目录
前言
几个高频面试题目
基于对比学习(ContrastiveLearning)的文本表示模型【为什么】能学到文本【相似】度?
为什么对比学习能学到很好的语义相似度?
那么如何评价这个表示空间的质量呢?
知识储备
监督学习和非监督学习
算法原理
什么是对比学习
对比学习过程步骤
算法思想
前置任务
颜色变换
编辑
几何变换
基于上下文的
基于帧的
未来预测
视图预测 View Prediction (Cross modal-based)
确定对的前置任务
对比学习一般泛式
对比损失
原始对比损失
三元组损失(triplet loss)
InfoNCE损失
对比方法如何工作的?
Deep InfoMax
Contrastive Predictive Coding
对比学习在NLP文本表示的一些方法
一. 基于BERT的句子表示
二. 基于对比学习的BERT表示学习
对比学习论文
NCL
ICL
RGCL
MCCLK
MIDGN
PCL
BalFeat
MiCE
i-Mix
Contrastive Learning with Hard Negative Samples
LooC
CALM
Support-set bottlenecks for video-text representation learning
SpCL
SimCLR V2
Hard Negative Mixing for Contrastive Learning
Supervised Contrastive Learning
Contrastive Learning with Adversarial Examples
LoCo
What Makes for Good Views for Contrastive Learning?
GraphCL
ContraGAN
算法拓展
多层次对比学习的跨模态检索
方法
编码器
动量跨模态对比(MCC)
层次跨模态对比匹配(HCM)
实验
应用场景
半监督学习
前言
自监督学习(Self-supervised learning)最近获得了很多关注,因为其可以避免对数据集进行大量的标签标注。它可以把自己定义的伪标签当作训练的信号,然后把学习到的表示(representation)用作下游任务里。最近,对比学习被当作自监督学习中一个非常重要的一部分,被广泛运用在计算机视觉、自然语言处理等领域。它的目标是:将一个样本的不同的、增强过的新样本们在嵌入空间中尽可能地近,然后让不同的样本之间尽可能地远。
几个高频面试题目
基于对比学习(ContrastiveLearning)的文本表示模型【为什么】能学到文本【相似】度?
有监督训练的典型问题,就是标注数据是有限的。目前NLP领域的经验,自监督预训练使用的数据量越大,模型越复杂,那么模型能够吸收的知识越多,对下游任务效果来说越好。这可能是自从Bert出现以来,一再被反复证明。所以对比学习的出现,是图像领域为了解决“在没有更大标注数据集的情况下,如何采用自监督预训练模式,来从中吸取图像本身的先验知识分布,得到一个预训练的模型”对比学习是自监督学习的一种,也就是说,不依赖标注数据,要从无标注图像中自己学习知识。目前,对比学习貌似处于“无明确定义、有指导原则”的状态,它的指导原则是:通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。
为什么对比学习能学到很好的语义相似度?
因为对比学习的目标就是要从数据中学习到一个优质的语义表示空间众所周知,直接用BERT句向量做无监督语义相似度计算效果会很差。
BERT模型可以使用无监督的方法做文本相似度任务吗?
前不久的BERT-flow通过normalizing flow将向量分布映射到规整的高斯分布上,更近一点的BERT-whitening对向量分布做了PCA降维消除冗余信息,但是标准化流的表达能力太差,而白化操作又没法解决非线性的问题,有更好的方法提升表示空间的质量吗?
正好,对比学习的目标之一就是学习到分布均匀的向量表示,因此我们可以借助对比学习间接达到规整表示空间的效果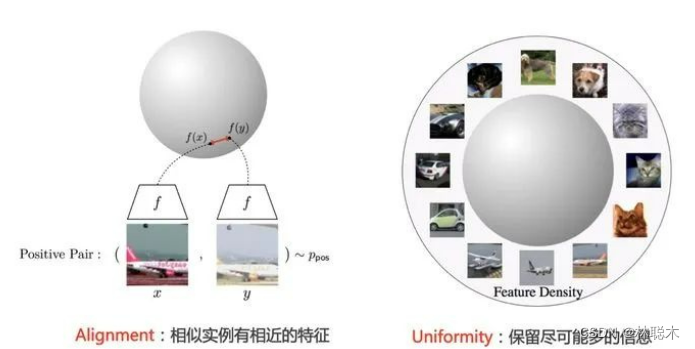
那么如何评价这个表示空间的质量呢?
Wang and Isola (2020)提出了衡量对比学习质量的两个指标:
- Alignment计算xi和xi+的平均距离;
- 而Uniformity计算向量整体分布的均匀程度。
我们希望这两个指标都尽可能低,也就是一方面希望正样本要挨得足够近,另一方面语义向量要尽可能地均匀分布在超球面上,因为均匀分布信息熵最高,分布越均匀则保留的信息越多。
于是通过对比学习获得的语义向量,自然而然效果就更好了。“拉近正样本,推开负样本”实际上就是在优化这两个指标。下面来看一下语义相似度SOTA模型SimCSE,由陈丹琦发布,它将对比学习的思想引入到sentence embedding中,大幅刷新了有监督和无监督语义匹配SOTA,更让人惊叹的是,无监督SimCSE的表现在STS基准任务上甚至超越了包括SBERT在内的所有有监督模型。
对比学习的宗旨就是拉近相似数据,推开不相似数据,有效地学习数据表征。也就是当文本表征模型采用对比学习方法进行模型训练时,天然地就将相似文本的各维特征变得更相似,而各维特征的相似程度的综合也就是文本之间的相似程度。但值得注意的是,什么样的数据是相似数据,什么样的数据是不相似数据,则是对比学习的关键,也就是在模型训练前,如何构造正负样本。假如:“我爱北京天安门”和“我不爱北京天安门”是相似样本,那么学习过程中就学习不到语义的相关信息,学习的就是字面上的特征;“我爱北京天安门”和“我不爱北京天安门”是不相似样本,那么学习过程中就可以学习到否定方面的语义信息;所以,这也是目前很多对比学习论文的重点在如何构造正负样本上,难负例可以使文本表征模型学习到更多的语义信息。
知识储备
监督学习和非监督学习
深度学习从大量数据中自动学习的能力使其在各种领域广泛应用,例如CV和NLP。但是深度学习也有其瓶颈,就是它需要大量的人工标注的标签。例如在计算机视觉中,监督模型需要在图片的表示和图片的标签之间建立关联。
传统的监督学习模型极度依赖于大量的有标签数据。所以研究者们想研究出一种办法,如何利用大量的无标签数据。所以自监督学习的到了广泛关注,因为它可以从数据自己本身中寻找标签来监督模型的训练。
监督学习不仅需要大量的标注数据,它还面临着下面的各种问题:
- 模型的泛化性能
- 伪相关
- 对抗攻击
最近,自监督学习结合了生成模型和对比模型的特点:从大量无标签数据中学习表示。
一种流行的方式是设计各种前置任务(pretext task)来让模型从伪标签中来学习特征。例如图像修复、图像着色、拼图、超分辨率、视频帧预测、视听对应等。这些前置任务被证明可以学习到很好的表示。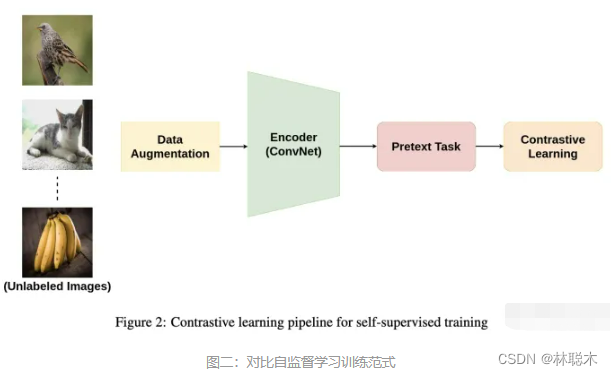
一般来说,机器学习任务分为监督学习和非监督学习
- 监督学习会有标注数据,训练的目标是为了让训练数据预测的标签或者得分接近真实的标签或者得分
- 无监督学习没有真实的标注数据,通常会设定一些度量指标或者启发函数,模型的训练的目标就是让这些指标达到一个极值收敛
对比函数主要的目标是构造一个对比损失或者对比函数,使得正样例的score远远大于负样例的score![]()
因为这个函数的目标是为了建模构建两个类别的差异性,所以又称对比损失(Contrastive loss)
所以说具体到不同的问题有很多不同的构建对比loss的方式,例如用内积来计算样本的相似度,对比loss可以写成,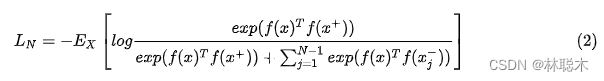
这个loss鼓励正例的相似度足够大(分子),鼓励负例的相似度足够小(分母)。类似于LDA(Linear Discriminant Analysis),对比学习是一种度量学习,度量学习的目标就是让同类别的距离尽可能近,不同类别的距离尽可能远。LDA、SVM是监督学习,现在更多的研究重点是通过自监督方式构建同源数据作为正样例来做大规模的预训练,有足够多的准确的同类标注数据做监督对比学习也是可以的.
监督对比学习是一种机器学习技术,通过同时教模型哪些数据点相似或不同,来学习数据集的一般特征。监督对比学习是一种监督学习方法,对样本质量要求较高。相比于一般监督学习,监督对比学习通常能获得更好的效果
在大多数实际场景中,我们没有为每个样本添加标签。以医学成像为例,获取样本的难度很大,为了创建标签,专业人士不得不花费无数的时间来手动分类、分割图像。虽然生成带有干净标签的数据集是昂贵的,但是我们时时刻刻都在生成大量的未标记的数据。自监督学习是让我们能够从这些未标记的数据中学习知识的一种方法。要利用这些大量的未标记数据,一种方法是适当地设定学习目标,以便从数据本身获得监督。
在NLP中,word2vec, Mask Language Model就是典型的自监督学习。在CV中也有很多自监督学习的例子,比如:将一张图片切成小的blocks,预测blocks之间的关系、将小的blocks拼图成原图等。

自监督学习
自监督对比学习和监督对比学习整体上是相似的,不同之处在于:自监督对比学习通过数据增强来构建有标签的样本,而监督对比学习的有人工标注的对比样本。
因此,自监督对比学习的核心和难点是构建优质的对比样本。在CV中,一般通过剪切、旋转、高斯噪声、遮掩、染色等操作生成正样本。在NLP中一般通过回译、对字符的增、删、改来添加噪声,从而生成正样本。由于文本的离散性质,一般较难生成好的标签不变的增强样本。
如何使用对比样本pair进行正确分类呢?这就要用到自监督对比损失函数

Alignment(对称性) : 一个正对的两个样本应该映射成近邻特征向量,并且特征对于噪声因子是不变的。
Uniformity(均匀性) : 特征向量应大致均匀地分布在单位超球面 上,并尽可能保留多的数据信息。
算法原理
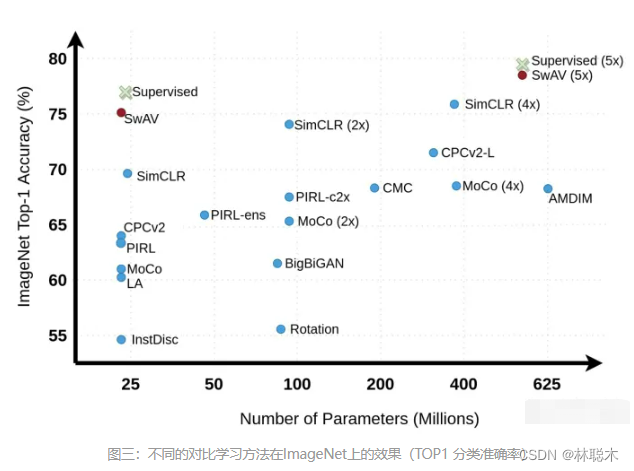
对比学习属于无监督或者自监督学习,但是目前多个模型的效果已超过了有监督模型。
目前研究大多数都是:充分使用越来越大量的无标注数据,使用越来越复杂的模型,采用自监督预训练模式,来从中吸取图像本身的先验知识分布,在下游任务中通过Fine-tuning,来把预训练过程习得的知识,迁移给并提升下游任务的效果。
对比学习不依赖标注数据,要从无标注图像中自己学习知识。图像领域里的自监督可以分为两种类型:生成式自监督学习,判别式自监督学习。VAE和GAN是生成式自监督学习的两类典型方法,即它要求模型重建图像或者图像的一部分,这类型的任务难度相对比较高,要求像素级的重构,中间的图像编码必须包含很多细节信息。对比学习则是典型的判别式自监督学习,相对生成式自监督学习,对比学习的任务难度要低一些。
目前,对比学习貌似处于“无明确定义、有指导原则”的状态,它的指导原则是:通过自动构造相似实例和不相似实例,要求习得一个表示学习模型,通过这个模型,使得相似的实例在投影空间中比较接近,而不相似的实例在投影空间中距离比较远。而如何构造相似实例,以及不相似实例,如何构造能够遵循上述指导原则的表示学习模型结构,以及如何防止模型坍塌(Model Collapse),这几个点是其中的关键。
目前出现的对比学习方法已有很多,如果从防止模型坍塌的不同方法角度,我们可大致把现有方法划分为:基于负例的对比学习方法、基于对比聚类的方法、基于不对称网络结构的方法,以及基于冗余消除损失函数的方法。
什么是对比学习
在2014年生成对抗网络(GAN)推出之后,生成模型得到了很多关注。它之后变成了许多强大的模型的基础,例如 CycleGAN, StyleGAN, PixelRNN, Text2Image, DiscoGAN 等。这些模型启发研究者去研究自监督学习(不需要标签)。他们发现基于GAN的模型很复杂,不容易训练,主要是由于下面原因:
- 难以收敛
- 判别器太强大而导致生成器难以生成好的结果
- 判别器和生成器需要同步
与生成模型不同,对比学习是一种判别模型,它让相似样本变近,不同样本变远.
为了达到这一点,一种衡量远近的指标被用来衡量嵌入之间的远近。对比损失用来训练对比学习模型。一般来说,以图片为例,对比学习把一张图片的增强版本当作一个正例,其余图片当作反例,然后训练一个模型来区分正反例。区分依赖于某种前置任务。
这样做,学习到的表示就可以用到下游任务之中。
对比学习是一种自监督学习方法,用于在没有标签的情况下,通过让模型学习哪些数据点相似或不同来学习数据集的一般特征。
让我们从一个简单的例子开始。想象一下,你是一个试图理解世界的新生婴儿。在家里,假设你有两只猫和一只狗。
即使没有人告诉你它们是“猫”和“狗”,你仍可能会意识到,与狗相比,这两只猫看起来很相似。
仅仅通过识别它们之间的异同,我们的大脑就可以了解我们的世界中物体的高阶特征。
例如,我们可能意识地认识到,两只猫有尖尖的耳朵,而狗有下垂的耳朵。或者我们可以对比狗突出的鼻子和猫的扁平脸。
本质上,对比学习允许我们的机器学习模型做同样的事情。它会观察哪些数据点对“相似”和“不同”,以便在执行分类或分割等任务之前了解数据更高阶的特征。
为什么这个功能如此强大?
这是因为我们可以在没有任何注释或标签的情况下,训练模型以学习很多关于我们的数据的知识,因此术语,自监督学习。
在大多数实际场景中,我们没有为每张图像设置标签。以医学成像为例,为了创建标签,专业人士必须花费无数个小时查看图像以手动分类、分割等。
通过对比学习,即使只有一小部分数据集被标记,也可以显著提高模型性能。
对比学习过程步骤
整个过程可以简明地描述为三个基本步骤:
(1)对于数据集中的每个图像,我们可以执行两种增强组合(即裁剪 + 调整大小 + 重新着色、调整大小 + 重新着色、裁剪 + 重新着色等)。我们希望模型知道这两个图像是“相似的”,因为它们本质上是同一图像的不同版本。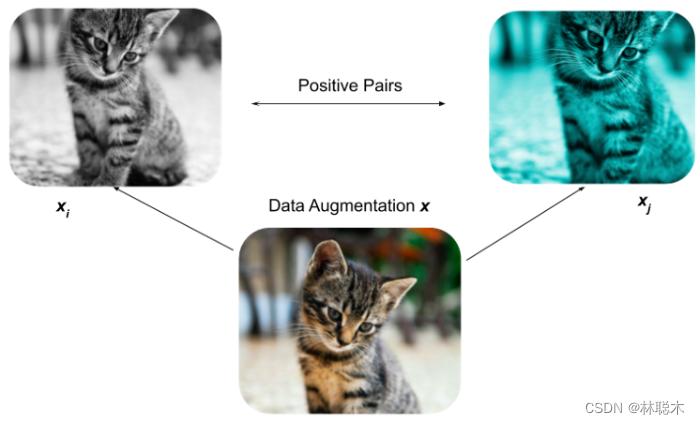
(2)为此,我们可以将这两个图像输入到我们的深度学习模型(Big-CNN,例如 ResNet)中,为每个图像创建向量表示。目标是训练模型输出相似图像的相似表示。
(3)最后,我们尝试通过最小化对比损失函数来最大化两个向量表示的相似性。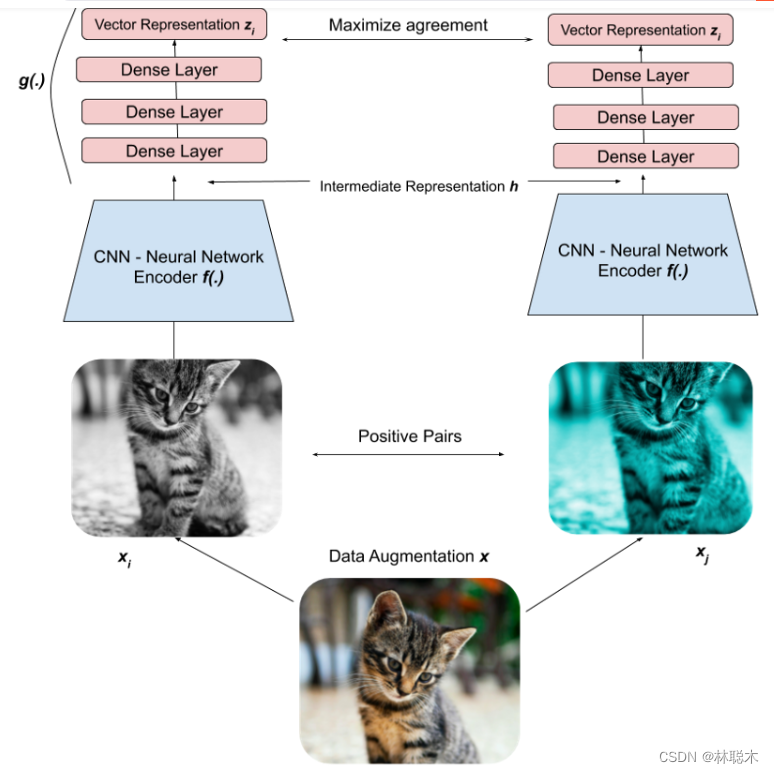
随着时间的推移,模型将了解到猫的两个图像应该具有相似的表示,而猫的表示应该与狗的表示不同。
这意味着模型能够在不知道图像是什么的情况下区分不同类型的图像!
我们可以通过将其分解为三个主要步骤来进一步剖析这种对比学习方法:数据增强、编码和损失最小化。

