1、TCP 和 UDP 协议有什么区别,分别适用于什么场景?
TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)是两种常用的传输层协议,两者的区别比较如下:
| TCP | UDP | |
|---|---|---|
| 可靠性 | 可靠 | 不可靠 |
| 连接性 | 面向链接 | 无连接 |
| 报文 | 面向字节流 | 面向报文 |
| 效率 | 传输效率低 | 传输效率高 |
| 安全性 | 容易被攻击、安全性不如UDP | 也会被攻击,相对TCP来说安全 |
| 可靠性 | 可靠,无差错、不丢失、不重复有序的传输 | 不可靠传输,不保证传输有序性 |
| 双工性 | 全双工 | 一对一、一对多、多对一、多对多 |
| 流量控制 | 滑动窗口 | 无 |
| 拥塞控制 | 慢开始、拥塞避免、快重传、快恢复 | 无 |
| 传输速度 | 慢 | 快 |
| 应用场景 | 对效率要求低,对准确性要求高或要求有链接的场景 | 对效率要求高、对准确性要求低 |
TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)是两种常用的传输层协议,它们有以下的区别:
1、连接方面
TCP 是面向连接的协议,而 UDP 是无连接的协议。在 TCP 中,发送方和接收方必须先建立连接,然后才能传输数据。UDP 则不需要建立连接,直接发送数据即可。
2、可靠性 TCP 保证数据传输的可靠性,通过序列号、确认应答和重传机制等方式来保证数据的完整性和正确性。UDP 则不保证数据传输的可靠性,因为它不提供确认和重传机制。
3、传输速度 因为 TCP 要保证数据传输的可靠性,所以在传输速度方面相对较慢。而 UDP 则不需要进行复杂的传输控制,因此传输速度更快。
4、传输内容 TCP 是一种面向字节流的协议,将数据看作是一连串的字节流,没有明确的消息边界。UDP 则是面向报文的协议,将数据看作是一系列的报文,每个报文是一个独立的单元,具有明确的消息边界。
基于以上的特点,TCP 和 UDP 适用于不同的场景。TCP 适用于对传输可靠性要求比较高的场景,例如网页浏览、文件传输、邮件等。而 UDP 则适用于对传输可靠性要求较低、传输速度要求较高的场景,例如在线游戏、视频直播等。
TCP 用于在传输层有必要实现可靠传输的情况;而在一方面,UDP 主要用于那些对高速传输和实时性有较高要求的通信或广播通信。TCP 和 UDP 应该根据应用的目的按需使用。
2、如何用 Redis 实现分布式 Session?
回答一:
通过redis中的hash来实现,将token的值作为键,他里面的每一个字段对应着,用户相关的信息,当用户第一次登陆的时候就会生成一个token,在用户下次登陆的时候就会请求头中携带这个token,后端通过校验请求头的token在redis中是否存在,如果存在就直接返回用户的信息,不存在就直接跳转登录页,这个token可以使用uuid的形式来生成避免重复,以及被窃取的风险
回答二:
在分布式系统中,通常会将 Session 存储在 Redis 中来实现分布式 Session,这样就可以在多台服务器之间共享 Session 数据。实现分布式 Session 的方式有多种,其中一种常用的方式是使用 Redis 的数据结构 Hash。具体实现步骤如下:
- 在用户登录成功后,将 Session 数据存储在 Redis 中。
- 将 Redis 中的 Session 数据的 Key 设置为一个全局唯一的 ID,一般使用类似于“session:token”这样的格式,其中 token 是一个随机生成的字符串,用来标识这个 Session 数据。
- 在客户端返回响应的同时,将 Session ID(即 token)以 Cookie 的形式返回给客户端。客户端在后续的请求中都会携带这个 Cookie。
- 在后续的请求中,服务器会从客户端传递过来的 Cookie 中获取 Session ID,然后根据这个 ID 从 Redis 中获取对应的 Session 数据。如果 Redis 中没有找到对应的 Session 数据,那么就表示这个请求无法通过认证。
- 在用户退出登录或 Session 失效时,需要将 Redis 中的对应 Session 数据删除。
可以使用 Redis 的 EXPIRE 命令来设置 Session 数据的过期时间,这样可以自动删除已经过期的 Session 数据。同时,还需要注意保护 Redis 中的 Session 数据不被恶意攻击者窃取,一般可以通过设置 Session 数据的前缀和使用随机的 Session ID 等方式来提高安全性。
