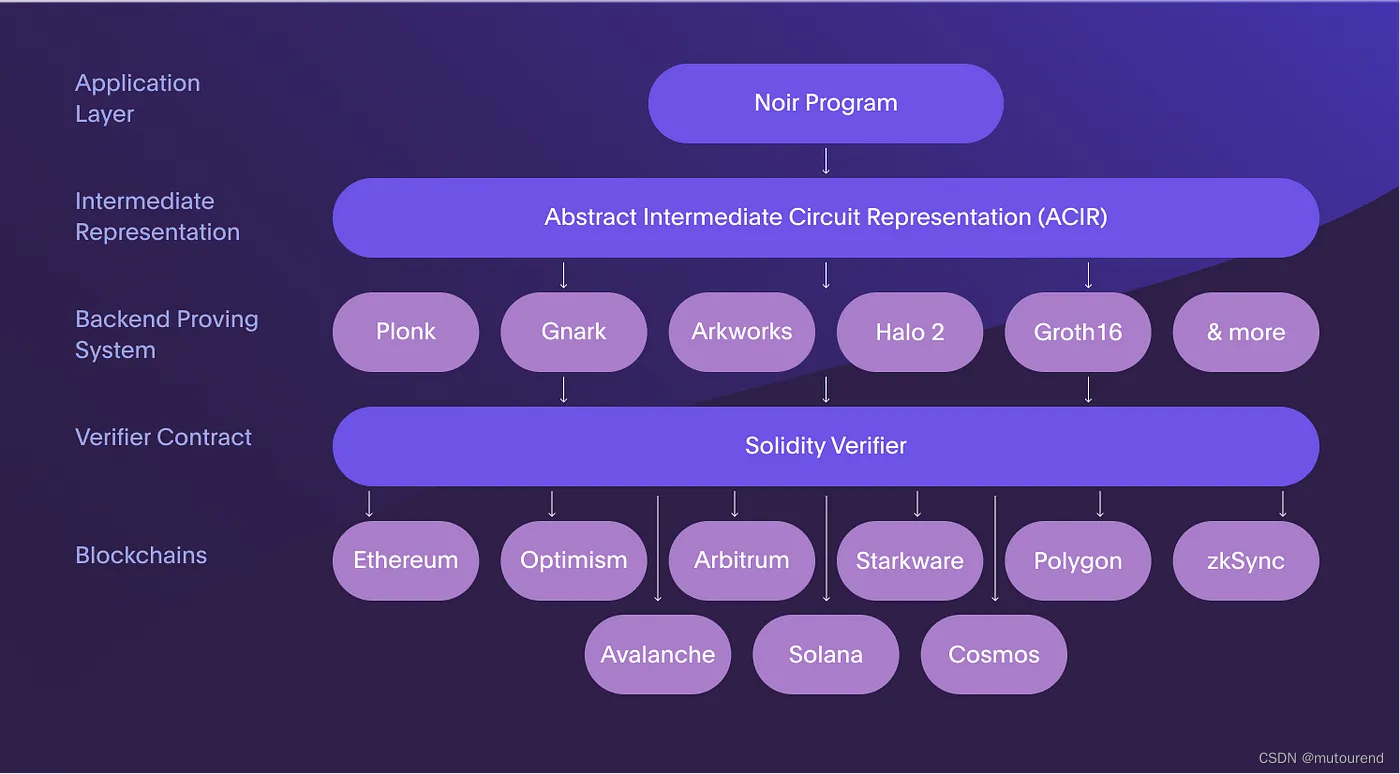
分布式深度学习里的通信严重依赖于规则的集群通信诸如 all-reduce, reduce-scatter, all-gather 等,因此,实现高度优化的集群通信,以及根据任务特点和通信拓扑选择合适的集群通信算法至关重要。
本文以数据并行经常使用的 all-reduce 为例来展示集群通信操作的数学性质。
1、all-reduce 在干什么?
