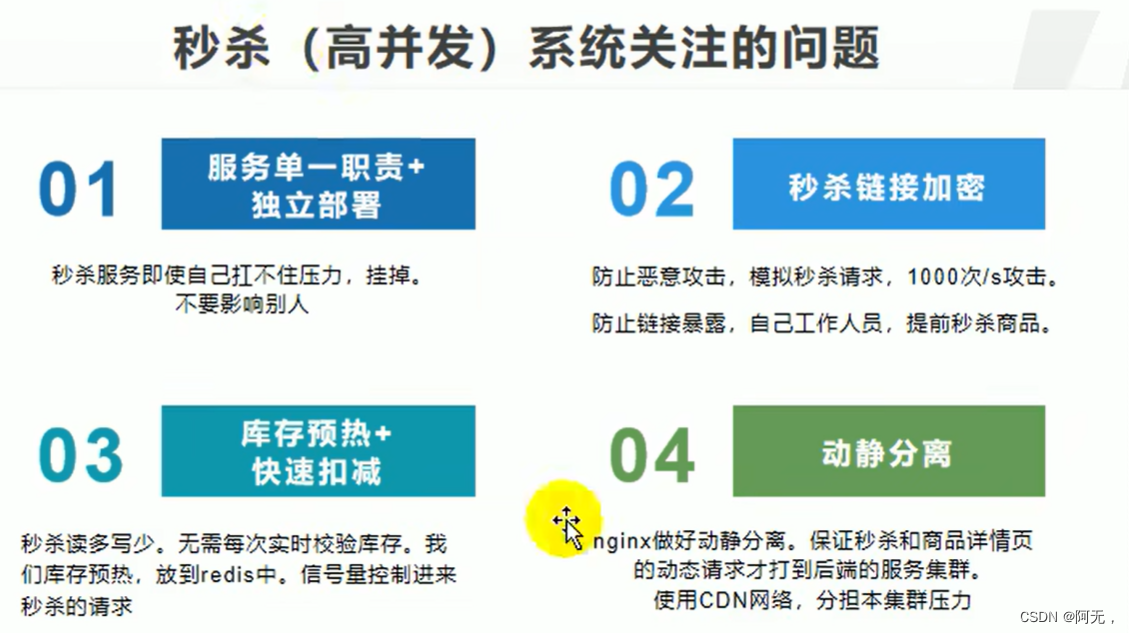

我们在秒杀服务加的以上所有手段都是为了快,除了快之外,我们还需要保证稳定。
我们即使再快也会有一个极限值,现在假设单机下每秒处理一万个单,这已经是超高的处理能力了,秒杀服务上了五台服务器,有三台掉线,但是秒杀请求网关直接放过了10w请求,全部放进来,那剩下的两台服务器就处理不过来,每台服务器的顶峰值是1w,所有的请求都得排队,排着排着就造成了请求的时间累积,时间一长,资源耗尽,服务器就要崩溃了。
所以快保证了以后,我们就需要保证稳定。
如何保证稳定,那就是在我们分布式系统中的限流&熔断&降级,我们无论哪个分布式系统,不管是不是高并发,都要考虑,因为有了这些的保护手段,我们的整个集群就可以达到稳定。
我们以前是用springCloud的hystrix,不更新了,而且支持的功能也是有限的,
在我们的系统里面,我们使用springCloud alibaba的Sentinel,来完成整个系统的限流&熔断&降级。
会把我们整个系统保护的非常稳定,即使百台服务器的大集群,有了Sentinel的保护,上线或者崩溃几台服务器,都会非常的稳定。
限流&熔断&降级
-
什么是熔断
A 服务调用 B 服务的某个功能,由于网络不稳定问题,或者 B 服务卡机,导致功能时间超长。如果这样子的次数太多。我们就可以直接将 B 断路了(A 不再请求 B 接口),凡是调用 B 的直接返回降级数据,不必等待 B 的超长执行。 这样 B 的故障问题,就不会级联影响到 A。如果没有任何保护,feign远程调用,feign有一个默认超时时间,例如是3s,3s时间如果不返回数据,就认为被调用的服务出问题了,feign接口就会报超时错误,但我们等不了这么久,因为这样就会引起整个调用链的
累积效应,
a调用b,b调用c,c方法现在要等3s,b需要等c,a需要等b,大家都需要等,就会全线卡死,资源不能得到释放,吞吐量就会下降,大量的请求又在排队,这就形成了一个死循环,能力越不行,请求累积的越多,越多的请求又需要越多的资源进行分配处理,我们的机器就会整个卡死,宕机。
所以我们需要加入熔断机制,a调用b,如果发现b不能正常返回,那以后我们直接把b进行断路,接下来a调用b不需要关注b是否成功,直接快速返回失败 -
什么是降级
整个网站处于流量高峰期,服务器压力剧增,根据当前业务情况及流量,对一些服务和页面进行有策略的降级[停止服务,所有的调用直接返回降级数据]。以此缓解服务器资源的的压力,以保证核心业务的正常运行,同时也保持了客户和大部分客户的得到正确的相应。 -
异同
-
相同点
- 为了保证集群大部分服务的可用性和可靠性,防止崩溃,牺牲小我
- 用户最终都是体验到某个功能不可用
-
不同点:
- 熔断是被调用方故障,触发的系统主动规则
- 降级是基于全局考虑,停止一些正常服务,释放资源
-
-
什么是限流
对打入服务的请求流量进行控制,使服务能够承担不超过自己能力的流量压力
每次和学校谈话结束,苏迎澜就第一时间分享给小逸,“过来,我和你汇报下工作”。她省略了具体谈判的过程,以一个孩子能理解的语言把事情总结出来。
https://baijiahao.baidu.com/s?id=1760481532554271247
一个妈妈的反校园暴力“战斗”




![[架构之路-188]-《软考-系统分析师》-3-操作系统 - 图解页面替换算法LRU、LFU](https://img-blog.csdnimg.cn/af6b34e6092948f08e78ebfcf93ba33f.jpeg)