我们随机执行以下增强的任意组合:裁剪、调整大小、颜色失真、灰度。我们对批次中的每张图像执行两次此操作,以创建包含两个增强图像的一对正对(a positive pair)。
2)编码
然后,我们使用我们的Big-CNN神经网络,我们可以认为它是一个简单的函数,h = f ( x ) 其中“x”是我们的增强图像之一,以此将我们的两个图像编码为矢量表示。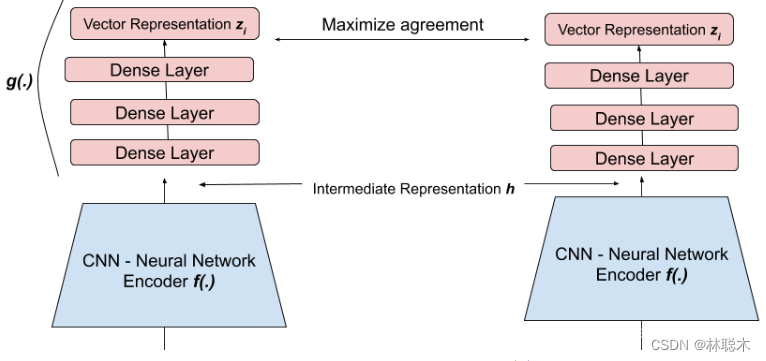
然后,将CNN的输出输入到一组称为projection head的Dense Layers中,z = g ( h ) z=g(h)z=g(h)将数据转换到另一个空间。经验表明,这个额外的步骤可以提高性能。
通过将我们的图像压缩为潜在空间表示,该模型能够学习图像的高阶特征。
事实上,随着我们继续训练模型以最大化相似图像之间的向量相似度,我们可以想象模型正在学习潜在空间中相似数据点的clusters。
例如,猫表示将更接近,但与狗表示更远,因为这是我们训练模型学习的内容。
3)损失最小化
现在我们有两个向量z,我们需要一种方法来量化它们之间的相似性。
由于我们正在比较两个向量,因此自然选择余弦相似度,它基于空间中两个向量之间的角度。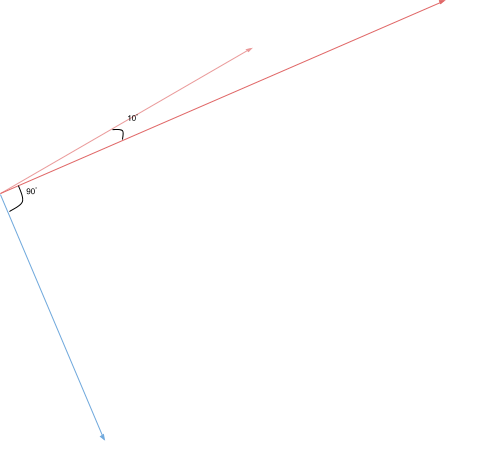
合乎逻辑的是,当向量在空间中靠得越近(它们之间的夹角越小),它们就越相似。因此,如果我们将余弦(两个向量之间的角度) 作为度量,当角度接近 0 时,我们将获得高相似度,否则将获得低相似度,这正是我们想要的。
我们还需要一个可以最小化的损失函数。一种选择是 NT-Xent(标准化温度标度交叉熵损失 Normalized Temperature-Scaled Cross-Entropy Loss)。
我们首先计算两个增强图像相似的概率。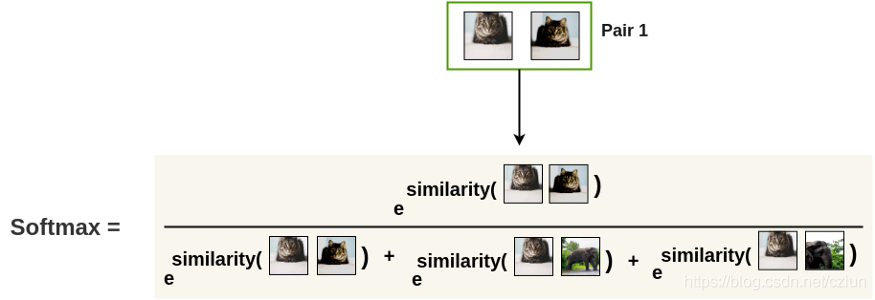
算法思想
前置任务
前置任务是自监督学习中非常重要的一种策略。它可以用伪标签从数据中学习表示。
伪标签是从数据本身中定义而来的。
这些任务可以应用到各种数据之中,例如图片、视频、语言、信号等。
在对比学习的前置任务之中,原始图片被当作一种anchor,其增强的图片被当作正样本(positive sample),然后其余的图片被当作负样本。
大多数的前置任务可以被分为四类:
- 颜色变换
- 几何变换
- 基于上下文的任务
- 基于交叉模式的任务
具体使用哪种任务取决于具体的问题。
颜色变换

颜色变换很好理解,不多说了。在这个前置任务中,图片经过变换,它们还是相似的图片,模型需要学会辨别这些经过颜色变换的图片。
几何变换
几何变换也很好理解,不多说了。
原图被当作全局视图(global view),转换过的图片被当作局部试图(local view):
基于上下文的
拼图
解决拼图问题是无监督学习中一个非常重要的部分。
在对比学习中,原图被当作anchor,打乱后的图片被当作正样本,其余图片被当作负样本。
基于帧的
这个策略一般应用于时许数据,例如传感器的数据或者一系列视频帧。
策略背后的意义是:时间上相近的相似,时间上很远的不相似。
解决这样的前置任务可以让模型学习到一些跟时间有关的表示。
在这里,一个视频中的帧被当作正样本,其余视频被当作负样本。
其余的方法还包括:随机抽样一个长视频中的两个片段,或者对每个视频片段做几何变换。
目标是使用对比损失(contrastive loss)来训练模型,使得来自一个视频的片段在嵌入空间中相近,来自不同视频的片段不相近。
Qian 等人 [20] 提出的一个模型中将两个正样本和其余所有的负样本之间进行对比。
一对正样本是两个增强的来自同一个视频的视频片段。
这样,所有的视频在嵌入空间中都是分割开来的,每个视频占据一个小的嵌入空间。
未来预测
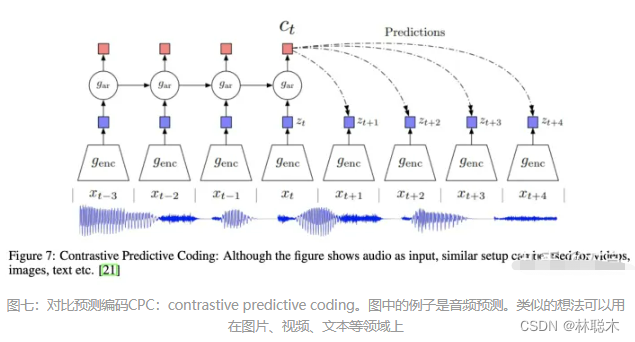
对于时序数据做对比一个最直观的方法是预测将来或者预测缺失的信息。
这个前置任务是基于已有的一系列时间点数据,去预测将来的高阶的信息。
在 [21] [22] 等模型中,高阶数据被压缩在一个低维度的隐藏嵌入空间之中。强大的序列模型被当作encoder来生成一个基于上下文的 ,然后用 来预测未来的信息。其中蕴含的意义是最大化两者之间的互信息(Mutual information maximization)。
视图预测 View Prediction (Cross modal-based)
视图预测任务一般用在数据本身拥有多个视图的情况下。
在 [23] 中,anchor和它的正样本图片来自同时发生的视角下,它们在嵌入空间中应当尽可能地近,与来自时间线中其他位置的负样本图片尽可能地远。
在 [24] 中,一个样本的多视角被当作正样本(intra-sampling),其余的inter-sampling当作负样本。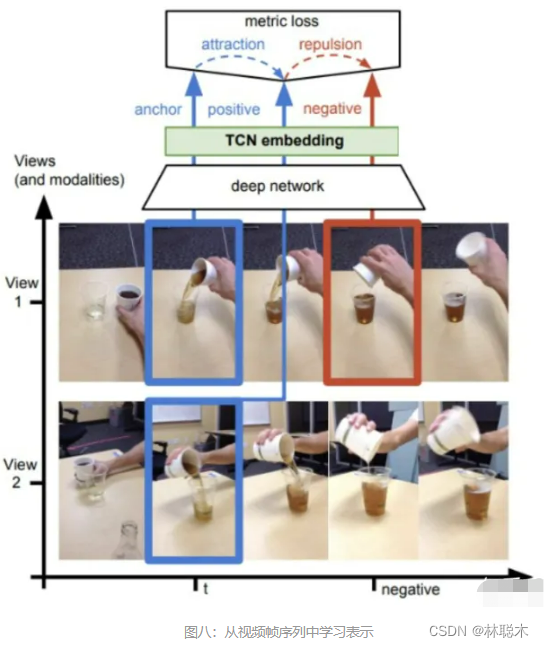
确定对的前置任务
选择什么样的前置任务取决于你所要解决的任务。
尽管已经有很多类型的前置任务在对比学习中提出来了,但是选择哪种前置任务依旧没有一个理论支撑。
选择正确的前置任务对表示学习有非常大的帮助。
前置任务的本质是:模型可以学习到数据本身的一些转换(数据转换之后依然被认作是原数据,转换后到数据和原数据处于同一嵌入空间),同时模型可以判别其他不同的数据样本。
但是前置任务本身是一把双刃剑,某个特定的前置任务可能对某些问题有利,对其他问题有害。
对比学习一般泛式

对比损失
原始对比损失
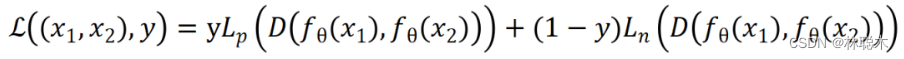
其中,D为距离度量函数,Lp为一递增函数,Ln为一递减函数。当互为正例时,距离越远损失越高;互为负例时,距离越近损失越高。
几种不同的Lp和Ln函数
![]()
三元组损失(triplet loss)
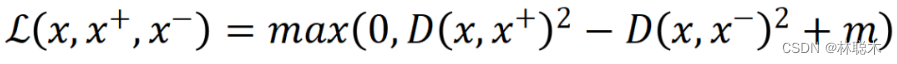 其中D为欧几里得距离,m是用来控制正例负例距离间的偏离量,使模型不需要考虑优化过于简单的负例。
其中D为欧几里得距离,m是用来控制正例负例距离间的偏离量,使模型不需要考虑优化过于简单的负例。
该方法在FaceNet中被提出,主要希望通过对比使得锚点与正例的距离更近,与负例更远。
但在实际操作中,我们可能会得到负样例个数远远多于正样例,由此我们引出了对比学习中主流的InfoNCE损失。
InfoNCE损失
NCE全称是噪声对比估计(Noise Contrastive Estimation),通过引入一个噪声分布,解决多分类问题softmax分母归一化中分母难以求值的问题。具体做法是把多分类问题通过引入一个噪音分布变成一个二元分类问题,将原来构造的多分类分类器(条件概率)转化为一个二元分类器,用于判别给定样例是来源于原始分布还是噪声分布,进而更新原来多元分类器的参数。(?)
如果把噪音分布的样本想成负样例,那这个二元分类问题就可以理解为让模型对比正负样例作出区分进而学习到正样例(原始分布)的分布特征
而InfoNCE, 又称global NCE,继承了NCE的基本思想,从一个新的分布引入负样例,构造了一个新的多元分类问题,并且证明了减小这个损失函数相当于增大互信息(mutual information)的下界。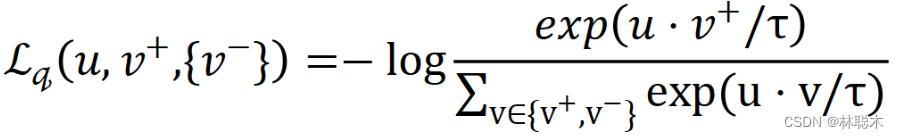
其中u、v+、v-分别为原样例、正样例、负样例归一化后的表示,为温度超参。
温度超参是softmax中常见的超参,t越小,softmax越接近真实的max函数,t越大越接近一个均匀分布。因此,当t很小时,只有难区分的负样例才会对损失函数产生影响,同时,对错分的样例(即与原样例距离比正样例与原样例距离近)有更大的惩罚。实验结果表明,对比学习对t很敏感。
对比方法如何工作的?

