在这个例子中,我们会介绍如何从我们本地读取多个文档构建知识库,并且使用 Openai API 在知识库中进行搜索并给出答案。
目录
一、安装向量数据库chromadb和tiktoken
二、使用案例
三、embeddings持久化
四、在线的向量数据库Pinecone
一、安装向量数据库chromadb和tiktoken
pip install chromadb
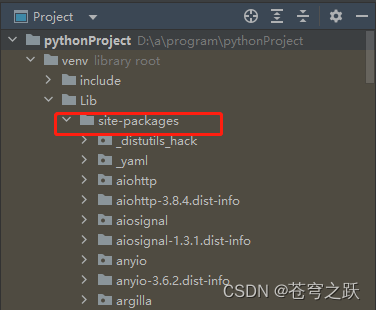
其中hnswlib安装不了,去一下网站下载源码解压后,将hnswlib文件夹放在了项目的\Lib\site-packages文件夹中
GitHub - nmslib/hnswlib: Header-only C++/python library for fast approximate nearest neighbors
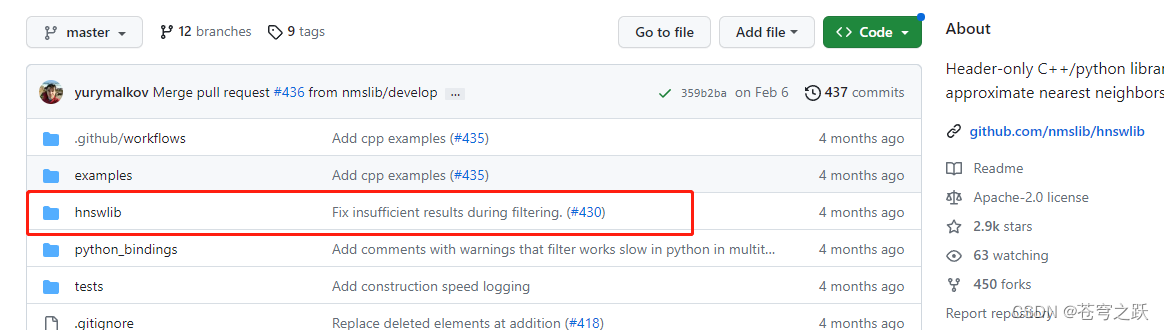
安装一下 pybind1
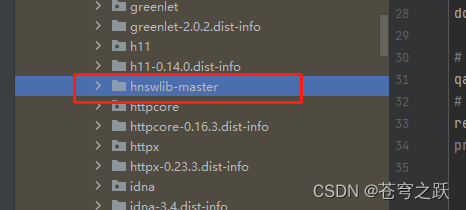
pip install pybind11安装hnswlib,cd到site-packages\hnswlib-master目录下执行
python setup.py install可能会直接成功,也可能报下面的错误

解决方案:
Rust 在 Windows10 下安装/执行出错的解决方法 | 蓝色梦想
重新安装hnswlib,cd到site-packages\hnswlib-master目录下执行
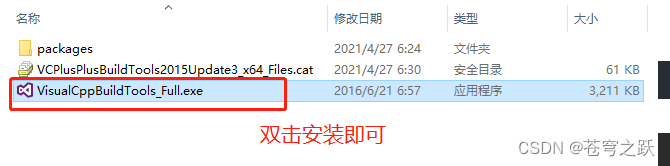
python setup.py install 下载Visualstudio安装,勾选如图https://download.visualstudio.microsoft.com/download/pr/473f1a59-e5bc-4332-8f76-5ff45df9cd24/c237d0f541dff305e3cd6d591710bf175a040af24570a6fdefca4a39fa7f0a93/vs_BuildTools.exe
下载Visualstudio安装,勾选如图https://download.visualstudio.microsoft.com/download/pr/473f1a59-e5bc-4332-8f76-5ff45df9cd24/c237d0f541dff305e3cd6d591710bf175a040af24570a6fdefca4a39fa7f0a93/