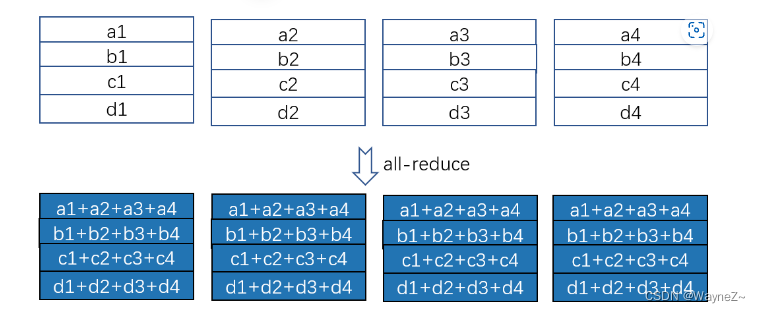
如图 1 所示,一共 4个设备,每个设备上有一个矩阵(为简单起见,我们特意让每一行就一个元素),all-reduce 操作的目的是,让每个设备上的矩阵里的每一个位置的数值都是所有设备上对应位置的数值之和。
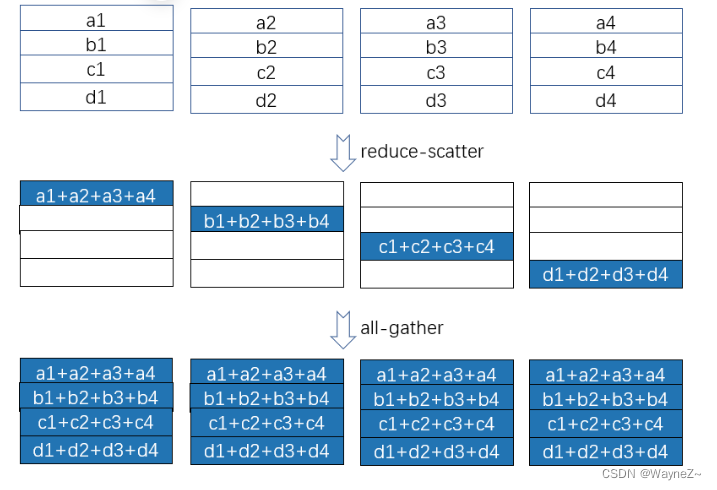
如图 2 所示, all-reduce 可以通过 reduce-scatter 和 all-gather 这两个更基本的集群通信操作来实现。基于 ring 状通信可以高效的实现 reduce-scatter 和 all-gather,下面我们分别用示意图展示其过程。
2、reduce-scatter 的实现和性质

高效实现一个集群通信的关键是如何充分利用设备和设备之间的带宽,基于环状(ring)通信实现的集群通信算法就是这一思想的体现。
从图 2 可以看出,reduce-scatter 的结果是每个设备保存一部分 reduce 之后的结果。
为了方便讨论,我们先定义一些符号。
- 假设有p 个设备(上面的例子中p=4);
- 假设整个矩阵大小是V, 那么 reduce-scatter 后,每个设备上有 V/p 大小的数据块;
- 假设卡和卡之间通信带宽是 B,而且是双工通信(duplex),即每个设备出口和入口带宽可以同时达到 B,所有设备的入口带宽总和是 p×B ,所有设备的出口带宽总和也是p×B.
