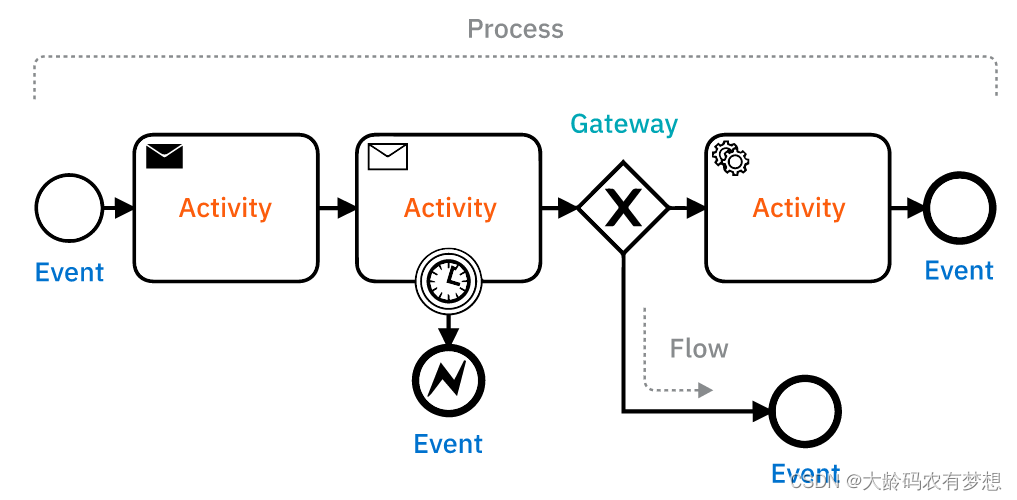
结构速览
- 论文速读
- 解决什么问题
- 解决这个问题的几个关键点
- 总体架构上面提出了哪些创新
- 如何实现蛙跳
- 如何处理轨迹表达和训练问题
- 0.Abstract
- 1. Introduction
- 第一段(介绍轨迹预测这个研究方向)
- 第二段(前人未来轨迹预测方面的研究有哪些)
- 第三段()
- 2. Related Work
- 2.1Trajectory prediction.
- 3. Background
- 3.1. Problem Formulation
- 第一段
- 第二段(因为未来的可能性多种多样,这里的任务一般会被扩增为预测多种可能)
- 3.2. Diffusion Model for Trajectory Prediction
- 第一段(简单介绍这里的内容和本文研究内容的关系)
- 第二三段(介绍扩散过程,目前看和正常的扩散模型类似)
- 第四段(扩散模型预测阶段太慢了,作者以此引出自己的研究)
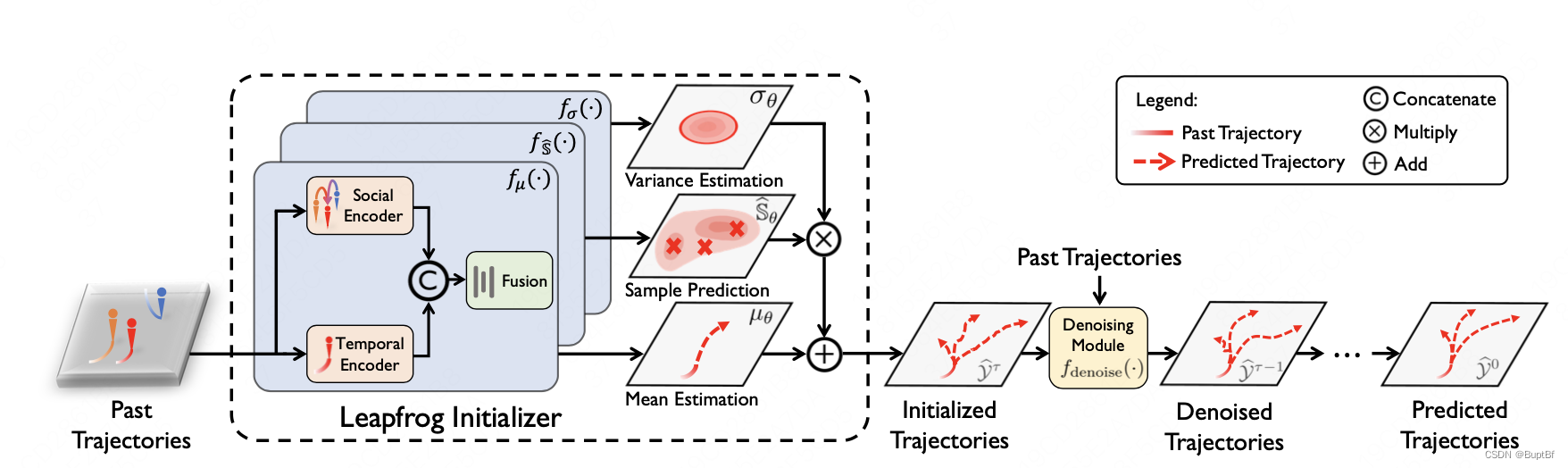
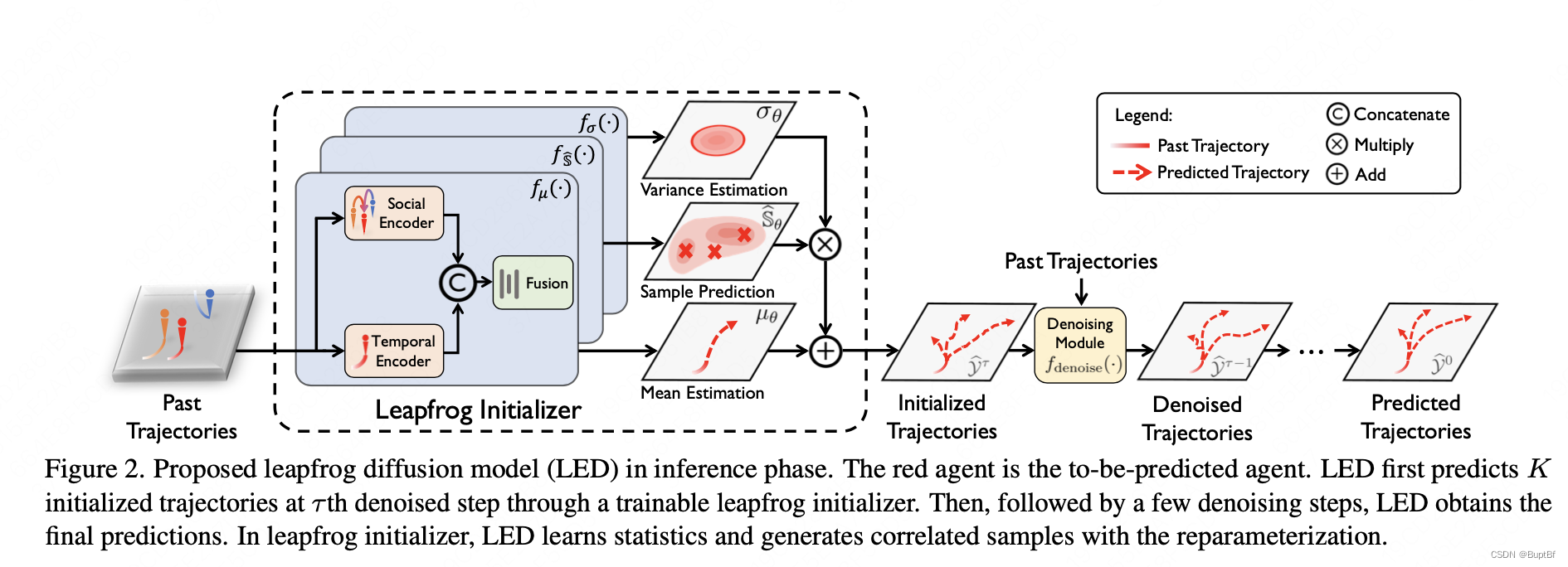
- 4. Leapfrog Diffusion Model
- 4.1. System Architecture
- 4.2. Leapfrog Initializer 蛙跳初始化器
- 第一段(讲述跳跃预测的方案)
- 第二段(详细分析各个模型的功能)
- 第三段(从理论上分析这样做的好处)
- 第四段(介绍网络具体设置)
- 4.3. Denoising Module
- 第一段(介绍降燥模型的设计逻辑)
- 4.4. Training Objective
- 第一段(作者在训练的过程中分成两个阶段,一个阶段训练扩散模型,另外一个阶段训练跳步,这样的训练为了避免不稳定训练,也就是两个都在变,那就没法训练了。)
- 第二段(讲扩散模型的训练)
- 第三段(讲蛙跳初始化怎么训练的)
- 第四段(讲述为什么不直接训练蛙跳)
- 4.5. Inference Phase 推段阶段
- 讲述推断阶段(就是先蛙跳,再扩散,没有太多内容)
论文速读
CVPR2023
暂时没有上传的开源代码:https://github.com/mediabrain-sjtu/led
解决什么问题
解决实时性问题,扩散模型用在扩散生成当中,虽然取得了很好的预测效果,但是由于扩散模型预测阶段耗时高,影响了未来轨迹预测的实时性。因此作者采用蛙跳的方式加速这个过程。
解决这个问题的几个关键点
总体架构上面提出了哪些创新
直接使用一个网络跳过扩散模型开始的步骤,并且这个跳过的步骤还比较特殊,跳出的结果直接就是一个轨迹集合了。
这里作者说了三个关键点:
1)这里初始跳跃的时候将直接跳过了噪声到轨迹,跳跃的结果就是一些轨迹,之后再从这些轨迹开始扩散;
2)这种方法可以在预测的过程中让输出的这些K个轨迹彼此之间有感知,知道对方是什么情况。
3)作者设计的跳跃扩散模型和普通的扩散模型,都具有最后的逐步降燥的过程,保证了生成数据的质量。
如何实现蛙跳
直接使用蛙跳进行
如何处理轨迹表达和训练问题
0.Abstract
To model the indeterminacy of human behaviors, stochastic trajectory prediction requires a sophisticated multi-modal distribution of future trajectories. Emerging diffusion models have revealed their tremendous representation capacities in numerous generation tasks, showing potential for stochastic trajectory prediction. However, expensive time consumption prevents diffusion models from real-time prediction, since a large number of denoising steps are required to assure sufficient representation ability. To resolve the dilemma, we present LEapfrog Diffusion model (LED), a novel diffusion- based trajectory prediction model, which provides real-time, precise, and diverse predictions. The core of the proposed LED is to leverage a trainable leapfrog initializer to directly learn an expressive multi-modal distribution of future trajectories, which skips a large number of denoising steps, significantly accelerating inference speed. Moreover, the leapfrog initializer is trained to appropriately allocate correlated samples to provide a diversity of predicted future trajectories, significantly improving prediction performances. Extensive experiments on four real-world datasets, including NBA/NFL/SDD/ETH-UCY, show that LED consistently improves performance and achieves 23.7%/21.9% ADE/FDE improvement on NFL. The proposed LED also speeds up the inference 19.3/30.8/24.3/25.1 times compared to the standard diffusion model on NBA/NFL/SDD/ETH-UCY, satisfying real-time inference needs. Code is available at https: //github.com/MediaBrain-SJTU/LED.