通常被称为“锚”数据点。为了优化这一特性,我们可以构造一个 softmax 分类器来正确地分类正样本和负样本。这个分类器鼓励 score 函数给正例样本赋于大值,给负样本赋于小值:

这是 N-way softmax 分类器常见的交叉熵损失,在对比学习文献中通常称为 InfoNCE 损失。在之前的工作中,我们将其称为多类 n-pair loss 和 基于排序的 NCE。
InfoNCE 也与共同的信息有关系。具体地说,最小化 InfoNCE 损失可使 和
之间共同的信息的下界最大化。
让我们更仔细地看看不同的对比方法来理解他们在做什么:
Deep InfoMax

Deep InfoMax中的对比任务
Deep InfoMax 通过利用图像中的本地结构来学习图像的表示。DIM的对比任务是区分全局特征和局部特征是否来自同一幅图像。在这里,全局特征是卷积编码器的最终输出(一个平面向量,Y),局部特征是编码器中间层(一个M x M特征图)的一个输出。每个局部特征图都有一个有限的感受野。所以,直观上,这意味着要做好对比任务全局特征向量必须从所有不同的局部区域中获取信息。
DIM的损失函数看起来与我们上面描述的对比损失函数完全一样。给定一个锚图像 ,

Contrastive Predictive Coding
对比预测编码(CPC (van den Oord et al ., 2018) 是一种对比方法,可以应用于任何形式的可以表示为有序序列的数据:文字,语音,视频,甚至图片(一个图像可以看作是一系列像素或patch)。
CPC通过编码信息来学习表示,这些信息在相隔多个时间步的数据点之间共享,放弃了局部信息。这些特征通常被称为“慢特征”:不会随着时间变化得太快的特征。具体的例子包括音频信号中说话者的身份,视频中进行的活动,图像中的物体等。
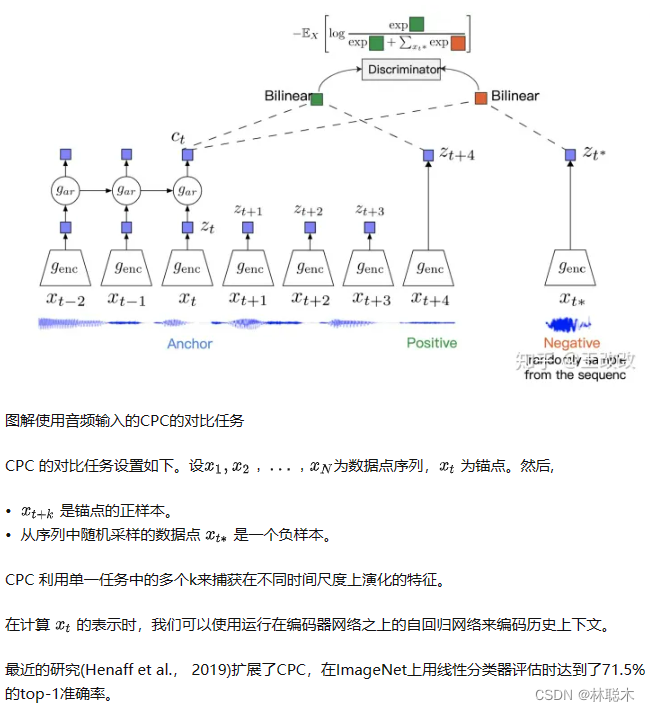
对比学习在NLP文本表示的一些方法
一. 基于BERT的句子表示
BERT
虽然BERT在很多下游任务表现非常出色,但是BERT缺不适合做文本表示,一个很重要的原因是在预训练的时候并没有把文本表示作为目标来训练,而只是训练下游的NSP或者MLM任务,而这些任务对文本表示并没有正向作用,所以实际测试情况,BERT的表示直接拿来做文本表示,在计算文本相似度(STS)时,效果远不如Glove的向量平均,所以很多对BERT做了改进,使其适合作文本表征
各向异性是指单词嵌入在向量空间中占据一个狭窄的圆锥体
- BERT的词向量在空间中并非均匀分布,而是呈锥形。高频词都靠近原点,而低频词远离原点,相当于这两种词处于了空间中不同的区域,那高频词和低频词之间的相似度就不再适用
- 低频词的分布稀疏,因为其表示训练不充分,导致该区域存在语义定义不完整的地方(poorly defined),这样算出来的相似度也有问题

Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere中指出好的对比学习系统应该具备两个属性:
Alignment:指的是相似的例子,也就是正例,映射到单位超球面后应该有接近的特征,也即是说,在超球面上距离比较近
Uniformity:指的是系统应该倾向在特征里保留尽可能多的信息,这等价于使得映射到单位超球面的特征,尽可能均匀地分布在球面上,分布得越均匀,意味着保留的信息越充分。分布均匀意味着两两有差异,也意味着各自保有独有信息,这代表信息保留充分
所以很多时候,会使用相关系数衡量表示学习得到的向量好坏
BERT-flow
基于以上对相似度的深入探讨和问题研究,BERT-flow基于流式生成模型,将BERT的表示可逆地映射到一个均匀的空间,上述的问题就迎刃而解了
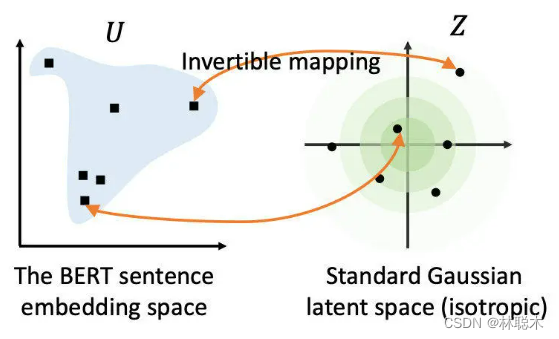
标准高斯分布是各向同性的,在传统的词嵌入方法中,研究表明词向量矩阵的前面几个奇异值通常和高频词高度相关,通过将嵌入分布变换到各向同性的分布上,奇异值就可以被压缩。另外,标准高斯分布是凸的,或者说是没有空洞,因此语义分布更为光滑
Flow-based Generative Model:

Sentence-BERT
Sentence-BERT是基于一个很直接的思想,既然原先的BERT任务不适合做句子表示,换个任务就好了,所以Sentence-BERT直接将添加了一个句子相似度的任务,两个正样本经过BERT得到句子向量,然后句子向量再做拼接,相减,计算softmax
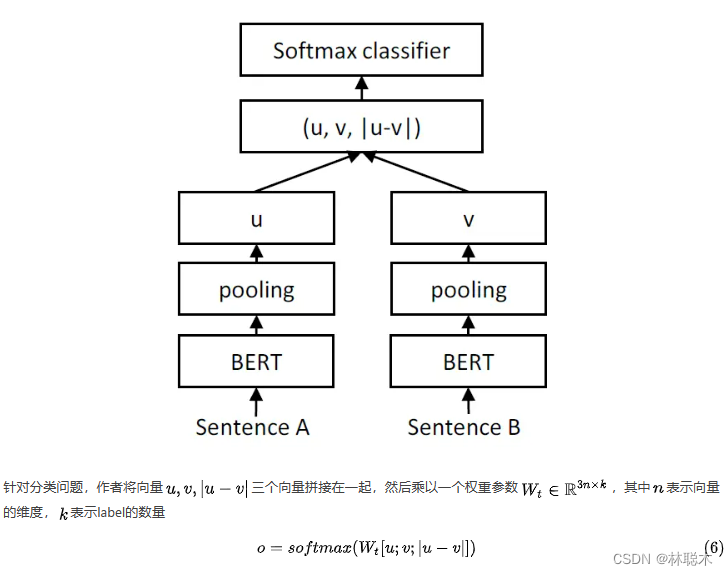
损失函数为CrossEntropyLoss
二. 基于对比学习的BERT表示学习
上文分析得到,BERT得到的句子向量本身不适合做句子的相似度计算,所以对比学习就通过对比损失直接用句子表示来构建损失函数
SimCSE
SimCSE的思路是非常新颖的,因为本身BERT就是有DROPOUT操作,所以讲一句话输入到BERT两次,因为有DROPOUT操作的存在,所以这个就是两个不同的向量,这个构成了无监督SimCSE的训练方式,一个batch内,每句话输入两次,构造正样本,同一个batch内的其他作为负样本。监督方式训练的话,还是使用NLI的数据,entailment是正样本,contradiction的是负样本

ConSERT
ConSERT方法以Simese Net结构为基础,使用一个预训练语言模型M为基础,在一个任务同领域的无标注语料库D上进行fine-tune,ConSERT的整体模型结构如下所示:
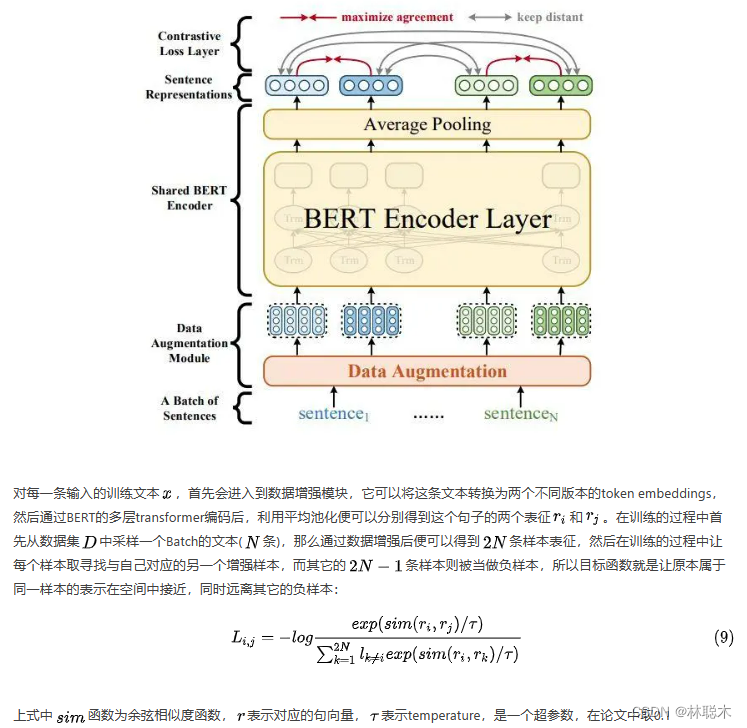
它的结构主要包括以下几个部分:
- 共享BERT编码器:且在BERT的最后一层使用平均池化的方法将句子表征为句向量
- 对比损失层:用于在一个Batch的样本中计算损失的对比,最大化同一个样本不同增强版本句向量的相似度,同时使得不同样本的句向量相互远离
- 数据增强模块:可以在Embedding层将输入的同一个samples生成为不同版本
文本数据增强方法:
在论文中,文本数据增强方法是比较重要的一个部分,很多的文本增强方法(回译、CBERT)无法保证保证语义一致,并且每一次数据增强都需要做一次模型Inference,开销会很大。所以论文探索了4种在Embedding层隐式生成增强样本的方法 :
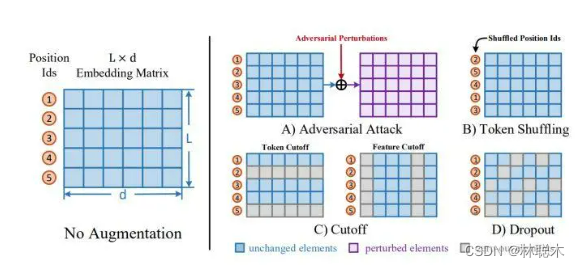
- Adversarial Attack:通过梯度反传生成对抗扰动,将该扰动加到原本的Embedding矩阵上,就能得到增强后的样本。由于生成对抗扰动需要梯度反传,因此这一数据增强方法仅适用于有监督训练的场景
- Token Shuffling:这一方法扰乱输入样本的词序。由于Transformer结构没有“位置”的概念,模型对Token位置的感知全靠Embedding中的Positionids得到。因此在实现上,只需要将Position Ids进行Shuffle即可
- Feature Cutoff:又可以进一步分为两种,Token Cutoff:随机选取Token,将对应Token的Embedding整行置为零。Feature Cutoff:随机选取Embedding的Feature,将选取的Feature维度整列置为零
- Dropout:Embedding中的每一个元素都以一定概率置为零,与Cutoff不同的是,该方法并没有按行或者按列的约束
这四种方法均可以通过对Embedding矩阵(或是BERT的Position Encoding)进行修改得到,因此相比显式生成增强文本的方法更为高效。实验的结果表明Token Shuffle和Feature Cutoff的组合取得了最优性能,从单种数据增强的方法而言,Token Shuffle > Token Cutoff >> Feature Cutoff ≈ Dropout >> None
Self-BERT
考虑到句子向量被广泛用于计算两个句子的相似性,对比学习引入的归纳偏差对BERT来说可能有助于良好地在这些任务中工作。但问题是,句子级的对比学习通常需要使用数据增强或关于训练数据的先验知识,例如句子顺序信息,以便合理的构建正/负样本,并通过利用BERT的隐藏表示来规避这些约束


尽管上述四个因素都扮演了各自的角色,但一些组件可能是无用的甚至对目标产生负面影响
对比学习论文
对比学习应用趋势
- 图数据增强方式的改进(NodeDrop、EdgeDrop、随机游走、引入辅助信息的drop);
- 基于多视图的对比学习(例如在图的结构视图、语义视图、解耦子图间进行对比学习,可以应用到社交网络,知识图谱、bundle推荐、跨域推荐等方向);
- 利用节点关系进行对比任务(利用节点与邻居节点的关系作为样本选取准则、可以考虑GNN节点在不同层的输出表示间的关系、超图);
- 其他角度的对比学习任务(例如,对embedding添加噪声)。
NCL
1.1 NCL核心思想
利用用户交互历史信息构建的二部图,节点关系可以分为四种:1. 相似用户;2. 相似物品;3. 用户-物品交互关系;4. 具有相似语义关系(例如用户意图等)。大多数推荐任务围绕用户-物品交互关系展开,而对同质节点之间的结构关系考虑较少,对语义关系考虑的次数则更少。NCL创新点则在于利用推荐系统中节点的潜在关系设计对比学习任务(包括结构关系与语义关系)。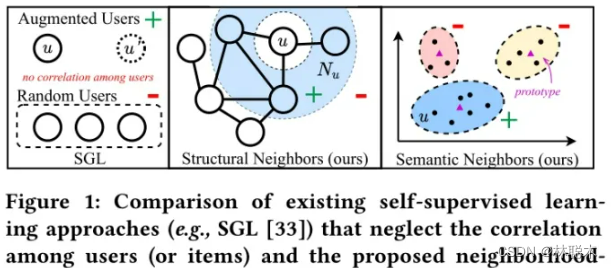
1.2 算法细节
节点级的对比学习任务针对于每个节点进行两两学习,这对于大量邻居来说是极其耗时的,考虑效率问题,文章学习了每种邻居的单一代表性embedding,这样一个节点的对比学习就可以通过两个代表性embedding(结构、语义)来完成。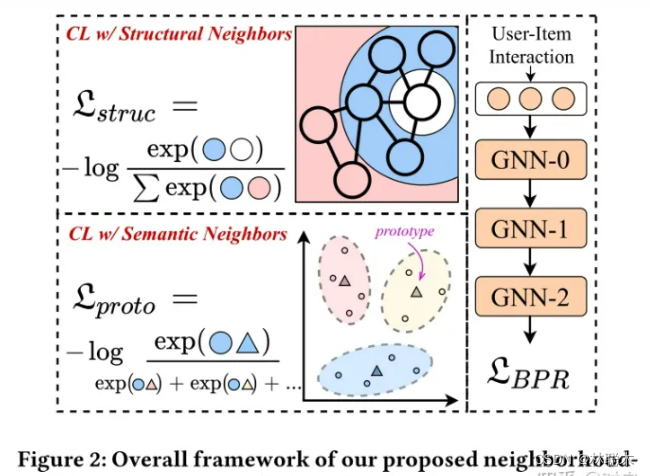
构建基于节点结构关系的对比学习任务:将每个用户(物品)与它的结构邻居进行对比。
构建基于节点语义关系的对比学习任务:将每个用户(物品)与它具有相似语义关系的节点进行对比。这里具有语义关系指的是,图上不可到达,但具有相似物品特征、用户偏好等的节点。
怎么识别具有相同语义的节点呢?我们认为相似的节点倾向于落在临近的embedding空间中,而我们的目标就是寻找代表一组语义邻居的中心(原型)。因此,我们对节点embedding应用聚类算法去获取用户或物品的原型。
由于这个过程不可以端到端优化,我们用EM算法学习提出的语义原型对比任务。形式上,GNN模型的目标是最大化对数似然函数:
M步:得到聚类中心,目标函数重写为: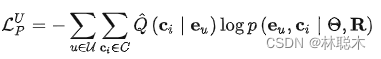
假设用户在所有聚类上的分布是各向同性高斯分布。因此,函数可以写成:
完整算法

