
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable
object Spark04_Req1_HotCategoryTop10Analysis3 {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
// 1. 读取原始日志数据
val actionRDD = sc.textFile("datas/user_visit_action.txt")
val acc = new HotCategoryAccumulator
sc.register(acc, "hotCategory")
// 2. 将数据转换结构
actionRDD.foreach(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
acc.add((datas(6), "click"))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.foreach(
id => {
acc.add((id, "order"))
}
)
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.foreach(
id => {
acc.add((id, "pay"))
}
)
}
}
)
val accVal: mutable.Map[String, HotCategory] = acc.value
val categories: mutable.Iterable[HotCategory] = accVal.map(_._2)
val sort = categories.toList.sortWith(
(left, right) => {
if (left.clickCnt > right.clickCnt) {
true
} else if (left.clickCnt == right.clickCnt) {
if (left.orderCnt > right.orderCnt) {
true
} else if (left.orderCnt == right.orderCnt) {
left.payCnt > right.payCnt
} else {
false
}
} else {
false
}
}
)
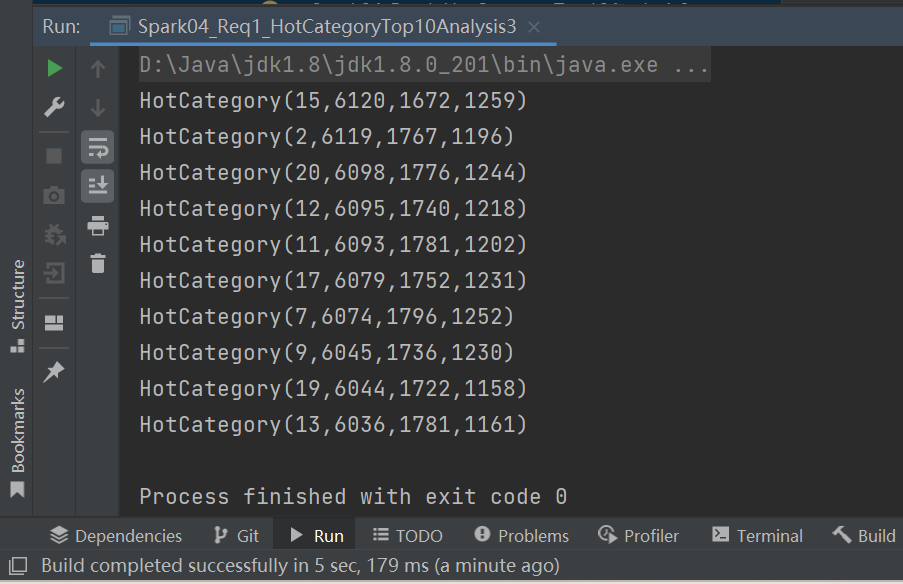
// 5. 将结果采集到控制台打印出来
sort.take(10).foreach(println)
sc.stop()
}
case class HotCategory(cid: String, var clickCnt: Int, var orderCnt: Int, var payCnt: Int)
/**
* 自定义累加器
* 1. 继承AccumulatorV2,定义泛型
* IN : ( 品类ID, 行为类型 )
* OUT : mutable.Map[String, HotCategory]
* 2. 重写方法(6)
*/
class HotCategoryAccumulator extends AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] {
private val hcMap = mutable.Map[String, HotCategory]()
override def isZero: Boolean = {
hcMap.isEmpty
}
override def copy(): AccumulatorV2[(String, String), mutable.Map[String, HotCategory]] = {
new HotCategoryAccumulator()
}
override def reset(): Unit = {
hcMap.clear()
}
override def add(v: (String, String)): Unit = {
val cid = v._1
val actionType = v._2
val category: HotCategory = hcMap.getOrElse(cid, HotCategory(cid, 0, 0, 0))
if (actionType == "click") {
category.clickCnt += 1
} else if (actionType == "order") {
category.orderCnt += 1
} else if (actionType == "pay") {
category.payCnt += 1
}
hcMap.update(cid, category)
}
