前言
本文已收录在MySQL性能优化+原理+实战专栏,点击此处浏览更多优质内容。
 前面的文章我们介绍了InnoDB存储引擎的一些内存、内存+磁盘的结构以及工作原理,今天我们就来看一下关于MySQL Server层的一些内存结构。
前面的文章我们介绍了InnoDB存储引擎的一些内存、内存+磁盘的结构以及工作原理,今天我们就来看一下关于MySQL Server层的一些内存结构。
目录
- 一、Binlog Cache
- 1.1 Binlog Cache工作原理
- 1.2 Binlog的写入机制
- 1.3 Binlog相关参数
- 1.3.1 binlog_cache_size
- 1.3.2 sync_binlog
- 1.4 Binlog刷盘策略应用场景
- 二、Query Cache
- 三、Key Buffer
- 3.1 Key Buffer是什么
- 3.2 Key Buffer相关参数
- 四、Read Buffer & Read Rnd Buffer
- 4.1 Read Buffer是什么
- 4.2 Read Buffer相关参数
- 4.3 Read Rnd Buffer是什么
- 4.4 Read Rnd Buffer相关参数
- 五、Sort Buffer
- 5.1 Sort Buffer是什么
- 5.2 Sort Buffer相关参数
- 5.3 常见的排序算法
- 5.3.1 全字段排序
- 5.3.2 归并排序
- 5.3.3 rowid排序
- 六、Join Buffer
- 6.1 Join Buffer是什么
- 6.2 Join Buffer相关参数
一、Binlog Cache
Binlog(二进制日志)包含描述数据库更改的“事件”,例如表创建操作或表数据的更改。它还包含可能进行更改的语句的事件,除非使用基于Row的日志记录。二进制日志还包含有关每个语句花费多长时间更新数据的信息。二进制日志有两个重要目的:
- 复制,复制源服务器上的二进制日志提供了要发送到副本的数据更改记录。源将其二进制日志中包含的事件发送到其副本,副本执行这些事件以进行与源相同的数据更改。
- 某些数据恢复操作需要使用二进制日志。恢复备份后,将重新执行备份后记录的二进制日志中的事件。这些事件使数据库从备份点开始更新
和InnoDB存储引擎的特有日志Redo Log一样,Binlog是MySQL Server层特有的日志,存放着对数据库操作的变更记录。二者的不同点在于,Redo Log是物理日志,而Binlog是逻辑日志,因为是逻辑日志(记录着除SELECT、SHOW之外的SQL语句)的原因,所以单独的Binlog是不具备Crash-safe能力的,整个MySQL体系结构中,Redo Log和Binlog二者相结合才能保证关系型数据库ACID的特性
1.1 Binlog Cache工作原理