ICL
2.1ICL核心思想
很有趣的一点,这篇文章所提模型简称ICL和上篇NCL很像啊······
以下图作引,我们直观理解这篇文章的思想。Figure 1中展现了两个用户的购物序列,尽管没有出现一样相同的商品,但是他们最后却购买了同样的物品。原因很简单,因为他俩同为钓鱼爱好者,购买意图冥冥中含有不可言说的关系。

正是因此,我们必须重视不同用户购买序列之间的潜在意图关系。文章提出的一个良好的解决方案是,我们从未标记的用户行为序列中学习用户的意图分布函数,并使用对比学习优化SR模型。具体来说,我们引入一个潜在变量来表示用户的意图,并通过聚类学习潜在变量的分布函数。
2.2 算法细节

这篇文章的重要价值之一:模型图画的很漂亮,深得我心。从图中可以看出,模型采用EM算法进行优化,在E步中进行聚类,在M步进行损失函数的计算和参数更新。


可以发现,上式最大化了一个单独序列与其相应意图之间的互信息。我们为每个序列通过增强构建用于对比学习的正样本,然后优化以下损失函数:

完整算法:
RGCL
3.1 RGCL核心思想
这篇论文的创新点是引入了用户评分和评论作为辅助信息,为了将二者更好地融入图结构中,RGCL以交互评论作为图的边信息,并以此为基础设计了两个分别基于节点增强和边增强的对比学习任务。
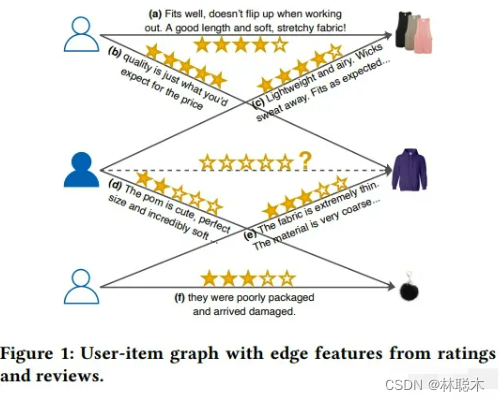
3.2 算法细节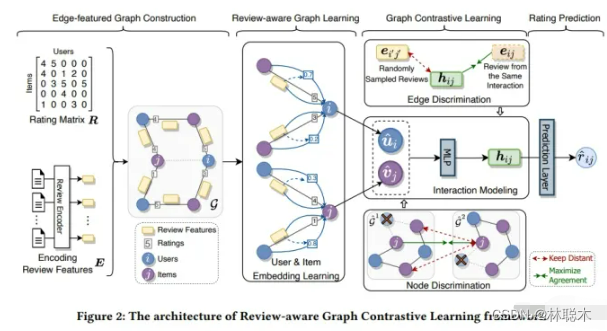

交互建模:区别于一般推荐采用的内积预测方式,论文采用MLP学习用户物品的交互特征,并根据得到的交互特征预测评分(此处的预测评分在对比学习部分会用到): 
MCCLK
4.1 MCCLK核心思想
传统的对比学习方法多通过统一的数据增强方式生成两个不同的视图,本文别出心裁,从知识图不同视图的角度去应用对比学习,提出了一种多层次跨视图对比学习机制。
结合了KGR的特点,论文考虑了三种不同的图视图,包括全局结构视图、局部协同视图和语义视图,视图的理解参见下图~
值得一说的是,针对在语义视图,文章提出物品-物品语义图构建模块去获取以往工作中经常忽略的重要物品-物品语义关系。
4.2 算法细节
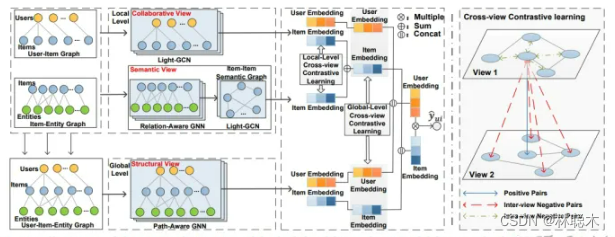
从模型图中可以看出,MCCLK包括三个主要部分视图生成、局部对比学习和全局对比学习。
多视图生成:前面我们说道一共需要构建三个视图,这里详细解释一下三个视图究竟是什么。其中全局结构视图为原始的用户-物品-实体图,协同视图与语义视图分别为用户-物品-实体图生成的用户-物品图和物品-实体图。由于全局结构视图与协同视图很常见,所以重点在构建语义视图。
局部级对比学习:从模型图可以看出,利用协同视图和语义视图中物品的视图embedding,可以实现局部级的交叉视图对比学习。在这之前,我们先来看两个视图中的编码部分。
- 协同视图(即,物品-用户-物品)编码,采用Light-GCN递归地执行聚合操作:


注意,负样本有两个来源,分别为视图内节点和视图间节点,对应于公式分母中的第二项和第三项。
全局级对比学习:这里设计了一个路径感知GNN(该GNN可以在进行次聚合的同时保留路径信息,即user-interact-item-relation-entity等远程连接),将路径信息自动编码到节点embedding中,然后利用全局级视图和局部级视图的编码embedding,进行全局级对比学习。
结构视图的聚合公式为:
采用与局部级对比相同的正负采样策略,有以下对比损失:
MIDGN
5.1 MIDGN核心思想
该模型将DGCF的解耦思路用在了bundle推荐,从全局(解耦bundle间的用户意图)和局部(解耦bundle中的用户意图)两个视图对用户意图进行解耦,并采用InfoNCE加强学习效果。下图可以形象地解释上述两个视图~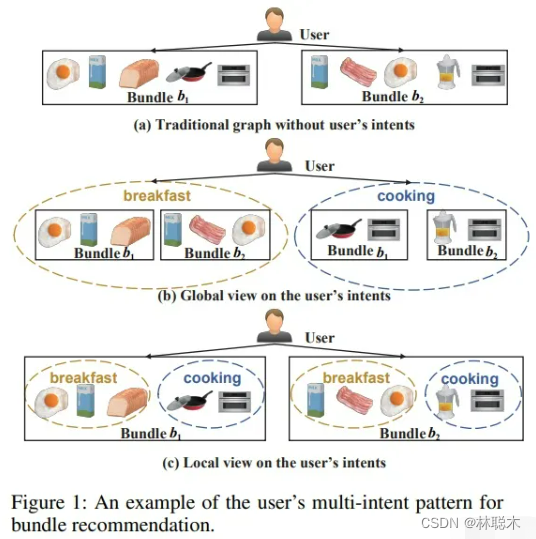
5.2 算法细节
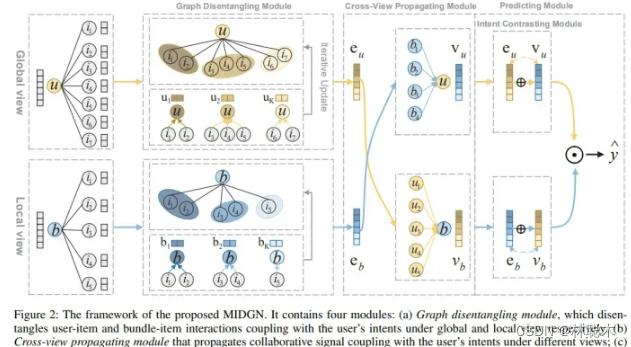
从图中可以看到,MIDGN由四个不同的模块组成:图解耦模块、 视图交叉传播模块、意图对比模块和预测模块。
图解耦模块
每个意图下交互的置信度更新公式为:
图解耦模块从用户-物品交互图中学习分布在不同bundle(全局视图)中的用户意图;从bundle-物品图中,学习用户在每个bundle(局部视图)中的多个意图。结合来自全局和局部视图的意图,得到用户和bundle的表示:
PCL
论文标题:Prototypical Contrastive Learning of Unsupervised Representations
论文方向:图像领域,提出原型对比学习,效果远超MoCo和SimCLR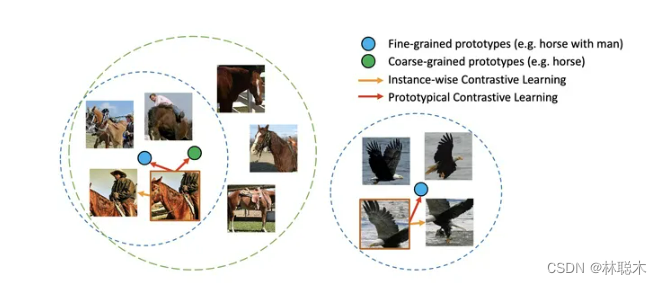
作者提出了原型对比学习(PCL),它是无监督表示学习的一种新方法,综合了对比学习和聚类学习的优点。
在 PCL 中,作者引入了一个「原型」作为由相似图像形成的簇的质心。将每个图像分配给不同粒度的多个原型。训练的目标是使每个图像嵌入更接近其相关原型,这是通过最小化一个 ProtoNCE 损失函数来实现的。
在高层次上,PCL 的目标是找到给定观测图像的最大似然估计(MLE)模型参数: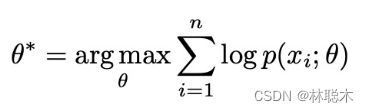
作者引入原型 c 作为与观测数据相关的潜在变量,提出了一种EM算法来求解最大似然估计。在 E-step 中,通过执行 K 平均算法估计原型的概率。在M步中,通过训练模型来最大化似然估计,从而最小化一个 ProtoNCE 损失:
在期望最大化框架下,作者证明以前的对比学习方法是 PCL 的一个特例。
此外,作者在少样本迁移学习、半监督学习和目标检测三个任务上对 PCL 进行评估,在所有情况下都达到了SOTA的性能。
作者希望 PCL 可以扩展到视频,文本,语音等领域,让 PCL 激励更多有前途的非监督式学习领域的研究,推动未来人工智能的发展,使人工标注不再是模型训练的必要组成部分。
from __future__ import print_function, division, absolute_import
import csv
import os
import os.path
import tarfile
from six.moves.urllib.parse import urlparse
import numpy as np
import torch
import torch.utils.data as data
from PIL import Image
import random
from tqdm import tqdm
from six.moves.urllib.request import urlretrieve
object_categories = ['aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair',
'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant',
'sheep', 'sofa', 'train', 'tvmonitor']
urls = {
'devkit': 'http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCdevkit_18-May-2011.tar',
'trainval_2007': 'http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar',
'test_images_2007': 'http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar',
'test_anno_2007': 'http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtestnoimgs_06-Nov-2007.tar',
}
def read_image_label(file):
print('[dataset] read ' + file)
data = dict()
with open(file, 'r') as f:
for line in f:
tmp = line.split(' ')
name = tmp[0]
label = int(tmp[-1])
data[name] = label
# data.append([name, label])
# print('%s %d' % (name, label))
return data
def read_object_labels(root, dataset, set):
path_labels = os.path.join(root, 'VOCdevkit', dataset, 'ImageSets', 'Main')
labeled_data = dict()
num_classes = len(object_categories)
for i in range(num_classes):
file = os.path.join(path_labels, object_categories[i] + '_' + set + '.txt')
data = read_image_label(file)
if i == 0:
for (name, label) in data.items():
labels = np.zeros(num_classes)
labels[i] = label
labeled_data[name] = labels
else:
for (name, label) in data.items():
labeled_data[name][i] = label
return labeled_data
def write_object_labels_csv(file, labeled_data):
# write a csv file
print('[dataset] write file %s' % file)
with open(file, 'w') as csvfile:
fieldnames = ['name']
fieldnames.extend(object_categories)
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for (name, labels) in labeled_data.items():
example = {'name': name}
for i in range(20):
example[fieldnames[i + 1]] = int(labels[i])
writer.writerow(example)
csvfile.close()
def read_object_labels_csv(file, header=True):
images = []
num_categories = 0
print('[dataset] read', file)
with open(file, 'r') as f:
reader = csv.reader(f)
rownum = 0
for row in reader:
if header and rownum == 0:
header = row
else:
if num_categories == 0:
num_categories = len(row) - 1
name = row[0]
labels = (np.asarray(row[1:num_categories + 1])).astype(np.float32)
labels = torch.from_numpy(labels)
item = (name, labels)
images.append(item)
rownum += 1
return images
def find_images_classification(root, dataset, set):
path_labels = os.path.join(root, 'VOCdevkit', dataset, 'ImageSets', 'Main')
images = []
file = os.path.join(path_labels, set + '.txt')
with open(file, 'r') as f:
for line in f:
images.append(line)
return images
def download_voc2007(root):
path_devkit = os.path.join(root, 'VOCdevkit')
path_images = os.path.join(root, 'VOCdevkit', 'VOC2007', 'JPEGImages')
tmpdir = os.path.join(root, 'tmp')
# create directory
if not os.path.exists(root):
os.makedirs(root)
if not os.path.exists(path_devkit):
if not os.path.exists(tmpdir):
os.makedirs(tmpdir)
parts = urlparse(urls['devkit'])
filename = os.path.basename(parts.path)
cached_file = os.path.join(tmpdir, filename)
if not os.path.exists(cached_file):
print('Downloading: "{}" to {}\n'.format(urls['devkit'], cached_file))
download_url(urls['devkit'], cached_file)
# extract file
print('[dataset] Extracting tar file {file} to {path}'.format(file=cached_file, path=root))
cwd = os.getcwd()
tar = tarfile.open(cached_file, "r")
os.chdir(root)
tar.extractall()
tar.close()
os.chdir(cwd)
print('[dataset] Done!')
# train/val images/annotations
if not os.path.exists(path_images):
# download train/val images/annotations
parts = urlparse(urls['trainval_2007'])
filename = os.path.basename(parts.path)
cached_file = os.path.join(tmpdir, filename)
if not os.path.exists(cached_file):
print('Downloading: "{}" to {}\n'.format(urls['trainval_2007'], cached_file))
download_url(urls['trainval_2007'], cached_file)
# extract file
print('[dataset] Extracting tar file {file} to {path}'.format(file=cached_file, path=root))
cwd = os.getcwd()
tar = tarfile.open(cached_file, "r")
os.chdir(root)
tar.extractall()
tar.close()
os.chdir(cwd)
print('[dataset] Done!')
# test annotations
test_anno = os.path.join(path_devkit, 'VOC2007/ImageSets/Main/aeroplane_test.txt')
if not os.path.exists(test_anno):
# download test annotations
parts = urlparse(urls['test_images_2007'])
filename = os.path.basename(parts.path)
cached_file = os.path.join(tmpdir, filename)
if not os.path.exists(cached_file):
print('Downloading: "{}" to {}\n'.format(urls['test_images_2007'], cached_file))
download_url(urls['test_images_2007'], cached_file)
# extract file
print('[dataset] Extracting tar file {file} to {path}'.format(file=cached_file, path=root))
cwd = os.getcwd()
tar = tarfile.open(cached_file, "r")
os.chdir(root)
tar.extractall()
tar.close()
os.chdir(cwd)
print('[dataset] Done!')
# test images
test_image = os.path.join(path_devkit, 'VOC2007/JPEGImages/000001.jpg')
if not os.path.exists(test_image):
# download test images
parts = urlparse(urls['test_anno_2007'])
filename = os.path.basename(parts.path)
cached_file = os.path.join(tmpdir, filename)
if not os.path.exists(cached_file):
print('Downloading: "{}" to {}\n'.format(urls['test_anno_2007'], cached_file))
download_url(urls['test_anno_2007'], cached_file)
# extract file
print('[dataset] Extracting tar file {file} to {path}'.format(file=cached_file, path=root))
cwd = os.getcwd()
tar = tarfile.open(cached_file, "r")
os.chdir(root)
tar.extractall()
tar.close()
os.chdir(cwd)
print('[dataset] Done!')
def download_url(url, destination=None, progress_bar=True):
"""Download a URL to a local file.
Parameters
----------
url : str
The URL to download.
destination : str, None
The destination of the file. If None is given the file is saved to a temporary directory.
progress_bar : bool
Whether to show a command-line progress bar while downloading.
Returns
-------
filename : str
The location of the downloaded file.
Notes
-----
Progress bar use/example adapted from tqdm documentation: https://github.com/tqdm/tqdm
"""
def my_hook(t):
last_b = [0]
def inner(b=1, bsize=1, tsize=None):
if tsize is not None:
t.total = tsize
if b > 0:
t.update((b - last_b[0]) * bsize)
last_b[0] = b
return inner
if progress_bar:
with tqdm(unit='B', unit_scale=True, miniters=1, desc=url.split('/')[-1]) as t:
filename, _ = urlretrieve(url, filename=destination, reporthook=my_hook(t))
else:
filename, _ = urlretrieve(url, filename=destination)
class Voc2007Classification(data.Dataset):
def __init__(self, root, set, transform=None, target_transform=None):
self.root = root
self.path_devkit = os.path.join(root, 'VOCdevkit')
self.path_images = os.path.join(root, 'VOCdevkit', 'VOC2007', 'JPEGImages')
self.set = set
self.transform = transform
self.target_transform = target_transform
self.low_shot = False
# download dataset
download_voc2007(self.root)
# define path of csv file
path_csv = os.path.join(self.root, 'files', 'VOC2007')
# define filename of csv file
file_csv = os.path.join(path_csv, 'classification_' + set + '.csv')
# create the csv file if necessary
if not os.path.exists(file_csv):
if not os.path.exists(path_csv): # create dir if necessary
os.makedirs(path_csv)
# generate csv file
labeled_data = read_object_labels(self.root, 'VOC2007', self.set)
# write csv file
write_object_labels_csv(file_csv, labeled_data)
self.classes = object_categories
self.images = read_object_labels_csv(file_csv)
print('[dataset] VOC 2007 classification set=%s number of classes=%d number of images=%d' % (
set, len(self.classes), len(self.images)))
def __getitem__(self, index):
if self.low_shot:
path, target = self.images_lowshot[index]
else:
path, target = self.images[index]
img = Image.open(os.path.join(self.path_images, path + '.jpg')).convert('RGB')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
if self.low_shot:
return len(self.images_lowshot)
else:
return len(self.images)
def get_number_classes(self):
return len(self.classes)
def convert_low_shot(self, k): #sample k images per class
label2img = {c:[] for c in range(len(self.classes))}
for img in self.images:
label = img[1]
label_classes = torch.where(label>0)[0]
for c in label_classes:
label2img[c.item()].append(img)
self.images_lowshot = []
for c,imlist in label2img.items():
random.shuffle(imlist)
self.images_lowshot += imlist[:k]
self.low_shot = True BalFeat
论文标题:Exploring Balanced Feature Spaces for Representation Learning
论文方向:图像领域,提出k-positive对比学习,主要解决类别分布不均匀的问题
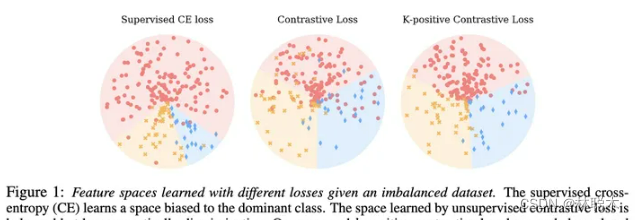
现有的自监督学习(SSL)方法主要用于训练来自人工平衡数据集(如ImageNet)的表示模型。目前还不清楚它们在实际情况下的表现如何,在实际情况下,数据集经常是不平衡的。基于这个问题,作者在训练实例分布从均匀分布到长尾分布的多个数据集上,对自监督对比学习和监督学习方法的性能进行了一系列的研究。作者发现与具有较大性能下降的监督学习方法不同的是,自监督对比学习方法即使在数据集严重不平衡的情况下也能保持稳定的学习性能。
这促使作者探索通过对比学习获得的平衡特征空间,其中特征表示在所有类中都具有相似的线性可分性。作者的实验表明,在多个条件下,生成平衡特征空间的表征模型比生成不平衡特征空间的表征模型具有更好的泛化能力。基于此,作者提出了k-positive对比学习,它有效地结合了监督学习方法和对比学习方法的优点来学习具有区别性和均衡性的表示。大量实验表明,该算法在长尾识别和正常平衡识别等多种识别任务中都具有优越性。
MiCE
论文标题:MiCE: Mixture of Contrastive Experts for Unsupervised Image Clustering
论文方向:图像领域,对比学习结合混合专家模型MoE,无需正则化
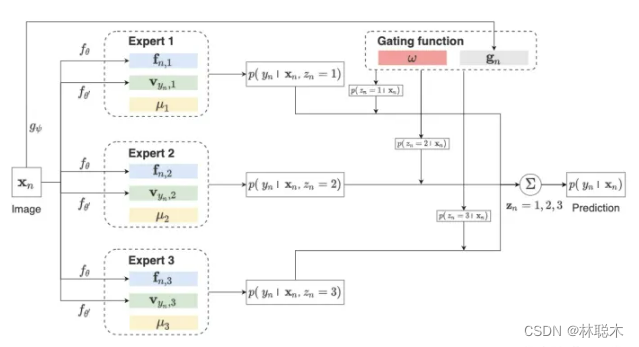
目前深度聚类方法都是使用two-stage进行构建,即首先利用pre-trained模型进行表示学习,之后再使用聚类算法完成聚类,但是由于这两个stage相互独立且现有的baseline在表示学习中并没有很好的建模语义信息,导致后面无法得到很好的聚类。
作者提出一个统一概率聚类模型Mixture of Contrastive Experts (MiCE),其同时利用了对比学习学习到的判别性表示(discriminative representation)和潜在混合模型获取的语义结构(semantic structures)。受多专家模型(mixture of experts ,MoE)启发,通过引入潜变量来表示图像的聚类标签,从而形成一种混合条件模型,每个条件模型(也称为expert)学习区分实例的子集,同时该模型采用门控函数(gating function)通过在专家之间分配权重,将数据集根据语义信息划分为子集。进一步,为了解决潜在变量引起的非简单推断(nontrivial inference)和其他训练问题,作者进一步构建了可扩展的EM算法,并给出了收敛性证明。其中E步,根据观测数据得到潜在变量后验分布的估计,M步最大化关于所有变量的对数条件似然。
MICE具有以下优点:
- 方法论上的统一:MICE结合了通过对比学习得到的判别性表示和通过统一概率框架内的潜在混合模型得到的语义结构的优点。
- 无需正则化:MICE仅通过EM进行优化,不需要任何其他的辅助loss和正则化loss。
Preliminary