为了模拟人类行为的不定性,随机轨迹预测需要对未来轨迹进行复杂的多模式分布建模。新兴的扩散模型在多种生成任务中展示了巨大的表示能力,显示出对随机轨迹预测的潜力。然而,由于确保足够的表示能力需要大量的去噪步骤,因此扩散模型难以实现实时预测。为了解决这个困境,我们提出了 LEapfrog Diffusion 模型 (LED),这是一种基于扩散的新颖轨迹预测模型,能够提供实时、精确和多样化的预测。LED 的核心在于利用可训练的 leapfrog 初始化器直接学习未来轨迹的表达能力多模式分布,从而跳过大量的去噪步骤,显著加速推断速度。此外,leapfrog 初始化器被训练为适当地分配相关样本,以提供预测的未来轨迹的多样性,显著提高预测性能。在包括 NBA/NFL/SDD/ETH-UCY 四个真实数据集的广泛实验中表明,LED 持续稳定地提高性能,在 NFL 数据集上实现了 23.7%/21.9% 的 ADE/FDE 改进。提出的 LED 还与标准扩散模型相比,在 NBA/NFL/SDD/ETH-UCY 上加速推断 19.3/30.8/24.3/25.1 倍,满足了实时推断需求。代码可在 https://github.com/MediaBrain-SJTU/LED 上获得。
1. Introduction
第一段(介绍轨迹预测这个研究方向)
Trajectory prediction aims to predict the future trajectories for one or multiple interacting agents conditioned on their past movements. This task plays a significant role in numerous applications, such as autonomous driving [5, 24], drones [11], surveillance systems [46], human-robot interaction systems [6], and interactive robotics [21, 26]. Recently, lots of fascinating research progresses have been made from many aspects, including temporal encoding [7, 14, 47, 54], interaction modeling [1, 16, 19, 44, 50], and rasterized pre- diction [12, 13, 27, 49, 55]. In practice, to capture multiple possibilities of future trajectories, a real-world prediction system needs to produce multiple future trajectories. This leads to the emergence of stochastic trajectory prediction, aiming to precisely model the distribution of future trajectories.
轨迹预测旨在根据过去运动的条件预测一个或多个相互作用代理的未来轨迹。这个任务在许多应用中发挥着重要作用,例如自动驾驶 [5,24],无人机 [11],监控系统 [46],人类 - 机器人交互系统 [6],和交互机器人 [21,26]。最近,从多个方面取得了许多有趣的研究成果,包括时间编码 [7,14,47,54],相互作用建模 [1,16,19,44,50],和栅格化预测 [12,13,27,49,55]。在实践中,为了捕捉未来轨迹的多种可能性,一个现实世界的预测系统需要生成多个未来轨迹。这导致了随机轨迹预测的出现,旨在精确地建模未来轨迹的分布。
第二段(前人未来轨迹预测方面的研究有哪些)
Previous works have proposed a series of deep generative models for stochastic trajectory prediction. For example, [16, 19] exploit the generator adversarial net- works (GANs) to model the future trajectory distribution; [28, 39, 50] consider the conditional variational auto- encoders (CVAEs) structure; and [3] uses the conditional normalizing flow to relax the Gaussian prior in CVAEs and learn more representative priors. Recently, with the great success in image generation [18, 34] and audio synthesis [4, 22], denoising diffusion probabilistic models have been applied to time-series analysis and trajectory prediction, and show promising prediction performances [15, 45]. Compared to many other generative models, diffusion models have advatages in stable training and modeling sophisticated distributions through sufficient denoising steps [9].