1.2 Binlog的写入机制
和Redo Log一样,Binlog自身也有其写入策略。其实,Binlog的写入逻辑比较简单:事务执行过程中,先把日志写到Binlog Cache,事务提交的时候,再把Binlog Cache写到binlog文件中。
一个事务的binlog是不能被拆开的,因此不论这个事务多大,也要确保一次性写入(因为Binlog写入的单位是Events,一个Events必须包含一个完整的事务,所以这也是大事务造成主从延迟的主要原因)。这就涉及到了Binlog Cache的保存问题。
系统给Binlog Cache分配了一片内存,每个线程一个,参数binlog_cache_size用于控制单个线程内Binlog Cache所占内存的大小。如果超过了这个参数规定的大小,就要暂存到磁盘。
事务提交的时候,执行器把Binlog Cache里的完整事务写入到binlog中,并清空Binlog Cache
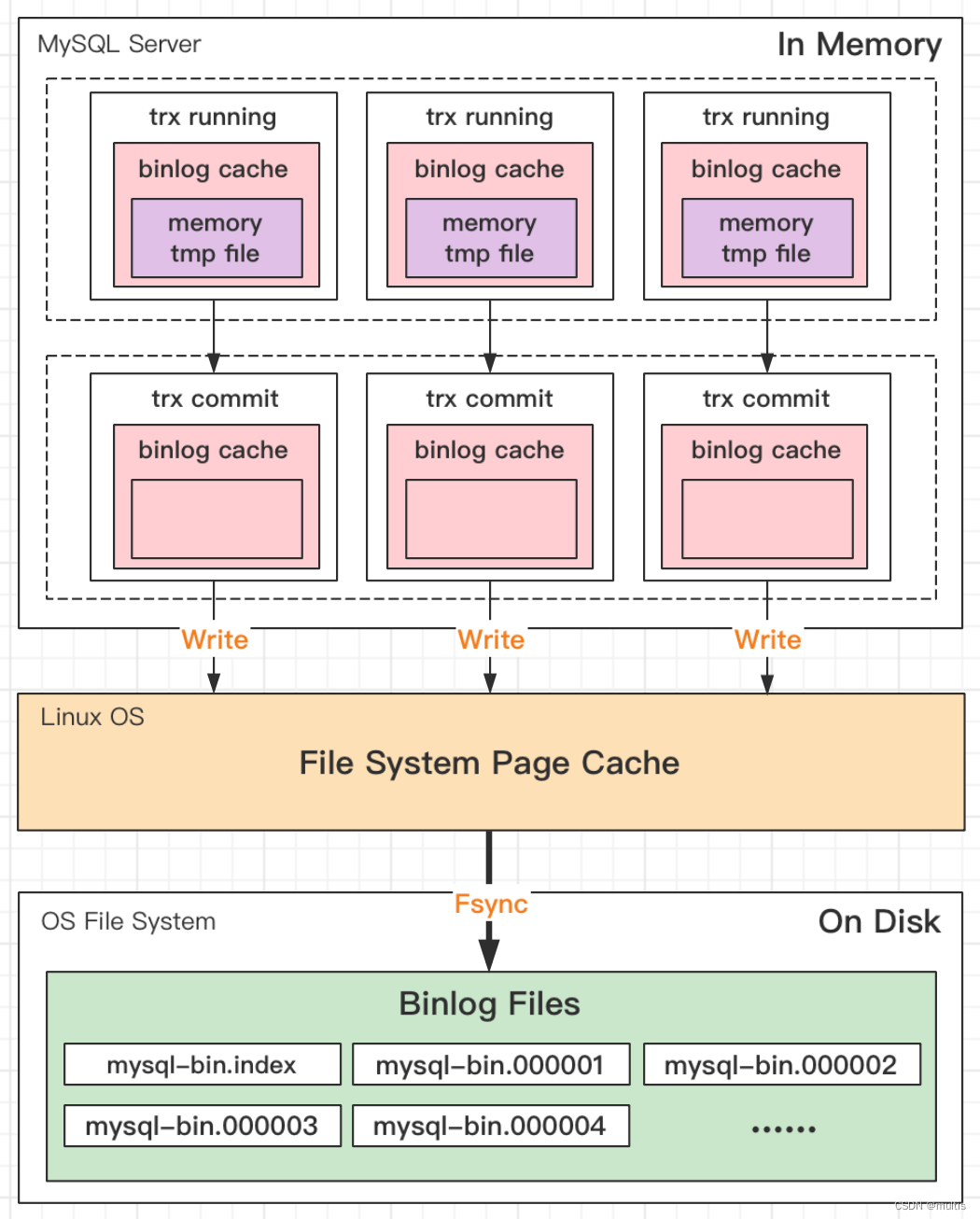
可以看到,每个线程有自己Binlog Cache,但是共用同一份binlog文件。
- 图中的Write,指的就是指把日志写入到文件系统的FS Page Cache,并没有把数据持久化到磁盘,所以速度比较快。
- 图中的Fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为Fsync才占磁盘的IOPS
1.3 Binlog相关参数
1.3.1 binlog_cache_size
设置Binlog Cache的大小,默认大小为32MB,单位:B(字节)
mysql> show variables like 'binlog_cache_size%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| binlog_cache_size | 32768 |
+-------------------+-------+
1 row in set (0.00 sec)
1.3.2 sync_binlog
控制binlog文件的刷盘策略,可选的参数为0、1或N。如下图所示
mysql> show variables like '%sync_binlog%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| sync_binlog | 1 |
+---------------+-------+
1 row in set (0.01 sec)
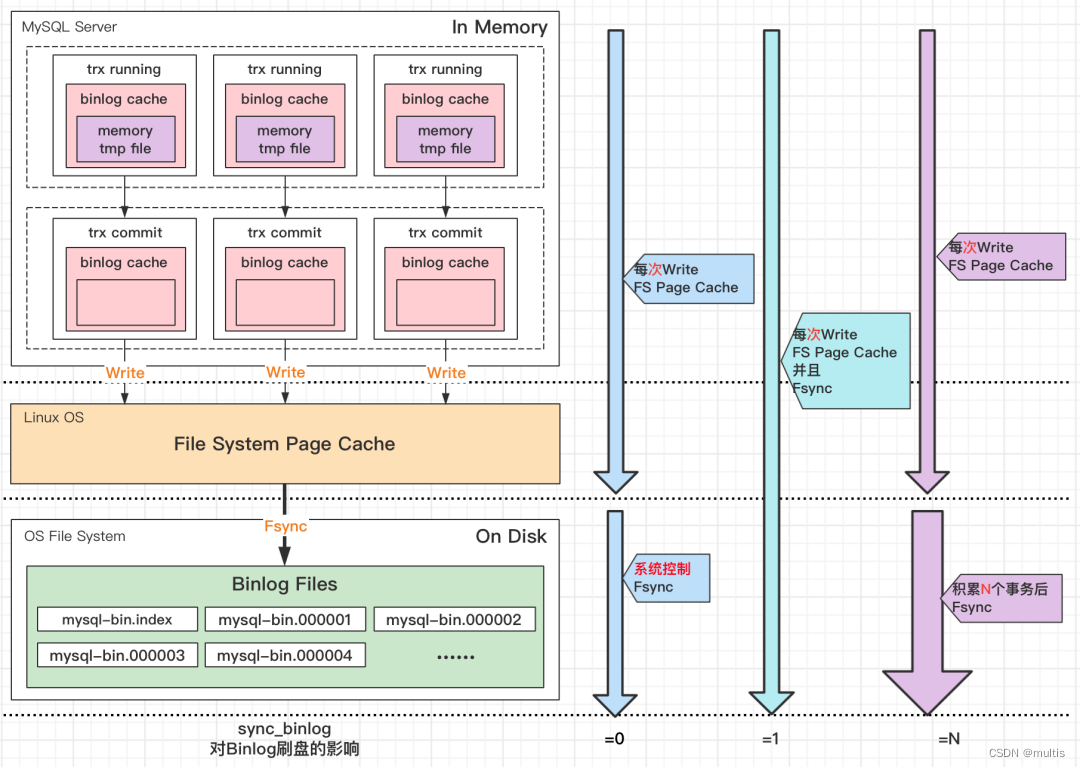
策略一: 最佳性能(sync_binlog=0)
处理过程: 表示每次提交事务都只Write,不主动Fsync;
策略二: 强一致(sync_binlog=1)