门控函数根据图像embedding和gating prototype之间的余弦相似度对数据集进行软划分(soft partitioning),我们可以把它看作是一个基于prototype的判别聚类模块,使用后验推理来获得聚类标签,以考虑expert中的附加信息
在(5)式中,第一个instance-wise点积计算实例层次(instance-level)信息,以在每个expert中产生具有判别性的表示(discriminative representation),第二个instance-prototype点积将类别层次(class-level)信息整合到表示学习中,使之能够围绕prototype形成清晰的集群结构,因此产生的embedding具有语意结构同时有足够的判别性来表示不同实例
该式子基于MoCo和EMA构造,更多细节查看原文附录D。
import torch
from torch import nn
import math
import numpy as np
import torch.nn.functional as F
class MiCE_ELBO(nn.Module):
def __init__(self, inputSize, outputSize, nu, tau=1.0, n_class=10):
super(MiCE_ELBO, self).__init__()
print("--------------------Initializing -----------------------------------")
self.outputSize = outputSize
self.inputSize = inputSize
self.queueSize = nu
self.tau = tau
self.kappa = self.tau
self.index = 0
self.n_class = n_class
stdv = 1. / math.sqrt(inputSize / 3)
self.register_buffer('queue', torch.rand(self.queueSize, self.n_class, inputSize).mul_(2 * stdv).add_(-stdv))
print('using queue shape: ({},{},{})'.format(self.queueSize, self.n_class, inputSize))
if n_class==10:
cluster_file = np.loadtxt("./kernel_paras/meanvar1_featuredim128_class10.mat")
elif n_class == 20:
cluster_file = np.loadtxt("./kernel_paras/meanvar1_featuredim128_class20.mat")
elif n_class ==15:
cluster_file = np.loadtxt("./kernel_paras/meanvar1_featuredim128_class15.mat")
self.register_buffer('gating_prototype', torch.from_numpy(cluster_file).type(torch.FloatTensor))
self.expert_prototype = nn.Parameter(torch.Tensor(self.n_class, inputSize))
self.logSoftmax = torch.nn.LogSoftmax(dim=1)
self.logSoftmax2 = torch.nn.LogSoftmax(dim=2)
print("--------------------Initialization Ends-----------------------------------")
def update_cluster(self, new_center):
with torch.no_grad():
new_center = F.normalize(new_center, dim=1)
out_ids = torch.arange(self.n_class).cuda()
out_ids = out_ids.long() # BS x 1
self.expert_prototype.index_copy_(0, out_ids, new_center)
def forward(self, f, v, g,):
batchSize = f.shape[0]
v = v.detach()
pi_logit_student = torch.div(torch.einsum('kd,bd->bk', [self.gating_prototype.detach().clone(), g]),
self.kappa) # K x D vs B x D ---> BS x K
log_pi = self.logSoftmax(pi_logit_student + 1e-18)
pi = torch.exp(log_pi) # p(z | x)
# positive sample
v_f = torch.einsum("bkd,bkd->bk", [f, v]).unsqueeze(-1) # BS x K x D --> BS x K x 1
v_mu = torch.einsum("bkd,kd->bk", [v, F.normalize(self.expert_prototype, dim=1)]).unsqueeze(-1) # BS x K x 1
l_pos = (v_f + v_mu) # BS x K x 1
l_pos = torch.einsum('bki->kbi', [l_pos]) # BS x K x 1 --> K x BS x 1
# Negative sample
queue = self.queue.detach().clone() # nu x D x K
queue_f = torch.einsum('vkd,bkd->kbv', [queue, f]) # K x BS x nu
queue_mu = torch.einsum('vkd,kd->kv', [queue, F.normalize(self.expert_prototype, dim=1)]).unsqueeze(1) # K x 1 x nu
del queue
l_neg = queue_f + queue_mu # K x BS x nu
out = torch.div(torch.cat([l_pos, l_neg], dim=2), self.tau) # K x BS x (nu + 1)
del l_pos, l_neg
log_phi = self.logSoftmax2(out + 1e-18)
normalized_phi = torch.exp(log_phi) # p(y | x, z)
log_phi_pos = log_phi[:, :, 0]
normalized_phi_pos = normalized_phi[:, :, 0]
del normalized_phi
normalized_phi_pos = normalized_phi_pos.transpose(1, 0) * pi # BS x K
posterior = torch.div(normalized_phi_pos, normalized_phi_pos.sum(1).view(-1, 1)).squeeze().contiguous() # BS x K: posterior -> each row = p(z | v_i, x_i) # BS x Classes, probability
log_phi_pos = log_phi_pos.transpose(1, 0).squeeze().contiguous() # K x BS -> BS x K
loss = -torch.sum(posterior * (log_pi + log_phi_pos - torch.log(posterior + 1e-18))) / float(batchSize)
# update queue using EMA predictions
with torch.no_grad():
out_ids = torch.arange(batchSize).cuda()
out_ids += self.index
out_ids = torch.fmod(out_ids, self.queueSize)
out_ids = out_ids.long()
self.queue.index_copy_(0, out_ids, v)
self.index = (self.index + batchSize) % self.queueSize
return loss, loss, posterior, log_pi i-Mix
论文标题:i-Mix: A Strategy for Regularizing Contrastive Representation Learning
论文方向:图像领域,少样本+MixUp策略来提升对比学习效果
对比表示学习已经证明了从未标记数据中学习表示是有效的。然而,利用领域知识精心设计的数据增强技术已经在视觉领域取得了很大进展。
作者提出了i-Mix,一个简单而有效的领域未知正则化策略,以改善对比表示学习。作者将 MixUp 技巧用在了无监督对比学习上,可有效提升现有的对比学习方法(尤其是在小数据集上):给每个样本引入虚拟标签,然后插值样本空间和 label 空间进行数据增强。
实验结果证明了i-Mix在图像、语音和表格数据等领域不断提高表示学习的质量。
Contrastive Learning with Hard Negative Samples
论文标题:Contrastive Learning with Hard Negative Samples
论文方向:图像&文本领域,研究如何采样优质的难负样本
对比学习在无监督表征学习领域的潜力无需多言,已经有非常多的例子证明其效果,目前比较多的针对对比学习的改进包括损失函数、抽样策略、数据增强方法等多方面,但是针对负对的研究相对而言更少一些,一般在构造正负对时,大部分模型都简单的把单张图像及其增强副本作为正对,其余样本均视为负对。这一策略可能会导致的问题是模型把相距很远的样本分得很开,而距离较近的负样本对之间可能比较难被区分。
基于此,本文构造了一个难负对的思想,主要目的在于,把离样本点距离很近但是又确实不属于同一类的样本作为负样本,加大了负样本的难度,从而使得类与类之间分的更开,来提升对比学习模型的表现。
好的难负样本有两点原则:1)与原始样本的标签不同;2)与原始样本尽量相似。
这一点就与之前的对比学习有比较明显的差异了,因为对比学习一般来说并不使用监督信息,因此除了锚点之外的其他样本,不管标签如何,都被认为是负对,所以问题的一个关键在于“用无监督的方法筛出不属于同一个标签的样本”。不仅如此,这里还有一个冲突的地方,既要与锚点尽可能相似,又得不属于同一类,这对于一个无监督模型来说是有难度的,因此本文在实际实现过程中进行了一个权衡,假如对样本的难度要求不是那么高的时候,就只满足原则1,而忽略原则2。同时,这种方法应该尽量不增加额外的训练成本。
import os.path as osp
from tqdm import tqdm
import torch
import torch.nn.functional as F
from torch.nn import Sequential, Linear, ReLU
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
from torch_geometric.nn import GINConv, global_add_pool
import numpy as np
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV, KFold, StratifiedKFold
from sklearn.svm import SVC, LinearSVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn import preprocessing
from sklearn.metrics import accuracy_score
import sys
class Encoder(torch.nn.Module):
def __init__(self, num_features, dim, num_gc_layers):
super(Encoder, self).__init__()
# num_features = dataset.num_features
# dim = 32
self.num_gc_layers = num_gc_layers
# self.nns = []
self.convs = torch.nn.ModuleList()
self.bns = torch.nn.ModuleList()
for i in range(num_gc_layers):
if i:
nn = Sequential(Linear(dim, dim), ReLU(), Linear(dim, dim))
else:
nn = Sequential(Linear(num_features, dim), ReLU(), Linear(dim, dim))
conv = GINConv(nn)
bn = torch.nn.BatchNorm1d(dim)
self.convs.append(conv)
self.bns.append(bn)
def forward(self, x, edge_index, batch):
if x is None:
x = torch.ones((batch.shape[0], 1)).to(device)
xs = []
for i in range(self.num_gc_layers):
x = F.relu(self.convs[i](x, edge_index))
x = self.bns[i](x)
xs.append(x)
# if i == 2:
# feature_map = x2
xpool = [global_add_pool(x, batch) for x in xs]
x = torch.cat(xpool, 1)
return x, torch.cat(xs, 1)
def get_embeddings(self, loader):
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
ret = []
y = []
with torch.no_grad():
for data in loader:
data.to(device)
x, edge_index, batch = data.x, data.edge_index, data.batch
if x is None:
x = torch.ones((batch.shape[0],1)).to(device)
x, _ = self.forward(x, edge_index, batch)
ret.append(x.cpu().numpy())
y.append(data.y.cpu().numpy())
ret = np.concatenate(ret, 0)
y = np.concatenate(y, 0)
return ret, y
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
try:
num_features = dataset.num_features
except:
num_features = 1
dim = 32
self.encoder = Encoder(num_features, dim)
self.fc1 = Linear(dim*5, dim)
self.fc2 = Linear(dim, dataset.num_classes)
def forward(self, x, edge_index, batch):
if x is None:
x = torch.ones(batch.shape[0]).to(device)
x, _ = self.encoder(x, edge_index, batch)
x = F.relu(self.fc1(x))
x = F.dropout(x, p=0.5, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=-1)
def train(epoch):
model.train()
if epoch == 51:
for param_group in optimizer.param_groups:
param_group['lr'] = 0.5 * param_group['lr']
loss_all = 0
for data in train_loader:
data = data.to(device)
optimizer.zero_grad()
# print(data.x.shape)
# [ num_nodes x num_node_labels ]
# print(data.edge_index.shape)
# [2 x num_edges ]
# print(data.batch.shape)
# [ num_nodes ]
output = model(data.x, data.edge_index, data.batch)
loss = F.nll_loss(output, data.y)
loss.backward()
loss_all += loss.item() * data.num_graphs
optimizer.step()
return loss_all / len(train_dataset)
def test(loader):
model.eval()
correct = 0
for data in loader:
data = data.to(device)
output = model(data.x, data.edge_index, data.batch)
pred = output.max(dim=1)[1]
correct += pred.eq(data.y).sum().item()
return correct / len(loader.dataset)