以前的工作已经提出了一系列深度生成模型用于随机轨迹预测。例如,[16,19] 利用生成对抗网络 (GANs) 来建模未来轨迹分布;[28,39,50] 考虑了条件变分自编码器 (CVAEs) 的结构;[3] 使用了条件归一化流来放松 CVAEs 中的高斯先验,并学习更代表性的前馈。最近,在图像生成 [18,34] 和音频合成 [4,22] 方面取得了巨大的成功,降噪扩散概率模型已被应用于时间序列分析和轨迹预测,并表现出了有前途的预测性能 [15,45]。与其他生成模型相比,扩散模型在稳定的训练和对足够的降噪步骤进行建模方面具有优势。
第三段()
However, there are two critical problems in diffusion mod- els for stochastic trajectory prediction. First, the real-time inference is time-consuming [15]. To ensure the representation ability and generate high-quality samples, an adequate number of denoising steps are required in standard diffusion models, which costs more computational time. For
2. Related Work
2.1Trajectory prediction.
Early works on trajectory prediction focus on a deterministic approach by exploring force models [17, 31], RNNs [1, 33, 48], and frequency analysis [29, 30]. For example, [17] models an agent’s behavior with attractive and repulsive forces and builds the force equations for prediction. To capture the multi-modalities and model future distribution, recent works start to focus on stochastic trajectory prediction and have proposed a series of deep generative models. Generative Adversarial Network (GAN) structures [8, 10, 16, 19, 37, 43] are proposed to generate multiple future trajectory distribution. [23, 28, 39, 50, 52] use the Variational Auto-Encoder (VAE) structure and learn the distribution through variational inference. [3] relaxes the Gaussian prior and proposes to use the normalizing flow. Heatmap [12, 13, 27] is used for modeling future trajectories’ distribution on rasterized images. In this work, we propose a new diffusion-based model for trajectory prediction. Com- pared to previous generative models, our method has a large representation capacity and can model sophisticated trajectory distributions by using a number of diffusion steps. We also enable the correlation between samples to adaptively adjust sample diversity, improving prediction performance.
早期的轨道预测工作主要集中在探索力模型 (如 [17, 31]),循环神经网络 (如 [1, 33, 48]) 和频率分析 (如 [29, 30]) 上,以采用确定性方法进行预测。例如,[17] 使用吸引力和排斥力模型来建模代理的行为,并建立力方程来进行预测。为了捕捉多模态性和建模未来分布,最近的工作开始将随机轨道预测作为重点,并提出了一系列深度生成模型。生成对抗网络 (GAN) 结构 (如 [8, 10, 16, 19, 37, 43]) 被提出用于生成多个未来的轨道分布。(如 [23, 28, 39, 50, 52]) 使用变分自编码器 (VAE) 结构并通过变分推断学习分布。(如 [3]) 提出了放松高斯先验并使用归一化流的提议。heatmap(如 [12, 13, 27]) 被用于在栅格化图像上建模未来的轨道分布。在本文中,我们提出了一种新的轨道预测基于扩散的方法。与以前的生成模型相比,我们的方法具有较大的表示能力,并可以通过使用多个扩散步骤来建模复杂的轨道分布。我们还允许样本之间的关联自适应地调整样本多样性,从而提高预测性能。
3. Background
3.1. Problem Formulation
第一段