处理过程: 表示每次提交事务都会执行Write和Fsync;
策略三: 人为折衷控制(sync_binlog=N)
处理过程: 当sync_binlog=N(N>1)的时候,表示每次提交事务都Write,但累积N个事务后才Fsync
1.4 Binlog刷盘策略应用场景
因此,在出现IO瓶颈的场景里,将sync_binlog设置成一个比较大的值,可以提升性能。在实际的业务场景中,考虑到丢失日志量的可控性,一般不建议将这个参数设成0,比较常见的是将其设置为100~1000中的某个数值。
但是,将sync_binlog设置为N,对应的风险是:如果主机发生异常重启,会丢失最近N个事务的binlog日志。
经常听到:MySQL的双“1”设置。其实双“1”就代表:innodb_flush_log_at_trx_commit=1 && sync_binlog=1,因为在这种组合配置下,MySQL的数据是最有保障的。
二、Query Cache
还记得丁奇大佬的这张图吗?本小节要介绍的Query Cache就在这张图中,已经用红框标注出来了,中文名:查询缓存。
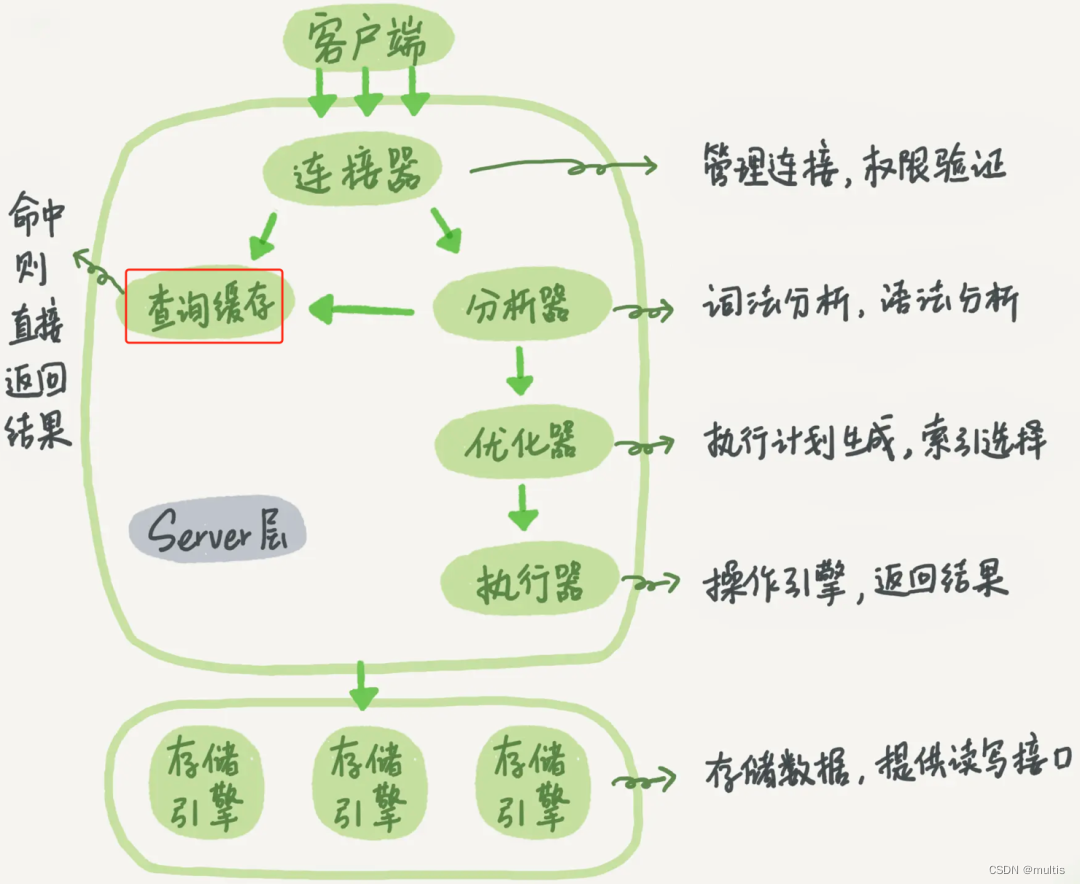
MySQL拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以key-value对的形式,被直接缓存在内存中。key是查询的语句,value是查询的结果。如果你的查询能够直接在这个缓存中找到key,那么这个value就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
已经被MySQL官方放弃的功能就不介绍了,感兴趣的可以查阅相关资料。
三、Key Buffer
3.1 Key Buffer是什么
Key Buffer是缓冲MyISAM表的索引块的,注意:只缓存MyISAM存储引擎的表索引块,即该参数只对MyISAM表生效。同时,这个内存区域是所有线程共享的。
3.2 Key Buffer相关参数
mysql> SHOW VARIABLES LIKE '%key_buffer%';
+-----------------+---------+
| Variable_name | Value |
+-----------------+---------+
| key_buffer_size | 8388608 |
+-----------------+---------+
1 row in set (0.01 sec)
是用于定义MyISAM表索引块的缓冲区的大小,单位:B字节。一般情况下,此参数设置为8~32MB即可,因为MySQL的默认存储引擎已经从原来的MyISAM转变为InnoDB了,所以,该参数也无需过多关注
四、Read Buffer & Read Rnd Buffer