if __name__ == '__main__':
for percentage in [ 1.]:
for DS in [sys.argv[1]]:
if 'REDDIT' in DS:
epochs = 200
else:
epochs = 100
path = osp.join(osp.dirname(osp.realpath(__file__)), '..', 'data', DS)
accuracies = [[] for i in range(epochs)]
#kf = StratifiedKFold(n_splits=10, shuffle=True, random_state=None)
dataset = TUDataset(path, name=DS) #.shuffle()
num_graphs = len(dataset)
print('Number of graphs', len(dataset))
dataset = dataset[:int(num_graphs * percentage)]
dataset = dataset.shuffle()
kf = KFold(n_splits=10, shuffle=True, random_state=None)
for train_index, test_index in kf.split(dataset):
# x_train, x_test = x[train_index], x[test_index]
# y_train, y_test = y[train_index], y[test_index]
train_dataset = [dataset[int(i)] for i in list(train_index)]
test_dataset = [dataset[int(i)] for i in list(test_index)]
print('len(train_dataset)', len(train_dataset))
print('len(test_dataset)', len(test_dataset))
train_loader = DataLoader(train_dataset, batch_size=128)
test_loader = DataLoader(test_dataset, batch_size=128)
# print('train', len(train_loader))
# print('test', len(test_loader))
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
model = Net().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(1, epochs+1):
train_loss = train(epoch)
train_acc = test(train_loader)
test_acc = test(test_loader)
accuracies[epoch-1].append(test_acc)
tqdm.write('Epoch: {:03d}, Train Loss: {:.7f}, '
'Train Acc: {:.7f}, Test Acc: {:.7f}'.format(epoch, train_loss,
train_acc, test_acc))
tmp = np.mean(accuracies, axis=1)
print(percentage, DS, np.argmax(tmp), np.max(tmp), np.std(accuracies[np.argmax(tmp)]))
input()LooC
论文标题:What Should Not Be Contrastive in Contrastive Learning
论文方向:图像领域,探讨对比学习可能会引入偏差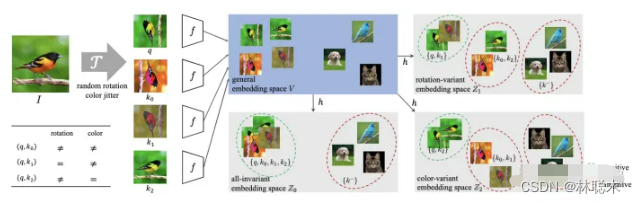
当前对比学习的框架大多采用固定的数据增强方式,但是对于不同的下游任务,不同的数据增强肯定会有不一样的效果,例如在数据增强中加入旋转,那么下游任务就会难以辨别方向,本文针对该问题进行研究。
作者发现原来的对比学习都是映射到同一空间,但是这样会有害学习其他的特征,所以作者把每个特征都映射到单独的特征空间,这个空间里都只有经过这一种数据增强的数据。
总而言之,数据增强是要根据下游任务来说的,分成不同的Embedding空间来适合多种不同的下游任务,但是对需要两种以上特征的下游任务效果可能就不好了。比如不仅仅需要结构信息,还需要位置。
CALM
论文标题:Pre-training Text-to-Text Transformers for Concept-centric Common Sense
论文方向:文本领域,利用对比学习和自监督损失,在预训练语言模型中引入常识信息
预训练语言模型 在一系列自然语言理解和生成任务中取得了令人瞩目的成果。然而,当前的预训练目标,例如Masked预测和Masked跨度填充并没有明确地对关于日常概念的关系常识进行建模,对于许多需要常识来理解或生成的下游任务是至关重要的。为了用以概念为中心的常识来增强预训练语言模型,在本文中,作者提出了从文本中学习常识的生成目标和对比目标,并将它们用作中间自监督学习任务,用于增量预训练语言模型(在特定任务之前下游微调数据集)。此外,作者开发了一个联合预训练框架来统一生成和对比目标,以便它们可以相互加强。
大量的实验结果表明,CALM可以在不依赖外部知识的情况下,将更多常识打包到预训练的文本到文本Transformer的参数中,在NLU和NLG 任务上都取得了更好的性能。作者表明,虽然仅在相对较小的语料库上进行了几步的增量预训练,但 CALM 以一致的幅度优于baseline,甚至可以与一些较大的 预训练语言模型相媲美,这表明 CALM 可以作为通用的“即插即用” 方法,用于提高预训练语言模型的常识推理能力。
"""Fine-tune T5-based model."""
import argparse
import os
import pytorch_lightning as pl
import torch
from logger import LoggingCallback
from trainer import T5FineTuner
from utils import get_best_checkpoint, set_seed
def main() -> None:
"""Fine-tune T5-based model."""
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument(
"--data_dir", type=str, default="task_data/semeval-t5", help="Path for data files."
)
parser.add_argument(
"--output_dir",
type=str,
default="checkpoints/unifiedqa-3b-semeval",
help="Path to save the checkpoints.",
)
parser.add_argument("--checkpoint_dir", type=str, default="", help="Checkpoint directory.")
parser.add_argument(
"--save_every_n_steps",
type=int,
default=-1,
help="Interval of training steps to save the model checkpoints."
"Use -1 to disable this callback.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
default="allenai/unifiedqa-t5-3b",
help="Model name or path.",
)
parser.add_argument(
"--tokenizer_name_or_path",
type=str,
default="allenai/unifiedqa-t5-3b",
help="Tokenizer name or path.",
)
# You can find out more on optimization levels at
# https://nvidia.github.io/apex/amp.html#opt-levels-and-properties
parser.add_argument("--opt_level", type=str, default="O1", help="Optimization level.")
parser.add_argument(
"--early_stop_callback", action="store_true", help="Whether to do early stopping."
)
# If you want to enable 16-bit training, set this to true
parser.add_argument(
"--fp_16",
action="store_true",
help="Whether to use 16-bit precision floating point operations.",
)
parser.add_argument("--learning_rate", type=float, default=3e-4, help="Learning rate.")
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay.")
parser.add_argument(
"--adam_epsilon", type=float, default=1e-8, help="Epsilon value for Adam optimizer."
)
# If you enable 16-bit training then set this to a sensible value, 0.5 is a good default
parser.add_argument(
"--max_grad_norm", type=float, default=1.0, help="Maximum gradient norm value for clipping."
)
parser.add_argument("--max_seq_length", type=int, default=128, help="Maximum sequence length.")
parser.add_argument("--warmup_steps", type=int, default=400, help="Number of warmup steps.")
parser.add_argument("--train_batch_size", type=int, default=16, help="Batch size for training.")
parser.add_argument(
"--eval_batch_size", type=int, default=16, help="Batch size for evaluation."
)
parser.add_argument(
"--num_train_epochs", type=int, default=100, help="Number of training epochs."
)
parser.add_argument(
"--gradient_accumulation_steps", type=int, default=1, help="Gradient accumulation steps."
)
parser.add_argument(
"--n_gpu", type=int, default=1, help="Number of GPUs to use for computation."
)
parser.add_argument(
"--gpu_nums",
type=str,
default="-1",
help='GPU IDs separated by "," to use for computation.',
)
parser.add_argument("--seed", type=int, default=42, help="Manual seed value.")
parser.add_argument("--model_parallel", action="store_true", help="Enable model parallelism.")
args = parser.parse_known_args()[0]
print(args)
set_seed(args.seed)
# Create a folder if output_dir doesn't exist
if not os.path.exists(args.output_dir):
print("Creating output directory")
os.makedirs(args.output_dir)
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=args.output_dir + "/{epoch}-{val_loss:.6f}",
prefix="checkpoint_",
monitor="val_loss",
mode="min",
save_top_k=1,
)
if args.checkpoint_dir:
best_checkpoint_path = get_best_checkpoint(args.checkpoint_dir)
print(f"Using checkpoint = {best_checkpoint_path}")
checkpoint_state = torch.load(best_checkpoint_path, map_location="cpu")
model = T5FineTuner(args)
model.load_state_dict(checkpoint_state["state_dict"])
else:
model = T5FineTuner(args)
trainer = pl.Trainer(
accumulate_grad_batches=args.gradient_accumulation_steps,
early_stop_callback=args.early_stop_callback,
max_epochs=args.num_train_epochs,
precision=16 if args.fp_16 else 32,
amp_level=args.opt_level,
gradient_clip_val=args.max_grad_norm,
checkpoint_callback=checkpoint_callback,
distributed_backend="ddp" if not args.model_parallel else None,
gpus=args.gpu_nums if not args.model_parallel else None,
callbacks=[LoggingCallback()],
)
trainer.fit(model)
if __name__ == "__main__":
main()Support-set bottlenecks for video-text representation learning
论文标题:Support-set bottlenecks for video-text representation learning
论文方向:多模态领域(文本+视频),提出了cross-captioning目标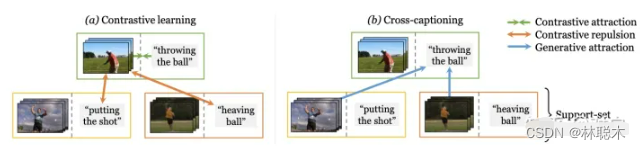
学习视频-文本表示的主流典范——噪声对比学习——增加了已知相关样本对的表示的相似性,例如来自同一样本的文本和视频,但将所有样本对都认为是负例。作者认为最后一个行为过于严格,即使对于语义相关的样本也强制执行不同的表示——例如,视觉上相似的视频或共享相同描述动作的视频。在本文中,作者提出了一种新方法,通过利用生成模型将这些相关样本自然地推到一起来缓解这种情况:每个样本的标题必须重建为其他支持样本的视觉表示的加权组合。这个简单的想法确保表示不会过度专门用于单个样本,可以在整个数据集中重复使用,并产生明确编码样本之间共享语义的表示,这与噪声对比学习不同。作者提出的方法在 MSR-VTT、VATEX、ActivityNet 和 MSVD 的视频到文本和文本到视频检索方面明显优于其他方法。
Cross-modal discrimination和cross-captioning:作者的模型从两个互补的损失中学习:(a)Cross-modal 对比学习学习强大的联合视频文本的Embedding,但所有其他样本都被认为是负例,甚至推开语义相关的标题(橙色箭头)。 (b) 我们引入了cross-captioning的生成任务,通过学习将样本的文本表示重构为支持集的加权组合,由其他样本的视频表示组成,从而缓解了这一问题。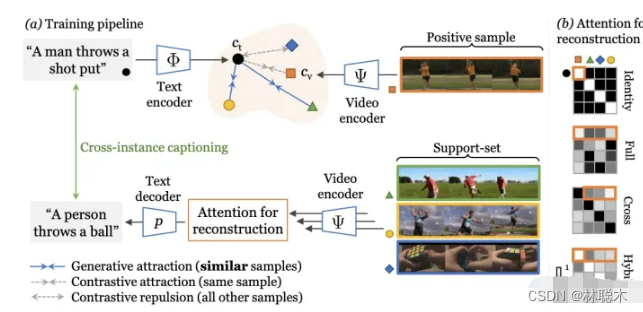
作者的cross-modal框架具有判别(对比)目标和生成目标。该模型学习将公共Embedding空间中的视频-文本对与文本和视频编码器(顶部)相关联。同时,文本还必须重建为来自支持集的视频Embedding的加权组合,通过Attention选择,这会强制不同样本之间的Embedding共享。
SpCL
论文标题:Self-paced Contrastive Learning with Hybrid Memory for Domain Adaptive Object Re-ID
论文方向:目标重识别,提出自步对比学习,在无监督目标重识别任务上显著地超越最先进模型高达16.7%
本文提出自步对比学习(Self-paced Contrastive Learning)框架,包括一个图像特征编码器(Encoder)和一个混合记忆模型(Hybrid Memory)。核心是混合记忆模型在动态变化的类别下所提供的连续有效的监督,以统一对比损失函数(Unified Contrastive Loss)的形式监督网络更新,实现起来非常容易,且即插即用。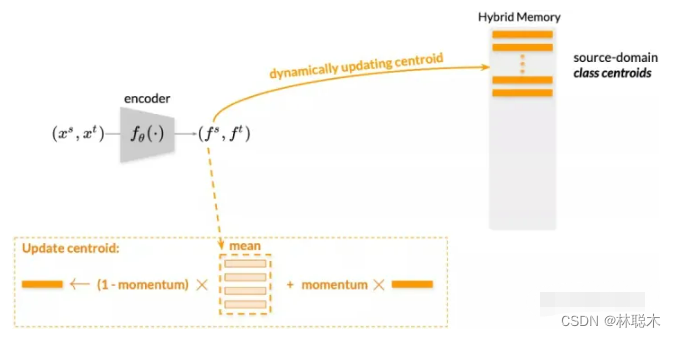