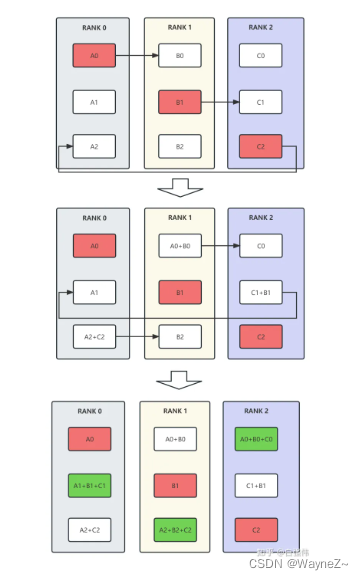
我们以 reduce-scatter 为例来看看环状通信算法是怎么工作的。一共有p 个设备,每个设备上数据都划分为p 份,环状 reduce-scatter 一共需要p-1 步才能完成。
- 在第 1 步中,每个设备都负责某一块 V/p 的数据并向左边的设备发送这块数据,如在图 3 中,第 1 个设备负责第 2 片数据并向第 0 个设备发送(也就是第 4 个设备),第 2 个设备负责第 3 片数据并向第 1 个设备发送,第 3 个设备负责第 4 片数据并向第 2 个设备发送,第 4 个设备负责第 1 片数据并向第 3 个设备发送,每个设备收到右边设备的数据后,就把收到的数据累加到本地对应位置的数据上去(通过逐渐变深的颜色表示数据累加的次数更多)。注意,在这样的安排下,每个设备的入口带宽和出口带宽都被用上了,而且不会发生争抢带宽的事情.
- 在第 2 步中,第 1 个设备把累加后的第 3 片数据向第 0 个设备发送(也就是第 4 个设备),第 2 个设备把累加后的第 4 片数据向第 1 个设备发送,第 3 个设备把累加后的第 1 片数据向第 2 个设备发送,第 4 个设备把累加后的第 2 片数据向第 3 个设备发送,每个设备收到右边设备发过来的数据后,就把收到的数据累加到本地对应位置的数据上去(累加后颜色更深)。
- 在第 3 步中,第 1 个设备把累加后的第 4 片数据向第 0 个设备发送(也就是第 4 个设备),第 2 个设备把累加后的第 1 片数据向第 1 个设备发送,第 3 个设备把累加后的第 2 片数据向第2 个设备发送,第 4 个设备把累加后的第 3 片数据向第 3 个设备发送,每个设备收到右边设备发送过来的数据后,就把收到的数据累加到对应位置的数据上去(累加后颜色更深)。
经过p-1 步之后,每个设备上都有了一片所有设备上对应位置数据 reduce 之后的数据。整个过程中,每个设备向外发送了Vsend =(p−1)*V/p 大小的数据,也收到了Vrec = (p−1)*V/p 大小的数据,因为每个设备的出口或入口带宽是B,所以整个过程需要的时间是Vsend / B,如果 p 足够大,完成时间近似为V/B ,神奇的是,这个时间和设备数p 无关。当然,在所有设备间传递的数据量是Vsend * p = (p-1)V,和设备数p成正比。
强调一下:基于环状通信的集群通信算法执行时间几乎和设备数无关,但总通信量和设备数成正比。
3、all-gather 的实现和性质
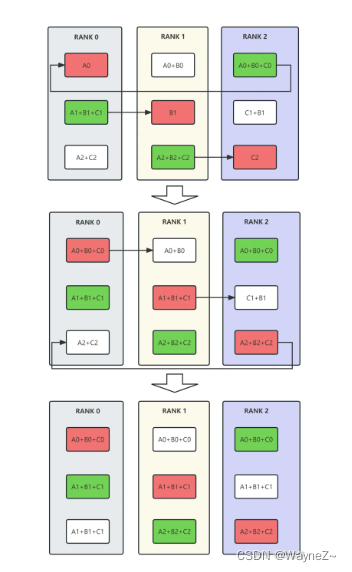
reduce-scatter 执行结束之后,再通过 all-gather 过程就可以实现 all-reduce,其中 all-gather 也可以通过环状通信算法来实现。

图 4 给出了环状 all-gather 的实现过程,我们就不详细描述了,值得注意的是,它的通信时间和通信量的分析与 reduce-scatter 一模一样:整个过程需要的时间是 Vsend / B ,如果p足够大,完成时间近似为V/B,这个时间和设备数p无关,当然,在所有设备间传递的数据量是(p-1)V,和设备数 p 成正比。不过,请注意在 reduce-scatter 里,V 都是完整矩阵的数据量,即 reduce-scatter 输入矩阵的数据量和 all-gather 输出矩阵的数据量。
4、通信量和冗余显存之间的关系
文只分析了通信量,而没有分析对设备显存的占用量。
以图 3 为例,每个设备上的输入矩阵大小是V,但经过 reduce-scatter 之后每个设备上只需要V/p大小的显存,也就是 V-V/p = (p-1)*V/p的空间是冗余的,因为一共有p个设备,所以整个集群中有(p-1)V的显存是可以节省下来的。注意,每个设备冗余的显存恰好和每个设备的通信量一致,所有设备冗余的显存和所有设备的总通信量一致。