vs_BuildTools.exe![]() https://download.visualstudio.microsoft.com/download/pr/473f1a59-e5bc-4332-8f76-5ff45df9cd24/c237d0f541dff305e3cd6d591710bf175a040af24570a6fdefca4a39fa7f0a93/vs_BuildTools.exe
https://download.visualstudio.microsoft.com/download/pr/473f1a59-e5bc-4332-8f76-5ff45df9cd24/c237d0f541dff305e3cd6d591710bf175a040af24570a6fdefca4a39fa7f0a93/vs_BuildTools.exe
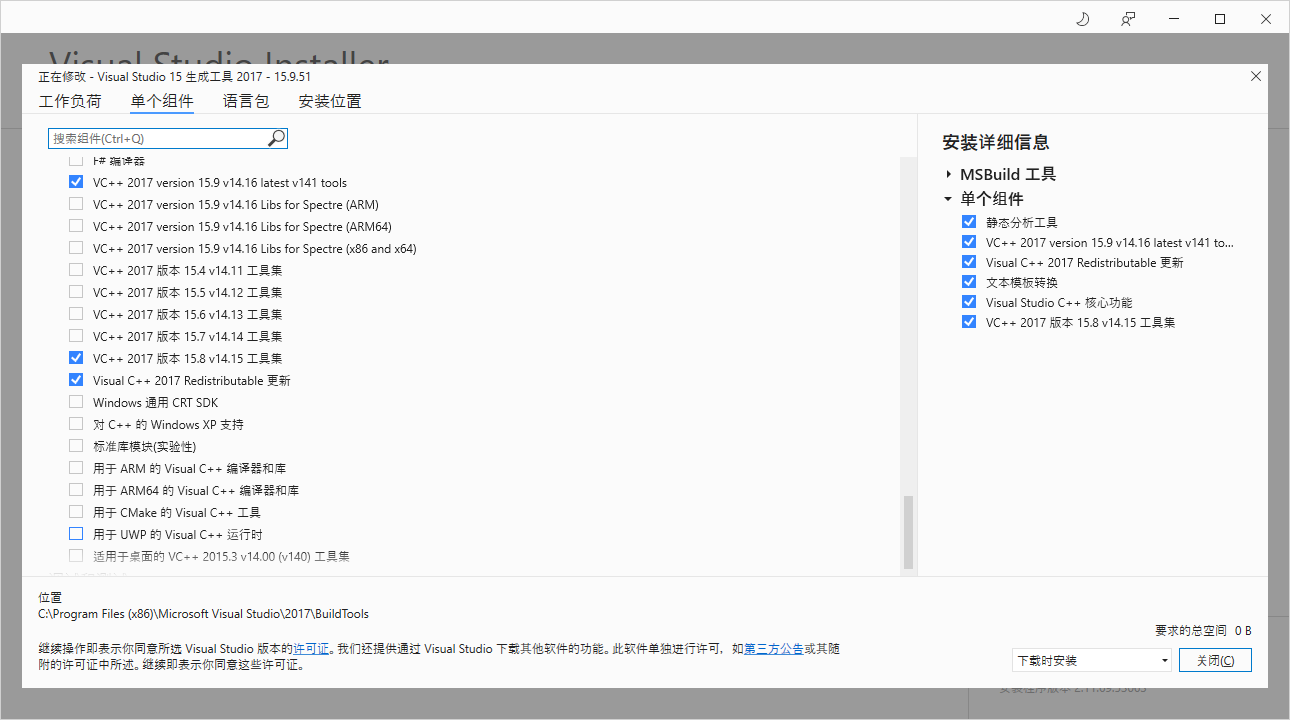
安装完毕后,再次安装hnswlib
python setup.py install
再次安装chromadb即可成功。
pip install chromadb
安装依赖
pip install tiktoken二、使用案例
在项目中新建一个data文件夹,里面放一个doc.txt,内容我摘抄一段朱炫大师兄的年少荒唐中的文章。
import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI, VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
# openAI的Key
os.environ["OPENAI_API_KEY"] = '**********************'
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('D:\pythonwork\mindlangchain\data', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)
# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch, return_source_documents=True)
# 进行问答
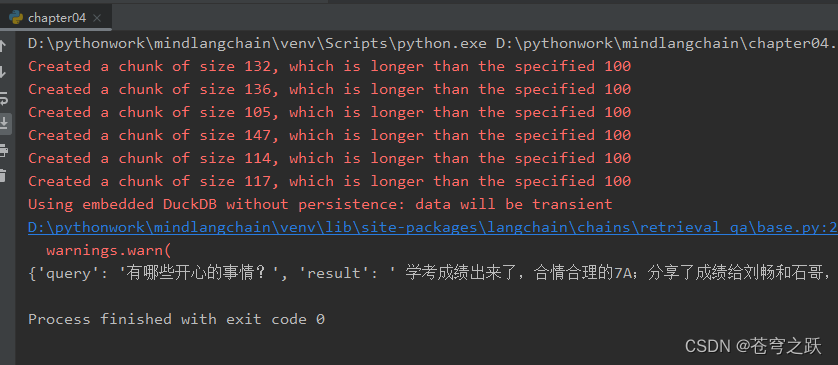
result = qa({"query": "有哪些开心的事情?"})
print(result)
三、embeddings持久化