上文中提到混合记忆模型(Hybrid Memory)实时提供三种不同的类别原型,作者提出了使用动量更新(Momentum Update),想必这个词对大家来说并不陌生,在MoCo、Mean-teacher等模型中常有见到,简单来说,就是以“参数= (1-动量)x新参数+动量x参数”的形式更新。这里针对源域和目标域采取不同的动量更新算法,以适应其不同的特性。对于源域的数据而言,由于具有真实的类别,作者提出以类为单位进行存储。这样的操作一方面节省空间,一方面在实验中也取得了较好的结果。将当前mini-batch内的源域特征根据类别算均值,然后以动量的方式累计到混合记忆模型中对应的类质心上去。对于目标域的数据而言,作者提出全部以实例为单位进行特征存储,这是为了让目标域样本即使在聚类和非聚类离群值不断变化的情况下,仍然能够在混合记忆模型中持续更新(Continuously Update)。具体而言,将当前mini-batch内的目标域特征根据实例的index累计到混合记忆模型对应的实例特征上去。
SimCLR V2
论文标题:Big Self-Supervised Models are Strong Semi-Supervised Learners
论文方向:图像领域(Google出品)
本文针对深度学习中数据集标签不平衡的问题,即大量的未标注数据和少量标注数据,作者提出了一种弱监督的模型SimCLRv2(基于SimCLRv1)。作者认为这种庞大的、极深的网络更能够在自监督的学习中获得提升。论文中的思想可以总结为一下三步:
1. 使用ResNet作为backbone搭建大型的SimCLRv2,进行无监督的预训练;
2. 然后在少量有标注的数据上进行有监督的finetune;
3. 再通过未标注的数据对模型进行压缩并迁移到特定任务上;
实验结果表明他们的模型对比SOTA是有很大的提升的: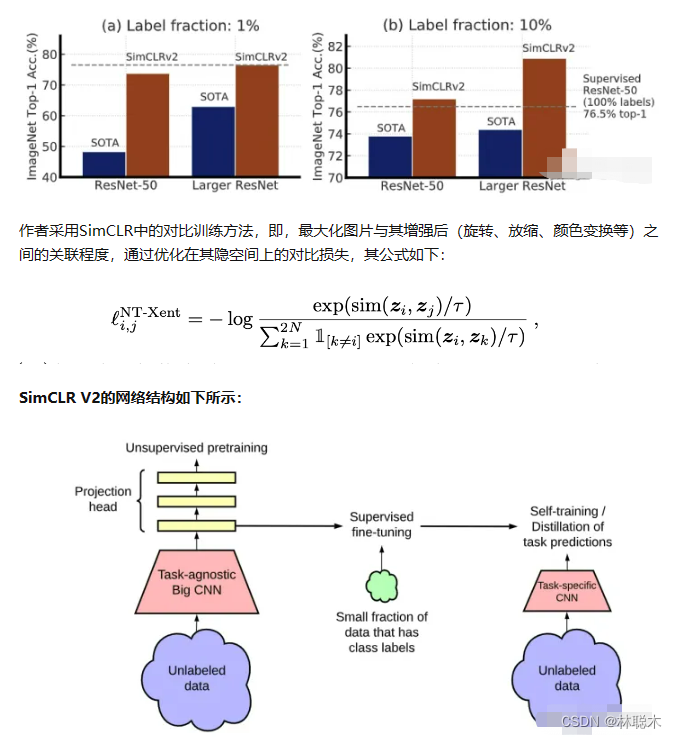
在SimCLR V2中,相比V1有一下几点改进:
- V2大大加深了网络的规模,最大的规模达到了152层的ResNet,3倍大小的通道数以及加入了SK模块(Selective Kernels),据说在1%标注数据的finetune下可以达到29%的性能提升;
- 首先V2使用了更深的projection head;其次,相比于v1在预训练完成后直接抛弃projection head,V2保留了几层用于finetune,这也是保留了一些在预训练中提取到的特征;
- 使用了一种记忆机制,设计一个记忆网络,其输出作为负样本缓存下来用以训练。
Hard Negative Mixing for Contrastive Learning
论文标题:Hard Negative Mixing for Contrastive Learning
论文方向:图像和文本领域,通过在特征空间进行 Mixup 的方式产生更难的负样本
难样本一直是对比学习的主要研究部分,扩大 batch size,使用 memory bank 都是为了得到更多的难样本,然而,增加内存或batch size并不能使得性能一直快速提升,因为更多的负样本并不一定意味着带来更难的负样本。于是,作者通过Mixup的方式来产生更难的负样本。该文章对这类问题做了详尽的实验,感兴趣的可以阅读原论文。
Supervised Contrastive Learning
论文标题:Supervised Contrastive Learning
论文方向:提出了监督对比损失(Google出品,必属精品)
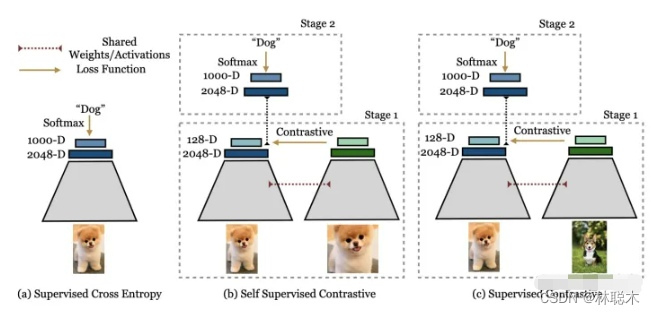
有监督方法vs自监督方法的对比损失:
- supervised contrastive loss(左),将一类的positive与其他类的negative进行对比(因为提供了标签), 来自同一类别的图像被映射到低维超球面中的附近点。
- self-supervised contrastive loss(右),未提供标签。因此,positive是通过作为给定样本的数据增强生成的,negative是batch中随机采样的。这可能会导致false negative(如右下所示),可能无法正确映射,导致学习到的映射效果更差。
论文核心点:
- 其基于目前常用的contrastive loss提出的新的loss,(但是这实际上并不是新的loss,不是取代cross entropy的新loss,更准确地说是一个新的训练方式)contrastive loss包括两个方面:一是positive pair, 来自同一个训练样本 通过数据增强等操作 得到的两个feature构成, 这两个feature会越来越接近;二是negative pair, 来自不同训练样本的 两个feature 构成, 这两个feature 会越来越远离。 本文不同之处在于对一个训练样本(文中的anchor)考虑了多对positive pair,原来的contrastive learning 只考虑一个。
- 其核心方法是两阶段的训练。如上图所示。 从左向右分别是监督学习,自监督对比学习,和本文的监督对比学习。 其第一阶段: 通过已知的label来构建contrastive loss中的positive 和negative pair。 因为有label,所以negative pair 不会有false negative(见图1解释)。 其第二阶段: 冻结主干网络,只用正常的监督学习方法,也就是cross entropy 训练最后的分类层FC layer。
实验方面,主要在ImageNet上进行了实验,通过accuracy验证其分类性能,通过common image corruption 验证其鲁棒性。
Contrastive Learning with Adversarial Examples
论文标题:Contrastive Learning with Adversarial Examples
论文方向:对抗样本+对比学习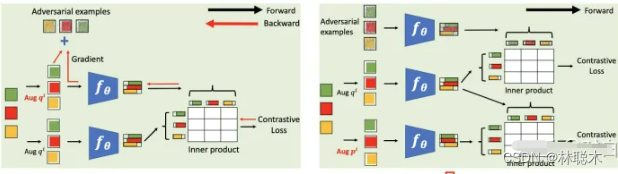
本文在标准对比学习的框架中,引入了对抗样本作为一种数据增强的手段,具体做法为在标准对比损失函数基础上,额外添加了对抗对比损失作为正则项,从而提升了对比学习基线的性能。简单来说,给定数据增强后的样本,根据对比损失计算对该样本的梯度,然后利用 FGSM (Fast Gradient Sign Method)生成相应的对抗样本,最后的对比损失由两个项构成,第一项为标准对比损失(两组随机增强的样本对),第二项为对抗对比损失(一组随机增强的样本以及它们的对抗样本),两项的重要性可指定超参数进行调节。
LoCo
论文标题:LoCo: Local Contrastive Representation Learning
论文方向:利用对比学习对网络进行各层训练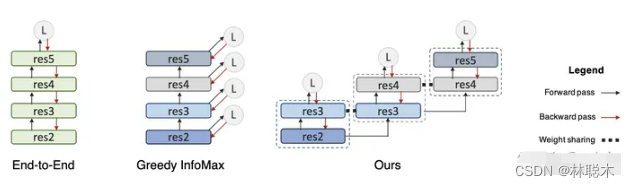
上图左边,展示了一个使用反向传播的常规端到端网络,其中每个矩形表示一个下采样阶段。在中间,是一个GIM,其中在每个阶级的末尾加上一个infoNCE损失,但是梯度不会从上一级流回到下一级。编码器早期的感受野可能太小,无法有效解决对比学习问题。由于相同的infoNCE损失被应用于所有的局部学习块(包括早期和晚期),早期阶段的解码器由于感受野有限,很难得到表征进行正确的区分正样本。例如,在第一阶段,我们需要在特征图上使用 56×56 的核执行全局平均池化,然后将其发送到解码器(非线性全连接)进行分类。
我们可以在解码器中加入卷积层来扩大感受野。然而,这种增加并没有对端到端的simclr产生影响,因为最后阶段的感受野足够很大。其实,通过在局部阶段之间共享重叠级,就我们可以有效地使解码器的感受野变大,而不会在前向传递中引入额外的成本,同时解决了文中描述的两个问题。
What Makes for Good Views for Contrastive Learning?
论文标题:What Makes for Good Views for Contrastive Learning?
论文方向:提出InfoMin假设,探究对比学习有效的原因(Google出品,必属精品)
首先作者提出了三个假设:
- Sufficient Encoder
- Minimal Sufficient Encoder
- Optimal Representation of a Task
其次,作者举了一个非常有趣的例子,如下图所示: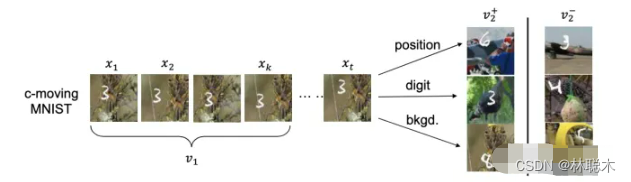
数字, 在某个随机背景上以一定速度移动, 这个数据集有三个要素:
- 数字
- 数字的位置
- 背景
左边的v1即为普通的view, 右边v2+是对应的正样本, 所构成的三组正样本对分别共享了数字、数字的位置和背景三个信息,其余两个要素均是随机选择,故正样本也仅共享了对应要素的信息. 负样本对的各要素均是随机选择的。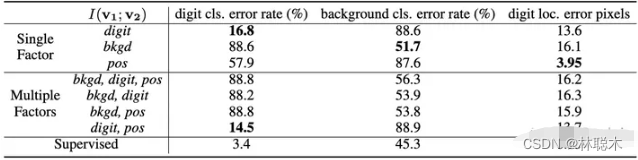
实验结果如上表,如果像文中所表述的,正样本对仅关注某一个要素, 则用于下游任务(即判别对应的元素,如判别出数字,判别出背景, 判别出数字的位置),当我们关注哪个要素的时候, 哪个要素的下游任务的效果就能有明显提升(注意数字越小越好)。
本文又额外做了同时关注多个要素的实验, 实验效果却并不理想, 往往是背景这种更为明显,更占据主导的地位的共享信息会被对比损失所关注。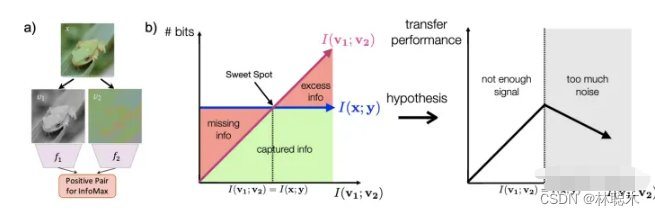
作者紧接着, 提出了一些构造 novel views 的办法。 正如前面已经提到过的, novel views v1,v2应当是二者仅共享一些与下游任务有关的信息, 抓住这个核心。这样会形成一个U型,最高点定义为甜点,我们的目标就是让两个视图的信息能够刚好达到甜点,不多不少,只学到特定的特征。
GraphCL
论文标题:Graph Contrastive Learning with Augmentations
论文方向:图+对比学习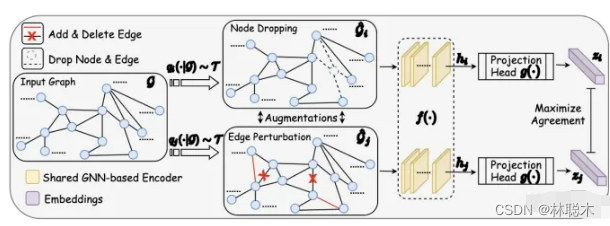
如上图所示,通过潜在空间中的对比损失来最大化同一图的两个扩充view之间的一致性,来进行预训练。
在本文中,作者针对GNN预训练开发了具有增强功能的对比学习,以解决图数据的异质性问题。
- 由于数据增强是进行对比学习的前提,但在图数据中却未得到充分研究,因此本文首先设计四种类型的图数据增强,每种类型都强加了一定的先于图数据,并针对程度和范围进行了参数化;
- 利用不同的增强手段获得相关view,提出了一种用于GNN预训练的新颖的图对比学习框架(GraphCL),以便可以针对各种图结构数据学习不依赖于扰动的表示形式;
- 证明了GraphCL实际上执行了互信息最大化,并且在GraphCL和最近提出的对比学习方法之间建立了联系;
- 证明了GraphCL可以被重写为一个通用框架,从而统一了一系列基于图结构数据的对比学习方法;
- 评估在各种类型的数据集上对比不同扩充的性能,揭示性能的基本原理,并为采用特定数据集的框架提供指导;
- GraphCL在半监督学习,无监督表示学习和迁移学习的设置中达到了最佳的性能,此外还增强了抵抗常见对抗攻击的鲁棒性。
ContraGAN
论文标题:ContraGAN: Contrastive Learning for Conditional Image Generation
论文方向:条件图像生成领域
本文的方法是:判别器的大致结构和projGAN类似,首先输入图片x经过特征提取器D,得到特征向量;然后分两个分支,一个用于对抗损失判断图片是否真实,一个用于将特征经过一个projection head h 变成一个维度为k的向量(这个D+h的过程称为)。对于图片的类别,经过一个类别emmbeddinge变成一个也是维度为k的向量。
损失函数也是infoNCE loss 只不过使用类标签的嵌入作为相似,而不是使用数据扩充。
这样,就拉近图片和其类别的距离,同时拉近相同类别的图片的距离。
对比学习已广泛应用在AI各个领域中,且作为自监督学习中的代表,效果甚至已经超越了很多有监督学习任务。很多互联网公司内部其实都有许许多多这样的业务需要大量人力进行标注,AI才能进行训练,从而得到一个不错的效果(无监督一般不敢上),而有了对比学习这个思想后,既能降本又能增效,AI炼丹师们终于可以开心的得到一个更好的效果,实现”技术有深度,业务有产出“这样的目标。
算法拓展
多层次对比学习的跨模态检索
当前主流的视频文本检索模型基本上都采用了基于 Transformer[1] 的多模态学习框架,主要可以分成 3 类:
- Two-stream,文本和视觉信息分别通过独立的 Vision Transformer 和 Text Transformer,然后在多模态 Transformer 中融合,代表方法例如 ViLBERT[2]、LXMERT[3] 等。
- Single-stream,文本和视觉信息只通过一个多模态 Transformer 进行融合,代表方法例如 VisualBERT[4]、Unicoder-VL[5] 等。
- Dual-stream,文本和视觉信息仅仅分别通过独立的 Vision Transformer 和 Text Transformer,代表方法例如 COOT[6]、T2VLAD[7] 等。
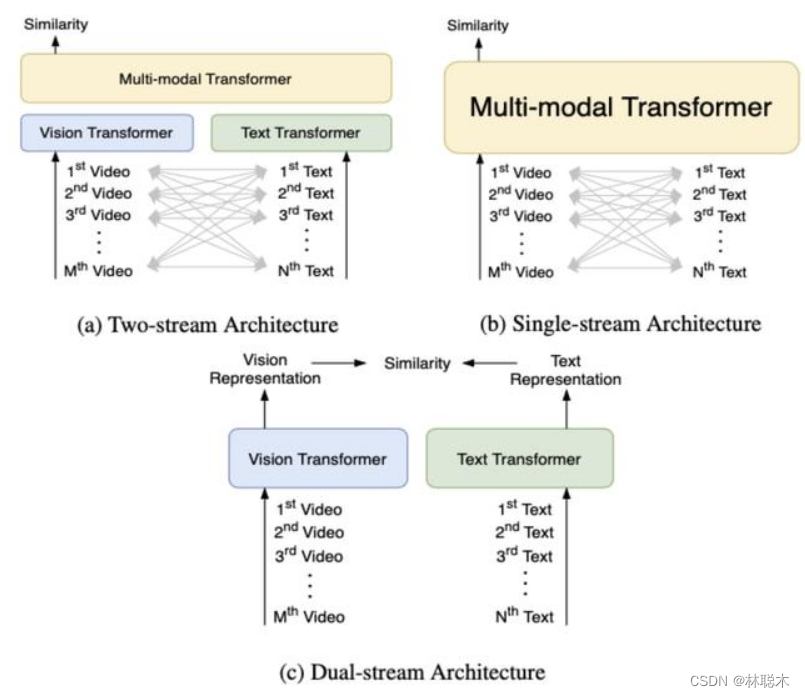
由于类别 1 和类别 2 方法在时间开销上的限制,本文提出的 HiT( Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval)[8] 模型采用了类别 3 Dual-stream 的 Transformer 框架,以满足大规模视频文本检索的需求。然而现有基于 Transformer 的多模态学习方法会有两个局限性:
- Transformer 不同网络层的输出具有不同层次的特性,而现有方法并没有充分利用这一特性;
- 端到端模型受到显存容量的限制,无法在一个 batch 内利用较多的负样本。
针对上述 2 个局限,本文提出(1)层次跨模态对比匹配(Hierarchical Cross-modal Contrast Matching,HCM),对 Transformer 的底层网络和高层网络分别进行对比匹配,解决局限 1 的问题;(2)引入 MoCo[9] 的动量更新机制到跨模态对比匹配中,使跨模态对比匹配的过程中能充分利用更多的负样本,解决局限 2 的问题。实验表明 HiT 在多个视频-文本检索数据集上取得 SOTA 的效果。
HiT 模型主要有两个创新点:
- 提出层次跨模态对比匹配 HCM。Transformer 的底层和高层侧重编码不同层次的信息,以文本输入和 BERT[10] 模型为例,底层 Transformer 侧重于编码相对简单的基本语法信息,而高层 Transformer 则侧重于编码相对复杂的高级语义信息。因此使用 HCM 进行多次对比匹配,可以利用 Transformer 这一层次特性,从而得到更好的视频文本检索性能;
- 引入 MoCo 的动量更新机制到跨模态对比匹配中,提出动量跨模态对比 MCC。MCC 为文本信息和视觉信息分别维护了一个容量很大并且表征一致的负样本队列,从而克服端到端训练方法受到显存容量的限制,只能在一个相对较小的 batch 内寻找负样本这一缺点,利用更多的负例,从而得到更好的视频和文本表征。
方法
HiT 模型整体流程如图所示。输入视频经过视频编码器,输入文本经过文本编码器,然后在 2 种网络层级(特征底层、语义高层)上分别使用 2 种检索方式(文本检索视频、视频检索文本)共完成 4 次跨模态对比匹配。其中编码器都是基于 Transformer 结构,4 次跨模态对比匹配均使用上文提到的 MCC,构建了 4 个负样本队列和对应基于动量更新的 Key 编码器。
编码器
本文提出的 HiT 模型中,编码器有视频编码器和文本编码器两种,视频编码器采用 4 层 Transformer 结构,文本编码器采用 12 层 Transformer 结构。模型的视觉输入包括视觉特征Embedding、视觉Segment Mask、Position Embedding和Expert Embedding。抽取视频编码器的第一层输出作为视频低层特征,最后一层的输出作为视频高层特征。后文有实验对比选取不同的网络层输出对最终结果的影响。
动量跨模态对比(MCC)
现有的端到端多模态学习方法受到显存容量的限制,在参数更新的过程中,只能在当前 batch 内选取很少的负样本进行交互,如果能在这一过程中加入更多的负样本参与计算,对模型得到更好的视频和文本表征是有帮助的。因此,本文引入 MoCo 的动量更新机制到 HiT 模型中。
以特征层的对比匹配为例,如下图所示,对视频和文本分别构建负样本队列,对应图中的 Memory Bank,Memory Bank 中存储的表征来自于 Key 编码器。在特征层共进行了两次对比匹配:(1)文本 Query 编码器与视觉 Memory Bank 对比匹配(2)视觉 Query 编码器与文本 Memory Bank 对比匹配。在参数更新的过程中,Query 编码器的参数通过梯度下降更新,文本 Key 编码器的参数基于文本 Query 编码器的参数进行动量更新,视觉 Key 编码器的参数基于视觉 Query 编码器的参数进行动量更新。
与单模态的 MoCo 只维护两个相同结构的编码器不同,本文提出的 MCC 为视觉信息和文本信息分别构建了不同结构的编码器,并设计了新颖的参数更新方式,解决不同模态信息之间由于模态差异而带来的难以优化的问题。
层次跨模态对比匹配(HCM)
对于一般的特征提取网络,底层结构偏向于提取输入信息的低层特征,例如输入文本的基本语法结构;高层网络结构则偏向于提取高层特征,例如输入文本的语义信息。基于这个特点,本文提出层次跨模态对比匹配,让视频-文本分别在特征和语义两个层次上进行两次对比匹配,如下图所示。模型共完成 4 次跨模态对比匹配,分别对应 2 个网络层级(特征层,语义层)和 2 种检索方式(文本检索视频、视频检索文本)。每次对比匹配使用 InfoNCE 作为损失函数,因此最终损失函数是 4 个 InfoNCE 的加权求和,本文中权重超参数均设置为 1。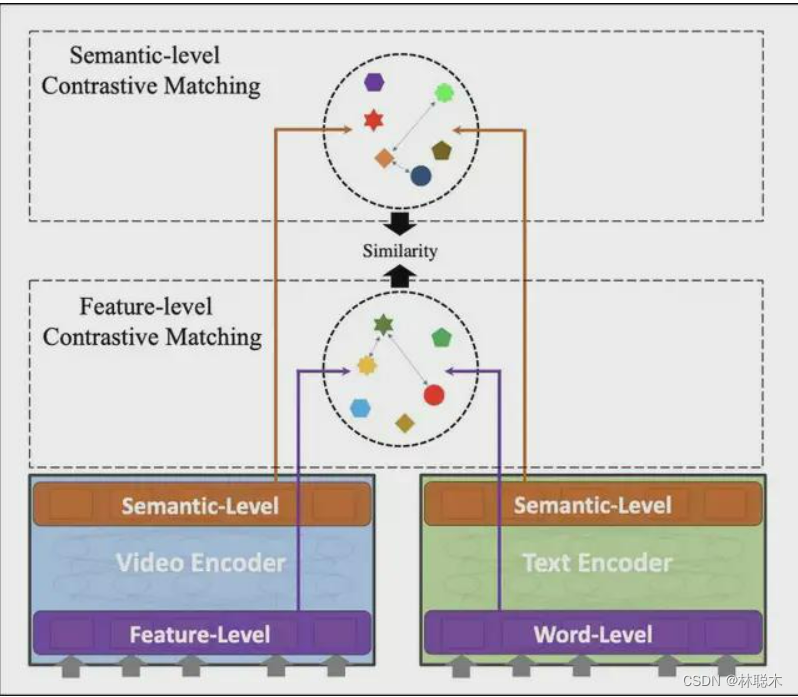
实验
研究进行了消融实验,验证提出的各个模型组件、以及不同参数值对最终结果的影响。
模型在 MSR-VTT、ActivityNet Captions 和 LSMDC 数据上与其他方法的对比:
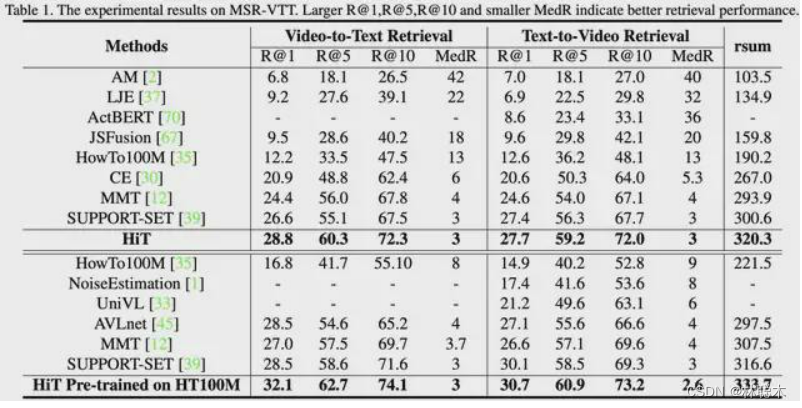