回答三:
在分布式系统中,为了保持用户的登录状态,需要使用Session来记录用户信息,但是单机的Session无法满足高并发和负载均衡的需求。Redis可以通过集群、主从复制等技术实现分布式Session,具体实现方式如下:
- 选择一个集中式的缓存服务器(如Redis),将Session信息存储到缓存服务器中。这里可以使用Redis的Hash数据结构存储Session信息,使用Session ID作为Hash的Key,Session对象作为Hash的Value。
- 为了保证Session的有效性,需要给Session设置一个过期时间。在Redis中,可以通过设置Hash的expire时间来实现Session过期。一般情况下,Session过期时间设置为30分钟或者1个小时。
- 在客户端请求到达应用服务器时,应用服务器会读取Session ID,并通过Session ID从缓存服务器中读取Session信息。如果Session已过期,则需要重新生成一个Session ID,并重新创建一个新的Session信息。
- 为了提高性能,可以在应用服务器本地缓存一份Session信息。当应用服务器需要读取Session信息时,先从本地缓存中读取,如果本地缓存中不存在,则从缓存服务器中读取,并将Session信息保存到本地缓存中。这样可以减少对缓存服务器的访问,提高系统性能。
- 在多台应用服务器上部署同一个应用程序时,需要保证Session的一致性。可以使用Redis的集群或主从复制功能来实现Session的共享。
回答四:
在分布式系统中为了保证用户的登陆态,我们会把用户的登录信息存储在「session」里。而session是依赖于「cookie」的,即服务器创建session时会给它分配一个唯一的ID,并且在响应时创建一个cookie用于存储这个「sessionId」。当客户端收到这个cookie之后,就会自动保存这个sessionId,并且在下次访问时自动携带这个sessionId,届时服务器就可以通过这个sessionId得到与之对应的session,从而识别用户的身。
- 第一是「创建令牌(key)」的程序,就是在用户初次访问服务器时,给它创建一个「唯一的身份标识」,并且使用cookie封装这个标识再发送给客户端。那么当客户端下次再访问服务器时,就会自动携带这个身份标识了,这和sessionId的道理是一样的,只是改由我们自己来实现了。另外,在返回令牌之前,我们需要将它存储起来,以便于后续的验证。而这个令牌是不能保存在服务器本地的,因为其他服务器无法访问它。因此,我们可以将其存储在服务器之外的一个地方,那么Redis便是一个理想的场所。
- 第二是「验证令牌」的程序,就是在用户再次访问服务器时,我们获取到了它之前的身份标识,那么我们就要验证一下这个标识是否存在了。验证的过程很简单,我们从Redis中尝试获取一下就可以知道结果。
3、什么是分布式的 CAP 理论?
CAP原则又称CAP定理,指的是在一个分布式系统中,Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能同时满足其中的2个。
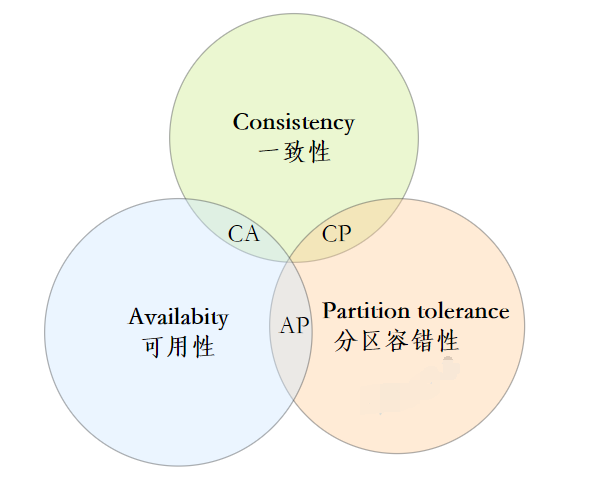
- 一致性 :数据在多个副本之间能够保持一致的特性。
- 可用性:系统提供的服务一直处于可用的状态,每次请求都能获得正确的响应。
- 分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
CAP三者不可同得,那么必须得做一些权衡。
CA without P
如果不要求P(不允许分区),则C(强一致性)和A(可用性)是可以保证的。但是对于分布式系统,分区是客观存在的,其实分布式系统理论上是不可选CA的。
CP without A
如果不要求A(可用),相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式。
AP wihtout C
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
t C**
要高可用并允许分区,则需放弃一致性。一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。


![[LeetCode周赛复盘] 第 343 场周赛20230430](https://img-blog.csdnimg.cn/46ea90ad5f0f409e8ae4b116f78b6c80.png)