输入包含:
1)历史上当前agent的运动轨迹(Tp,2)
2)当前agent的周围的L个人或物的历史运动轨迹(L,Tp,2)
输出包含:
预测的当前agent的运动轨迹(Tf,2)
第二段(因为未来的可能性多种多样,这里的任务一般会被扩增为预测多种可能)
Because of the indeterminacy of future trajectories, it is usually more reliable to predict more than one trajectory to capture multiple possibilities. Here we consider stochastic trajectory prediction, which predicts the distribution of a future trajectory, instead of a single future trajectory.
由于未来轨迹的不确定性质,通常更可靠的做法是预测多个轨迹以捕捉多种可能性。这里我们考虑随机轨迹预测,它预测未来轨迹的分布,而不是单个未来轨迹。

所以作者最终的任务是:
输入包含:
1)历史上当前agent的运动轨迹(Tp,2)
2)当前agent的周围的L个人或物的历史运动轨迹(L,Tp,2)
输出包含:
预测的当前agent可能的K种运动轨迹(K,Tf,2)
3.2. Diffusion Model for Trajectory Prediction
第一段(简单介绍这里的内容和本文研究内容的关系)
Here we present a standard diffusion model for trajectory prediction, which lays a foundation for the proposed method. The core idea is to learn and refine a sophisticated underly- ing distribution of trajectories through cascading a series of simple denoising steps. To implement this, a diffusion model performs a forward diffusion process to intentionally add a series of noises to a ground-truth future trajectory; and then, it uses a conditional denoising process to recover the future trajectory from noise inputs conditioned on past trajectories.
这里我们介绍一种用于轨迹预测的标准扩散模型,该模型为提出的方法奠定了基础。其核心思想是通过一组简单的去噪步骤,学习并优化复杂 underlying 轨迹分布。为了实现这一目标,扩散模型执行向前扩散过程,有意地将真实未来轨迹添加一系列噪声中;然后,它使用条件去噪过程从基于过去轨迹的噪声输入中恢复未来轨迹。
第二三段(介绍扩散过程,目前看和正常的扩散模型类似)