上个案例里面有一步是将 document 信息转换成向量信息和embeddings的信息并临时存入 Chroma 数据库。
因为是临时存入,所以当我们上面的代码执行完成后,上面的向量化后的数据将会丢失。如果想下次使用,那么就还需要再计算一次embeddings,这肯定不是我们想要的。
那么,这个案例我们就来通过 Chroma 和 Pinecone 这两个数据库来讲一下如何做向量数据持久化。
上面的案例中我们只是将embeddings临时存进了Chroma,只需多加一个路径参数就可以实现持久化。

import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI, VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
# openAI的Key
os.environ["OPENAI_API_KEY"] = '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'
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('D:\pythonwork\mindlangchain\data', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
vector_store_path = r"D:\pythonwork\mindlangchain\vector_store"
docsearch = Chroma.from_documents(documents=split_docs,
embedding=embeddings,
persist_directory=vector_store_path)
# docsearch = Chroma(persist_directory=vector_store_path,embedding_function=embeddings)
# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch, return_source_documents=True)
# 进行问答
result = qa({"query": "有哪些开心的事情?"})
print(result)
读取持久化的embeddings:

import os
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI, VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
# openAI的Key
os.environ["OPENAI_API_KEY"] = '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'
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('D:\pythonwork\mindlangchain\data', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
vector_store_path = r"D:\pythonwork\mindlangchain\vector_store"
# docsearch = Chroma.from_documents(documents=split_docs,
# embedding=embeddings,
# persist_directory=vector_store_path)
docsearch = Chroma(persist_directory=vector_store_path,embedding_function=embeddings)
# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch, return_source_documents=True)
# 进行问答
result = qa({"query": "有哪些开心的事情?"})
print(result)
四、在线的向量数据库Pinecone
Pinecone 是一个在线的向量数据库。所以,我可以第一步依旧是注册,然后拿到对应的 api key。(免费版如果索引14天不使用会被自动清除)
Pinecone ConsoleWeb site created using create-react-apphttps://app.pinecone.io/
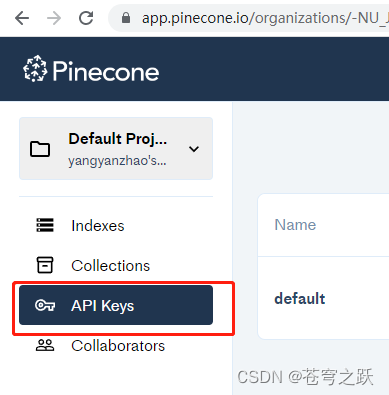
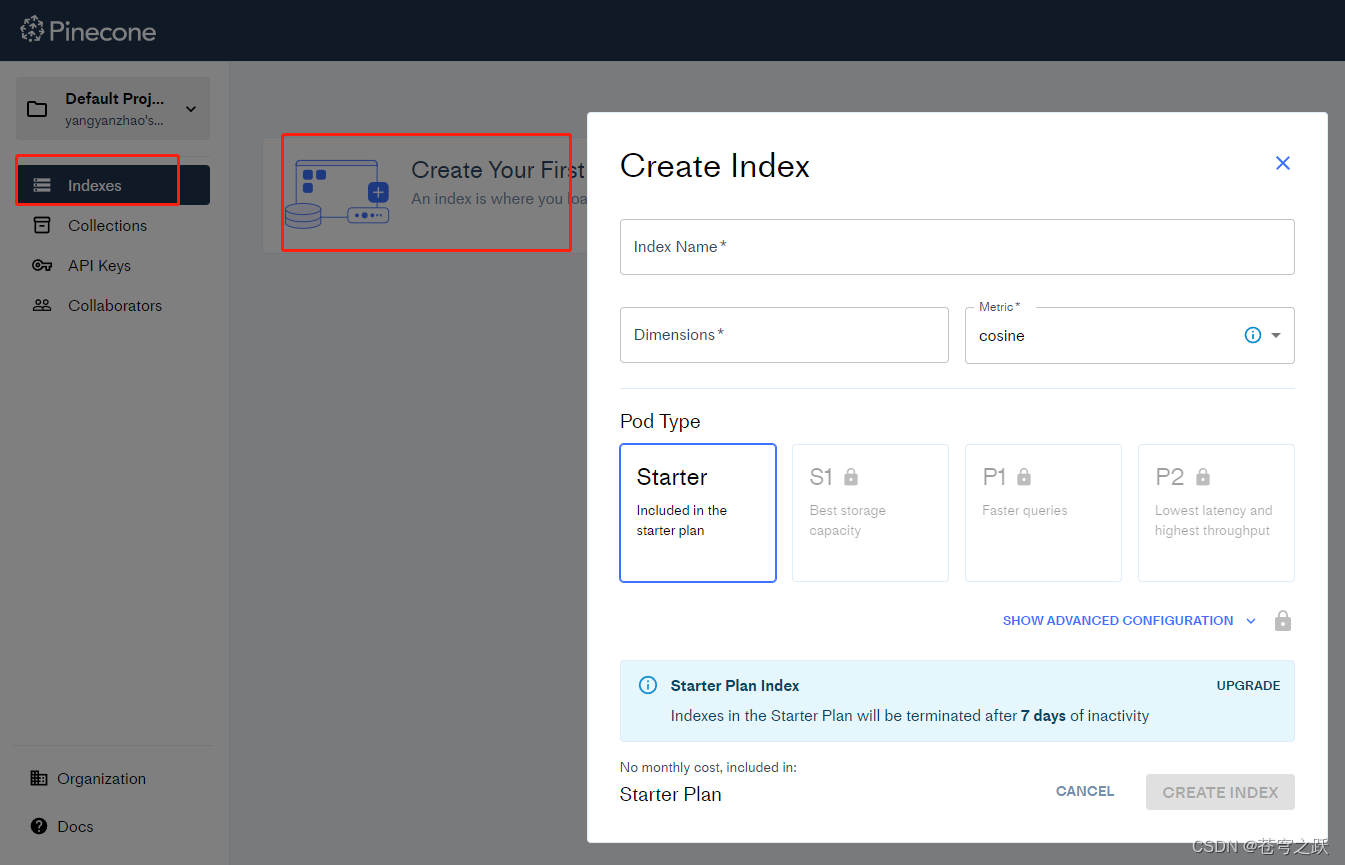
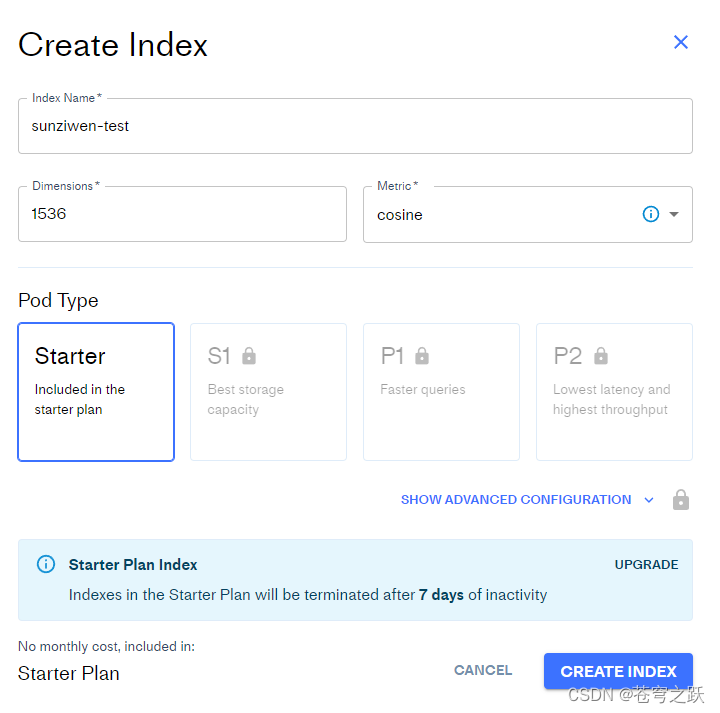
创建数据库
# 持久化数据
docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
# 加载数据
docsearch = Pinecone.from_existing_index(index_name, embeddings)