override def merge(other: AccumulatorV2[(String, String), mutable.Map[String, HotCategory]]): Unit = {
val map1 = this.hcMap
val map2 = other.value
map2.foreach {
case (cid, hc) => {
val category: HotCategory = map1.getOrElse(cid, HotCategory(cid, 0, 0, 0))
category.clickCnt += hc.clickCnt
category.orderCnt += hc.orderCnt
category.payCnt += hc.payCnt
map1.update(cid, category)
}
}
}
override def value: mutable.Map[String, HotCategory] = hcMap
}
}P117【117.尚硅谷_SparkCore - 案例实操 - 需求二 - 功能实现】14:48
6.2 需求 2:Top10 热门品类中每个品类的 Top10 活跃 Session 统计

package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark05_Req2_HotCategoryTop10SessionAnalysis {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
val actionRDD = sc.textFile("datas/user_visit_action.txt")
actionRDD.cache()
val top10Ids: Array[String] = top10Category(actionRDD)
// 1. 过滤原始数据,保留点击和前10品类ID
val filterActionRDD = actionRDD.filter(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
top10Ids.contains(datas(6))
} else {
false
}
}
)
// 2. 根据品类ID和sessionid进行点击量的统计
val reduceRDD: RDD[((String, String), Int)] = filterActionRDD.map(
action => {
val datas = action.split("_")
((datas(6), datas(2)), 1)
}
).reduceByKey(_ + _)
// 3. 将统计的结果进行结构的转换
// (( 品类ID,sessionId ),sum) => ( 品类ID,(sessionId, sum) )
val mapRDD = reduceRDD.map {
case ((cid, sid), sum) => {
(cid, (sid, sum))
}
}
// 4. 相同的品类进行分组
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupByKey()
// 5. 将分组后的数据进行点击量的排序,取前10名
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(10)
}
)
resultRDD.collect().foreach(println)
sc.stop()
}
def top10Category(actionRDD: RDD[String]) = {
val flatRDD: RDD[(String, (Int, Int, Int))] = actionRDD.flatMap(
action => {
val datas = action.split("_")
if (datas(6) != "-1") {
// 点击的场合
List((datas(6), (1, 0, 0)))
} else if (datas(8) != "null") {
// 下单的场合
val ids = datas(8).split(",")
ids.map(id => (id, (0, 1, 0)))
} else if (datas(10) != "null") {
// 支付的场合
val ids = datas(10).split(",")
ids.map(id => (id, (0, 0, 1)))
} else {
Nil
}
}
)
val analysisRDD = flatRDD.reduceByKey(
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2, t1._3 + t2._3)
}
)
analysisRDD.sortBy(_._2, false).take(10).map(_._1)