4.1 Read Buffer是什么
每个对MyISAM表执行顺序扫描的线程为其扫描的每个表分配的缓冲区。也用于所有存储引擎的上下文:
- 用于在临时文件(不是临时表)中缓存索引,当为ORDER BY;
- 用于批量插入分区;
- 用于缓存嵌套查询的结果;
- 也以另一种特定于存储引擎的方式使用:确定MEMORY表的内存块大小。
4.2 Read Buffer相关参数
mysql> SHOW VARIABLES LIKE '%read_buffer%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| read_buffer_size | 131072 |
+------------------+--------+
1 row in set (0.00 sec)
如果您执行多次顺序扫描,您可能希望增加此值,默认为131072。此变量的值应为4KB的倍数。如果将其设置为不是4KB倍数的值,则其值将向下舍入到最接近的4KB倍数。
4.3 Read Rnd Buffer是什么
用于从MyISAM表中读取、任何存储引擎用于Multi-Range Read(MRR)优化的缓冲区。在MyISAM键排序操作后按排序顺序从表中读取行时,通过此缓冲区读取行以避免磁盘寻道。这是为每个客户端分配的缓冲区,不是全局变量。
4.4 Read Rnd Buffer相关参数
mysql> SHOW VARIABLES LIKE '%read_rnd_buffer%';
+----------------------+--------+
| Variable_name | Value |
+----------------------+--------+
| read_rnd_buffer_size | 262144 |
+----------------------+--------+
1 row in set (0.01 sec)
定义Read Rnd Buffer缓冲区大小的参数,将变量设置为较大的值可以大大提高ORDER BY 性能
五、Sort Buffer
5.1 Sort Buffer是什么
MySQL会给每个线程分配一块内存用于排序,即SQL语句中的ORDER BY,这块内存区域就称之为Sort Buffer。
5.2 Sort Buffer相关参数
mysql> SHOW VARIABLES LIKE 'sort_buffer_size';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| sort_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)
定义Sort Buffer缓冲区大小的参数。
5.3 常见的排序算法
5.3.1 全字段排序
