目录
一、标注
1.1 标注软件下载labelimg
下载地址:mirrors / tzutalin / labelimg · GitCode
1.2 json转txt
1.3 xml转txt
二、修改配置文件
2.1 建立文件目录
2.2 修改wzry_parameter.yaml文件
三、开始训练
3.1
2.结果
四、识别检测detect.py
1.调参找到def parse_opt():这行,以下是我们要调参的位置
2.结果结果在runs/detect/exp中原文链接:https://blog.csdn.net/m0_53392188/article/details/119334634
从第三章开始就错了,我的train.py运行有问题,可能原文是v5环境,我直接再7里面弄的
一、标注
有两个软件可以用:labelme,需要json转txt(我用的这个)还有一个是labelimg是将xml转为txt.
1.1 标注软件下载labelimg
下载地址:mirrors / tzutalin / labelimg · GitCode
下载后解压压缩包,注意路径一定不要有中文名称。
在labeling目录下,打开cmd,然后输入:pyrcc5 -o resources.py resources.qrc
可能出现错误:
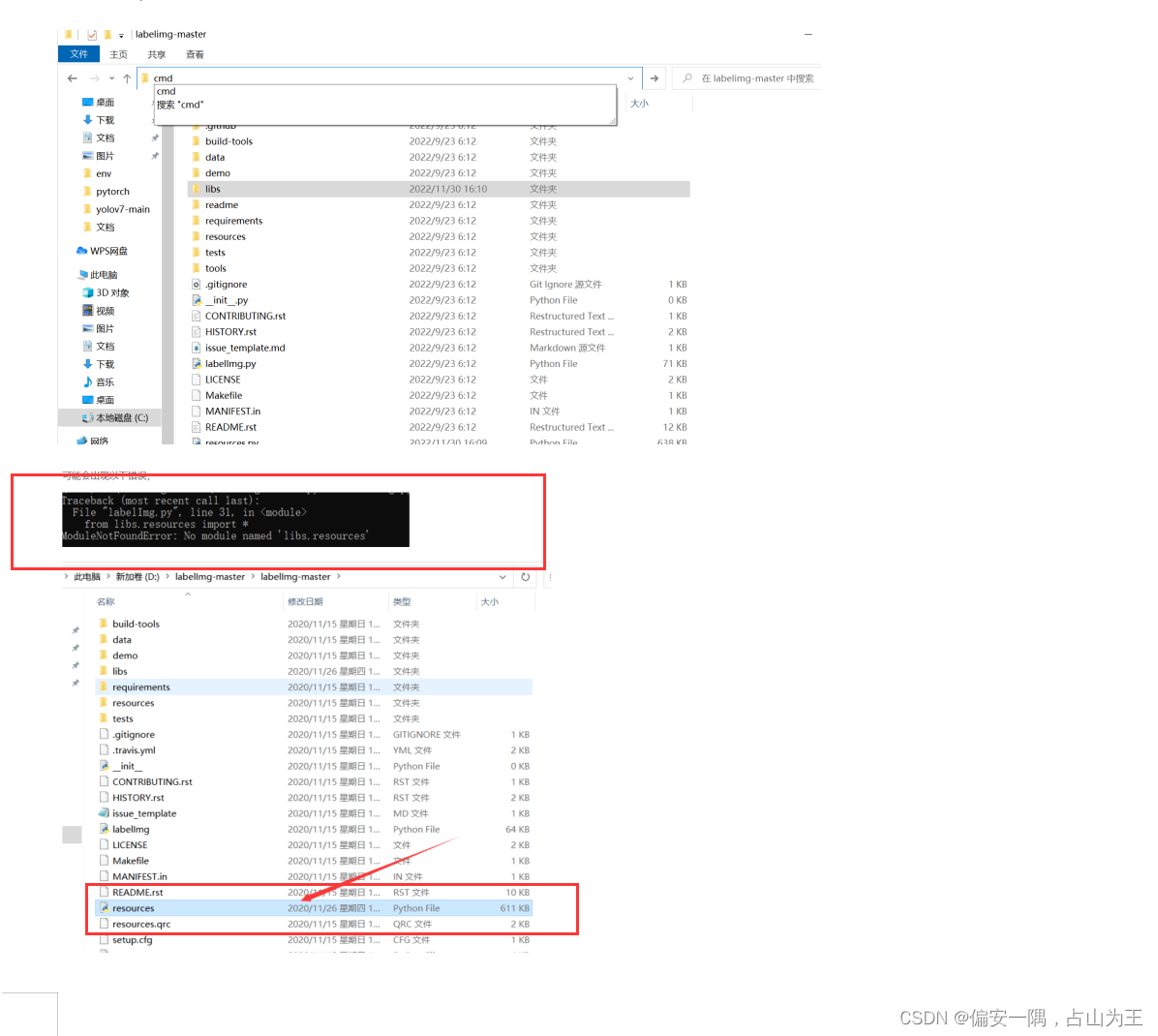
将resources.py文件放入libs文件夹,再输入python labelImg.py进入以下界面:
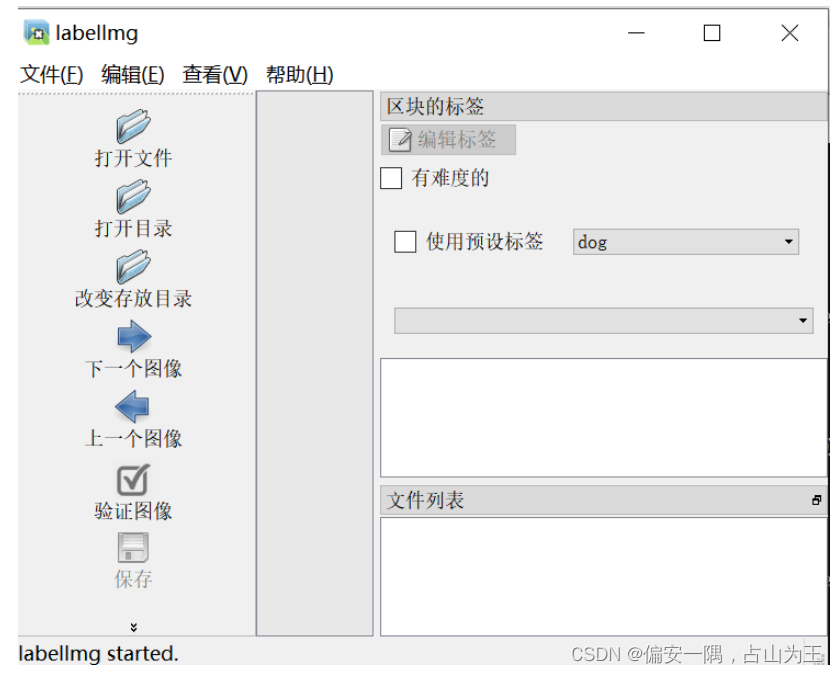
到此,安装成功!!!
参考文章:labelImg安装所遇到的那些坑_与君初相识的博客-CSDN博客
方法二:
GitHub - wkentaro/labelme: Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation).