(这里面的ego agent 应该是翻译成自治系统,应该就是指一个独立的个体)
第2c步骤是: 使用 K 个独立且同分布的样本来初始化从正态分布中降噪的轨迹 Y。
看起来这个扩散过程和正常的扩散模型没有太大区别。
第四段(扩散模型预测阶段太慢了,作者以此引出自己的研究)
The standard diffusion model is expressively powerful in learning sophisticated distributions and has achieved great success in many generation tasks. However, the task of motion prediction requires real-time inference but the running time of a diffusion model is constrained by the large number of denoising steps. Meanwhile, less denoising steps usually cause a weaker representation ability of future distributions. To achieve higher efficiency while preserving a promising representation ability, we propose leapfrog diffusion model, which uses a trainable initializer to capture sophisticated distributions and substitute a large number of denoising steps.
标准扩散模型在学习复杂的分布方面具有表达能力,并在许多生成任务中取得了巨大成功。然而,运动预测任务需要实时推理,但扩散模型的运行时受到大量去噪步骤的限制。同时,较少的去噪步骤通常会导致未来的分布表示能力较弱。为了实现更高的效率,同时保留有潜力的表示能力,我们提出了 leapfrog 扩散模型,该模型使用可训练的初始化器来捕捉复杂的分布,并替代大量去噪步骤。
4. Leapfrog Diffusion Model
4.1. System Architecture
In this section, we propose the leapfrog diffusion model. Here leapfrog means that a large number of small denois- ing steps can be replaced by a single, yet powerful leapfrog initializer, which can significantly accelerate the inference speed without losing representation ability.
在这一节中,我们提出了 leapfrog 扩散模型。这里 leapfrog 意味着许多小型扩散步骤可以被一个强大而单一的 leapfrog 初始化器所取代,这将极大地加速推断速度,同时不会失去表示能力。