SELECT列表中的全部字段都参与排序的排序方式叫做全字段排序。
5.3.2 归并排序
如果要排序的数据量小于sort_buffer_size,排序就在内存中完成。但如果排序数据量太大,内存放不下,则不得不利用磁盘临时文件辅助排序。
OPTIMIZER_TRACE的结果可以从number_of_tmp_files中看到是否使用了临时文件。(内存放不下时,就需要使用外部排序,外部排序一般使用归并排序算法。数字表示,MySQL将需要排序的数据分成12份,每一份单独排序后存在这些临时文件中。然后把这12个有序文件再合并成一个有序的大文件。0表示排序可以直接在内存中完成,sort_buffer_size 越小,需要分成的份数越多,number_of_tmp_files的值就越大)
5.3.3 rowid排序
MySQL认为排序的单行长度太大,采用另外一种算法法,max_length_for_sort_data,是MySQL中专门控制用于排序的行数据的长度的一个参数。它的意思是,如果单行的长度超过这个值,MySQL就认为单行太大,要换一个算法。(排序的列只包含order by后面的字段和id)
六、Join Buffer
6.1 Join Buffer是什么
之前表联结的章节提到了笛卡尔积(两张表做联结查询的时候,第一个表有M行数据,第二个表有N行数据,第二张表的每行数据要与第一张表的每行数据一一匹配,得到的结果集行数为M×N)的概念。MySQL针对笛卡尔积的联结查询,做了优化,这里我们称M表为驱动表,N表为被驱动表(驱动表和被驱动表不在本章讨论范围,后续的文章会单独讲解,大家先知道这个概念就好),MySQL提出了一个Join Buffer的概念,Join Buffer就是执行连接连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个Join Buffer中,然后开始扫描被驱动表,每一条被驱动表的记录一次性和Join Buffer中的多条驱动表记录做匹配,因为匹配的过程都是在内存中完成的,所以这样可以显著减少被驱动表的I/O代价。
6.2 Join Buffer相关参数
mysql> SHOW VARIABLES LIKE '%join_buffer%';
+------------------+--------+
| Variable_name | Value |
+------------------+--------+
| join_buffer_size | 262144 |
+------------------+--------+
1 row in set (0.00 sec)
用于普通索引扫描、范围索引扫描和不使用索引并因此执行全表扫描的连接的缓冲区的最小大小(单位:B字节),默认大小为262144字节(也就是256KB),最小可以设置为128字节。