下载完成之后,在Anaconda Prompt里pip install pyqt5和pip install labelme
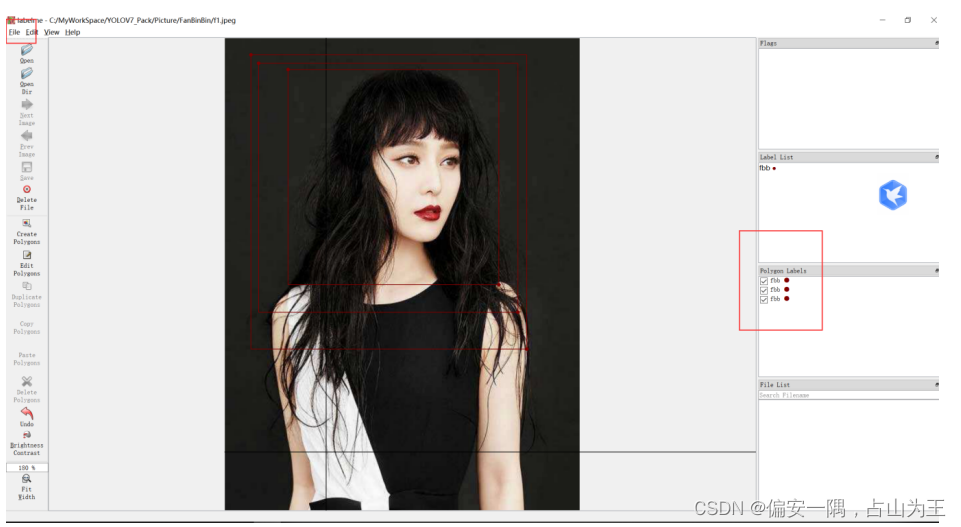
右击,点击rectangle,即画矩形框,框选你要识别训练的东西,框选之后输入标签的名字,注意,可以框选多个作为标签。框选完一张图后保存,然后接着下一张图。保存的文件格式是.json
1.2 json转txt
由于yolov5只认txt而不认json,因此还要有一个转换的过程
在yolov5-master中创建一个.py文件,代码如下:
name2id = {'fbb': 0} 是标签的名字,我只搞了一个标签;注意,json文件夹下只能由json,不要和你的图片放在一个文件夹下了。
import json
import os
name2id = {'fbb': 0} # 标签名称
def convert(img_size, box):
dw = 1. / (img_size[0])
dh = 1. / (img_size[1])
x = (box[0] + box[2]) / 2.0 - 1
y = (box[1] + box[3]) / 2.0 - 1
w = box[2] - box[0]
h = box[3] - box[1]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def decode_json(json_floder_path, json_name):
txt_name = 'C:\\MyWorkSpace\\PythonWorkSpace\\yolov7-main\\yolov7-main\\MX\\datasets\\labels\\train\\' + json_name[0:-5] + '.txt'
# 存放txt的绝对路径
txt_file = open(txt_name, 'w')
json_path = os.path.join(json_floder_path, json_name)
data=json.load(open(json_path,'r',encoding='gb2312',errors='ignore'))
img_w = data['imageWidth']
img_h = data['imageHeight']
for i in data['shapes']:
label_name = i['label']
if (i['shape_type'] == 'rectangle'):
x1 = int(i['points'][0][0])
y1 = int(i['points'][0][1])
x2 = int(i['points'][1][0])
y2 = int(i['points'][1][1])
bb = (x1, y1, x2, y2)
bbox = convert((img_w, img_h), bb)