作者提出了一种直接跳跃的方式来完成这个任务,直接使用一个网络,在开始的阶段直接跳过开始的一些步骤,之后使用扩散模型完成剩下的步骤即可。

这里作者说了三个关键点:
1)这里初始跳跃的时候将直接跳过了噪声到轨迹,跳跃的结果就是一些轨迹,之后再从这些轨迹开始扩散;
2)这种方法可以在预测的过程中让输出的这些K个轨迹彼此之间有感知,知道对方是什么情况。
3)作者设计的跳跃扩散模型和普通的扩散模型,都具有最后的逐步降燥的过程,保证了生成数据的质量。
4.2. Leapfrog Initializer 蛙跳初始化器
第一段(讲述跳跃预测的方案)

作者这里说到想要直接让网络学习预测结果是比较困难的,所以作者采取了退而求其次的方案,作者采用的方案为:
- 1.预测方差和均值;
- 2.预测几个单体的标准位置内容;
具体流程如下:


也就是三个网络解决这个问题,1)均值预测网络 2)方差预测网络 3)标准位置预测网络
再通过重投影,得到跳跃结果。
第二段(详细分析各个模型的功能)

均值估计网络主要是在当前的自身历史轨迹和周围有关点的历史轨迹的情况下,预测未来预测轨迹的平均轨迹。并且这些轨迹的均值在全部的k个去噪轨迹当中共享。

方差估计网络主要是在当前的自身历史轨迹和周围历史轨迹的情况下,预测轨迹的不稳定程度,同样的这个方差也同时影响到全部的k个去噪轨迹。

单点预测轨迹则是在当前的自身历史轨迹和周围历史轨迹的情况下,并且额外加入上面预测的方差,预测单例输出。
第三段(从理论上分析这样做的好处)
Note that i) the reparameterization in Eq. (4) allows us to avoid learning a raw sophisticated distribution, making the training much easier; and ii) K normalized predictions are generated simultaneously from the same underlying feature, assuring appropriately allocated trajectories with variance estimation and better capturing the multi-modalities.
i)注意:Eq. (4) 中的重参数化可以让我们避免学习原始复杂的分布,从而使训练变得更加容易;
同时,ii) 从相同的底层特征中同时生成 K 个标准化预测,以确保具有方差估计的合适分配轨迹,更好地捕捉多模态。
第四段(介绍网络具体设置)

作者这里采用的两个网络,一个是时空挖掘网络一个是社会信息挖掘网络,挖掘两种信息,之后再用聚合网络进行聚合,作者给出了示意图:
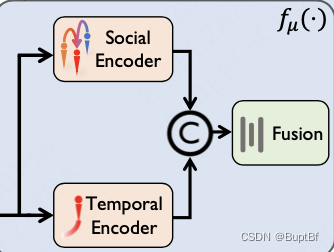
具体的可以看到这里的社会信息挖掘应该就是一个注意力机制的使用。

也就是分别给QKV使用不同的embedding层得到相同维度的数据之后计算注意力机制。
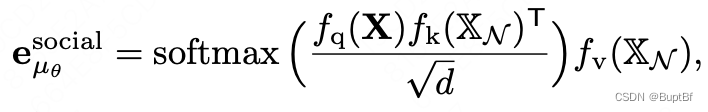
时空信息挖掘部分:大约就是使用一维卷积先进行维度扩增,之后使用GRU提取最终结果

拼接部分:看起来应该就是把他们拼接在一起之后使用线性层进行提取

上面这些事时间和社会特征的挖掘,最终的单例生成网络和他们有细小的差异:
大约就是先使用特征提取网络将其扩增到高维度特征,之后再进行融合,然后再由高维度信息进行数据生成,最终使得方差的预测结果不仅仅用在重投影数据,还会用在单例的生成当中。