}
}P118【118.尚硅谷_SparkCore - 案例实操 - 需求三 - 需求介绍】03:41
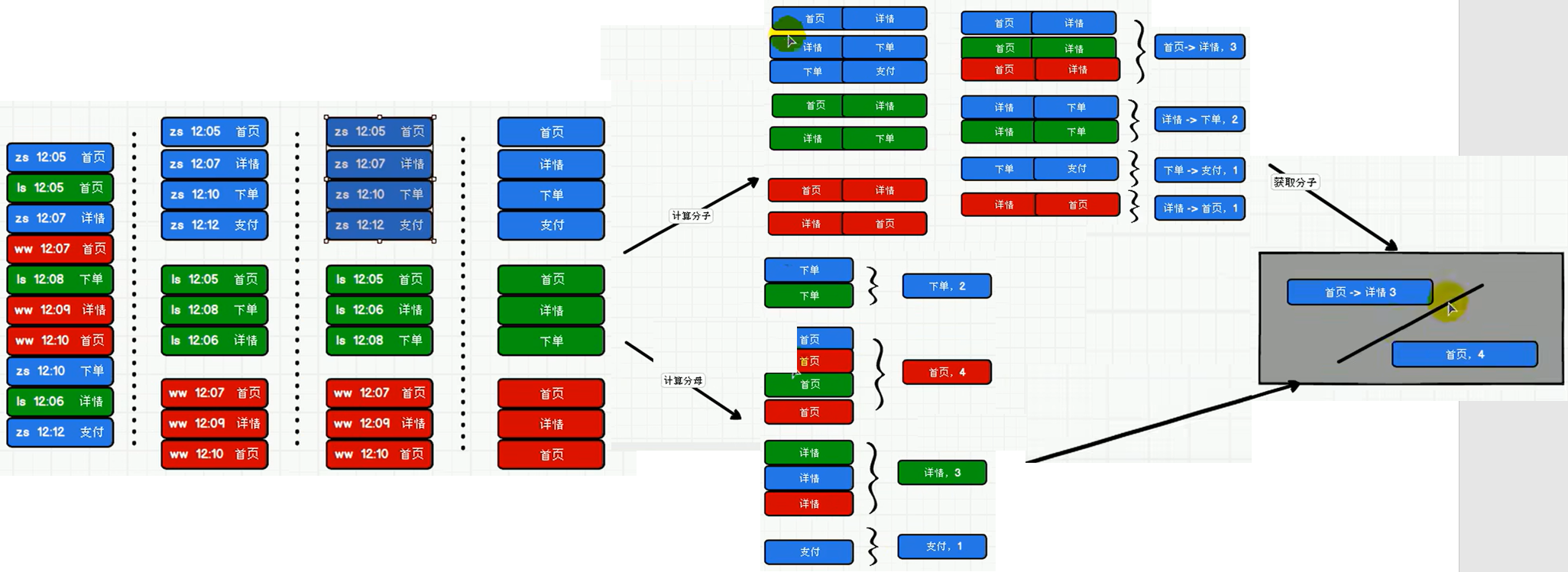
6.3 需求 3:页面单跳转换率统计
6.3.1 需求说明

P119【119.尚硅谷_SparkCore - 案例实操 - 需求三 - 需求分析 - 图解】19:05
6.3.2 需求分析
6.3.3 功能实现
P120【120.尚硅谷_SparkCore - 案例实操 - 需求三 - 代码实现 - 分母的计算】05:59
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark06_Req3_PageflowAnalysis {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
val actionRDD = sc.textFile("datas/user_visit_action.txt")
val actionDataRDD = actionRDD.map(
action => {
val datas = action.split("_")
UserVisitAction(
datas(0),
datas(1).toLong,
datas(2),
datas(3).toLong,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong
)
}
)
actionDataRDD.cache()
// TODO 对指定的页面连续跳转进行统计
// 1-2,2-3,3-4,4-5,5-6,6-7
val ids = List[Long](1, 2, 3, 4, 5, 6, 7)
val okflowIds: List[(Long, Long)] = ids.zip(ids.tail)
// TODO 计算分母
val pageidToCountMap: Map[Long, Long] = actionDataRDD.filter(
action => {
ids.init.contains(action.page_id)
}
).map(
action => {
(action.page_id, 1L)
}
).reduceByKey(_ + _).collect().toMap
// TODO 计算分子
// TODO 计算单跳转换率
sc.stop()
}
//用户访问动作表
case class UserVisitAction(
date: String, //用户点击行为的日期
user_id: Long, //用户的ID
session_id: String, //Session的ID
page_id: Long, //某个页面的ID
action_time: String, //动作的时间点
search_keyword: String, //用户搜索的关键词
click_category_id: Long, //某一个商品品类的ID
click_product_id: Long, //某一个商品的ID
order_category_ids: String, //一次订单中所有品类的ID集合
order_product_ids: String, //一次订单中所有商品的ID集合
pay_category_ids: String, //一次支付中所有品类的ID集合
pay_product_ids: String, //一次支付中所有商品的ID集合
city_id: Long
) //城市 id
}P121【121.尚硅谷_SparkCore - 案例实操 - 需求三 - 代码实现 - 分子的计算并求转换率】15:27
页面单跳转换率统计
P122【122.尚硅谷_SparkCore - 案例实操 - 需求三 - 代码实现 - 优化需求】08:30
页面单跳转换率统计优化
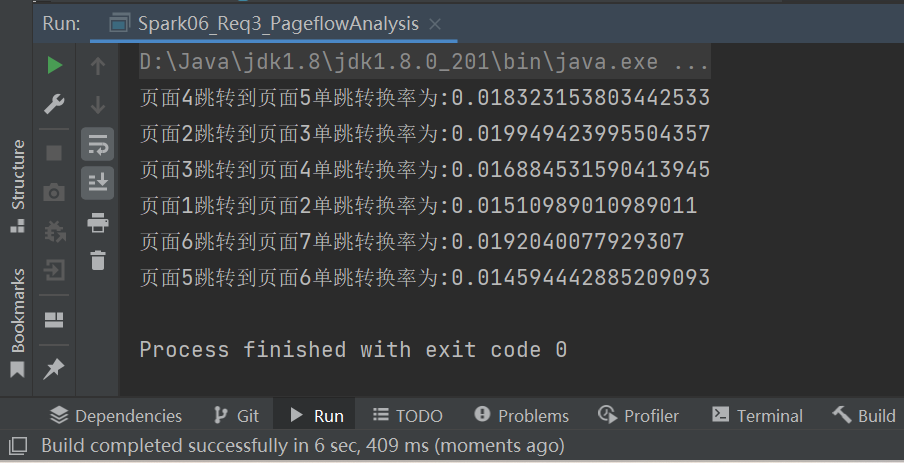
package com.atguigu.bigdata.spark.core.req
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark06_Req3_PageflowAnalysis {
def main(args: Array[String]): Unit = {
// TODO : Top10热门品类
val sparConf = new SparkConf().setMaster("local[*]").setAppName("HotCategoryTop10Analysis")
val sc = new SparkContext(sparConf)
val actionRDD = sc.textFile("datas/user_visit_action.txt")