验证 MCC 的作用,模型使用 MCC、使用不同参数的 MCC 对最终结果的影响。可以看出使用 MCC 的 rsum 结果都优于未使用 MCC 的模型,并且较为有趣的是,随着负样本队列 Memory Bank 容量的增大,rsum 结果先提升后下降,由此可以看出,Memory Bank 的容量不宜设置太大。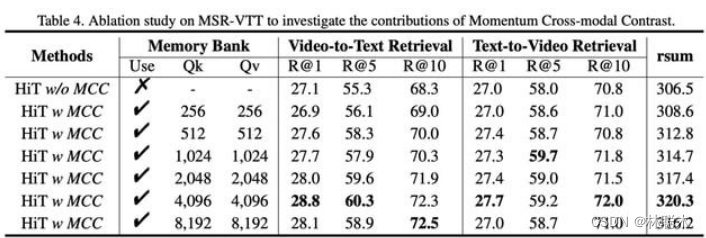
应用场景
半监督学习
当我们的标签很少,或者很难获得特定任务(即临床注释)的标签时,我们希望能够同时使用标记数据和未标记数据来优化模型的性能和学习能力。这就是半监督学习的定义。
一种在文献中得到广泛关注的方法是无监督的预训练、有监督的微调、知识蒸馏范式(knowledge distillation paradigm)。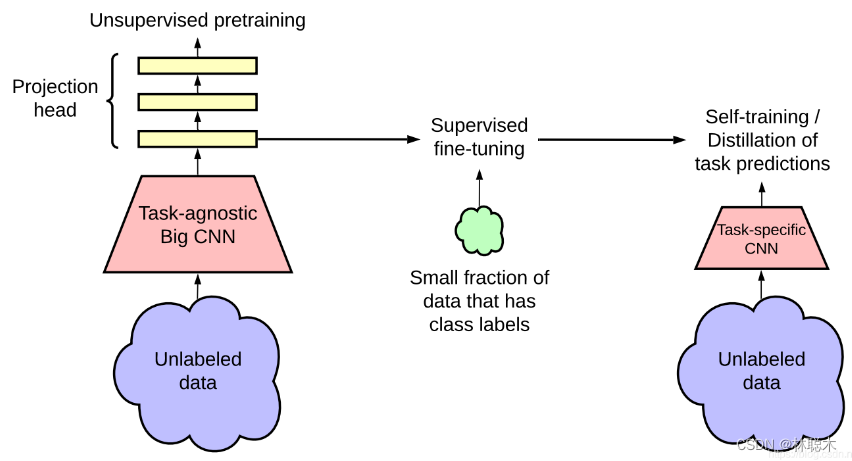
在这个范式中,自监督对比学习方法是一个关键的“预处理”步骤,它允许 Big CNN 模型(即 ResNet-152)在尝试使用有限的标记的图像对图像进行分类之前首先从未标记的数据中学习一般特征数据。
Google Brain 团队证明,这种半监督学习方法的label-efficient非常高,并且更大的模型可以带来更大的改进,尤其是对于低标签分数。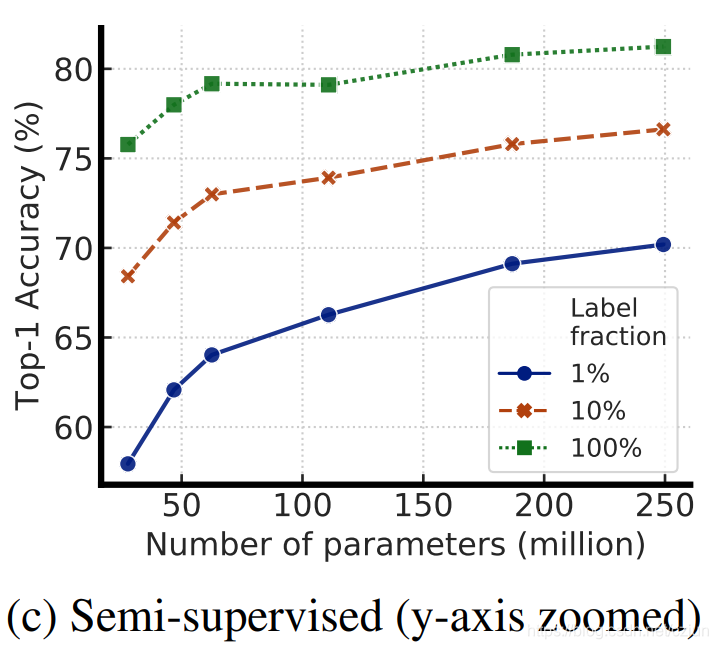
- 对比学习是一种自监督的、与任务无关的深度学习技术,它允许模型学习数据,即使没有标签。
- 该模型通过学习哪些类型的图像相似,哪些不同,来学习数据集的一般特征。
- SimCLRv2是对比学习方法的一个例子,它学习如何表示图像,使得相似的图像具有相似的表示,从而允许模型学习如何区分图像。
- 当标签稀缺时,对数据有一般理解的预训练模型可以针对特定任务进行微调,例如图像分类,以显着提高标签效率,并有可能超越监督方法。