以图 4 为例,每个设备上的输入矩阵大小是V/p,但经过 all-gather 之后每个设备上需要的显存是V,而且每个设备上的矩阵的大小和数值都完全一样,也就是经过 all-gather 之后,在设备之间产生了冗余,不同的设备存储了一些完全一样的数据。同样,每个设备冗余的显存恰好和每个设备的通信量一致,所有设备冗余的显存和所有设备的总通信量一致。
当然,冗余量和通信量之间的等价关系不是偶然的,正是因为这些通信才造成了设备之间数据的冗余。因此,当保持V 不变时,增大设备数p(我们不妨称 p 为集群通信的并行宽度)时,所有设备之间的通信量是正比增长的,而且在所有设备上造成的冗余显存是正比例增长的。当然,完成一个特定的集群通信所需要的时间基本和并行宽度 p 无关。
因此,增加并行宽度 p 是一个双刃剑,一方面它让每个设备处理的数据量更小,即V/p,从而让计算的时间更短,但另一方面,它会需要更多的通信带宽(p-1)V,以及更多的显存空间(p-1)V。
5、环状算法的最优性
前面提了一个问题:能不能想出比环状算法更好的集群算法实现?答案是,理论上不可能有更好的算法了。
我们已经分析过了要完成 reduce-scatter 和 all-gather 每个设备至少要向外发送(以及同时接收)的数据量是Vsend = (p-1)*V/p,无论使用什么算法,这个数据量是不可能更少了。
在这个数据量下,最少需要多少时间呢?出口带宽是 B,因此一张卡向外发送数据至少需要的时间是Vsend/B ,这也正是环状算法需要的时间。
我们来计算下整个Allreduce过程的通信成本。假设我们有N个设备,每个设备的数据大小为K,在一次Allreduce过程中,我们进行了N-1次Scatter-Reduce操作和N-1次Allgather操作,每一次操作所需要传递的数据大小为K/N,所以整个Allreduce过程所传输的数据大小为2(N-1) * K/N (< 2K,与设备数N无关),而整个Allreduce的通信速度只受限于逻辑环中最慢的两个GPU的连接(每次需要通信的数据大小仅为K/N,随着N增大,通信量减少,一般小于network bandwidth)。
由于所有传输都是在离散迭代中同步进行的,因此所有传输的速度受到环中相邻GPU之间最慢(最低带宽)连接的限制。给定每个GPU的邻居的正确选择,该算法是带宽最优的,并且是执行全面操作的最快算法(假设延迟成本与带宽相比可以忽略不计)。一般来说,如果一个节点上的所有GPU在环中彼此相邻,则该算法的功能最佳;这最小化了网络争用的量,否则这可能会显著降低GPU-GPU连接的有效带宽。
当然,我们这里的通信时间只考虑传输带宽,而没有考虑每次传输都包含的延迟(latency)。当数据量V比较大时,延迟项可以忽略,上文的分析就是成立的。当 V 特别小,或者设备数 p 特别大时,带宽B就变得不重要了,反而是延迟比较关键,这时更好地实现就不是环状算法了,而应该使用树状通信。
这也是为什么英伟达 NCCL 里既实现了ring all-reduce,也实现了 double-tree all-reduce 算法(https://developer.nvidia.com/blog/massively-scale-deep-learning-training-nccl-2-4/)‘
手把手推导Ring All-reduce的数学性质 - 知乎 (zhihu.com)



![[Gitops--10]微服务项目部署流水线编写](https://img-blog.csdnimg.cn/c45505142b8945f8890a0b3086d26ef7.png)