4.3. Denoising Module
第一段(介绍降燥模型的设计逻辑)

这里作者主要是介绍如何完成有条件的扩散模型,主要分成三个步骤
1)首先对自身历史轨迹和周围有关点的历史轨迹进行特征提取,形成条件信息C;
2)之后在条件C和当前扩散结果以及扩散步数的信息融合下,形成下一步扩散的噪声;
3)最后使用扩散模型的推算公式进行推算。
4.4. Training Objective
第一段(作者在训练的过程中分成两个阶段,一个阶段训练扩散模型,另外一个阶段训练跳步,这样的训练为了避免不稳定训练,也就是两个都在变,那就没法训练了。)

To train a leapfrog diffusion model, we consider a two- stage training strategy, where the first stage trains a denoising module and the second stage focuses on a leapfrog initializer. The reason to use two stages is because the training of leapfrog initializer is more stable given fixed distribution P (Y τ ), avoiding non-convergent training.
要训练一个 leapfrog 扩散模型,我们考虑了一种两阶段训练策略,第一阶段训练一个去噪模块,而第二阶段则专注于 leapfrog 初始化器。使用两阶段训练的原因是因为 leapfrog 初始化器的训练在给定固定分布 P(Yτ) 的情况下更加稳定,避免非收敛训练。
第二段(讲扩散模型的训练)
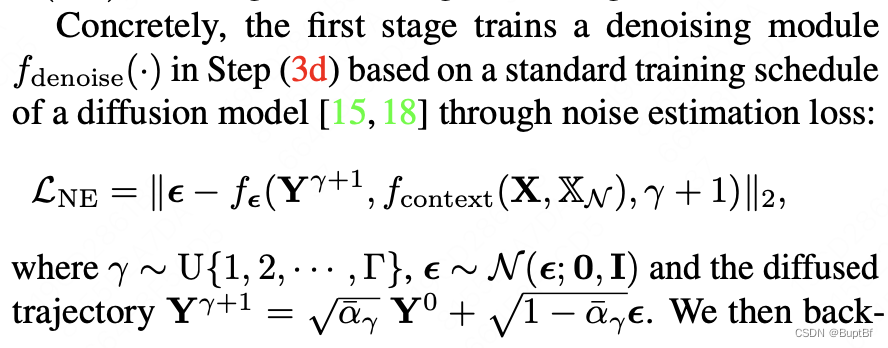

这里的扩散模型训练和正常的扩散模型训练应该是比较类似的,也是回传噪声的二范式,
训练的结果一个是条件信息提取器,一个是扩散模型的噪声预测器。
第三段(讲蛙跳初始化怎么训练的)

主要包含两个点:
- 1.蛙跳训练器训练的时候,扩散模型锁梯度不进行训练
- 2.在计算损失的时候计算两组损失的和:正常的欧式距离、去中心化的损失,并在最后加入一个log(方差),避免一个极大方差的出现。
第四段(讲述为什么不直接训练蛙跳)

4.5. Inference Phase 推段阶段
讲述推断阶段(就是先蛙跳,再扩散,没有太多内容)
During the inference, instead of the Γ-steps’ denoising, leapfrog diffusion model only takes τ-steps, accelerating the inference. To be specific, we first generate K correlated samples to model the distribution P (Y τ ) using the trained leapfrog initializer. Then, these samples will be fed into the denoising process and iteratively fine-tuned to produce the final predictions; see Algorithm 1.
在推断期间,相比于 Γ-步骤的去噪,leapfrog 扩散模型只需要 τ-步骤,从而加速推断。具体来说,我们首先使用训练好的 leapfrog 初始化器生成 K 组相互关联的样本,以模拟分布 P(Yτ)。然后,这些样本将被输入去噪过程,并迭代地进行微调,以生成最终的预测;见算法 1。


![[杂谈]从《天堂2》到永恒之塔私服的感慨](https://img-blog.csdnimg.cn/img_convert/dc69afab7fe0a37f6a745323ce5cb235.gif)
![[230509]托福听力真题TPO66|精听 Lecture2:marine biology class|9:45~11:30+12:00~12:30](https://img-blog.csdnimg.cn/53c2737715f442b0825989e8268533b3.png)





![分布式事务 [面试]](https://img-blog.csdnimg.cn/img_convert/bf251045f2ee4ff65eb19e2884b14b82.jpeg)