txt_file.write(str(name2id[label_name]) + " " + " ".join([str(a) for a in bbox]) + '\n')
if __name__ == "__main__":
json_path = r"C:\MyWorkSpace\YOLOV7_Pack\Picture\FanBinBin"
# 存放json的文件夹的绝对路径
json_names = os.listdir(json_path)
for json_name in json_names:
decode_json(json_path, json_name)1.3 xml转txt
这是别人的方法,我没试
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
def convert(size, box):
# size=(width, height) b=(xmin, xmax, ymin, ymax)
# x_center = (xmax+xmin)/2 y_center = (ymax+ymin)/2
# x = x_center / width y = y_center / height
# w = (xmax-xmin) / width h = (ymax-ymin) / height
x_center = (box[0] + box[1]) / 2.0
y_center = (box[2] + box[3]) / 2.0
x = x_center / size[0]
y = y_center / size[1]
w = (box[1] - box[0]) / size[0]
h = (box[3] - box[2]) / size[1]
# print(x, y, w, h)
return (x, y, w, h)
def convert_annotation(xml_files_path, save_txt_files_path, classes):
xml_files = os.listdir(xml_files_path)
# print(xml_files)
for xml_name in xml_files:
# print(xml_name)
xml_file = os.path.join(xml_files_path, xml_name)
out_txt_path = os.path.join(save_txt_files_path, xml_name.split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
tree = ET.parse(xml_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
# continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# b=(xmin, xmax, ymin, ymax)
# print(w, h, b)
bb = convert((w, h), b)
out_txt_f.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
# 把forklift_pallet的voc的xml标签文件转化为yolo的txt标签文件
# 1、需要转化的类别
classes = ['People', 'Car', 'Bus', 'Motorcycle', 'Lamp', 'Truck']
# 2、voc格式的xml标签文件路径
xml_files1 = r'D:\Technology\Python_File\yolov5\M3FD\Annotation_xml'
# xml_files1 = r'C:/Users/GuoQiang/Desktop/数据集/标签1'
# 3、转化为yolo格式的txt标签文件存储路径
save_txt_files1 = r'D:\Technology\Python_File\yolov5\M3FD\Annotation_txt'
convert_annotation(xml_files1, save_txt_files1, classes)二、修改配置文件
2.1 建立文件目录
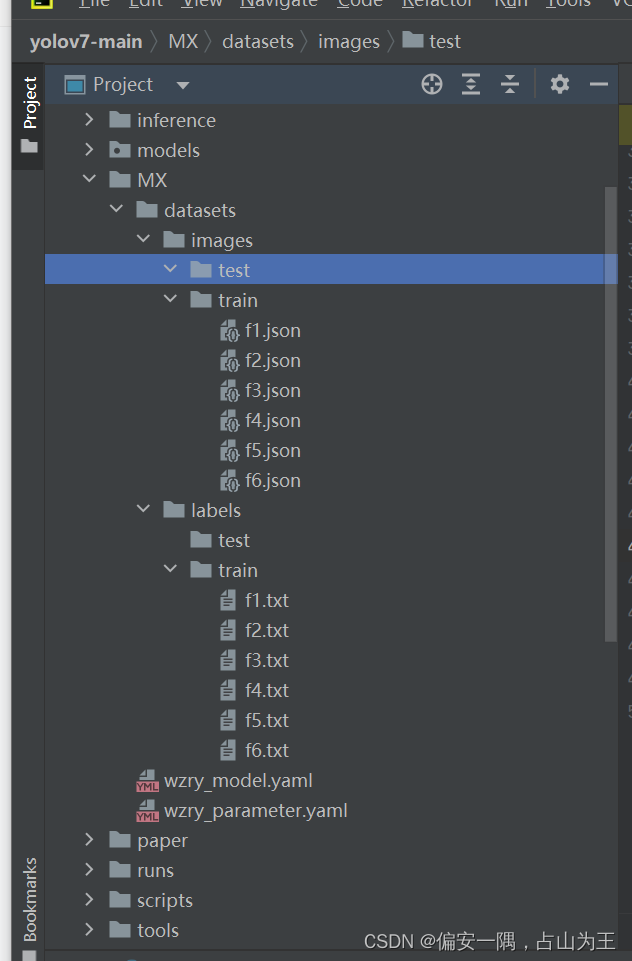
image:图片 label:标签
train:用于训练的 test:用于测试的
2.2 修改wzry_parameter.yaml文件
在yolov5/data/coco128.yaml中先复制一份,粘贴到wzry中,改名为wzry_parameter.yaml
wzry_parameter.yaml文件需要修改的参数是nc与names。nc是标签名个数,names就是标签的名字
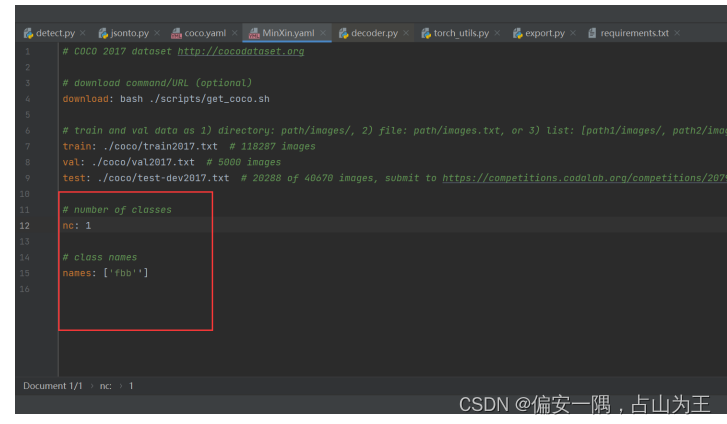
说明:
path是绝对路径
train是在path绝对路径条件下的训练集路径,即:wzry/datasets/images/train
val同上,但是是验证集,这里我为了方便,让训练集和验证集是一个,也没啥大问题。
test可不填
关于训练集、验证集、测试集三者关系,如下:
如何正确使用机器学习中的训练集、验证集和测试集?_nkwshuyi的博客-CSDN博客
yolov5有4种配置,不同配置的特性如下,我这里选择yolov5x,效果较好,但是训练时间长,也比较吃显存
在yolov5/models先复制一份yolov5x.yaml至wzry,更名为wzry_model.yaml(意为模型),只将如下的nc修改为训练集种类即可。
三、开始训练
3.1
在train.py,找到def parse_opt(known=False)这行,这下面是我们要修改的程序部分