val actionDataRDD = actionRDD.map(
action => {
val datas = action.split("_")
UserVisitAction(
datas(0),
datas(1).toLong,
datas(2),
datas(3).toLong,
datas(4),
datas(5),
datas(6).toLong,
datas(7).toLong,
datas(8),
datas(9),
datas(10),
datas(11),
datas(12).toLong
)
}
)
actionDataRDD.cache()
// TODO 对指定的页面连续跳转进行统计
// 1-2,2-3,3-4,4-5,5-6,6-7
val ids = List[Long](1, 2, 3, 4, 5, 6, 7)
val okflowIds: List[(Long, Long)] = ids.zip(ids.tail)
// TODO 计算分母
val pageidToCountMap: Map[Long, Long] = actionDataRDD.filter(
action => {
ids.init.contains(action.page_id)
}
).map(
action => {
(action.page_id, 1L)
}
).reduceByKey(_ + _).collect().toMap
// TODO 计算分子
// 根据session进行分组
val sessionRDD: RDD[(String, Iterable[UserVisitAction])] = actionDataRDD.groupBy(_.session_id)
// 分组后,根据访问时间进行排序(升序)
val mvRDD: RDD[(String, List[((Long, Long), Int)])] = sessionRDD.mapValues(
iter => {
val sortList: List[UserVisitAction] = iter.toList.sortBy(_.action_time)
// 【1,2,3,4】
// 【1,2】,【2,3】,【3,4】
// 【1-2,2-3,3-4】
// Sliding : 滑窗
// 【1,2,3,4】
// 【2,3,4】
// zip : 拉链
val flowIds: List[Long] = sortList.map(_.page_id)
val pageflowIds: List[(Long, Long)] = flowIds.zip(flowIds.tail)
// 将不合法的页面跳转进行过滤
pageflowIds.filter(
t => {
okflowIds.contains(t)
}
).map(
t => {
(t, 1)
}
)
}
)
// ((1,2),1)
val flatRDD: RDD[((Long, Long), Int)] = mvRDD.map(_._2).flatMap(list => list)
// ((1,2),1) => ((1,2),sum)
val dataRDD = flatRDD.reduceByKey(_ + _)
// TODO 计算单跳转换率
// 分子除以分母
dataRDD.foreach {
case ((pageid1, pageid2), sum) => {
val lon: Long = pageidToCountMap.getOrElse(pageid1, 0L)
println(s"页面${pageid1}跳转到页面${pageid2}单跳转换率为:" + (sum.toDouble / lon))
}
}
sc.stop()
}
//用户访问动作表
case class UserVisitAction(
date: String, //用户点击行为的日期
user_id: Long, //用户的ID
session_id: String, //Session的ID
page_id: Long, //某个页面的ID
action_time: String, //动作的时间点
search_keyword: String, //用户搜索的关键词
click_category_id: Long, //某一个商品品类的ID
click_product_id: Long, //某一个商品的ID
order_category_ids: String, //一次订单中所有品类的ID集合
order_product_ids: String, //一次订单中所有商品的ID集合
pay_category_ids: String, //一次支付中所有品类的ID集合
pay_product_ids: String, //一次支付中所有商品的ID集合
city_id: Long
) //城市 id
}