我标注“修改处”的,是一定要修改的;其他的注释是一些较为重要的参数,对于小白而言不改也可。具体修改的地方为defalut后
479行:是我们训练的初始权重的位置,是以.pt结尾的文件,第一次训练用别人已经训练出来的权重。可能有朋友会想,自己训练的数据集和别人训练的数据集不一样,怎么能通用呢?实际上他们是通用的,后面训练会调整过来。而如果不填已有权重,那么训练效果可能会不好;
480行:训练模型文件,在本项目中对应wzry_model.yaml;
481行:数据集参数文件,在本项目中对于wzry_parameter.yaml;
482行:超参数设置,是人为设定的参数。包括学习率啥的等等,可不改;
483行:训练轮数,决定了训练时间与训练效果。如果选择训练模型是yolov5x.yaml,那么大约200轮数值就稳定下来了(收敛);
484行:批量处理文件数,这个要设置地小一些,否则会out of memory。这个决定了我们训练的速度;
485行:图片大小,虽然我们训练集的图片是已经固定下来了,但是传入神经网络时可以resize大小,太大了训练时间会很长,且有可能报错,这个根据自己情况调小一些;
487行:断续训练,如果说在训练过程中意外地中断,那么下一次可以在这里填True,会接着上一次runs/exp继续训练
496行:GPU加速,填0是电脑默认的CUDA,前提是电脑已经安装了CUDA才能GPU加速训练,安装过程可查博客
501行:多线程设置,越大读取数据越快,但是太大了也会报错,因此也要根据自己状况填小。
3.2
2.结果
运行效果正确的应该是这个样子:
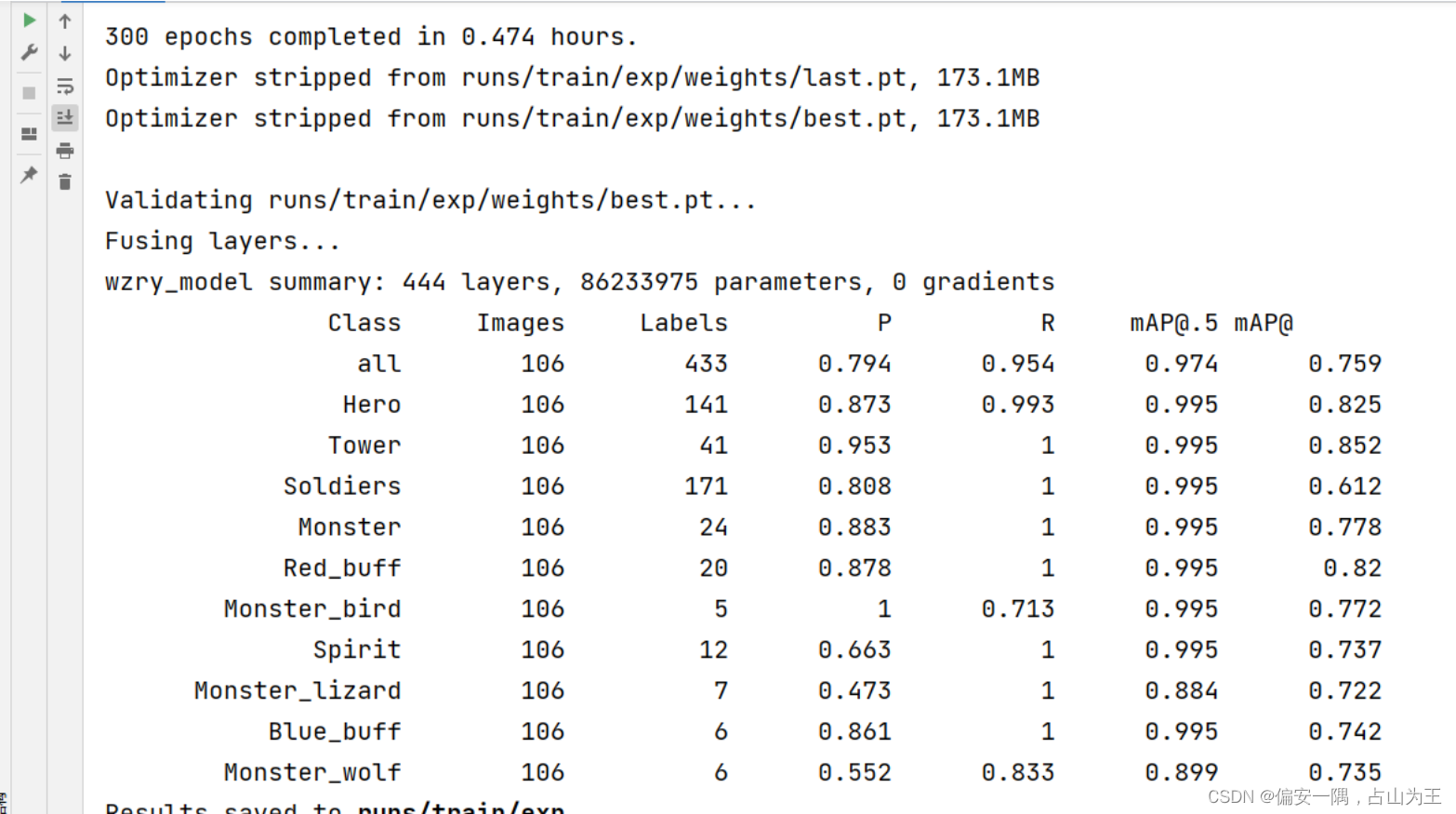
结果保存在runs/train/exp中,多次训练就会有exp1、exp2、等等
best.pt和last.pt是我们训练出来的权重文件,比较重要,用于detect.py。last是最后一次的训练结果,best是效果最好的训练结果(只是看起来,但是泛化性不一定强)。

四、识别检测detect.py
1.调参
找到def parse_opt():这行,以下是我们要调参的位置
217行:填我们训练好的权重文件路径
218行:我们要检测的文件,可以是图片、视频、摄像头。填0时为打开电脑默认摄像头
219行:数据集参数文件,同上
220行:图片大小,同上
221行:置信度,当检测出来的置信度大于该数值时才能显示出被检测到,就是显示出来的框框
222行:非极大抑制,具体不赘述了,自行查阅,可不改
224行:GPU加速,同上





![[附源码]Python计算机毕业设计SSM联动共享汽车管理系统(程序+LW)](https://img-blog.csdnimg.cn/48dc57608fb348bcb0d4845e40cc3cca.png)







![[附源码]SSM计算机毕业设计学生宿舍管理系统JAVA](https://img-blog.csdnimg.cn/79447298c7c64ddb9fba24f8bc28b67a.png)